
A Thorough Reproducibility Study on Sentiment Classification: Methodology, Experimental Setting, Results


Abstract
:1. Introduction
- The main aim of [3] is to make a library of semantic similarity measures publicly available for the first time, together with a set of reproducible experiments whose aims are the exact replication of three experimental surveys. In addition, the authors propose a self-contained experimental platform which can be easily used for extensive experimentation, even with no software coding.
- In [4], the authors present a number of controllable environment settings that often go unreported, and illustrate that these are factors that can cause irreproducibility of results as presented in the literature. These environmental factors have an effect on the effectiveness of neural networks due to the non-convexity of the optimization surface.
- In the study proposed by [5], the focus is on the communication aspect, investigating students’ current understanding of reproducibility, whether they are able to communicate reproducible data analysis, and if not, what skills are missing and what types of training can be helpful. Training on reproducible data analysis should be an indispensable component in data science education.
- The authors of [6] review the extent and causes of the replication crisis in many areas of science, with a focus on issues relating to the use of null hypothesis significance as an evidentiary criterion. They also discuss alternative ways for analyzing data and present evidence for hypothesized effects. They also argue for improved openness and transparency in experimental research.
- In [7], the authors attempt a complete reproduction of five automatic malware detectors from the literature, and they discuss to what extent they are reproducible. In particular, they provide insights on the implications around the guesswork that may be required to finalize a working implementation.
- A survey of machine learning platforms with the aim of studying whether they provide features that simplify making experiments reproducible out-of-the-box [8] showed that none of the studied platforms support this feature set; moreover, the experiment reveals a statistically significant difference in results when the exact same experiment is conducted on different data sets.
- In [9], the authors propose a methodological approach that not only provides a replicable experimental analysis but also provides researchers with a workflow using existing tools that can be transposed to other domains with only little manual work.
2. Terminology for Reproducing Experiments
3. Case Study
3.1. Task: Fine-Grained Sentiment Classification
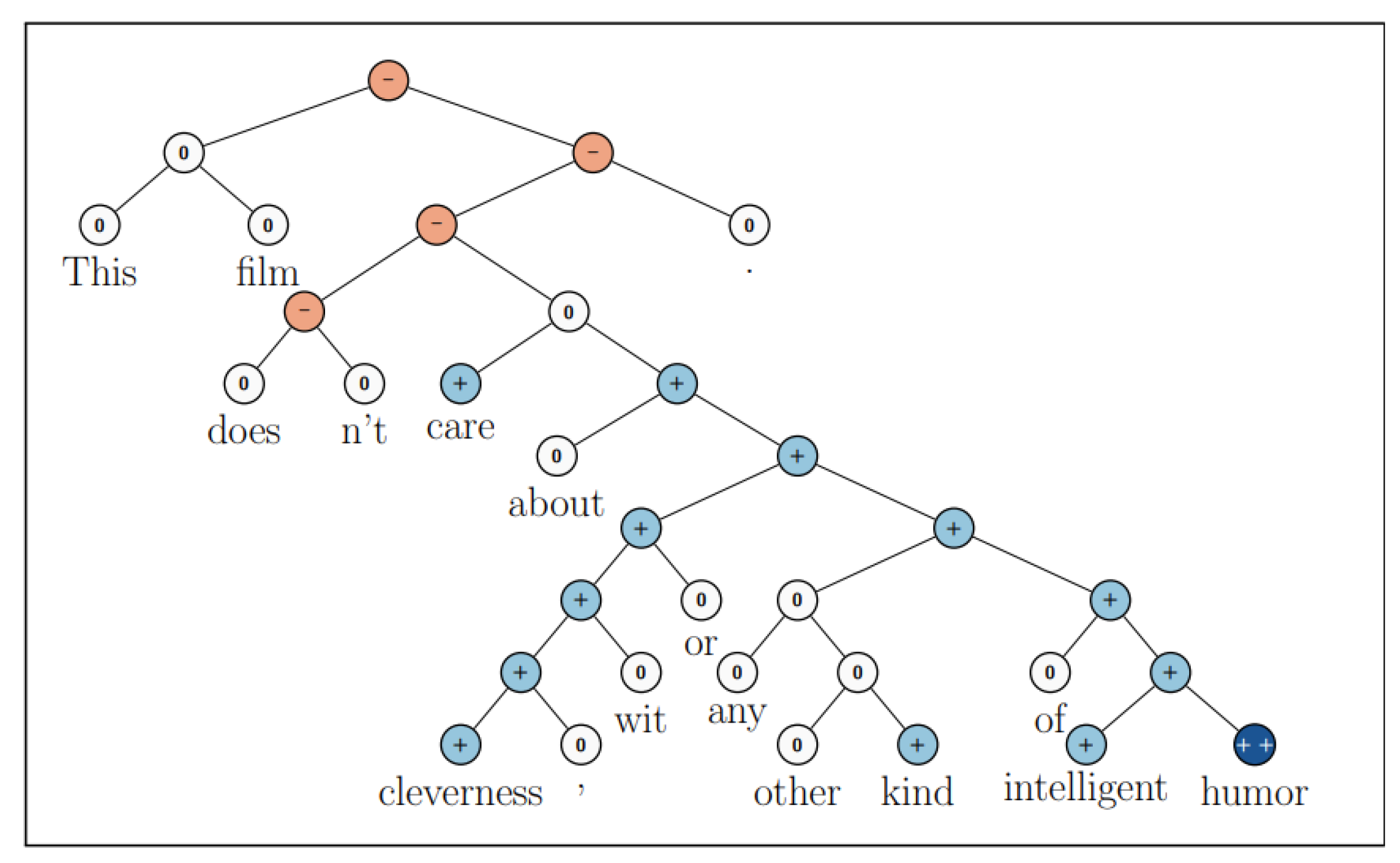
3.2. Dataset: Stanford Sentiment Tree (SST)
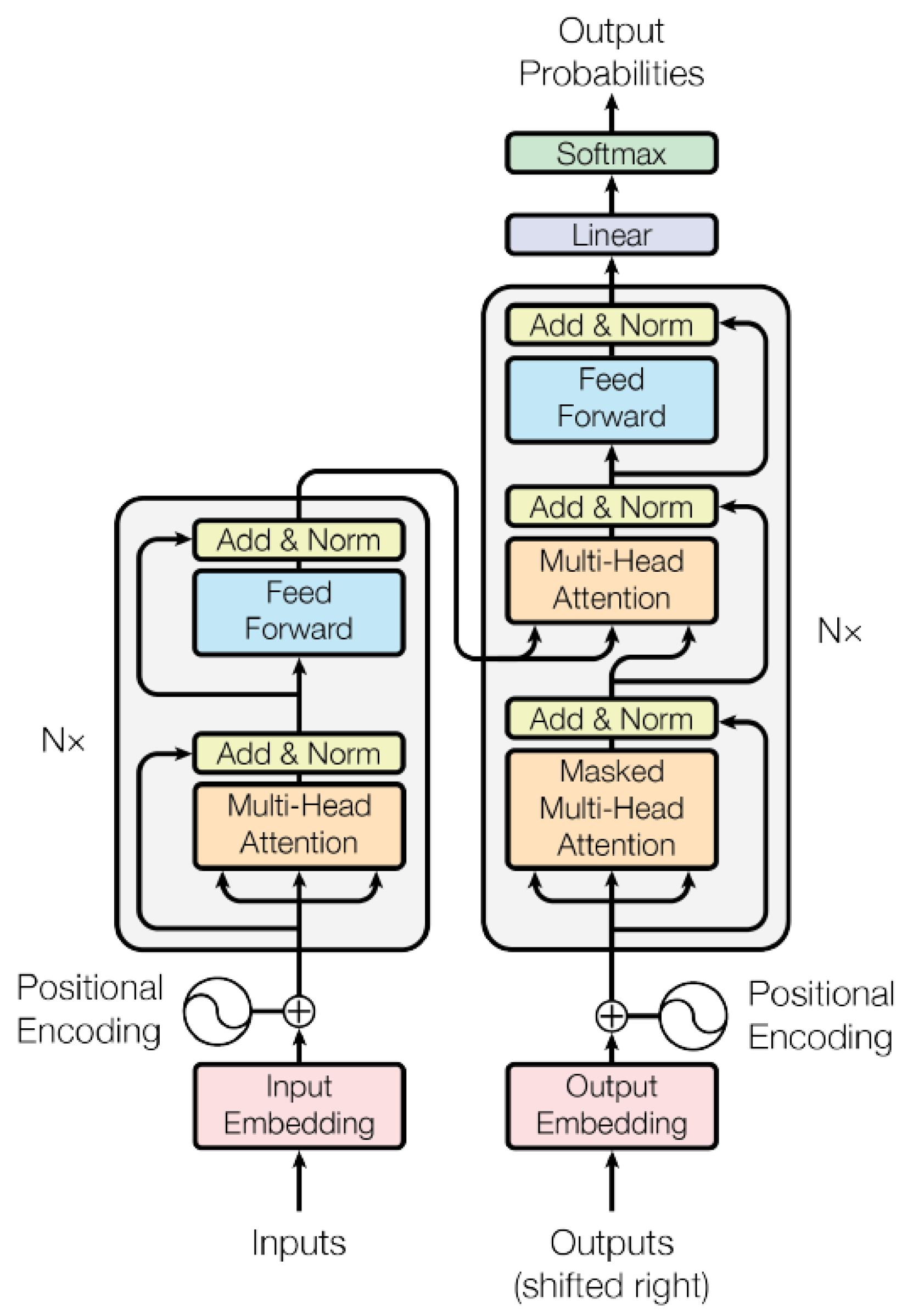
3.3. Transformers
3.3.1. BERT
- Encoder:Composed of a stack of identical layers, each one with the two sub-layers of a multi-head self-attention mechanism and a position-wise fully connected feedforward network. A residual connection around the sub-layers, followed by layer normalization, is implemented, that is, the output of each sub-layer is , where is the function implemented by the sub-layer itself. Outputs of the fixed dimension are produced by all sub-layers and the embedding layers in order to facilitate these residual connections.
- Decoder:Composed of a stack of identical layers, as well as the encoder. In addition to the two sub-layers, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, they employ residual connections around each of the sub-layers, followed by layer normalization. The self-attention sub-layer in the decoder stack is modified in order to prevent positions from attending to subsequent positions. This masking, combined with the fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
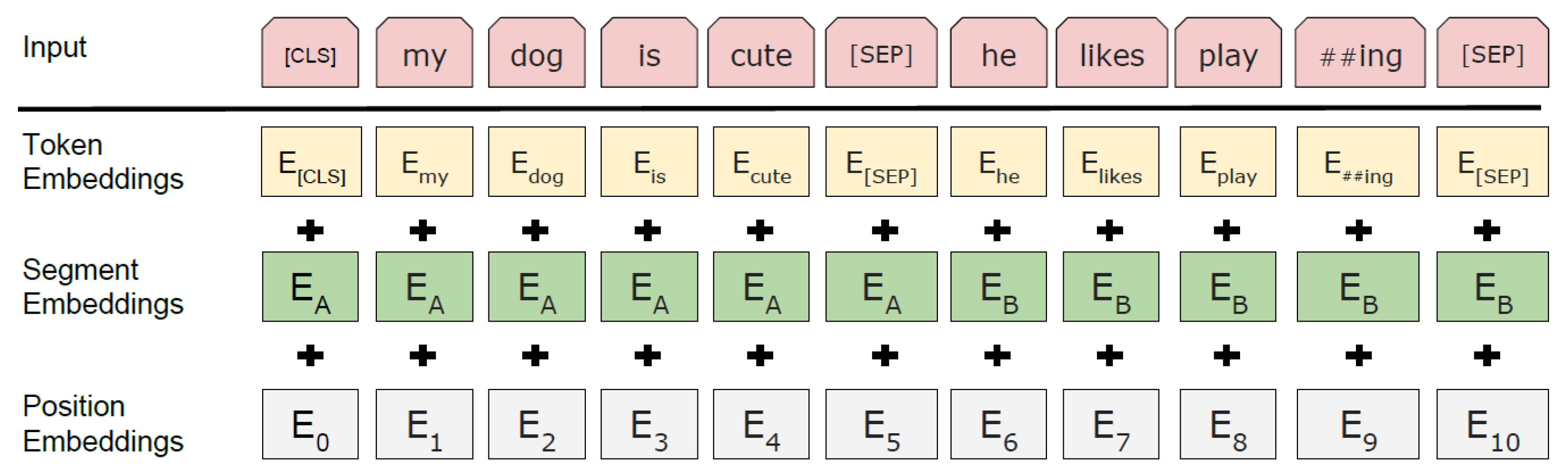
3.3.2. Word Embeddings
3.3.3. Pre-Training and Fine-Tuning
- Masked LM:Standard conditional language models can only be trained left-to-right or right-to-left, since bidirectional conditioning would allow each word to indirectly “see itself”, and the model could trivially predict the target word in a multilayered context. In order to train a deep bidirectional representation, the authors simply mask some percentage of the input tokens at random, and then predict those masked tokens.In all of the experiments, they mask of all WordPiece tokens in each sequence at random, and they only predict the masked words rather than reconstructing the entire input. Although this allows them to obtain a bidirectional pre-trained model, a downside is that they create a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, they do not always replace “masked” words with the actual [MASK] token.The training data generator chooses of the token positions at random for prediction. If the i-th token is chosen, the i-th token is replaced with (1) the [MASK] token of the time, (2) a random token of the time (3), and the unchanged i-th token of the time. Then, the model predicts the original token with cross-entropy loss.
- Next Sentence Prediction:In order to train a model that understands sentence relationships, the model is pre-trained for a binarized next sentence prediction task that can be trivially generated from any monolingual corpus. Specifically, when choosing the sentences A and B for each pretraining example, of the time B is the actual next sentence that follows A (labeled as IsNext), and of the time it is a random sentence from the corpus (labeled as NotNext).Despite its simplicity, pre-training towards this task is very beneficial for many important downstream tasks that are based on understanding the relationship between two sentences, which is not directly captured by language modeling.
3.3.4. BERT Alternatives
4. Experimental Settings for Reproducibility
4.1. Environment
- Hardware;
- Programming language;
- Libraries and packages imported.
4.2. Hardware
4.3. Source Code
Notebook Files
| Listing 1. Right Padding and Get Binary Label function. |
 |
| Listing 2. Initial part of SSTDataset class with the root-level binary choise for the dataset. |
 |
| Listing 3. Configuration of DistilBERT. |
 |
| Listing 4. Training and evaluation phases. |
 |
| Listing 5. Tuning the model. |
 |
4.4. Syntax Errors
model(input_ids = batch, labels = labels)[:2]that gives as output a tuple composed of a tensor of shape (1,) with the value of the loss function for the current epoch and by the logits that are a tensor of shape (batch_size, config.num_labels), corresponding to the predicted probabilities per each label of each batch input, plus other possible outputs such as hidden_states tensor and attention tensor that need to be specified. This line is what causes the error in the execution. The downloaded scripts did not have the final part, but the model() function gave as output 6 values to be assigned to some variables, hence it crashed, because only the first two variables were assigned. With , we force it to consider only the first two outputs that we are looking for, the loss and the logits. Maybe it could have happened that previously it was not necessary to explicitly set if the last two parameters had not been defined, but in the current version, it was perhaps made mandatory to insert that part of the code.
4.5. Inconsistencies
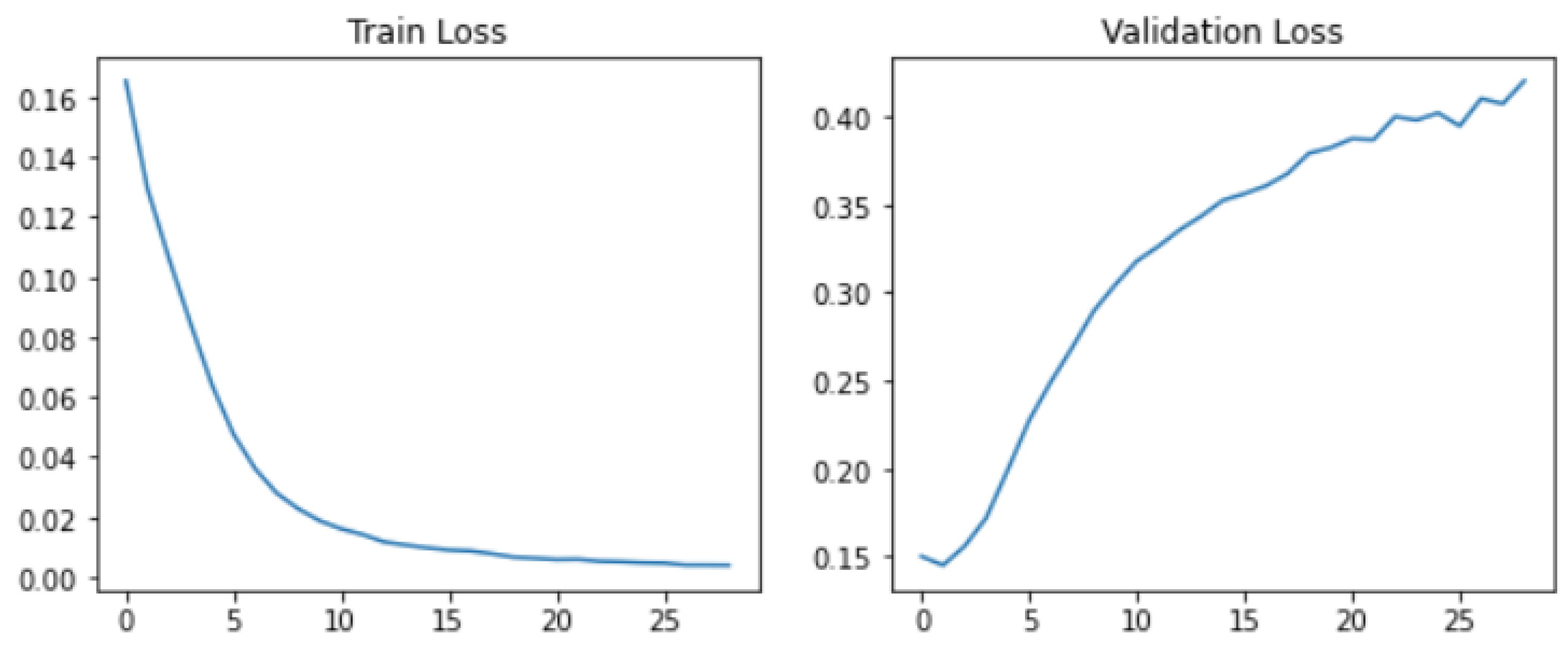
“After noticing the test accuracy tended to fluctuate randomly over 30 epochs, neither improving nor getting worse as training loss converged, and getting different patterns on different machines, we decided that the original model training process led to significant on the train set, so we decided to implement an early-stoppage protocol in our analysis. This practice also let us analyze how quickly models would converge in terms of epochs.”
- last_loss is just a random big enough value to initialize the procedure;
- Patience is the previously cited number N that determine how many epochs there can be with no improvements;
- trigger_times is another value that needs to be set equal to 0 at the start of the training and behaves like a flag. Every time there is an increase in the validation loss during an epoch, this number is increased by 1.
| Listing 6. Early-Stopping Procedure. |
 |
| Listing 7. Random-Seed Function. |
 |
5. Experimental Results
5.1. A Note of Caution: Test Accuracy
- Train the parameters of the model with the training set;
- Optimize the hyper-parameters of the model with the validation set;
- Select the model that obtains the best performance on the validation set;
- Test the selected model on the test set.
- A table with training times and test accuracy for 30 epochs and for a (supposedly) early-stopping approach (for example, Table 6a);
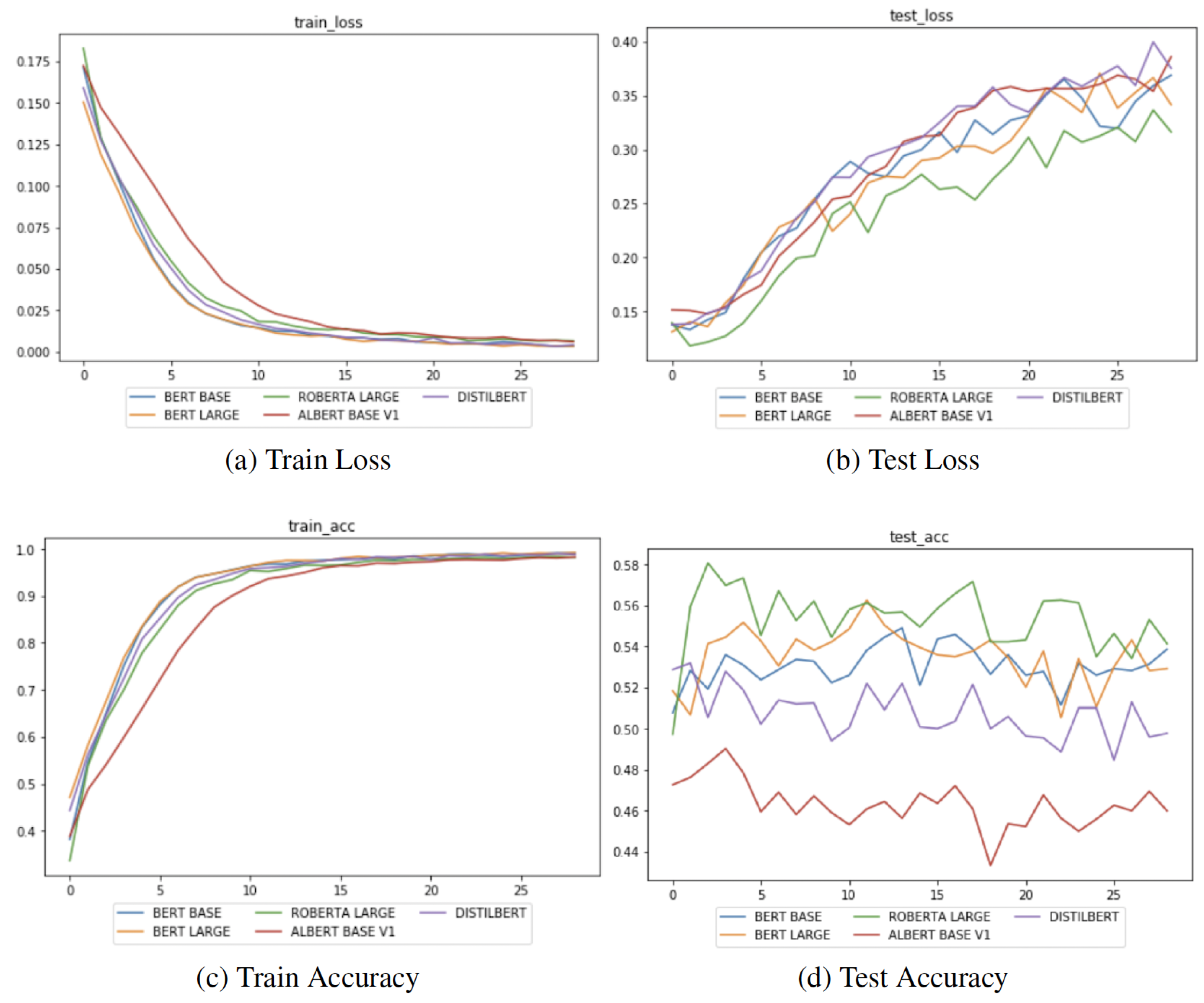
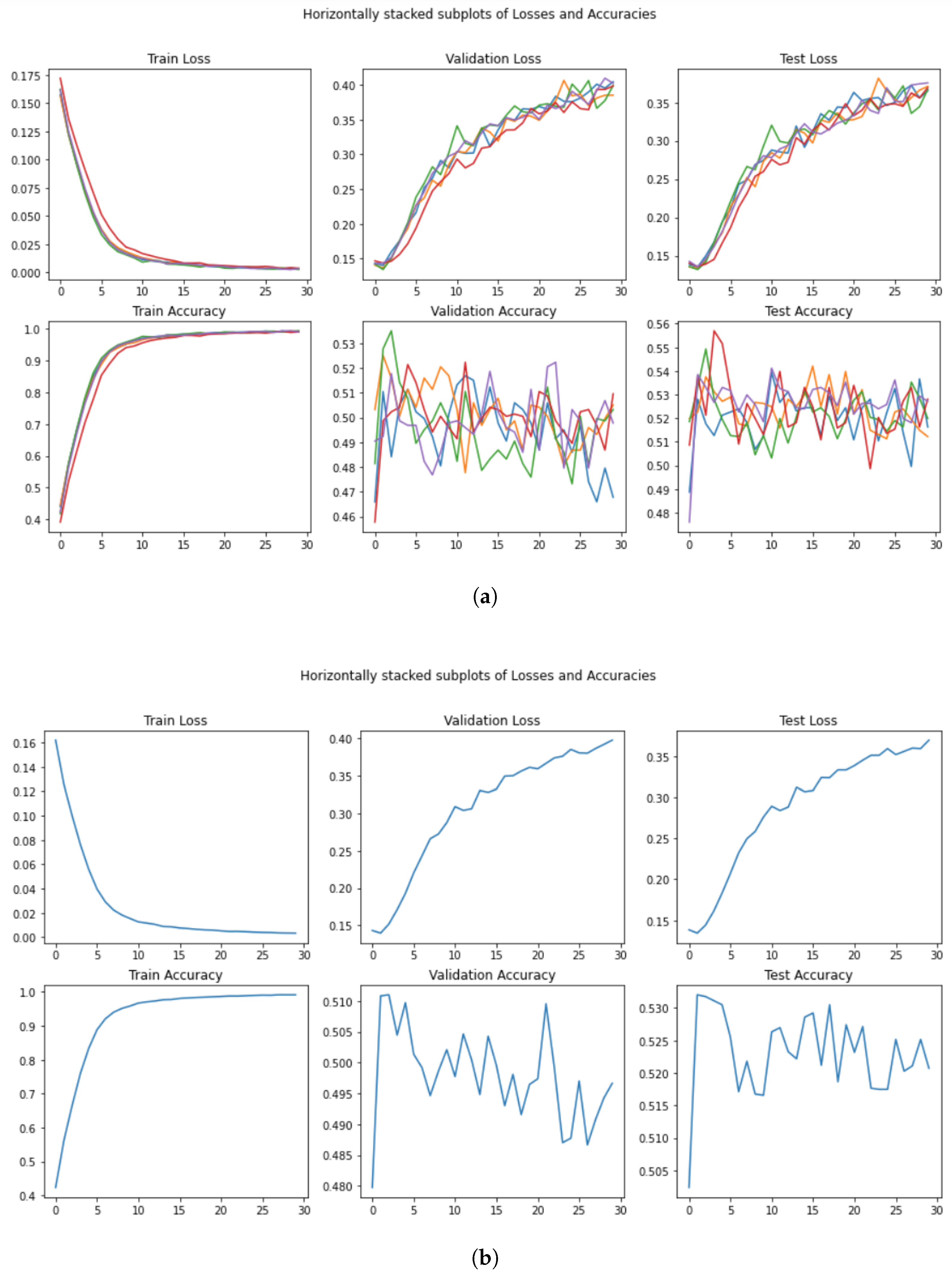
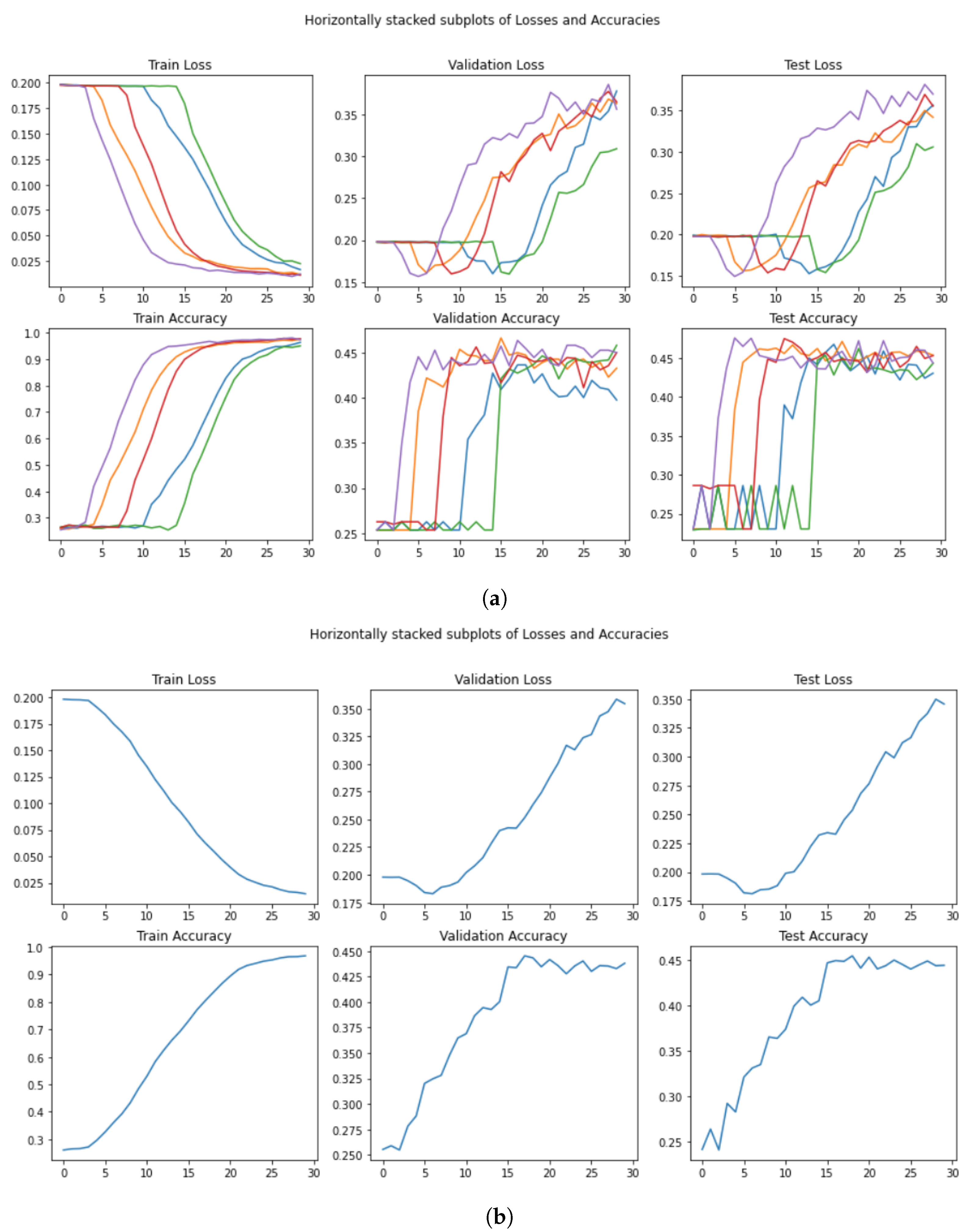
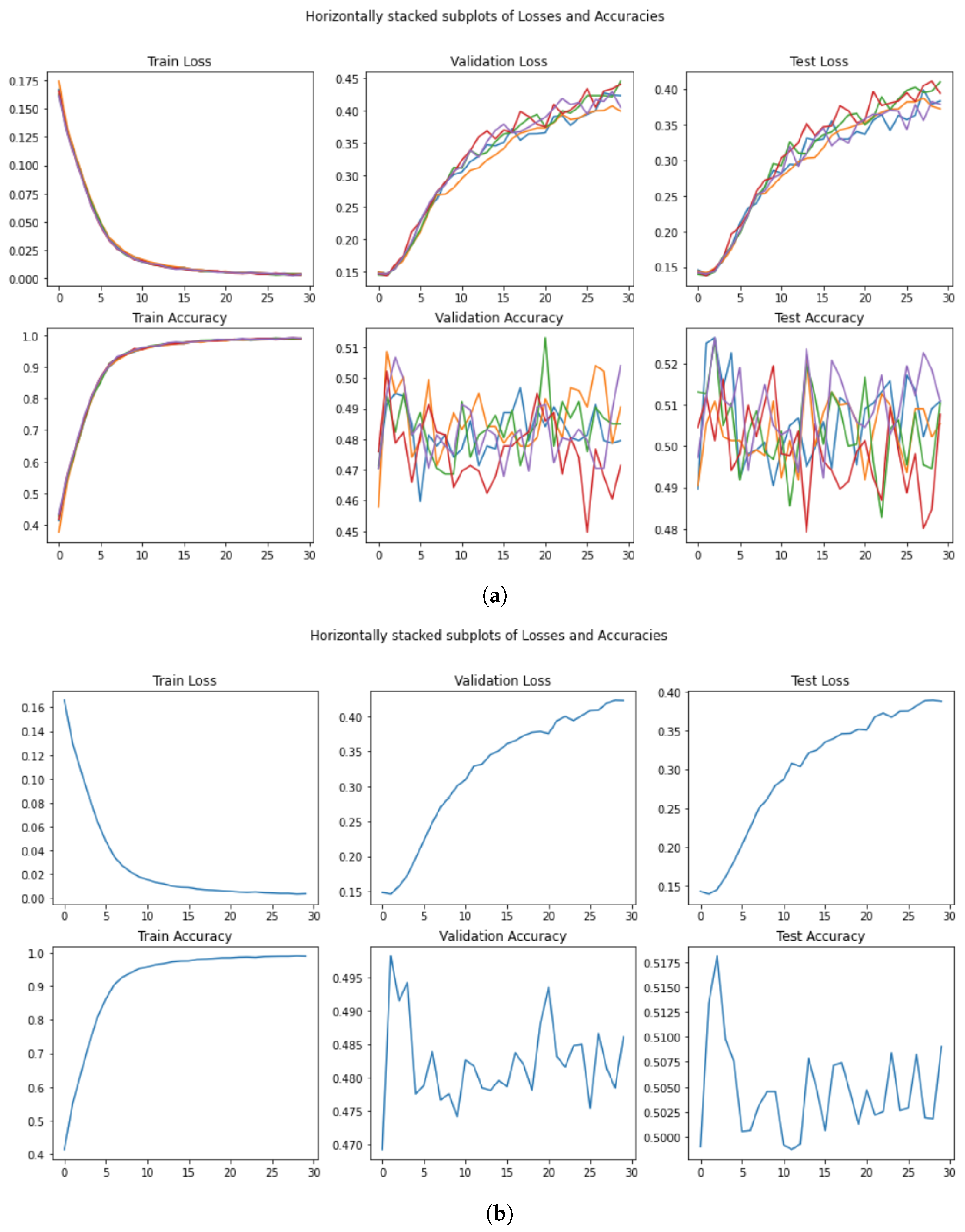
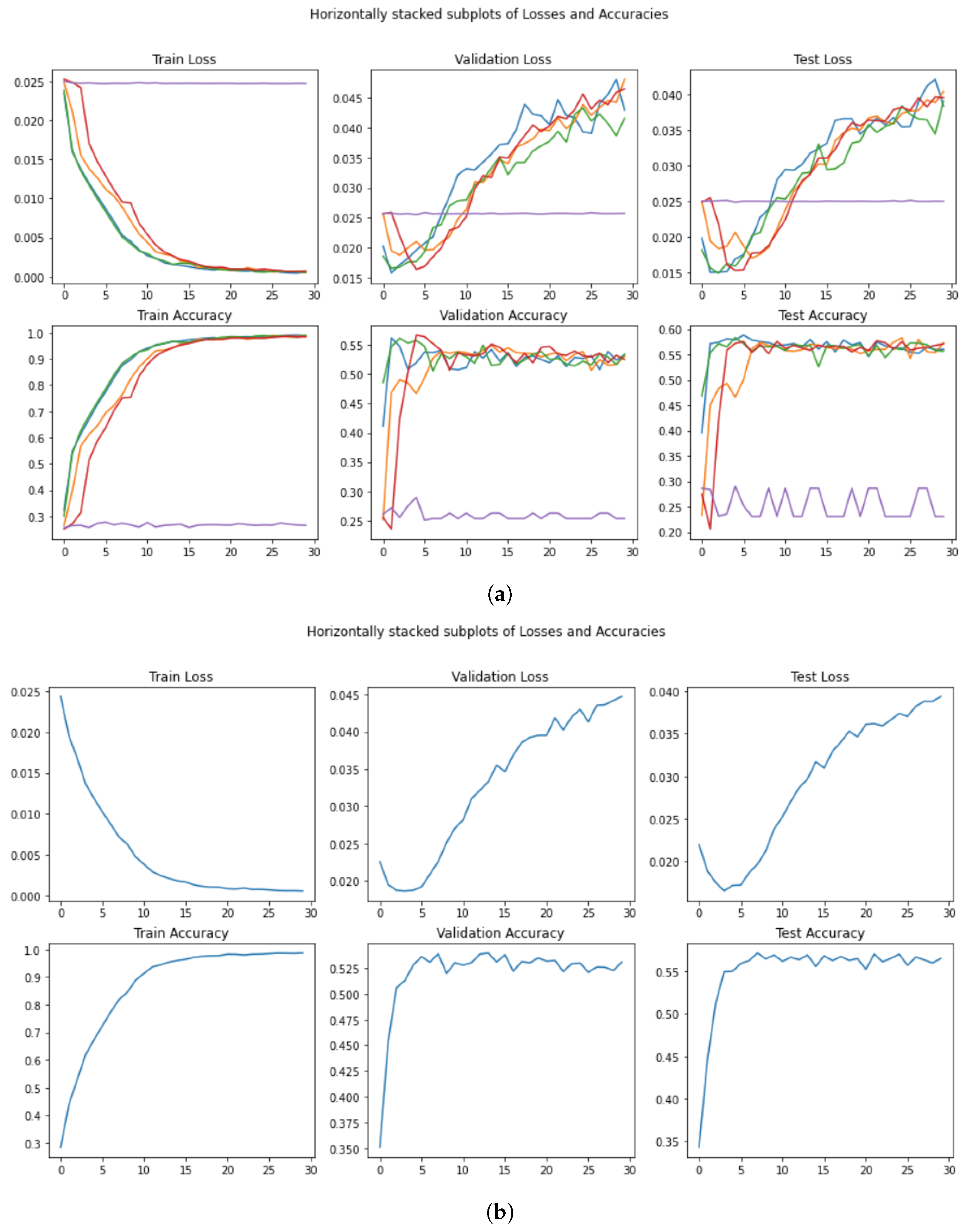
- A Figure with training/validation/test loss and accuracy (for example, Figure 7a);
- A Figure with the average training/validation/test loss and accuracy (for example, Figure 7b);
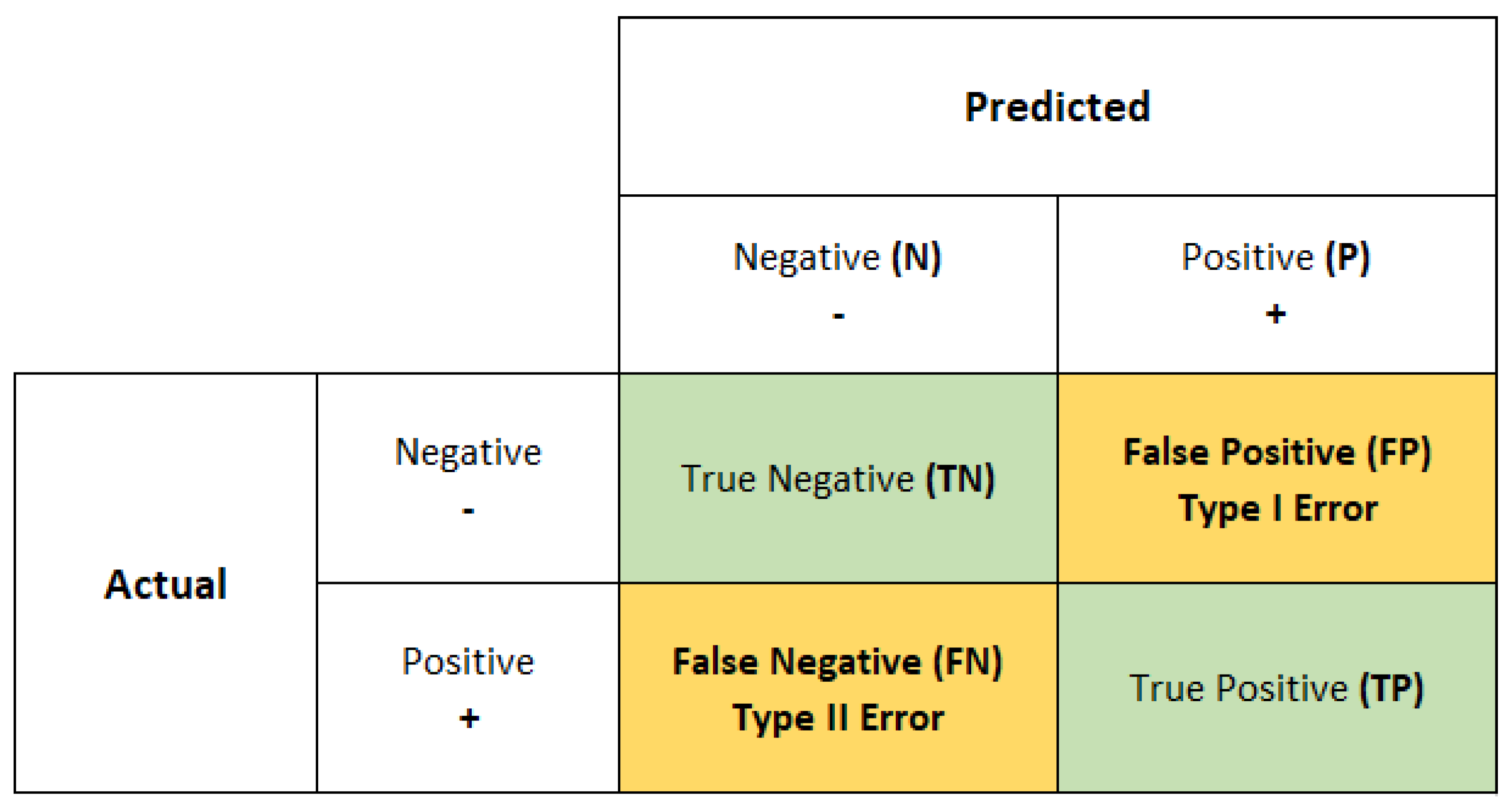
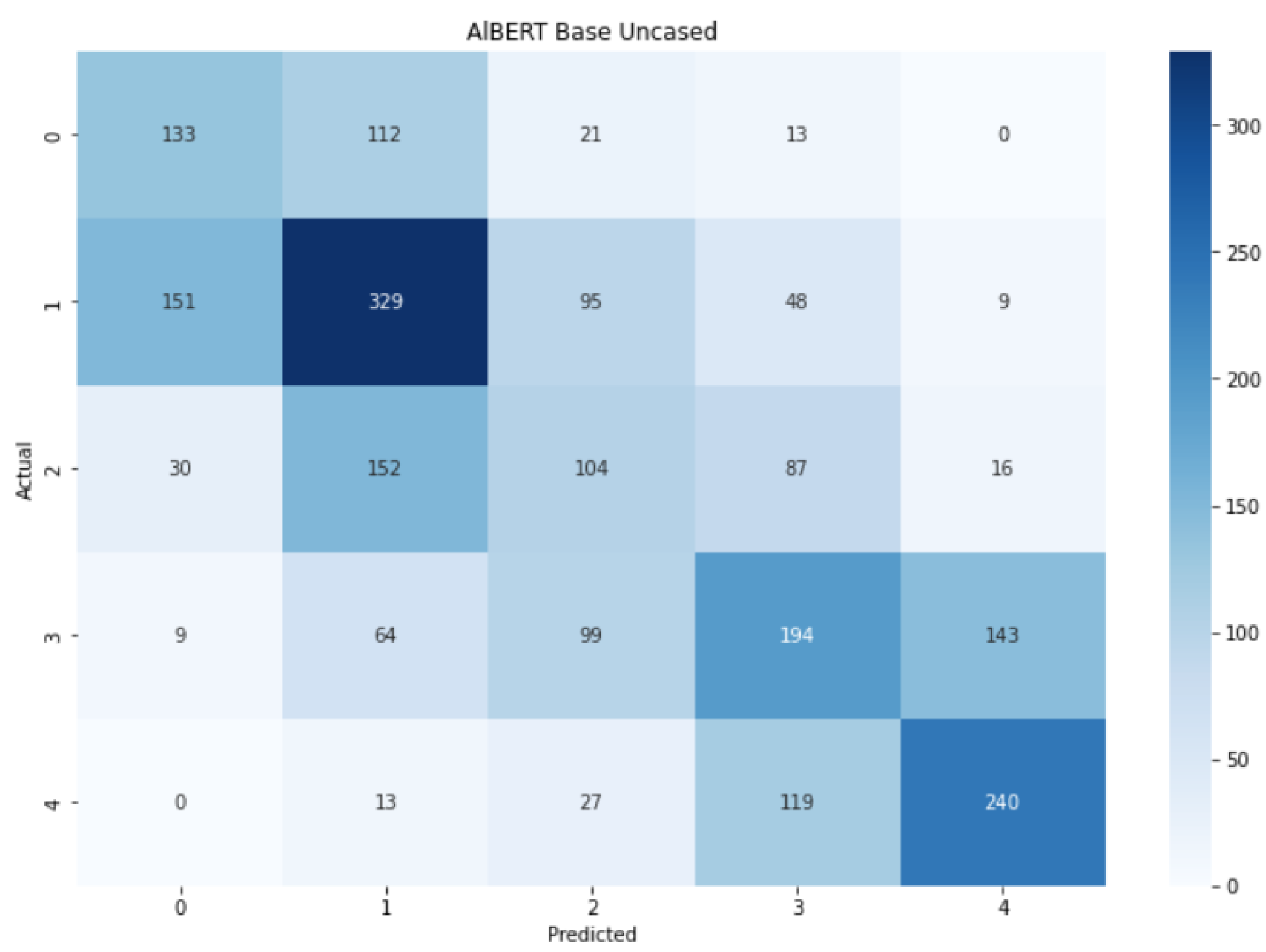
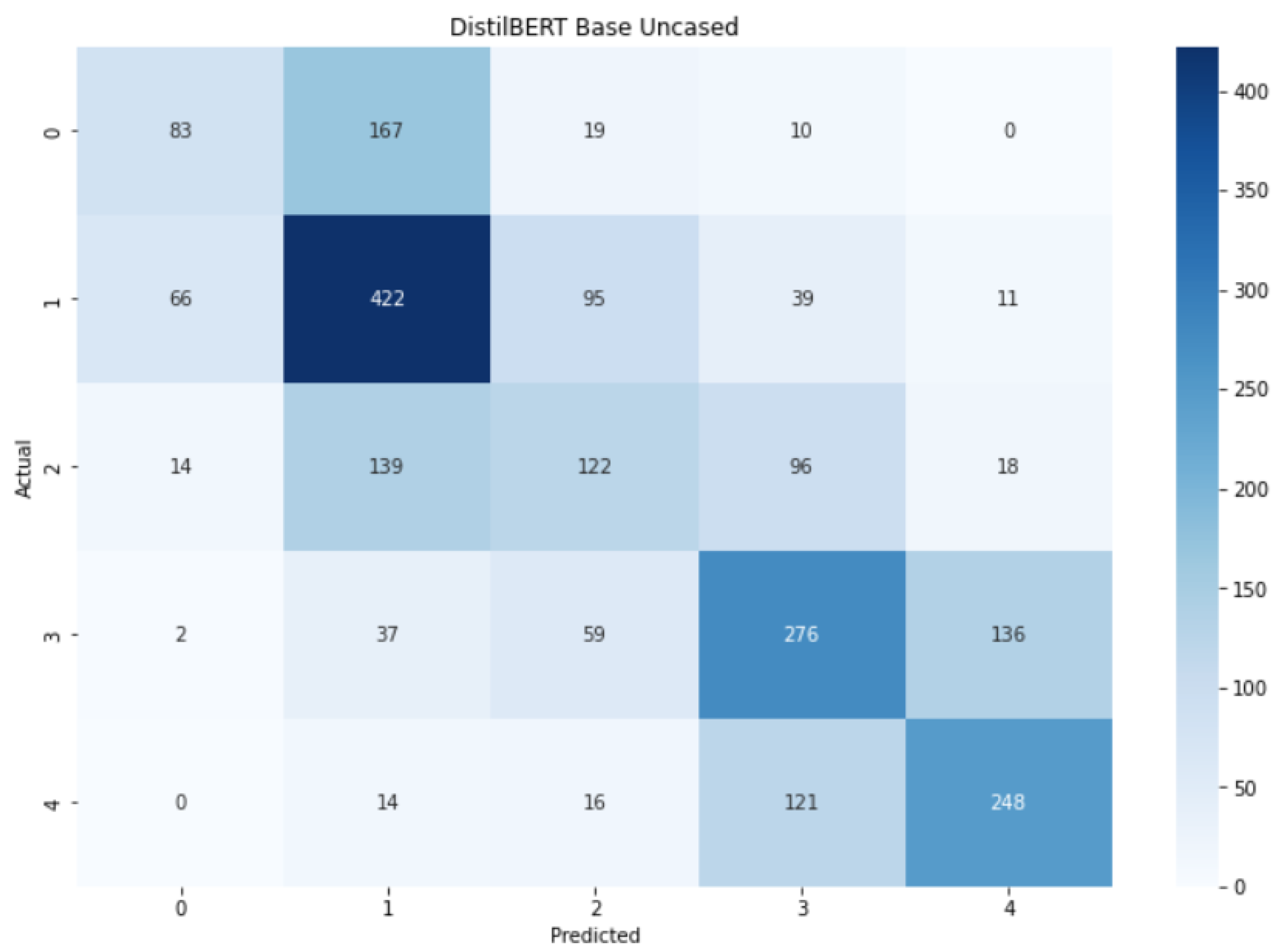
- A Figure with the confusion matrix for the five classes (for example, Figure 8).
5.2. Evaluation Metrics
5.3. BERT_BASE
“The performance did not peak until the 13th epoch and achieved a accuracy on the SST-5 test set.”
5.4. BERT_LARGE
5.5. AlBERT
5.6. DistilBERT_BASE
5.7.
6. Discussion
6.1. How Does This Study Reflect on Current Knowledge about Issues in the Reproducibility of Computational Experiments?
6.2. Was the Original Study by Cheang Et Alii Able to Provide All the Necessary Information to Ensure Its Reproduction in All Respects?
6.3. What Are the Problems and Challenges Encountered?
6.4. What Could Be Done in the Original Study to Overcome the Problems Found?
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pugliese, R.; Regondi, S.; Marini, R. Machine learning-based approach: Global trends, research directions, and regulatory standpoints. Data Sci. Manag. 2021, 4, 19–29. [Google Scholar] [CrossRef]
- Baker, M. Reproducibility crisis. Nature 2016, 533, 353–366. [Google Scholar]
- Lastra-Díaz, J.J.; García-Serrano, A.; Batet, M.; Fernández, M.; Chirigati, F. HESML: A scalable ontology-based semantic similarity measures library with a set of reproducible experiments and a replication dataset. Inf. Syst. 2017, 66, 97–118. [Google Scholar] [CrossRef]
- Crane, M. Questionable Answers in Question Answering Research: Reproducibility and Variability of Published Results. Trans. Assoc. Comput. Linguist. 2018, 6, 241–252. [Google Scholar] [CrossRef] [Green Version]
- Yu, B.; Hu, X. Toward Training and Assessing Reproducible Data Analysis in Data Science Education. Data Intell. 2019, 1, 381–392. [Google Scholar] [CrossRef]
- Cockburn, A.; Dragicevic, P.; Besançon, L.; Gutwin, C. Threats of a replication crisis in empirical computer science. Commun. ACM 2020, 63, 70–79. [Google Scholar] [CrossRef]
- Daoudi, N.; Allix, K.; Bissyandé, T.F.; Klein, J. Lessons Learnt on Reproducibility in Machine Learning Based Android Malware Detection. Empir. Softw. Eng. 2021, 26, 74. [Google Scholar] [CrossRef]
- Gundersen, O.E.; Shamsaliei, S.; Isdahl, R.J. Do machine learning platforms provide out-of-the-box reproducibility? Future Gener. Comput. Syst. 2022, 126, 34–47. [Google Scholar] [CrossRef]
- Reveilhac, M.; Schneider, G. Replicable semi-supervised approaches to state-of-the-art stance detection of tweets. Inf. Process. Manag. 2023, 60, 103199. [Google Scholar] [CrossRef]
- Pineau, J.; Vincent-Lamarre, P.; Sinha, K.; Larivière, V.; Beygelzimer, A.; d’Alché Buc, F.; Fox, E.; Larochelle, H. Improving reproducibility in machine learning research: A report from the NeurIPS 2019 reproducibility program. J. Mach. Learn. Res. 2021, 22, 1–20. [Google Scholar]
- Cheang, B.; Wei, B.; Kogan, D.; Qiu, H.; Ahmed, M. Language representation models for fine-grained sentiment classification. arXiv 2020, arXiv:2005.13619. [Google Scholar]
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A survey on sentiment analysis methods, applications, and challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rougier, N.P.; Hinsen, K.; Alexandre, F.; Arildsen, T.; Barba, L.A.; Benureau, F.C.; Brown, C.T.; De Buyl, P.; Caglayan, O.; Davison, A.P.; et al. Sustainable computational science: The ReScience initiative. PeerJ Comput. Sci. 2017, 3, e142. [Google Scholar] [CrossRef] [Green Version]
- Wieling, M.; Rawee, J.; van Noord, G. Reproducibility in computational linguistics: Are we willing to share? Comput. Linguist. 2018, 44, 641–649. [Google Scholar] [CrossRef]
- Whitaker, K. The MT Reproducibility Checklist. Presented at the Open Science in Practice Summer School. 2017. Available online: https://openworking.wordpress.com/2017/10/14/open-science-in-practice-summer-school-report/ (accessed on 19 January 2023).
- Belz, A.; Agarwal, S.; Shimorina, A.; Reiter, E. A systematic review of reproducibility research in natural language processing. arXiv 2021, arXiv:2103.07929. [Google Scholar]
- Joint Committee for Guides in Metrology. International vocabulary of metrology—Basic and general concepts and associated terms (VIM). VIM3 Int. Vocab. Metrol. 2008, 3, 104. [Google Scholar]
- Munikar, M.; Shakya, S.; Shrestha, A. Fine-grained sentiment classification using BERT. In Proceedings of the 2019 Artificial Intelligence for Transforming Business and Society (AITB), Kathmandu, Nepal, 5 November 2019; Volume 1, pp. 1–5. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Aßenmacher, M.; Heumann, C. On the comparability of Pre-trained Language Models. arXiv 2020, arXiv:2001.00781. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. arXiv 2005, arXiv:cs/0506075. [Google Scholar]
- Klein, D.; Manning, C.D. Accurate unlexicalized parsing. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics, Sapporo, Japan, 7–12 July 2003; pp. 423–430. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Wan, Z.; Xu, C.; Suominen, H. Enhancing Clinical Information Extraction with Transferred Contextual Embeddings. arXiv 2021, arXiv:2109.07243. [Google Scholar]
- Balagopalan, A.; Eyre, B.; Robin, J.; Rudzicz, F.; Novikova, J. Comparing Pre-trained and Feature-Based Models for Prediction of Alzheimer’s Disease Based on Speech. Front. Aging Neurosci. 2021, 13, 635945. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. arXiv 2015, arXiv:1506.06724. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning; Technical Report; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Ulmer, D.; Bassignana, E.; Müller-Eberstein, M.; Varab, D.; Zhang, M.; van der Goot, R.; Hardmeier, C.; Plank, B. Experimental Standards for Deep Learning in Natural Language Processing Research. arXiv 2022, arXiv:2204.06251. [Google Scholar]
- Biderman, S.; Scheirer, W.J. Pitfalls in Machine Learning Research: Reexamining the Development Cycle. arXiv 2021, arXiv:2011.02832. [Google Scholar]
- Skripchuk, J.; Shi, Y.; Price, T. Identifying Common Errors in Open-Ended Machine Learning Projects. In Proceedings of the the 53rd ACM Technical Symposium on Computer Science Education, SIGCSE 2022, Providence, RI, USA, 3–5 March 2022; Association for Computing Machinery: New York, NY, USA, 2022; Volume 1, pp. 216–222. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Main Objective, Issues, and Results |
|---|---|---|
| [3] | 2017 | Library of semantic similarity measures publicly available for the first time, together with a set of reproducible experiments. |
| [4] | 2018 | A number of controllable environment settings that often go unreported can cause irreproducibility of results as presented in the literature |
| [5] | 2019 | Investigating students’ skills and understanding of reproducibility, whether they are able to communicate reproducible data analysis. |
| [6] | 2020 | Issues relating to the use of null hypothesis significance and discussion on alternative ways to analyze data and present evidence for hypothesized effects. |
| [7] | 2021 | A complete reproduction of five models and insights on the implications around the guesswork that may be required to finalize a working implementation. |
| [8] | 2022 | A survey of machine learning platforms to study whether they provide features that simplify making experiments reproducible out-of-the-box. |
| [9] | 2023 | A methodological approach for a replicable experimental analysis and a workflow using existing tools that can be transposed to other domains. |
| Data | |||
|---|---|---|---|
| Same | Different | ||
| Code | Same | Reproducible | Replicable |
| Different | Robust | Generalisable | |
| Set | Label 1 | Label 2 | Label 3 | Label 4 | Label 5 | Total |
|---|---|---|---|---|---|---|
| Training | 1092 | 2218 | 1624 | 2322 | 1288 | 8544 |
| Validation | 139 | 289 | 229 | 279 | 165 | 1101 |
| Test | 279 | 633 | 389 | 510 | 399 | 2210 |
| Model | No. Layers | No. Hidden Units | No. Self-Attention Heads |
|---|---|---|---|
| (Total Trainable Parameters) | |||
| 12 | 768 | 12 | |
| (110 M) | |||
| 24 | 1024 | 16 | |
| (340 M) | |||
| 12 | 768 | 12 | |
| (12 M) | |||
| 6 | 768 | 12 | |
| (66 M) | |||
| 12 | 768 | 12 | |
| (125 M) | |||
| 24 | 1024 | 16 | |
| (355 M) |
| Item | Original Paper | Our Experiment |
|---|---|---|
| GPU | NVIDIA GeForce GTX 1080 | NVIDIA GeForce GTX 1650 Ti |
| Language | Python v3.8 | Python v3.11 |
| Software | Jupyter notebook v6.0 | Jupyter notebook v6.5 |
| (a) | |||
| Model | Training Time (epoch) | Test Acc. (30 epochs) | Test Acc. (Early-Stopping) |
| Authors’ model | |||
| Our model | |||
| (b) | |||
| Model | Training Time (epoch) | Test Acc. (30 epochs) | Test Acc. (Early-Stopping) |
| Authors’ model | |||
| Our model | (Colab) | ||
| (c) | |||
| Model | Training Time (epoch) | Test Acc. (30 epochs) | Test Acc. (Early-Stopping) |
| Authors’ model | N/A | ||
| Our model | |||
| (d) | |||
| Model | Training Time (epoch) | Test Acc. (30 epochs) | Test Acc. (Early-Stopping) |
| Authors’ model | N/A | ||
| Our model | |||
| (e) | |||
| Model | Training Time (epoch) | Test Acc. (30 epochs) | Test Acc. (Early-Stopping) |
| Authors’ model | N/A | N/A | |
| Our model | (Colab) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Nunzio, G.M.; Minzoni, R. A Thorough Reproducibility Study on Sentiment Classification: Methodology, Experimental Setting, Results. Information 2023, 14, 76. https://doi.org/10.3390/info14020076
Di Nunzio GM, Minzoni R. A Thorough Reproducibility Study on Sentiment Classification: Methodology, Experimental Setting, Results. Information. 2023; 14(2):76. https://doi.org/10.3390/info14020076
Chicago/Turabian StyleDi Nunzio, Giorgio Maria, and Riccardo Minzoni. 2023. "A Thorough Reproducibility Study on Sentiment Classification: Methodology, Experimental Setting, Results" Information 14, no. 2: 76. https://doi.org/10.3390/info14020076