1. Introduction
The vibration signal contains meaningful information about the appearance of fault/damage on mechanical systems [
1,
2]. Therefore, it has been widely used for DDM-based MFI [
3,
4,
5,
6]. Accordingly, a data matrix
labeled via vector
(called source domain) is built in the offline phase to identify the dynamic response of the managed mechanical object (MMO), whereas a data matrix
(called target domain) is set up online to reflect the dynamic behavior of the MMO at the survey time. With advantages in managing inaccurate and uncertain databases, fuzzy logic (FL) and artificial neural networks (ANN) are employed extensively for this approach [
7,
8,
9,
10]. Reality has shown that a fit fuzzy-set space for FL and a suitable net structure for ANN need to be pre-estlablished in each application. However, a satisfactory response to these requirements is often a considerable challenge [
11]. Additionally, processing noise online in SMD and mitigating the negative effect of domain drift between
and
are always difficult [
12,
13].
ANFIS is a fuzzy model that is set up automatically through the ANN’s training process. Due to being able to partly subdue the inherent difficulties of FL and ANN, it has been widely used, including the AI-based fault diagnosis [
7,
10]. ANFIS can also collaborate with singular spectrum analysis (SSA) successfully in applications related to time series [
11]. In such an approach, filtering noise in measured data or seeking information in data series are typical applications [
14,
15,
16]. For example, a continuous hidden Markov model to extract the bearing fault features relies on the singular features via SSA [
17], or processing data for an ANFIS-based classification derives from SSA [
11].
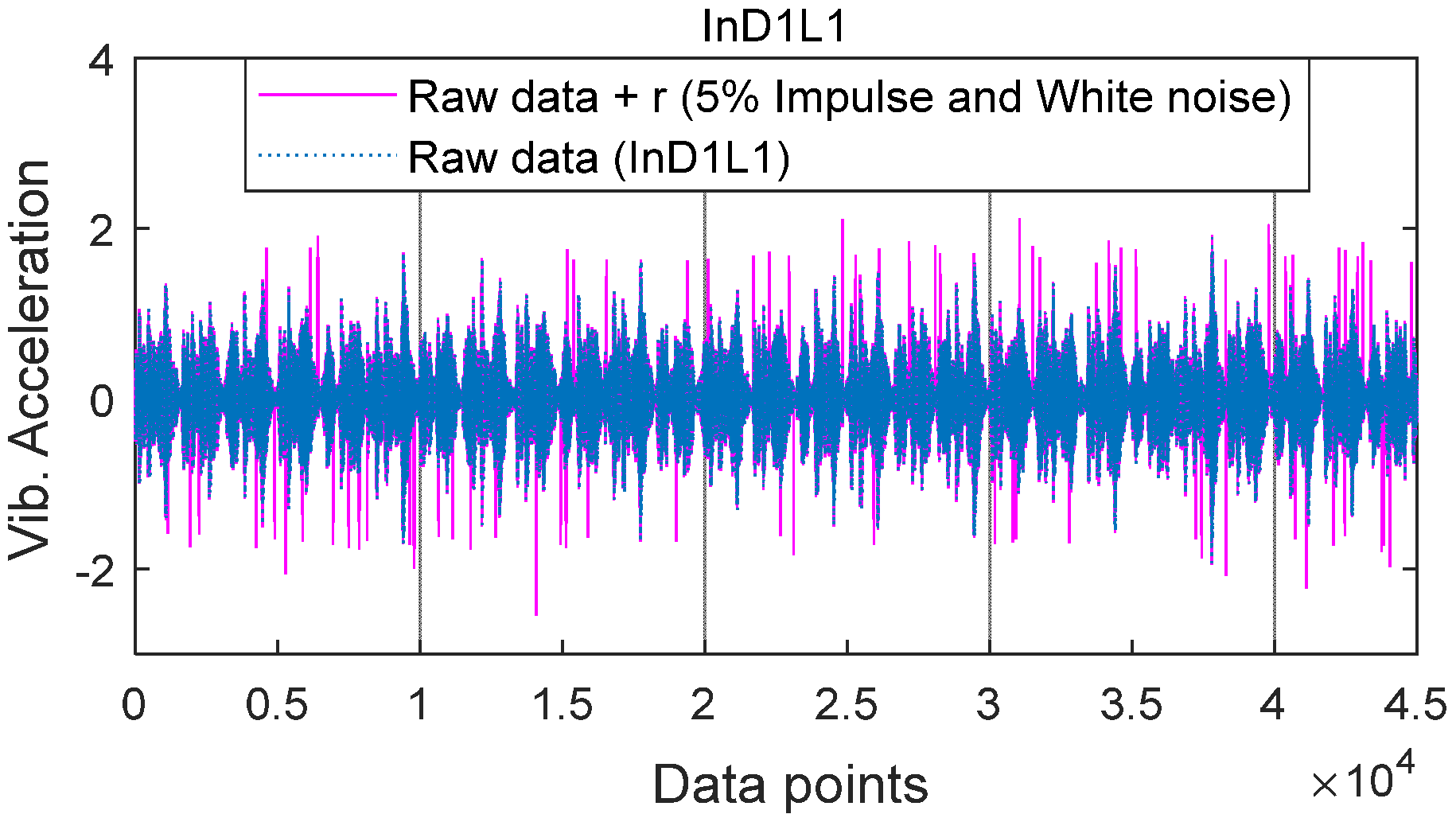
Noise in measurement data related to the measurement method and instrument errors, false observations, changing environmental conditions, or random aspects cause random IN (impulse noise). There is, however, still no sufficiently strong solution for canceling IN in measured data [
18]. This difficulty is because IN occurs randomly related to a group of factors whose circumstances and the mechanism that affects measurement accuracy are unknown; the source of these errors is unclear and not easy to find. Nguyen et al. [
19] presented a method of filtering random noise and IN in data derived from the dynamic response of smart dampers such as magnetorheological and electrorheological dampers. The filter relied on an optimal data screening threshold quantified via clustering results. Unfortunately, its narrow application scope is only the databases derived from the dynamic response of smart dampers.
Along with the negative impact of noise, DDSTD in the databases for MFI always exists, which reduces the effectiveness and feasibility of DDM-based MFIs in practical applications. In many cases, DDSTD is the main cause for a method with appropriate accuracy in the theoretical investigation, but not in its applications with practical operating conditions. It is the strong motivation attracting researchers to pay attention to seeking solutions for domain adaptation (DA) to take part in compensating adaptively for domain drift [
3,
4,
5,
6,
13]. Li et al. [
3] proposed a bearing fault diagnosis based on ANN and cross-domain. Wu et al. [
4] showed a method of bearing fault diagnosis that trained an ANN from the cross-domain to reduce the distribution difference between the source domain and target domain in each data channel. Another DA, called transfer Component analysis (Pal et al. [
13]), was also applied effectively for pattern analysis. It learned transfer components across domains in a reproducing kernel Hilbert space. In the subspace spanned by these transfer components, data properties are preserved, and data distributions in different domains become closer to each other. However, either generating the fake samples as shown by Li et al. [
3] or adjusting the ANN weights by Wu et al. [
4] leads to a disadvantage related to the cumulated error from the network-based MFIs. It is exacerbated under the influence of noise. Additionally, the impact of IN is the considerable difficulty encountered in the method of transfer component analysis, as shown by Pan et al. [
13].
Consequently, we propose an online bearing fault diagnosis method relying on ANFIS, named ANFIS-BFDM in this research, by seeking fit solutions for the aspects noted above. Namely, we (i) set up a fusion domain deriving from the source and target domains, and (ii) carry out tasks of processing measured data and exploiting the filtered data to classify/label via solutions understood as performing embedding processes in the fusion domain, , where is the data matrix containing the labeled samples (in the label vector ) corresponding to the bearing’s healthy condition, and the remainder in denoted is the unlabeled samples. These works can partially diminish the influence of DDSTD in data processing and fault identification. The ANFIS-BFDM has offline and online phases. First, in the offline, frequency-based splitting of SMDs into different time series is performed to cancel the high-frequency region. An optimal data screening threshold ODST is then distilled in the remaining low-frequency data, to which we develop an impulse noise filter named FIN. From SMDs processed by the FIN, the dynamic response of the managed bearing(s) is identified via an ANFIS. Finally, we exploit the FIN and the trained ANFIS in the online phase to filter noise and recognize the object’s health status online.
The three main contributions of this study follow. The first is the FIN. It follows the idea shown by Nguyen et al. [
19], where the change in the distribution of the cluster data space built from the measured data stream is employed to catch IN. However, instead of focusing on the source domain only as in this reference, we seek the change in the embedding data space called the fusion domain. It relies on an observation that the fusion domain can track the measured data stream better than the source domain. The reason is the existing domain drift between the source and target domains.
The second contribution is a solution of combination between SSA and the filter FIN to extend the frequency range of processed data. This aspect is a vital supplementation for the previous research [
11], where the high-frequency noise is filtered only.
The third contribution is the algorithm ANFIS-BFDM for identifying damage of the bearing(s). It consists in processing SMD streams based on SSA and the FIN, establishing a multifeature from the processed data, and the ANFIS-based interpolation (1), where the ANFIS takes the role of a mapping from the fusion domain
to the target domain
:
where
is the output vector of the ANFIS corresponding to the input
. In this relationship, instead of using a data-driven model to identify the source domain
, as shown by Lei et al. [
10] and Tran et al. [
11], we exploit
to make the negative impacting degree of domain drift between the source and target domains weaken.
During this paper, we use the abbreviations and symbols in
Table 1.
2. Related Works
Let us consider a given initial data set (IDS), consisting of input–output data points , where belongs to the input data space X and belongs to the output data space y. The IDS is a measured database with noise, including random and impulse noise (IN), expressing an unknown mapping .
This section shows (i) an approximation of the mapping
f using ANFIS, and (ii) the method for filtering IN based on ANFIS. These contents are exploited in the proposed theory, described in
Section 3.
2.1. Building ANFIS from a Database
The algorithm named ANFIS-JS (Nguyen et al. [
16]) for building an ANFIS from the joined input–output data space IDS is presented here. It is exploited in
Section 3 to (i) set up a cluster data space (CDS) for our proposed filter (named FIN) for filtering IN in mechanical vibration databases, and (ii) build ANFISs for our proposed method of DDM-based fault diagnosis. The algorithm for kernel fuzzy
C-means clustering with kernelization (KFCM-K) (Marcelo et al. [
20]) is adopted here. Accordingly, clusters
are established through seeking cluster centers
in the input space such that
, where
is the kernel function and
is the fuzzy factor. In the case of using Gaussian kernel function
K(.), the update law of the cluster centroids
and the membership degree of the
j-th data point for the
i-th cluster (
) can be inferred from (2) as follows:
The hard distribution in the CDS can be set up. The j-th data point is called to be distributed hardly into the q-th cluster if . In this hard distribution, the created data clusters are the so-called hard clusters.
2.2. Optimal Data Screening Threshold
This subsection summarizes the algorithm AfODST (Nguyen et al. [
19]) called Algorithm 1 in this paper. The algorithm takes part in the proposed new filter named FIN in the following section.
2.2.1. Related Definitions
First, the given IDS is re-formed as a new database:
, in which
By using the algorithm KFCM-K for , a CDS of C data fuzzy clusters signed , is obtained.
Definition 1. (Convergent degree). Convergent degree of is defined as follows: where , and is the number of data points to be distributed hard in .
Definition 2. (Distribution radius). Distribution radius of data cluster , signedis defined: where
is the membership degree of the q-th data point belonging to the k-th cluster to be estimated by (4);
is the Euclidean distance between data point
and cluster centroid . The normalized distribution radius Rk is defined as follows: Remark 1. The distribution radius in Definition 2 is normalized to remove the dimension. Based on this approach, the filter FIN proposed in Section 3 can match with different numerical databases well.
Definition 3. (Data dispersion). The dispersion of data points in the k-th cluster signed is then defined: where
is an experience formula. 2.2.2. The AfODST
can be redepicted
From a given IDS, ODST-trainset and ODST-testset are set up. They are the two distinct datasets with the same size and input–output structures as shown in (10). Then, an ANFIS named ANFIS_train (with
input data clusters in the input cluster data space iCDS
1) is built from ODST-trainset; also, an ANFIS_test (with
input data clusters in the input cluster data space iCDS
2) is set up based on ODST-testset. In these works, the algorithm ANFIS-JS is adopted for establishing CDSs. From iCDS
1,
, (9) is estimated. One then (i) seeks the
m-th cluster satisfying
, (ii) removes this hard cluster along with all the data points hard distributed in it, and (iii) updates the ANFIS_train net based on the remaindered clusters in iCDS
1. The result obtained is the updated ANFIS_train net denoted uANFIS_train, filtered ODST-trainset denoted fODST-trainset, and
. Similarly, one gets uANFIS_test from ANFIS_test, fODST-testset from ODST-testset, and
. The input of fODST-testset is eventually used for uANFIS_train to calculate the error, Equation (11), where
is the
j-th output of uANFIS_train.
This loop process is carried out until . As a result, the ODST is the value of at the (h − 1)-th loop. This content can be depicted via the two procedures and Algorithm 1 below.
Procedure 1. (For probing and removing IN). At the h-th loop, calculate using Equation (9) for iCDS1 (C1 clusters) and iCDS2 (C2 clusters). For iCDS1: look for the cluster satisfying ; cancel this cluster and its data points, and restructure ANFIS_train; fODST-trainset, uANFIS_train, and
are the obtained results. For iCDS2: similarly, look for the cluster satisfying
cancel this cluster along with its data points, and restructure ANFIS_test; fODST-testset, uANFIS_test, and
are the ones coming from this phase.
Procedure 2. (for quantifying the ODST). The input of fODST-testset is used for the uANFIS_train to calculate (11). The loop is to be continued if . Otherwise, if : stop this process and fix . corresponding to this loop is called .
| Algorithm 1 The AfODST (Nguyen et al. [19]) |
| Input: (10) |
| Output: The ODST of the IDS (together with [E], [h], and ) |
Build ODST-trainset and ODST-testset. From ODST-trainset, ODST-testset and [E]: set up ANFIS_train (iCDS1, clusters) and ANFIS_test (iCDS2, clusters). Determine the ODST:
|
| While ODST = 0 and |
| ; at the h-th loop: |
| (a) Perform Procedure 1 |
| (b) Perform Procedure 2 |
| End While |
| (c) Save the ODST, [E], [h], and ; Stop. |
5. Conclusions
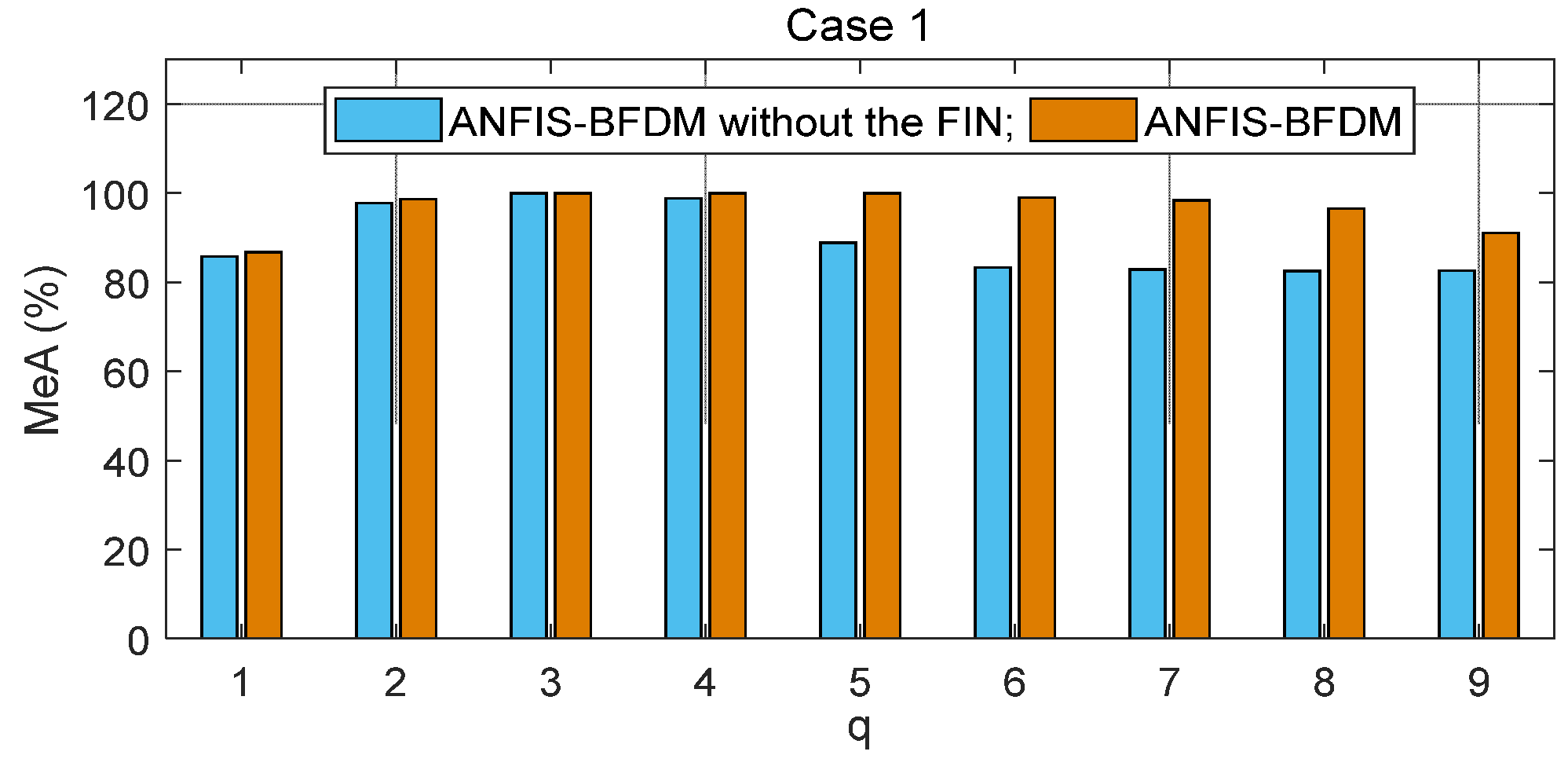
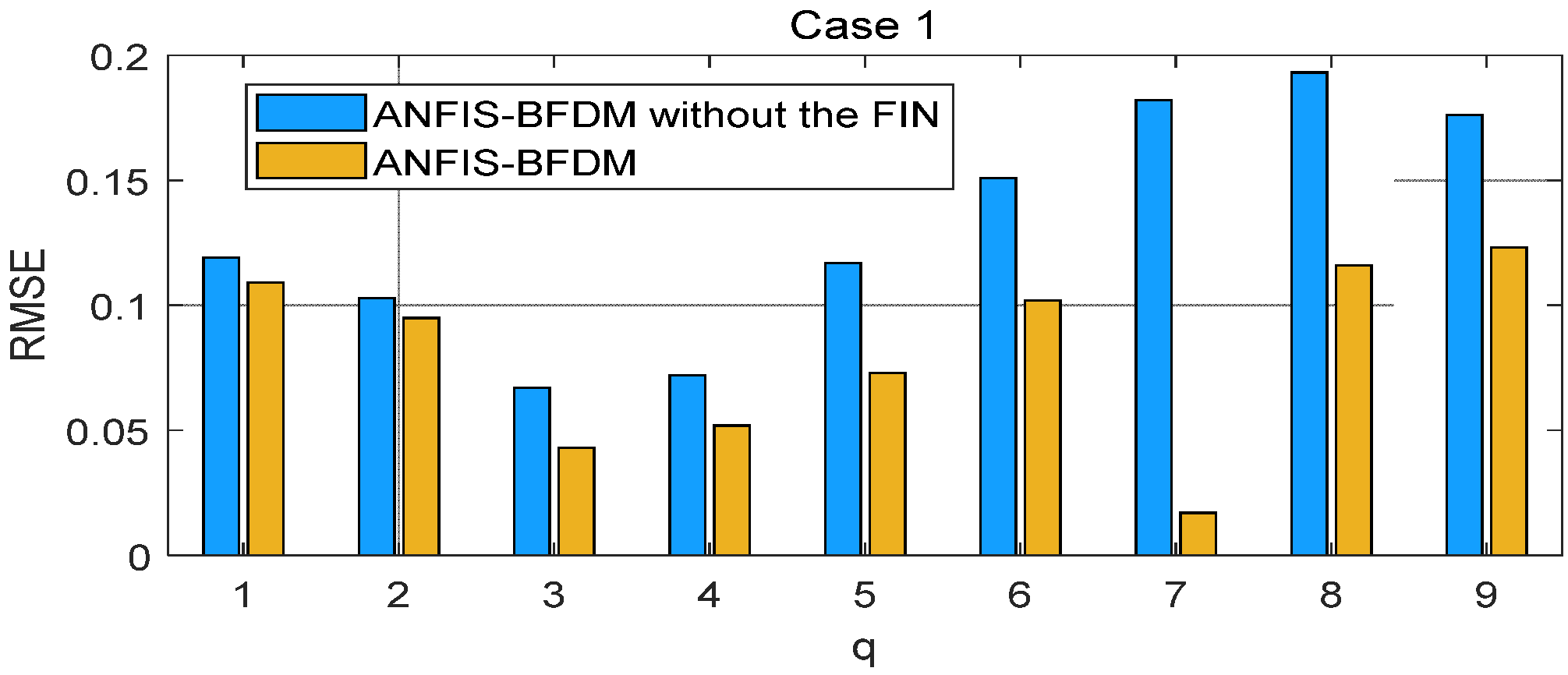
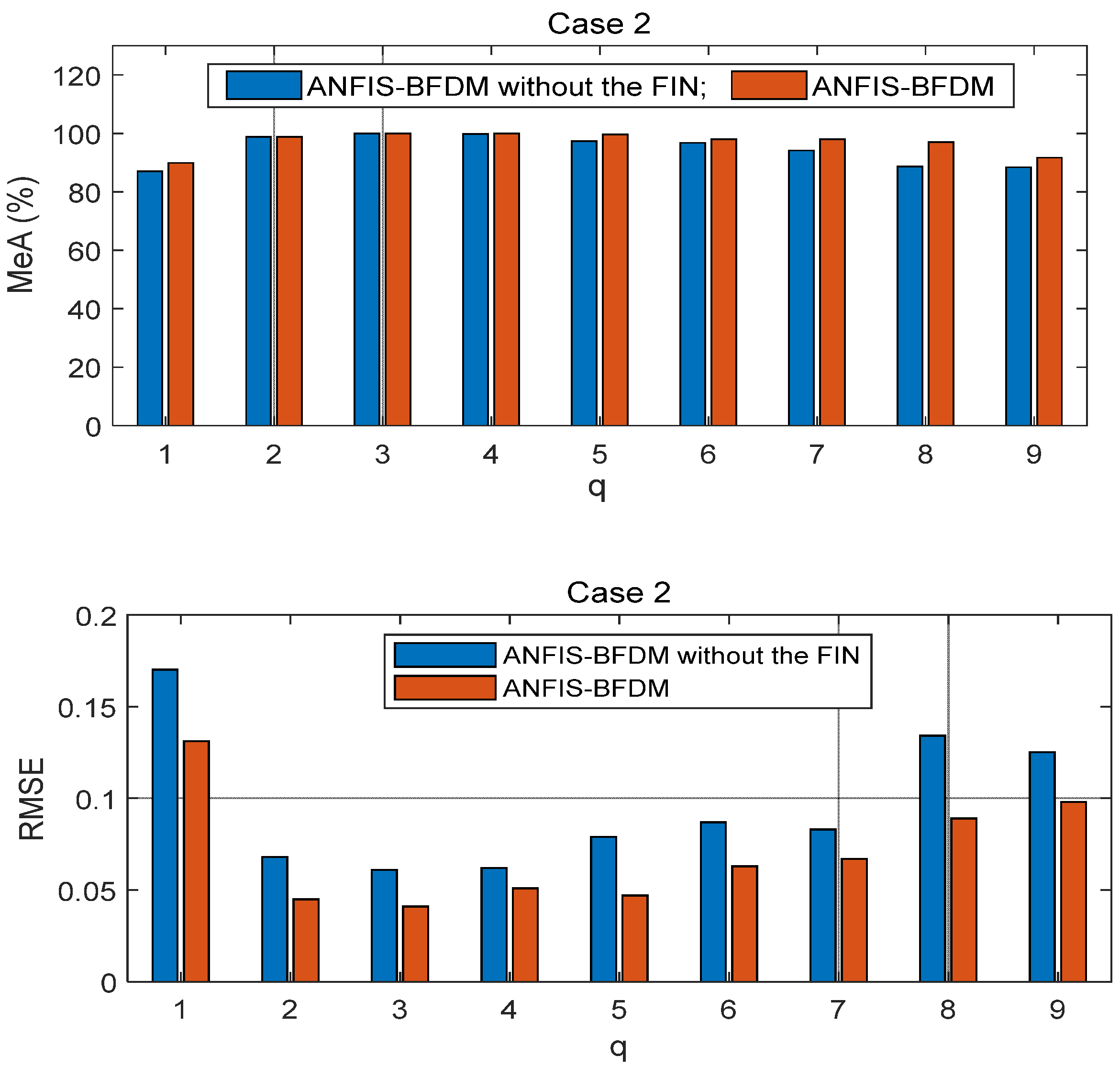
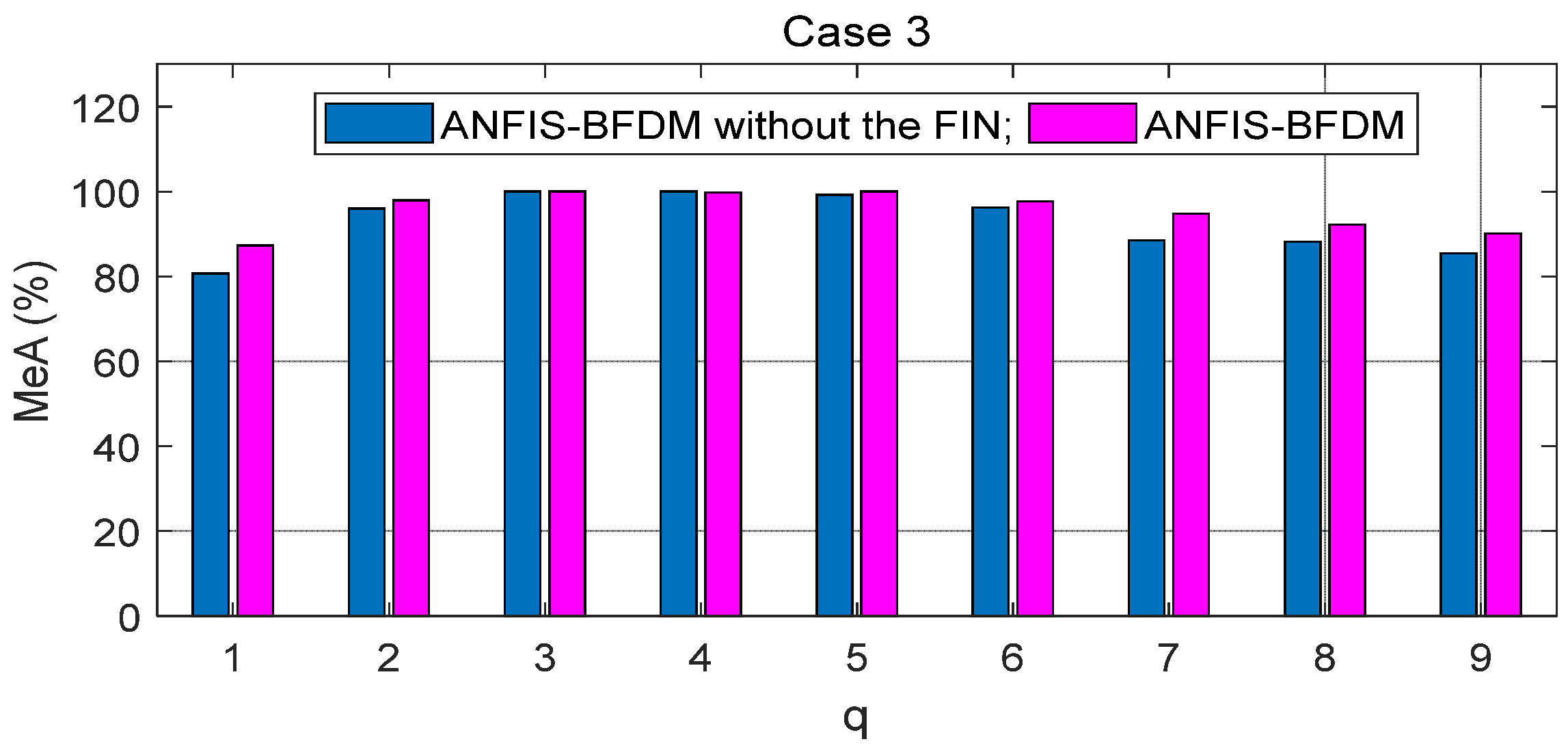
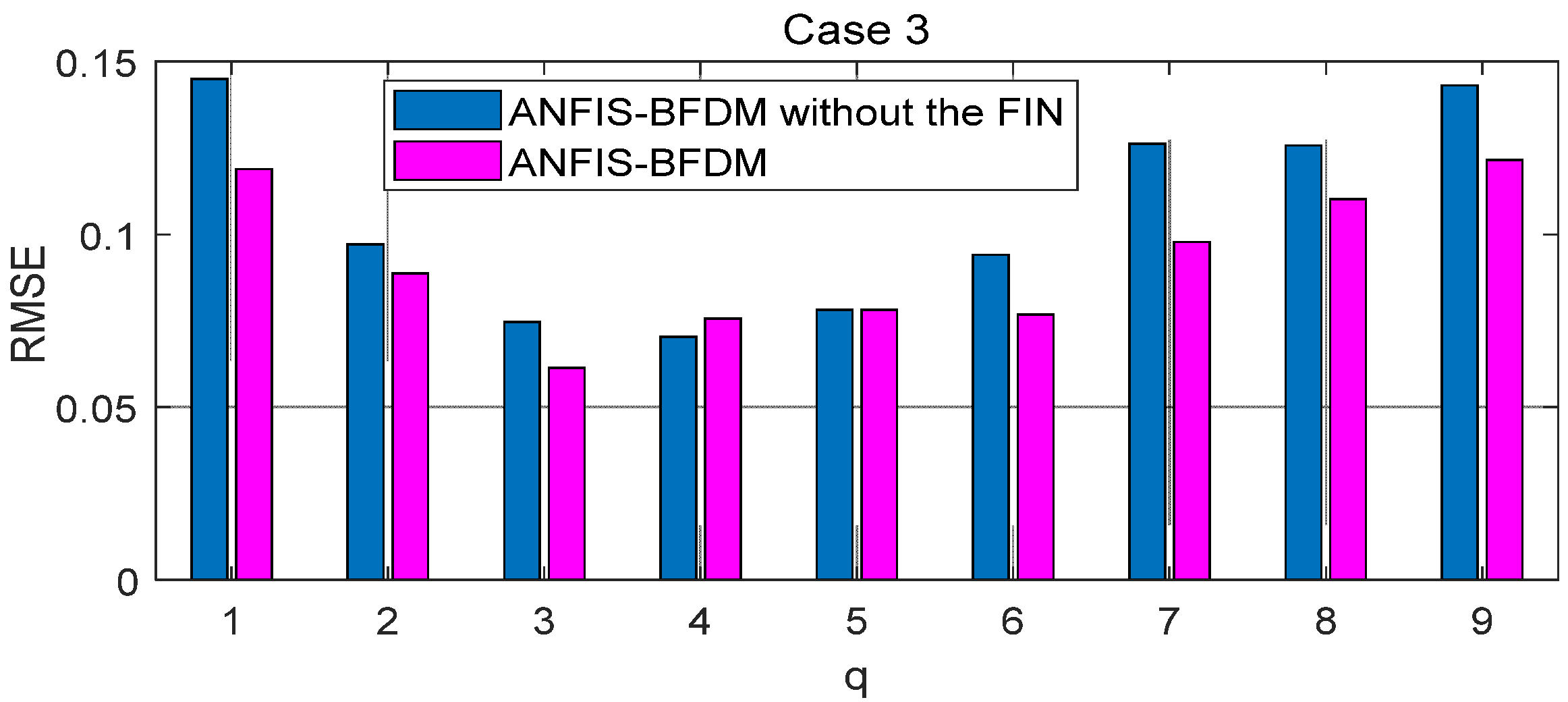
The proposed method of fault diagnosis of rolling element bearings named ANFIS-BFDM is presented. The online solution for preprocessing measured data and the way of exploiting the filtered data to label the target domain were our key proposals in this research. In the offline phase, frequency-based splitting of the stream of measured data into different time series was performed to cancel the high-frequency region. The optimal data screening threshold ODST was distilled in remaindered low-frequency data to set up the impulse noise filter FIN. An ANFIS was trained from the preprocessed data to identify the dynamic response of the managed bearing(s). In the online phase, the ODST and ANFIS were employed to filter noise and recognize online the object’s health status, respectively. Together with the survey results obtained, some aspects can be observed from the theoretical basis, as follows.
This combination of filtering high-frequency noise and IN allows for improving the processing efficiency and speed, suitable for online applications.
The proposed way of organizing data in IDS_1 and IDS_2 (12) of the FIN enriches information related to the labeled data samples covering both the source and target domains. It allows not only to weaken the negative influence of the domain drift between the source and target, but also to increase the difference of data correlation between with and without IN to improve the filtering effectiveness.
As presented in the proposed algorithm ANFIS-BFDM, the ANFIS that takes the role of the mapping (1) from the fusion domain to the target domain can make the negative impacting degree of domain drift between the source and target domains weaken.
In short, there are two key advantages of the proposed method: (i) the possibility for actual applications of the data preprocessing solution based on SSA and the filter FIN in online filtering of the measured data, and (ii) the compared effectiveness of the ANFIS-BFDM in reliably identifying a fault even if severe impulse noise appears in the databases. These aspects are verified in
Section 4.
Finally, despite the strong points, the considerable time delay related to the calculating cost of this method is also a challenge. The improvement of the delay is the motivation for the authors’ future research.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}