1. Introduction
The energy consumption of Information and Communications Technology (ICT) accounted for 7% of the global electricity usage in 2020 and is forecast to be around the average of the best-case and expected scenarios (7% and 21%) by 2030 [
1]. This trend makes the energy efficiency of digital platforms a large new technological challenge.
There are two main approaches to responding to this challenge—hardware and software. The first approach deals with energy-efficient hardware devices at a transistor (or gate) level and aims to produce electronic devices consuming as little power as possible.
The second approach deals with the development of energy-efficient software. On the level of solutions, it can be further subdivided into the system-level and applicationlevel approaches. The system-level approach tries to optimize the execution environment rather than the application. It is currently a mainstream approach using Dynamic Voltage and Frequency Scaling (DVFS), Dynamic Power Management (DPM), and energy-aware scheduling to optimize the energy efficiency of the execution of the application. DVFS reduces the dynamic power a processor consumes by throttling its clock frequency. Briefly, dynamic power is consumed due to the switching activity in the processor’s circuits. Static power is consumed when the processor is idle. DPM turns off the electronic components or moves them to a low-power state when idle to reduce energy consumption.
The application-level energy optimization techniques use application-level decision variables and aim to optimize the application rather than the executing environment [
2,
3]. This category’s most important decision variable is
workload distribution.
The development of energy-efficient software employing application-level energy optimization techniques has become an important category owing to the paradigm shift in the composition of digital platforms from single-core processors to heterogeneous platforms integrating multicore CPUs and graphics processing units (GPUs). This paradigm shift has created significant opportunities for application-level energy optimization and bi-objective optimization for energy and performance.
In this work, we present an overview of the application-level bi-objective optimization methods for energy and performance that address two fundamental challenges, nonlinearity and heterogeneity, inherent in modern HPC platforms. Applying the methods requires energy profiles of computational kernels (components) of a hybrid parallel application executing on the different computing devices of the HPC platform. Therefore, we summarize the research innovations in the three mainstream component-level energy measurement methods and present their accuracy and performance trade-offs.
Finally, accelerating and scaling the optimization methods for energy and performance is crucial to achieving energy efficiency objectives and meeting quality-of-service requirements in modern HPC platforms and cloud computing infrastructures. We introduce the building blocks needed to achieve this scaling and conclude with the challenges to scaling. Briefly, two significant challenges are described, namely fast optimization methods and accurate component-level energy runtime measurements, especially for components running on accelerators.
The paper is organized as follows.
Section 2 presents the terminology used in energy-efficient computing, including a brief on bi-objective optimization.
Section 3 describes the experimental methodology and statistical confidence in experiments used in this work.
Section 4 reviews the application-level optimization methods on modern heterogeneous HPC platforms for energy and performance.
Section 5 overviews the state-of-the-art energy measurement methods.
Section 6 illuminates the building blocks for scaling for energy-efficient parallel computing and highlights the challenges to scaling. Finally,
Section 7 provides concluding remarks.
6. Building Blocks for Scaling for Energy-Efficient Parallel Computing
Accelerating and scaling the optimization methods for energy and performance is crucial to achieving energy efficiency objectives and meeting quality-of-service requirements in modern HPC platforms and cloud computing infrastructures.
To elucidate the building blocks needed to achieve this scaling, we will recapitulate the main steps of the optimization methods [
2,
3,
13,
14,
19,
20].
The first step involves modeling the hybrid application if the execution environment is a heterogeneous hybrid platform comprising different computing devices (multicore CPUs and accelerators). A hybrid application comprises several multithreaded kernels executing simultaneously on different computing devices of the platform. The load of one kernel may significantly affect others’ performance due to severe resource contention arising from tight integration. Due to this, modeling each kernel’s performance and energy consumption individually in hybrid applications becomes a problematic task [
43].
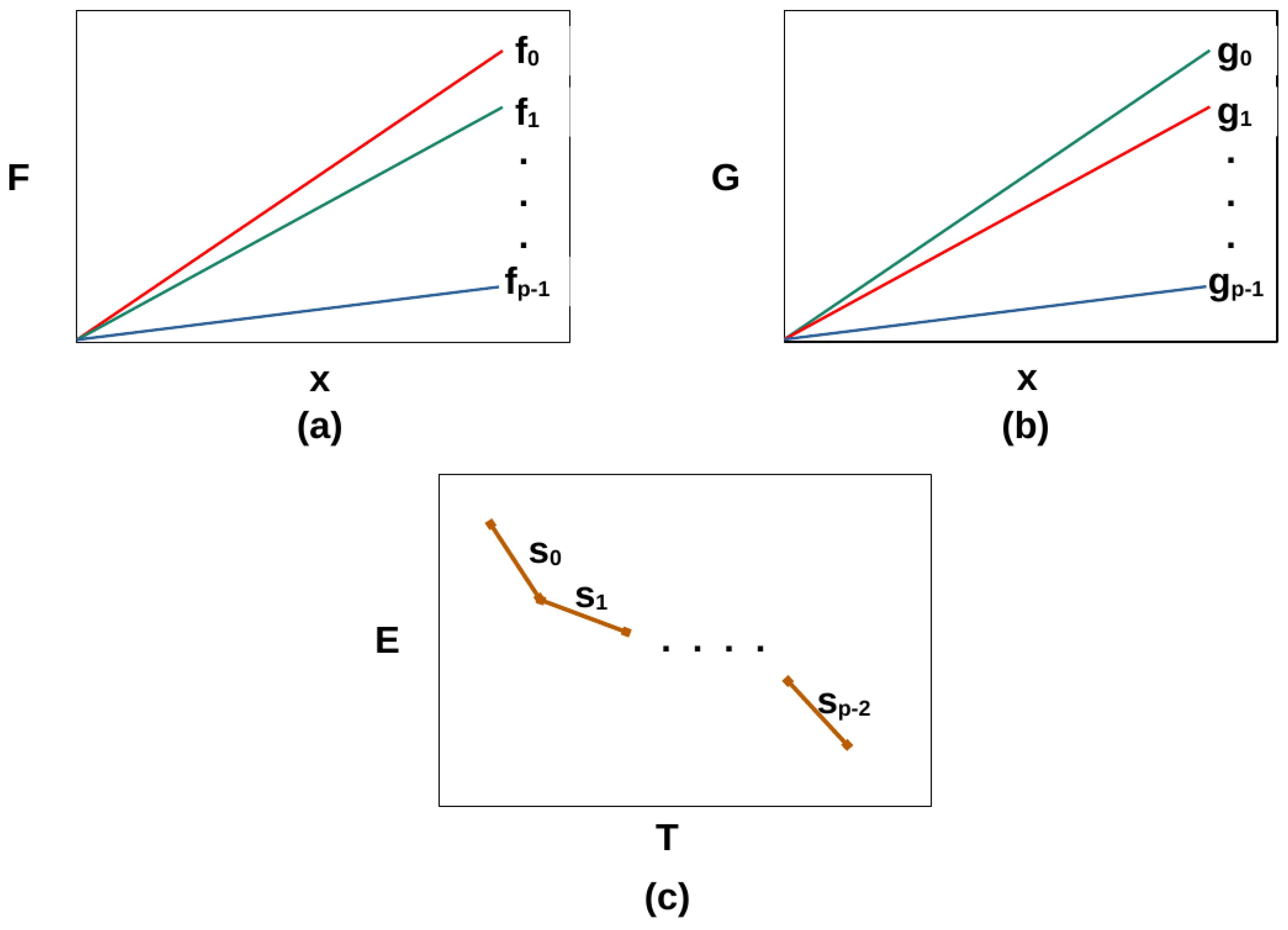
Therefore, the research above considers hybrid application configurations comprising no more than one kernel per device. Each group of cores executing a kernel is modeled as an abstract processor. Hence, the executing platform is represented by a set of heterogeneous abstract processors. The grouping aims to minimize the contention and mutual dependence between abstract processors. In addition, the sharing of system resources is maximized within groups and minimized between the groups.
Hence, a hybrid application is represented by a set of computational kernels executing on groups of cores, which we term
heterogeneous abstract processors. Consider the platform shown in
Figure 1 as an example. It consists of two multicore CPUs: a dual-socket Intel Haswell multicore CPU with 24 physical cores with 64 GB main memory and a singlesocket Intel Skylake processor containing 22 cores. The first multicore CPU hosts two accelerators, an Nvidia K40c GPU and an Intel Xeon Phi 3120P. The second multicore CPU hosts an Nvidia P100 PCIe GPU. Therefore, the hybrid application executing on this platform is modeled by four heterogeneous abstract processors, CPU_1, GPU_1, PHI_1, and GPU_2. CPU_1 comprises 22 (out of a total of 24) CPU cores. GPU_1 symbolizes the Nvidia K40c GPU and a host CPU core connected to this GPU via a dedicated PCI-E link. PHI_1 symbolizes the Intel Xeon Phi and a host CPU core connected to this Xeon Phi processor via a dedicated PCI-E link. The Nvidia P100 PCIe GPU and a host CPU core connected to this GPU via a dedicated PCI-E link are denoted by GPU_2.
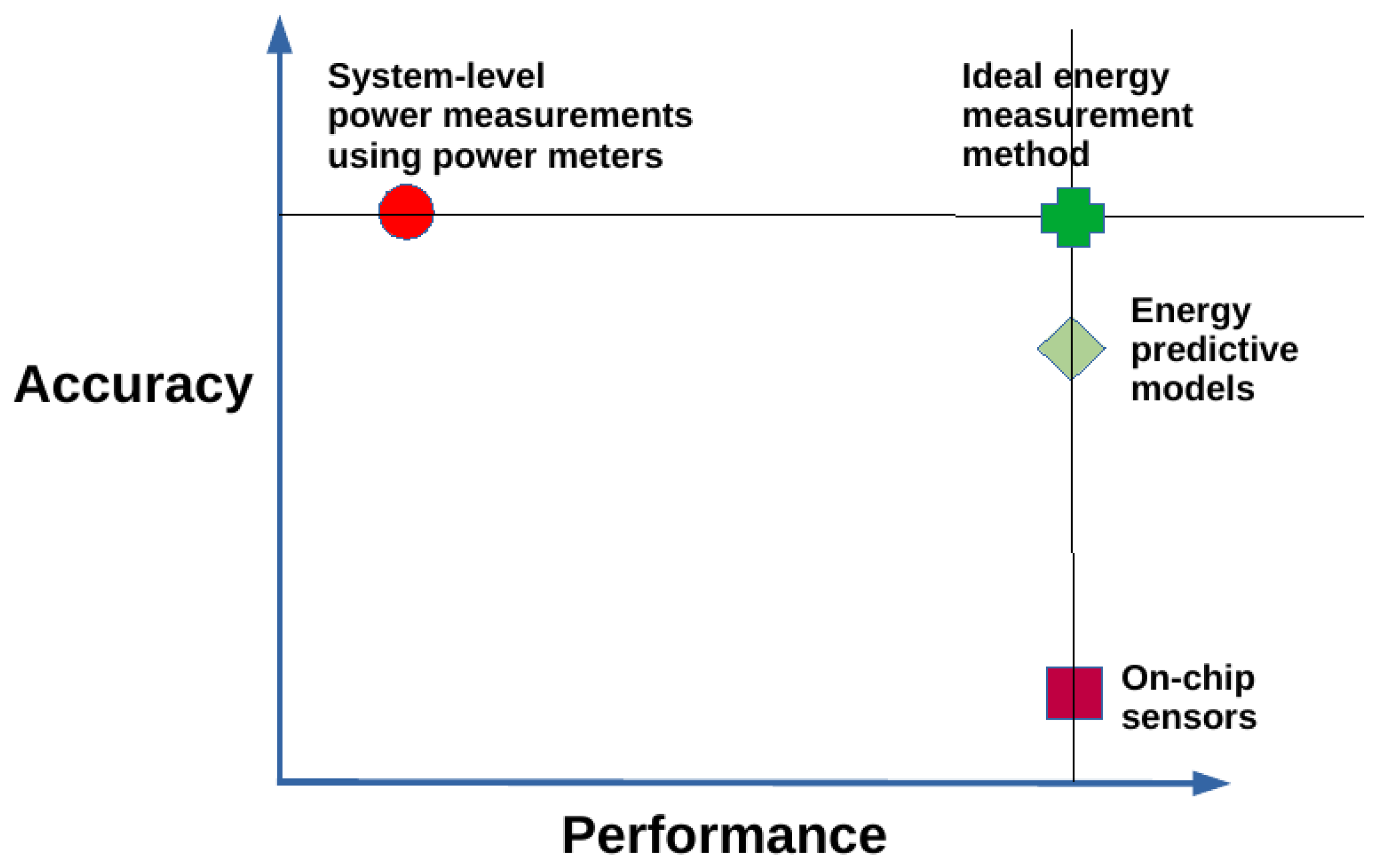
Then, the computational kernels’ performance and dynamic energy profiles are built offline using a methodology based on processor clocks and system-level power measurements provided by external power meters (ground-truth method).
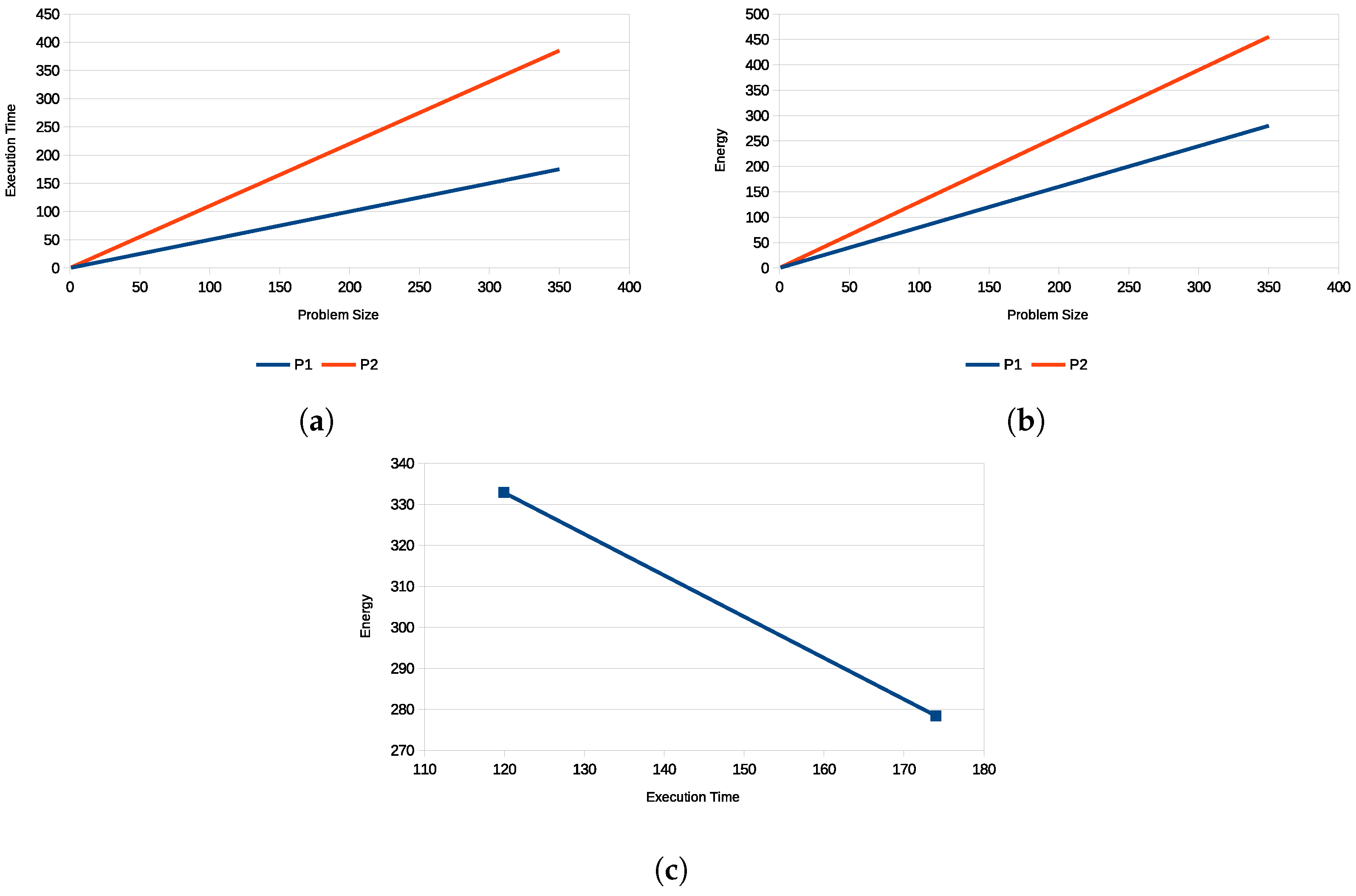
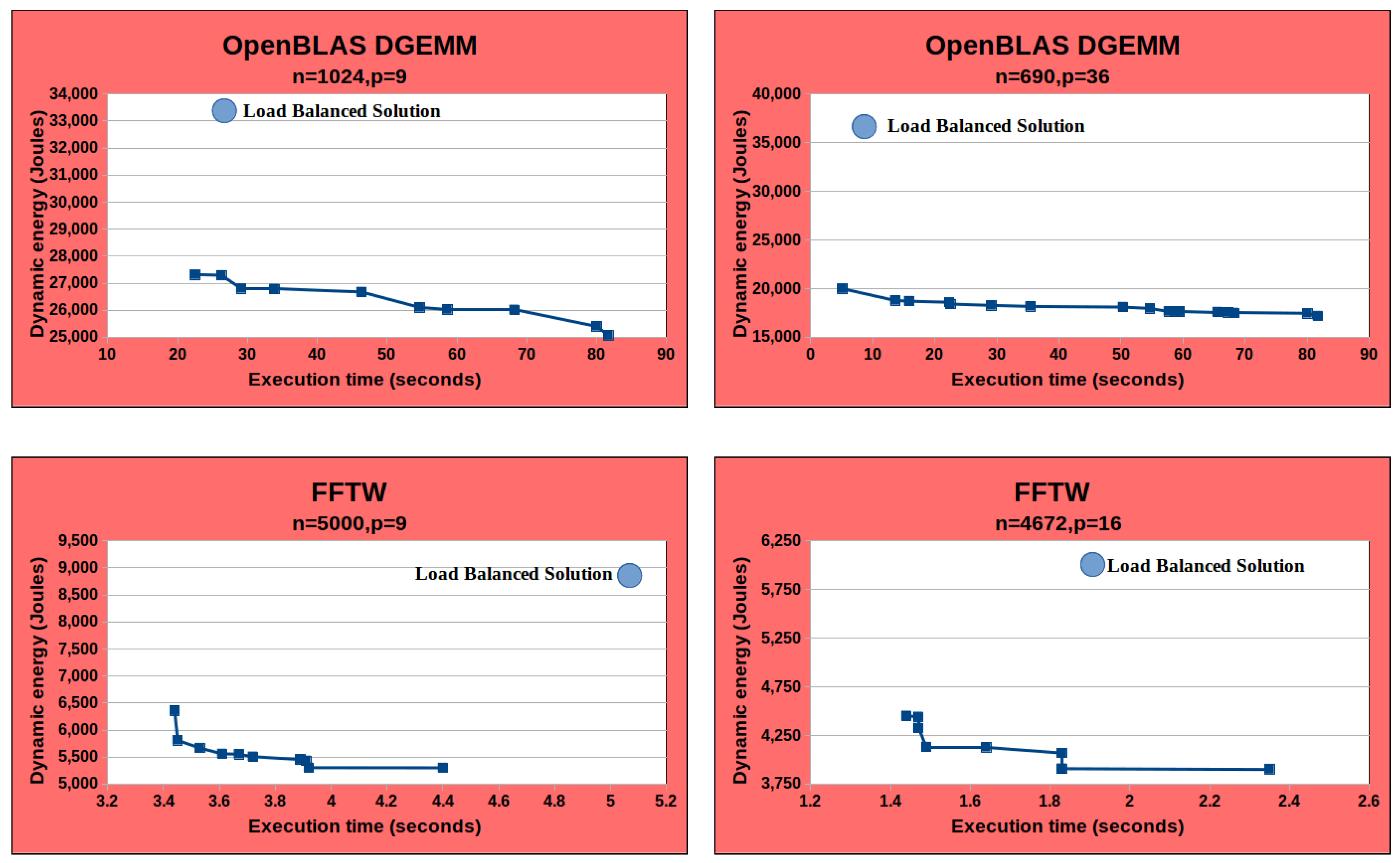
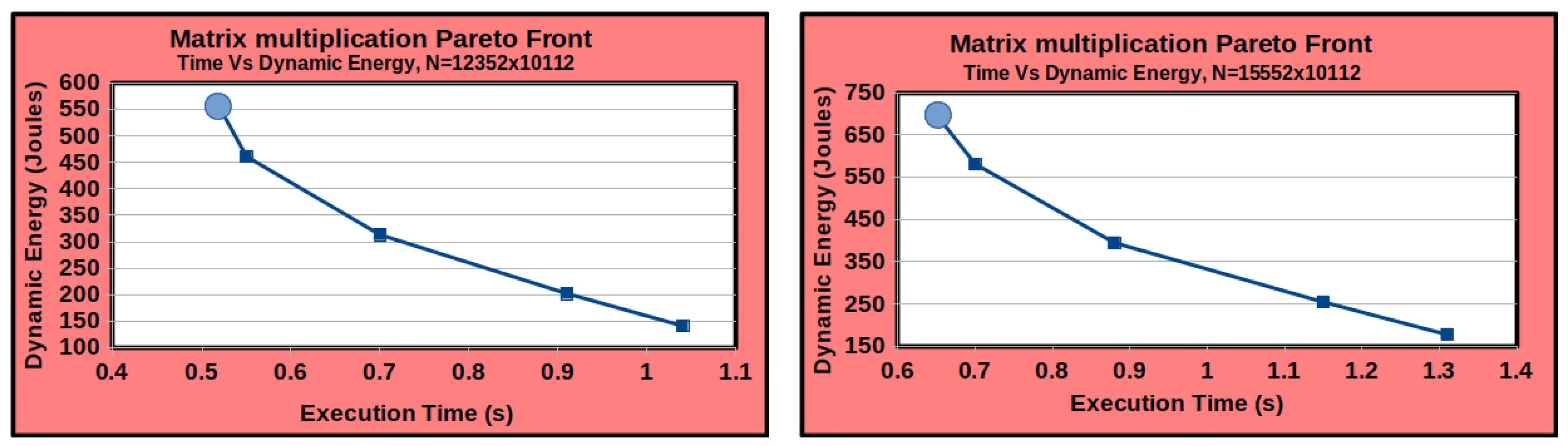
Finally, given the performance or dynamic energy profiles or both, a data-partitioning algorithm solves the single-objective optimization problems for performance or energy or the bi-objective optimization problem for energy and performance to determine the Pareto-optimal solutions (workload distributions), minimizing the execution time and the energy consumption of computations during the parallel execution of the application.
However, two issues hinder the scaling of the proposed optimization methods. We will highlight the issues using as an example the solution method [
13] solving the bi-objective optimization problem for energy and performance on
p non-linear heterogeneous processors.
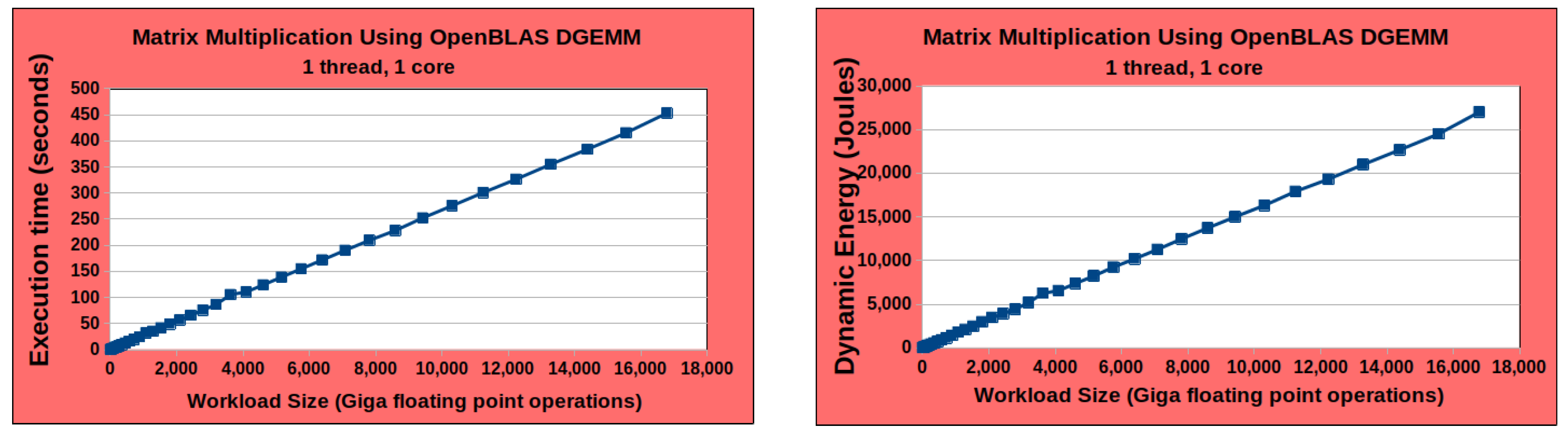
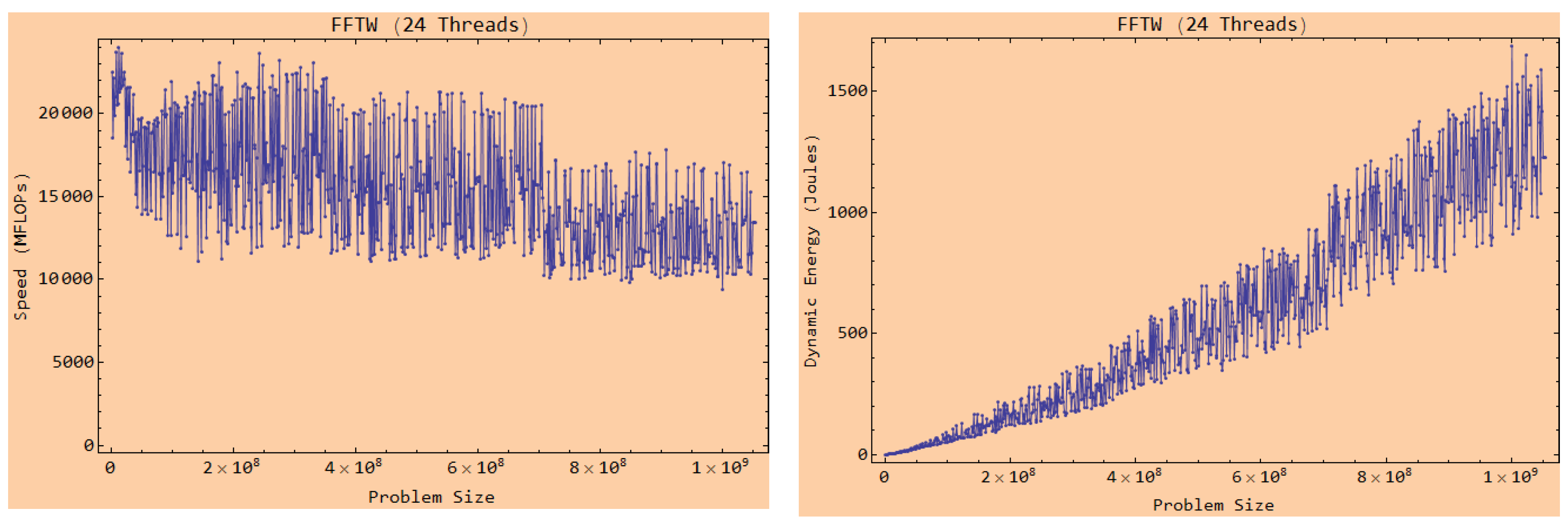
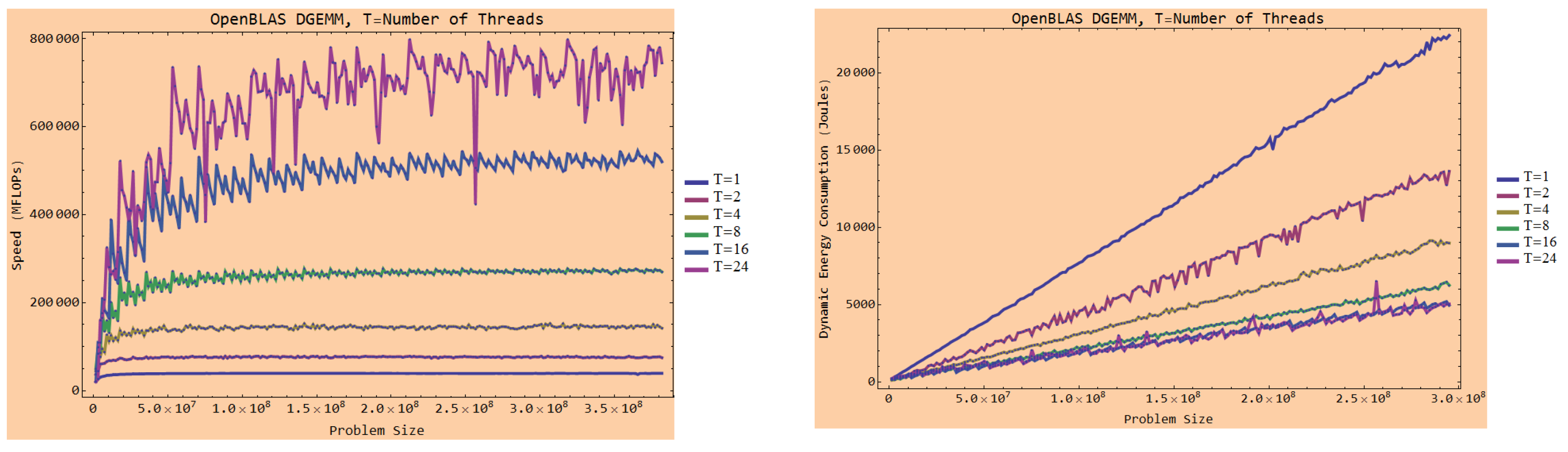
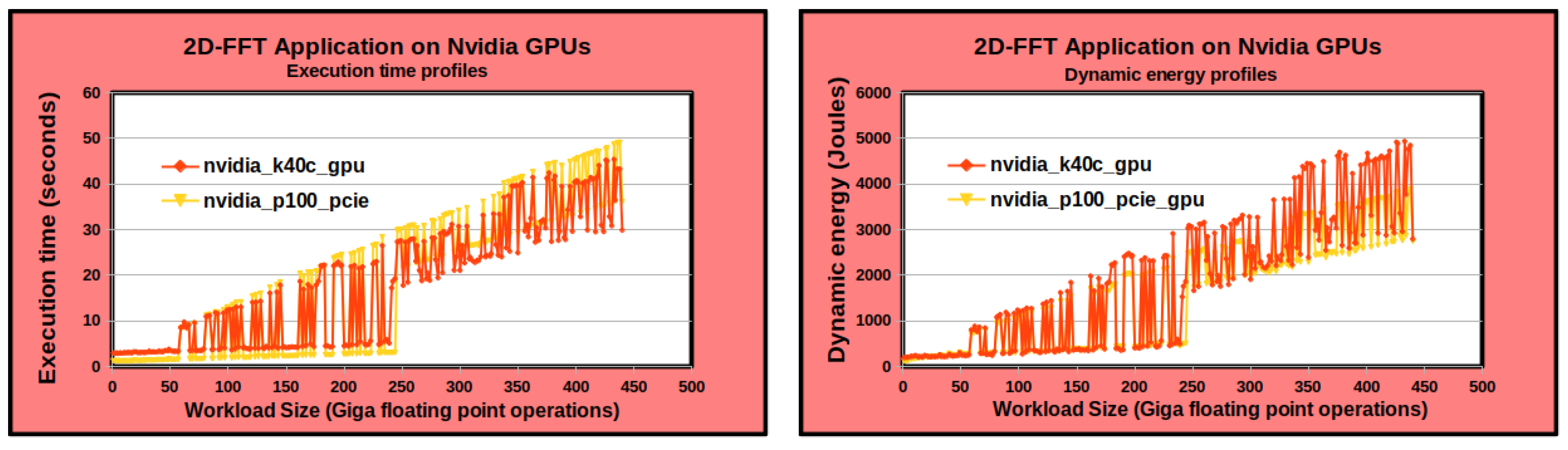
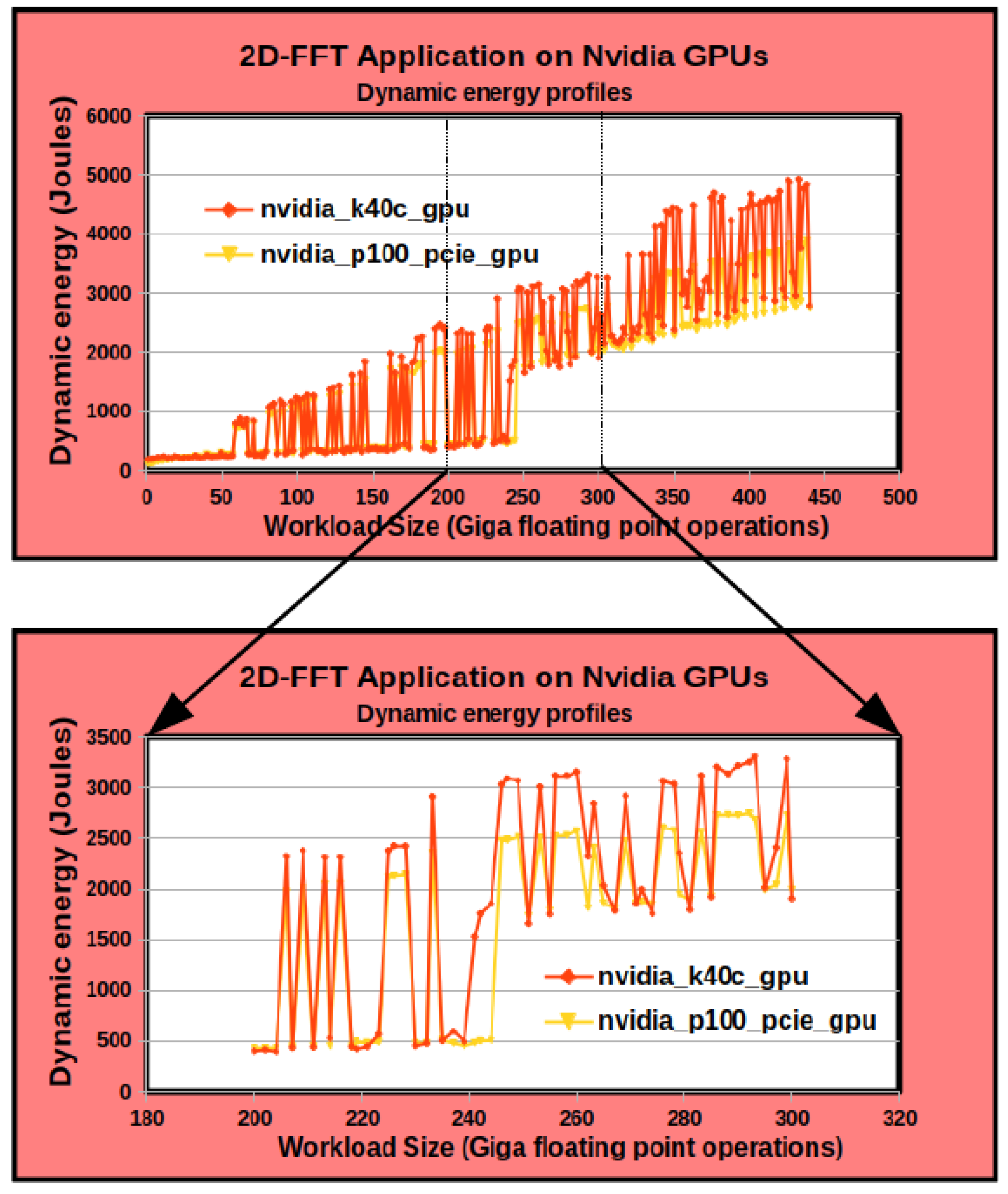
First, constructing the performance and dynamic energy profiles by employing system-level power measurements provided by external power meters (
ground-truth method) is sequential and expensive. The execution times of constructing the discrete performance and dynamic energy profiles comprising 210 and 256 workload sizes for the two applications, DGEMM and 2D-FFT, are 8 h and 14 h, respectively. The construction procedure is run on the Intel Skylake processor (
Figure 1). Briefly, while the ground-truth method exhibits the highest accuracy, it is also the most expensive [
8]. In addition, it cannot be employed in dynamic environments (HPC platforms and data centers) containing nodes not equipped with power meters.
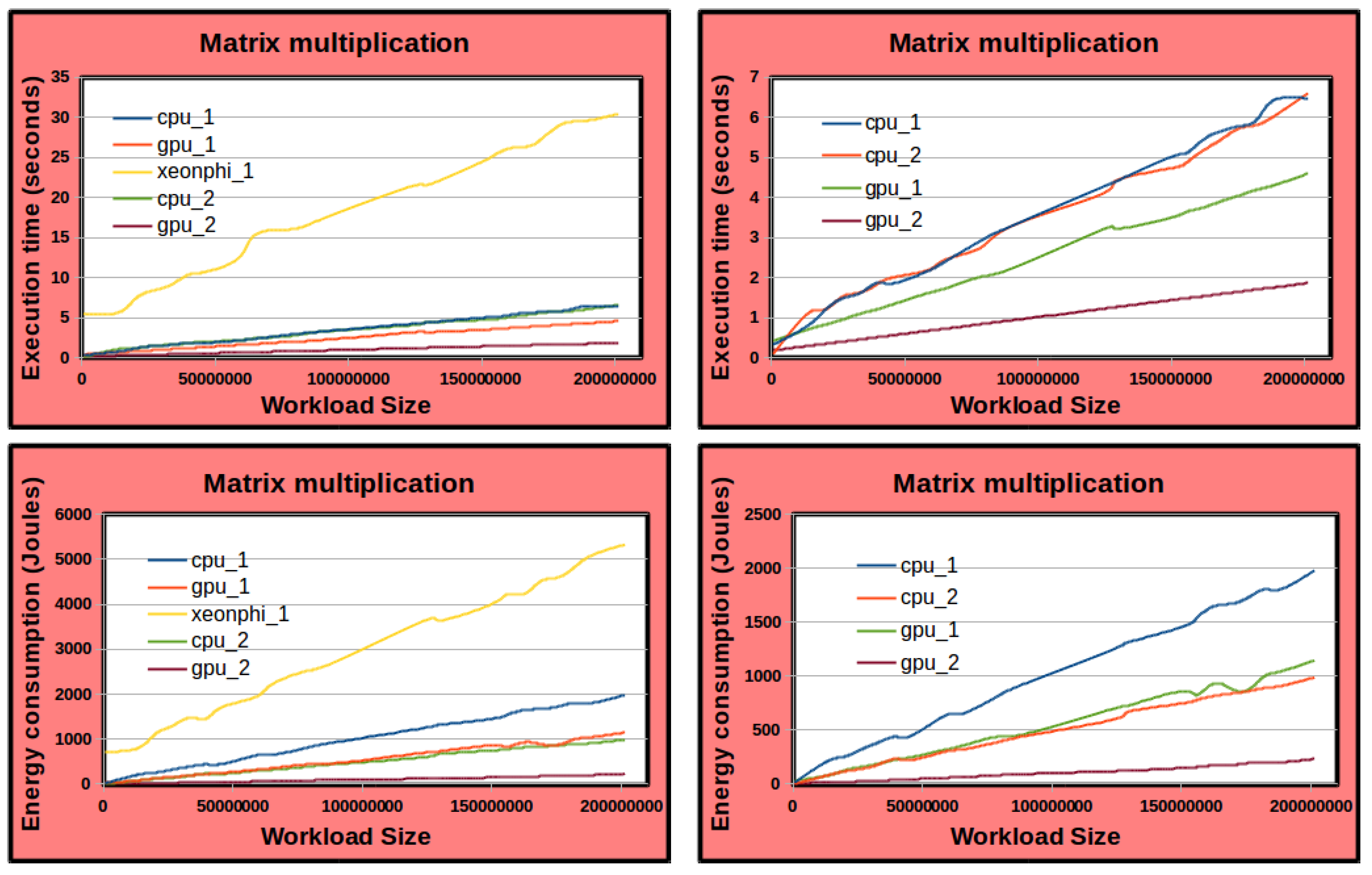
Second, the data-partitioning algorithm is
sequential and takes exorbitant execution times for even moderate values of
p. For example, consider its execution times for HEPOPTA [
13] solving the bi-objective optimization problem for two scientific data-parallel applications, matrix multiplication (DGEMM) and 2D fast Fourier transform (2D-FFT), executed on the hybrid platform (
Figure 1). HEPOPTA is sequential and is executed using a single core of the Intel Skylake multicore processor. For the DGEMM application, the data-partitioning algorithm’s execution time ranges from 4 s to 6 h for values of
p varying from 12 to 192. For the 2D-FFT application, the execution time increases from 16 s to 16 h for values of
p, going from 12 to 192.
Therefore, there are three crucial challenges to accelerating and scaling optimization methods on modern heterogeneous HPC platforms:
Acceleration of the sequential optimization algorithms allowing fast runtime computation of Pareto-optimal solutions optimizing the application for performance and energy.
Software energy sensors for multicore CPUs and accelerators that are implemented using energy-predictive models employing model variables that are highly additive and satisfying energy conservation laws and based on statistical tests such as high positive correlation.
Fast runtime construction of performance and dynamic energy profiles using the software energy sensors.
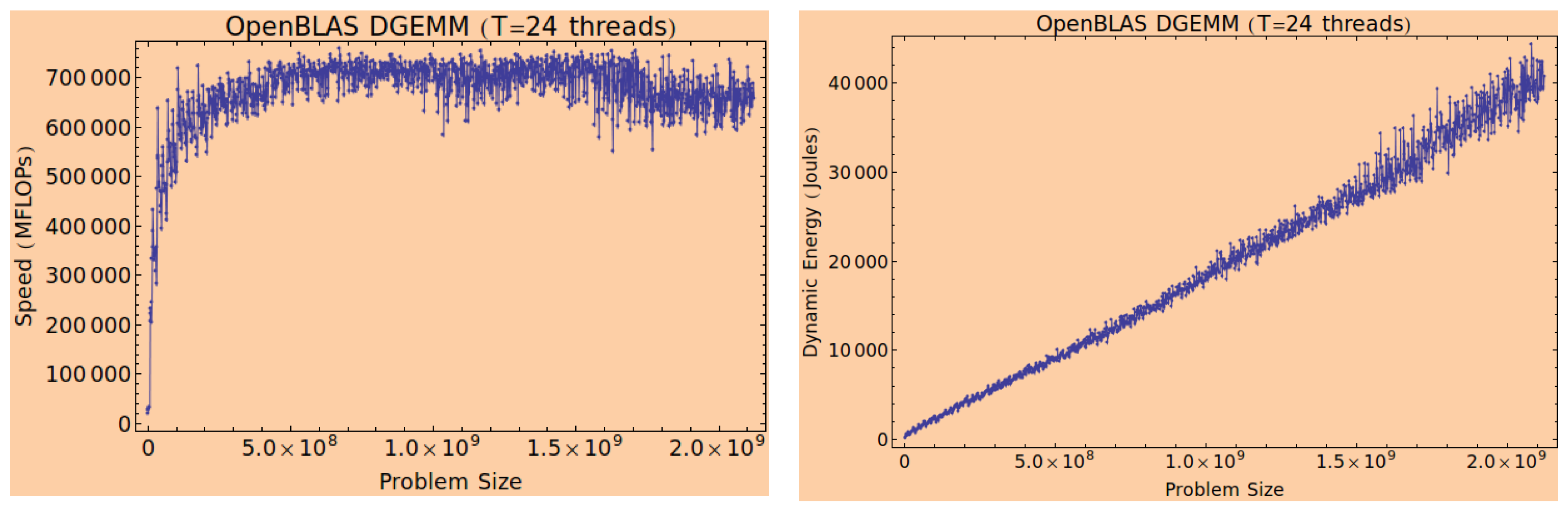
All three challenges are open problems. However, good progress has been made toward developing software energy sensors for multicore CPUs. For example, the software energy sensor for the Intel multicore CPU can be implemented using a linear energypredictive model based on resource utilization variables and performance monitoring counters (PMCs) that have shown 10-20% accuracy for popular scientific kernels.
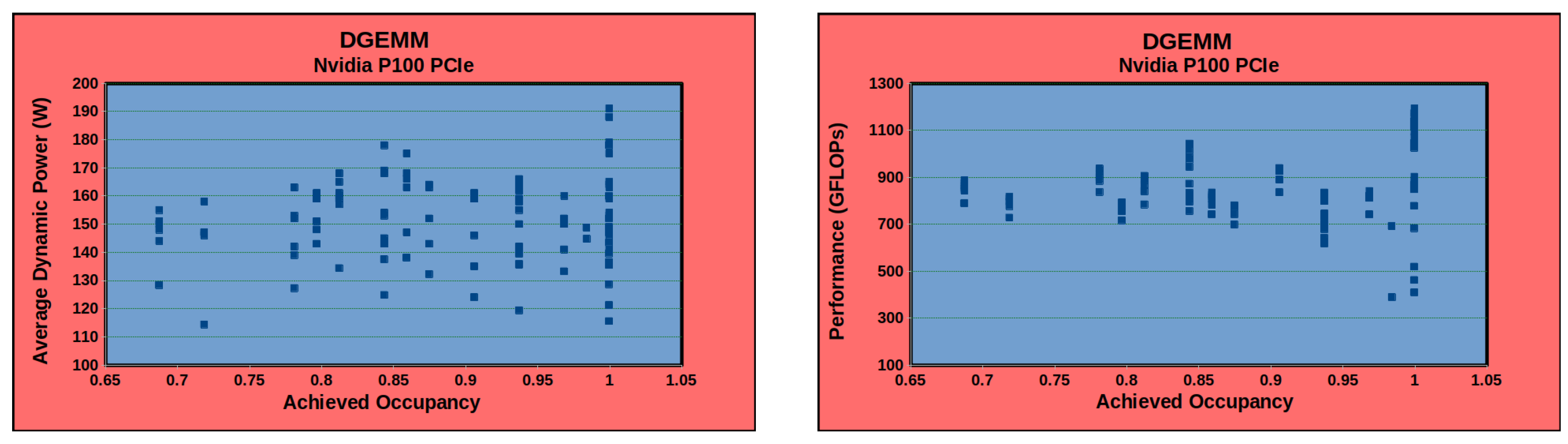
Older generations of Nvidia GPUs (
Figure 1) were poorly instrumented for runtime energy modeling. However, the latest generation of GPUs, such as Nvidia A40 (
Table 1), provide better energy instrumentation support to facilitate the accurate runtime modeling of energy consumption.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











