

Using Generative AI to Improve the Performance and Interpretability of Rule-Based Diagnosis of Type 2 Diabetes Mellitus

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset and Features
2.2. Research Tools
2.3. Study Design
| Algorithm 1: Pseudocode of the whole process. |
 |
- The proportion of an outcome class should always be between 0.3 and 0.7, ensuring that rule representation is not highly imbalanced.
- The number of rules containing the outcome must be at least 1/10 of the total generated rules.
- Message 1: You will be provided with a set of rules presented in a RuleList format, each containing an antecedent and a consequent. For example, a rule might be given as , signifying that if ‘A’ falls within the range of 19 and 67, it implies that ‘B’ must fall within the range of 59 and 98, and ‘C’ must fall within the range of 2.56 and 8.3. The rule list is as follows:
- Message 2: The rule list is provided as a list of rules.
- Message 3: For the test sample: determine the ‘Outcome’ value. Respond with an answer in the following format ‘Outcome = x’ where x can be either ‘0’ or ‘1’. Additionally, provide a set of rules that significantly contributed to the obtained result in highest frequencies. Provide them in the following format ‘Rules = [Rule1; Rule2; Rule3; Rule4]’. Rules should be written as an [antecedent] ⇒ [consequent] and should be separated by a semicolon.
2.4. Demonstration Example
- Gender: female.
- Age: 35.
- Insulin: 250 (mu U/mL).
- BMI: 21.5.
- BloodPressure: 100/70 mmHg.
- Glucose: 100 mg/dL.
- DiabetesPedigreeFunction: 0.2.
- Pregnancies: 2.
- Rule 1: [Insulin([0, 427]), BMI([8.148, 64.294]), BloodPressure([11, 114])] ⇒ [Outcome(0), Pregnancies([2, 12])]. The patient’s insulin level (250 pg/mL) falls within the range of the first rule, and the patient’s BMI (21.5) and blood pressure (100/70 mmHg) also fall within the ranges specified in the rule. Therefore, we can apply this rule to the patient. The rule predicts an outcome of 0 (non-diabetic) and a range of 2–12 pregnancies, which corresponds to the patient; even if the pregnancy level was absent or none, it still would. Predicted: 0.
- Rule 2: [Insulin([281, 386])] ⇒ [Outcome(0)]. The patient’s insulin level (250 pg/mL) does not fall within the range of the second rule. Therefore, we cannot apply this rule to the patient. Predicted: None.
- Rule 3: [Insulin([157, 209])] ⇒ [Outcome(1)]. The patient’s insulin level (250 pg/mL) falls outside the range of the third rule. Therefore, we cannot apply this rule to the patient. Predicted: None.
- Rule 4: [Insulin([0, 601])] ⇒ [BloodPressure([71, 76]), Pregnancies([0, 7]), Outcome(0), DiabetesPedigreeFunction ([1.568, 2.42])]. The patient’s insulin level (250 pg/mL) falls within the range of the fourth rule. Therefore, we can apply this rule to the patient. Predicted: 0.
- Rule 5: [Insulin([0, 427]), BMI([8.148, 64.294]), BloodPressure([11, 114])] ⇒ [Outcome(0), Pregnancies([2, 12])]. The patient’s insulin level, BMI, and blood pressure fall within specified ranges of the fifth rule. Therefore, we can apply the rule. Predicted: 0.
3. Results
3.1. Niaarm Rules
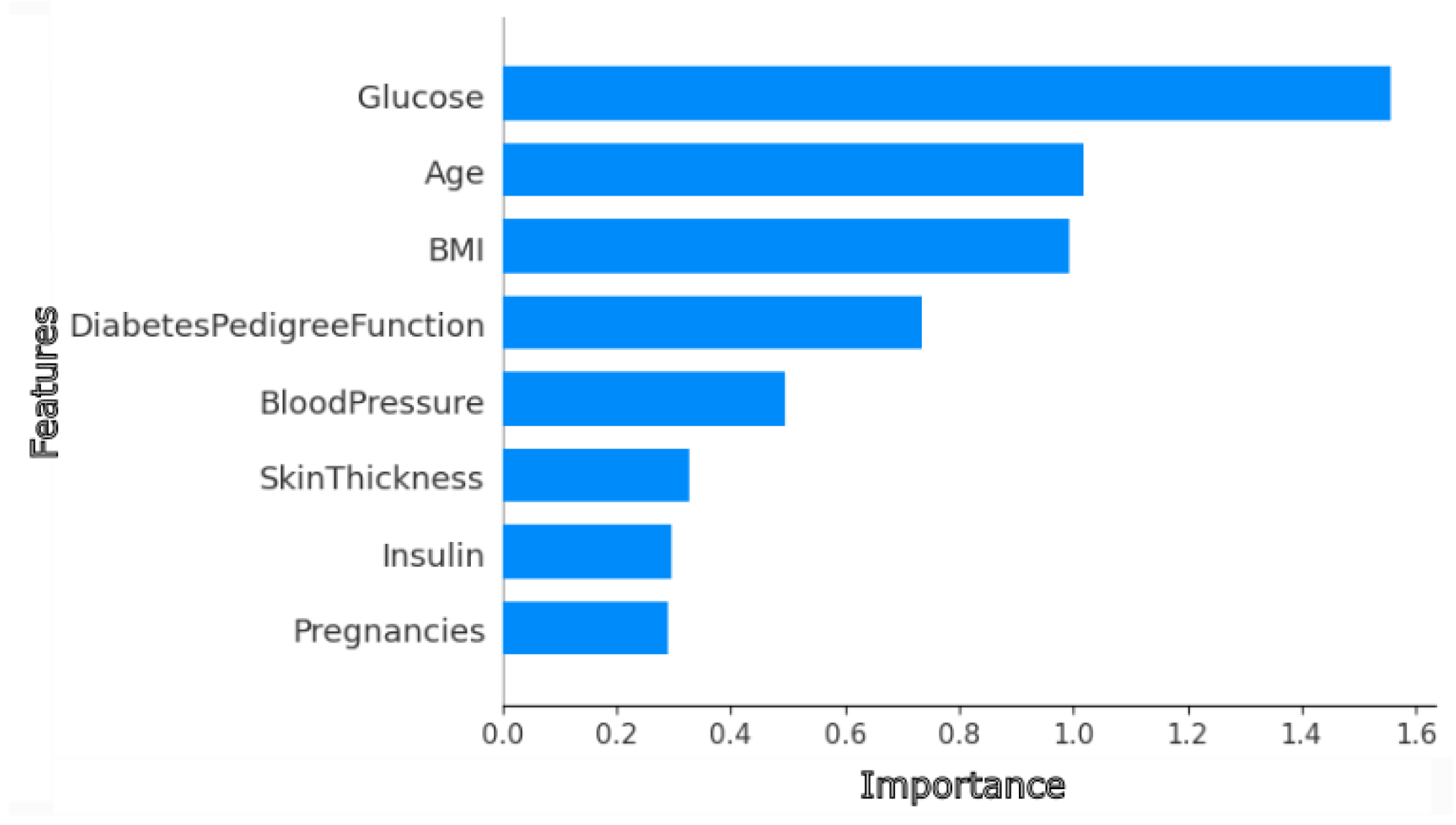
3.2. Model Performance
3.3. GPT Predictions and Reported Rules
- ‘[Insulin(0, 400), BMI(9.709, 65.806), Outcome(1)]⇒ [Pregnancies(0, 6)]’.
- ‘[Insulin(0, 558)] ⇒ [Outcome(1), DiabetesPedigreeFunction(1.255, 2.42), Pregnancies(2, 16)]’.
- ‘BloodPressure(23, 59), BMI(3.832, 58.949), Pregnancies(0, 2)] ⇒ [Outcome(1)]’.
- ‘[Insulin(157, 209)]⇒[Outcome(1)]’.
3.4. Computational Time Analysis
3.5. Comparing and Mapping GPT-Reported Rules with NiaARM-Generated Rules
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| API | application programming interface |
| AUC | area under the curve |
| BMI | body mass index |
| CART | classification and regression tree |
| EFB | exclusive feature bundling |
| GOSS | gradient-based one-side sampling |
| GPT | generative pretrained transformer |
| NLP | natural language processing |
| SD | standard deviation |
| SHAP | Shapley additive explanations |
| T2DM | Type 2 diabetes mellitus |
References
- Sun, H.; Saeedi, P.; Karuranga, S.; Pinkepank, M.; Ogurtsova, K.; Duncan, B.B.; Stein, C.; Basit, A.; Chan, J.C.; Mbanya, J.C.; et al. IDF Diabetes Atlas: Global, regional and country-level diabetes prevalence estimates for 2021 and projections for 2045. Diabetes Res. Clin. Pract. 2022, 183, 109119. [Google Scholar] [CrossRef]
- Oh, S.H.; Lee, S.J.; Park, J. Precision medicine for hypertension patients with type 2 diabetes via reinforcement learning. J. Pers. Med. 2022, 12, 87. [Google Scholar] [CrossRef]
- Malerbi, F.K.; Andrade, R.E.; Morales, P.H.; Stuchi, J.A.; Lencione, D.; de Paulo, J.V.; Carvalho, M.P.; Nunes, F.S.; Rocha, R.M.; Ferraz, D.A.; et al. Diabetic retinopathy screening using artificial intelligence and handheld smartphone-based retinal camera. J. Diabetes Sci. Technol. 2022, 16, 716–723. [Google Scholar] [CrossRef]
- Tao, R.; Yu, X.; Lu, J.; Wang, Y.; Lu, W.; Zhang, Z.; Li, H.; Zhou, J. A deep learning nomogram of continuous glucose monitoring data for the risk prediction of diabetic retinopathy in type 2 diabetes. Phys. Eng. Sci. Med. 2023, 46, 813–825. [Google Scholar] [CrossRef]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- Patil, B.; Joshi, R.; Toshniwal, D. Association rule for classification of type-2 diabetic patients. In Proceedings of the 2010 Second International Conference on Machine Learning and Computing, Bangalore, India, 9–11 February 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 330–334. [Google Scholar]
- Kopitar, L.; Kocbek, P.; Cilar, L.; Sheikh, A.; Stiglic, G. Early detection of type 2 diabetes mellitus using machine learning-based prediction models. Sci. Rep. 2020, 10, 11981. [Google Scholar] [CrossRef]
- Deberneh, H.M.; Kim, I. Prediction of type 2 diabetes based on machine learning algorithm. Int. J. Environ. Res. Public Health 2021, 18, 3317. [Google Scholar] [CrossRef]
- Smith, J.W.; Everhart, J.E.; Dickson, W.; Knowler, W.C.; Johannes, R.S. Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the Annual Symposium on Computer Application in Medical Care; American Medical Informatics Association: Washington, DC, USA, 1988; p. 261. [Google Scholar]
- Stupan, Ž.; Fister, I. NiaARM: A minimalistic framework for Numerical Association Rule Mining. J. Open Source Softw. 2022, 7, 4448. [Google Scholar] [CrossRef]
- Fister, I., Jr.; Podgorelec, V.; Fister, I. Improved nature-inspired algorithms for numeric association rule mining. In Intelligent Computing and Optimization, Proceedings of the 3rd International Conference on Intelligent Computing and Optimization 2020 (ICO 2020), Hua Hin, Thailand, 8–9 October 2020; Springer: Cham, Switzerland, 2021; pp. 187–195. [Google Scholar]
- Kaushik, M.; Sharma, R.; Peious, S.A.; Shahin, M.; Ben Yahia, S.; Draheim, D. On the potential of numerical association rule mining. In Proceedings of the International Conference on Future Data and Security Engineering, Quy Nhon, Vietnam, 25–27 November 2020; Springer: Singapore, 2020; pp. 3–20. [Google Scholar]
- Zaki, M.J. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, Santiago de Chile, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Kaushik, M.; Sharma, R.; Fister, I., Jr.; Draheim, D. Numerical association rule mining: A systematic literature review. arXiv 2023, arXiv:2307.00662. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 3146–3154. [Google Scholar]
- Baniecki, H.; Kretowicz, W.; Piatyszek, P.; Wisniewski, J.; Biecek, P. dalex: Responsible Machine Learning with Interactive Explainability and Fairness in Python. J. Mach. Learn. Res. 2021, 22, 1–7. [Google Scholar]
- Molnar, C. Interpretable Machine Learning; Lulu.com: Morrisville, NC, USA, 2020. [Google Scholar]
- OpenAI Platform—platform.openai.com. Available online: https://platform.openai.com/account/rate-limits (accessed on 28 September 2023).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Safari, S.; Baratloo, A.; Elfil, M.; Negida, A. Evidence based emergency medicine; part 5 receiver operating curve and area under the curve. Emergency 2016, 4, 111. [Google Scholar]
- Šter, B.; Dobnikar, A. Neural networks in medical diagnosis: Comparison with other methods. In Proceedings of the International Conference on Engineering Applications of Neural Networks, London, UK, 17–19 June 1996; pp. 427–430. [Google Scholar]
- Li, W.; Han, J.; Pei, J. CMAR: Accurate and efficient classification based on multiple class-association rules. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; IEEE: Piscataway, NJ, USA, 2001; pp. 369–376. [Google Scholar]
- Wang, J.; Karypis, G. HARMONY: Efficiently mining the best rules for classification. In Proceedings of the 2005 SIAM International Conference on Data Mining, Newport Beach, CA, USA, 21–23 April 2005; pp. 205–216. [Google Scholar]
- Ma, B.; Liu, B.; Hsu, Y. Integrating classification and association rule mining. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998; Volume 50, pp. 80–86. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Drew, B.J.; Harris, P.; Zègre-Hemsey, J.K.; Mammone, T.; Schindler, D.; Salas-Boni, R.; Bai, Y.; Tinoco, A.; Ding, Q.; Hu, X. Insights into the problem of alarm fatigue with physiologic monitor devices: A comprehensive observational study of consecutive intensive care unit patients. PLoS ONE 2014, 9, e110274. [Google Scholar] [CrossRef] [PubMed]
- Kaukonen, K.M.; Bailey, M.; Pilcher, D.; Cooper, D.J.; Bellomo, R. Systemic inflammatory response syndrome criteria in defining severe sepsis. N. Engl. J. Med. 2015, 372, 1629–1638. [Google Scholar] [CrossRef] [PubMed]
- Kopitar, L.; Cilar, L.; Kocbek, P.; Stiglic, G. Local vs. global interpretability of machine learning models in type 2 diabetes mellitus screening. In International Workshop on Knowledge Representation for Health Care; Springer: Cham, Switzerland, 2019; pp. 108–119. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Joshi, R.D.; Dhakal, C.K. Predicting type 2 diabetes using logistic regression and machine learning approaches. Int. J. Environ. Res. Public Health 2021, 18, 7346. [Google Scholar] [CrossRef] [PubMed]
- Seah, J.Y.H.; Yao, J.; Hong, Y.; Lim, C.G.Y.; Sabanayagam, C.; Nusinovici, S.; Gardner, D.S.L.; Loh, M.; Müller-Riemenschneider, F.; Tan, C.S.; et al. Risk prediction models for type 2 diabetes using either fasting plasma glucose or HbA1c in Chinese, Malay, and Indians: Results from three multi-ethnic Singapore cohorts. Diabetes Res. Clin. Pract. 2023, 203, 110878. [Google Scholar] [CrossRef]
- International Diabetes Federation. IDF Diabetes Atlas, 10th ed.; International Diabetes Federation: Brussels, Belgium, 2021. [Google Scholar]
- Bogardus, C.; Lillioja, S.; Howard, B.; Reaven, G.; Mott, D. Relationships between insulin secretion, insulin action, and fasting plasma glucose concentration in nondiabetic and noninsulin-dependent diabetic subjects. J. Clin. Investig. 1984, 74, 1238–1246. [Google Scholar] [CrossRef]
- Reaven, G.M. Compensatory hyperinsulinemia and the development of an atherogenic lipoprotein profile: The price paid to maintain glucose homeostasis in insulin-resistant individuals. Endocrinol. Metab. Clin. 2005, 34, 49–62. [Google Scholar] [CrossRef]
- Clark, A.; Jones, L.C.; de Koning, E.; Hansen, B.C.; Matthews, D.R. Decreased insulin secretion in type 2 diabetes: A problem of cellular mass or function? Diabetes 2001, 50, S169. [Google Scholar] [CrossRef] [PubMed]
- Santoleri, D.; Titchenell, P.M. Resolving the paradox of hepatic insulin resistance. Cell. Mol. Gastroenterol. Hepatol. 2019, 7, 447–456. [Google Scholar] [CrossRef]
- Tsujimoto, T.; Kajio, H.; Sugiyama, T. Association between hyperinsulinemia and increased risk of cancer death in nonobese and obese people: A population-based observational study. Int. J. Cancer 2017, 141, 102–111. [Google Scholar] [CrossRef]
- Jia, G.; Sowers, J.R. Hypertension in diabetes: An update of basic mechanisms and clinical disease. Hypertension 2021, 78, 1197–1205. [Google Scholar] [CrossRef]
- Przezak, A.; Bielka, W.; Pawlik, A. Hypertension and Type 2 Diabetes—The Novel Treatment Possibilities. Int. J. Mol. Sci. 2022, 23, 6500. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.J.; Kim, K.i. Blood pressure target in type 2 diabetes mellitus. Diabetes Metab. J. 2022, 46, 667–674. [Google Scholar] [CrossRef]
- Kim, M.J.; Lim, N.K.; Choi, S.J.; Park, H.Y. Hypertension is an independent risk factor for type 2 diabetes: The Korean genome and epidemiology study. Hypertens. Res. 2015, 38, 783–789. [Google Scholar] [CrossRef]
- Lee, W.Y.; Kwon, C.H.; Rhee, E.J.; Park, J.B.; Kim, Y.K.; Woo, S.Y.; Kim, S.; Sung, K.C. The effect of body mass index and fasting glucose on the relationship between blood pressure and incident diabetes mellitus: A 5-year follow-up study. Hypertens. Res. 2011, 34, 1093–1097. [Google Scholar] [CrossRef] [PubMed]
- Tian, X.; Zuo, Y.; Chen, S.; Zhang, Y.; Zhang, X.; Xu, Q.; Wu, S.; Wang, A. Hypertension, arterial stiffness, and diabetes: A prospective cohort study. Hypertension 2022, 79, 1487–1496. [Google Scholar] [CrossRef] [PubMed]
- Boutouyrie, P.; Chowienczyk, P.; Humphrey, J.D.; Mitchell, G.F. Arterial Stiffness and Cardiovascular Risk in Hypertension. Circ. Res. 2021, 128, 864–886. [Google Scholar] [CrossRef] [PubMed]
- Laurent, S.; Boutouyrie, P. Arterial Stiffness and Hypertension in the Elderly. Front. Cardiovasc. Med. 2020, 7, 544302. [Google Scholar] [CrossRef]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning-based prediction models in healthcare. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1379. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Meaning |
|---|---|
| Pregnancies | Number of times pregnant |
| Glucose | Plasma glucose concentration (2 h in an oral glucose tolerance test) |
| BloodPressure | Diastolic blood pressure (mmHg) |
| SkinThickness | Triceps skin fold thickness (mm) |
| Insulin | 2 h serum insulin (mu U/mL) |
| BMI | Body mass index (weight in kg/(height in m)2) |
| DiabetesPedigreeFunction | Diabetes pedigree function |
| Age | Age (years) |
| Outcome | Diabetes |
| Features | Non-Diabetic—0 1 | Diabetic—1 1 | p-Value 2 |
|---|---|---|---|
| Pregnancies | 3.3 (±3.0) | 4.9 (±3.7) | <0.0001 |
| Glucose | 110.0 (±26.1) | 141.3 (±31.9) | <0.0001 |
| BloodPressure | 68.2 (±18.1) | 70.8 (±21.5) | <0.0001 |
| SkinThickness | 19.7 (±14.9) | 22.2 (±17.7) | 0.013 |
| Insulin | 68.8 (±98.9) | 100.3 (±138.7) | 0.066 |
| BMI | 30.3 (±7.7) | 35.1 (±7.3) | <0.0001 |
| DiabetesPedigreeFunction | 0.4 (±0.3) | 0.6 (±0.4) | <0.0001 |
| Age | 31.2 (±11.7) | 37.1 (±11.0) | <0.0001 |
| Predicted | NiaARM Rules | GPT-Recognized Rules | Similarity | Frequency |
|---|---|---|---|---|
| 0 | [Insulin([0, 427]), BMI([8.148, 64.294]), BloodPressure([11, 114])] => [Outcome(0), Pregnancies([2, 12])] | [Insulin(0, 427), BMI(8.148, 64.294), BloodPressure(11, 114)] => [Outcome(0), Pregnancies(2, 12)] | 0.965 | 0.012 |
| 0 | [Insulin([281, 386])] => [Outcome(0)] | Insulin(0, 744)] => [Outcome(0)] | 0.813 | 0.012 |
| 1 | [Insulin([157, 209])] => [Outcome(1)] | [Insulin(0, 846)] => [Outcome(1)] | 0.813 | 0.058 |
| 1 | [Insulin([0, 601])] => [BloodPressure([71, 76]), Pregnancies([0, 7]), Outcome(0), DiabetesPedigreeFunction ([1.568, 2.42])] | [Insulin(0, 601)] => [BloodPressure(71, 76), Pregnancies(0, 7), Outcome(0), DiabetesPedigreeFunction (1.568, 2.42)] | 0.967 | 0.023 |
| 1 | [Insulin([0, 427]), BMI([8.148, 64.294]), BloodPressure([11, 114])] => [Outcome(0), Pregnancies([2, 12])] | [Insulin(0, 427), BMI(8.148, 64.294), BloodPressure(11, 114)] => [Outcome(0), Pregnancies(2, 12)] | 0.965 | 0.016 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopitar, L.; Fister, I., Jr.; Stiglic, G. Using Generative AI to Improve the Performance and Interpretability of Rule-Based Diagnosis of Type 2 Diabetes Mellitus. Information 2024, 15, 162. https://doi.org/10.3390/info15030162
Kopitar L, Fister I Jr., Stiglic G. Using Generative AI to Improve the Performance and Interpretability of Rule-Based Diagnosis of Type 2 Diabetes Mellitus. Information. 2024; 15(3):162. https://doi.org/10.3390/info15030162
Chicago/Turabian StyleKopitar, Leon, Iztok Fister, Jr., and Gregor Stiglic. 2024. "Using Generative AI to Improve the Performance and Interpretability of Rule-Based Diagnosis of Type 2 Diabetes Mellitus" Information 15, no. 3: 162. https://doi.org/10.3390/info15030162