
Forecasting Vertical Profiles of Ocean Currents from Surface Characteristics: A Multivariate Multi-Head Convolutional Neural Network–Long Short-Term Memory Approach

 , ,
, , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Data and Methodology
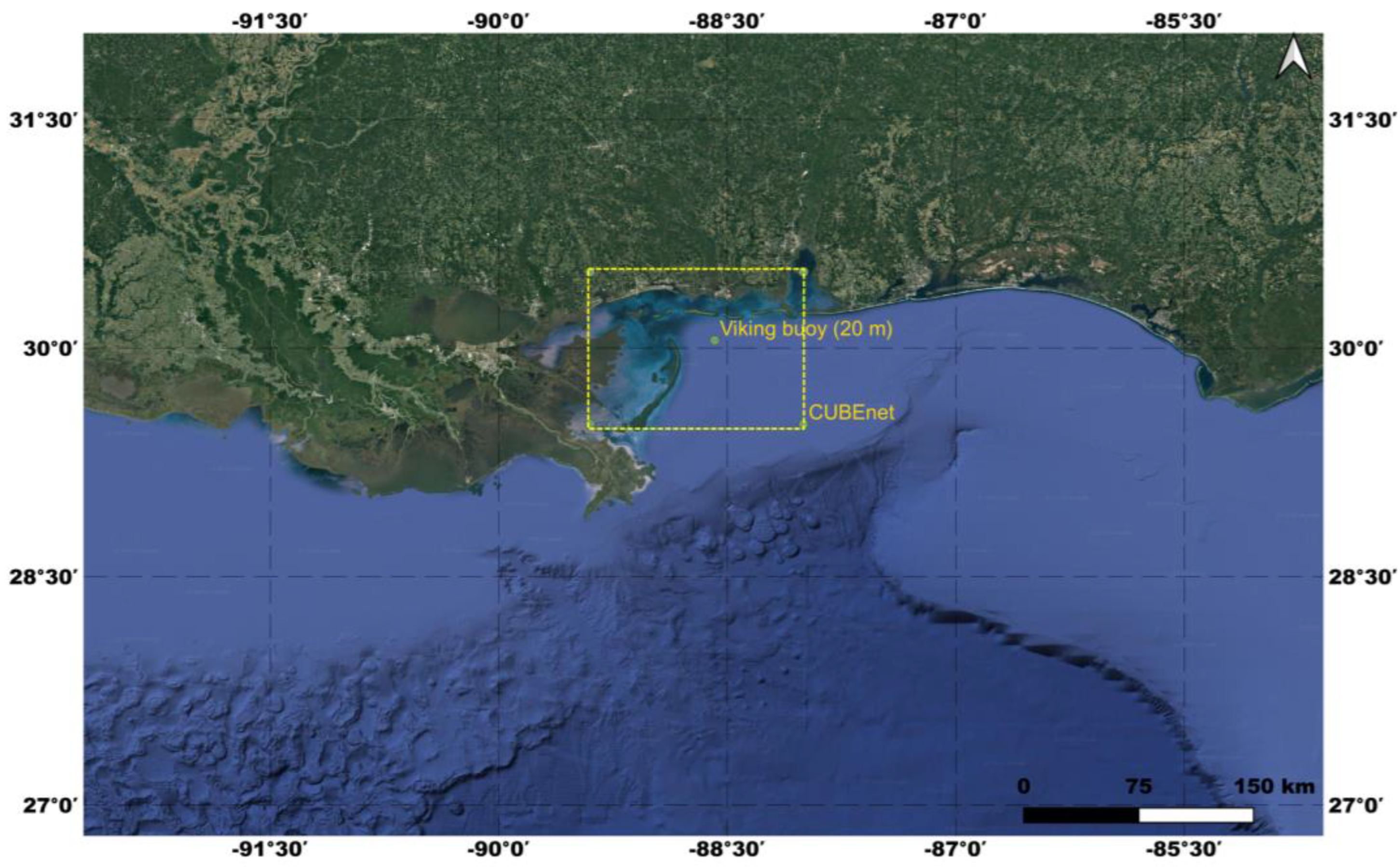
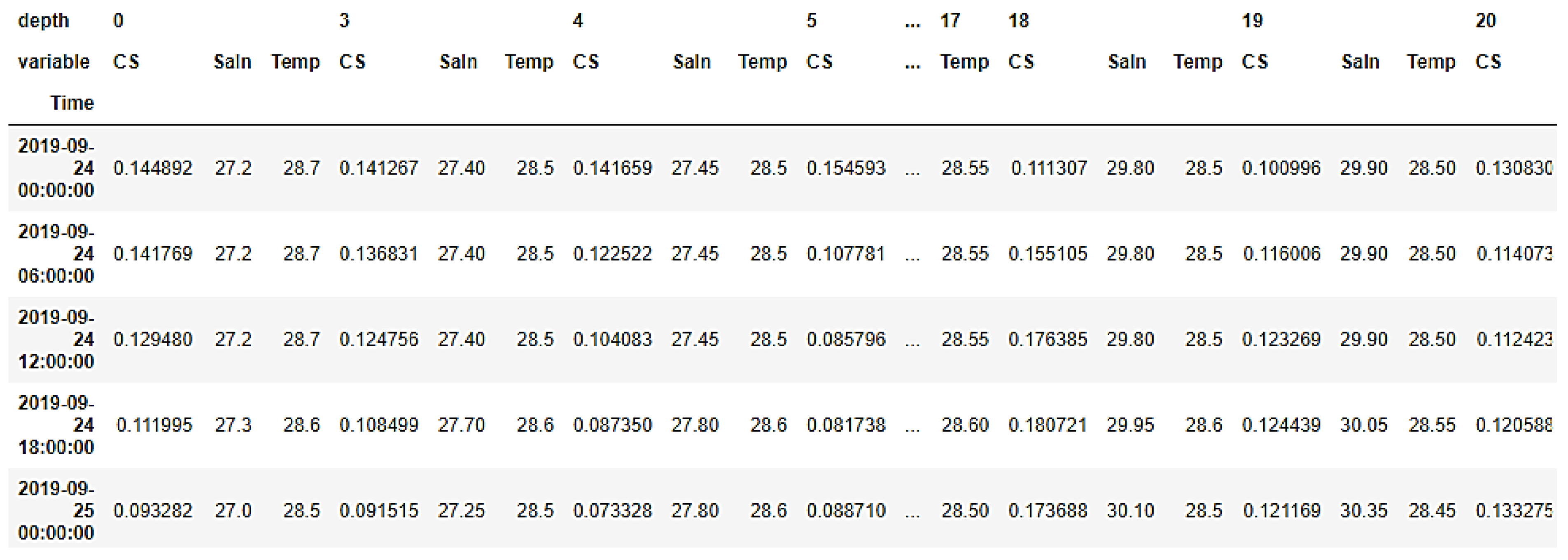
2.1. Buoy Data
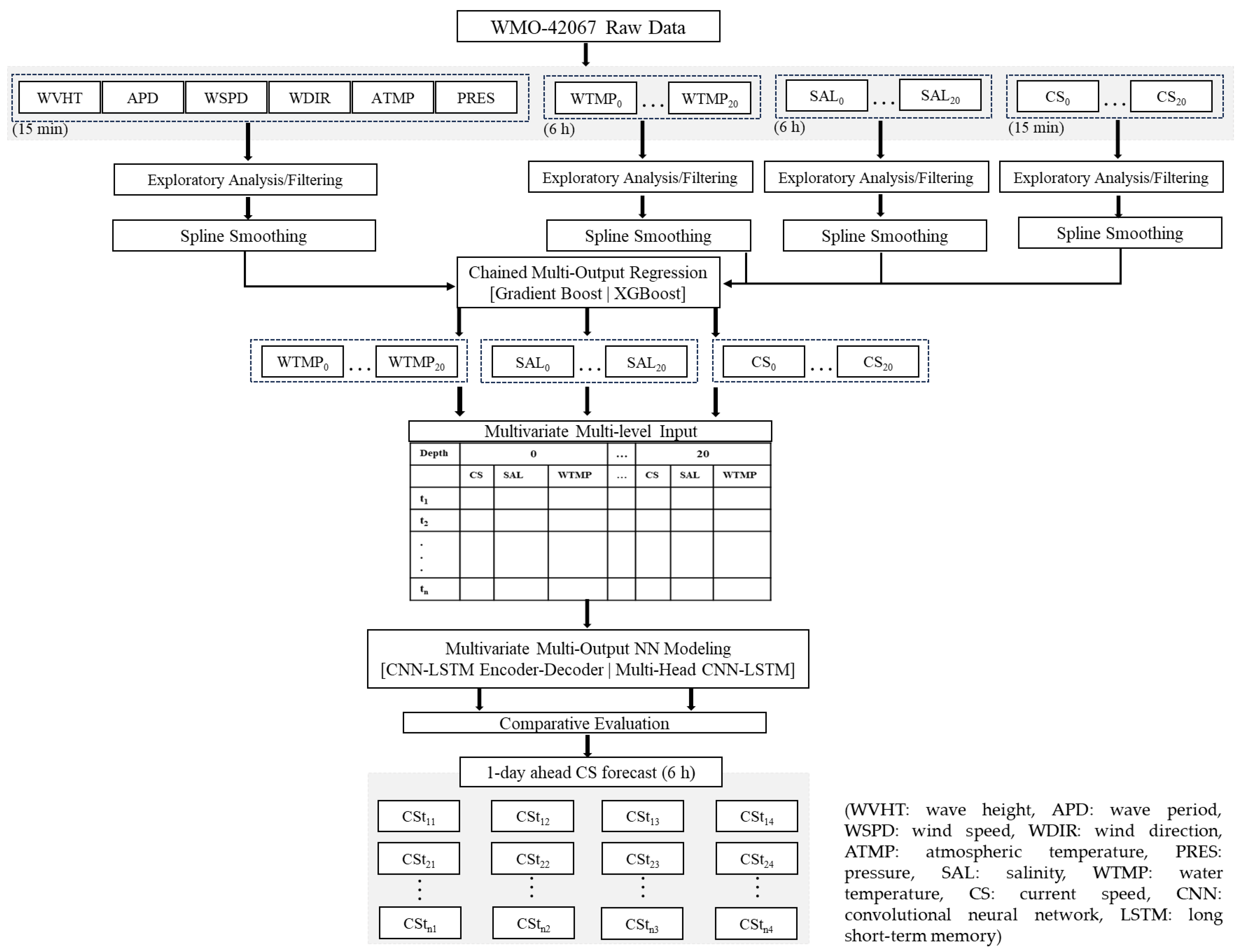
2.2. Methodology Overview
2.3. Data Preprocessing
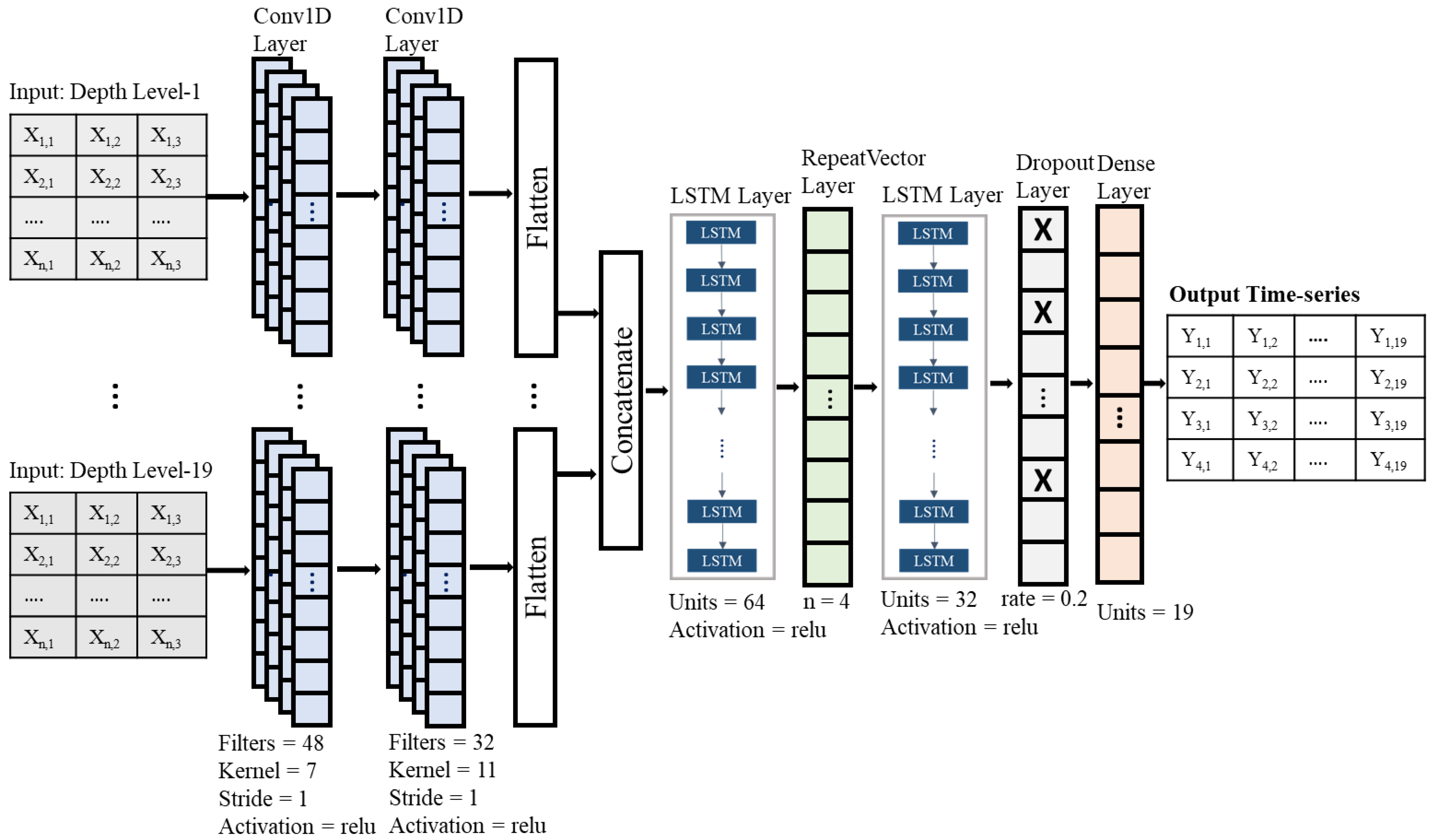
2.4. Data Reconstruction Method
2.4.1. Model Description
2.4.2. Model Training and Evaluation
2.5. Multi-Output Multi-Step Forecast
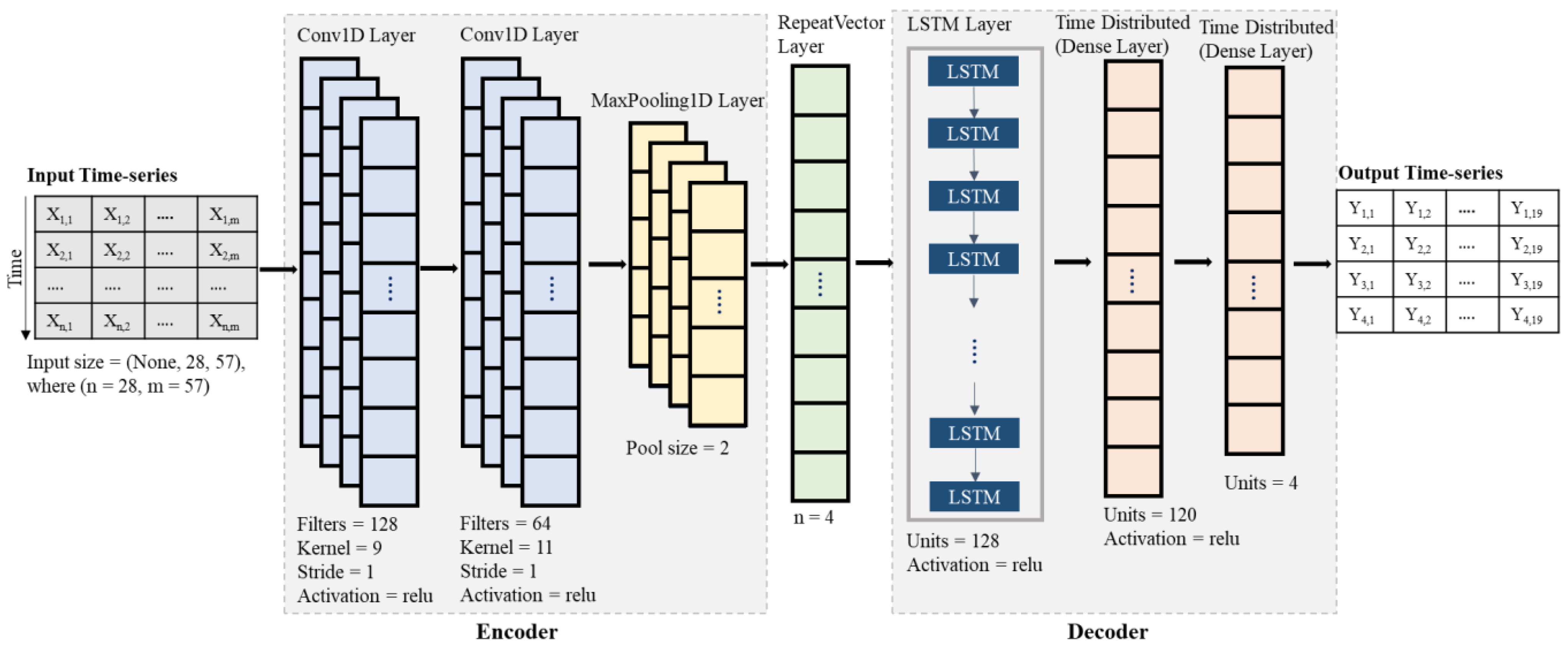
2.5.1. CNN Architecture
2.5.2. LSTM Architecture
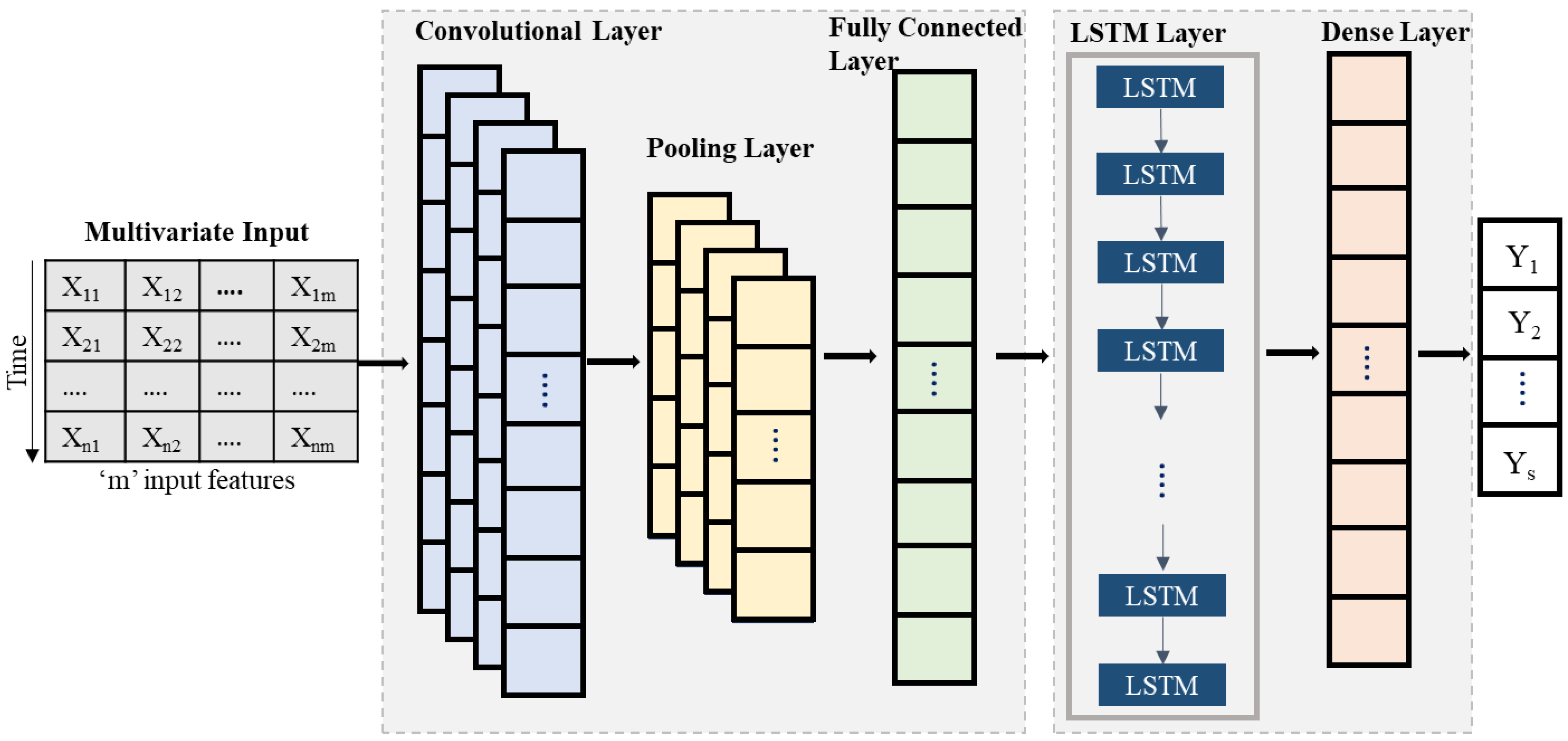
2.5.3. CNN-LSTM Architecture
2.5.4. Forecast Model Architecture and Configuration
2.5.5. Data Preparation
2.5.6. Model Training and Evaluation
3. Results and Discussion
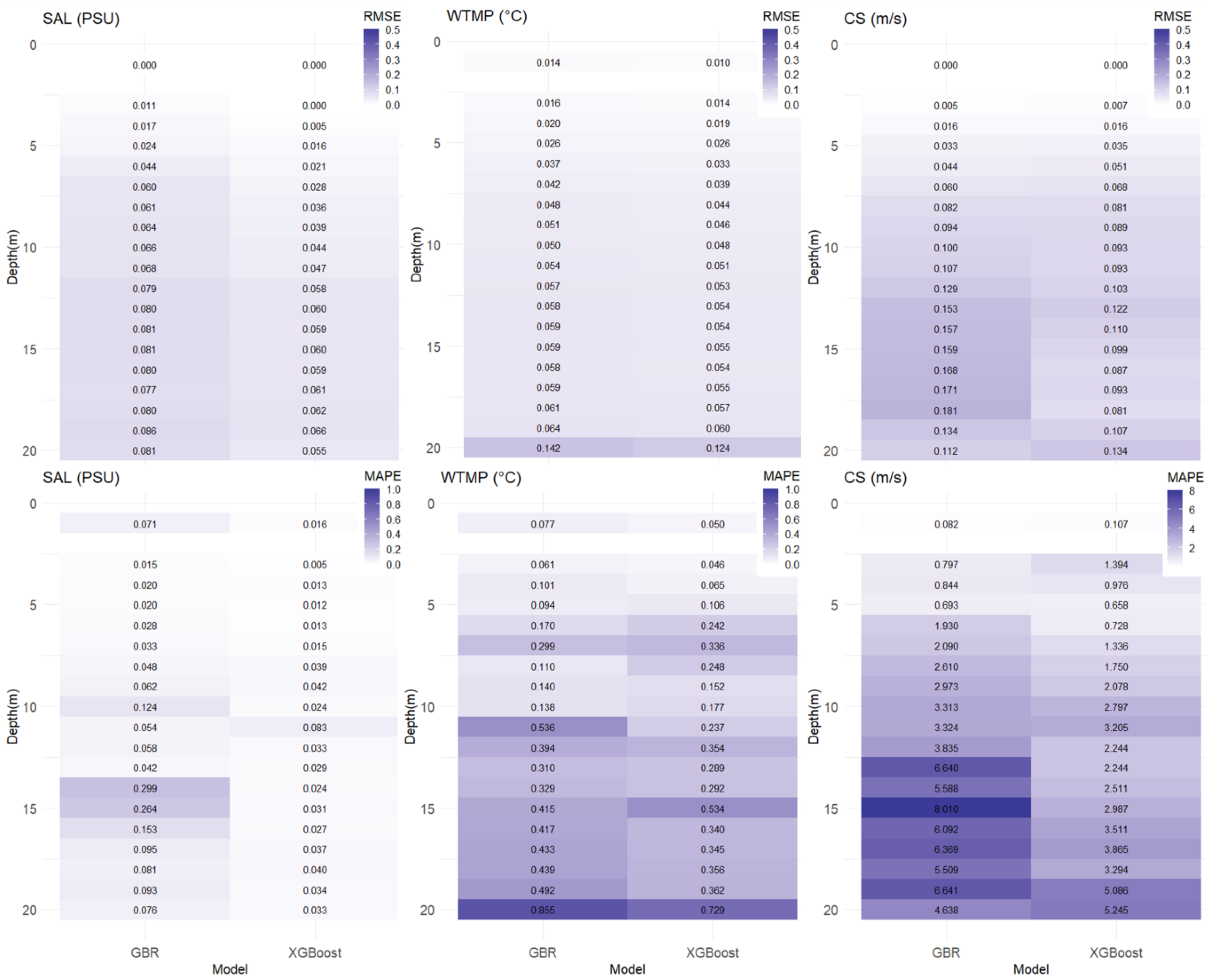
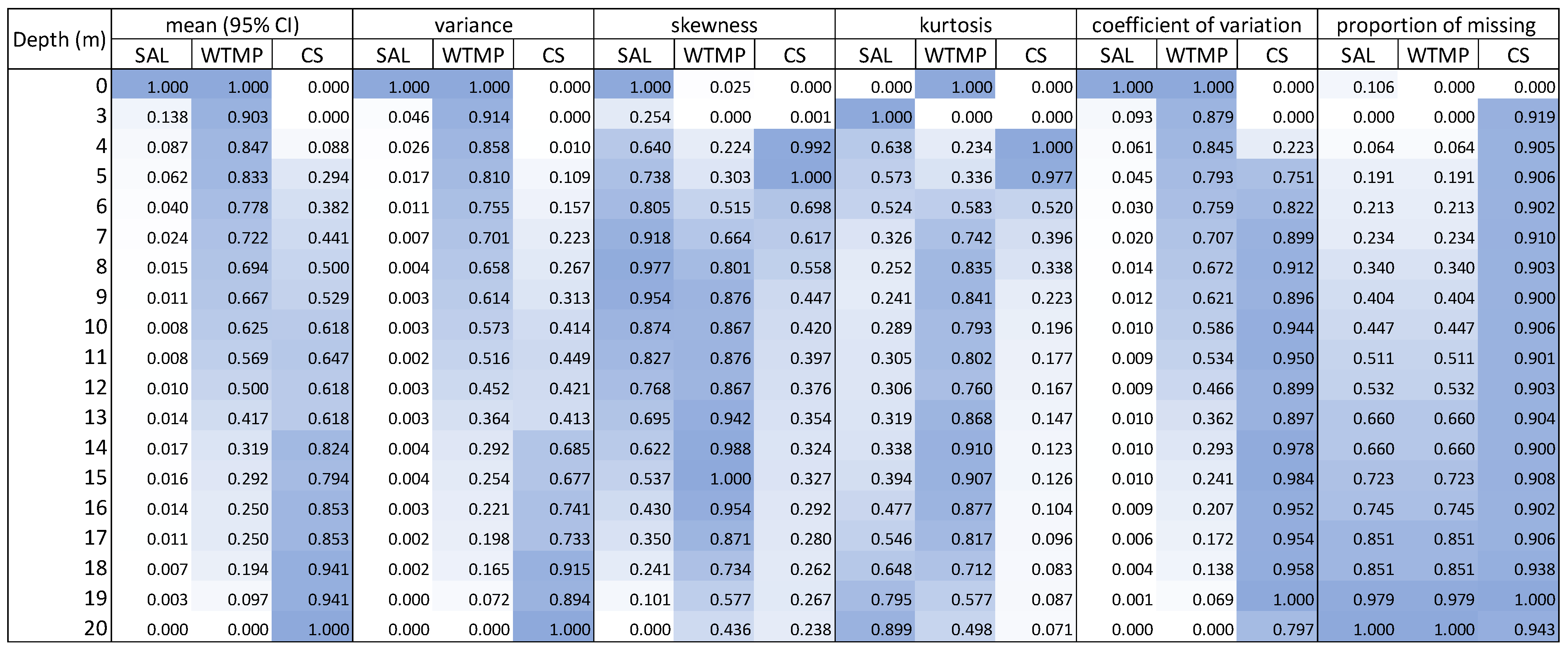
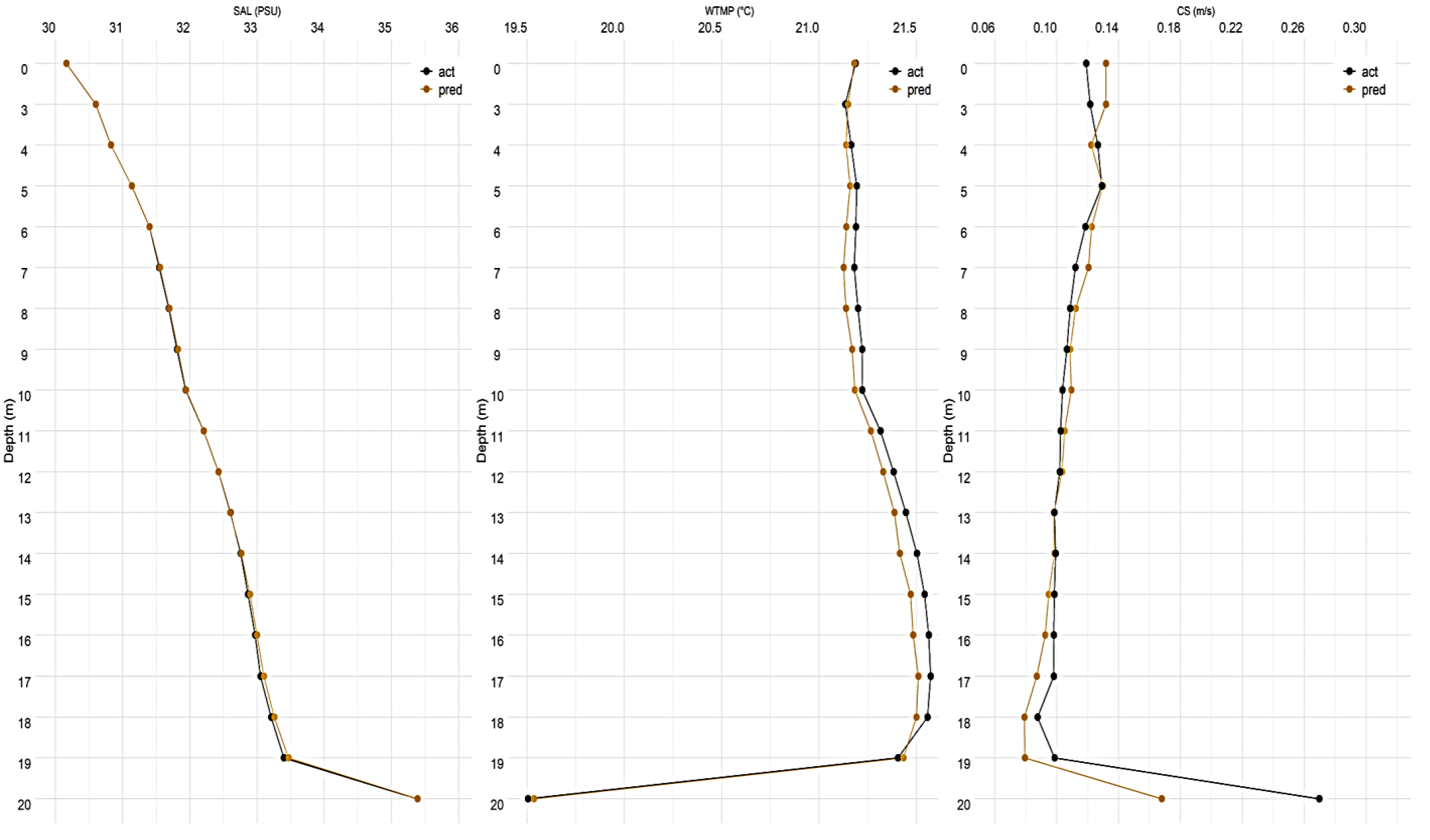
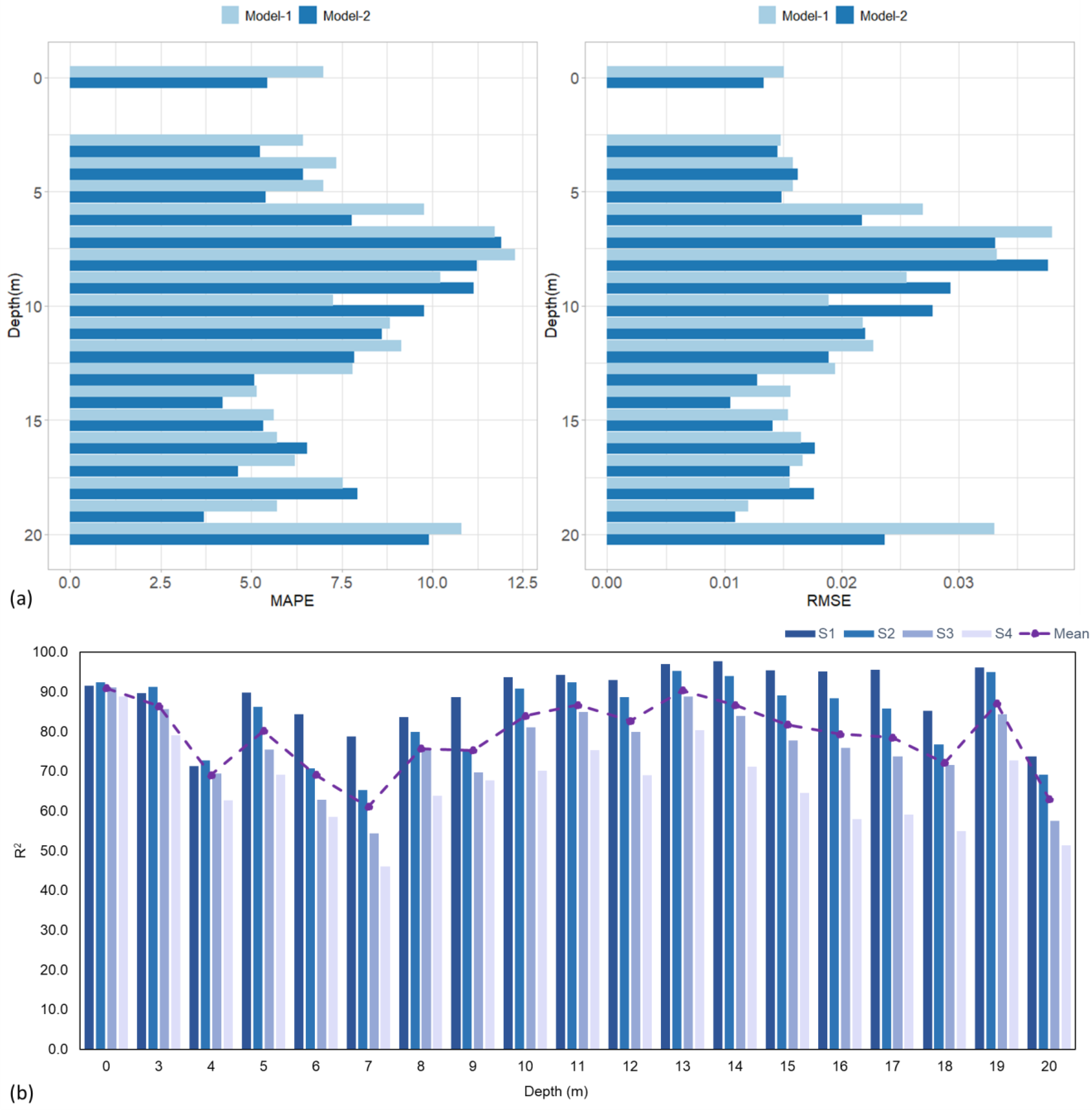
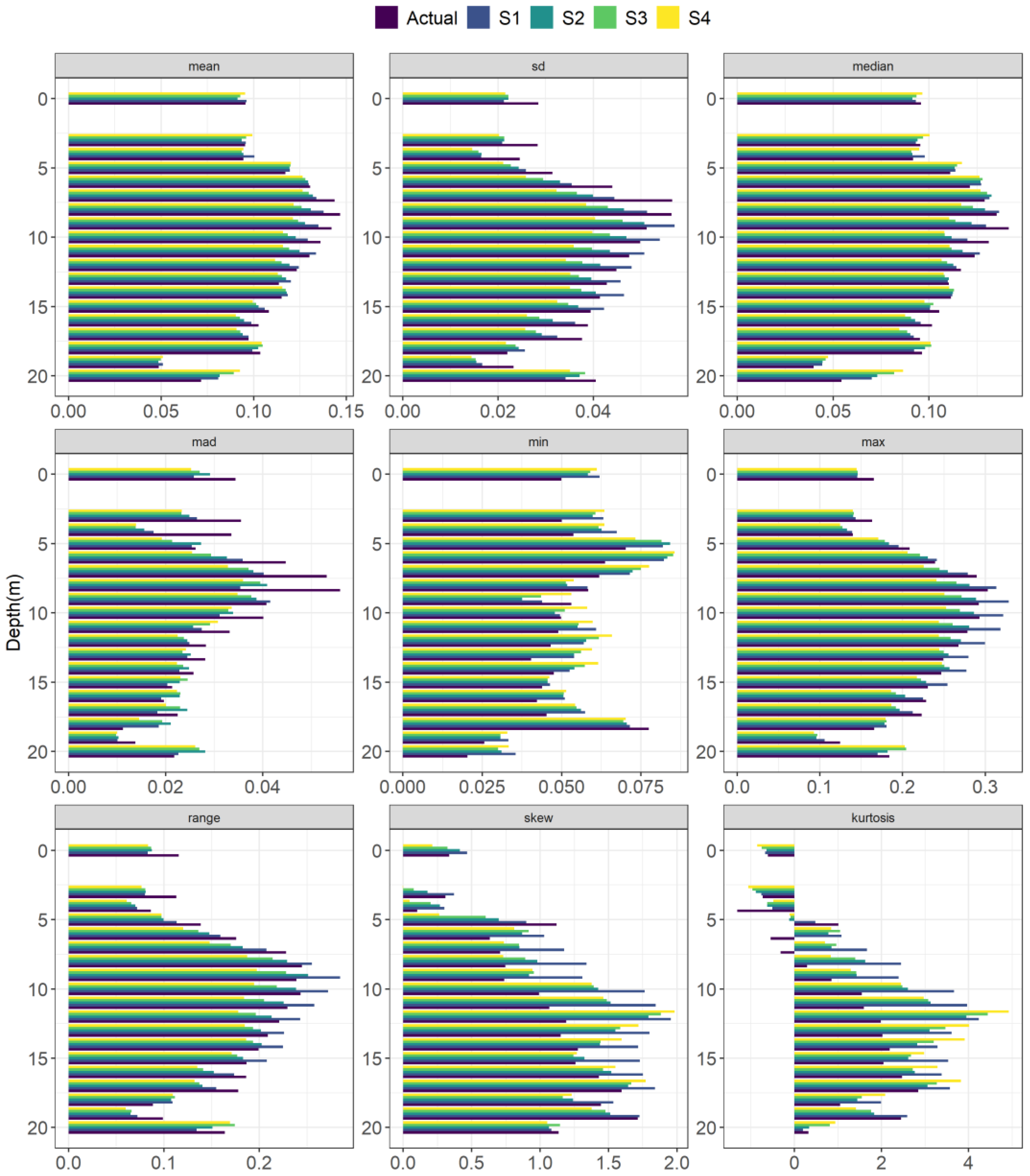
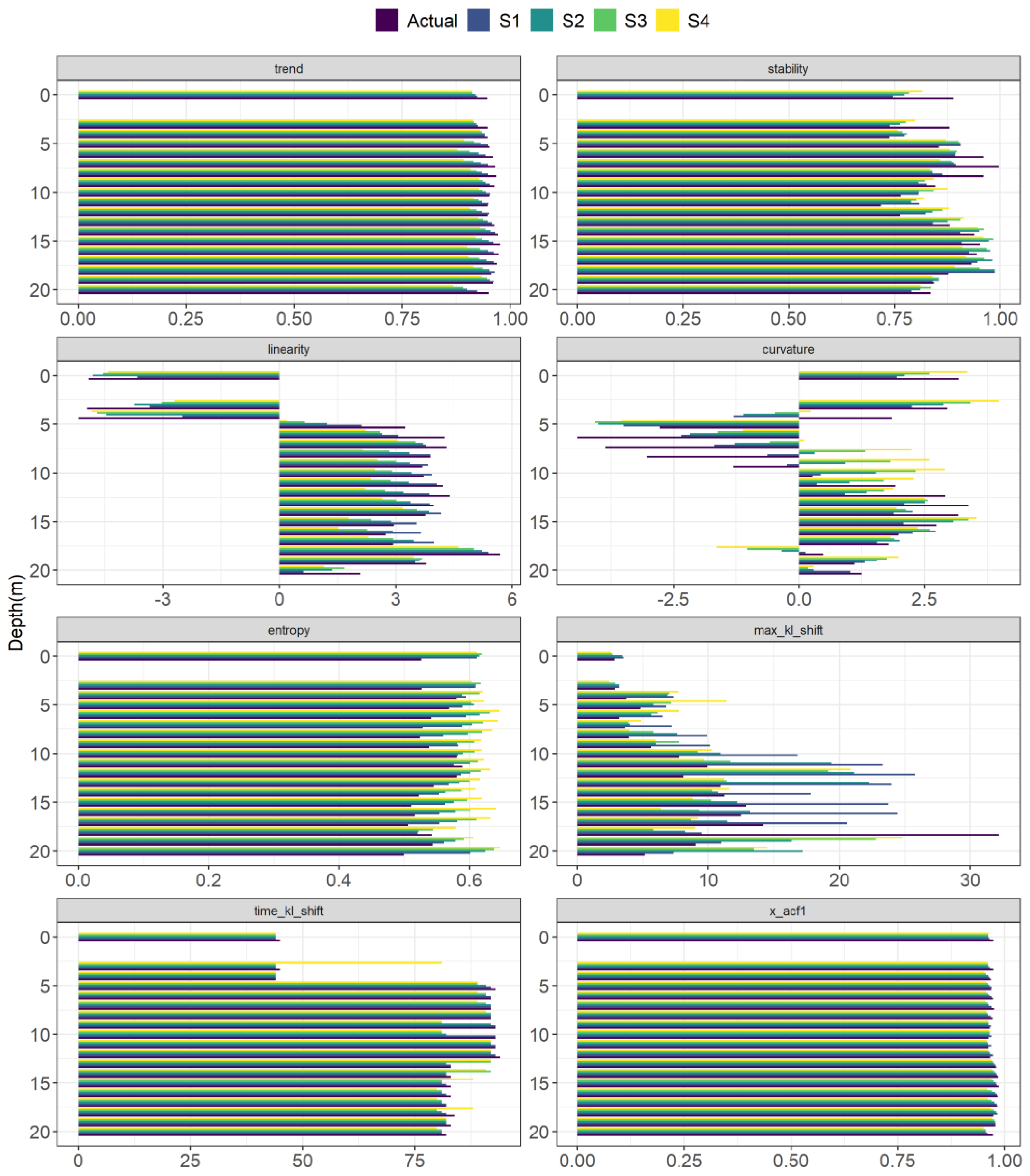
3.1. Reconstruction Performance
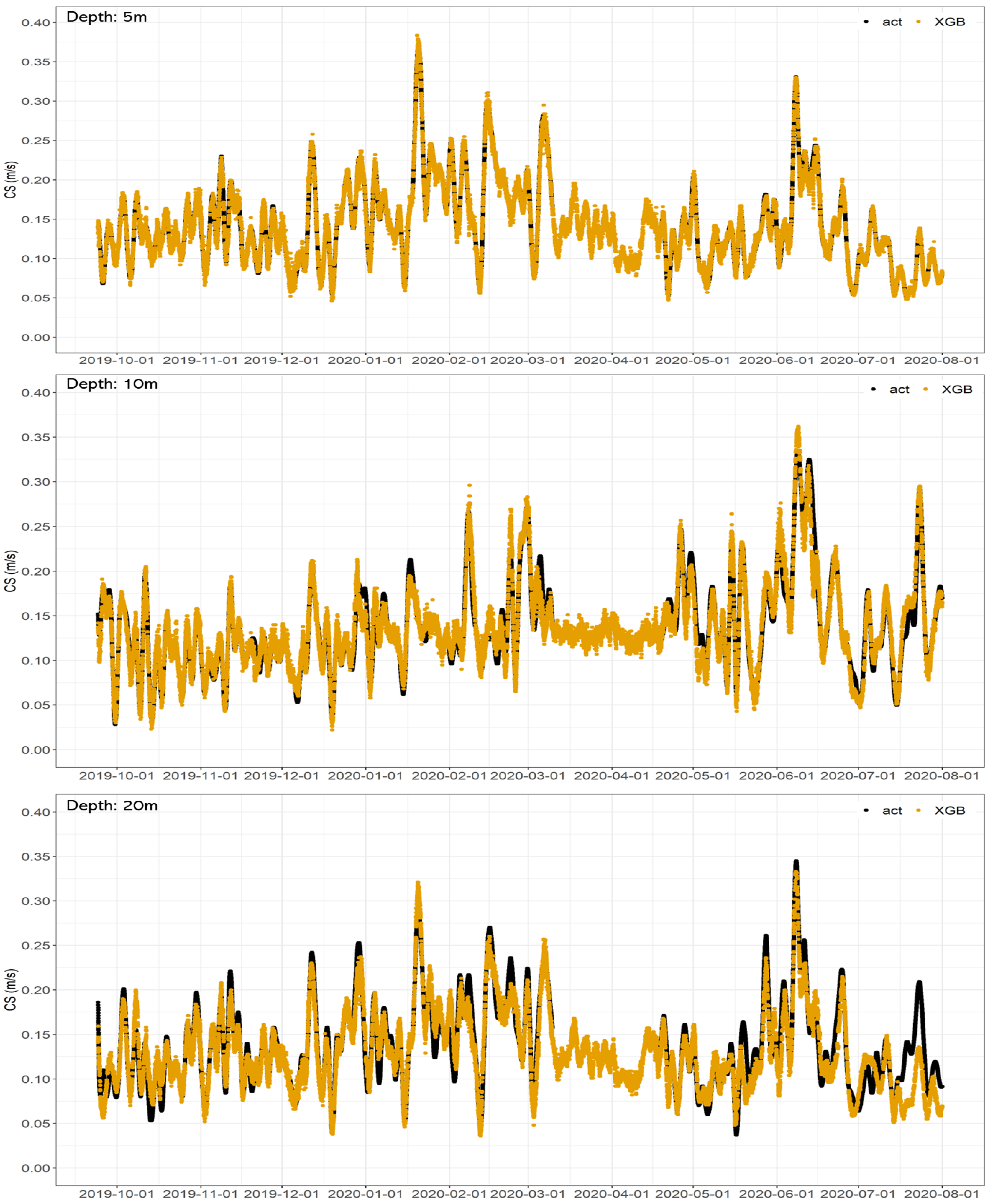
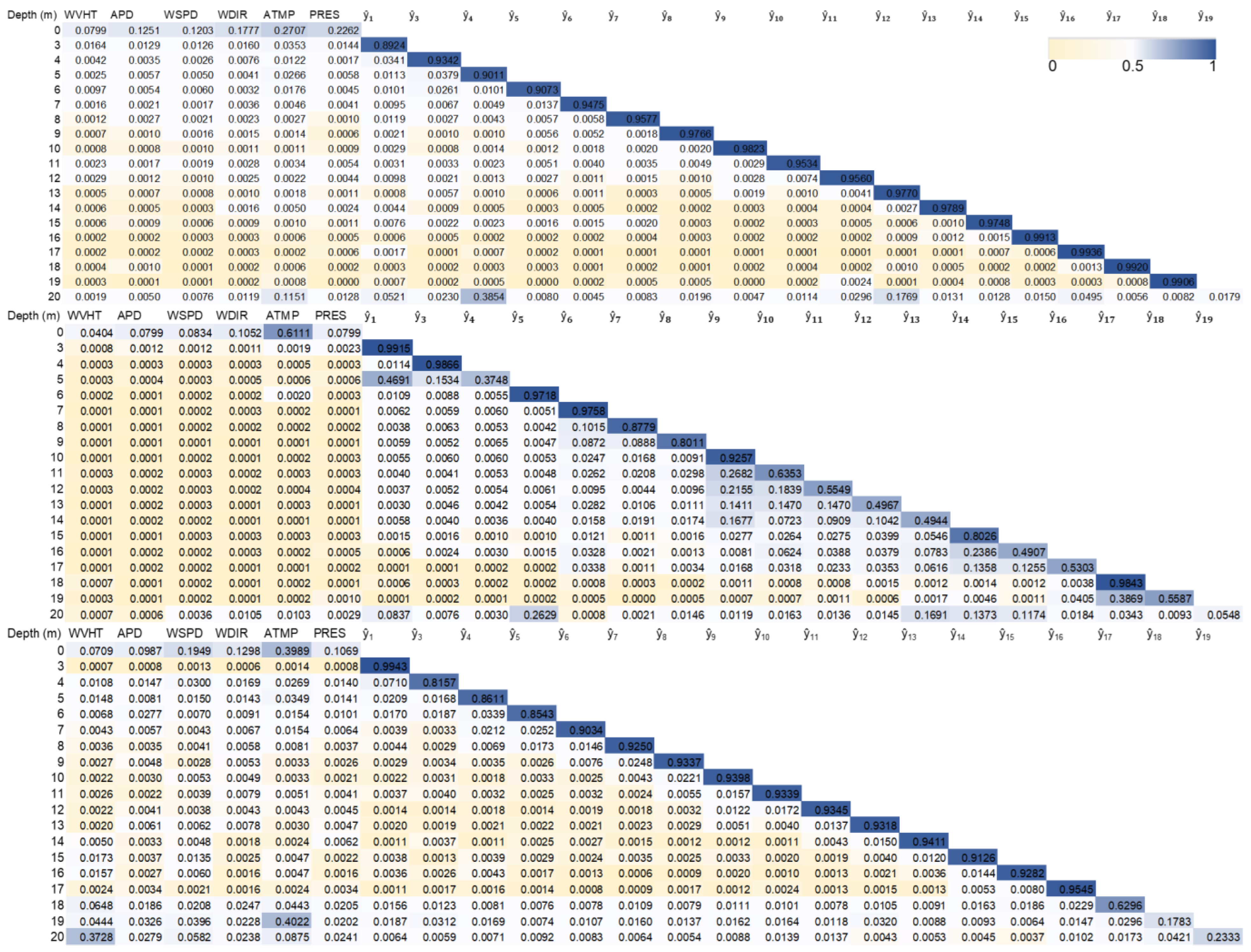
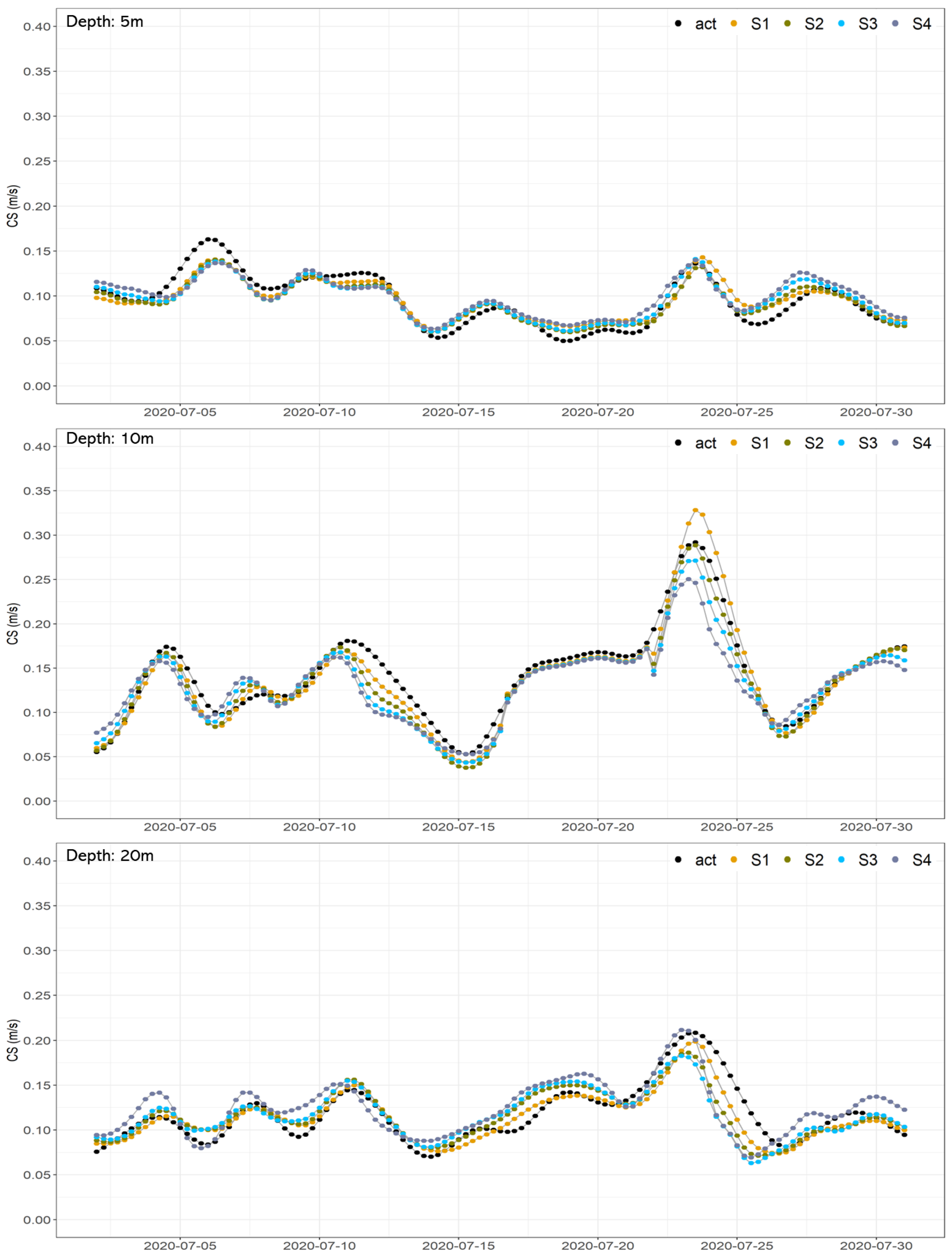
3.2. Multi-Step Forecast Performance
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, J.; Kwon, M.; Kim, S.D.; Kug, J.S.; Ryu, J.G.; Kim, J. Spatiotemporal neural network with attention mechanism for El Niño forecasts. Sci. Rep. 2022, 12, 7204. [Google Scholar] [CrossRef]
- Wang, S.; Mu, L.; Liu, D. A hybrid approach for El Niño prediction based on Empirical Mode Decomposition and convolutional LSTM Encoder-Decoder. Comput. Geosci. 2021, 149, 104695. [Google Scholar] [CrossRef]
- Wenhai, L.; Cusack, C.; Baker, M.; Tao, W.; Mingbao, C.; Paige, K.; Xiaofan, Z.; Levin, L.; Escobar, E.; Amon, D.; et al. Successful blue economy examples with an emphasis on international perspectives. Front. Mar. Sci. 2019, 6, 261. [Google Scholar] [CrossRef]
- Wen, J.; Yang, J.; Wei, W.; Lv, Z. Intelligent multi-AUG ocean data collection scheme in maritime wireless communication network. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3067–3079. [Google Scholar] [CrossRef]
- Kar, S.; Sunkara, V.; McKenna, J.; Stanic, S.; Bernard, L. Near Real-Time Radio Frequency (RF) Data Analysis Pipeline for Aiding Marine Domain Awareness and Surveillance. In OCEANS 2022, Hampton Roads; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Trice, A.; Robbins, C.; Philip, N.; Rumsey, M. Challenges and Opportunities for Ocean Data to Advance Conservation and Management; Ocean Conservancy: Washington, DC, USA, 2021. [Google Scholar]
- Sunkara, V.; McKenna, J.; Kar, S.; Iliev, I.; Bernstein, D.N. The Gulf of Mexico in trouble: Big data solutions to climate change science. Front. Mar. Sci. 2023, 10, 1075822. [Google Scholar] [CrossRef]
- Franz, M.; Lieberum, C.; Bock, G.; Karez, R. Environmental parameters of shallow water habitats in the SW Baltic Sea. Earth Syst. Sci. Data 2019, 11, 947–957. [Google Scholar] [CrossRef]
- Salles, R.; Mattos, P.; Iorgulescu, A.M.; Bezerra, E.; Lima, L.; Ogasawara, E. Evaluating temporal aggregation for predicting the sea surface temperature of the Atlantic Ocean. Ecol. Inform. 2016, 36, 94–105. [Google Scholar] [CrossRef]
- Jonathan, P.; Ewans, K.; Flynn, J. Joint modelling of vertical profiles of large ocean currents. Ocean. Eng. 2012, 42, 195–204. [Google Scholar] [CrossRef]
- Srinivasan, A.; Sharma, N.; Gustafson, D. A multi-resolution probabilistic ocean current forecasting system for offshore energy operations. In Proceedings of the InOffshore Technology Conference, Houston, TX, USA, 30 April 2018; p. D031S042R003. [Google Scholar]
- Zhu, C.; Liu, W.; Li, X.; Xu, Y.; El-Serehy, H.A.; Al-Farraj, S.A.; Ma, H.; Stoeck, T.; Yi, Z. High salinity gradients and intermediate spatial scales shaped similar biogeographical and co-occurrence patterns of microeukaryotes in a tropical freshwater-saltwater ecosystem. Environ. Microbiol. 2021, 23, 4778–4796. [Google Scholar] [CrossRef]
- Bagatinsky, V.A.; Diansky, N.A. Contributions of Climate Changes in Temperature and Salinity to the Formation of North Atlantic Thermohaline Circulation Trends in 1951–2017. Mosc. Univ. Phys. Bull. 2022, 77, 564–580. [Google Scholar] [CrossRef]
- Rudels, B. The thermohaline circulation of the Arctic Ocean and the Greenland Sea. In Arctic and Environmental Change; Routledge: London, UK, 2019; pp. 87–99. [Google Scholar]
- Kniebusch, M.; Meier, H.M.; Radtke, H. Changing salinity gradients in the Baltic Sea as a consequence of altered freshwater budgets. Geophys. Res. Lett. 2019, 46, 9739–9747. [Google Scholar] [CrossRef]
- Love, T.; Toal, D.; Flanagan, C. Buoyancy control for an autonomous underwater vehicle. IFAC Proc. Vol. 2003, 36, 199–204. [Google Scholar] [CrossRef]
- Fox-Kemper, B.; Adcroft, A.; Böning, C.W.; Chassignet, E.P.; Curchitser, E.; Danabasoglu, G.; Eden, C.; England, M.H.; Gerdes, R.; Greatbatch, R.J.; et al. Challenges and prospects in ocean circulation models. Front. Mar. Sci. 2019, 6, 65. [Google Scholar] [CrossRef]
- Robertson, R.; Dong, C. An evaluation of the performance of vertical mixing parameterizations for tidal mixing in the Regional Ocean Modeling System (ROMS). Geosci. Lett. 2019, 6, 1–8. [Google Scholar] [CrossRef]
- Griffies, S.M. Elements of the modular ocean model (MOM). GFDL Ocean. Group Tech. Rep. 2012, 7, 47. [Google Scholar]
- Chassignet, E. Global Ocean Prediction with the HYbrid Coordinate Ocean Model, HYCOM. In Proceedings of the 35th COSPAR Scientific Assembly, Paris, France, 18–25 July 2004; Volume 35, p. 585. [Google Scholar]
- Warner, J.C.; Armstrong, B.; He, R.; Zambon, J.B. Development of a coupled ocean–atmosphere–wave–sediment transport (COAWST) modeling system. Ocean. Model. 2010, 35, 230–244. [Google Scholar] [CrossRef]
- Pranić, P.; Denamiel, C.; Vilibić, I. Performance of the Adriatic Sea and Coast (AdriSC) climate component–a COAWST V3. 3-based one-way coupled atmosphere–ocean modelling suite: Ocean results. Geosci. Model Dev. 2021, 14, 5927–5955. [Google Scholar] [CrossRef]
- Su, H.; Yang, X.; Lu, W.; Yan, X.H. Estimating subsurface thermohaline structure of the global ocean using surface remote sensing observations. Remote Sens. 2019, 11, 1598. [Google Scholar] [CrossRef]
- Tian, T.; Cheng, L.; Wang, G.; Abraham, J.; Wei, W.; Ren, S.; Zhu, J.; Song, J.; Leng, H. Reconstructing ocean subsurface salinity at high resolution using a machine learning approach. Earth Syst. Sci. Data 2022, 14, 5037–5060. [Google Scholar] [CrossRef]
- Han, M.; Feng, Y.; Zhao, X.; Sun, C.; Hong, F.; Liu, C. A convolutional neural network using surface data to predict subsurface temperatures in the Pacific Ocean. IEEE Access 2019, 7, 172816–172829. [Google Scholar] [CrossRef]
- Su, H.; Zhang, T.; Lin, M.; Lu, W.; Yan, X.H. Predicting subsurface thermohaline structure from remote sensing data based on long short-term memory neural networks. Remote Sens. Environ. 2021, 260, 112465. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, Y.; Yang, S.; Wang, S.; Ma, W. A Combination Forecasting Model Based on AdaBoost_GRNN in Depth-Averaged Currents Using Underwater Gliders. In Global Oceans 2020: Singapore–US Gulf Coast; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Wong, A.P.; Wijffels, S.E.; Riser, S.C.; Pouliquen, S.; Hosoda, S.; Roemmich, D.; Gilson, J.; Johnson, G.C.; Martini, K.; Murphy, D.J.; et al. Argo data 1999–2019: Two million temperature-salinity profiles and subsurface velocity observations from a global array of profiling floats. Front. Mar. Sci. 2020, 7, 700. [Google Scholar] [CrossRef]
- Paskyabi, M.B.; Fer, I. Turbulence measurements in shallow water from a subsurface moored moving platform. Energy Procedia 2013, 35, 307–316. [Google Scholar] [CrossRef]
- Xiao, C.; Tong, X.; Li, D.; Chen, X.; Yang, Q.; Xv, X.; Lin, H.; Huang, M. Prediction of long lead monthly three-dimensional ocean temperature using time series gridded Argo data and a deep learning method. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102971. [Google Scholar] [CrossRef]
- Cheng, X.; Li, G.; Han, P.; Skulstad, R.; Chen, S.; Zhang, H. Data-driven modeling for transferable sea state estimation between marine systems. IEEE Trans. Intell. Transp. Syst. 2021, 23, 2561–2571. [Google Scholar] [CrossRef]
- Stanic, S.; Bernard, L.; Delgado, R.; Braud, J.; Jones, B.; Fanguy, P.; Hawkins, J.; Lingsch, W. The 4-dimension ocean cube training test and evaluation area. In Global Oceans 2020: Singapore–US Gulf Coast; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Barbato, G.; Barini, E.M.; Genta, G.; Levi, R. Features and performance of some outlier detection methods. J. Appl. Stat. 2011, 38, 2133–2149. [Google Scholar] [CrossRef]
- Li, H.; Wan, X.; Liang, Y.; Gao, S. Dynamic time warping based on cubic spline interpolation for time series data mining. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; IEEE: Piscataway, NJ, USA; pp. 19–26. [Google Scholar]
- Kar, S.; Garin, V.; Kholová, J.; Vadez, V.; Durbha, S.S.; Tanaka, R.; Iwata, H.; Urban, M.O.; Adinarayana, J. SpaTemHTP: A data analysis pipeline for efficient processing and utilization of temporal high-throughput phenotyping data. Front. Plant Sci. 2020, 11, 552509. [Google Scholar] [CrossRef]
- Lepot, M.; Aubin, J.B.; Clemens, F.H. Interpolation in time series: An introductive overview of existing methods, their performance criteria and uncertainty assessment. Water 2017, 9, 796. [Google Scholar] [CrossRef]
- Bashir, F.; Wei, H.L. Handling missing data in multivariate time series using a vector autoregressive model-imputation (VAR-IM) algorithm. Neurocomputing 2018, 276, 23–30. [Google Scholar] [CrossRef]
- Janik, M.; Bossew, P.; Kurihara, O. Machine learning methods as a tool to analyse incomplete or irregularly sampled radon time series data. Sci. Total Environ. 2018, 630, 1155–1167. [Google Scholar] [CrossRef]
- Cui, Z.; Qing, X.; Chai, H.; Yang, S.; Zhu, Y.; Wang, F. Real-time rainfall-runoff prediction using light gradient boosting machine coupled with singular spectrum analysis. J. Hydrol. 2021, 603, 127124. [Google Scholar] [CrossRef]
- Başakın, E.E.; Ekmekcioğlu, Ö.; Stoy, P.C.; Özger, M. Estimation of daily reference evapotranspiration by hybrid singular spectrum analysis-based stochastic gradient boosting. MethodsX 2023, 10, 102163. [Google Scholar] [CrossRef]
- Li, Z.; Lu, T.; He, X.; Montillet, J.P.; Tao, R. An improved cyclic multi model-eXtreme gradient boosting (CMM-XGBoost) forecasting algorithm on the GNSS vertical time series. Adv. Space Res. 2023, 71, 912–935. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Geiß, C.; Brzoska, E.; Pelizari, P.A.; Lautenbach, S.; Taubenböck, H. Multi-target regressor chains with repetitive permutation scheme for characterization of built environments with remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102657. [Google Scholar] [CrossRef]
- Kanai, S.; Fujiwara, Y.; Iwamura, S. Preventing gradient explosions in gated recurrent units. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Kar, S.; McKenna, J.; Sunkara, V.; Stanic, S.; Bernard, L. Multi-step ahead wave forecasting and extreme event prediction from buoy data using an ensemble of LSTM and genetic algorithm-aided classification model. In OCEANS 2022, Hampton Roads; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Zha, W.; Liu, Y.; Wan, Y.; Luo, R.; Li, D.; Yang, S.; Xu, Y. Forecasting monthly gas field production based on the CNN-LSTM model. Energy 2022, 8, 124889. [Google Scholar] [CrossRef]
- Agga, A.; Abbou, A.; Labbadi, M.; El Houm, Y.; Ali, I.H. CNN-LSTM: An efficient hybrid deep learning architecture for predicting short-term photovoltaic power production. Electr. Power Syst. Res. 2022, 208, 107908. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef]
- Wang, Q.; Kang, K.; Zhang, Z.; Cao, D. Application of LSTM and conv1d LSTM network in stock forecasting model. Artif. Intell. Adv. 2021, 3, 1. [Google Scholar] [CrossRef]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Luo, T.; Cao, X.; Li, J.; Dong, K.; Zhang, R.; Wei, X. Multi-task prediction model based on ConvLSTM and encoder-decoder. Intell. Data Anal. 2021, 25, 359–382. [Google Scholar] [CrossRef]
- Canizo, M.; Triguero, I.; Conde, A.; Onieva, E. Multi-head CNN–RNN for multi-time series anomaly detection: An industrial case study. Neurocomputing 2019, 363, 246–260. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint 2014, arXiv:1412.6980. [Google Scholar]
- Guo, X.; Gao, Y.; Li, Y.; Zheng, D.; Shan, D. Short-term household load forecasting based on Long-and Short-term Time-series network. Energy Rep. 2021, 7, 58–64. [Google Scholar] [CrossRef]
- Mehtab, S.; Sen, J. Analysis and forecasting of financial time series using CNN and LSTM-based deep learning models. In Advances in Distributed Computing and Machine Learning: Proceedings of ICADCML 2021; Springer: Singapore, 2022; pp. 405–423. [Google Scholar]
- Hyndman, R.; Kang, Y.; Talagala, T.; Wang, E.; Yang, Y. Tsfeatures: Timeseriesfeatureextraction.Rpackageversion1.0.0. 2019. Available online: https://pkg.robjhyndman.com/tsfeatures/ (accessed on 8 August 2023).
- Sprintall, J.; Tomczak, M. Evidence of the barrier layer in the surface layer of the tropics. J. Geophys. Res. Ocean. 1992, 97, 7305–7316. [Google Scholar] [CrossRef]
- Wu, S.; Wang, B.; Zhao, L.; Liu, H.; Geng, J. High-efficiency and high-precision seismic trace interpolation for irregularly spatial sampled data by combining an extreme gradient boosting decision tree and principal component analysis. Geophys. Prospect. 2022. [Google Scholar] [CrossRef]
- Lobus, N.V.; Arashkevich, E.G.; Flerova, E.A. Major, trace, and rare-earth elements in the zooplankton of the Laptev Sea in relation to community composition. Environ. Sci. Pollut. Res. 2019, 26, 23044–23060. [Google Scholar] [CrossRef]
- Han, L.; Zhang, R.; Wang, X.; Bao, A.; Jing, H. Multi-step wind power forecast based on VMD-LSTM. IET Renew. Power Gener. 2019, 13, 1690–1700. [Google Scholar] [CrossRef]
- Widiputra, H.; Mailangkay, A.; Gautama, E. Multivariate cnn-lstm model for multiple parallel financial time-series prediction. Complexity 2021, 2021, 1–4. [Google Scholar] [CrossRef]
- Aydog, B.; Ayat, B.; Öztürk, M.N.; Çevik, E.Ö.; Yüksel, Y. Current velocity forecasting in straits with artificial neural networks, a case study: Strait of Istanbul. Ocean. Eng. 2010, 37, 443–453. [Google Scholar] [CrossRef]
- Bai, L.H.; Xu, H. Accurate estimation of tidal level using bidirectional long short-term memory recurrent neural network. Ocean. Eng. 2021, 235, 108765. [Google Scholar] [CrossRef]
- Immas, A.; Do, N.; Alam, M.R. Real-time in situ prediction of ocean currents. Ocean. Eng. 2021, 228, 108922. [Google Scholar] [CrossRef]
- Wubet, Y.A.; Lian, K.Y. Voice conversion based augmentation and a hybrid CNN-LSTM model for improving speaker-independent keyword recognition on limited datasets. IEEE Access 2022, 10, 89170–89180. [Google Scholar] [CrossRef]
- Alahmari, F.; Naim, A.; Alqahtani, H. E-Learning Modeling Technique and Convolution Neural Networks in Online Education. In IoT-enabled Convolutional Neural Networks: Techniques and Applications; River Publishers: Ljubljana, Slovenia, 2023; pp. 261–295. [Google Scholar]
- Krichen, M. Convolutional neural networks: A survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]

















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kar, S.; McKenna, J.R.; Anglada, G.; Sunkara, V.; Coniglione, R.; Stanic, S.; Bernard, L. Forecasting Vertical Profiles of Ocean Currents from Surface Characteristics: A Multivariate Multi-Head Convolutional Neural Network–Long Short-Term Memory Approach. J. Mar. Sci. Eng. 2023, 11, 1964. https://doi.org/10.3390/jmse11101964
Kar S, McKenna JR, Anglada G, Sunkara V, Coniglione R, Stanic S, Bernard L. Forecasting Vertical Profiles of Ocean Currents from Surface Characteristics: A Multivariate Multi-Head Convolutional Neural Network–Long Short-Term Memory Approach. Journal of Marine Science and Engineering. 2023; 11(10):1964. https://doi.org/10.3390/jmse11101964
Chicago/Turabian StyleKar, Soumyashree, Jason R. McKenna, Glenn Anglada, Vishwamithra Sunkara, Robert Coniglione, Steve Stanic, and Landry Bernard. 2023. "Forecasting Vertical Profiles of Ocean Currents from Surface Characteristics: A Multivariate Multi-Head Convolutional Neural Network–Long Short-Term Memory Approach" Journal of Marine Science and Engineering 11, no. 10: 1964. https://doi.org/10.3390/jmse11101964