
Adaptive Kernel Graph Nonnegative Matrix Factorization


Abstract
:1. Introduction
- (1)
- We performed learning using an optimal graph that most closely approximates the initial kernel matrix, and attempted to preserve the sample’s similarity. This adaptive strategy can better accomplish manifold structure learning.
- (2)
- Both the similarity matrix of graphs and the decomposition matrix from the high-dimensional nonlinear mapping features of the original data can be learned in the proposed model. All variables are reciprocally updated in an alternating iterative optimization algorithm, and we simultaneously obtained similarity information and valid feature representation.
- (3)
- Our method takes non-linear mapping into consideration, meaning it is more capable of handling both linear and non-linear data. Instead of using the previous constructed and fixed graph-regularization term, the adaptively learned similarity preserves the ideal local geometry structure for feature representation. Moreover, the kernel matrix itself contains global similarity information of data points; hence, it is feasible to conserve the overall relations by learning the graph close to the kernel.
- (4)
- Comprehensive experiments were conducted on both synthetic and real-world datasets to exhibit the effectiveness of the proposed algorithms and demonstrate their superiority.
2. Related Work
2.1. Graph-Regularized Nonnegative Matrix Factorization
2.2. Graph Learning
3. Adaptive Kernel Graph Nonnegative Matrix Factorization
3.1. Kernel Nonnegative Matrix Factorization Review
3.2. Adaptive Kernel Graph Nonnegative Matrix Factorization
3.3. Optimization
3.3.1. Update and
3.3.2. Update Given and
| Algorithm 1 Adaptive kernel graph nonnegative matrix factorization (AKGNMF). |
|
3.4. Convergence Analysis
3.5. Complexity
4. Experiment
4.1. Datasets and the Evaluation Metrics
4.2. Comparison Methods
- K-means [51]. The most famous and commonly used clustering algorithm is based on Euclidean distance. It is widely used among all clustering algorithms because of its simplicity and efficiency.
- Nonnegative matrix factorization (NMF) [21]. As a classical multivariate analysis method, it incorporates extra constraints, such as locality, which can be shown to improve decomposition performance, while identifying better local features or providing a more sparse representation.
- Graph-regularized nonnegative matrix factorization (GNMF) [22]. In this method, an affinity graph is constructed to encode the geometric information and provide greater discriminating power than with the standard NMF algorithm.
- Kernel-based nonnegative spectral clustering methods KNSC-Ncut and KNSC-Rcut [23]. The kernel matrix under the kernel-based NMF multiplicative update rules refers to the nonlinear graph affinity matrix in Ncut and Rcut spectral clustering.
- Clustering with adaptive neighbor (CAN) [34]. Based on adaptive local structure learning, CAN constructs the classic similarity graph.
- Kernel-based orthogonal graph-regularized NMF (KOGNMF) [23]. By incorporating the graph constraint into the nonlinear NMF framework, this method formulates kernel-based graph-regularized orthogonal nonnegative matrix factorization.
- Clustering with similarity preserving (SPC) [8]. Single kernel learning based on similarity-preserving clustering methods.
- AKGNMF. Our proposed non-negative matrix-factorization method explores the graph’s structure in the nonlinear feature space, and the similarity matrix is automatically learned from the nonlinear mapping data. The similarity matrix can be learned jointly with matrix decomposition.
4.3. Results
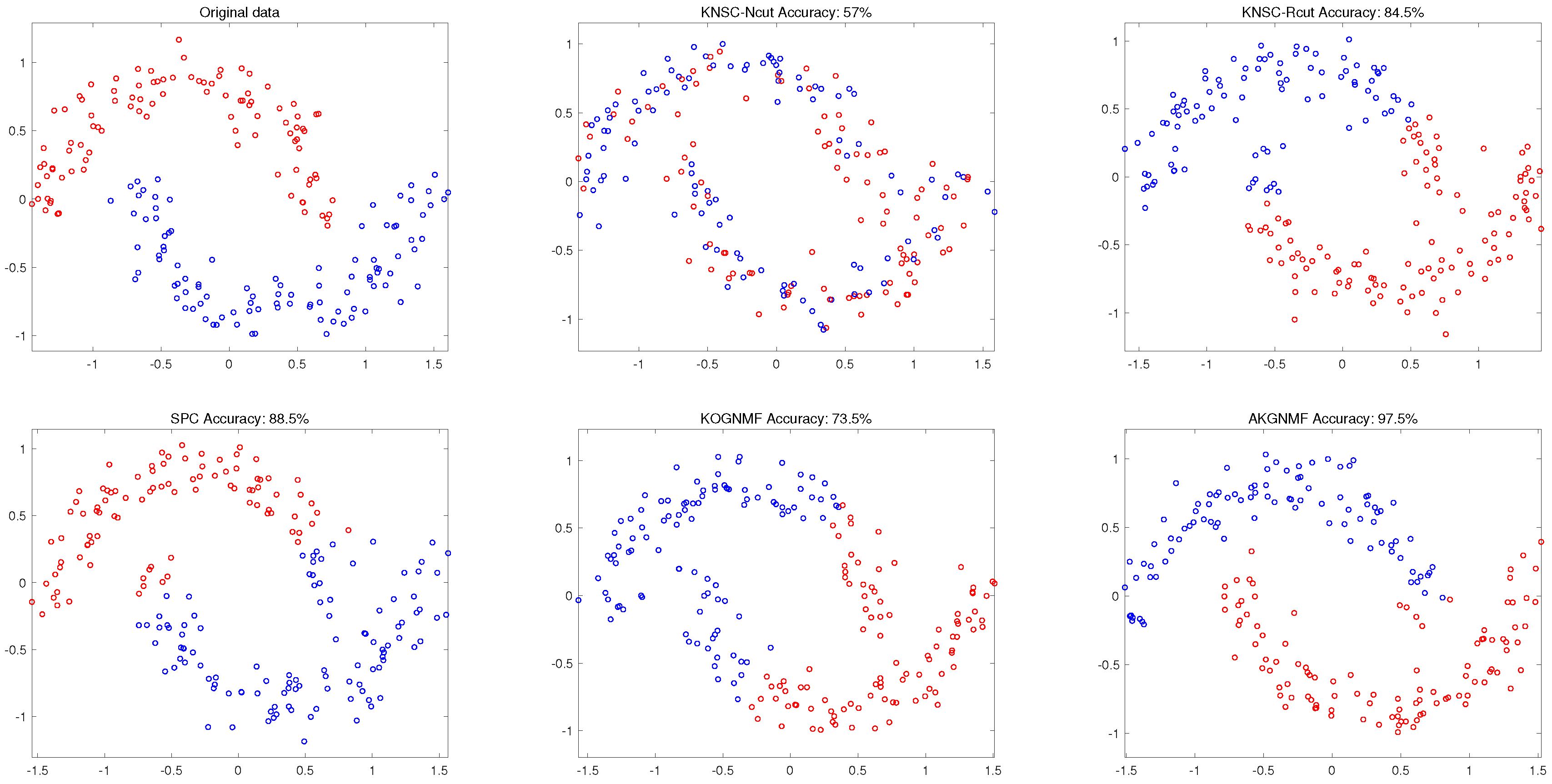
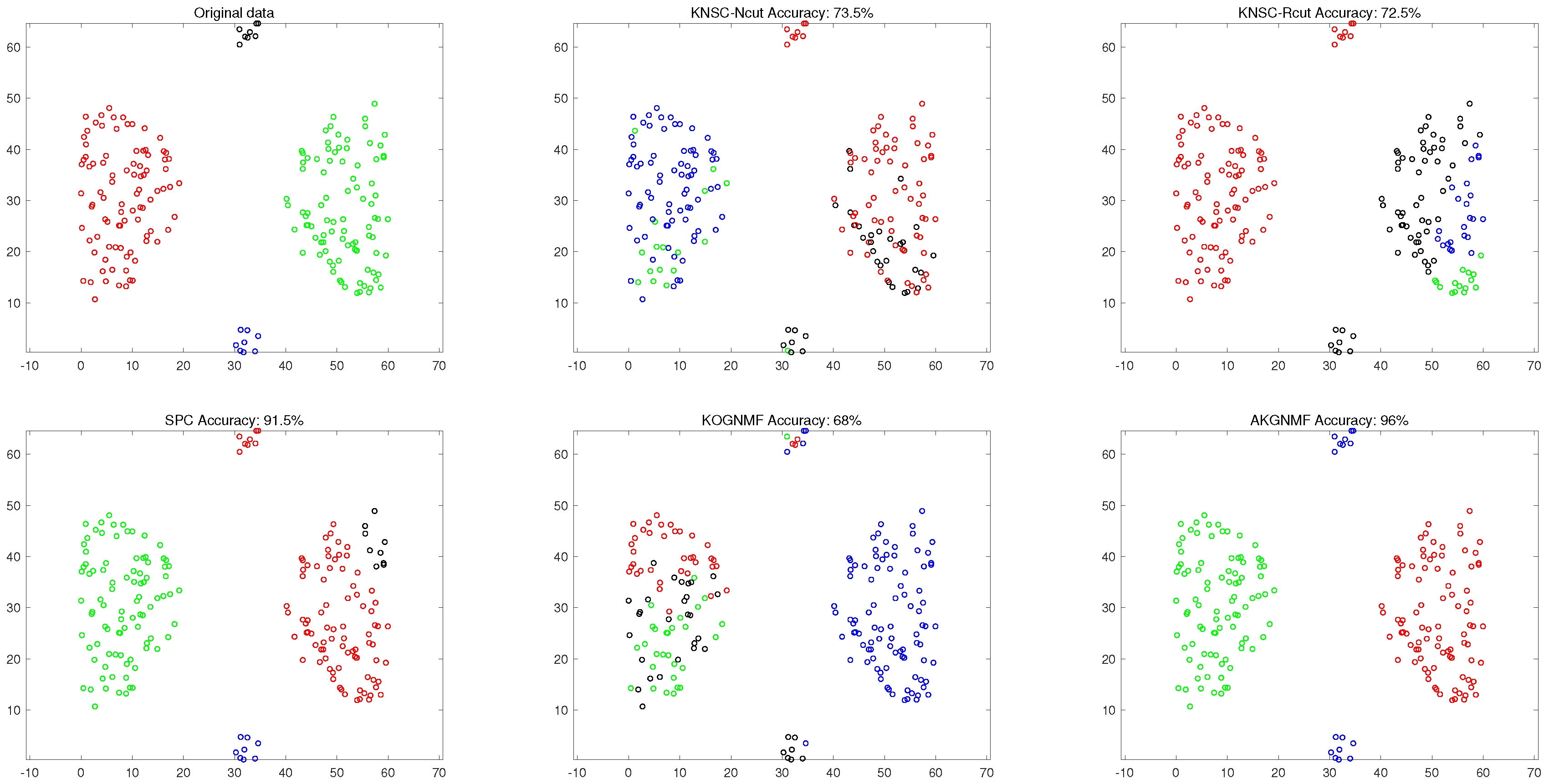
4.3.1. Clustering Results on Synthetic Data
4.3.2. Clustering Results on Real Data
- (1)
- In all the experiments except that with the JAFFE dataset, AKGNMF performed better than the other NMF-based and graph-based clustering approaches. For the JAFFE dataset, AKGNMF also presented competitive clustering accuracy.
- (2)
- For NMF and GNMF, the accuracy of AKGNMF on the Glass dataset increased by 39.72% and 15.42%, respectively. Accuracy also improves by 45.48% and 28.94% for the TDT2 dataset. Hence, this demonstrates the ability of graph learning to adaptively capture structural information.
- (3)
- With respect to k-means and the recently proposed kernel-based non-negative spectral clustering methods KNSC-Ncut and KNSC-Rcut, the improvement is promising. When comparing these three methods, the accuracy of AKGNMF for all datasets was found to be the highest.
- (4)
- Instead of directly constructing linear graph adjacency matrix in KOGNMF, AKGNMF obtains the optimal similarity matrix in the same nonlinear feature space as matrix factorization. A better graph structure boosts the data-representation performance of KNMF, which leads to better clustering performance of the AKGNMF method. For example, compared with KOGNMF, in TDT2, Glass and YALE datasets, the best accuracy of AKGNMF was found to improved by 11.02%, 7% and 6.06%, respectively.
- (5)
- In terms of similarity preservation, CAN mainly focuses on local similarity, which may ignore global similarity and lead to suboptimal results. The global structural information obtained using the AKGNMF method from high-dimensional maps is more advantageous on most datasets. Compared with SPC, we learned the nonlinear graph structure combined with the inherent potential features of NMF, and considered both the kernelized input data and the factorized representation, thereby realizing better performance of the proposed method in clustering tasks. As the results show, the best performance of AKGNMF in the dermatology dataset was improved by 16.94%, 18.19%, and 16.40% in terms of accuracy, NMI, and purity metrics, respectively; and the average performance was improved by 11.62%, 14.59%, and 11.8%, respectively.
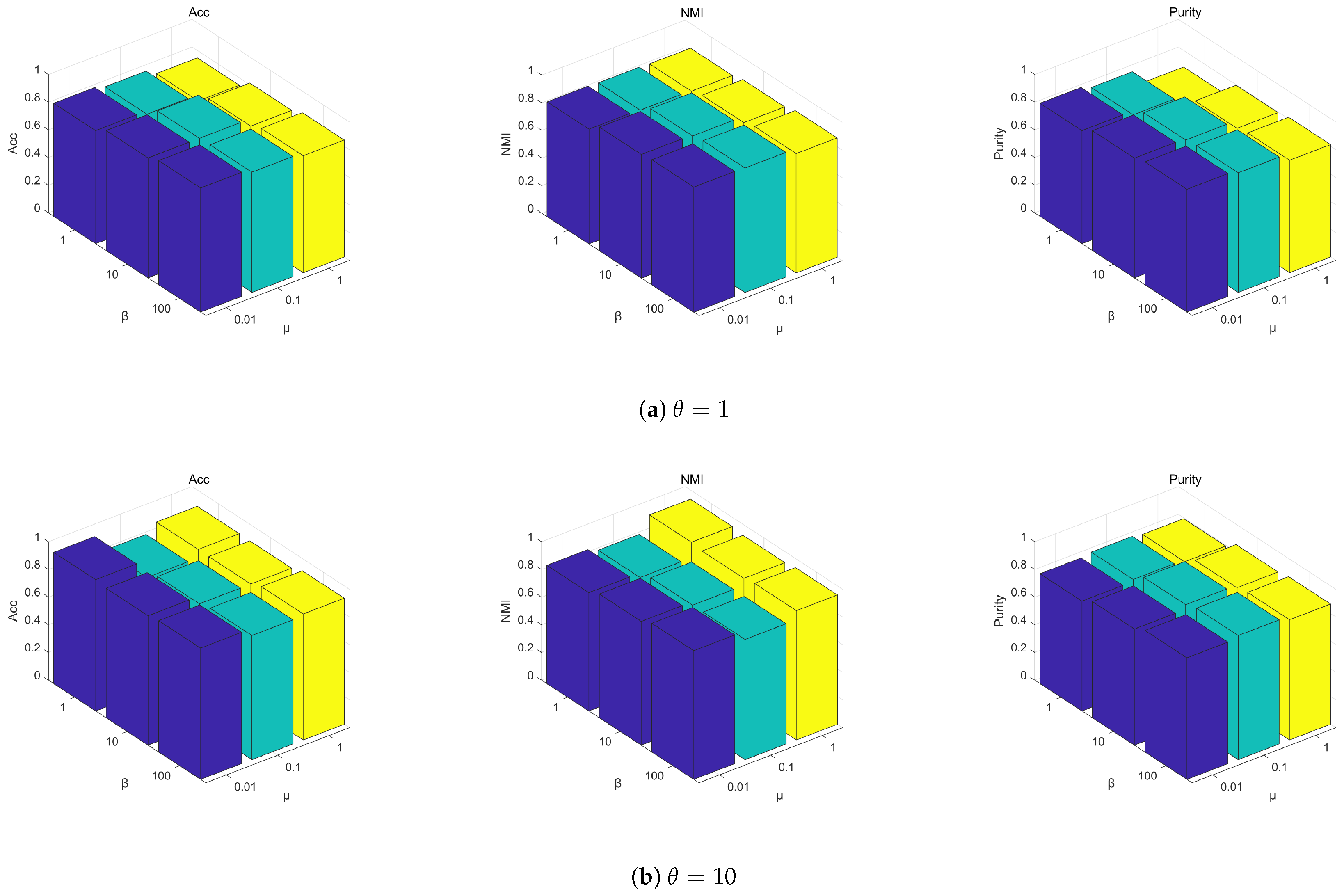
4.4. Parameter Analysis
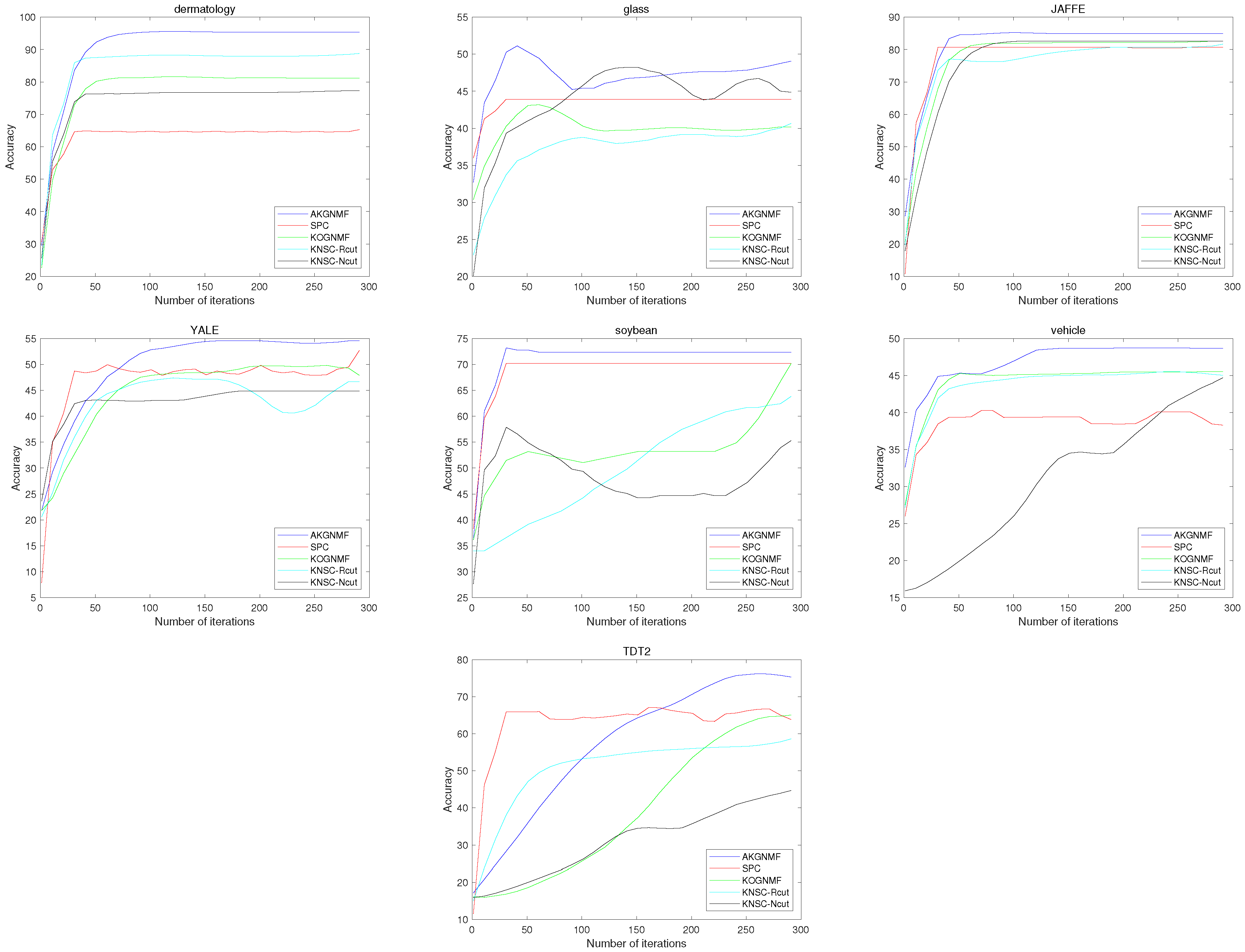
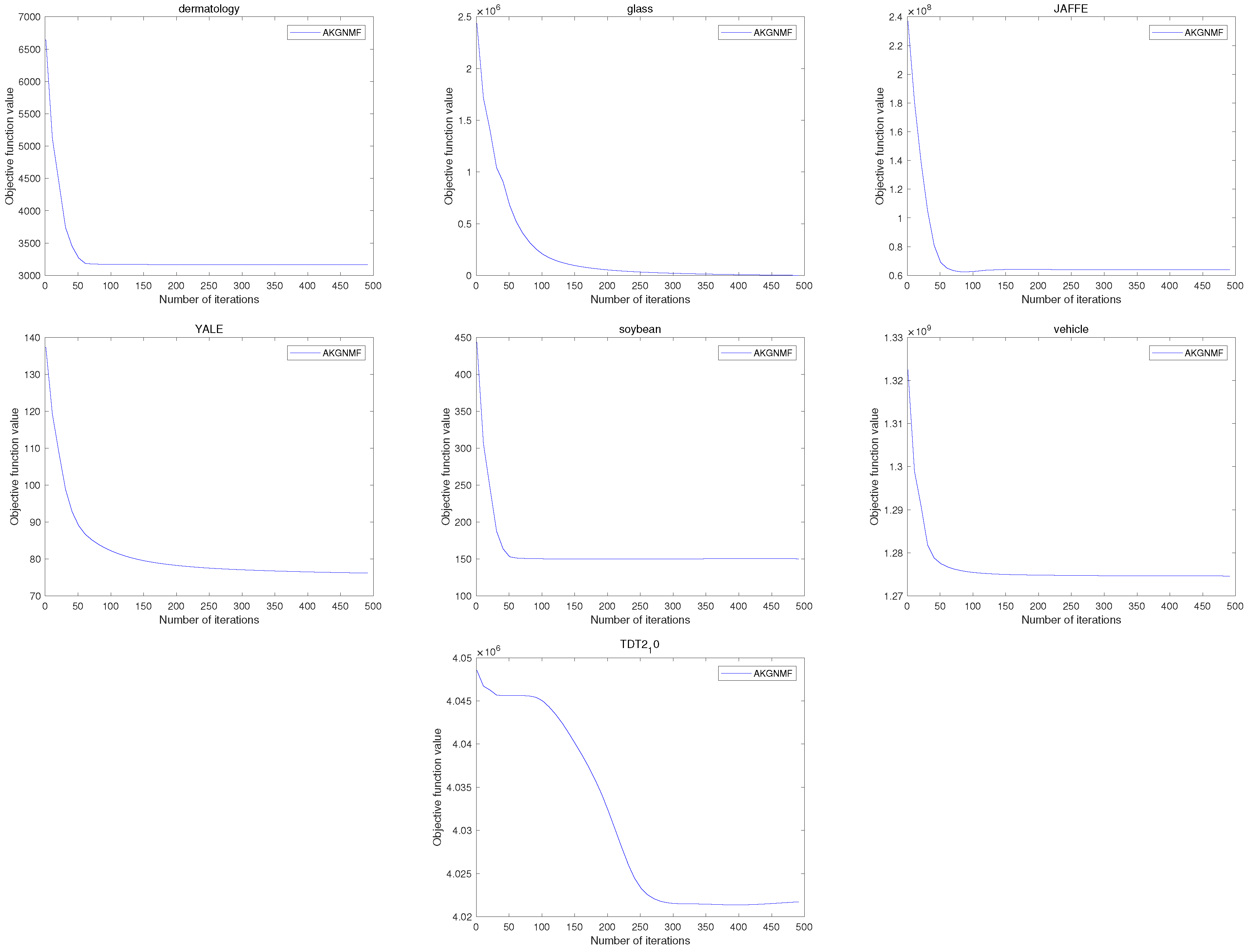
4.5. Convergence Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
References
- Li, X.; Cui, G.; Dong, Y. Graph Regularized Non-Negative Low-Rank Matrix Factorization for Image Clustering. IEEE Trans. Cybern. 2016, 47, 3840–3853. [Google Scholar] [CrossRef] [PubMed]
- Ye, R.; Li, X. Compact Structure Hashing via Sparse and Similarity Preserving Embedding. IEEE Trans. Cybern. 2015, 46, 718–729. [Google Scholar] [CrossRef]
- Fang, X.; Xu, Y.; Li, X.; Fan, Z.; Liu, H.; Chen, Y. Locality and Similarity Preserving Embedding for Feature Selection. Neurocomputing 2014, 128, 304–315. [Google Scholar] [CrossRef]
- Yang, Y.; Shen, H.; Nie, F.; Ji, R.; Zhou, X. Nonnegative Spectral Clustering with Discriminative Regularization. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; Volume 25, pp. 555–560. [Google Scholar]
- Peng, C.; Kang, Z.; Cai, S.; Cheng, Q. Integrate and Conquer: Double-Sided Two-Dimensional k-Means via Integrating of Projection and Manifold Construction. ACM Trans. Intell. Syst. Technol. (TIST) 2018, 9, 1–25. [Google Scholar] [CrossRef]
- Elkan, C. Using the Triangle Inequality to Accelerate k-Means. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 147–153. [Google Scholar]
- Hou, C.; Nie, F.; Yi, D.; Tao, D. Discriminative Embedded Clustering: A Framework for Grouping High-Dimensional Data. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1287–1299. [Google Scholar] [PubMed]
- Kang, Z.; Xu, H.; Wang, B.; Zhu, H.; Xu, Z. Clustering With Similarity Preserving. Neurocomputing 2019, 365, 211–218. [Google Scholar] [CrossRef] [Green Version]
- Kang, Z.; Lu, Y.; Su, Y.; Li, C.; Xu, Z. Similarity Learning via Kernel Preserving Embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4057–4064. [Google Scholar]
- Zeng, K.; Yu, J.; Li, C.; You, J.; Jin, T. Image Clustering by Hyper-Graph Regularized Non-Negative Matrix Factorization. Neurocomputing 2014, 138, 209–217. [Google Scholar] [CrossRef]
- Lu, Y.; Lai, Z.; Xu, Y.; You, J.; Li, X.; Yuan, C. Projective Robust Nonnegative Factorization. Inf. Sci. 2016, 364, 16–32. [Google Scholar] [CrossRef]
- Maisog, J.M.; DeMarco, A.T.; Devarajan, K.; Young, S.; Fogel, P.; Luta, G. Assessing Methods for Evaluating the Number of Components in Non-Negative Matrix Factorization. Mathematics 2021, 9, 2840. [Google Scholar] [CrossRef]
- Turk, M.; Pentland, A. Eigenfaces for Recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Oja, E. Independent Component Analysis: Algorithms and Applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dunteman, G.H. Principal Components Analysis; Sage: Newbury Park, CA, USA, 1989; Number 69. [Google Scholar]
- Liu, W.; Zheng, N. Non-Negative Matrix Factorization Based Methods for Object Recognition. Pattern Recognit. Lett. 2004, 25, 893–897. [Google Scholar] [CrossRef]
- Févotte, C.; Idier, J. Algorithms for Nonnegative Matrix Factorization with the β-Divergence. Neural Comput. 2011, 23, 2421–2456. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P.; Sindhwani, V. Manifold Regularization: A Geometric Framework for Learning From Labeled and Unlabeled Examples. J. Mach. Learn. Res. 2006, 7, 2399–2434. [Google Scholar]
- Xu, Z.; King, I.; Lyu, M.R.T.; Jin, R. Discriminative Semi-supervised Feature Selection via Manifold Regularization. IEEE Trans. Neural Networks 2010, 21, 1033–1047. [Google Scholar] [PubMed]
- Huang, S.; Xu, Z.; Wang, F. Nonnegative Matrix Factorization With Adaptive Neighbors. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 486–493. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the Parts of Objects by Non-Negative Matrix Factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph Regularized Nonnegative Matrix Factorization for Data Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar]
- Tolić, D.; Antulov-Fantulin, N.; Kopriva, I. A Nonlinear Orthogonal Non-Negative Matrix Factorization Approach to Subspace Clustering. Pattern Recognit. 2018, 82, 40–55. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Nie, F.; Huang, H. A New Simplex Sparse Learning Model to Measure Data Similarity for Clustering. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Kang, Z.; Peng, C.; Cheng, Q.; Xu, Z. Unified Spectral Clustering With Optimal Graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Ge, H.; Song, A. A New Low-Rank Structurally Incoherent Algorithm for Robust Image Feature Extraction. Mathematics 2022, 10, 3648. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Q.; Du, B.; You, J.; Tao, D. Adaptive Manifold Regularized Matrix Factorization for Data Clustering. In Proceedings of the 6th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 9–25 August 2017; pp. 3399–3405. [Google Scholar]
- Peng, Y.; Long, Y.; Qin, F.; Kong, W.; Nie, F.; Cichocki, A. Flexible Non-Negative Matrix Factorization With Adaptively Learned Graph Regularization. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3107–3111. [Google Scholar] [CrossRef]
- Huang, S.; Xu, Z.; Kang, Z.; Ren, Y. Regularized Nonnegative Matrix Factorization With Adaptive Local Structure Learning. Neurocomputing 2020, 382, 196–209. [Google Scholar] [CrossRef]
- Yi, Y.; Wang, J.; Zhou, W.; Zheng, C.; Kong, J.; Qiao, S. Non-negative Matrix Factorization With Locality Constrained Adaptive Graph. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 427–441. [Google Scholar] [CrossRef]
- Chen, K.; Che, H.; Li, X.; Leung, M.F. Graph Non-Negative Matrix Factorization with Alternative Smoothed L0 Regularizations. Neural Comput. Appl. 2022, 1–15. [Google Scholar]
- Yang, X.; Che, H.; Leung, M.F.; Liu, C. Adaptive Graph Nonnegative Matrix Factorization With the Self-Paced Regularization. Appl. Intell. 2022, 1–18. [Google Scholar] [CrossRef]
- Paatero, P.; Tapper, U. Positive Matrix Factorization: A Non-Negative Factor Model With Optimal Utilization of Error Estimates of Data Values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Nie, F.; Wang, X.; Huang, H. Clustering and Projected Clustering with Adaptive Neighbors. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; KDD ’14. pp. 977–986. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, S.; Hu, R.; Zhu, Y.; Song, J. Local and Global Structure Preservation for Robust Unsupervised Spectral Feature Selection. IEEE Trans. Knowl. Data Eng. 2017, 30, 517–529. [Google Scholar] [CrossRef]
- Ren, Z.; Sun, Q. Simultaneous Global and Local Graph Structure Preserving for Multiple Kernel Clustering. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 1839–1851. [Google Scholar] [CrossRef]
- Ding, C.H.; Li, T.; Jordan, M.I. Convex and Semi-Nonnegative Matrix Factorizations. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 45–55. [Google Scholar] [CrossRef] [Green Version]
- White, S.; Smyth, P. A Spectral Clustering Approach to Finding Communities in Graphs. In Proceedings of the 2005 SIAM International Conference on Data Mining, Newport Beach, CA, USA, 21–23 April 2005; pp. 274–285. [Google Scholar]
- He, X.; Niyogi, P. Locality Preserving Projections. Adv. Neural Inf. Process. Syst. 2004, 16, 153–160. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef] [Green Version]
- Cai, D.; Wang, X.; He, X. Probabilistic Dyadic Data Analysis With Local and Global Consistency. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 105–112. [Google Scholar]
- Huang, T.M.; Kecman, V.; Kopriva, I. Kernel Based Algorithms for Mining Huge Data Sets; Springer: Warsaw, Poland, 2006; Volume 1. [Google Scholar]
- Boyd, S.; Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Michalski, R.S. Learning by Being Told and Learning by Examples: An Experimental Comparison of the Two Methods of Knowledge Acquisition in the Context of Developing an Expert System for Soybean Disease Analysis. Int. J. Policy Anal. Inf. Syst. 1980, 4, 125–161. [Google Scholar]
- Güvenir, H.A.; Demiröz, G.; Ilter, N. Learning Differential Diagnosis of Erythemato-Squamous Diseases Using Voting Feature Intervals. Artif. Intell. Med. 1998, 13, 147–165. [Google Scholar] [CrossRef] [Green Version]
- Evett, I.W.; Spiehler, E.J. Rule Induction in Forensic Science; Halsted Press: Pinner, UK, 1989; pp. 152–160. [Google Scholar]
- Siebert, J.P. Vehicle Recognition Using Rule Based Methods; Turing Institute: Glasgow, Scotland, 1987. [Google Scholar]
- Cai, D.; He, X.; Han, J. Locally Consistent Concept Factorization for Document Clustering. IEEE Trans. Knowl. Data Eng. 2010, 23, 902–913. [Google Scholar] [CrossRef] [Green Version]
- Georghiades, A.S.; Belhumeur, P.N.; Kriegman, D.J. From Few to Many: Illumination Cone Models for Face Recognition Under Variable Lighting and Pose. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 643–660. [Google Scholar] [CrossRef] [Green Version]
- Lyons, M.J.; Kamachi, M.; Gyoba, J. Coding Facial Expressions With Gabor Wavelets (IVC Special Issue). arXiv 2020, arXiv:2009.05938. [Google Scholar]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Lee, D.; Seung, H.S. Algorithms for Non-negative Matrix Factorization. In Proceedings of the 14th Annual Neural Information Processing Systems Conference, Denver, CO, USA, 27 November–2 December 2000; pp. 556–562. [Google Scholar]
- Hoyer, P.O. Non-Negative Sparse Coding. In Proceedings of the 12th IEEE Workshop on Neural Networks for Signal Processing, Martigny, Switzerland, 4–6 September 2002; pp. 557–565. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Definition |
|---|---|
| m | the dimensionality of a dataset |
| n | the number of data points |
| c | the number of clusters |
| the kernel matrix | |
| the input data matrix | |
| the graph Laplacian matrix | |
| the nonlinear mapping function | |
| the basis matrix in input space | |
| the cluster indicator matrices | |
| the basis matrix in mapped space | |
| the all-one column vector | |
| the identity matrix | |
| the similarity matrix | |
| Tr(·) | the trace operator of a matrix |
| the Frobenius norm |
| Datasets | Instances | Features | Classes |
|---|---|---|---|
| Soybean | 47 | 35 | 4 |
| Dermatology | 366 | 33 | 6 |
| Glass | 214 | 10 | 6 |
| Vehicle | 846 | 18 | 4 |
| YALE | 165 | 1024 | 15 |
| JAFFE | 213 | 676 | 10 |
| TDT2 | 653 | 36,771 | 10 |
| Methods | Complexity | Methods | Complexity |
|---|---|---|---|
| K-means | NMF | ||
| GNMF | CAN | ||
| KNSC-RCut | KNSC-NCut | ||
| KOGNMF | SPC | ||
| AKGNMF |
| Datasets | Kmeans | NMF | GNMF | CAN | KNSC-RCut | KNSC-NCut | KOGNMF | SPC | AKGNMF |
|---|---|---|---|---|---|---|---|---|---|
| (a) Accuracy (%) | |||||||||
| Soybean | 72.34 | 72.34 | 89.36 | 74.46 | 100 (73.82) | 85.10 (72.02) | 100 (75.10) | 97.87 (76.59) | 100 (79.78) |
| Dermatology | 94.26 | 72.95 | 81.97 | 95.36 | 95.90 (84.04) | 93.44 (77.19) | 95.90 (85.64) | 80.60 (78.94) | 97.54 (90.56) |
| Glass | 54.21 | 22.42 | 46.72 | 51.40 | 52.80 (43.06) | 48.59 (46.98) | 55.14 (43.01) | 52.33 (45.46) | 62.14 (47.78) |
| Vehicle | 45.27 | 38.41 | 45.03 | 40.54 | 45.86 (45.48) | 43.97 (41.01) | 46.09 (45.75) | 40.30 (39.00) | 51.77 (47.28) |
| YALE | 38.18 | 42.42 | 50.30 | 42.42 | 61.21 (51.69) | 52.12 (45.66) | 58.18 (52.18) | 60.60 (53.12) | 64.24 (55.87) |
| JAFFE | 84.04 | 82.62 | 96.71 | 96.71 | 96.24 (84.27) | 93.42 (74.24) | 96.71 (84.88) | 97.65 (87.53) | 97.18 (87.46) |
| TDT2 | 50.38 | 41.19 | 57.73 | 14.24 | 80.55 (66.09) | 50.38 (48.95) | 75.65 (66.97) | 71.97 (70.82) | 86.67 (71.15) |
| (b) NMI (%) | |||||||||
| Soybean | 71.08 | 71.56 | 81.49 | 71.38 | 100 (71.30) | 76.02 (67.72) | 100 (72.90) | 73.67 (73.63) | 100 (77.28) |
| Dermatology | 89.47 | 82.30 | 85.31 | 91.18 | 91.79 (86.80) | 87.96 (84.51) | 92.33 (86.38) | 74.40 (71.41) | 92.59 (86.00) |
| Glass | 36.41 | 2.88 | 35.53 | 30.85 | 32.33 (27.87) | 27.76 (23.88) | 32.77 (29.15) | 33.07 (20.75) | 31.75 (22.41) |
| Vehicle | 18.14 | 10.60 | 17.25 | 15.52 | 18.86 (18.55) | 19.47 (15.36) | 19.71 (19.22) | 12.87 (12.57) | 20.91 (18.42) |
| YALE | 45.07 | 48.41 | 53.01 | 45.60 | 62.12 (55.21) | 54.16 (50.04) | 61.38 (55.65) | 58.62 (54.99) | 63.56 (58.89) |
| JAFFE | 88.13 | 85.03 | 96.23 | 96.23 | 95.52 (87.74) | 91.77 (79.53) | 96.23 (87.94) | 96.43 (91.81) | 96.23 (89.96) |
| TDT2 | 44.98 | 35.48 | 51.80 | 3.62 | 71.66 (60.75) | 46.66 (41.04) | 69.58 (61.00) | 74.16 (68.48) | 67.71 (61.30) |
| (c) Purity (%) | |||||||||
| Soybean | 78.72 | 78.72 | 89.36 | 78.72 | 100 (79.46) | 85.10 (76.38) | 100 (79.78) | 97.87 (76.59) | 100 (83.72) |
| Dermatology | 94.26 | 84.70 | 85.79 | 95.36 | 95.90 (91.07) | 93.44 (85.90) | 95.90 (91.17) | 81.14 (79.53) | 97.54 (91.33) |
| Glass | 58.41 | 38.78 | 53.27 | 54.20 | 60.74 (58.20) | 49.53 (47.71) | 61.21 (58.92) | 57.00 (46.23) | 65.31 (49.15) |
| Vehicle | 45.27 | 38.77 | 45.03 | 41.25 | 45.86 (45.48) | 46.80 (41.57) | 46.09 (45.75) | 40.30 (39.23) | 51.77 (47.28) |
| YALE | 40.00 | 44.24 | 52.12 | 44.24 | 61.81 (52.69) | 53.93 (47.66) | 58.78 (53.18) | 61.21 (54.63) | 64.84 (57.33) |
| JAFFE | 85.91 | 84.97 | 96.71 | 96.71 | 96.24 (86.94) | 93.42 (77.34) | 96.71 (86.90) | 97.65 (89.57) | 97.18 (89.38) |
| TDT2 | 52.67 | 43.95 | 58.80 | 14.85 | 80.55 (67.31) | 50.38 (50.17) | 75.80 (68.13) | 74.42 (72.62) | 86.67 (72.37) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, R.-Y.; Guo, Y.; Zhang, B. Adaptive Kernel Graph Nonnegative Matrix Factorization. Information 2023, 14, 208. https://doi.org/10.3390/info14040208
Li R-Y, Guo Y, Zhang B. Adaptive Kernel Graph Nonnegative Matrix Factorization. Information. 2023; 14(4):208. https://doi.org/10.3390/info14040208
Chicago/Turabian StyleLi, Rui-Yu, Yu Guo, and Bin Zhang. 2023. "Adaptive Kernel Graph Nonnegative Matrix Factorization" Information 14, no. 4: 208. https://doi.org/10.3390/info14040208