1. Introduction
Ship-radiated noise includes airborne noise and underwater noise. Airborne noise mainly influences human health [
1,
2]. For military and security reasons, we pay more attention to underwater noise. At present, deep learning methods applied to Ship-radiated noise featuring learning and classification has become a hot research topic [
3,
4,
5,
6,
7,
8]. Ship-radiated noise featuring learning and classification is an important research direction of underwater acoustic target recognition. From the perspective of sound generation mechanisms, the target radiated noise is considered to be mainly composed of mechanical noise, propeller noise, and hydrodynamic noise [
9]. The difference in the target radiated noise of different types can be reflected in the following aspects: (1) mechanical noise generated by different shipborne mechanical equipment; (2) propeller radiation characteristics being different due to different propeller parameters; and (3) the difference in hydrodynamic noise caused by different hull structures. Therefore, the ship-radiated noise can reflect ship attributes and be used to classify ship categories. Compared with shallow models, deep neural networks can learn more abstract and invariant features from a large dataset [
10,
11]. Therefore, deep learning can not only automatically learn feature representations from the raw signal, but can also perform further deep feature extraction and even feature fusion based on some artificial feature parameters such as Mel Frequency Cepstrum Coefficient (MFCC) [
12], constant Q transform (CQT) [
13], wavelet feature [
14,
15], DEMON spectrum and LOFAR spectrum [
16], and high-order spectral features [
17,
18]. Those traditional feature analysis methods effectively reduce information redundancy and the computational cost of the back-end model.
Due to the difficulty and high cost of marine experiments, the effective samples of ship-radiated noise data are insufficient [
19]. The insufficient data would lead to over-fitting of the large-scale deep network model, which is difficult to converge, ultimately affecting the classification accuracy [
20]. To solve this problem, Gao et al. [
21] used a deep convolutional generative adversarial network (DCGAN) to expand the training set, improving the classification effect. Jiang et al. [
22] proposed the modified DCGAN model to augment data for targets with a small sample size. Using GAN to generate ship-radiated noise data can effectively solve the problem of scarcity of samples, but the training of generative networks is time-consuming. Yang et al. [
12] proposed an improved competitive deep belief network (DBN), which addresses the problem of insufficient training samples by pre-training the DBN with a large amount of unlabeled ship-radiated noise. Jin et al. [
23] used a CNN pre-trained on the ImageNet dataset [
24] and fine-tuned the network with fish image data with a small sample size to effectively solve the underwater image classification problem. These pre-training methods as transfer learning methods require considering the similarity between data, tasks, or models and need preload model parameters. A measurement of similarity needs to be defined. The negative transfer may occur when the source domain data and target domain data are not similar or when the deep model is not good enough to find a transferable feature. For our study, a lightweight network is designed to improve classification accuracy in a small sample condition.
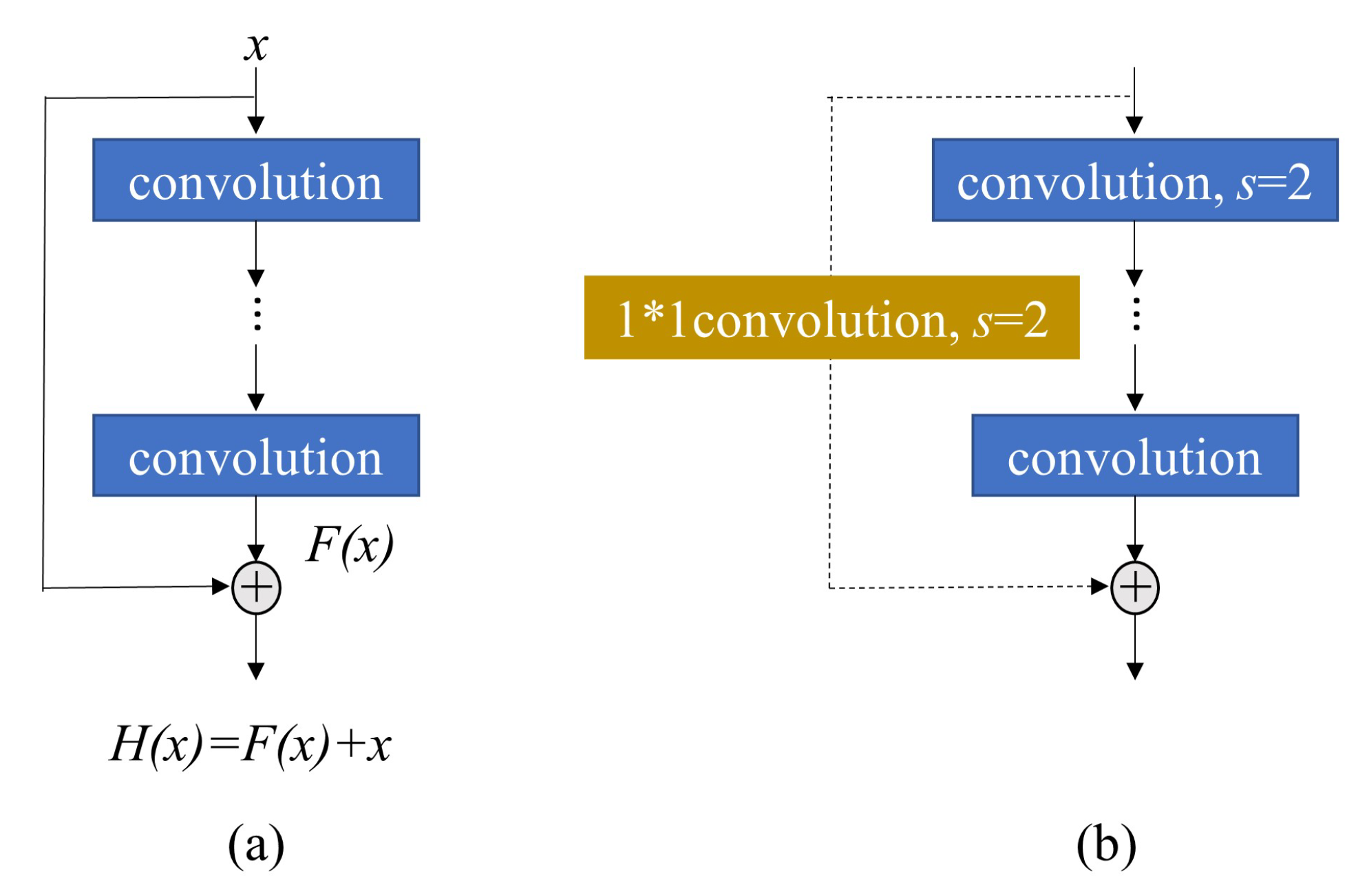
The large-scale residual network (ResNet) [
25] is redundant in the field of computer vision. Gao et al. [
26] randomly removed many layers of ResNet during the training process, which did not affect the convergence of the algorithm, and the removal of the middle layers had little effect on the final results, illustrating that ResNet has redundancy. For underwater acoustic target recognition, a depth search experiment for a multiscale residual deep neural network (MSRDN) [
27] was conducted. The results prove that the original MSRDN with 101 depths is redundant. Xue et al. [
28] observed that the recognition rate will decrease by increasing the number of residual layers, which indicates the redundancy of ResNet. Therefore, it is feasible to reduce the model parameters while maintaining the model performance. For our work, a reduction of the model parameter is realized by shrinking the number of residual units in ResNet.
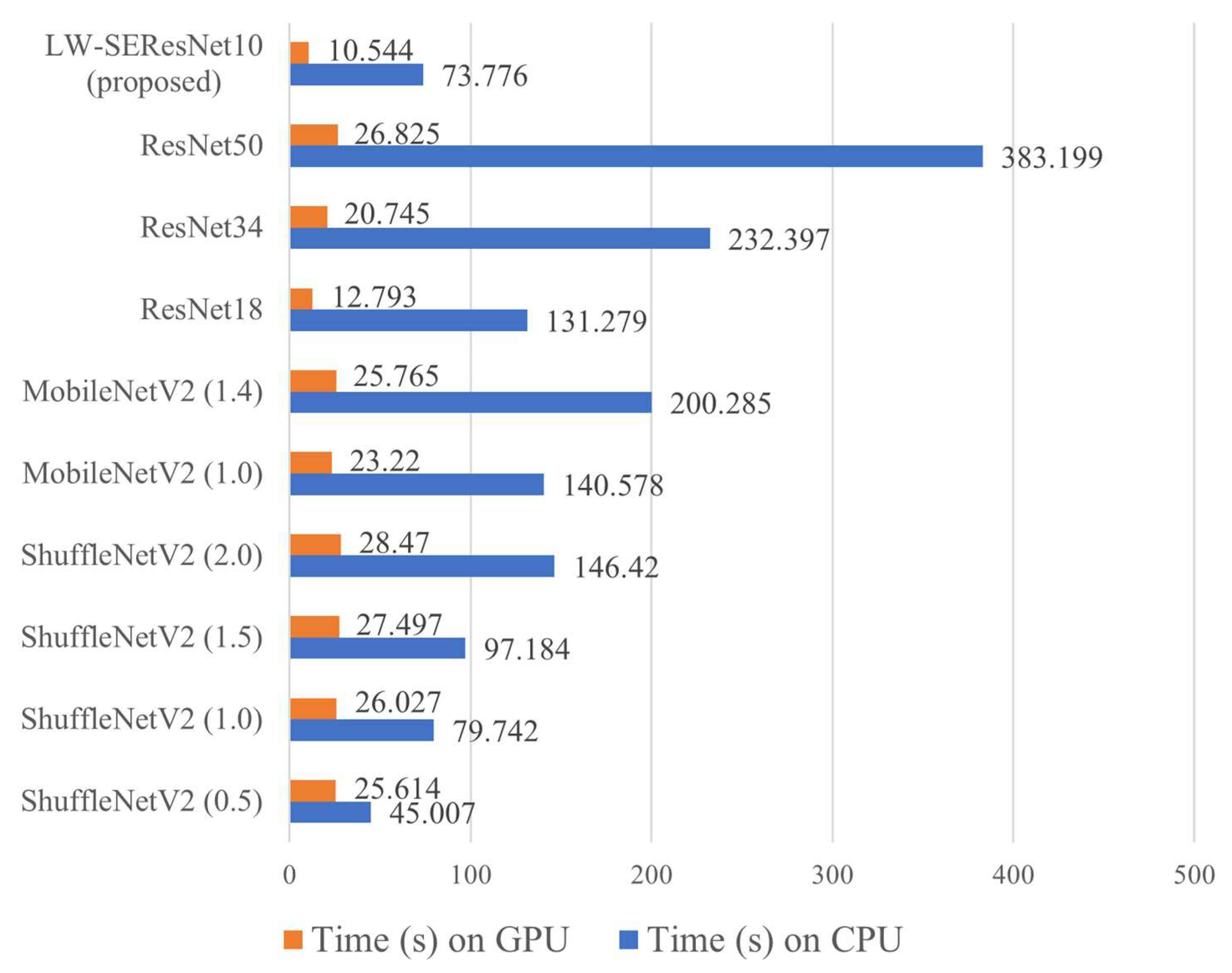
Meanwhile, large-scale deep models have the problem of high computation costs [
29]. For practical applications, the trade-off between accuracy and model efficiency is necessary. The efficiency is defined with lower computation cost or time cost. To develop efficient deep models, recent works in the field of computer vision usually focus on structural design [
30,
31], low-rank factorization [
32], and knowledge distillation [
33,
34]. For underwater acoustic target recognition, Lei et al. [
35] proposed that avoiding high computational costs is an important future direction of underwater acoustic information processing. Jiang et al. [
22] proposed the S-ResNet model to obtain good classification accuracy while significantly reducing the complexity of the model and achieving a good trade-off between classification accuracy and model complexity. Meanwhile, the parameters and floating-point operations (FLOPs) of the model are used to measure the model’s complexity. However, on the actual equipment, due to a variety of optimization calculation operations, the theoretical parameters and FLOPs cannot accurately measure the actual time consumption of the model [
31]. Therefore, for our study, in addition to using the theoretical parameters, we will also measure the complexity of the model according to the actual time consumption. Tian et al. [
36] designed a lightweight MSRDN using lightweight network design techniques, in which 64.18% of parameters and 79.45% of FLOPs are reduced from the original MSRDN with a small loss of accuracy. Meanwhile, the time cost under the same hardware and software platforms was conducted. For our study, we will measure time costs on different platforms.
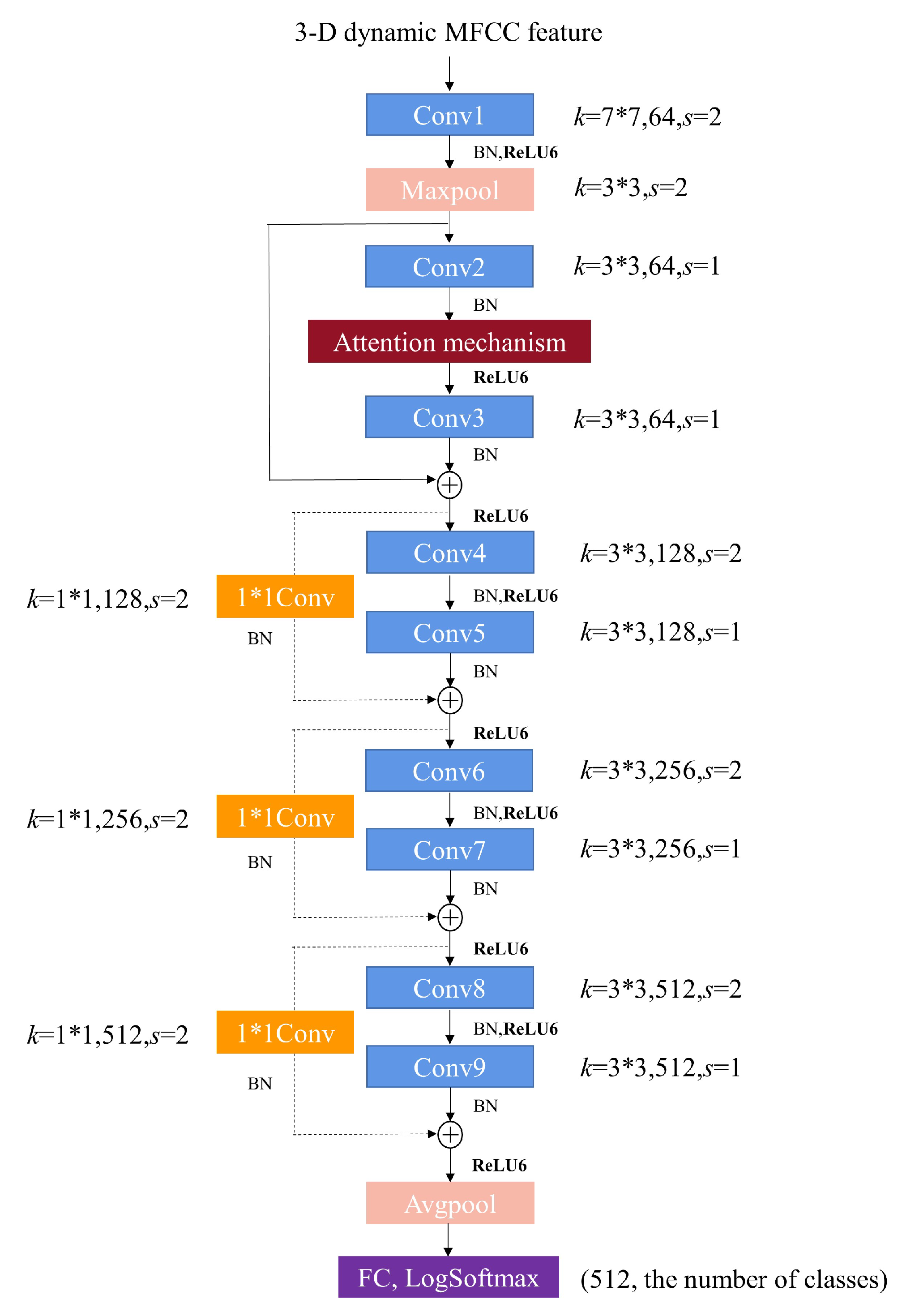
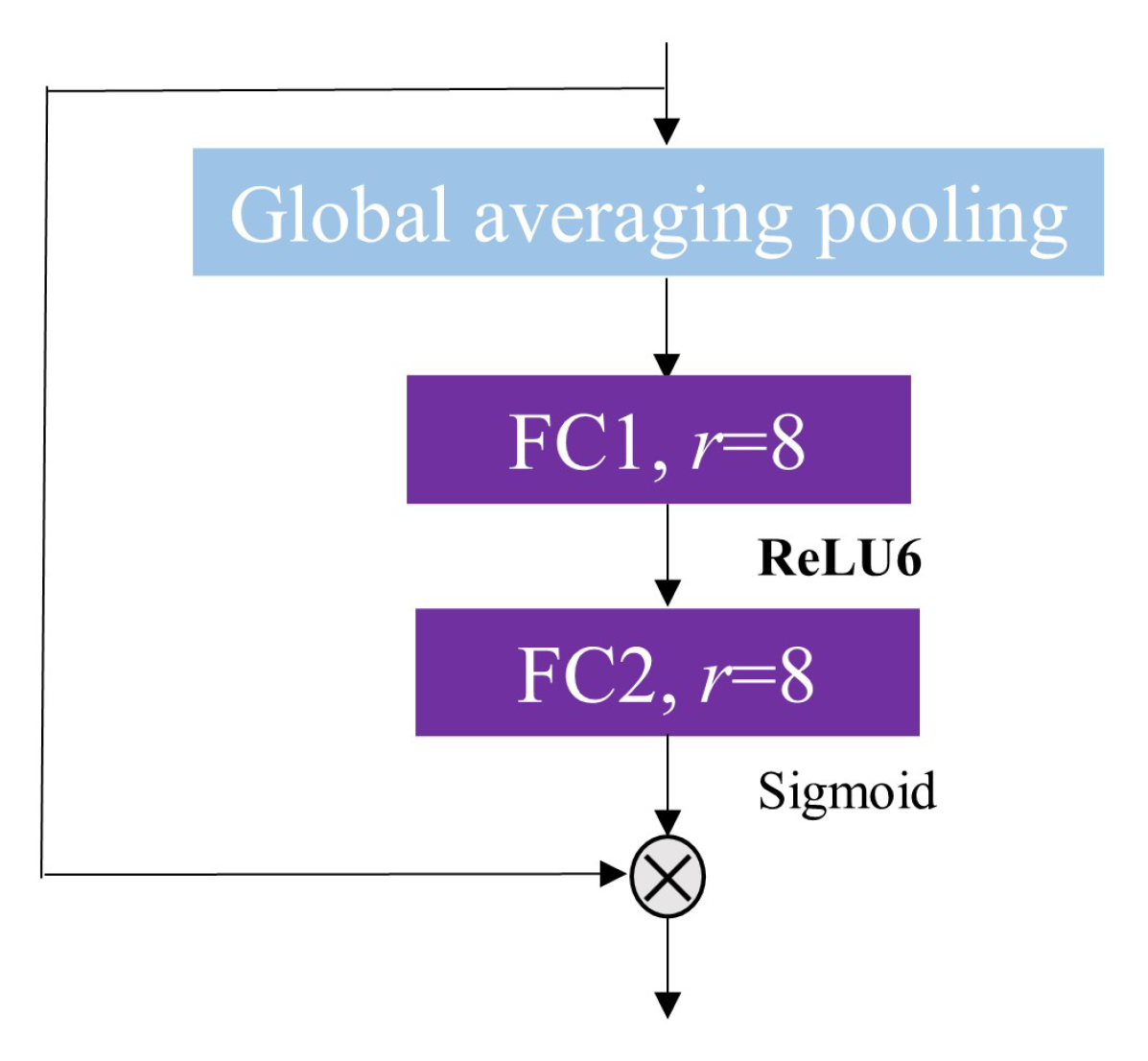
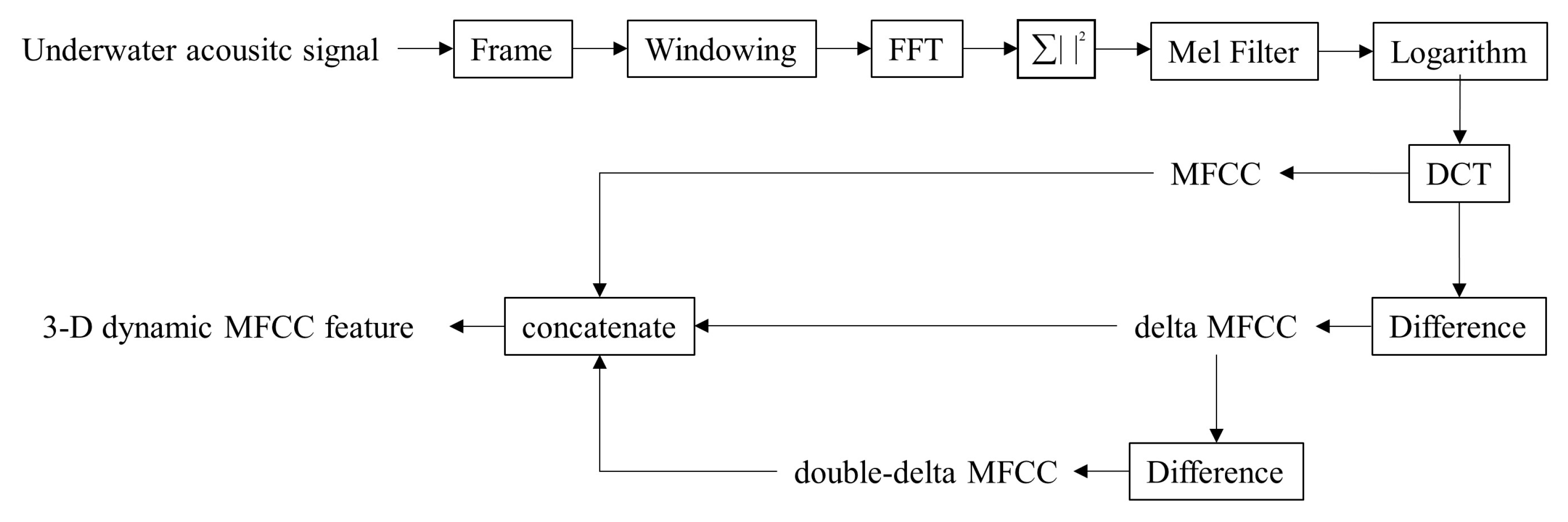
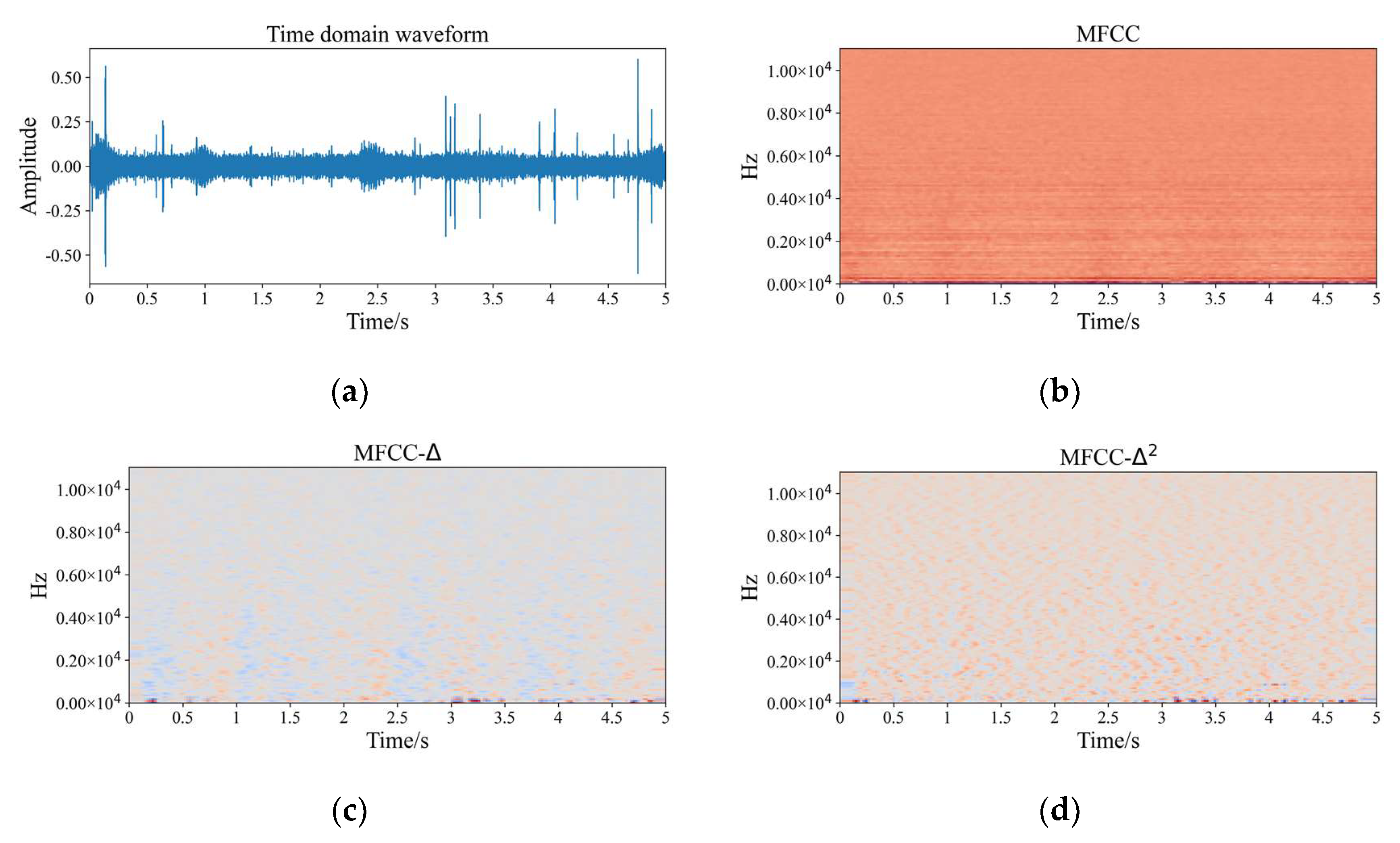
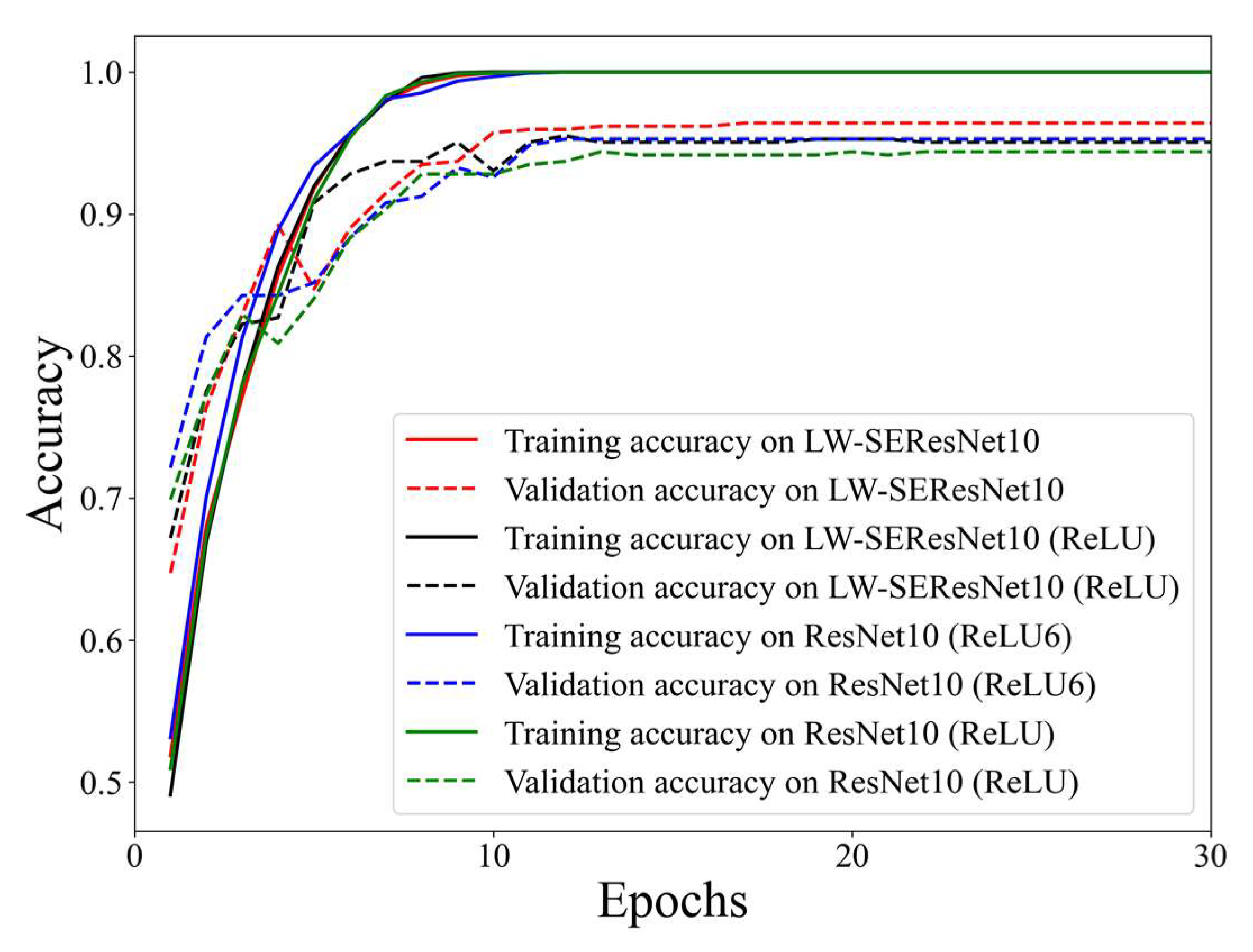
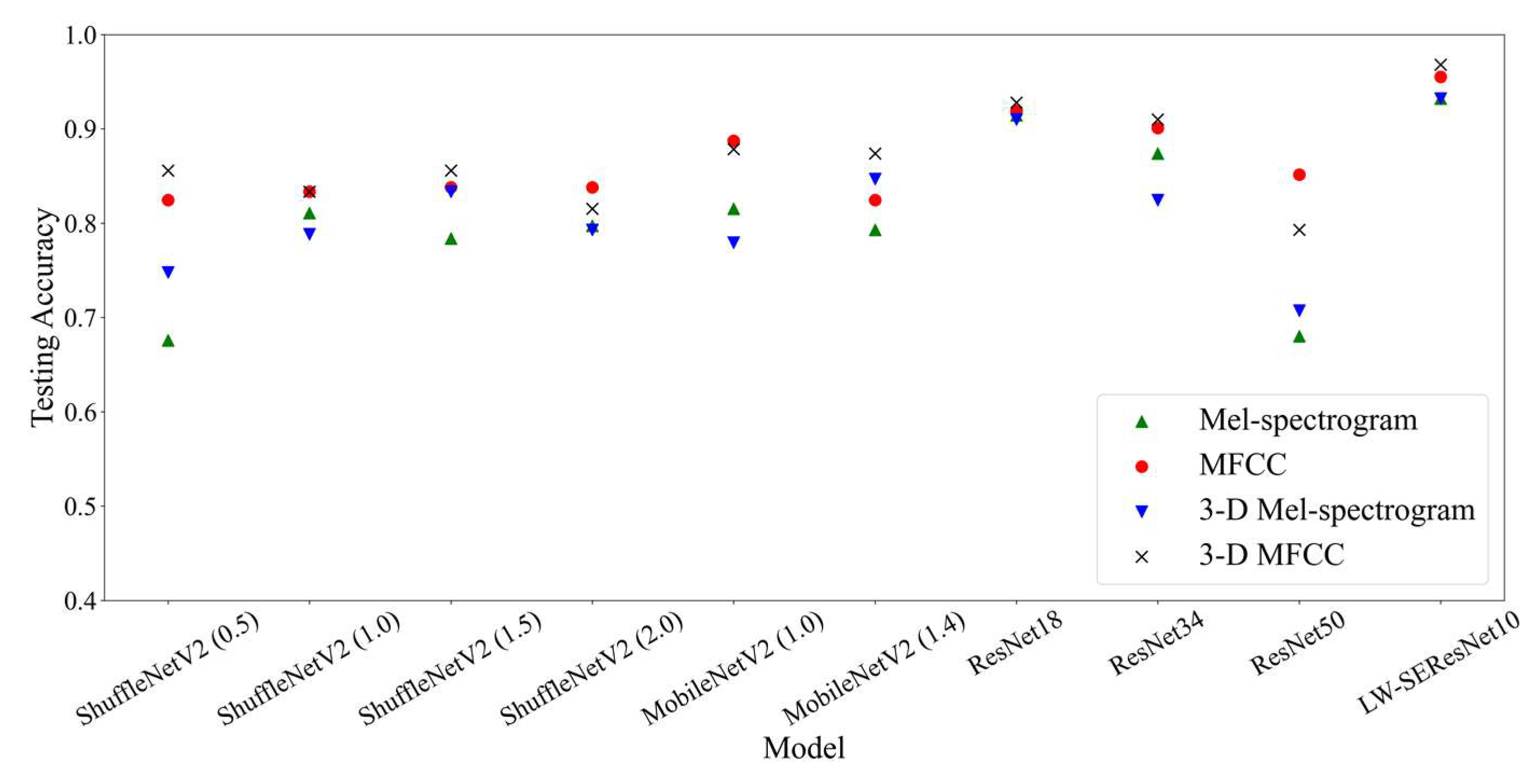
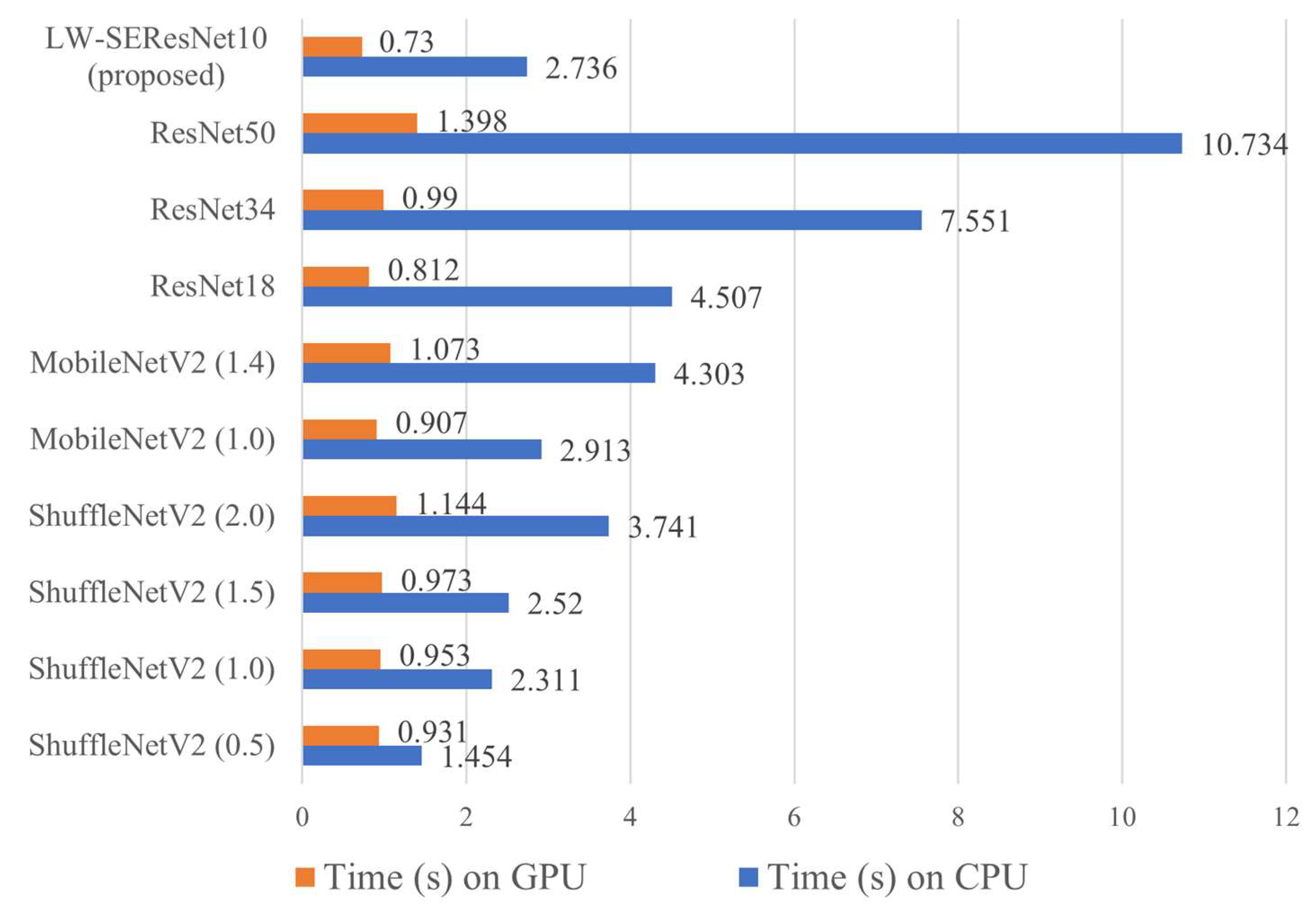
Our study utilizes the structural design technique to design our lightweight network. Lightweight networks are defined as having fewer model parameters or faster run times. The proposed model, namely lightweight squeeze and excitation residual network 10 (LW-SEResNet10), aims to inhibit overfitting and achieve high accuracy and high efficiency. Firstly, shrinking the number of residual units in the ResNet reduces the number of parameters. Secondly, the attention mechanism called “squeeze-excitation” (SE) block [
37] with low parameters is introduced into the proposed model. The attention mechanism [
38] can help the network give different weights to each part of the input features, extracting more critical and important information. The attention mechanism is integrated into a residual unit structure, which helps to capture the correlation between features, and the representation generated by convolution networks can be strengthened. Thirdly, the ReLU6 activation function [
39] is employed to increase the model stability. The ReLU6 activation function does not introduce additional parameters. Moreover, the 3D dynamic MFCC feature is used as the input of the proposed model. The 3D dynamic MFCC feature effectively compresses the raw time-domain information of the target radiated noise signal, while extracting the higher-order dynamic time information of the signal. To verify the lightweight nature and superiority of our proposed model, we compare the proposed model with the ResNet and the classical lightweight network models MobileNet V2 [
30] and ShuffleNet V2 [
31] in the field of computer vision in terms of parameters, time consumption, accuracy, and noise mismatch.
The remainder of this article is organized as follows.
Section 2 provides an overview of our ship-radiated noise classification method in detail. Experiments are presented in
Section 3, and
Section 4 concludes this article.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}