Extracting Typhoon Disaster Information from VGI Based on Machine Learning



Abstract
:1. Introduction
1.1. Background
1.2. Analysis of Existing Studies
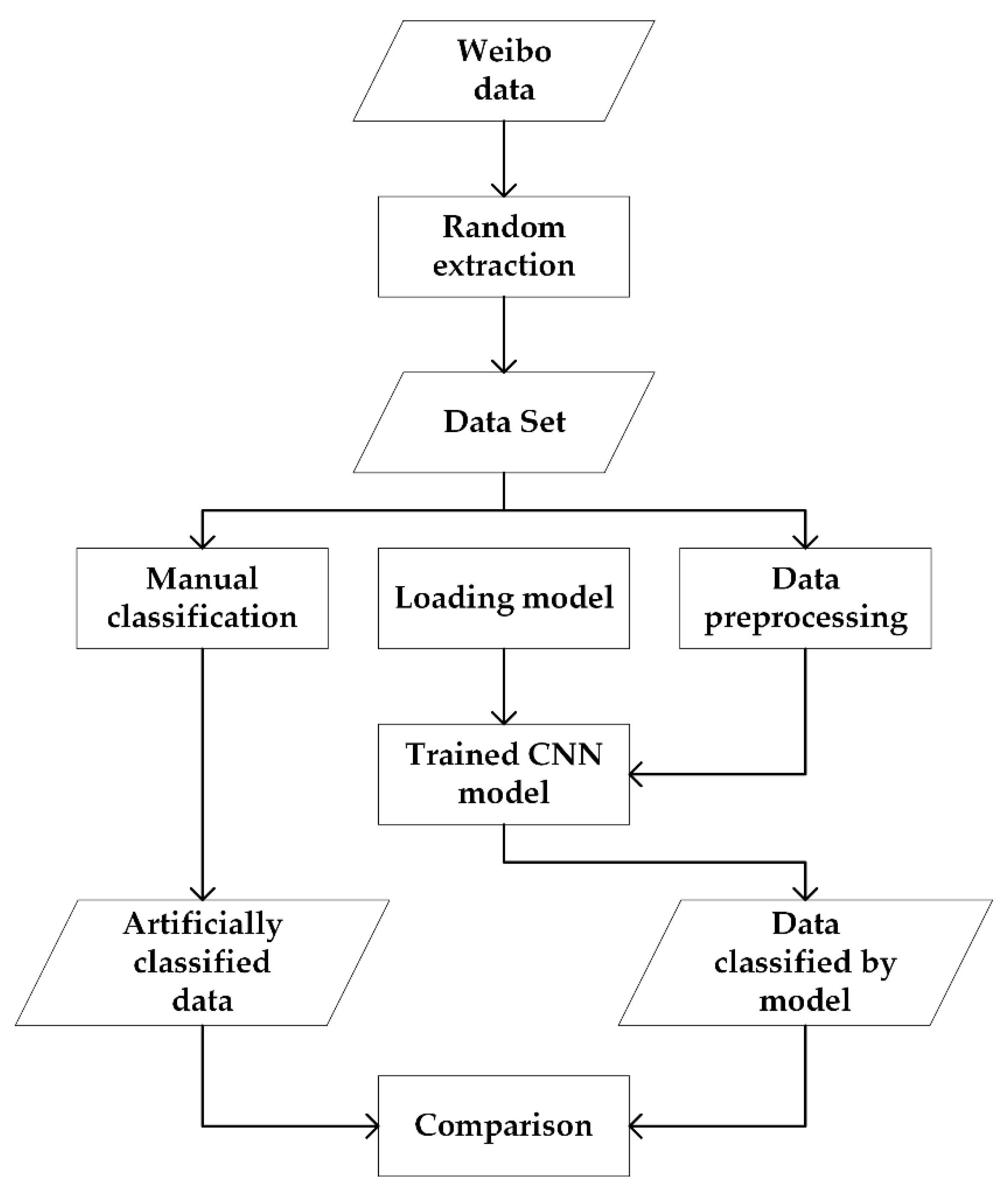
2. Methodology
2.1. Design of Classification
- Building: Weibo content mainly describing damage to buildings, such as water flooding into the house, buildings destroyed, billboards blown off, etc;
- Green plants: Weibo content mainly describing damage to trees, green belts, etc. in the city;
- Transportation: Weibo content mainly describing road flooding caused by the typhoon, poor traffic, etc.;
- Water and electricity: Weibo content mainly describing water being cut off and power cuts caused by typhoons;
- Other: Data related to typhoon disaster information, but not explicitly related to the above categories;
- Useless: Data that were not related to the above categories.
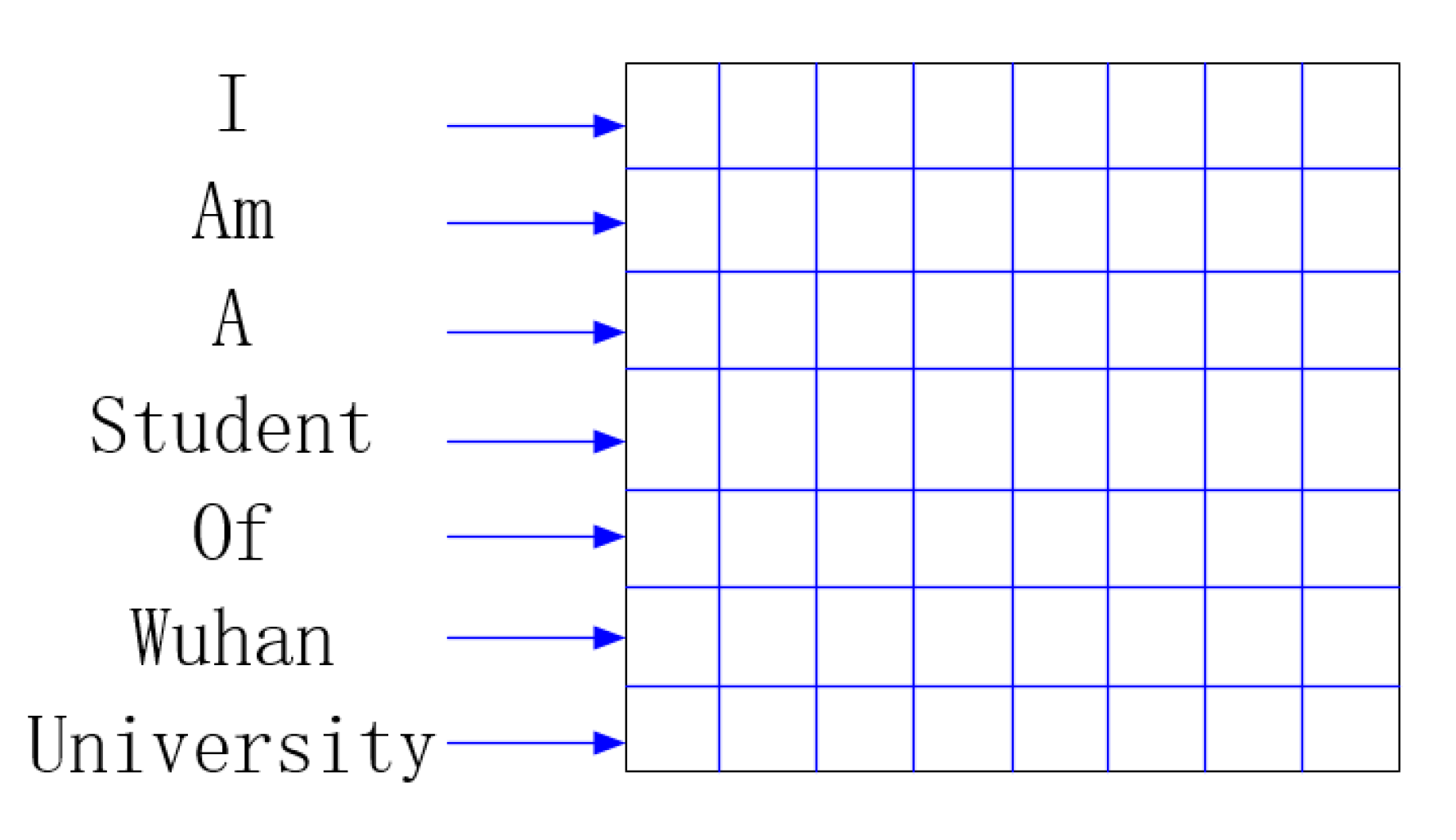
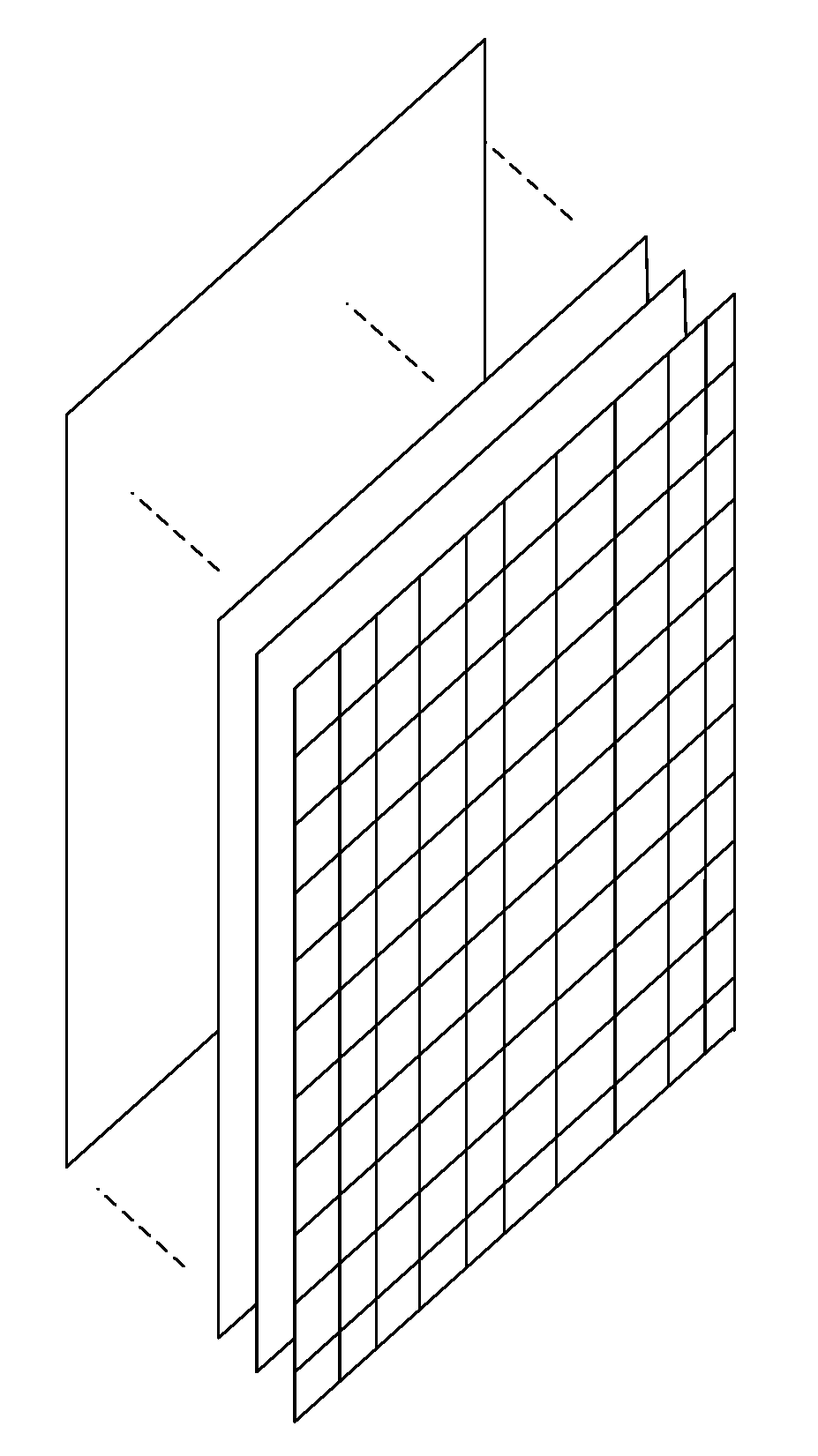
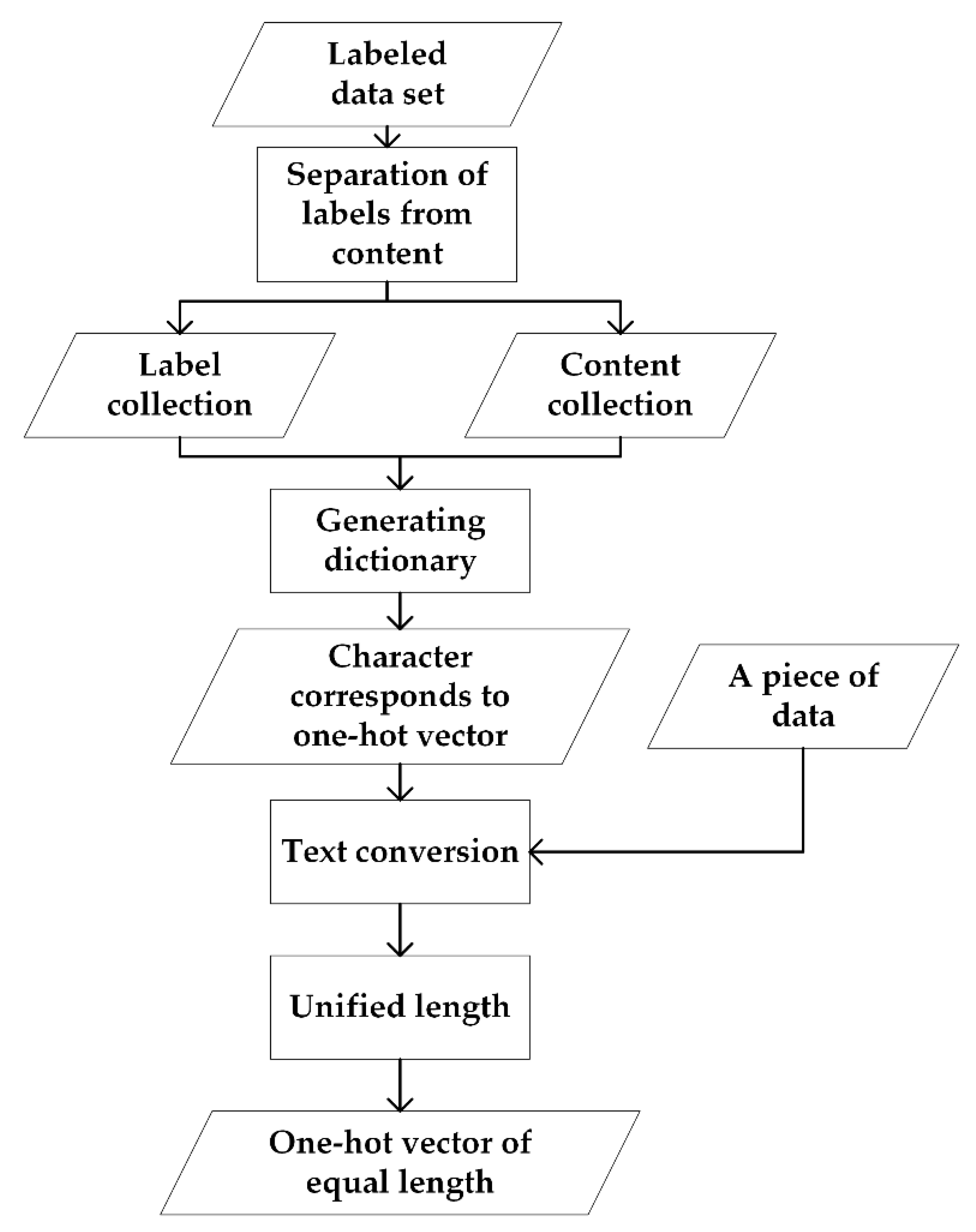
2.2. Text Representation
2.3. Model Construction
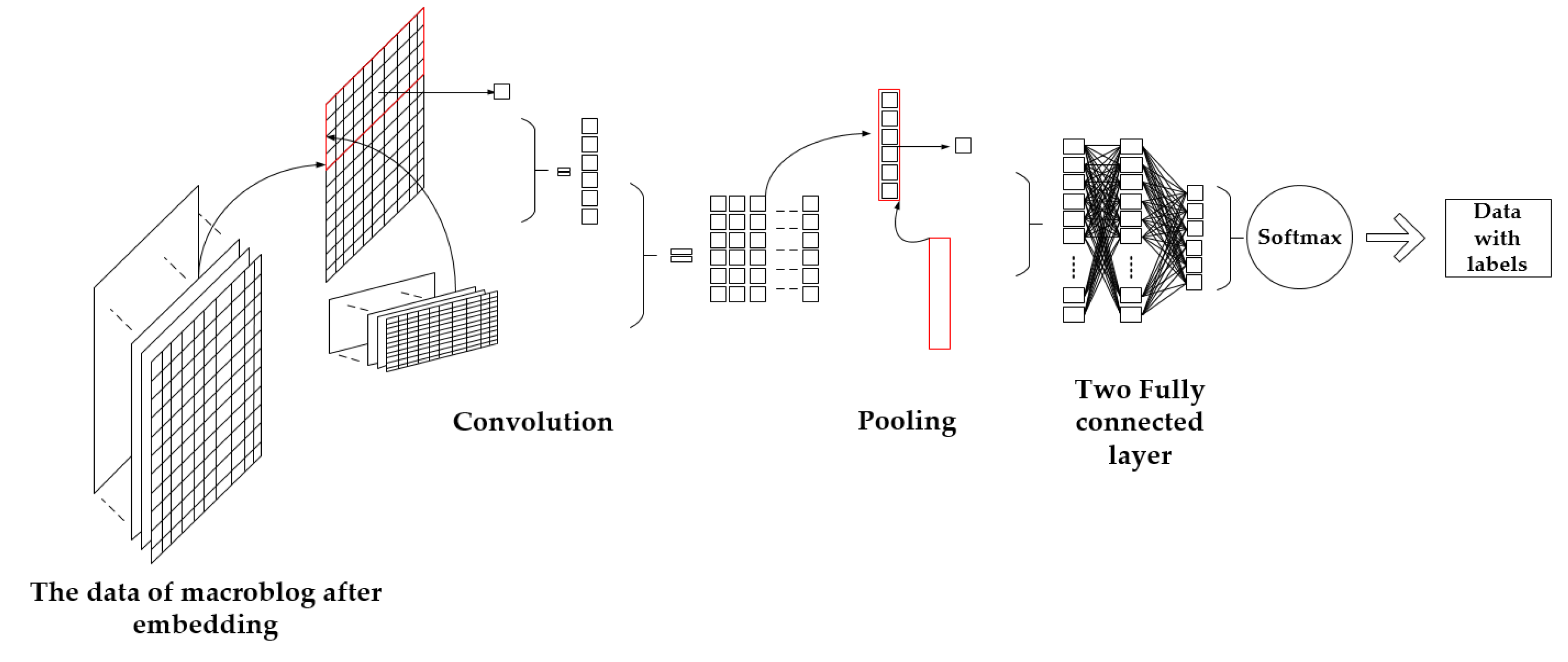
2.3.1. Structure of Model
2.3.2. The Loss Function
3. Case Study
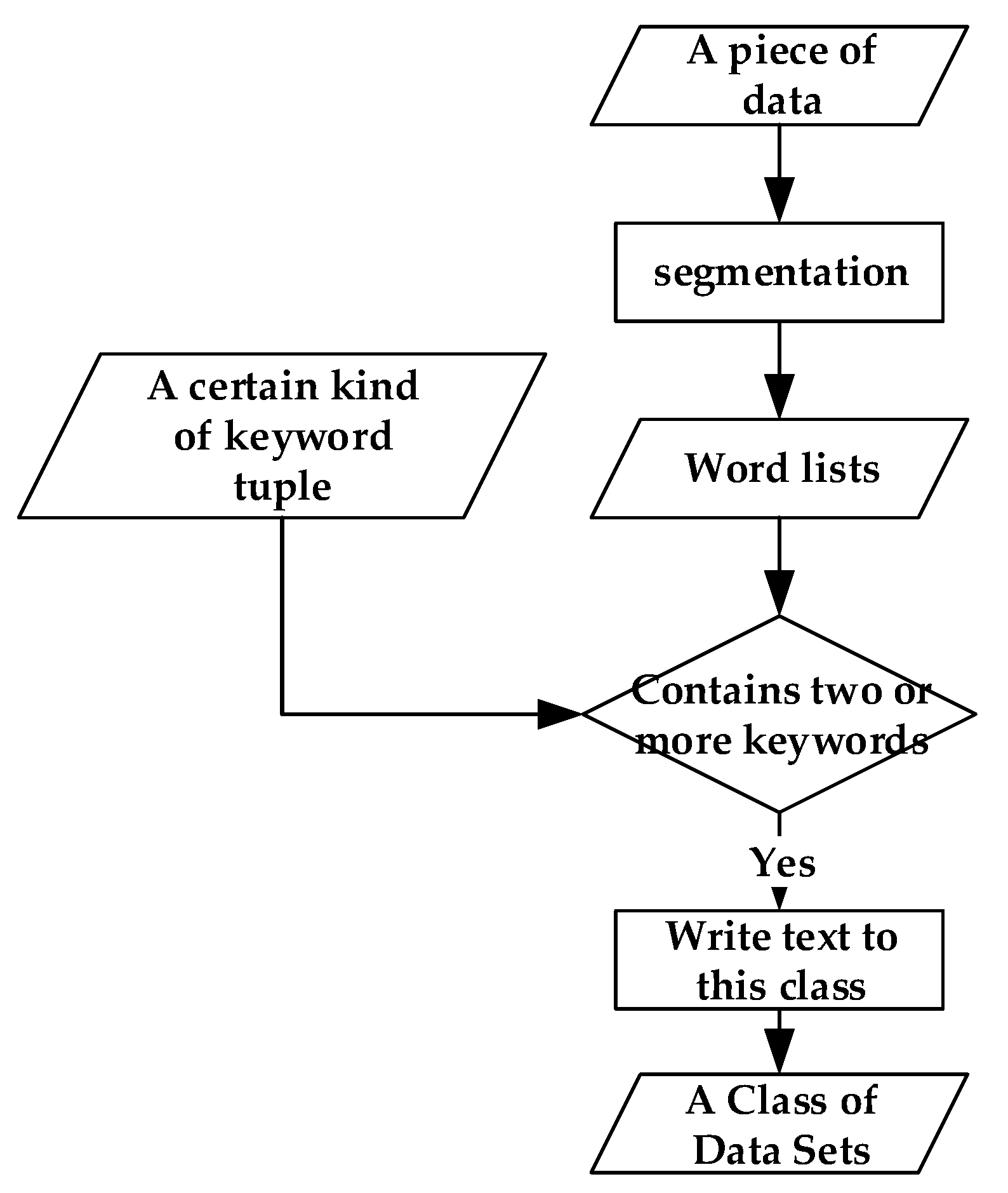
3.1. Data Preprocessing
- (1)
- /Green plants/tab/After the typhoon, the trees on the side of the road fell down and the traffic lights were broken./
- (2)
- /Water and electricity/tab/#typhoon# Go ahead, it’s all the sound of the wind and the wind..., And it’s still out of power./
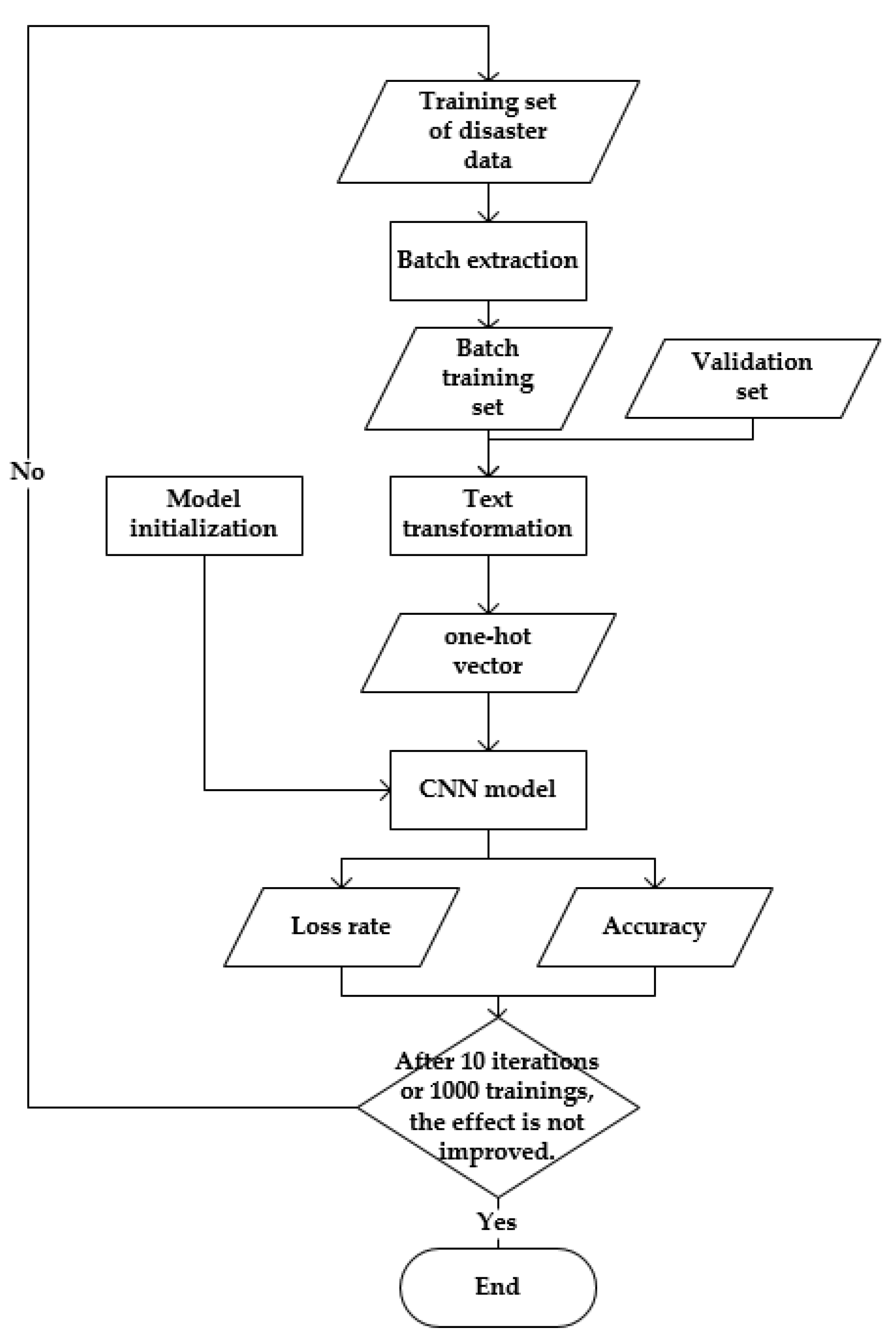
3.2. Training and Verification
3.2.1. Generation of the Dictionary and the One-Hot Vector
3.2.2. Construction of the CNN Model
3.2.3. Training and Testing
3.3. Discussion
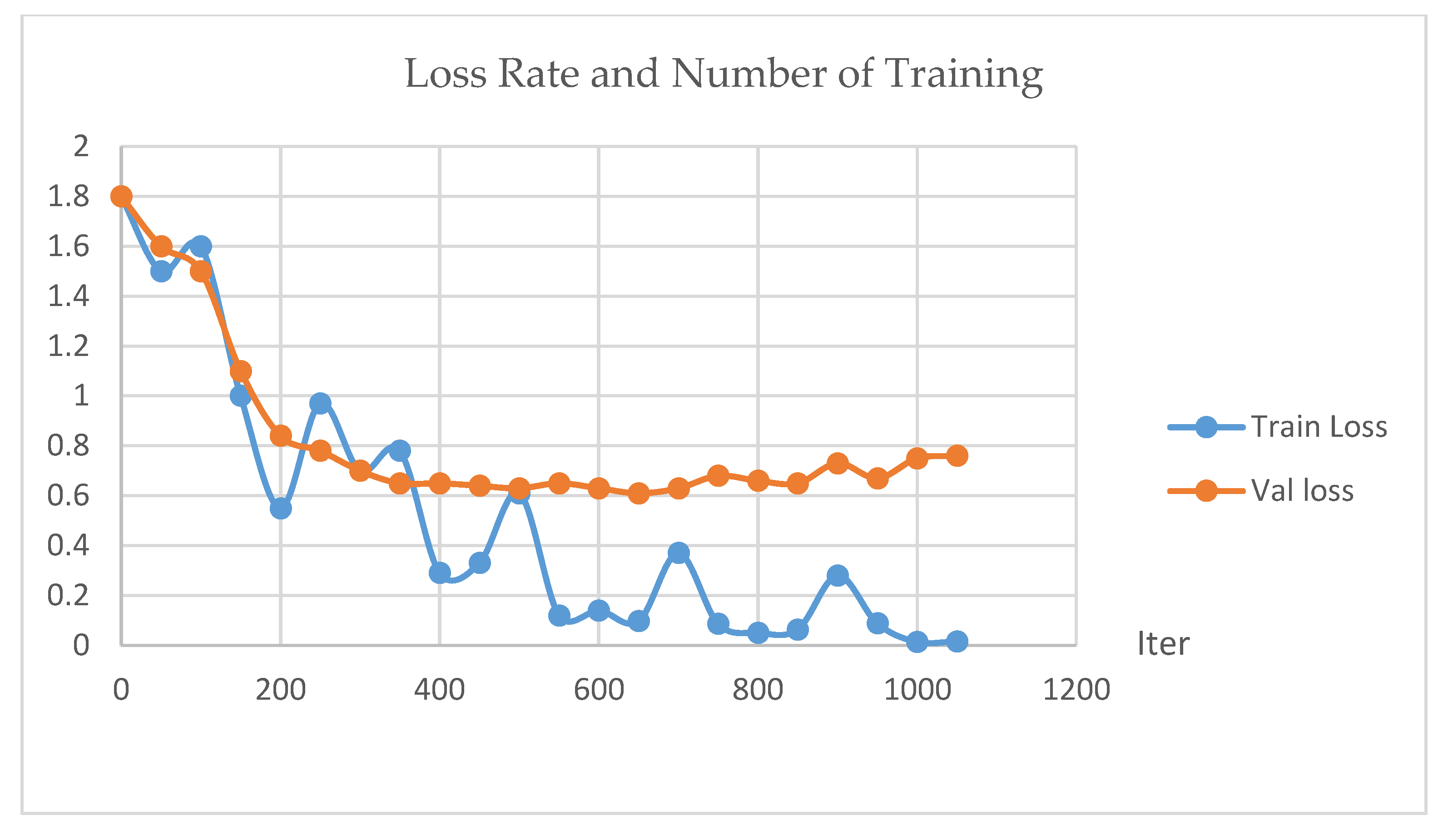
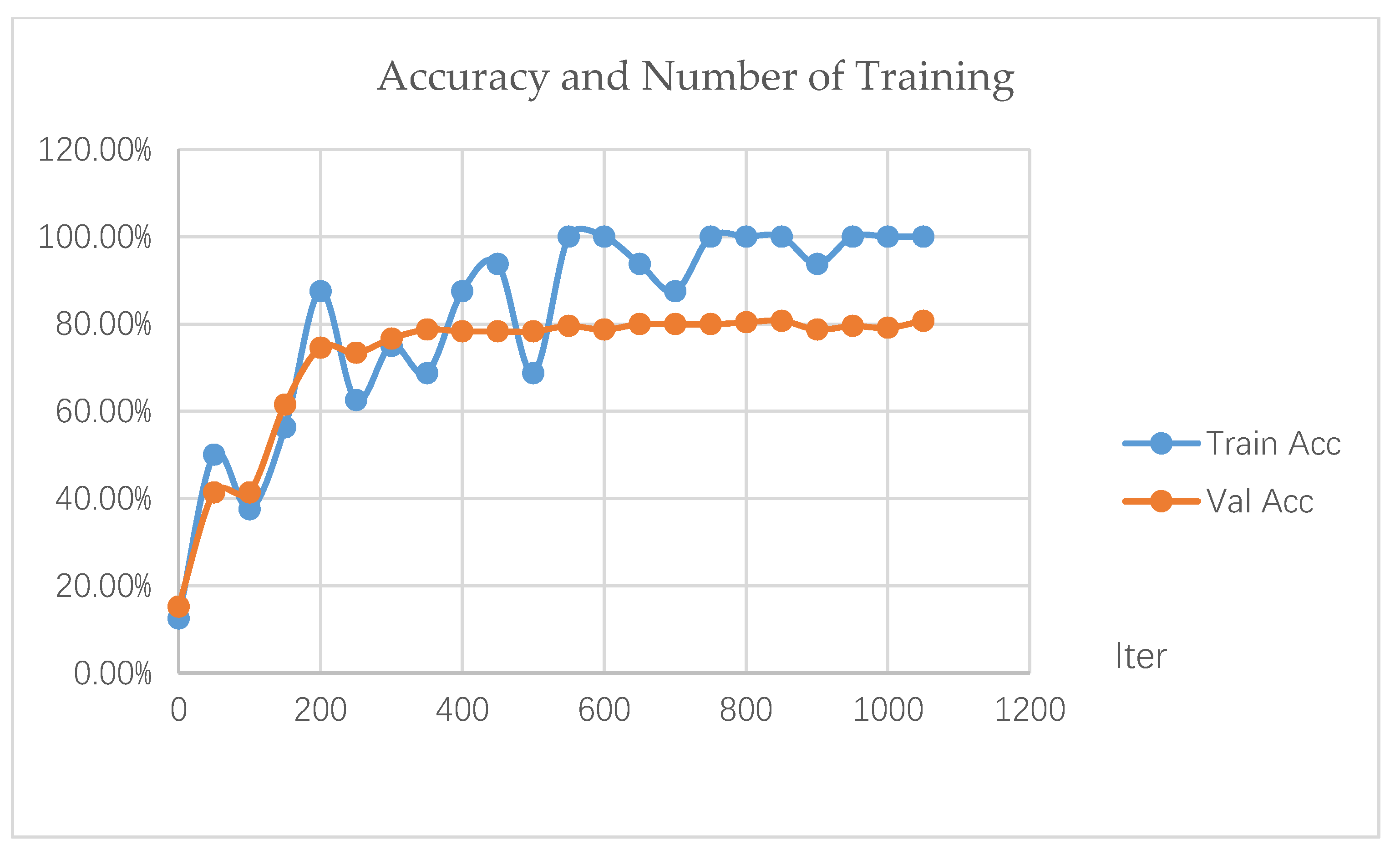
3.3.1. Description of Training Results
3.3.2. Description of Test Results
3.3.3. Comparison of Results of Datasets with Different Sizes
3.3.4. Actual Forecasting Effect
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Li, D.R.; Qian, X.L. A Brief Introduction of Data Management for Volunteered Geographic Information. Geom. Inf. Sci. Wuhan Univ. 2010, 35, 379–383. [Google Scholar]
- Turner, A. The role of angularity in route choice: an analysis of motorcycle courier GPS traces. In Proceedings of the Spatial Information Theory, Aber Wrac’h, France, 21–25 September 2009; pp. 489–504. [Google Scholar]
- Heipke, C. Crowd Sourcing Geospatial Data. ISPRS J. Photogramm. Remote Sens. 2010, 65, 550–557. [Google Scholar] [CrossRef]
- Starbird, K. Digital Volunteerism During Disaster: Crowdsourcing Information Processing. In Proceedings of the Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 7–12. [Google Scholar]
- Shan, J.; Qin, K.; Huang, C.; Hu, X.; Yu, Y.; Hu, Q.; Lin, Z.; Chen, J.P.; Jia, T. Methods of Crowd Sourcing Geographic Data Processing and Analysis. Geom. Inf. Sci. Wuhan Univ. 2014, 39, 390–396. [Google Scholar]
- Yates, D.; Paquette, S. Emergency knowledge management and social media technologies: A case study of the 2010 Haitian earthquake. Int. J. Inf. Manag. 2011, 31, 6–13. [Google Scholar] [CrossRef]
- Camponovo, M.E.; Freundschuh, S.M. Assessing uncertainty in VGI for emergency response. Cartogr. Geogr. Inf. Sci. 2014, 41, 440–455. [Google Scholar] [CrossRef]
- Liu, S.B. Crisis Crowdsourcing Framework: Designing Strategic Configurations of Crowdsourcing for the Emergency Management Domain. Comput. Supported Cooper. Work 2014, 23, 389–443. [Google Scholar] [CrossRef]
- Niu, H.Y.; Liu, M.; Lu, M.; Quan, R.S.; Zhang, L.J.; Wang, J.J. Risk Assessment of Typhoon Disasters in China Coastal Area during Last 20 Years. Sci. Geogr. Sin. 2011, 31, 764–768. [Google Scholar]
- Wang, L.H.; Hovy, E.; Dredze, M. The Hurricane Sandy Twitter Corpus. In Proceedings of the AAAI Workshop on the World Wide Web and Public Health Intelligence, Quebec, QC, Canada, 27 July 2014; pp. 20–24. [Google Scholar]
- Qu, Y.; Huang, C.; Zhang, P. Microblogging after a Major Disaster in China: A Case Study of the 2010 Yushu Earthquake. In Proceedings of the 2011 ACM Conference on Computer Supported Cooperative Work, CSCW 2011, Hangzhou, China, 19–23 March 2011. [Google Scholar]
- Yury, K.; Haohui, C.; Esteban, M. Performance of Social Network Sensors during Hurricane Sandy. PLoS ONE 2015, 10, e0117288. [Google Scholar]
- Wang, Y.D.; Wang, T.; Ye, X.Y. Using Social Media for Emergency Response and Urban Sustainability: A Case Study of the 2012 Beijing Rainstorm. Sustainability 2015, 8, 142–143. [Google Scholar] [CrossRef]
- Wang, D.; Qi, C.; Wang, H. Improving emergency response collaboration and resource allocation by task network mapping and analysis. Saf. Sci. 2014, 70, 9–18. [Google Scholar] [CrossRef]
- Lerman, K.; Ghosh, R. Information Contagion: An Empirical Study of the Spread of News on Digg and Twitter Social Networks. Comput. Sci. 2010, 52, 166–176. [Google Scholar]
- Lazo, J.K.; Bostrom, A.; Morss, R.E. Factors Affecting Hurricane Evacuation Intentions. Risk Anal. 2015, 35, 1837. [Google Scholar] [CrossRef] [PubMed]
- Dittus, M.; Quattrone, G.; Capra, L. Mass Participation during Emergency Response: Event-centric Crowdsourcing in Humanitarian Mapping. In Proceedings of the Acm Conference on Computer Supported Cooperative Work & Social Computing, Portland, OR, USA, 25 February–1 March 2017. [Google Scholar]
- Zhao, Q.S.; Chen, Z.; Liu, C.; Luo, N.X. Extracting and classifying typhoon disaster information based on volunteered geographic information from Chinese Sina microblog. Concurr. Comput. Pract. Exp. 2019, 31, e4910. [Google Scholar] [CrossRef]
- Neppalli, V.K.; Caragea, C.; Squicciarini, A.; Stehle, S. Sentiment analysis during Hurricane Sandy in emergency response. Int. J. Disaster Risk Reduct. 2017, 21, 213–222. [Google Scholar] [CrossRef] [Green Version]
- Neppalli, V.K.; Caragea, C.; Caragea, D.; Medeiros, M.C.; Tapia, A.H.; Halse, S.E. Predicting tweet retweetability during hurricane disasters. Int. J. Inf. Syst. Crisis Response Manage. 2016, 8, 32–50. [Google Scholar] [CrossRef]
- Kogan, M.; Palen, L.; Anderson, K.M. Think Local, Retweet Global: Retweeting by the Geographically-Vulnerable during Hurricane Sandy. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015. [Google Scholar]
- Guikema, S.D.; Nateghi, R.; Quiring, S.M. Predicting Hurricane Power Outages to Support Storm Response Planning. IEEE Access 2017, 2, 1364–1373. [Google Scholar] [CrossRef]
- Neppalli, V.K.; Caragea, C.; Caragea, D. Deep Neural Networks versus Naive Bayes Classifiers for Identifying Informative Tweets during Disasters. In Proceedings of the Information Systems for Crisis Response and Management Asia Pacific Conference, Rochester, NY, USA, 20–23 May 2018. [Google Scholar]
- Chew, C.; Eysenbach, G. Pandemics in the Age of Twitter: Content Analysis of Tweets during the 2009 H1N1 Outbreak. PLoS ONE 2010, 5, e14118. [Google Scholar] [CrossRef] [PubMed]
- Imran, M.; Diaz, F.; Elbassuoni, S. Practical Extraction of Disaster-Relevant Information from Social Media. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Michael, A. Nielsen, Neural Networks and Deep Learning, Determination Press 2015. Available online: http://neuralnetworksanddeeplearning.com (accessed on 22 July 2019).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 8–13 December 2013; pp. 3111–3119. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. Comput. Sci. 2014, arXiv:1408.5882. [Google Scholar] [Green Version]
- Zhang, X.; Zhao, J.; Lecun, Y. Character-level Convolutional Networks for Text Classification. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Provinces (Cities) | People Affected | Transferred | Died | Houses Collapsed | Damaged |
|---|---|---|---|---|---|
| Zhejiang | 7,010,000 | 1,546,000 | 0 | 5100 | 15,000 |
| Shanghai | 361,000 | 311,000 | 2 | 50 | 700 |
| Jiangsu | 662,000 | 126,000 | 1 | 600 | 2400 |
| Anhui | 1,576,000 | 163,000 | 0 | 1500 | 13,000 |
| Epoch | Iter | Train Loss | Train Acc | Val Loss | Val Acc |
|---|---|---|---|---|---|
| 1 | 0 | 1.8 | 12.50% | 1.8 | 15.16% |
| 50 | 1.5 | 50.00% | 1.6 | 41.39% | |
| 100 | 1.6 | 37.50% | 1.5 | 41.39% | |
| 2 | 150 | 1 | 56.25% | 1.1 | 61.48% |
| 200 | 0.55 | 87.50% | 0.84 | 74.59% | |
| 3 | 250 | 0.97 | 62.50% | 0.78 | 73.36% |
| 300 | 0.7 | 75.00% | 0.7 | 76.64% | |
| 4 | 350 | 0.78 | 68.75% | 0.65 | 78.69% |
| 400 | 0.29 | 87.50% | 0.65 | 78.28% | |
| 5 | 450 | 0.33 | 93.75% | 0.64 | 78.28% |
| 500 | 0.61 | 68.75% | 0.63 | 78.28% | |
| 6 | 550 | 0.12 | 100.00% | 0.65 | 79.51% |
| 600 | 0.14 | 100.00% | 0.63 | 78.69% | |
| 7 | 650 | 0.097 | 93.75% | 0.61 | 79.92% |
| 700 | 0.37 | 87.50% | 0.63 | 79.92% | |
| 8 | 750 | 0.086 | 100.00% | 0.68 | 79.92% |
| 800 | 0.051 | 100.00% | 0.66 | 80.33% | |
| 850 | 0.064 | 100.00% | 0.65 | 80.74% | |
| 9 | 900 | 0.28 | 93.75% | 0.73 | 78.69% |
| 950 | 0.088 | 100.00% | 0.67 | 79.51% | |
| 10 | 1000 | 0.014 | 100.00% | 0.75 | 79.10% |
| 1050 | 0.0161 | 100.00% | 0.76 | 80.74% |
| Test Loss | 0.62 | Test Acc | 80.29% | |
|---|---|---|---|---|
| Class Name | Precision | Recall | F1-Score | Number of Entries in the Category |
| Building | 0.93 | 0.71 | 0.80 | 55 |
| Green plants | 0.80 | 0.86 | 0.83 | 78 |
| Transportation | 0.87 | 0.70 | 0.78 | 57 |
| Water and electricity | 0.75 | 0.94 | 0.84 | 54 |
| Other | 0.77 | 0.44 | 0.56 | 54 |
| Useless | 0.79 | 0.90 | 0.84 | 189 |
| Mean/sum | 0.81 | 0.80 | 0.80 | 487 |
| Class Name | Building | Green Plants | Transportation | Water and Electricity | Other | Useless |
|---|---|---|---|---|---|---|
| Building | 39 | 1 | 1 | 3 | 0 | 11 |
| Green plants | 1 | 67 | 0 | 2 | 2 | 6 |
| Transportation | 0 | 5 | 40 | 0 | 1 | 11 |
| Water and electricity | 0 | 0 | 0 | 51 | 0 | 3 |
| Other | 0 | 4 | 3 | 8 | 24 | 15 |
| Useless | 2 | 7 | 2 | 4 | 4 | 170 |
| Size of the Dataset | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
| Accuracy | 70.61% | 74.70% | 80.29% | 78.64% | 77.39% | 79.66% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Zhao, Q.; Chin, C.S. Extracting Typhoon Disaster Information from VGI Based on Machine Learning. J. Mar. Sci. Eng. 2019, 7, 318. https://doi.org/10.3390/jmse7090318
Yu J, Zhao Q, Chin CS. Extracting Typhoon Disaster Information from VGI Based on Machine Learning. Journal of Marine Science and Engineering. 2019; 7(9):318. https://doi.org/10.3390/jmse7090318
Chicago/Turabian StyleYu, Jiang, Qiansheng Zhao, and Cheng Siong Chin. 2019. "Extracting Typhoon Disaster Information from VGI Based on Machine Learning" Journal of Marine Science and Engineering 7, no. 9: 318. https://doi.org/10.3390/jmse7090318