
S-DETR: A Transformer Model for Real-Time Detection of Marine Ships

Abstract
:1. Introduction
- (1)
- A ship detection transformer model design based on shore images for the first time. Taking advantage of the global modeling capability of the transformer architecture, the model achieved the best performance on the public dataset, the Singapore Maritime Dataset. The proposed S-DETR model can be used as a baseline model to study transformer-based methods for ship detection.
- (2)
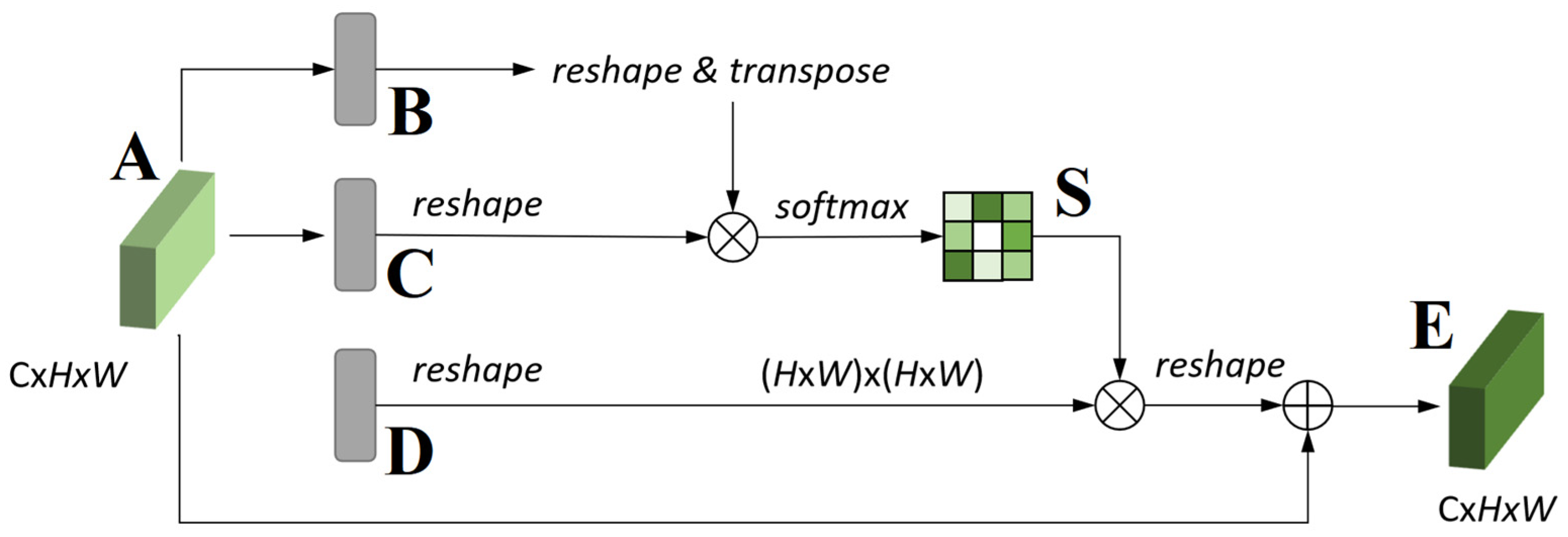
- A scale attention module that fuses multi-scale information is designed in the backbone network, which is better than simply using convolution to fuse different scale branch information in the past. The detection performance can be improved in the scene where the ship scale changes significantly.
- (3)
- We propose a new decoder for DETR, i.e., DQ-decoder, which significantly improves DETR on crowd ship detection. The DQ module can greatly improve the detection performance in dense ship scenes without increasing the computational complexity. The decoder has the potential to serve as a plug-and-play module for other intensive detection tasks.
2. Related Works
2.1. Ship Detection Method Based on Deep Learning
2.2. DETR and Deformable DETR
3. Methods
3.1. Overall Framework
3.2. Scale Attention Module
3.3. Dense Queries
4. Experiments and Results
4.1. Data and Experimental Preparation
4.2. Experimental Results
4.3. Ablation Study
4.3.1. Ablation Study on Scale Attention Module
4.3.2. Ablation Study on Dense Queries
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. SeaShips: A large-scale precisely annotated dataset for ship detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Krüger, W.; Orlov, Z. Robust layer-based boat detection and multi-target-tracking in maritime environments. In Proceedings of the 2010 International WaterSide Security Conference, Carrara, Italy, 3–5 November 2010; pp. 1–7. [Google Scholar]
- Prasad, D.K.; Prasath, C.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Object Detection in A Maritime Environment: Performance Evaluation of Background Subtraction Methods. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1787–1802. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Moosbauer, S.; Konig, D.; Jakel, J.; Teutsch, M. A benchmark for deep learning based object detection in maritime environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 916–925. [Google Scholar]
- Soloviev, V.; Farahnakian, F.; Zelioli, L.; Iancu, B.; Lilius, J.; Heikkonen, J. Comparing CNN-Based Object Detectors on Two Novel Maritime Datasets. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Shao, Z.; Wang, L.; Wang, Z.; Du, W.; Wu, W. Saliency-Aware Convolution Neural Network for Ship Detection in Surveillance Video. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 781–794. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, K.; Hong, S.; Choi, B.; Kim, E. Probabilistic Ship Detection and Classification Using Deep Learning. Appl. Sci. 2018, 8, 936. [Google Scholar] [CrossRef] [Green Version]
- Sanghyun, W.; Jongchan, P.; Joon-Young, L.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, H.; Deng, L.; Yang, C.; Liu, J.; Gu, Z. Enhanced YOLO v3 Tiny Network for Real-Time Ship Detection from Visual Image. IEEE Access 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, N.; Park, Y.W.; Won, C.S. Object Detection and Classification Based on YOLO-V5 with Improved Maritime Dataset. J. Mar. Sci. Eng. 2022, 10, 377. [Google Scholar] [CrossRef]
- Huang, K.C.; Wu, T.H.; Su, H.T.; Hsu, W.H. MonoDTR: Monocular 3D Object Detection with Depth-Aware Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4012–4021. [Google Scholar]
- Dang, L.M.; Wang, H.; Li, Y.; Nguyen, T.N.; Moon, H. DefectTR: End-to-end defect detection for sewage networks using a transformer. Constr. Build. Mater. 2022, 325, 126584. [Google Scholar] [CrossRef]
- Bar, A.; Wang, X.; Kantorov, V.; Reed, C.J.; Herzig, R.; Chechik, G.; Globerson, A. Detreg: Unsupervised pretraining with region priors for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 14605–14615. [Google Scholar]
- Gupta, A.; Narayan, S.; Joseph, K.J.; Khan, S.; Khan, F.S.; Shah, M. OW-DETR: Open-world Detection Transformer. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Wang, H.; Tang, J.; Liu, X. PTSEFormer: Progressive Temporal-Spatial Enhanced TransFormer Towards Video Object Detection. In Proceedings of the 2022 European Conference on Computer Vision, Cham, Switzerland, 24–28 October 2022; pp. 732–747. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Yin, Y.; Guo, Y.; Deng, L.; Chai, B. Improved PSPNet-based water shoreline detection in complex inland river scenarios. Complex Intell. Syst. 2022, 9, 233–245. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 July 2020. [Google Scholar]
- Yin, M.; Yao, Z.; Cao, Y.; Li, X.; Zhang, Z.; Lin, S.; Hu, H. Disentangled non-local neural networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Zou, H.; He, S.; Wang, Y.; Li, R.; Cheng, F.; Cao, X. Ship detection based on medium-low resolution remote sensing data and super-resolved feature representation. Remote Sens. Lett. 2022, 13, 323–333. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, L. Multilayer attention receptive fusion network for multiscale ship detection with complex background. J. Electron. Imaging 2022, 31, 043029. [Google Scholar] [CrossRef]
- Zhang, J.; Cui, Y.; Ren, J. Dynamic Mission Planning Algorithm for UAV Formation in Battlefield Environment. IEEE Trans. Aerosp. Electron. Syst. 2022, 55, 1004–1020. [Google Scholar] [CrossRef]
- Gong, M.; Cao, Y.; Wu, Q. A neighborhood-based ratio approach for change detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 307–311. [Google Scholar] [CrossRef]
- Hakim, W.L.; Achmad, A.R.; Eom, J.; Lee, C.-W. Land Subsidence Measurement of Jakarta Coastal Area Using Time Series Interferometry with Sentinel-1 SAR Data. J. Coast. Res. 2020, 102, 75–81. [Google Scholar] [CrossRef]
- Kang, M.S.; Baek, J.M. SAR Image Reconstruction via Incremental Imaging with Compressive Sensing. IEEE Trans. Aerosp. Electron. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Thota, M.; Leontidis, G. Contrastive domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2209–2218. [Google Scholar]
- Yoon, J.; Kang, D.; Cho, M. Semi-Supervised Domain Adaptation via Sample-to-Sample Self-Distillation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 1978–1987. [Google Scholar]
- Durrant, A.; Leontidis, G. Hyperspherically regularized networks for self-supervision. Image Vision Comput. 2022, 124, 104494. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SMD | MID | ||
|---|---|---|---|---|
| mAP@.5 | FPS | mAP@.5 | FPS | |
| YOLO-V5 [18] | 0.304 | 36.34 | 0.602 | 37.42 |
| Faster-Rcnn [26] | 0.712 | 18.93 | 0.874 | 18.84 |
| SSD [27] | 0.693 | 25.74 | 0.845 | 25.85 |
| CenterNet [28] | 0.734 | 24.51 | 0.891 | 24.28 |
| DETR | 0.578 | 27.85 | 0.713 | 27.72 |
| Deformable DETR | 0.596 | 26.38 | 0.780 | 26.65 |
| S-DETR | 0.778 | 27.98 | 0.914 | 27.41 |
| Backbone | Ferry | Buoy | Ship | Speed Boat | Boat | Kayak | Sail Boat | Other | mAP@.5 |
|---|---|---|---|---|---|---|---|---|---|
| ResNet50 | 0.887 | 0.738 | 0.826 | 0.641 | 0.392 | 0.493 | 0.443 | 0.562 | 0.608 |
| ResNet50+PSPNet | 0.891 | 0.769 | 0.819 | 0.663 | 0.475 | 0.549 | 0.577 | 0.604 | 0.668 |
| ResNet50+PSPNet+Channel Attention | 0.885 | 0.792 | 0.824 | 0.651 | 0.482 | 0.572 | 0.526 | 0.684 | 0.677 |
| ResNet50+PSPNet+Channel Correction | 0.887 | 0.784 | 0.812 | 0.668 | 0.468 | 0.585 | 0.514 | 0.691 | 0.676 |
| ResNet50+PSPNet+Scale Attention | 0.892 | 0.823 | 0.814 | 0.735 | 0.813 | 0.689 | 0.705 | 0.753 | 0.778 |
| DQ Layers | 0 (without DQ) | 0 | 2 | 3 | 6 |
|---|---|---|---|---|---|
| mAP@.5 | 0.742 | 0.767 | 0.778 | 0.776 | 0.775 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, Z.; Ren, J.; Fan, X.; Zhang, Y. S-DETR: A Transformer Model for Real-Time Detection of Marine Ships. J. Mar. Sci. Eng. 2023, 11, 696. https://doi.org/10.3390/jmse11040696
Xing Z, Ren J, Fan X, Zhang Y. S-DETR: A Transformer Model for Real-Time Detection of Marine Ships. Journal of Marine Science and Engineering. 2023; 11(4):696. https://doi.org/10.3390/jmse11040696
Chicago/Turabian StyleXing, Zijian, Jia Ren, Xiaozhong Fan, and Yu Zhang. 2023. "S-DETR: A Transformer Model for Real-Time Detection of Marine Ships" Journal of Marine Science and Engineering 11, no. 4: 696. https://doi.org/10.3390/jmse11040696