

CSK-CNN: Network Intrusion Detection Model Based on Two-Layer Convolution Neural Network for Handling Imbalanced Dataset

Abstract
:1. Introduction
- (1)
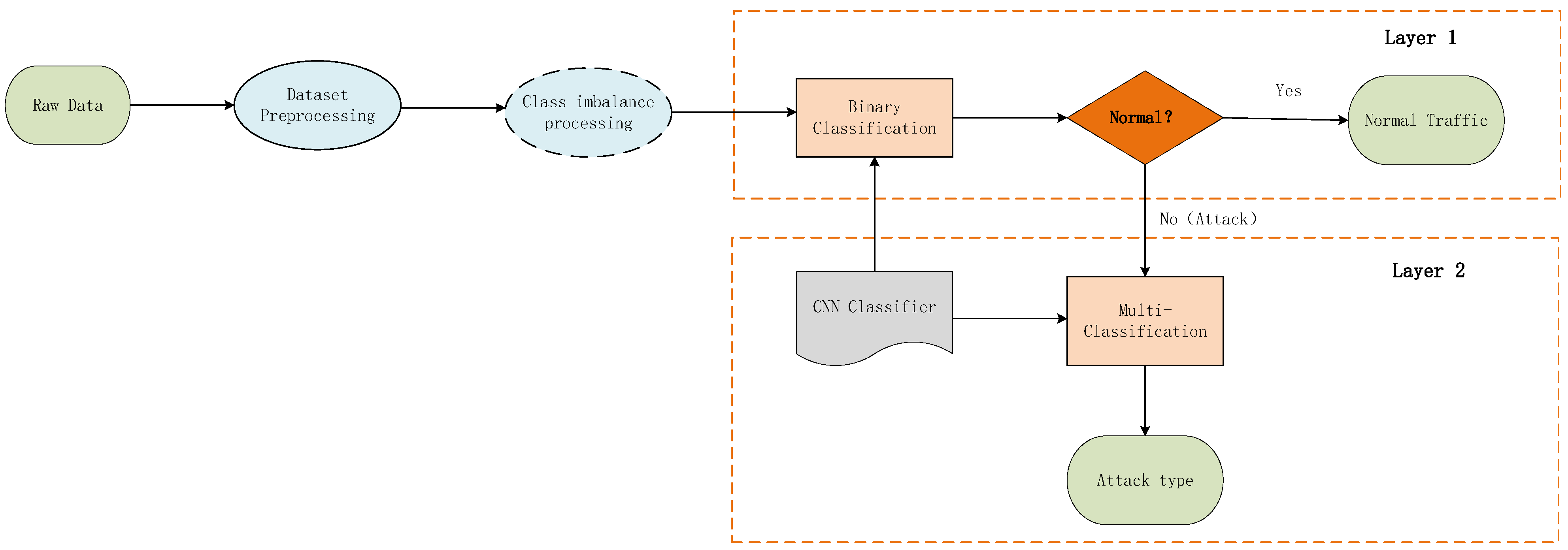
- This paper proposes a network intrusion detection model CSK-CNN, which combines the imbalance processing algorithm Cluster-SMOTE + K-means and two-layer CNN algorithm, and has a high detection rate in identifying imbalanced datasets. CSK-CNN is an anomaly based network intrusion detection model, which uses two-layer CNN to identify and classify network intrusion behaviors: Layer 1 uses binary classification to identify normal traffic and abnormal traffic. Layer 2 uses multiple classification to classify abnormal traffic into specific attack categories.
- (2)
- In this paper, we propose a novel method, CSK algorithm, to deal with class imbalanced datasets on large datasets. This method first uses Cluster-SMOTE to oversample the training samples for minority classes, and then uses K-means to under sample the training samples for majority classes, finally making the training sample classes balanced. This method can not only avoid a large amount of time and space waste caused by over sampling, as well as over fitting, but also avoid the loss of important sample information caused by random under sampling. Experiments show that the anomaly detection rate is significantly improved in minority classes.
- (3)
- This paper uses accuracy, recall, precision, F1 score, ROC curve, AUC value, training time and testing time to evaluate the proposed CSK-CNN model, and compares the performance of four imbalanced class processing algorithms (SMOTE, ROS, ADASYN, RUS + SMOTE, K-means + SMOTE) and two machine learning classification algorithms (RF and MLP). The experimental results show that the CSK-CNN model proposed in this paper is effective in dealing with large-scale imbalanced network intrusion detection, and its performance is better than other algorithms. Therefore, CSK-CNN, the accurate and efficient network anomaly intrusion detection method proposed in this paper, can be deployed in the real world network environment.
2. Related Work
3. Proposed Methods
3.1. Dataset Preprocessing
3.2. Class Imbalance Preprocessing
3.2.1. Over Sampling Process Based on Cluster-SMOTE
3.2.2. Under Sampling Process Based on K-Means Clustering
| Algorithm 1 CSK |
| Input: Training set = the total number of classes; # the total number of samples Output: a balanced training set needed ; 1: 2: for ⬅ 1 to C do 3: if then 4: # Use K-means to cluster into C clusters, 5: 6: for ⬅ 1 to C do 7: # Use SMOTE to oversample 8: end for 9: 10: end if 11: 12: if then 13: # Use K-means to cluster into C clusters, 14: 15: for ⬅ 1 to C do 16: # Randomly select samples from 17: end for 18: 19: end if 20: 21: end for 22: return |
3.3. Convolutional Neural Network
4. Experimental Results and Analysis
4.1. Dataset Description
4.2. Evaluation Matrix
4.3. Hyperparameters for Convolution Neural Network
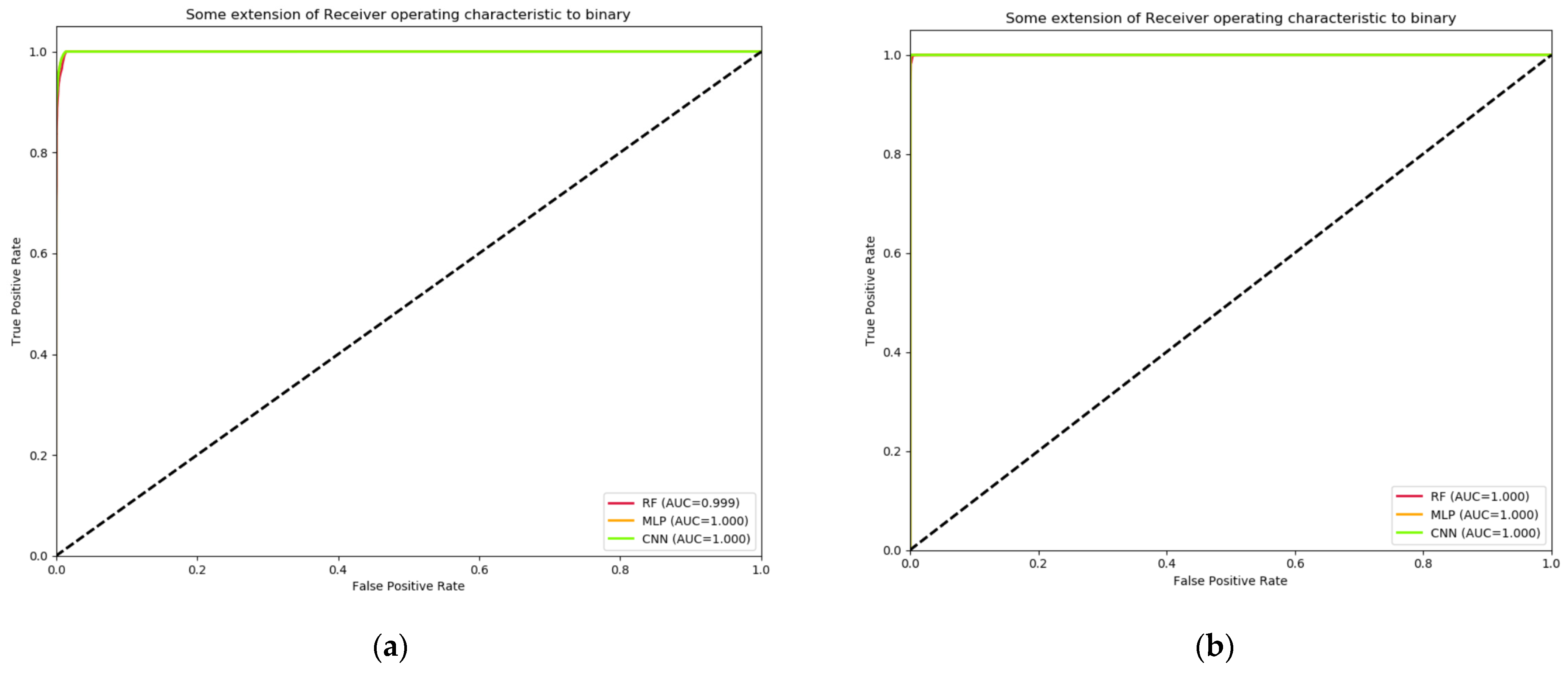
4.4. Layer 1: Binary Classification Results
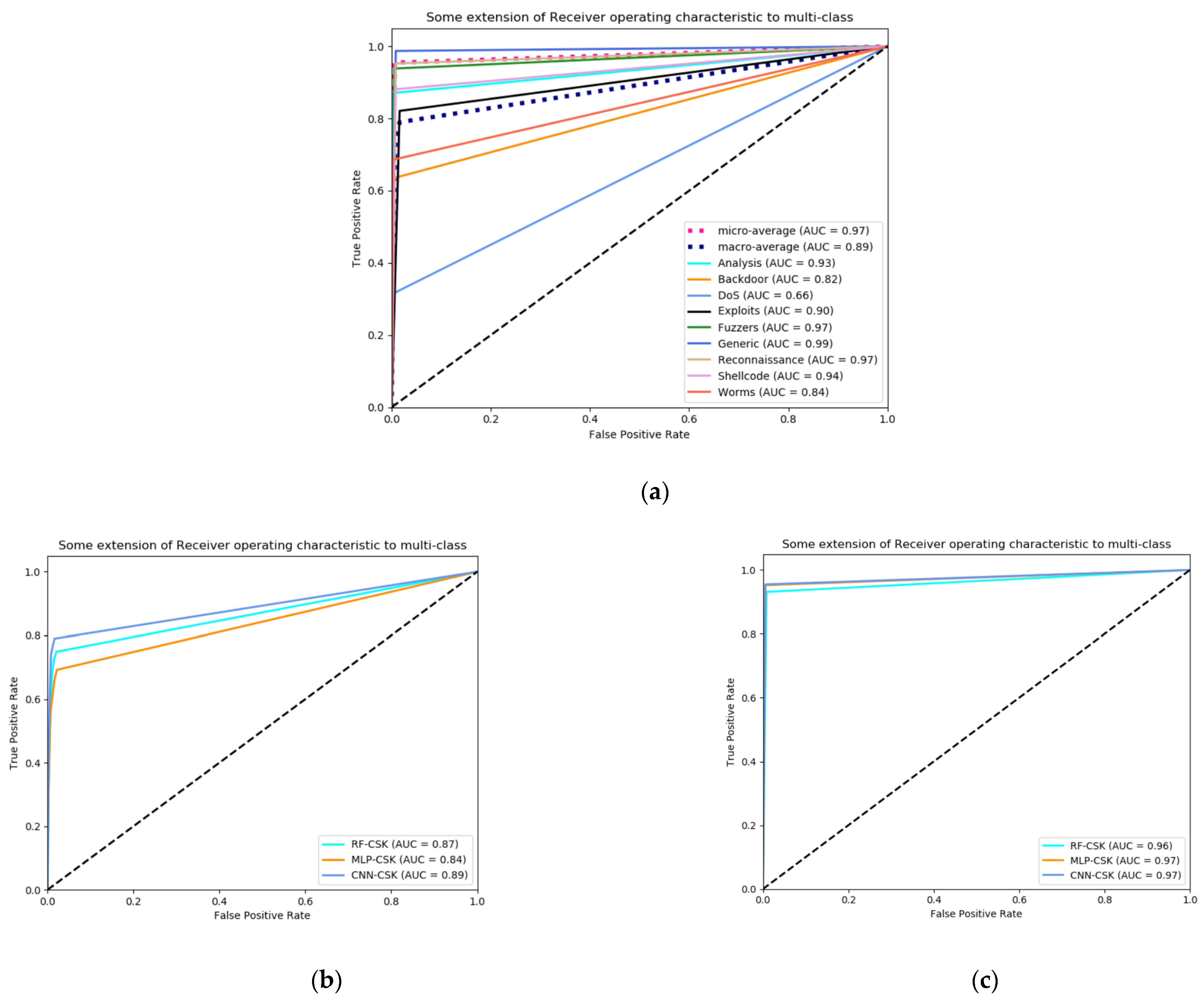
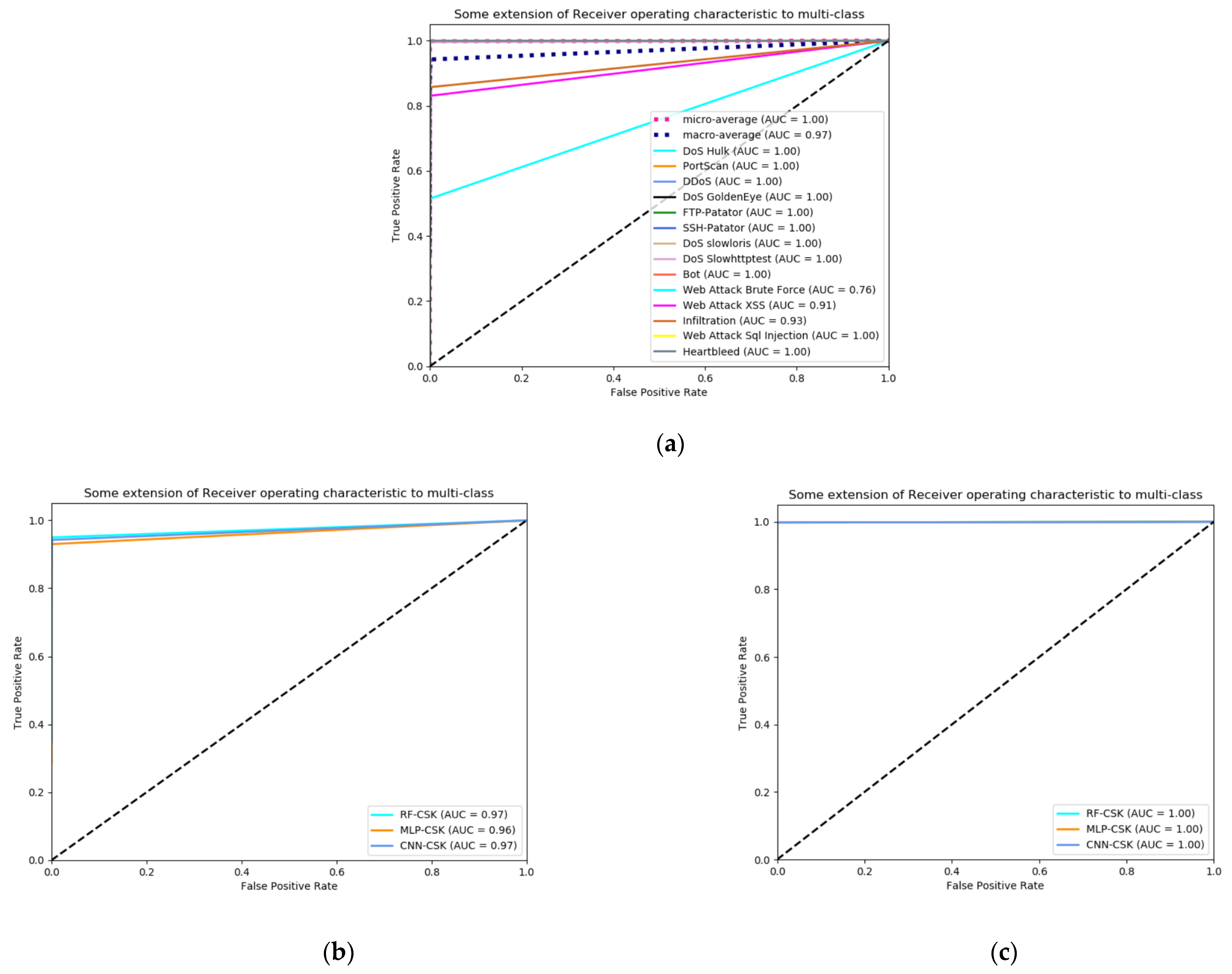
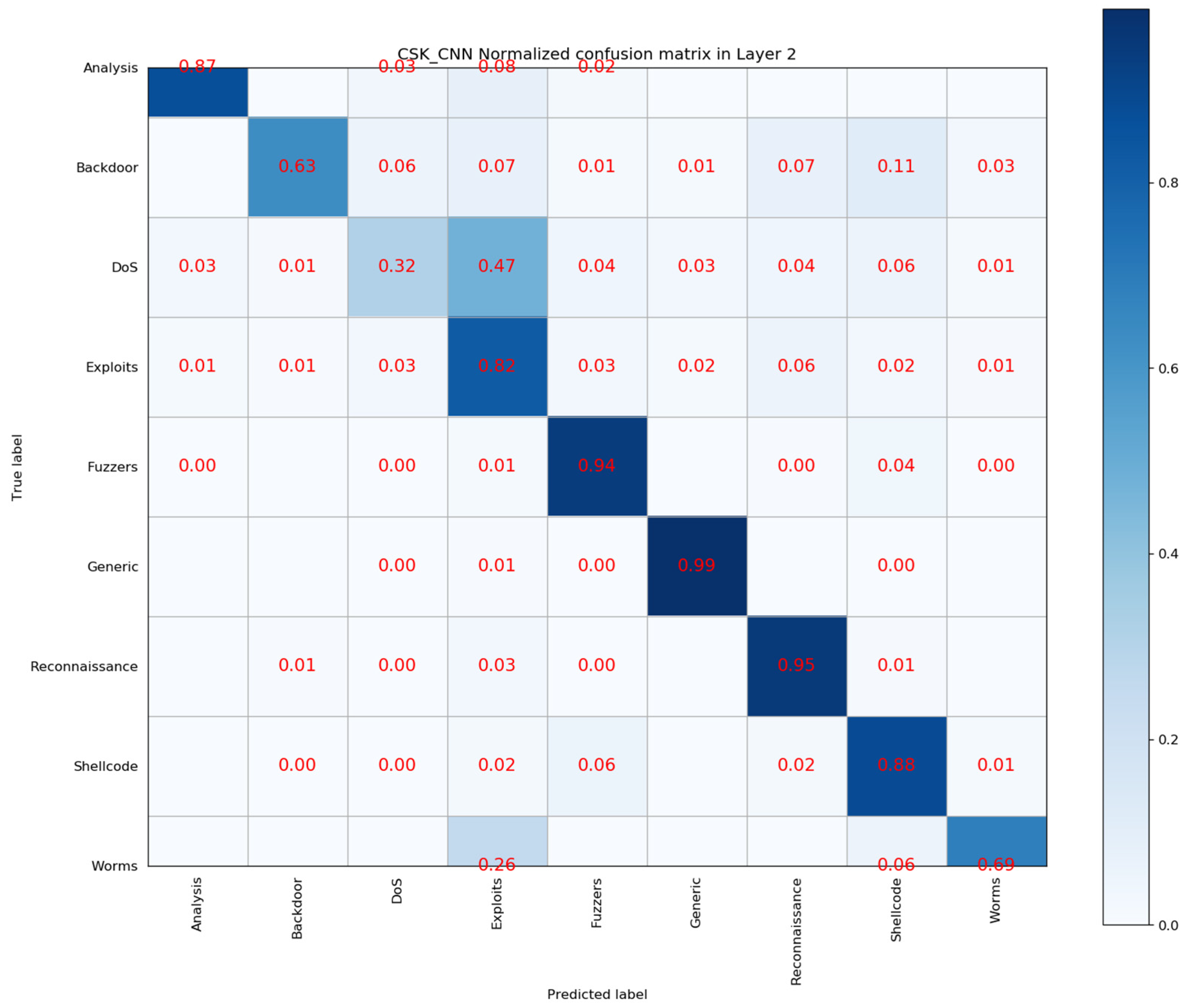
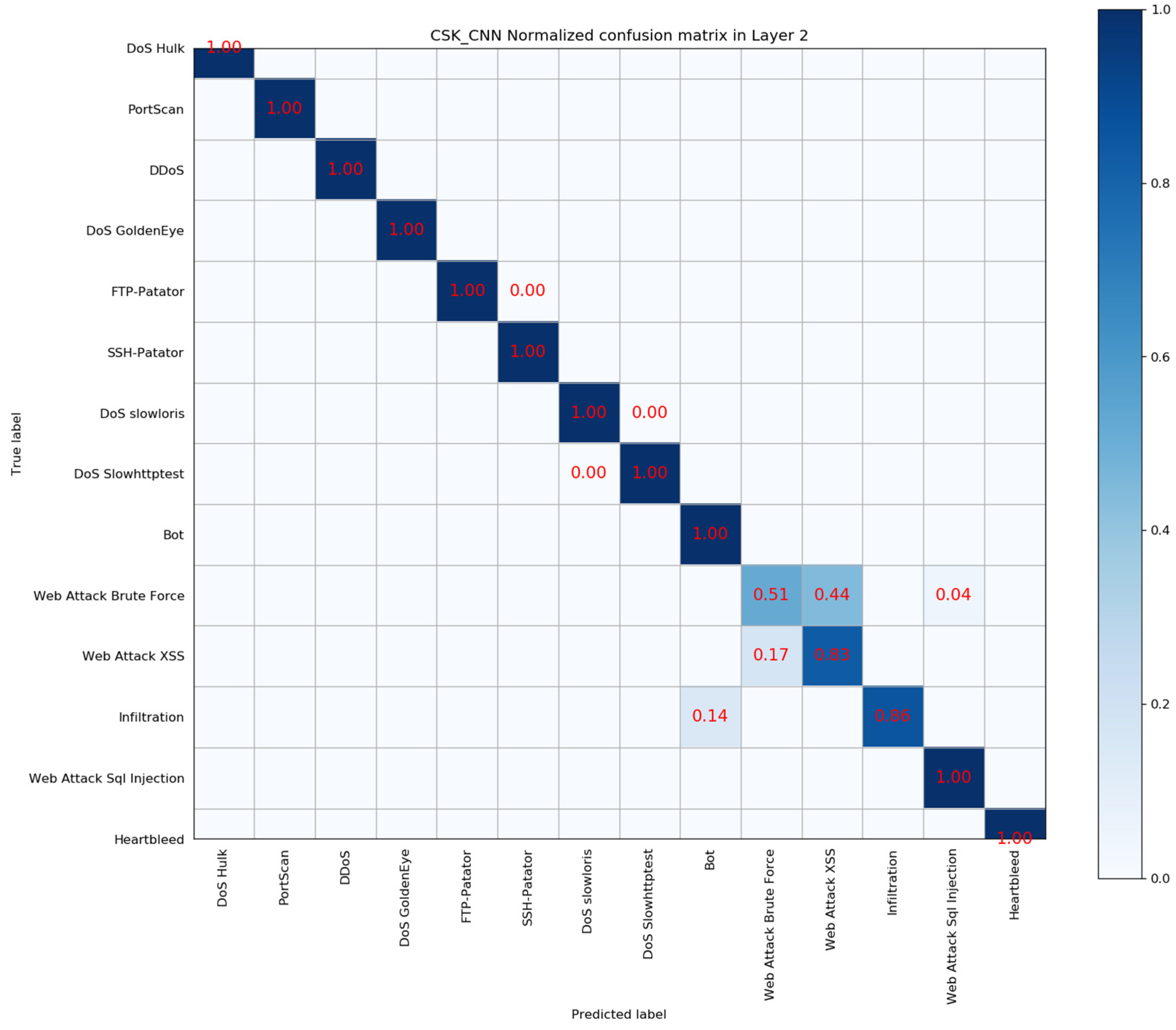
4.5. Layer 2: Multi Classification Results
4.6. Overall Performance of Network Intrusion Detection
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UNSW-NB15 | Normal | Attack |
|---|---|---|
| Normal | 437,288 | 3534 |
| Attack | 735 | 55,645 |
| CICIDS2017 | Normal | Attack |
|---|---|---|
| Normal | 454,351 | 269 |
| Attack | 48 | 111,481 |


References
- Abbood, Z.A.; Khaleel, I.; Aggarwal, K. Challenges and Future Directions for Intrusion Detection Systems Based on AutoML. Mesop. J. CyberSecurity 2021, 2021, 16–21. [Google Scholar] [CrossRef]
- Alajanbi, M.; Ismail, M.A.; Hasan, R.A.; Sulaiman, J. Intrusion Detection: A Review. Mesop. J. CyberSecurity 2021, 2021, 1–4. [Google Scholar] [CrossRef]
- Umamaheswari, A.; Kalaavathi, B. Honeypot TB-IDS: Trace back model based intrusion detection system using knowledge based honeypot construction model. Clust. Comput. 2019, 22, 14027–14034. [Google Scholar] [CrossRef]
- Zong, W.; Chow, Y.-W.; Susilo, W. Interactive three-dimensional visualization of network intrusion detection data for machine learning. Future Gener. Comput. Syst. 2020, 102, 292–306. [Google Scholar] [CrossRef]
- Ravale, U.; Marathe, N.; Padiya, P. Feature selection based hybrid anomaly intrusion detection system using k-means and RBF kernel function. Procedia Comput. Sci. 2015, 45, 428–435. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.Q.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Sangkatsanee, P.; Wattanapongsakorn, N.; Charnsripinyo, C. Practical real-time intrusion detection using machine learning approaches. Comput. Commun. 2011, 34, 2227–2235. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, C.; Zhang, Y.; Yuan, J. Multiscale convolutional CNN model for network intrusion detection. Comput. Eng. Appl. 2019, 55, 90. [Google Scholar] [CrossRef]
- Sheikhan, M.; Jadidi, Z.; Farrokhi, A. Intrusion detection using reduced-size RNN based on feature grouping. Neural Comput. Appl. 2012, 21, 1185–1190. [Google Scholar] [CrossRef]
- Althubiti, S.A.; Jones, E.M., Jr.; Roy, K. LSTM for anomaly-based network intrusion detection. In Proceedings of the 2018 28th International Telecommunication Networks and Applications Conference (ITNAC), Sydney, NSW, Australia, 21–23 November 2018. [Google Scholar]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Slay, J. Towards developing network forensic mechanism for botnet activities in the IoT based on machine learning techniques. Mob. Netw. Manag. 2018, 235, 30–44. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; He, Z.; Ye, G.; Zhang, H. Network intrusion detection based on PSO-XGBoost model. IEEE Access 2020, 8, 58392–58401. [Google Scholar] [CrossRef]
- Aljbali, S.; Roy, K. Anomaly detection using bidirectional LSTM. In Intelligent Systems and Applications. IntelliSys 2020; Advances in Intelligent Systems and Computing; Springer International Publishing: London, UK, 2020. [Google Scholar]
- Andresini, G.; Appice, A.; Malerba, D. Nearest cluster-based intrusion detection through convolutional neural networks. Knowl.-Based Syst. 2021, 216, 106798. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Faker, O.; Dogdu, E. Intrusion detection using big data and deep learning techniques. In Proceedings of the ACMSE 2019, Kennesaw, GA, USA, 18–20 April 2019. [Google Scholar] [CrossRef]
- Sun, P.; Liu, P.; Li, Q.; Liu, C.; Lu, X.; Hao, R.; Chen, J. DL-IDS: Extracting features using CNN-LSTM hybrid network for intrusion detection system. Sec. Commun. Netw. 2020, 2020, 8890306. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, L.; Wu, C.Q.; Li, Z. An effective convolutional neural network based on SMOTE and Gaussian mixture model for intrusion detection in imbalanced dataset. Comput. Netw. 2020, 177, 107315. [Google Scholar] [CrossRef]
- Gupta, N.; Jindal, V.; Bedi, P. LIO-IDS: Handling class imbalance using LSTM and Improved One-vs-One technique in Intrusion Detection System. Comput. Netw. 2021, 192, 108076. [Google Scholar] [CrossRef]
- Abdulhammed, R.; Musafer, H.; Alessa, A.; Faezipour, M.; Abuzneid, A. Features dimensionality reduction approaches for machine learning based network intrusion detection. Electronics 2019, 8, 322. [Google Scholar] [CrossRef] [Green Version]
- Cieslak, D.A.; Chawla, N.V.; Striegel, A. Combating imbalance in network intrusion datasets. In Proceedings of the 2006 IEEE International Conference on Granular Computing, Atlanta, GA, USA, 10–12 May 2006; pp. 732–737. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive dataset for network intrusion detection systems (UNSW-NB15 network dataset). In Proceedings of the IEEE: 2015 Military Communications and Information Systems Conference, IEEE, Canberra, ACT, Australia, 10–12 November 2015. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), Funchal, Madeira, Portugal, 22–24 January 2018. [Google Scholar]
- Tahmassebi, A.; Gandomi, A.H.; Fong, S.; Meyer-Baese, A.; Foo, S.Y. Multistage optimization of a deep model: A case study on ground motion modeling. PLoS ONE 2018, 13, e0203829. [Google Scholar] [CrossRef] [Green Version]
- Baig, M.M.; Awais, M.M.; El-Alfy, E.-S.M. A multiclass cascade of artificial neural network for network intrusion detection. J. Intell. Fuzzy Syst. 2017, 32, 2875–2883. [Google Scholar] [CrossRef]
- Chohra, A.; Shirani, P.; Karbab, E.B.; Debbabi, M. Chameleon: Optimized feature selection using particle swarm optimization and ensemble methods for network anomaly detection. Comput. Secur. 2022, 117, 102684. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Yang, Y. Improving the classification effectiveness of intrusion detection by using improved conditional variational autoencoder and deep neural network. Sensors 2019, 19, 2528. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Cheng, G.; Jiang, S.; Dai, M. Building an efficient intrusion detection system based on feature selection and ensemble classifier. Comput. Netw. 2020, 174, 107247. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Chen, X.; Guo, D.; Song, M.; Teng, Y.; Wang, X. PCCN: Parallel cross convolutional neural network for abnormal network traffic flows detection in multiclass imbalanced network traffic flows. IEEE Access 2019, 7, 119904–119916. [Google Scholar] [CrossRef]





| Ref. | Method | Description | Type |
|---|---|---|---|
| [8] 2018 | ARM, ANN, NB | Detect botnet | ML |
| [9] 2020 | PSO-Xgboost | Improve accuracy and efficiency | ML |
| [10] 2020 | LSTM | Outstanding performance. | DL |
| [11] 2021 | 2D CNN | Nearest cluster-based intrusion detection | DL |
| [12] 2017 | RNN | Good classification results. | DL |
| [13] 2019 | DNN, K-means | Feature representations, accuracy | DL |
| [14] 2020 | CNN-LSTM | Feature representations | DL |
| [15] 2020 | CNN, GMM | Imbalanced classification | DL |
| [16] 2021 | LIO-IDS | Handling class imbalance | DL |
| [17] 2019 | UDBB | Features dimensionality reduction approaches | ML |
| Category | Trainset-Size | Testset-Size | Validset-Size | Total |
|---|---|---|---|---|
| Normal | 1,542,873 | 440,822 | 220,412 | 2,204,107 |
| Analysis | 436 | 124 | 62 | 622 |
| Backdoors | 250 | 71 | 36 | 357 |
| DoS | 2693 | 769 | 385 | 3847 |
| Exploits | 19,810 | 5660 | 2830 | 28,300 |
| Fuzzers | 15,060 | 4303 | 2151 | 21,514 |
| Generic | 149,602 | 42,744 | 21,372 | 213,718 |
| Reconnaissance | 8297 | 2371 | 1185 | 11,853 |
| Shellcode | 1057 | 303 | 151 | 1511 |
| Worms | 122 | 35 | 17 | 174 |
| Total | 1,740,200 | 497,202 | 248,601 | 2,486,003 |
| Category | Trainset-Size | Testset-Size | Validset-Size | Total |
|---|---|---|---|---|
| BENIGN | 1,591,167 | 454,620 | 227,310 | 2,273,097 |
| DoS Hulk | 161,751 | 46,215 | 23,107 | 231,073 |
| PortScan | 111,251 | 31,786 | 15,893 | 158,930 |
| DDoS | 89,618 | 25,606 | 12,803 | 128,027 |
| DoS GoldenEye | 7205 | 2059 | 1029 | 10,293 |
| FTP-Patator | 5516 | 1588 | 794 | 7898 |
| SSH-Patator | 4128 | 1179 | 590 | 5897 |
| DoS slowloris | 4057 | 1159 | 580 | 5796 |
| DoS Slowhttptest | 3849 | 1100 | 550 | 5499 |
| Bot | 1376 | 393 | 197 | 1966 |
| Web Attack Brute Force | 1055 | 301 | 151 | 1507 |
| Web Attack XSS | 457 | 130 | 65 | 652 |
| Infiltration | 26 | 7 | 3 | 36 |
| Web Attack Sql Injection | 15 | 4 | 2 | 21 |
| Heartbleed | 8 | 2 | 1 | 11 |
| Total | 1,981,519 | 566,149 | 283,075 | 2,830,743 |
| Hyperparameter | Value |
|---|---|
| Convolutional kernel | 32-32-64-64 |
| Pool_size | 2 × 2 |
| Strides | 2 |
| Dropout | 0.2 |
| Full connection layer nodes | 128 |
| Learning rate | 0.008 |
| Iterations | 100 |
| mini-batch-size | 2048 |
| Activation function | ReLU |
| Optimization algorithm | Nadam |
| loss function | categorical_crossentropy |
| Model | Imbalanced Algorithms | Acc | Recall | FAR | Precision | F1-Score | Train-Times (s) | Test-Times (s) |
|---|---|---|---|---|---|---|---|---|
| RF | SMOTE | 0.9875 | 0.9999 | 0.0141 | 0.9006 | 0.9476 | 30.13 | 0.26 |
| ROS | 0.9875 | 0.9999 | 0.0141 | 0.9006 | 0.9476 | 28.84 | 0.26 | |
| ADASYN | 0.9875 | 0.9999 | 0.0141 | 0.9006 | 0.9476 | 29.40 | 0.27 | |
| RUS + SMOTE | 0.9875 | 0.9999 | 0.0141 | 0.9005 | 0.9476 | 21.08 | 0.26 | |
| K-means + SMOTE | 0.9876 | 0.9996 | 0.0139 | 0.9020 | 0.9483 | 18.05 | 0.28 | |
| CSK | 0.9878 | 0.9980 | 0.0135 | 0.9046 | 0.9491 | 18.06 | 0.26 | |
| MLP | SMOTE | 0.9884 | 0.9980 | 0.0128 | 0.9090 | 0.9514 | 2859.42 | 6.60 |
| ROS | 0.9880 | 0.9990 | 0.0134 | 0.9054 | 0.9499 | 3059.28 | 6.61 | |
| ADASYN | 0.9878 | 0.9994 | 0.0137 | 0.9030 | 0.9488 | 2996.84 | 6.26 | |
| RUS + SMOTE | 0.9885 | 0.9995 | 0.0137 | 0.9031 | 0.9488 | 1739.53 | 6.54 | |
| K-means + SMOTE | 0.9885 | 0.9980 | 0.0128 | 0.9090 | 0.9515 | 1884.72 | 6.36 | |
| CSK | 0.9898 | 0.9939 | 0.0107 | 0.9222 | 0.9567 | 1887.67 | 6.71 | |
| CNN | SMOTE | 0.9877 | 0.9996 | 0.0138 | 0.9023 | 0.9485 | 7836.51 | 19.21 |
| ROS | 0.9883 | 0.9991 | 0.0131 | 0.9068 | 0.9507 | 6077.96 | 20.05 | |
| ADASYN | 0.9889 | 0.9967 | 0.0121 | 0.9131 | 0.9531 | 7789.34 | 22.46 | |
| RUS + SMOTE | 0.9892 | 0.9961 | 0.0117 | 0.9157 | 0.9543 | 4595.55 | 21.93 | |
| K-means + SMOTE | 0.9890 | 0.9972 | 0.0121 | 0.9137 | 0.9536 | 4508.74 | 19.40 | |
| CSK | 0.9914 | 0.9870 | 0.0080 | 0.9403 | 0.9631 | 4212.50 | 19.48 |
| Model | Imbalanced Algorithms | Acc | Recall | FAR | Precision | F1-Score | Train-Times (s) | Test-Times (s) |
|---|---|---|---|---|---|---|---|---|
| RF | SMOTE | 0.9948 | 0.9854 | 0.0029 | 0.9883 | 0.9868 | 42.25 | 0.34 |
| ROS | 0.9949 | 0.9856 | 0.0028 | 0.9884 | 0.9870 | 44.73 | 0.35 | |
| ADASYN | 0.9949 | 0.9856 | 0.0028 | 0.9884 | 0.9870 | 43.58 | 0.34 | |
| RUS + SMOTE | 0.9950 | 0.9856 | 0.0027 | 0.9889 | 0.9873 | 43.98 | 0.36 | |
| K-means + SMOTE | 0.9950 | 0.9855 | 0.0027 | 0.9889 | 0.9872 | 37.27 | 0.32 | |
| CSK | 0.9959 | 0.9989 | 0.0049 | 0.9804 | 0.9896 | 31.26 | 0.35 | |
| MLP | SMOTE | 0.9981 | 0.9993 | 0.0022 | 0.9912 | 0.9953 | 3138.29 | 7.28 |
| ROS | 0.9978 | 0.9994 | 0.0026 | 0.9896 | 0.9945 | 3276.21 | 7.56 | |
| ADASYN | 0.9977 | 0.9983 | 0.0025 | 0.9900 | 0.9942 | 3186.58 | 8.24 | |
| RUS + SMOTE | 0.9982 | 0.9994 | 0.0022 | 0.9912 | 0.9953 | 2586.21 | 7.01 | |
| K-means + SMOTE | 0.9984 | 0.9994 | 0.0017 | 0.9896 | 0.9945 | 2784.78 | 7.50 | |
| CSK | 0.9986 | 0.9984 | 0.0013 | 0.9946 | 0.9965 | 2462.86 | 7.55 | |
| CNN | SMOTE | 0.9993 | 0.9998 | 0.0008 | 0.9969 | 0.9984 | 6242.24 | 30.58 |
| ROS | 0.9994 | 0.9997 | 0.0007 | 0.9974 | 0.9985 | 6028.14 | 32.23 | |
| ADASYN | 0.9992 | 0.9996 | 0.0009 | 0.9965 | 0.9980 | 6342.18 | 28.46 | |
| RUS + SMOTE | 0.9992 | 0.9996 | 0.0009 | 0.9965 | 0.9980 | 4042.39 | 24.98 | |
| K-means + SMOTE | 0.9993 | 0.9997 | 0.0008 | 0.9969 | 0.9983 | 3956.54 | 22.51 | |
| CSK | 0.9994 | 0.9996 | 0.0006 | 0.9976 | 0.9986 | 3917.58 | 26.29 |
| Model | Imbalanced Algorithms | Acc | Recall | Precision | F1-Score | Train-Times (s) | Test-Times (s) |
|---|---|---|---|---|---|---|---|
| RF | SMOTE | 0.9205 | 0.9205 | 0.9534 | 0.9304 | 80.47 | 0.3441 |
| ROS | 0.9209 | 0.9209 | 0.9532 | 0.9309 | 70.12 | 0.3361 | |
| ADASYN | 0.9231 | 0.9231 | 0.9519 | 0.9318 | 69.77 | 0.3381 | |
| RUS + SMOTE | 0.9232 | 0.9232 | 0.9525 | 0.9322 | 10.08 | 0.3351 | |
| K-means + SMOTE | 0.9223 | 0.9223 | 0.9521 | 0.9314 | 8.64 | 0.3431 | |
| CSK | 0.9312 | 0.9312 | 0.9465 | 0.9348 | 9.21 | 0.34 | |
| MLP | SMOTE | 0.9441 | 0.9441 | 0.9512 | 0.9472 | 1740.83 | 1.38 |
| ROS | 0.9492 | 0.9492 | 0.9530 | 0.9509 | 1595.38 | 0.96 | |
| ADASYN | 0.9374 | 0.9374 | 0.9469 | 0.9421 | 1708.83 | 1.00 | |
| RUS + SMOTE | 0.9378 | 0.9378 | 0.9537 | 0.9439 | 1053.86 | 1.85 | |
| K-means + SMOTE | 0.9414 | 0.9414 | 0.9545 | 0.9465 | 995.43 | 1.09 | |
| CSK | 0.9523 | 0.9523 | 0.9538 | 0.9525 | 988.85 | 0.78 | |
| CNN | SMOTE | 0.9472 | 0.9472 | 0.9588 | 0.9518 | 3223.57 | 4.20 |
| ROS | 0.9477 | 0.9477 | 0.9579 | 0.9517 | 3836.51 | 4.27 | |
| ADASYN | 0.9435 | 0.9435 | 0.9561 | 0.9486 | 3273.56 | 5.10 | |
| RUS + SMOTE | 0.9462 | 0.9462 | 0.9580 | 0.9508 | 1538.40 | 5.23 | |
| K-means + SMOTE | 0.9469 | 0.9469 | 0.9588 | 0.9510 | 1863.28 | 5.09 | |
| CSK | 0.9548 | 0.9548 | 0.9597 | 0.9560 | 1448.41 | 4.26 |
| Model | Imbalanced Algorithms | Acc | Recall | Precision | F1-Score | Train-Times (s) | Test-Times (s) |
|---|---|---|---|---|---|---|---|
| RF | SMOTE | 0.9976 | 0.9976 | 0.9983 | 0.9977 | 32.59 | 1.01 |
| ROS | 0.9976 | 0.9976 | 0.9983 | 0.9977 | 33.96 | 1.00 | |
| ADASYN | 0.9976 | 0.9976 | 0.9983 | 0.9977 | 33.51 | 1.25 | |
| RUS + SMOTE | 0.9977 | 0.9977 | 0.9984 | 0.9978 | 20.81 | 0.90 | |
| K-means + SMOTE | 0.9977 | 0.9977 | 0.9983 | 0.9978 | 35.02 | 0.89 | |
| CSK | 0.9977 | 0.9977 | 0.9983 | 0.9978 | 29.07 | 0.90 | |
| MLP | SMOTE | 0.9978 | 0.9978 | 0.9984 | 0.9979 | 859.77 | 2.08 |
| ROS | 0.9978 | 0.9978 | 0.9981 | 0.9978 | 901.44 | 1.67 | |
| ADASYN | 0.9978 | 0.9978 | 0.9981 | 0.9978 | 893.52 | 1.46 | |
| RUS + SMOTE | 0.9978 | 0.9978 | 0.9984 | 0.9978 | 567.42 | 1.52 | |
| K-means + SMOTE | 0.9977 | 0.9977 | 0.9980 | 0.9977 | 594.05 | 2.06 | |
| CSK | 0.9979 | 0.9979 | 0.9982 | 0.9979 | 540.80 | 1.96 | |
| CNN | SMOTE | 0.9979 | 0.9979 | 0.9985 | 0.9980 | 1638.52 | 4.72 |
| ROS | 0.9979 | 0.9979 | 0.9985 | 0.9980 | 1683.26 | 5.39 | |
| ADASYN | 0.9979 | 0.9979 | 0.9985 | 0.9980 | 1678.92 | 4.36 | |
| RUS + SMOTE | 0.9979 | 0.9979 | 0.9985 | 0.9980 | 669.13 | 6.55 | |
| K-means + SMOTE | 0.9980 | 0.9980 | 0.9985 | 0.9980 | 648.53 | 6.48 | |
| CSK | 0.9980 | 0.9980 | 0.9986 | 0.9982 | 653.85 | 4.73 |
| Dataset | Model | Acc (%) |
|---|---|---|
| UNSW-NB15 | CSCADE-ANN [25] | 95.98 |
| Chameleon [26] | 89.52 | |
| ICVAE-DNN [27] | 89.08 | |
| SMOTE + GMM [19] | 96.54 | |
| Proposed CSK-CNN | 98.77 | |
| CICIDS2017 | CFS-BA [28] | 99.89 |
| PCA + RF [20] | 99.60 | |
| DNN [18] | 99.57 | |
| PCCN [29] | 99.87 | |
| Proposed CSK-CNN | 99.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Wang, X.; He, M.; Jin, L. CSK-CNN: Network Intrusion Detection Model Based on Two-Layer Convolution Neural Network for Handling Imbalanced Dataset. Information 2023, 14, 130. https://doi.org/10.3390/info14020130
Song J, Wang X, He M, Jin L. CSK-CNN: Network Intrusion Detection Model Based on Two-Layer Convolution Neural Network for Handling Imbalanced Dataset. Information. 2023; 14(2):130. https://doi.org/10.3390/info14020130
Chicago/Turabian StyleSong, Jiaming, Xiaojuan Wang, Mingshu He, and Lei Jin. 2023. "CSK-CNN: Network Intrusion Detection Model Based on Two-Layer Convolution Neural Network for Handling Imbalanced Dataset" Information 14, no. 2: 130. https://doi.org/10.3390/info14020130