1. Introduction
The amount of legal information, available online in digital format, is vast and constantly growing. The excessive quantity of legal documents, manifested in various forms as statutes, regulations, judicial decisions, legal opinions, scholarly articles, and other legal and para-legal documents, can be overwhelming for legal professionals, making it difficult and time-consuming to find relevant information and keep up with the latest legal developments.
With the continuous expansion of legal information available online, attention towards techniques that have the potential to save time and reduce the cognitive load of legal professionals will progressively increase. Consider, for example, a lawyer preparing his/her arguments for a given case. He/she has to iteratively browse an enormous number of judgments selecting, through knowledge and experience, relevant passages, in order to acquire the needed in-depth context understanding. Browsing through condensed versions of the judgments is intuitively easier and less time-consuming, allowing them to focus on the main ideas and, thus, acquire a better understanding. Acknowledging the aforementioned problem, some Courts and commercial/proprietary legal information retrieval systems (e.g., LexisNexis, Westlaw, Bloomberg Law) offer summaries of judicial decisions, “hand crafted” by a specialized team of experts. Provisioning of tools to fully or partial automate the process can save time, reduce costs, and allow highly experienced legal professionals to focus on higher-level tasks utilizing their unique skills and expertise.
There has been extensive work on automatic text summarization [
1], where the key idea is to produce a shorter (summary) version of a document that represents the most-important or -relevant information within the original content. Extractive and abstractive text summarization are two common techniques used to generate summaries of documents. The former involves selecting and extracting the most-important sentences or phrases from the original text and using them to create a summary. On the contrary, the latter involves creating a summary that uses new wording and phrasing to convey the main ideas of the original text.
Automatic text summarization methods can be highly beneficial for legal information processing [
2]. However, applying text summarization techniques to legal documents poses several challenges due to the complexity of legal documents and the unique characteristics of the legal language they convey. Legal documents are not only precise in their language and meaning, to avoid ambiguity and misinterpretation, but also are written in a formal style, using specialized vocabulary specific to the legal field [
3]. Furthermore, legal documents often contain extensive amounts of text, follow a specific structure (e.g., headings, sections), and refer to other authoritative legal documents [
4]. Additionally, legal documents typically carry a certain authority and create a legally binding obligation, often within specific time frames. As errors can have significant consequences, it is apparent that distinct features of legal documents should be properly incorporated into text summarization techniques to provide accurate and effective summaries of legal documents.
While the most-reliable way to evaluate the effectiveness of an automatic summarization method is to have humans read the original text and the summary and judge its quality, manual assessment is expensive, subjective, and not applicable to large collections [
5]. Typically, text summarization techniques are evaluated by automatically applying a set of predefined metrics (e.g., ROUGE [
6] and its variants [
7], BLEU [
8], BertScore [
9]). This one-size-fits-all strategy poses additional challenges when it comes to evaluating the effectiveness of automatic summarization methods for legal documents: Which metric is most appropriate for a given task?
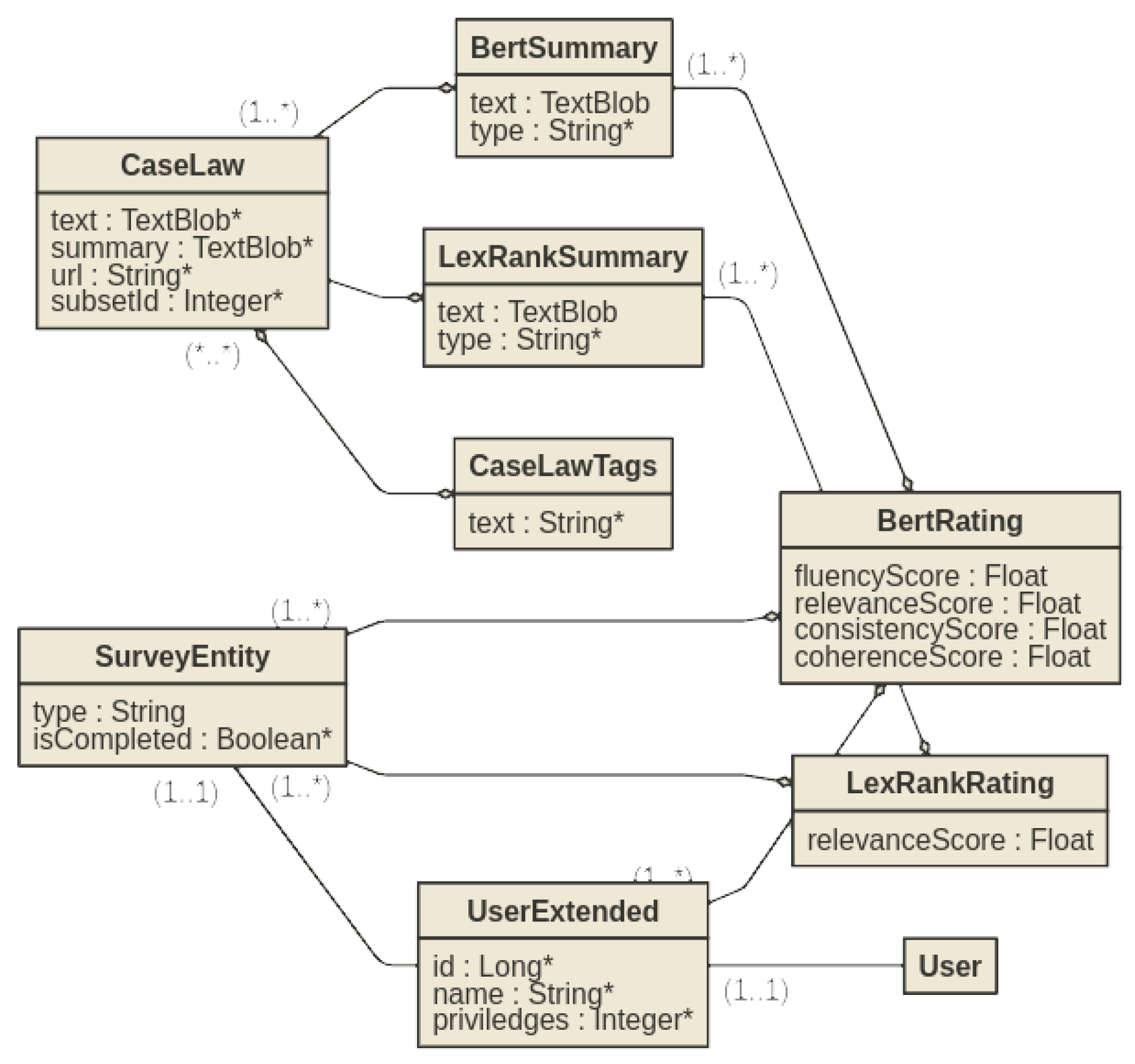
A key component for evaluating the effectiveness of an automatic summarization method is reference summaries, which are summaries of a document that have been created by humans and are considered to be high-quality summaries. While a few datasets provide reference summaries for evaluation purposes, in many cases, especially in linguistically under-resourced languages, such as the Greek language, reference summaries may not be available, making it impossible to automatically compare the performance of different legal automatic summarization methods.
In this paper, we address automatic summarization methods for Greek legal documents. There exists no dataset in the Greek language that is tailored for automated legal document summarization. To overcome this crucial obstacle, this paper introduces a dataset of Greek Court judgments that has been developed specifically for this purpose. The paper elaborates on the process of generating the dataset, outlines its characteristics, and compares it with other text summarization datasets (
Section 3).
Additionally, we employed and adapted to the specific context well-known extractive summarization algorithms, LexRank and Biased LexRank. We also modeled abstractive summarization as a sequence-generation task, by training and utilizing an encoder–decoder deep learning model based on the BERT architecture (
Section 4). We evaluated both of our approaches, extractive and abstractive, by conducting a human evaluation study, as well as utilizing automatic evaluation metrics, providing a detailed comparison of different variations of our extractive and abstractive summarization methods (
Section 5).
In this work, to the best of our knowledge, we employed the first study on evaluating state-of-the-art methods for summarizing Greek legal judgments. We pre-trained and evaluated our models with promising results on a dataset of Greek Court judgments we correspondingly developed for this task. Our automated evaluation revealed that fine-tuning BERT models on specific upstream tasks can significantly improve the models’ performances; incorporating the case category tags into the extractive models offered no noticeable improvements, whereas for the abstractive ones, this resulted in greatly increased performance. According to the evaluations by legal experts, extractive methods exhibit average performance, while abstractive methods produce text that is moderately fluent and coherent. However, abstractive methods receive low scores in terms of relevance and consistency metrics. This may suggest that legal professionals favor methods that are factually aligned with the judgment text, methods that accurately represent the facts and information presented in the original text. Finally, we noticed the need for standardized practices in manual summary writing and better-curated datasets.
The remainder of this paper is organized as follows:
Section 2 reviews previous work, while it stresses the differentiation and contribution of this work.
Section 3 introduces our dataset and compares it with other text summarization datasets.
Section 4 presents our summarization methods, while
Section 5 describes our experimental results and discusses their significance. Finally, we draw our conclusions and present future work in
Section 6.
3. A Summarization Dataset for Greek Case Law
A dataset plays a significant role in the development and improvement of legal document summarization models. It allows researchers and developers to compare the performance of various models and identify areas where enhancements can be made. At the same time, the quality of a text summarization dataset is critical to the performance of the machine learning models trained on it. Having a diverse and representative dataset, with a variety of document types, topics, and writing styles is important because it ensures that the models can generalize well to new documents and are effective across different types of documents and domains.
Generating a dataset demands a substantial investment of time and resources, particularly when ensuring that the dataset is of superior quality and faithfully reflects the domain. To ensure the accuracy and reliability of the dataset, we narrowed our search space to reputable sources offering publicly accurate and reliable information i.e., the highest-ranking Courts’ official websites. Another criterion we focused our effort on was to ensure that the dataset is diverse and covers different legal domains, such as criminal law, civil law, and administrative law. Last but not least, as text summarization techniques are more useful for complex and lengthy documents, we considered selecting documents that are at least a few pages long and contain formal language and legal terminology that may be challenging for non-experts to understand.
In this section, we firstly briefly describe the role of case law in Greece, then we describe the legal corpus we collected, proceed to provide information regarding token-level statistics of the dataset, and finally, compare it with other text summarization datasets.
We published our dataset (
https://huggingface.co/datasets/DominusTea/GreekLegalSum, accessed on 16 April 2023) with clear documentation and instructions on how it can be used, hoping that other researchers and practitioners may find it useful for text summarization tasks regarding Greek legal documents. Furthermore, all code, materials, and the baseline and best-performing models for this paper are openly available on GitHub (
https://github.com/DominusTea/LegalSumPaper, accessed on 16 April 2023).
Author Contributions
M.K.: conceptualization, methodology, original draft preparation, review and editing; D.G.: methodology, software, validation, data curation, original draft preparation, review and editing; E.G.: supervision, review and editing; P.T.: supervision, funding acquisition, review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
We gratefully acknowledge the support of the European-Union-funded Project PolicyCLOUD under Grant Agreement No. 870675.
Data Availability Statement
Acknowledgments
We express our gratitude to the legal experts who participated in the evaluation for their valuable time and expertise. We would also like to thank the Supreme Civil and Criminal Court of Greece for providing the texts of their decisions, as well as their notation, indexing, and summaries.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of the data; in the writing of the manuscript; nor in the decision to publish the results.
References
- Nenkova, A. Automatic Summarization. Found. Trends® Inf. Retr. 2011, 5, 103–233. [Google Scholar] [CrossRef]
- Jain, D.; Borah, M.D.; Biswas, A. Summarization of legal documents: Where are we now and the way forward. Comput. Sci. Rev. 2021, 40, 100388. [Google Scholar] [CrossRef]
- Solan, L.M. The Language of Judges; University of Chicago Press: Chicago, IL, USA, 1993. [Google Scholar] [CrossRef]
- Turtle, H. Text retrieval in the legal world. Artif. Intell. Law 1995, 3, 5–54. [Google Scholar] [CrossRef]
- Ermakova, L.; Cossu, J.V.; Mothe, J. A survey on evaluation of summarization methods. Inf. Process. Manag. 2019, 56, 1794–1814. [Google Scholar] [CrossRef]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Ganesan, K. ROUGE 2.0: Updated and Improved Measures for Evaluation of Summarization Tasks. arXiv 2018, arXiv:1803.01937. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Tianyi, Z.; Varsha, K.; Felix, W.; Kilian Q., W.; Yoav, A. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Kornilova, A.; Eidelman, V. BillSum: A Corpus for Automatic Summarization of US Legislation. In Proceedings of the 2nd Workshop on New Frontiers in Summarization, Hong Kong, China, 4 November 2019; pp. 48–56. [Google Scholar] [CrossRef]
- Bhattacharya, P.; Hiware, K.; Rajgaria, S.; Pochhi, N.; Ghosh, K.; Ghosh, S. A Comparative Study of Summarization Algorithms Applied to Legal Case Judgments. In Proceedings of the Advances in Information Retrieval, Cologne, Germany, 14–18 April 2019; Lecture Notes in Computer Science. Azzopardi, L., Stein, B., Fuhr, N., Mayr, P., Hauff, C., Hiemstra, D., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 413–428. [Google Scholar] [CrossRef]
- Shen, Z.; Lo, K.; Yu, L.; Dahlberg, N.; Schlanger, M.; Downey, D. Multi-LexSum: Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities. arXiv 2022, arXiv:2206.10883. [Google Scholar]
- Xu, H.; Šavelka, J.; Ashley, K.D. Using Argument Mining for Legal Text Summarization. In Proceedings of the JURIX, Brno, Czech Republic, 9–11 December 2020; Volume 334, pp. 184–193. [Google Scholar] [CrossRef]
- Zhong, L.; Zhong, Z.; Zhao, Z.; Wang, S.; Ashley, K.D.; Grabmair, M. Automatic Summarization of Legal Decisions using Iterative Masking of Predictive Sentences. In Proceedings of the Seventeenth International Conference on Artificial Intelligence and Law (ICAIL’19), Montreal, QC, Canada, 17–21 June 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 163–172. [Google Scholar] [CrossRef]
- de Vargas Feijó, D.; Moreira, V.P. RulingBR: A Summarization Dataset for Legal Texts. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 255–264. [Google Scholar] [CrossRef]
- Kryscinski, W.; Keskar, N.S.; McCann, B.; Xiong, C.; Socher, R. Neural Text Summarization: A Critical Evaluation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 540–551. [Google Scholar] [CrossRef]
- Grusky, M.; Naaman, M.; Artzi, Y. Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies. arXiv 2020, arXiv:1804.11283. [Google Scholar]
- Anand, D.; Wagh, R. Effective deep learning approaches for summarization of legal texts. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 2141–2150. [Google Scholar] [CrossRef]
- Xu, H.; Savelka, J.; Ashley, K.D. Toward summarizing case decisions via extracting argument issues, reasons, and conclusions. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law, Sao Paulo, Brazil, 21–25 June 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 250–254. [Google Scholar]
- Papantoniou, K.; Tzitzikas, Y. NLP for the Greek Language: A Brief Survey. In Proceedings of the 11th Hellenic Conference on Artificial Intelligence, ACM, Athens, Greece, 2–4 September 2020. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Farzindar, A.; Lapalme, G. Letsum, an automatic legal text summarizing system. In JURIX 2004, the Seventeenth Annual Conference; IOS Press: Amsterdam, The Netherlands, 2004; pp. 11–18. [Google Scholar]
- Polsley, S.; Jhunjhunwala, P.; Huang, R. CaseSummarizer: A System for Automated Summarization of Legal Texts. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: System Demonstrations, Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 258–262. [Google Scholar]
- Kim, M.Y.; Xu, Y.; Goebel, R. Summarization of Legal Texts with High Cohesion and Automatic Compression Rate. In Proceedings of the New Frontiers in Artificial Intelligence, Kanagawa, Japan, 27–28 October 2013; Lecture Notes in Computer Science. Motomura, Y., Butler, A., Bekki, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 190–204. [Google Scholar] [CrossRef]
- Manor, L.; Li, J.J. Plain English Summarization of Contracts. arXiv 2019, arXiv:1906.00424. [Google Scholar]
- Feijo, D.; Moreira, V. Summarizing Legal Rulings: Comparative Experiments. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; INCOMA Ltd.: Varna, Bulgaria, 2019; pp. 313–322. [Google Scholar] [CrossRef]
- Fabbri, A.R.; Kryściński, W.; McCann, B.; Xiong, C.; Socher, R.; Radev, D. SummEval: Re-evaluating Summarization Evaluation. Trans. Assoc. Comput. Linguist. 2021, 9, 391–409. [Google Scholar] [CrossRef]
- Maynez, J.; Narayan, S.; Bohnet, B.; McDonald, R. On Faithfulness and Factuality in Abstractive Summarization. arXiv 2020, arXiv:2005.00661. [Google Scholar]
- Karampatzos, A.; Malos, G. The Role of Case Law and the Prospective Overruling in the Greek Legal System. In Ius Comparatum-Global Studies in Comparative Law; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 163–184. [Google Scholar] [CrossRef]
- Dodge, J.; Ilharco, G.; Schwartz, R.; Farhadi, A.; Hajishirzi, H.; Smith, N. Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping. arXiv 2020, arXiv:2002.06305. [Google Scholar]
- Luijtgaarden, N.V.D. Automatic Summarization of Legal Text. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2019. Available online: https://studenttheses.uu.nl/handle/20.500.12932/34261 (accessed on 16 April 2023).
- Erkan, G.; Radev, D.R. LexRank: Graph-based Lexical Centrality as Salience in Text Summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report 1999-66; Stanford InfoLab: Stanford, CA, USA, 1999. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Otterbacher, J.; Erkan, G.; Radev, D.R. Biased LexRank: Passage retrieval using random walks with question-based priors. Inf. Process. Manag. 2009, 45, 42–54. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 3730–3740. [Google Scholar] [CrossRef]
- Koutsikakis, J.; Chalkidis, I.; Malakasiotis, P.; Androutsopoulos, I. GREEK-BERT: The Greeks Visiting Sesame Street. In Proceedings of the 11th Hellenic Conference on Artificial Intelligence (SETN 2020), Athens, Greece, 2–4 September 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 110–117. [Google Scholar] [CrossRef]
- Allahyari, M.; Pouriyeh, S.; Assefi, M.; Safaei, S.; Trippe, E.D.; Gutierrez, J.B.; Kochut, K. Text Summarization Techniques: A Brief Survey. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2017, 47, 1–66. [Google Scholar] [CrossRef]
- Krippendorff, K. Computing Krippendorff’s Alpha-Reliability. 2011. Available online: https://repository.upenn.edu/asc_papers/43 (accessed on 16 April 2023).
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. arXiv 2020, arXiv:2001.04451v2. [Google Scholar]
- Liu, W.; Wu, H.; Mu, W.; Li, Z.; Chen, T.; Nie, D. CO2Sum: Contrastive Learning for Factual-Consistent Abstractive Summarization. arXiv 2021, arXiv:2112.01147. [Google Scholar]
- Zhu, C.; Xu, R.; Zeng, M.; Huang, X. A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining. arXiv 2020, arXiv:2004.02016. [Google Scholar]
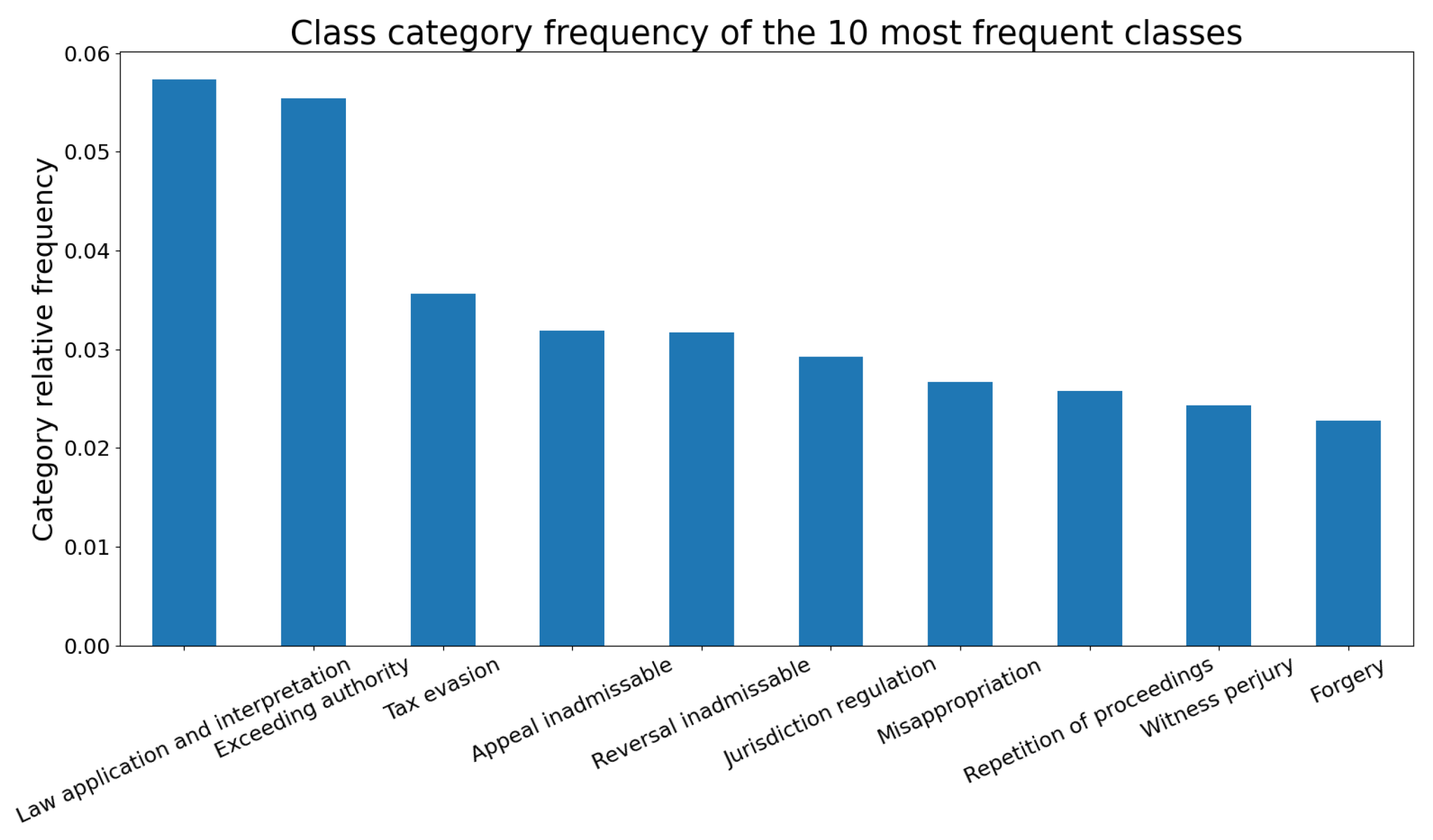
Figure 1.
The 10 most-frequent categories in the AreiosPagos dataset. The x-axis corresponds to the category labels. The y-axis corresponds to the absolute frequency of each category. Original Greek labels: Νόμου Εφαρμογή και ερμηνεία, Υπέρβαση εξουσίας, Φοροδιαφυγή, Εφέσεως απαράδεκτο, Aναιρέσεως απαράδεκτο, Κανονισμός αρμοδιότητας, Υπεξαίρεση, Επανάληψη διαδικασίας, Ψευδορκία μάρτυρα, Πλαστογραφία.
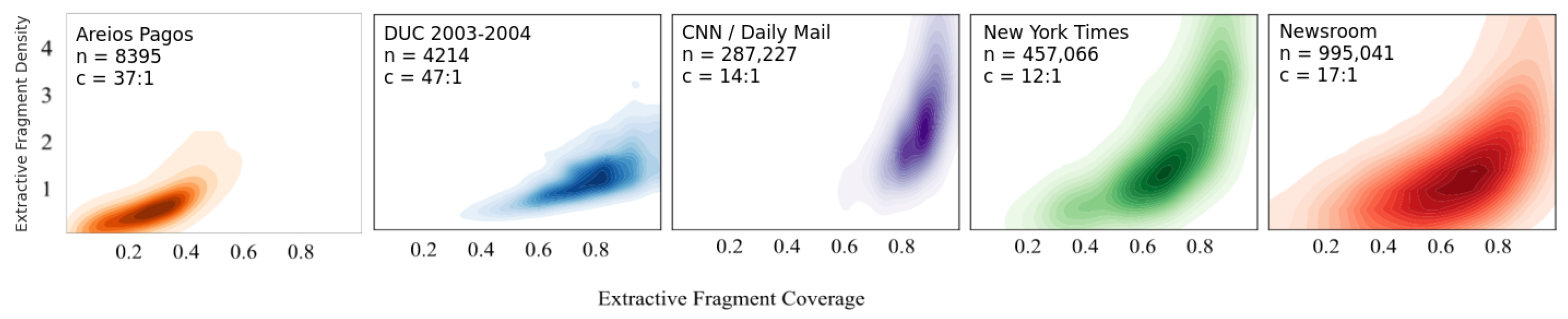
Figure 2.
A comparison of the extractive fragment coverage - extractive fragment density relationship for the AreiosPagos dataset compared to other text summarization datasets. Data observations are plotted using a kernel density estimate method.
n denotes the number of documents in the dataset, and
c refers to the compression ratio of the main text’s length over the summary’s length. Leftmost: the AreiosPagos dataset. Right: news domain datasets as reported in [
17]. The AreiosPagos dataset is homogeneous in terms of coverage, as a moderate percentage of words in the summary appear also in the main text. In terms of extractive fragment density, the AreiosPagos dataset shows less variance than the other datasets, while having generally low scores.
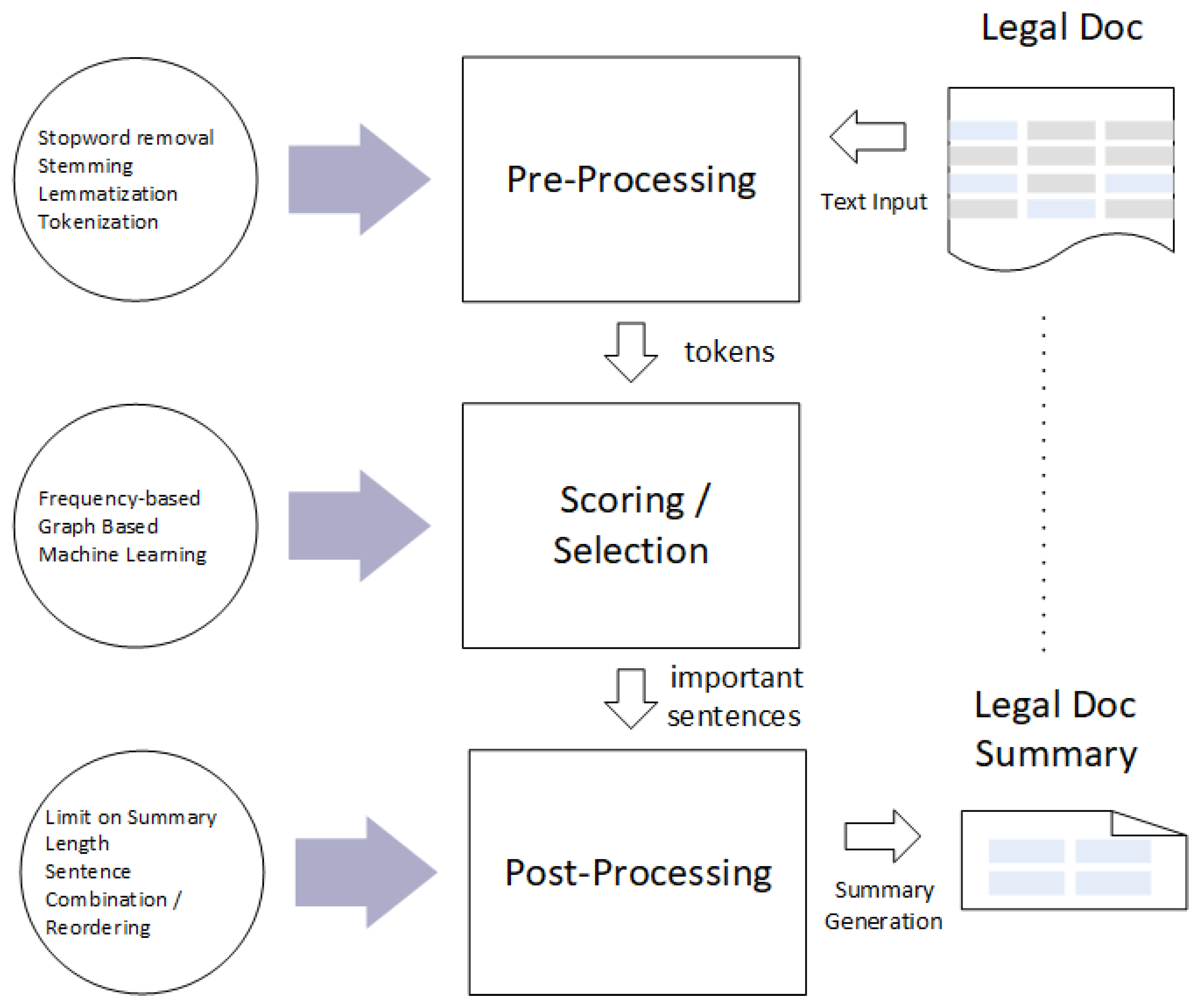
Figure 3.
A general workflow of an extractive text summarization system. A combination of techniques/heuristics may be applied to the text at each step, to identify the most-important information from the original text and present it in a concise and readable format.
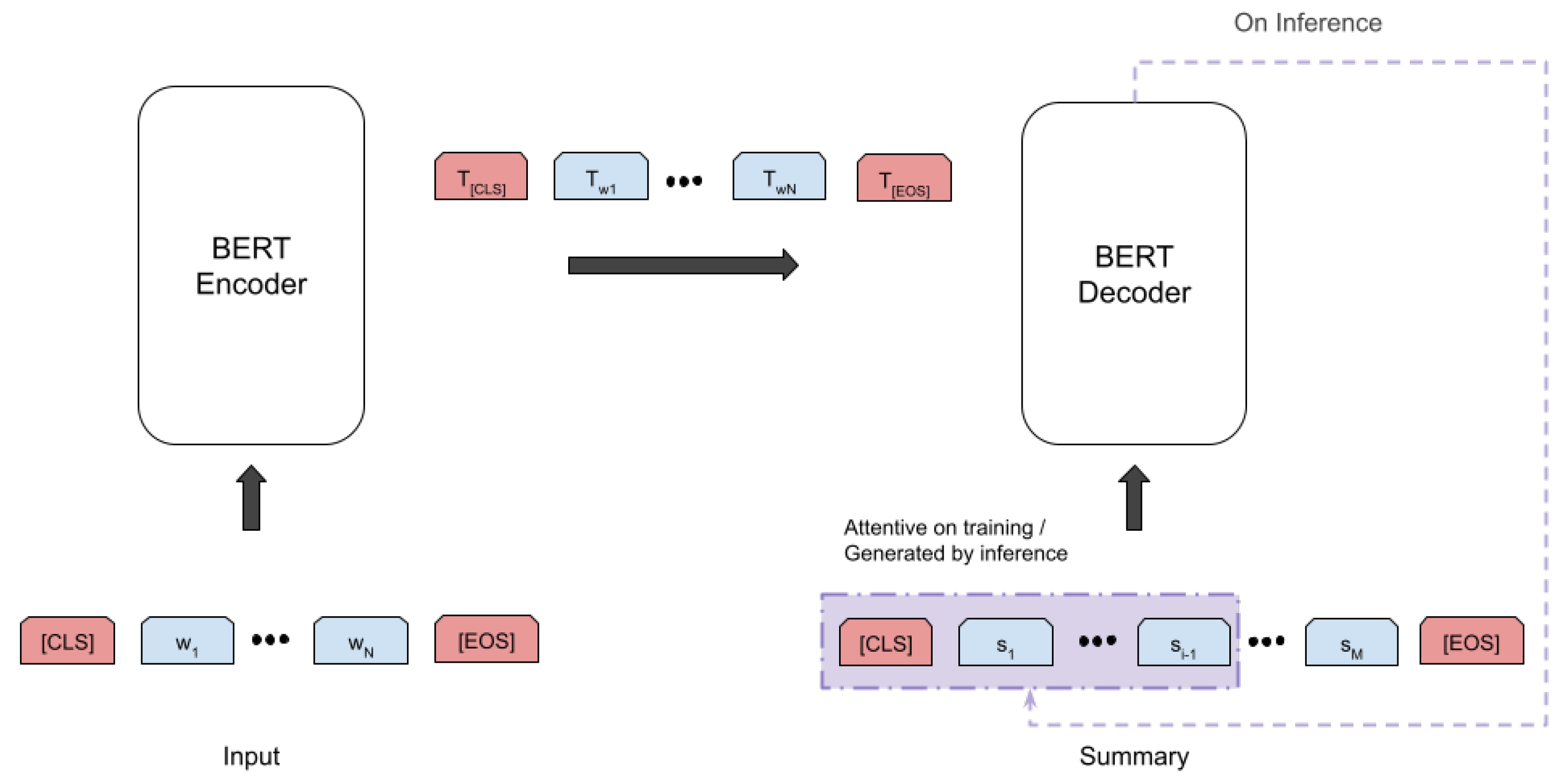
Figure 4.
The architecture of the BERT encoder–decoder summarization model we utilized, a two-step process, where the input text is first transformed into contextualized representations and then passed through a decoder to generate a summary. The BERT encoder generates contextualized representations of the input sequence, which are passed to the BERT decoder for generating a summary. Tokens (in blue) correspond to words in the input text, while [CLS] and [EOS] (in red) correspond to special tokens. During inference, the decoder takes as the input the output generated so far. During training, the decoder attends to the reference summary up to the token corresponding to each time step.
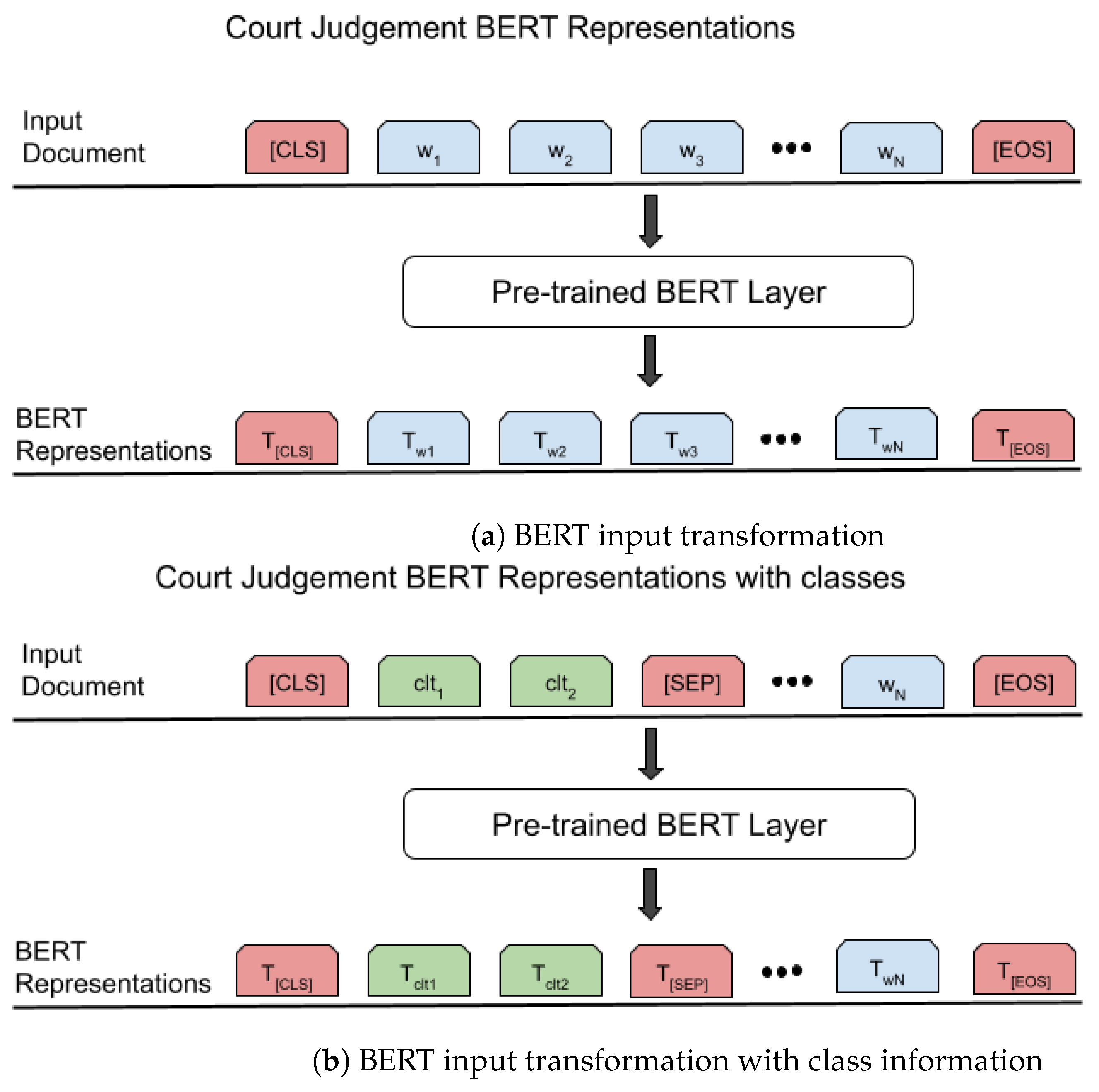
Figure 5.
(a) BERT input transformation; (b) BERT input transformation with class information. The BERT input transformation with class information involves adding special tokens to indicate the class of the input text and separating the class information from the original text using the [SEP] token. The tokens in blue correspond to words in the input text, those in red to special tokens, and those in green to class tokens.
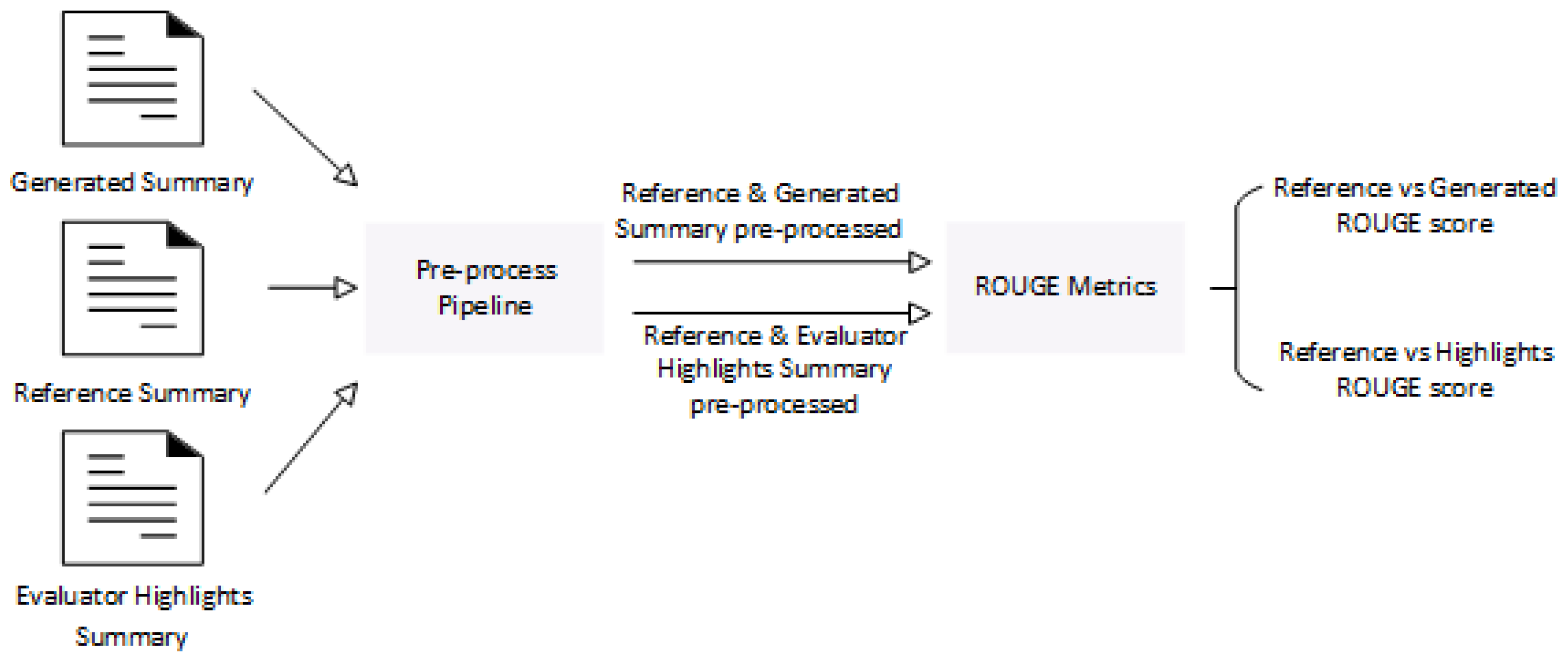
Figure 6.
A schema of the automatic evaluation process. Both reference, evaluator highlight summaries and generated summaries are pre-processed. The ROUGE metrics are used to compare generated and evaluator highlight summaries versus the reference summaries.
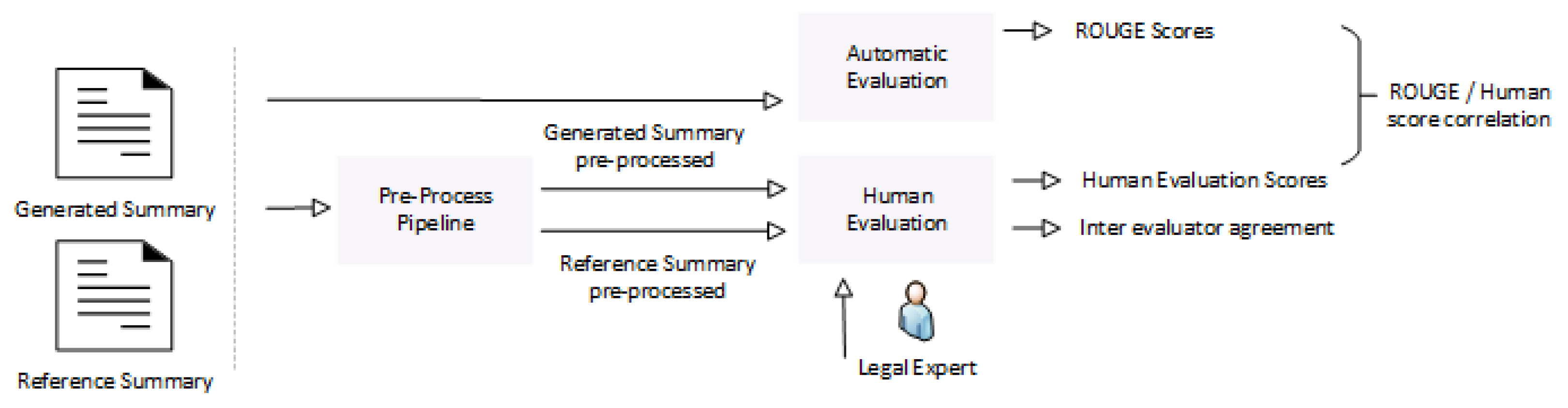
Figure 7.
A schema of the human evaluation pipeline. Reference summaries were pre-processed to match the BERT-generated summaries. Human evaluation metrics were used to measure the relevance, consistency, coherence, and fluency of the produced summaries and capture the inter-evaluator agreement.
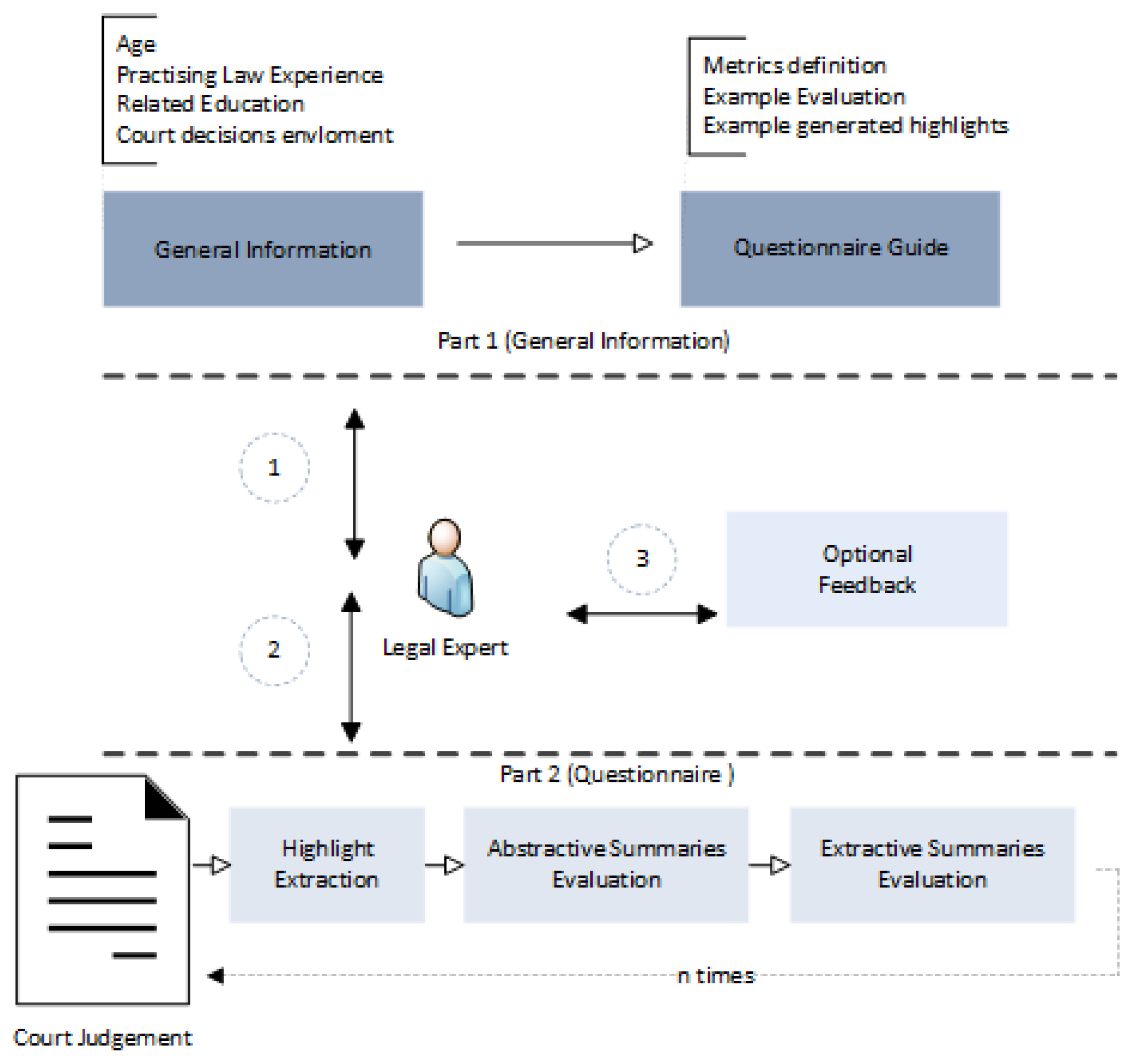
Figure 8.
A flowchart schema of the survey page web interface. Each participant is firstly asked to answer questions related to general information about him/her and then presented with a guide that explains the questionnaire question’s format and how to answer each question. Afterwards, the participant iteratively evaluates the extractive and abstractive summaries of the judicial judgment texts. Additional feedback may be provided at the end.
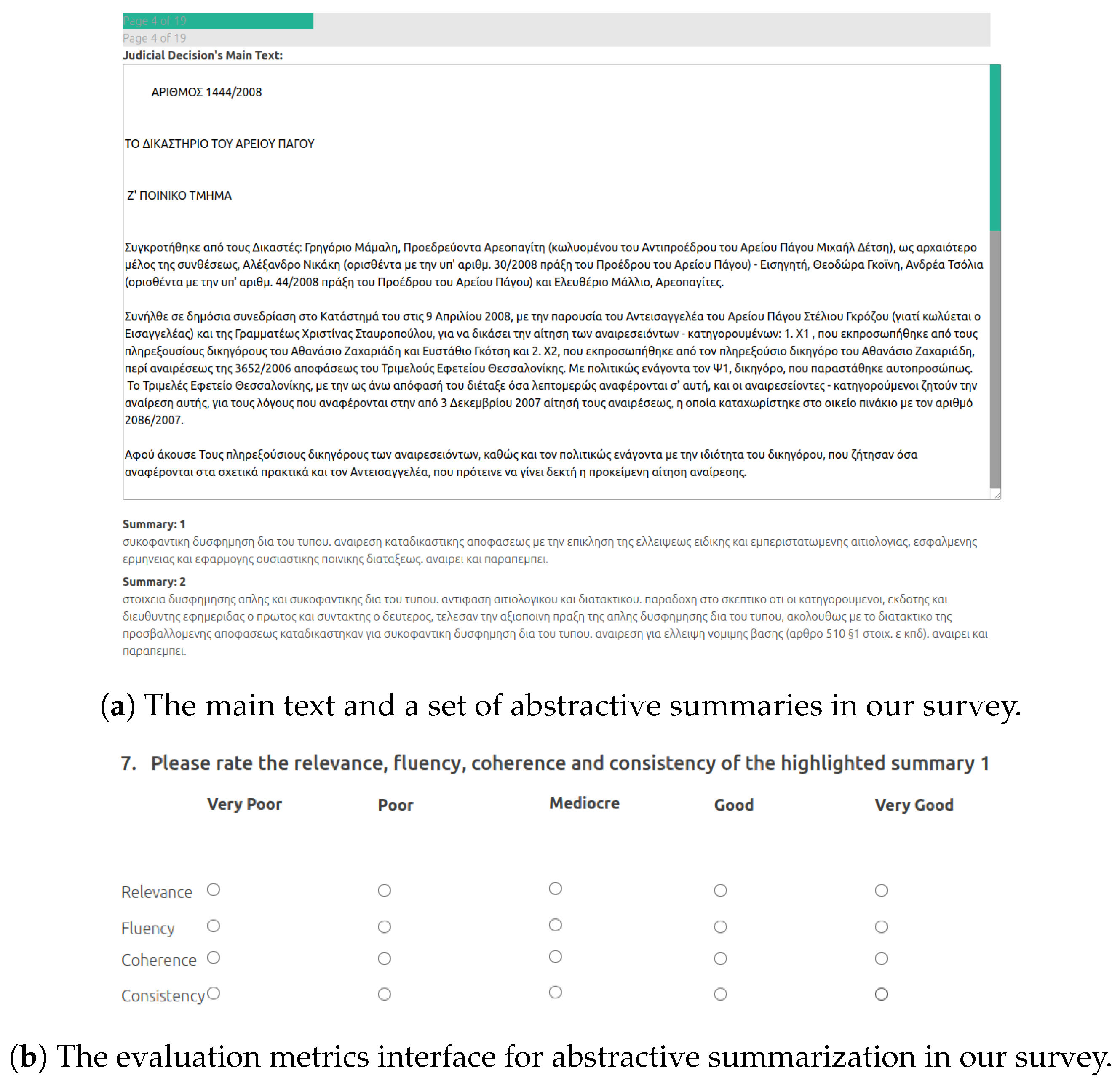
Figure 9.
Two screen captures of the abstractive summarization evaluation in our survey.
Figure 10.
A screenshot of the extractive summarization evaluation in our survey. Extracted summaries are highlighted in bright yellow color.
Table 1.
Basic statistics for AreiosPagos dataset and trained models.
| AreiosPagos Dataset |
|---|
| Property | # of Dataset Entries | # of Models (Train/Val/Test) |
| Cases with Summary | 8395 | 5888/1269/1238 |
| Cases with Classification | 6370 | 4458/956/956 |
Table 2.
Metadata of the Supreme Civil and Criminal Court judgments’ (AreiosPagos) dataset. Metadata that were automatically inferred, using the judgments’ main text, are labeled with a ✓ in the Inferred column.
| AreiosPagos Metadata |
|---|
| Metadata | Data Type | Inferred | Description |
| Case category | String | | The general category that each Court case is classified into by the Court legal editors. Each case belongs to one category. |
| Case tags | String | | The category tags that correspond to each Court case, as classified to by the Court legal editors. Each case may have multiple tags. |
| Court division | String | | The specific division and its type (e.g., penal, civil, etc.) of the Court that issued the decision. |
| Issue Year | Integer | ✓ | The year of the decision. |
| Court’s case identifier | String | ✓ | The identifier given by the Court for the particular case. It is unique among cases judged by the same Court division, but not across them. |
| Source URL | String | ✓ | The URL to the original HTML web page of the Court from which the text, summary, and metadata were sourced. |
Table 3.
Statistical properties of the text summarization dataset using the average ratios of token-level lengths for documents and summaries and their sentences. AreiosPagos and Rechtspraak are legal Court case text datasets, while Newsroom and CNN-DailyMail are news domain summarization datasets. The results on the Newsroom dataset are reported from [
17]. The results on the CNN-DailyMail and Rechtspraak datasets are reported from [
31]. The upper part of the table presents statistics on the judgments’ main texts, while the lower part presents the statistics on the judgment summaries.
| Dataset Comparison on Token-Level Length Statistics |
|---|
| Statistical Property | AreiosPagos | Rechtspraak | Newsroom | CNN-DailyMail |
| # of Documents | 8395 | 403,585 | 1,321,995 | 311,672 |
| Avg.tokens/doc | 3169.06 | 2341.5 | 658.6 | 766.0 |
| Avg.sent/doc | 77.00 | 140.6 | - | 29.74 |
| Avg.tokens/sent | 40.6 | 16.6 | - | 25.75 |
| # of Summaries | 6370 | 403,585 | 1,321,995 | 311,672 |
| Avg.tokens/sum | 84.6 | 62.1 | 26.7 | 25.75 |
| Avg.sent/sum | 5.12 | 3.41 | - | 3.72 |
| Avg.tokens/sent | 18.2 | - | - | - |
Table 4.
Automatic evaluation results for the whole dataset and its subset containing classes, presented in two segments of the table corresponding to (a) automatic extractive summarizers and (b) automatic abstractive summarizers. The extractive methods extract sentences until they reach three-times the length of the reference summary. In the abstractive models, we modified the inputs and labeled the models accordingly; RE: the text is rearranged so the case result is always included and at the start of the input, RM: less important parts of the text are removed, C: the case’s category tags are included at the start of the input, LR: the input document is halved using . The ROUGE scores are F1-scores given in percentage (%) form. The ROUGE-L/W scores are reported without stopword removal for the BERT methods. The best-performing automatic method in each category is in bold.
| AreiosPagos full (n = 8395) |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-3 | ROUGE-L | ROUGE-W |
| Random Sentence | 71.50 | 40.72 | 20.01 | 13.38 | 6.21 |
| 71.19 | 42.38 | 23.27 | 16.84 | 8.11 |
| 71.10 | 41.71 | 21.78 | 14.88 | 7.03 |
| BERT | 60.58 | 39.48 | 21.17 | 14.18 | 5.29 |
| BERT (RE) | 59.76 | 38.81 | 20.79 | 14.79 | 5.13 |
| BERT (RE + RM) | 60.92 | 40.05 | 22.08 | 14.57 | 5.43 |
| BERT (RE + RM + LR) | 60.60 | 39.75 | 21.75 | 14.27 | 5.31 |
| AreiosPagos w/classes (n = 6370) |
| Method | ROUGE-1 | ROUGE-2 | ROUGE-3 | ROUGE-L | ROUGE-W |
| Random Sentence | 70.64 | 40.26 | 19.77 | 13.41 | 6.28 |
| 71.46 | 42.90 | 23.78 | 17.29 | 8.35 |
| 71.51 | 42.10 | 22.02 | 15.09 | 7.09 |
| Biased LexRank | 67.73 | 41.05 | 22.06 | 15.50 | 7.33 |
| BERT | 62.90 | 38.52 | 20.64 | 14.37 | 5.28 |
| BERT (RE) | 62.80 | 38.51 | 20.39 | 14.19 | 5.21 |
| BERT (RE + RM) | 62.08 | 38.83 | 21.26 | 14.42 | 5.28 |
| BERT (RE + RM + C) | 64.24 | 40.40 | 22.27 | 15.34 | 5.64 |
| BERT (RE + RM + LR) | 62.01 | 37.89 | 20.32 | 13.71 | 4.99 |
| BERT (RE + RM + LR + C) | 63.98 | 39.85 | 21.90 | 15.33 | 5.64 |
Table 5.
Human evaluation results, on the modified human evaluation metrics using a 1–5 Likert scale. The first section of the table compares our BERT abstractive summarization method with reference summaries. The second section of the table compares the human-evaluated relevance score of the summaries generated by the vanilla LexRank and the Biased LexRank algorithms.
| Summary | Relevance | Fluency | Coherence | Consistency |
|---|
| Reference | 4.1 | 3.7 | 3.9 | 4.3 |
| BERT (RE + RM + C) | 2.6 | 3.4 | 3.4 | 2.6 |
| 3.3 | - | - | - |
| Biased LexRank | 3.4 | - | - | - |
Table 6.
Pearson’s correlation of human evaluation scores and ROUGE metrics’ F1-scores of automatically generated abstractive summaries. For each human evaluation metric, the most-correlated automatic metric is highlighted in bold, while the less-correlated is underlined.
| Metrics | Relevance | Fluency | Coherence | Consistency | Internal | External | Average |
|---|
| ROUGE-1 | 0.1621 | 0.5001 | 0.1632 | 0.0929 | 0.3899 | 0.1335 | 0.2995 |
| ROUGE-2 | 0.3608 | 0.4718 | 0.1224 | 0.2707 | 0.3496 | 0.3292 | 0.4153 |
| ROUGE-3 | 0.3793 | 0.2916 | −0.0738 | 0.2864 | 0.1323 | 0.3436 | 0.3105 |
| ROUGE-L | 0.1303 | 0.3546 | -0.1155 | 0.2332 | 0.1465 | 0.1870 | 0.2084 |
| ROUGE-W | −0.1273 | 0.1909 | −0.2944 | 0.1996 | −0.0513 | 0.1685 | 0.0909 |
Table 7.
Average length statistics and ROUGE F1-scores of the extractive summaries generated using the human evaluators’ highlights and the automatically generated extractive summaries versus the reference abstractive summaries. The second row represents the evaluators’ highlights summaries truncated to three-times the length of the reference summary, matching the extractive summaries in
Table 4. The last two columns present the token-level length statistics of the summaries compared to the Court’s judgment main text and reference summary, respectively.
| Human/Auto Summaries | R-1 | R-2 | R-3 | R-L | R-W | Sum/Doc | Sum/Ref |
|---|
| Eval.Highlights | 64.56 | 40.72 | 23.21 | 13.93 | 6.56 | 0.170 | 6.43 |
| Eval.Highlights (capped) | 69.44 | 42.17 | 24.09 | 14.93 | 7.14 | 0.088 | 2.54 |
| 61.45 | 36.90 | 19.52 | 12.15 | 6.41 | 0.079 | 3.00 |
| Biased LexRank | 55.57 | 35.41 | 18.68 | 14.58 | 7.63 | 0.079 | 3.00 |
Table 8.
ROUGE metrics’ comparison of automatic extractive summarization methods using the human evaluators’ highlights summaries as a reference. We report the average ROUGE F1-score, over all evaluators and all Court judgment summaries, in our human evaluation study.
| Auto Summaries | R-1 | R-2 | R-3 | R-L | R-W |
|---|
| 80.24 | 46.66 | 24.86 | 16.14 | 7.26 |
| Biased LexRank | 74.23 | 42.49 | 21.81 | 16.84 | 8.00 |
Table 9.
Krippendorff’s alpha agreement metric on each human evaluation metric for each summary type. The internal metric is the average of fluency and coherence metrics. The external metric is the average of relevance and consistency metrics. In the abstractive summaries category, we included both reference and generated abstractive summaries as human evaluators were evaluated both in the same way and in a randomized order without knowing if any of the summaries were written by legal experts.
| Type | Relevance | Fluency | Coherence | Consistency | Internal | External | Average |
|---|
| Abstractive | 0.6405 | −0.0215 | 0.0709 | 0.6400 | 0.0260 | 0.6754 | 0.4332 |
| Extractive | 0.4250 | - | - | - | - | - | - |
Table 10.
Average pairwise highlights agreement on each question over all human evaluators. The pairwise agreement is calculated as the ratio between the intersection and the union of the two sets of highlights.
| q1 | q2 | q3 | q4 | q5 | Average |
|---|
| 0.2619 | 0.0908 | 0.1531 | 0.2556 | 0.3957 | 0.2314 ± 0.141 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}