

Improving Semantic Information Retrieval Using Multinomial Naive Bayes Classifier and Bayesian Networks


Abstract
:1. Introduction
2. Related Work
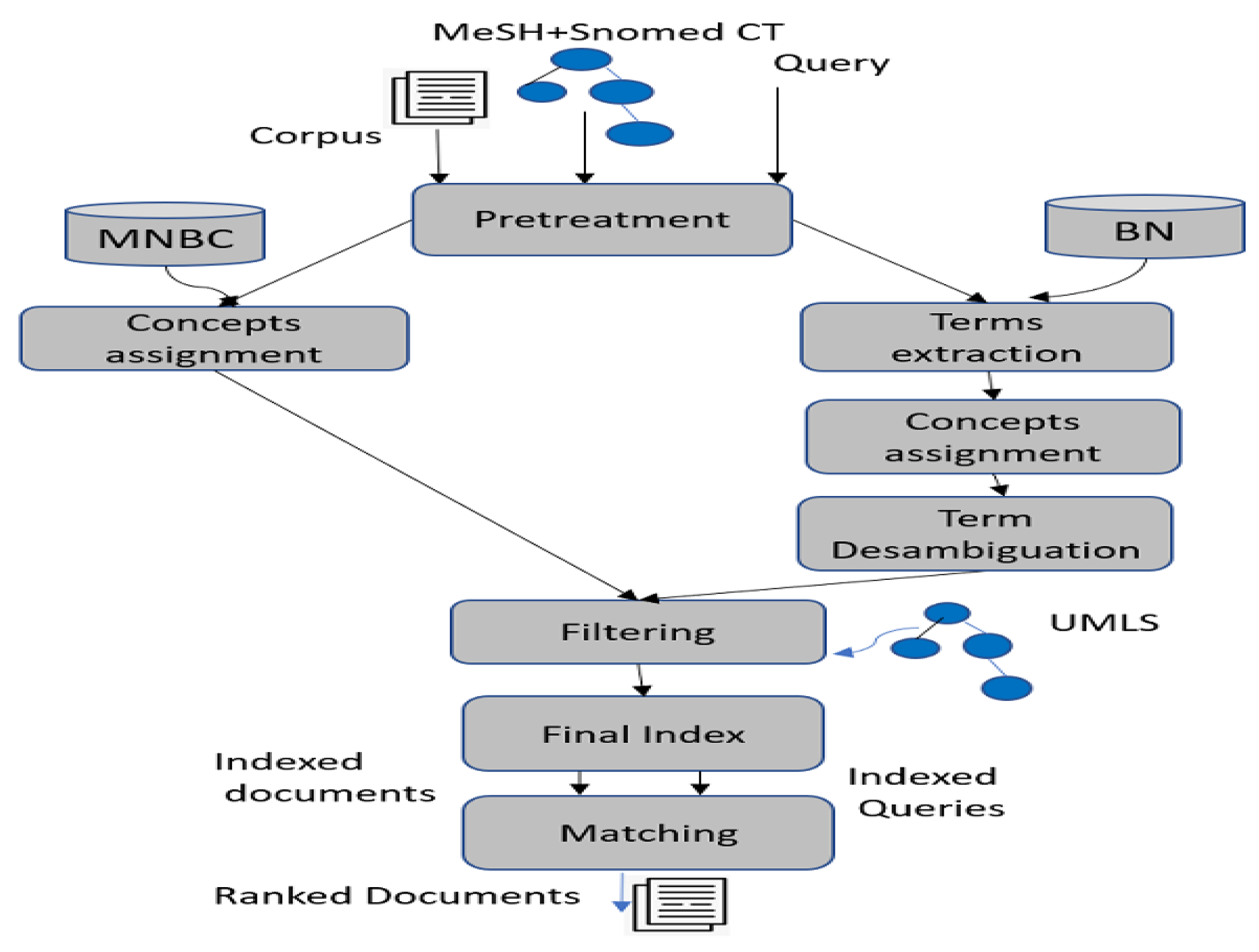
3. Materials and Method
- (1)
- (2)
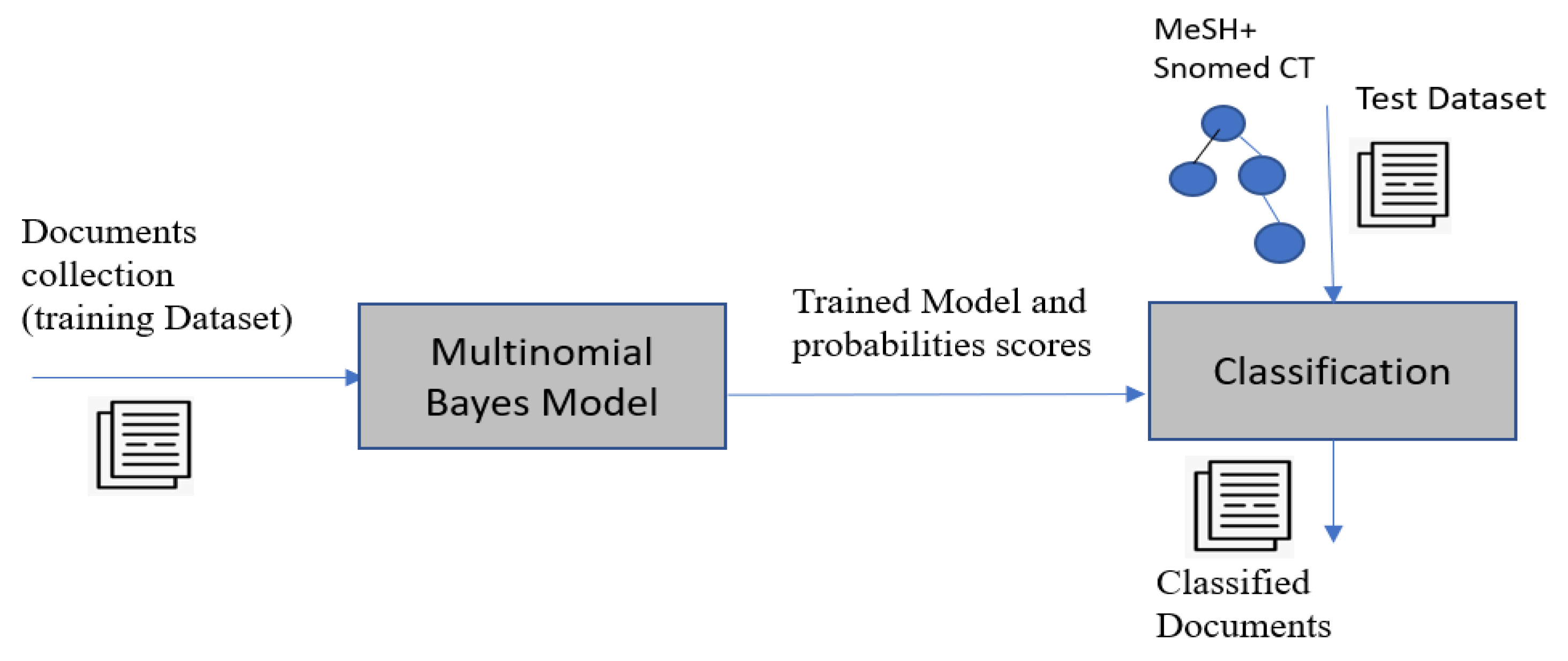
- Concept extraction using a multinomial naive Bayes classifier (MNBC)
- (3)
- Term and concept extraction and disambiguation using a Bayesian network
- (4)
- Filtering concepts
- (5)
- Final indexes
- (6)
- Matching queries and documents
3.1. Concept Extraction Using a Multinomial Naïve Bayes Classifier
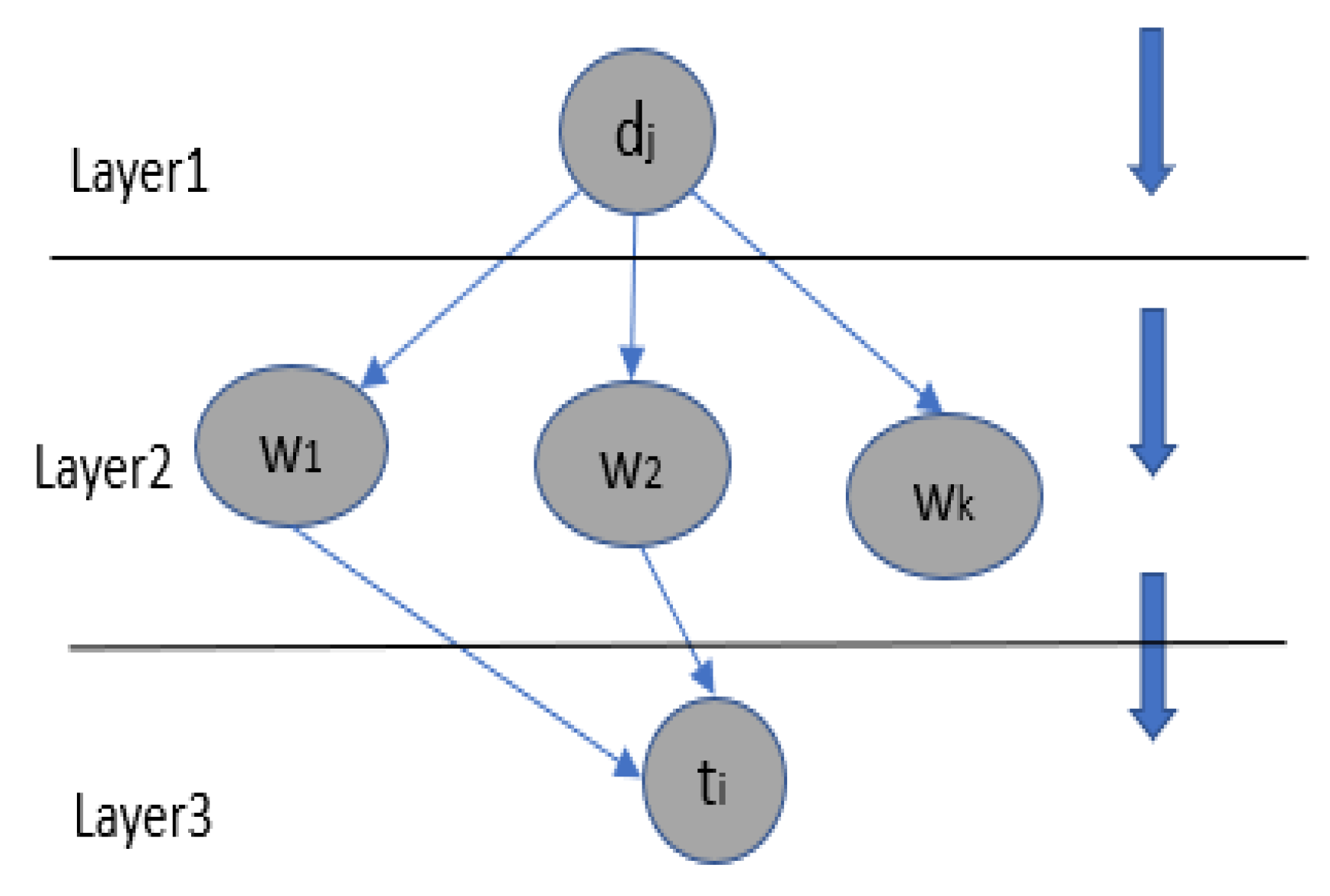
3.2. Concept Extraction Using BN
3.2.1. Evaluation of a Term
3.2.2. Computing the Weight of the Arc
3.2.3. Aggregation of Words of Terms
3.2.4. Concept Assignment and Terms Disambiguation
3.3. Filtering Based on UMLS
3.4. Computing a Similarity between Queries and Documents
4. Results
- (1)
- OHSUMED (https://trec.nist.gov/ (Hersh et al., 1994) accessed on 23 April 2023), is a document collection that was used for the TREC-9 filtering track. This corpus is the same as that used in [12]. Details on this corpus are presented in [12].
- (2)
- The Clinical Trial corpus 2021, which is composed of topics (descriptions of the user needs), clinical documents, and relevance judgments evaluated by experts. The topics correspond to the queries. This is the link to the corpus: http://www.trec-cds.org accessed on 12 May 2022.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chebil, W.; Soualmia, L.F.; Omri, M.N.; Darmoni, S.J. Indexing biomedical documents with a possibilistic network. J. Assoc. Inf. Sci. Technol. 2016, 67, 928–941. [Google Scholar] [CrossRef]
- Chebil, W.; Soualmia, L.F.; Dahamna, B.; Darmoni, S.J. Indexation automatique de documents en santé: Évaluation et analyse de sources d’erreurs. IRBM 2012, 33, 316–329. [Google Scholar] [CrossRef]
- Alazab, M. Automated malware detection in mobile app stores based on robust feature generation. Electronics 2020, 9, 435. [Google Scholar] [CrossRef]
- De Stefano, C.; Fontanella, F.; Marrocco, C.; di Freca, A.S.A. Hybrid Evolutionary Algorithm for Bayesian Networks Learning: An Application to Classifier Combination. In Applications of Evolutionary Computation. EvoApplications 2010; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6024. [Google Scholar]
- Shen, Y.; Zhang, L.; Zhang, J.; Yang, M.; Tang, B.; Li, Y.; Lei, K. CBN: Constructing a Clinical Bayesian Network based on Data from the Electronic Medical Record. J. Biomed. Inform. 2018, 88, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Malviya, S.; Tiwary, U.S. Knowledge-Based Summarization and Document Generation using Bayesian Network. Procedia Comput. Sci. 2018, 89, 333–340. [Google Scholar] [CrossRef]
- de Campos, C.P.; Zeng, Z.; Ji, Q. Structure Learning of Bayesian Networks Using Constraints. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; Association for Computing Machinery: New York, NY, USA. [Google Scholar]
- Salton, G.; Wong, A.; Yang, C. A vector space model for automatic indexing. Commun. ACM 1975, 18, 438–446, 613–620. [Google Scholar] [CrossRef]
- Robertson, S.; Jones, K.S. Relevance weighting of search terms. J. Am. Soc. Inf. Sci. 1976, 27, 129–146. [Google Scholar] [CrossRef]
- Salton, G.; Fox, E.A.; Wu, H. Extended boolean information retrieval. Commun. ACM 1983, 26, 1022–1036. [Google Scholar] [CrossRef]
- Wang, Y.; Choi, I.; Liu, H. Generalized ensemble model for document ranking in information retrieval. arXiv 2015, arXiv:1507.08586. [Google Scholar] [CrossRef]
- Chebil, W.; Soualmia, L.F.; Omri, M.; Darmoni, S.J. Possibilistic Information Retrieval Model Based on a Multi-Terminology. In Proceedings of the ADMA Advanced Data Mining and Applications, Nanjing, China, 18 November 2018. [Google Scholar]
- Ensan, F.; Bagheri, E. Retrieval model through semantic linking. In Proceedings of the 10th ACM International Conference on Websearch and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 181–190. [Google Scholar]
- Sneiders, E. Text retrieval by term cooccurrences in a query based vector space. In Proceedings of the COLING 2016 the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; Technical Papers. pp. 2356–2365. [Google Scholar]
- Kenter, T.; Borisov, A.; Van Gysel, C.; Dehghani, M.; de Rijke, M.; Mitra, B. Neural networks for information retrieval. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1403–1406. [Google Scholar]
- Jaina, S.; Seejab, K.; Jindal, R. A fuzzy ontology framework in information retrieval using semantic query expansion. J. Inf. Manag. Data Insights 2021, 1, 300–307. [Google Scholar] [CrossRef]
- Chebil, W.; Wedyan, M.O.; Lu, H.; Elshaweesh, O.G. Context-Aware Personalized Web Search Using Navigation History. Int. J. Semant. Web Inf. Syst. 2020, 16, 91–107. [Google Scholar] [CrossRef]
- Mohan, S.; Fiorini, N.; Kim, S.; Lu, Z. A fast deep learning model for textual relevance in biomedical information retrieval. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 77–86. [Google Scholar]
- Silva, S.; Seara, V.A.; Celard, P.; Iglesias, E.L.; Borrajo, L. A query expansion method using multinomial naive bayes. Appl. Sci. 2021, 11, 10284. [Google Scholar] [CrossRef]
- Xu, M.; Du, J.; Xue, Z.; Kou, F.; Xu, X. A semi-supervised semantic-enhanced framework for scientific literature retrieval. Neurocomputing 2021, 461, 450–461. [Google Scholar] [CrossRef]
- Prasath, R.; Sarkar, S.; OReilly, P. Improving cross language information retrieval using corpus based query suggestion approach. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; pp. 448–457. [Google Scholar]
- Chebil, W.; Soualmia, L.F.; Omri, M.; Darmoni, S.J. Indexing biomedical documents with Bayesian networks and terminologies. In Proceedings of the 12th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Nanjing, China, 24–26 November 2017. [Google Scholar]
- Bodenreider, O. The unified medical language system umls integrating biomedical terminology. Nucleic Acids Res. 2004, 32, 267–270. [Google Scholar] [CrossRef] [PubMed]
- Wedyan, M.; Alhadidi, B.; Alrabea, A. The effect of using a thesaurus in Arabic information retrieval system. Int. J. Comput. Sci. 2012, 9, 431–435. [Google Scholar]
- Zhang, C.; Bis, D.; Liu, X. Biomedical word sense disambiguation with bidirectional long short-term memory and attention-based neural networks. BMC Bioinform. 2019, 28, 159–182. [Google Scholar] [CrossRef] [PubMed]
- Pesaranghader, A.; Matwin, S.; Sokolova, M.; Pesaranghader, A. Deepbiowsd effective deep neural word sense disambiguation of biomedical text data. J. Am. Med. Inform. Assoc. 2020, 26, 438–446. [Google Scholar] [CrossRef] [PubMed]
- Sabbir, A.; Jimeno-Yepes, A.; Kavuluru, R. Knowledge-Based Biomedical Word Sense Disambiguation with Neural Concept Embeddings. In Proceedings of the 2017 IEEE 17th International Conference on Bioinformatics and Bioengineering (BIBE), Washington, DC, USA, 23–25 October 2017. [Google Scholar] [CrossRef]
- Yepes, A.; Berlanga, R. Knowledge based word concept model estimation and refinement for biomedical text mining. J. Biomed. Inform. 2015, 53, 300–307. [Google Scholar] [CrossRef] [PubMed]
- Lesk, M. Automatic sense disambiguation using machine readable dictionaries how to tell a pine cone from an ice cream cone. In SIGDOC ’86: Proceedings of the 5th Annual International Conference on Systems Documentation; Association for Computing Machinery: Washington, DC, USA, 1986; pp. 24–26. [Google Scholar]
- Voorhees, E.M. Using Wordnet to Disambiguate Word Senses for Text Retrieval. In SIGIR ’93: Proceedings of the ACM SIGIR, Conference on Research and Development in Information Retrieval; Association for Computing Machinery: Washington, DC, USA, 1993; pp. 171–180. [Google Scholar]
- Tulkens, S.; Suster, S.; Daelemans, W. Using distributed representations to disambiguate biomedical and clinical concepts. In Proceedings of the 15th Workshop on Biomedical Natural Language Processing, Berlin, Germany, 12 August 2016; Volume 53, pp. 77–82. [Google Scholar]
- Chebil, W.; Soualmia, L.F. Improving semantic information retrieval by combining possibilistic networks, vector space model and pseudo-relevance feedback. J. Inf. Sci. 2023. [Google Scholar] [CrossRef]
- Raschka, S. Naive Bayes and Text Classification I-Introduction and Theory. arXiv 2014. arXiv:1410-5329. [Google Scholar]
- Turtle, H.; Croft, W.B. Inference Networks for Document Retrieval. In Proceedings of the ACM SIGIR Conference on Research and Development in Information Retrieval, Association for Computing Machinery, Brussels Belgium, 5–7 September 1990; pp. 1–24. [Google Scholar]
- Xu, B.; Lin, H.; Yang, L.; Xu, K.; Zhang, Y.; Zhang, D.; Yang, Z.; Wang, J.; Lin, Y.; Yin, F. A supervised term ranking model for diversity enhanced biomedical information retrieval. BMC Bioinform. 2019, 20, 590. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | MAP | P@5 | P@10 | P@20 | P@50 |
|---|---|---|---|---|---|
| IMSIR-SVM | |||||
| IMSIR-RFC | |||||
| IMSIR-MNBC |
| Approach | MAP | P@5 | P@10 | P@20 | P@50 |
|---|---|---|---|---|---|
| CIRM [12] | 0.63 (+43.18%) | 0.72 (+33.33%) | 0.63 (+28.57%) | 0.61 (+28.57%) | +0.57 (32.55%) |
| Baseline [35] | 0.44 | 0.54 | 0.49 | 0.45 | 0.43 |
| Mingying et al. [20] | 0.65 (+47.72%) | 0.70 (+29.62%) | 0.6 (+22.44%)1 | 0.59 (+31.11%) | 0.53 (+23.25%) |
| IMSIR-VSM | 0.59 (+34.09%) | 0.71 (+31.48%) | 0.63 (+28.57%) | 0.58 (+28.57%) | 0.52 (+20.93%) |
| IMSIR-BM25 | 0.62 (+40.90%) | 0.71 (+31.48%) | 0.62 (+26.53%) | 0.54 (+28.57%) | 0.51 (+18.60%) |
| IMSIR-BN | 0.67 (+52.27%) * | 0.75 (+38.88%) * | 0.62 (+26.53%) * | 0.60 (+33.33%) | 0.56 (+30.23%) * |
| Approach | MAP | P@5 | P@10 | P@20 | P@50 |
|---|---|---|---|---|---|
| CIRM [12] | 0.61 (+35.55%) | 0.74 (+32.14%) | 0.65 (+25%) | 0.62 (+%) | 0.60 (+33.33%) |
| Baseline [35] | 0.45 | 0.56 | 0.50 | 0.47 | 0.45 |
| Mingying et al. [20] | 0.65 (44.44%) | 0.76 (35.71%) | 0.61 (22.00%) | 0.60 (26.65%) | 0.56 (24.44%) |
| IMSIR-VSM | 0.62 (+37.77%) | 0.74 (+32.14%) | 0.64 (+23.07%) | 0.60 (+21.66%) | 0.55 (+22.22%) |
| IMSIR-BM25 | 0.65 (+44.44%) | 0.73 (+30.35%) | 0.63 (+21.15%) | 0.59 (+20.33%) | 0.54 (+20%) |
| IMSIR-BN | 0.69 (+53.33%) * | 0.78 (+39.28%) * | 0.65 (+25%) * | 0.63 (+36.50%) | 0.59 (+31.11%) * |
| Approach | MAP | P@5 | P@10 | P@50 |
|---|---|---|---|---|
| IMSIR-BN * | ||||
| IMSIR-BN |
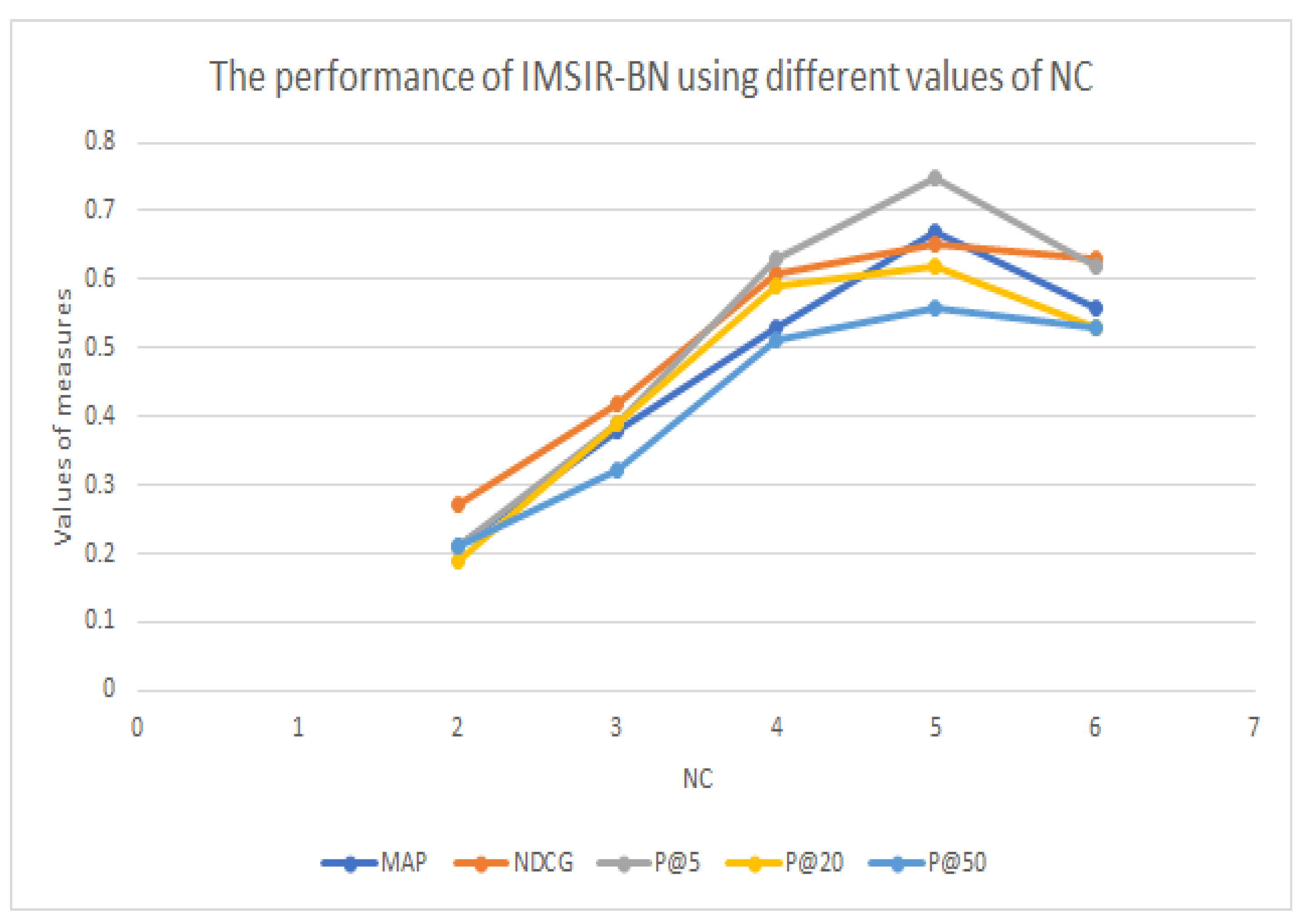
| Rank | NC = 2 | NC = 3 | NC = 4 | NC = 5 | NC = 6 |
|---|---|---|---|---|---|
| MAP | 0.21 | 0.38 | 0.53 | 0.67 | 0.56 |
| NDCG | 0.27 | 0.42 | 0.61 | 0.65 | 0.63 |
| P@5 | 0.21 | 0.39 | 0.63 | 0.75 | 0.62 |
| P@20 | 0.19 | 0.39 | 0.59 | 0.62 | 0.53 |
| P@50 | 0.21 | 0.32 | 0.51 | 0.56 | 0.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chebil, W.; Wedyan, M.; Alazab, M.; Alturki, R.; Elshaweesh, O. Improving Semantic Information Retrieval Using Multinomial Naive Bayes Classifier and Bayesian Networks. Information 2023, 14, 272. https://doi.org/10.3390/info14050272
Chebil W, Wedyan M, Alazab M, Alturki R, Elshaweesh O. Improving Semantic Information Retrieval Using Multinomial Naive Bayes Classifier and Bayesian Networks. Information. 2023; 14(5):272. https://doi.org/10.3390/info14050272
Chicago/Turabian StyleChebil, Wiem, Mohammad Wedyan, Moutaz Alazab, Ryan Alturki, and Omar Elshaweesh. 2023. "Improving Semantic Information Retrieval Using Multinomial Naive Bayes Classifier and Bayesian Networks" Information 14, no. 5: 272. https://doi.org/10.3390/info14050272