
Incremental Learning-Based Algorithm for Anomaly Detection Using Computed Tomography Data

Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental CT Dataset
- Defect-free scans [M1 and M2] are two reference scans of a complete tool with no missing pieces.
- Defective scans [M3–M21] are scans with various missing components such as spring stoppers, an internal disk pin, spring holders, spring support components, and/or inner disk clips (see Table 1 for more details on the defect types).
2.2. Anomaly Detection Model
2.3. The Proposed Thresholding-Based Algorithms
- Soft-thresholding-based training: The soft thresholding scheme uses all exemplars of the past data (that is, the data used previously for training) and combines them with the new data.The flowchart of the proposed scheme as shown in Figure 5 is summarized as follows. First, the new labelled scans of data are acquired. The next step is to determine whether old labelled scans of the data exist. If old data scans exist, the soft thresholding scheme will combine all the old data scans and new data scans and build a balanced dataset for training. Therefore, an equal number of image instances is represented per class for each training, validation, and testing set. If no old scans exist, only the new data scans will be used to build a balanced training set for training. If there is an existing model, the model is reloaded and used for training; otherwise, a new model is trained. The model is trained and validated using the training and validation sets, respectively, and the confidence score is obtained. The model retrains until the confidence score is greater than a specified confidence threshold (95%) or until the maximum number of times to repeat training () is achieved. The final model is saved. The entire process continues if new labeled scans of data are received.Algorithm 1 provides the proposed algorithm.
- Selective soft-thresholding-based training: The selective soft thresholding scheme uses the optimal training dataset selection process to select the old data or scans to be combined with the new data during training. The optimal training dataset selection process involves selecting old scan data whose accuracy fell below the specified threshold of . If no previously trained data fall within the specified threshold interval , the threshold will automatically be increased gradually (e.g., by each time) until at least one scan is selected to start the training process. If no optimal old data are returned, all old data are selected for training. After the selection of these old data, they are combined with the new data forming the training set of the task as shown in detail in Algorithm 2. This selection process is very important because it recognizes the previously trained data that falls outside the category of the specified accuracy threshold and selects them for further training with the model. Therefore, this saves some memory by selecting a subset of the old scan data to be trained further in combination with the new scan data. In addition, this also provides an opportunity to further train on the data in cases where the model performance was still below the desired threshold. The flowchart of the selective soft thresholding scheme is outlined in Figure 5.
| Algorithm 1: The proposed soft thresholding training algorithm |
 |
| Algorithm 2: Select optimal scans from old data |
 |
3. Results and Discussion
3.1. Comparison of the Proposed Soft Thresholding Schemes and the Nonincremental Scheme
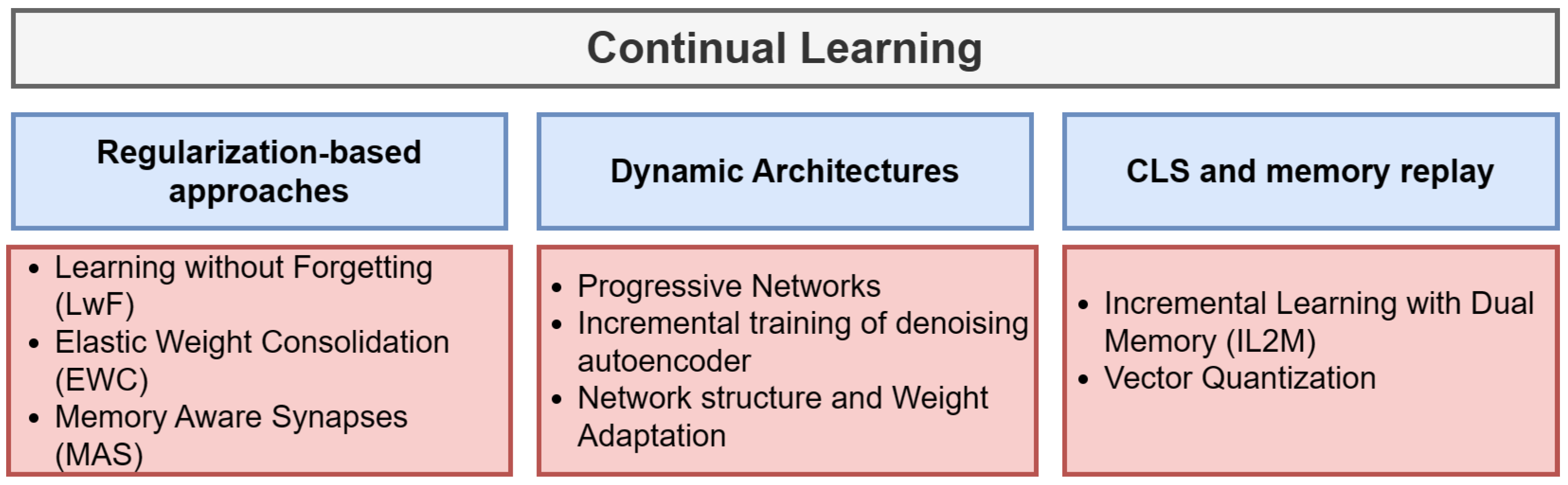
3.2. Performance Sensitivity Analysis Using Existing Incremental Learning Methods
3.3. Limitations
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CT | Computed Tomography |
| EWC | Elastic Weight Consolidation |
| IL | Incremental Learning |
| MAS | Memory-aware Synapses |
| MLP | Multilayer Perceptron |
| NDT | Nondestructive Testing |
| SI | Synaptic Intelligence |
References
- Geng, X.; Smith-Miles, K. Incremental Learning. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009; pp. 731–735. [Google Scholar] [CrossRef]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual Lifelong Learning with Neural Networks: A Review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Liu, B. Lifelong Machine Learning. In Synthesis Lectures on Artificial Intelligence and Machine Learning; Springer: Cham, Switzerland, 2018; p. 187. [Google Scholar] [CrossRef]
- Delange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A Continual Learning Survey: Defying Forgetting in Classification Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3366–3385. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Yin, L.; Bai, W.; Mao, K. An Appraisal of Incremental Learning Methods. Entropy 2020, 22, 1190. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aljundi, R.; Babiloni, F.; Elhoseiny, M.; Rohrbach, M.; Tuytelaars, T. Memory Aware Synapses: Learning What (not) to Forget. In Proceedings of the Computer Vision–ECCV 2018, Munich, Germany, 8 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11207, pp. 144–161. [Google Scholar] [CrossRef] [Green Version]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming Catastrophic Forgetting in Neural Networks. arXiv 2017, arXiv:1612.00796. [Google Scholar] [CrossRef] [PubMed]
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K.; Pascanu, R.; Hadsell, R. Progressive Neural Networks. arXiv 2022, arXiv:1606.04671. [Google Scholar] [CrossRef]
- Zhou, G.; Sohn, K.; Lee, H. Online Incremental Feature Learning with Denoising Autoencoders. In Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, La Palma, Canary Islands, 21 April 2012; Volume 22, pp. 1453–1461. [Google Scholar]
- Mehrotra, K.; Mohan, C.; Ranka, S. Elements of Artificial Neural Networks; The MIT Press: Cambridge, MA, USA, 1996. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 1 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Belouadah, E.; Popescu, A. IL2M: Class Incremental Learning with Dual Memory. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019; pp. 583–592. [Google Scholar] [CrossRef]
- Srivastava, S.; Yaqub, M.; Nandakumar, K.; Ge, Z.; Mahapatra, D. Continual Domain Incremental Learning for Chest X-ray Classification in Low-Resource Clinical Settings. In Domain Adaptation and Representation Transfer, and Affordable Healthcare and AI for Resource Diverse Global Health; Springer: Cham, Switzerland, 2021; Volume 12968, pp. 226–238. [Google Scholar] [CrossRef]
- Gabbar, H.A.; Chahid, A.; Khan, M.J.A.; Adegboro, O.G.; Samson, M.I. CTIMS: Automated Defect Detection Framework Using Computed Tomography. Appl. Sci. 2022, 12, 2175. [Google Scholar] [CrossRef]
- Belouadah, E. Large-Scale Deep Class-Incremental Learning. Computer Vision and Pattern Recognition [cs.CV]. Thesis, Ecole Nationale Supérieure Mines-Télécom Atlantique, Paris, France, 2021. [Google Scholar]
- Van de Ven, G.M.; Tuytelaars, T.; Tolias, A.S. Three Types of Incremental Learning. Nat. Mach. Intell. 2022, 4, 1185–1197. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Liu, S.; Xiang, Y.; Duan, Z.; Zhao, C.; Lu, Y. Incremental Learning based Multi-Domain Adaptation for Object Detection. Knowl.-Based Syst. 2020, 210, 106420. [Google Scholar] [CrossRef]
- Hsu, Y.-C.; Liu, Y.-C.; Ramasamy, A.; Kira, Z. Re-evaluating Continual Learning Scenarios: A Categorization and Case for Strong Baselines. arXiv 2019, arXiv:1810.12488. [Google Scholar]
- Diondo X-ray Systems and Services. Available online: https://www.diondo.com/ (accessed on 2 July 2023).
- New Vision Systems Canada Inc. Available online: https://nvscanada.ca/ (accessed on 2 July 2023).
- Schimanek, R.; Bilge, P.; Dietrich, F. Inspection in High-Mix and High-Throughput Handling with Skeptical and Incremental Learning. TechRxiv 2023. techrxiv: 23284049. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CT-Scan Name | Defect Picture | Image Examples |
|---|---|---|
| M1 and M2 |  |  |
| M3 and M4 |  |  |
| M6, M7, M8, and M9 |  |  |
| M10, M11, M12, and M13 |  |  |
| M14, M15, M16, and M17 |  |  |
| M18, M19, M20, and M21 |  |  |
| Scheme | Number of Tasks | Accuracy (%) | Confidence Score (%) |
|---|---|---|---|
| Soft Thresholding | 10 | 100 | 85.33 |
| Selective Soft Thresholding | 10 | 86 | 88.07 |
| Nonincremental approach | NA | 99.67 | NA |
| Parameter | Number of Tasks |
|---|---|
| Epoch | 100 (per task) |
| Batch size | 128 |
| Model architecture | MLP and ResNet18 |
| Loss function | Cross entropy |
| Optimizer | Adam |
| Learning rate |
| Nonselective Scheme | Selective Scheme | ||||
|---|---|---|---|---|---|
| Model | Method | Baseline | Soft Threshold | Selective Baseline | Selective Soft Threshold |
| MLP | EWC | 84.44 ± 0.91 | 84.79 ± 1.38 | 79.26 ± 5.87 | 79.79 ± 1.88 |
| Online EWC | 82.97 ± 0.35 | 84.05 ± 1.71 | 79.76 ± 0.83 | 82.61 ± 1.16 | |
| SI | 83.43 ± 0.74 | 82.48 ± 1.65 | 81.57 ± 1.48 | 82.63 ± 0.13 | |
| MAS | 83.45 ± 2.93 | 83.44 ± 1.54 | 82.34 ± 0.95 | 78.73 ± 2.85 | |
| ResNet | EWC | 99.06 ± 0.23 | 98.98 ± 0.28 | 93.44 ± 0.98 | 94.64 ± 1.56 |
| Online EWC | 98.99 ± 0.16 | 98.79 ± 0.12 | 91.83 ± 2.64 | 93.18 ± 1.51 | |
| SI | 98.87 ± 0.28 | 99.29 ± 0.05 | 92.55 ± 1.34 | 91.78 ± 1.23 | |
| MAS | 98.50 ± 0.57 | 98.91 ± 0.05 | 93.22 ± 0.50 | 93.84 ± 0.60 | |
| Experiment | MLP | ResNet | |||
|---|---|---|---|---|---|
| Average Accuracy (%) | Baseline | SI | 84.58 ± 0.86 | SI | 98.70 ± 0.39 |
| Selective | MAS (S) | 83.02 ± 0.78 | MAS (S) | 94.87 ± 1.35 | |
| Soft Thresholding | EWC (+) | 84.53 ± 1.10 | EWC (+) | 98.72 ± 0.32 | |
| Selective Soft Thresholding | EWC (S+) | 84.25 ± 2.59 | EWC Online (S+) | 94.42 ± 1.03 | |
| Experiment | MLP | ResNet | |||
|---|---|---|---|---|---|
| Confidence Score | Baseline | SI | 83.43 | EWC | 98.30 |
| Selective | MAS (S) | 81.91 | EWC (S) | 93.44 | |
| Soft Thresholding | EWC (+) | 82.81 | EWC (+) | 98.30 | |
| Selective Soft Thresholding | EWC Online (S+) | 82.61 | EWC Online (S+) | 93.18 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gabbar, H.A.; Adegboro, O.G.; Chahid, A.; Ren, J. Incremental Learning-Based Algorithm for Anomaly Detection Using Computed Tomography Data. Computation 2023, 11, 139. https://doi.org/10.3390/computation11070139
Gabbar HA, Adegboro OG, Chahid A, Ren J. Incremental Learning-Based Algorithm for Anomaly Detection Using Computed Tomography Data. Computation. 2023; 11(7):139. https://doi.org/10.3390/computation11070139
Chicago/Turabian StyleGabbar, Hossam A., Oluwabukola Grace Adegboro, Abderrazak Chahid, and Jing Ren. 2023. "Incremental Learning-Based Algorithm for Anomaly Detection Using Computed Tomography Data" Computation 11, no. 7: 139. https://doi.org/10.3390/computation11070139