
An Intrusion Detection Method for Industrial Control System Based on Machine Learning

Abstract
:1. Introduction
2. Materials and Methods
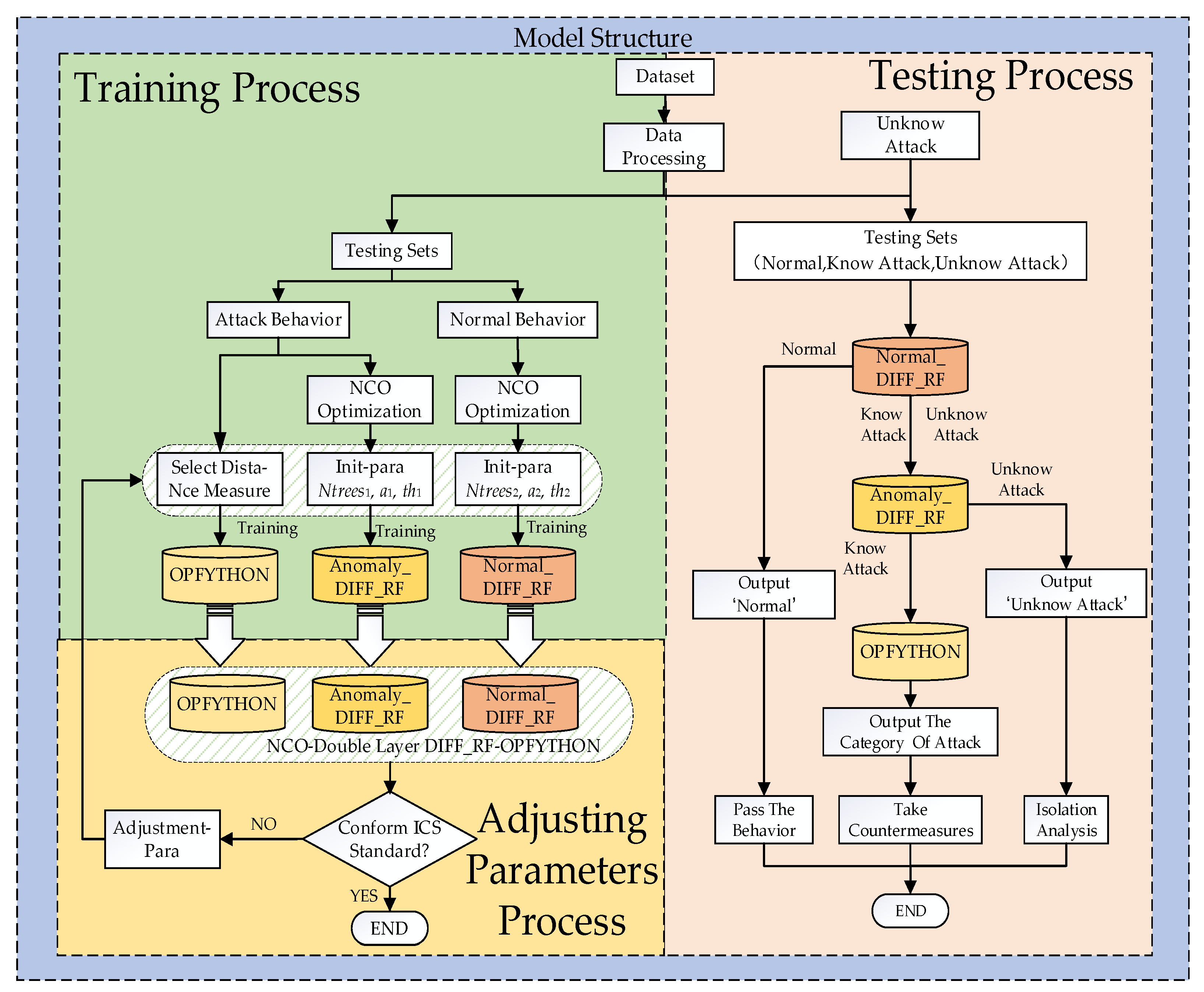
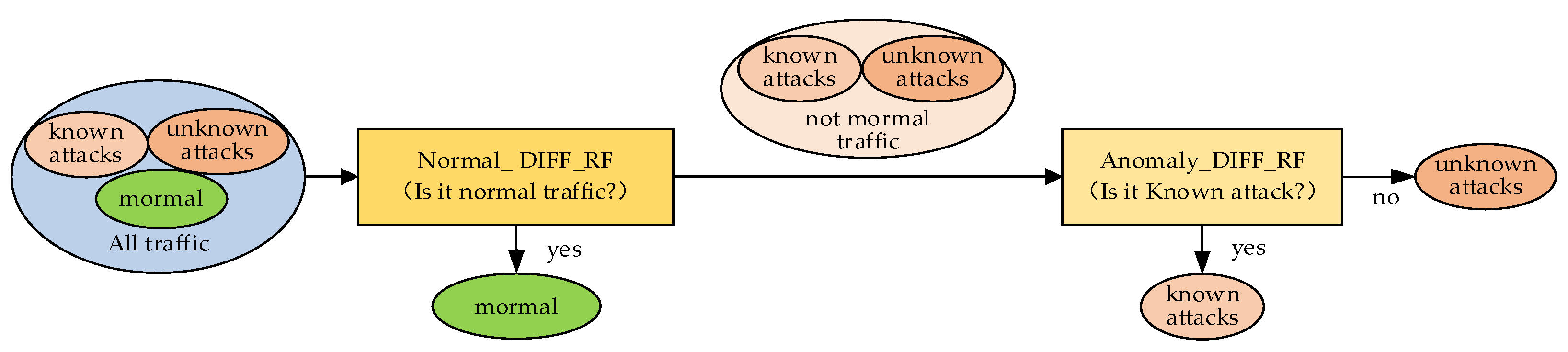
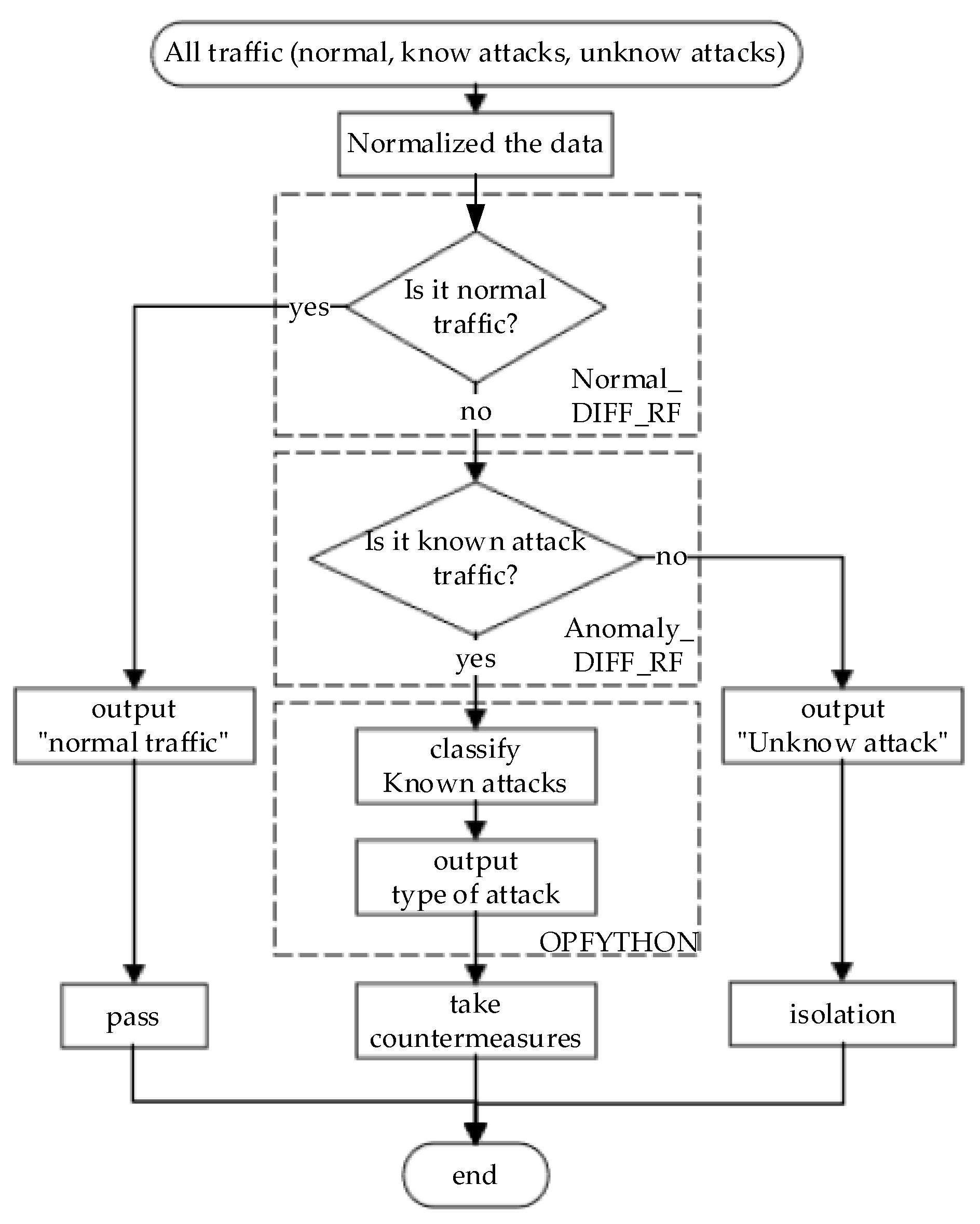
2.1. Normal_DIFF_RF–OPFYTHON Model
2.1.1. DIFF_RF Algorithm
| Algorithm 1 Built a DIFF Tree |
| DIFF_Tree (S, h, hmax) |
| Input (S: a sample randomly drawn from , h: the current depth level, |
| hmax) |
| 2: |
| : |
| 4: |
| 6: else: |
| 9: end if |
| 10: return leafNode (S, MS, σS, ) |
| 11: else: |
| 13: Randomly select a dimension according to distribution D |
| 14: Randomly select a split value P between max and min values along dimension |
| 16: return inNode(Left = DIFF_Tree (, h + 1, ), |
| 17: Right = DIFF_Tree (Sr, h + 1, ), |
| 18: splitAtt = q, splitVal = p) |
| 19: end if |
2.1.2. OPFYTHON Algorithm
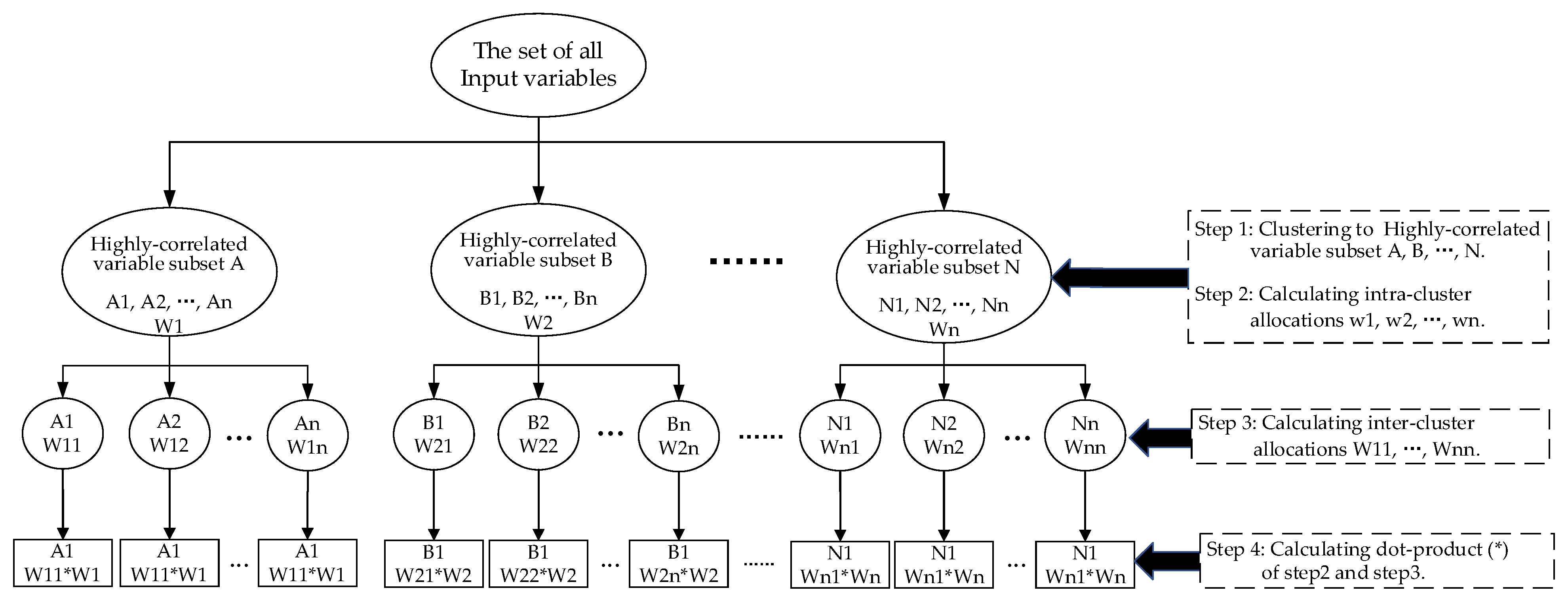
2.2. NCO–Normal_DIFF_RF–OPFYTH Model
2.3. NCO–double-layer DIFF_RF–OPFYTHON Model
3. Results
3.1. Dataset Description
3.2. Evaluation Metrics
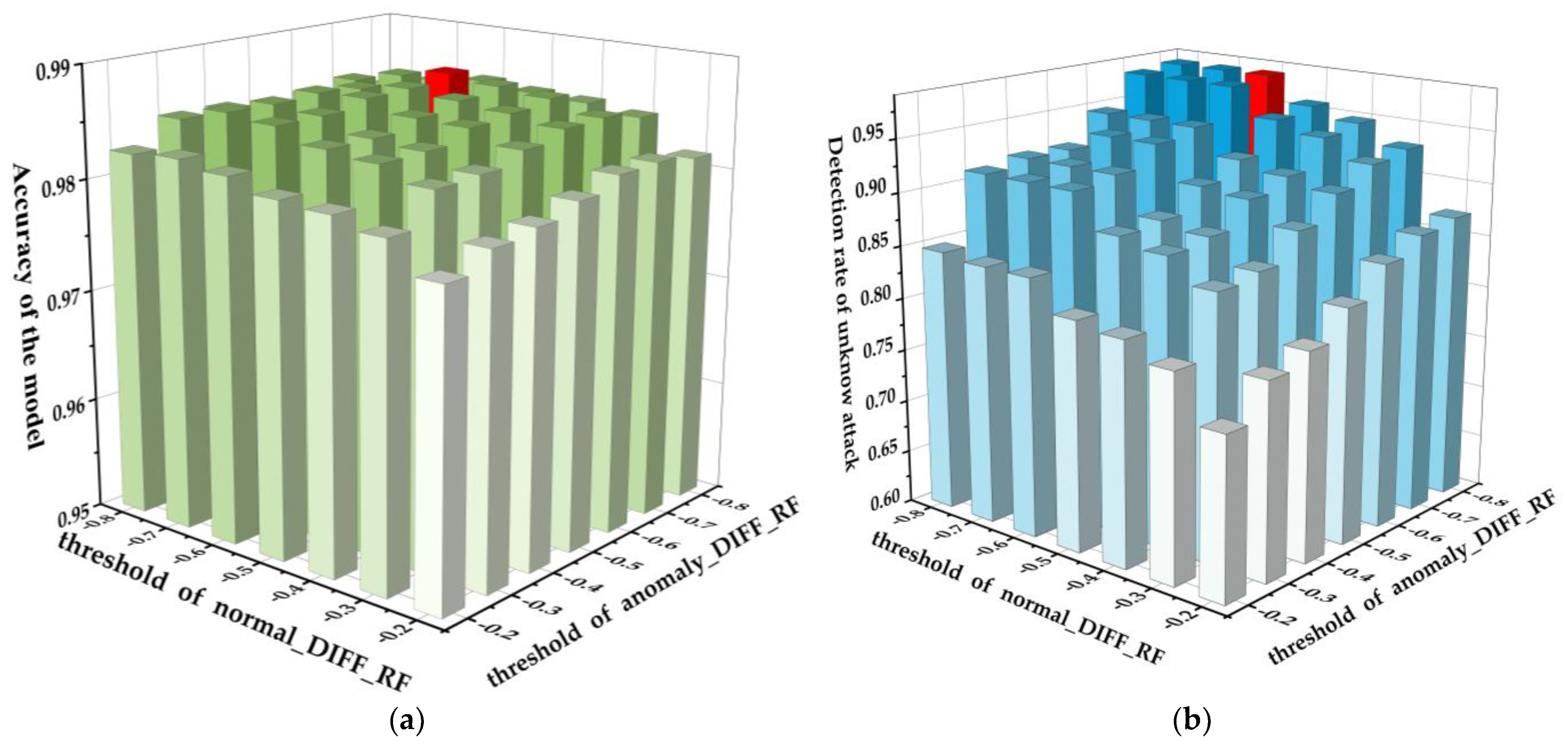
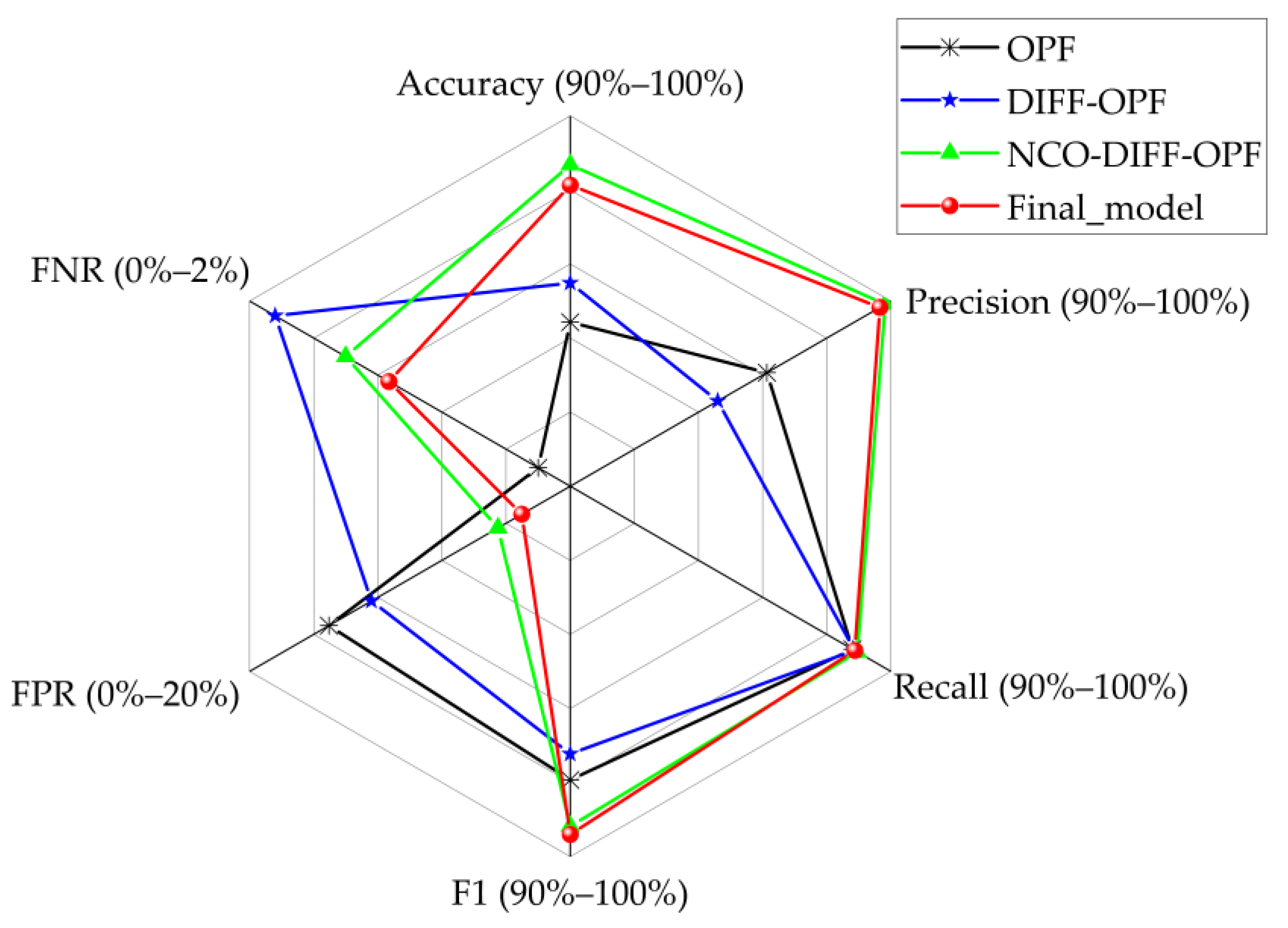
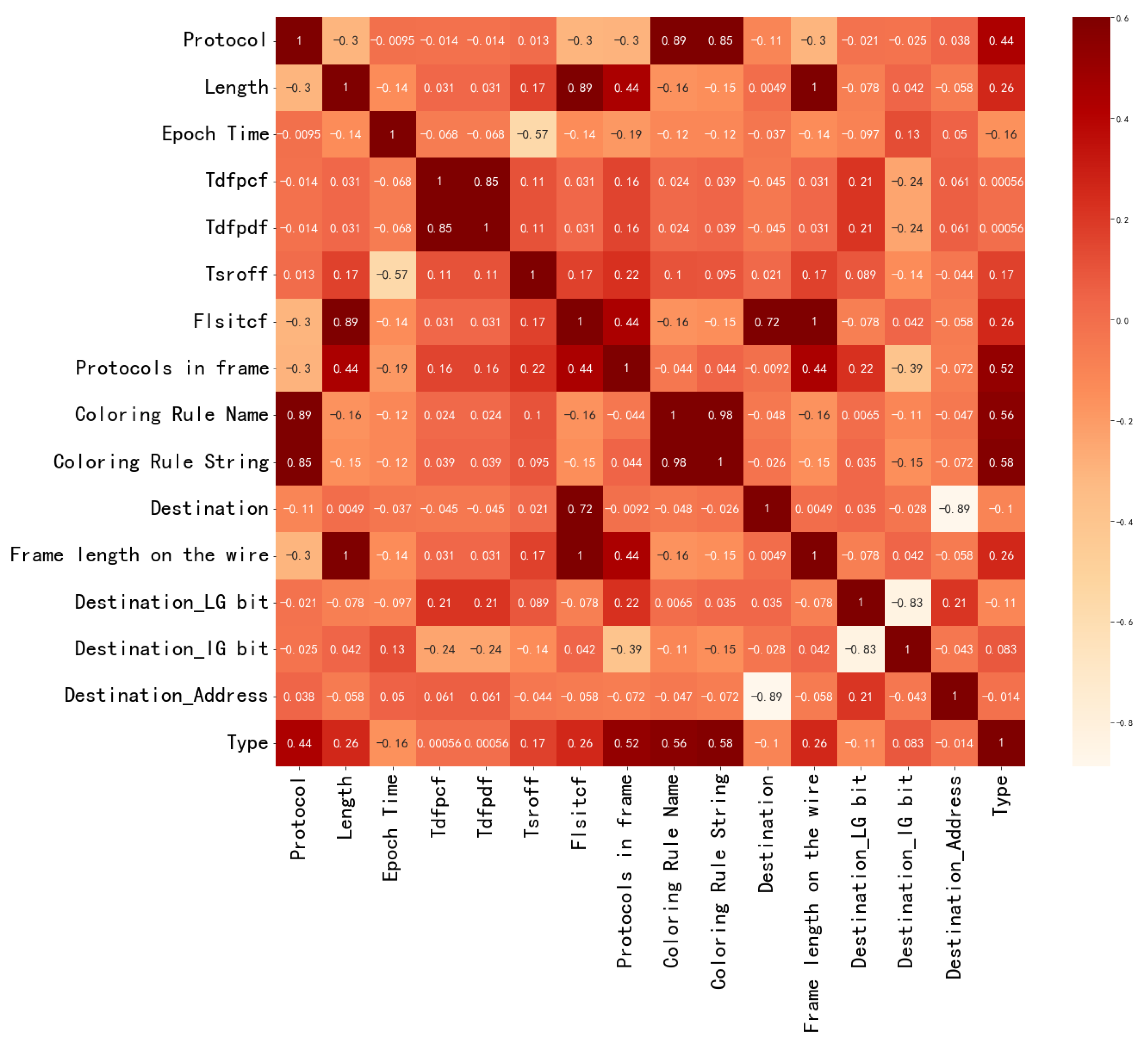
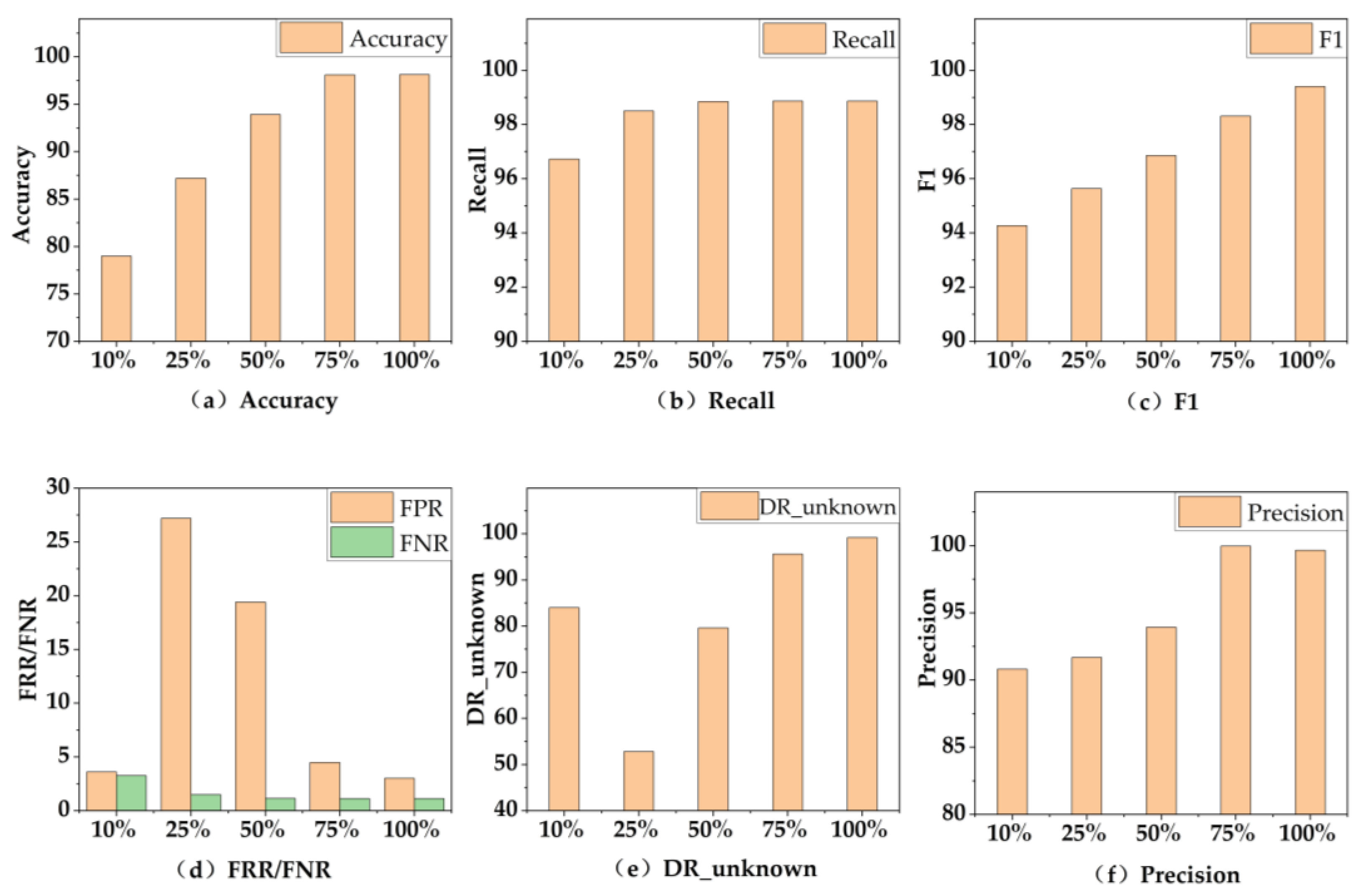
3.3. Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, Y.; Yang, A.; Li, H.; Sun, Y.; Sun, L. A survey of intrusion detection on industrial control systems. Int. J. Distrib. Sens. Netw. 2018, 14, 1550147718794615. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, X.D.; Li, T. A systematic literature review of methods and datasets for anomaly-based network intrusion detection. Comput. Secur. 2022, 116, 102675. [Google Scholar] [CrossRef]
- Shah, S.A.R.; Issac, B. Performance comparison of intrusion detection systems and application of machine learning to Snort system. Future Gener. Comput. Syst. 2018, 80, 157–170. [Google Scholar] [CrossRef]
- Gurina, A.; Eliseev, V.; Gurina, A.; Eliseev, V. Anomaly-Based Method for Detecting Multiple Classes of Network Attacks. Information 2019, 10, 84. [Google Scholar] [CrossRef] [Green Version]
- Hariri, S.; Kind, M.C.; Brunner, R.J. Extended Isolation Forest. IEEE Trans. Knowl. Data Eng. 2019, 33, 1479–1489. [Google Scholar] [CrossRef] [Green Version]
- Niemiec, M.; Kościej, R.; Gdowski, B. Multivariable Heuristic Approach to Intrusion Detection in Network Environments. Entropy 2021, 23, 776. [Google Scholar] [CrossRef]
- Bangui, H.; Buhnova, B. Recent Advances in Machine-Learning Driven Intrusion Detection in Transportation: Survey. Procedia Comput. Sci. 2021, 184, 877–886. [Google Scholar] [CrossRef]
- Kilincer, I.F.; Ertam, F.; Sengur, A. Machine learning methods for cyber security intrusion detection: Datasets and comparative study. Comput. Netw. 2021, 188, 107840. [Google Scholar] [CrossRef]
- Luo, H.; Shi, K.; Qiao, F.; Li, Y. Intrusion Detection Mechanism Based On Modular Neural Network. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 419–423. [Google Scholar]
- Prasath, M.K.; Perumal, B. A meta-heuristic Bayesian network classification for intrusion detection. Int. J. Netw. Manag. 2019, 29, e2047. [Google Scholar] [CrossRef]
- Mukhopadhyay, I.; Gupta, K.S.; Sen, D.; Gupta, P. Heuristic Intrusion Detection and Prevention System. In Proceedings of the 2015 International Conference and Workshop on Computing and Communication (IEMCON), Vancouver, BC, Canada, 15–17 October 2015; pp. 1–7. [Google Scholar]
- Azeroual, O.; Nikiforova, A. Apache Spark and MLlib-Based Intrusion Detection System or How the Big Data Technologies Can Secure the Data. Information 2022, 13, 58. [Google Scholar] [CrossRef]
- Muhuri, P.S.; Chatterjee, P.; Yuan, X.; Roy, K.; Esterline, A. Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks. Information 2020, 11, 243. [Google Scholar] [CrossRef]
- Xiao, Y.; Xiao, X. An Intrusion Detection System Based on a Simplified Residual Network. Information 2019, 10, 356. [Google Scholar] [CrossRef] [Green Version]
- Zheng, D.; Hong, Z.; Wang, N.; Chen, P. An Improved LDA-Based ELM Classification for Intrusion Detection Algorithm in IoT Application. Sensors 2020, 20, 1706. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gauthama Raman, M.R.; Somu, N.; Jagarapu, S.; Manghnani, T.; Selvam, T.; Krithivasan, K.; Shankar Sriram, V.S. An efficient intrusion detection technique based on support vector machine and improved binary gravitational search algorithm. Artif. Intell. Rev. 2020, 53, 3255–3286. [Google Scholar] [CrossRef]
- Wang, Z.; Cha, Y.-J. Unsupervised deep learning approach using a deep auto-encoder with a one-class support vector machine to detect damage. Struct. Health Monit. 2021, 20, 406–425. [Google Scholar] [CrossRef]
- Marteau, P.F. Random Partitioning Forest for Point-Wise and Collective Anomaly Detection—Application to Network Intrusion Detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2157–2172. [Google Scholar] [CrossRef]
- de Rosa, G.H.; Roder, M.; Papa, J.P. Comparative Study Between Distance Measures On Supervised Optimum-Path Forest Classification. arXiv arXiv:2202.03854.
- Prado, M. A Robust Estimator of the Efficient Frontier. SSRN Electron. J. 2019, 10, 2139. [Google Scholar]
- Liu, L.; Wang, P.; Lin, J.; Liu, L. Intrusion Detection of Imbalanced Network Traffic Based on Machine Learning and Deep Learning. IEEE Access 2020, 9, 7550–7563. [Google Scholar] [CrossRef]
- Fotiadou, K.; Velivassaki, T.-H.; Voulkidis, A.; Skias, D.; Tsekeridou, S.; Zahariadis, T. Network Traffic Anomaly Detection via Deep Learning. Information 2021, 12, 215. [Google Scholar] [CrossRef]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Mokhtari, S.; Abbaspour, A.; Yen, K.K.; Sargolzaei, A. A Machine Learning Approach for Anomaly Detection in Industrial Control Systems Based on Measurement Data. Electronics 2021, 10, 407. [Google Scholar] [CrossRef]
- Zhou, Y.L.; Xie, L.; Pan, H. Research on a PSO-H-SVM-Based Intrusion Detection Method for Industrial Robotic Arms. Appl. Sci.-Basel 2022, 12, 2765. [Google Scholar] [CrossRef]
- Zhao, S.; Guo, Y.; Sheng, Q.; Shyr, Y. Advanced heat map and clustering analysis using heatmap3. Biomed. Res. Int. 2014, 2014, 986048. [Google Scholar] [CrossRef] [Green Version]
- Hsu, H.H.; Hsieh, C.W. Feature Selection via Correlation Coefficient Clustering. JSW 2010, 5, 1371–1377. [Google Scholar] [CrossRef]
- Dhaliwal, S.; Nahid, A.A.; Abbas, R. Effective Intrusion Detection System Using XGBoost. Information 2018, 9, 149. [Google Scholar] [CrossRef] [Green Version]
- Tao, P.Y.; Sun, Z.; Sun, Z.X. An Improved Intrusion Detection Algorithm Based on GA and SVM. IEEE Access 2018, 6, 13624–13631. [Google Scholar] [CrossRef]
- Panigrahi, R.; Borah, S.; Bhoi, A.K.; Ijaz, M.F.; Pramanik, M.; Kumar, Y.; Jhaveri, R.H. A Consolidated Decision Tree-Based Intrusion Detection System for Binary and Multiclass Imbalanced Datasets. Mathematics 2021, 9, 751. [Google Scholar] [CrossRef]
- Zhang, J.; Zulkernine, M.; Haque, A. Random-forests-based network intrusion detection systems. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2008, 38, 649–659. [Google Scholar] [CrossRef]
- Morris, T.H.; Thornton, Z.; Turnipseed, I. Industrial control system simulation and data logging for intrusion detection system research. In Proceedings of the 7th Annual Southeastern Cyber Security Summit, Huntsville, AL, USA, 3–4 June 2015; pp. 3–4. [Google Scholar]
- Shukla, A.K. Detection of anomaly intrusion utilizing self-adaptive grasshopper optimization algorithm. Neural Comput. Appl. 2021, 33, 7541–7561. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Label | Count | Imbalance |
|---|---|---|---|
| Natural | 0 | 30,000 | 1 |
| Arp | 1 | 2000 | 15 |
| DDoS | 2 | 2000 | 15 |
| Socket | 3 | 2000 | 15 |
| Nmap | 4 | 2000 | 15 |
| Scapy | 5 | 500 | 60 |
| True | False | |
|---|---|---|
| Positive | TP | FP |
| Negative | FN | TN |
| Acc | Pr | Rec | F1 | Fpr | Fnr | Dr- Arp | Dr- DDOS | Dr- Socket | Dr- Nmap | Dr- Unknown | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random Forset | 92.21 | 91.17 | 99.93 | 95.35 | 36.30 | 0.06 | 97.60 | 99.10 | 8.20 | 44.80 | no |
| Decision Tree | 90.74 | 99.85 | 98.59 | 99.22 | 15.50 | 1.41 | 99.80 | 0 | 98.40 | 46.80 | no |
| SVM | 93.44 | 95.27 | 99.84 | 97.50 | 18.60 | 0.16 | 99.80 | 98.50 | 51.80 | 26.20 | no |
| XGboost | 93.63 | 96.77 | 98.60 | 97.68 | 12.35 | 1.40 | 99.80 | 99.30 | 98.40 | 1.60 | no |
| NCO–normal_DIFF–OPF | 98.68 | 99.82 | 98.55 | 99.18 | 4.50 | 1.40 | 99.80 | 100 | 99.00 | 91.80 | no |
| NCO–double-layer DIFF–OPF | 98.13 | 99.95 | 98.87 | 99.40 | 3.20 | 1.13 | 97.40 | 99.80 | 97.00 | 86.20 | 98.21 |
| Acc | Pr | Rec | F1 | Fpr | Fnr | Dr_Known 1 | Dr_Unknown | |
|---|---|---|---|---|---|---|---|---|
| Gas pipeline | 97.97 | 99.32 | 97.52 | 98.41 | 1.18 | 2.48 | 99.80 | 97.87 |
| CIC-IDS-2017 | 96.82 | 99.19 | 95.18 | 97.14 | 0.99 | 4.82 | 98.36 | 99.40 |
| This paper | 98.13 | 99.95 | 98.87 | 99.40 | 3.20 | 1.13 | 95.10 | 98.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Zhang, L.; Zhao, X.; Jin, K.; Chen, Z. An Intrusion Detection Method for Industrial Control System Based on Machine Learning. Information 2022, 13, 322. https://doi.org/10.3390/info13070322
Cao Y, Zhang L, Zhao X, Jin K, Chen Z. An Intrusion Detection Method for Industrial Control System Based on Machine Learning. Information. 2022; 13(7):322. https://doi.org/10.3390/info13070322
Chicago/Turabian StyleCao, Yixin, Lei Zhang, Xiaosong Zhao, Kai Jin, and Ziyi Chen. 2022. "An Intrusion Detection Method for Industrial Control System Based on Machine Learning" Information 13, no. 7: 322. https://doi.org/10.3390/info13070322