1. Introduction
Building a strong ocean state is currently a major strategic goal for countries worldwide, as reflected in three major aspects: exploration and awareness, exploitation, and integrated control of the ocean [
1]. Therefore, placing robots in the complex underwater environment to partially replace simple human tasks is the primary key technology to achieve this strategic goal, and the related research has become a hotspot in academia and industry. Currently, unmanned and intelligent robots are the mainstream trend in underwater robotics. However, for underwater robots to explore the marine environment, especially for a particular handling requirement, there are continuous time and discrete state features, and multiple robots must collaborate to fulfill the task [
2]. Existing studies claim that when many simple robots collaborate underwater, their adversarial relationship increases significantly, severely reducing the overall system efficiency [
3]. Moreover, the wading environment increases task uncertainty even more. However, sharing information and resources between individual robots and intelligently modifying the multi-robot system can improve the system’s robustness and fault tolerance. Generally, cooperation between the robots will improve the ability of the robot group, but the way to cooperate, model, and analyze their cooperation is challenging. Thus, underwater multi-robot swarm gaming and task allocation is the core technology to guarantee orderly task completion, utility improvement, and cost reduction during robot exploitation.
Currently, the literature does not offer systematic research on underwater multi-robot swarm games and task allocation for underwater scenarios. However, several promising swarm control and task allocation algorithms exist for land and air applications, such as unmanned vehicles and UAVs [
4,
5]. Swarming is a class of formation control algorithms that rely on speed synchronization and relative distance regulation between mobile groups of robots [
6]. The swarm control aims to utilize local or limited information to drive multiple robots to satisfy certain constraints on their physical position [
7]. Mobile formations are critical for a wide variety of robotic applications, including transportation [
8], space flight control [
9], and environmental monitoring [
10]. Nevertheless, the formation topology and the sensing and communication capabilities required by the robots pose some additional concerns. Given the different constraints and the complexity of each robotic task, several ground-level control algorithms have been proposed [
11], classified into leader–follower, virtual structure, and behavioral formation control, which we considered when designing our group model.
The cooperative relationship between individuals can be very complex. For instance, the leader–follower model designates one or more robots as leaders and places them on the expected trajectory formation [
12,
13]. The followers use the leader’s position and kinematics to maintain specific offsets and form the desired formation. In virtual structure schemes, the robotic groups are considered as a single object with a specified trajectory, where each robot uses this information and its local information to plan its motion. These schemes typically involve consensus algorithms to drive the robot’s state to a common value [
14]. Specifically, the virtual leader approaches the robots to agree on the position of a virtual robot [
15,
16,
17], which is then treated as the leader, adopting a leader–follower scheme. The behavioral formation control schemes assign simple behaviors to individual robots, e.g., cohesion and collision avoidance, to create an emergency formation [
18,
19,
20,
21]. A well-known example is a swarm, typically deployed in large groups of robots [
22]. The actions of the entire swarm can be directed by a default leader [
23] that does not explicitly identify itself as the leader. Instead, it follows its reference trajectory and, because of group cohesion, forces the group to follow it in the desired direction.
If one wishes to design a robot system that can perform complex tasks, the number of robots must be very large, which poses a challenging problem, but affords good prospects. Because of the many robots within the group, the operator cannot directly supervise each robot, but must delegate a certain level of autonomous decision making to the group. Bionics-based task assignment algorithms can address autonomous decision making for multiple robots in unknown environments, affording a wide range of task capabilities and presenting highly adaptable dynamics [
24]. For example, ants adopt a labor division mechanism and adjust their tasks according to the environmental changes so that the individual labor division meets the colony requirements depending on the task. For swarming insects, labor division means that different individuals perform different tasks. Labor division is a fundamental feature of social insects and is the main reason for their ecological success. Simultaneously, it is an important group intelligence behavior that solves decision-making problems in dynamic environments [
25].
Therefore, with the development of swarm technology for multi-robot systems, scholars have conducted in-depth studies on task allocation for robotic group systems. For instance, the authors of [
26] developed a cross-entropy-based collaborative task assignment algorithm for UAVs that effectively and accurately assign tasks to various collaborating UAV types. The algorithm’s performance is related to the random samples extracted and is affected if the samples are not random or the sample size is small. The work of [
27] combined the directed graph method and the wolf pack algorithm to construct a task assignment architecture, while [
28] used the simulated annealing method to optimize the particle swarm algorithm for task allocation. In contrast, intelligent optimization algorithms, such as the wolf pack and the particle swarm algorithms, are prone to fall into locally optimum solutions because of limited population diversity. In [
29], the authors exploited the iterative Gale–Shapley algorithm to achieve UAV task allocation, reaching a fair and efficient solution. Furthermore, [
30,
31] optimized the UAV task allocation process using game theory. Although this strategy obtains the desired results, such an iterative process is challenging when applied to highly variable or unexpected tasks. Alternative solutions [
32,
33] optimize the task order based on auction and consensus algorithms to achieve conflict-free task allocation. Nevertheless, deficiencies in the auctioneer’s identity and inadequate bidding values limit the algorithm’s effectiveness and compatibility when applied to unexpected new tasks. In [
34], the authors developed a time-limited immune cloning algorithm and adjusted task allocation according to a time-priority scheme. However, the algorithm’s inability to retain infeasible elite solutions and learn evolutionary experience limits its performance.
In summary, existing research on task allocation for swarm robot systems has mostly addressed swarm control in non-specific environments relying on distributed approaches. Moreover, heuristic-based intelligent algorithms have demonstrated incipient advantages for task allocation problems in specific environments. Game theory is often used to study individual conflicts of interest and cooperation, where individuals optimize their benefits in the game, similar to the decision-making process when robots execute their tasks. Hence, this paper proposes a distributed autonomous decision-making framework based on game theory that is appropriate for the task allocation problem of group robots in complex underwater environments. Specifically, we apply heuristic improvements to the relevant task allocation algorithms and model the underwater robot swarm and task allocation problem as a coalition-formation game, where the robots are divided into two types of individuals, namely, selfish and altruistic. Although conflicts between the robots may occur, the game’s ultimate goal is to find a stable Nash equilibrium in polynomial time, ensuring that all robots agree on the current allocation scheme and collaborate to complete the corresponding search and handling tasks. To the best of our knowledge, this work conducts the first experiments utilizing the above framework for underwater robot swarm games and task allocation.
2. Materials and Methods
Classifying basic task types for underwater robots in complex environments is helpful for modeling and analysis, given the simplicity and the large number of underwater task types. Therefore, a mathematical model was developed for the robot and task states based on the ‘many-to-many’ collaborative relationship between multiple underwater robots and multiple tasks. Then, the temporally continuous and state-discrete characteristics of the tasks and resources were modeled utilizing game theory. We developed a game-based multi-tasking robot model for robotic tasks in specific environments based on task and object characteristics. Additionally, the corresponding heuristic algorithms were improved to solve the swarming and task allocation problem of autonomous underwater robots in complex environments. It should be noted that real application scenarios are more complex than the ones examined here. However, since our experiments were conducted in real waters, our modeling methods and experiments could be quickly adapted to real task scenarios.
2.1. Basic Assumptions
Suppose there is a set of
N robots
A = {
a1,
a2, …,
aN} and a set of tasks
T =
T* ∪ {
tφ}, where
T* = {
t1,
t2, …,
tN} and
tφ means that no task is performed. Each robot has an independent utility function
πi: T × |A|→R, which is a function of the number of tasks given to a robot and its collaborating robots
p ∈ {1, 2, …,
N} (called the movers). The individual utility of
tφ is zero, regardless of the participants. Since each robot has a finite ability to complete the task individually, at most, one task can be given to a robot. Hence, we aim to find a robot that maximizes global utility, defined as the sum of the individual utilities of the entire swarm. The above problem is defined as follows:
and satisfies
where
xij is a binary decision variable indicating whether to assign task
tj to robot
ai.
Assumption 1 (Homogeneous robots with limited capabilities). Since a swarm is achieved through large-scale collaboration, this paper considered a homogeneous underwater multi-robot system, where the utility function πi of each robot is related to the number of collaborating robots. Note that the robots in this work may have different preferences for a given task, e.g., all robots in a swarm are divided into selfish and altruistic, with the former searching for themselves and gaining some benefit when they find a target. The altruistic robots record the search process and share it with the others during the search. Additionally, since altruistic robots record and share information, they move more slowly than selfish robots. Keep in mind that robot ai’s utility function πi(tj, m) may be used to determine the preference relation. As an illustration, for πi(t1, m1) > πi(t2, m2), it may be claimed that compared with the task (t2, m2), robot ai is more inclined to select the task (t1, m1).
Assumption 2 (Communication between the robots). The communication network of the entire multi-robot system must be strongly connected, i.e., there is a directed communication path between any two robots. Given a network, we denote as ai a set of neighbors. This assumption aims to enable individuals to share information.
Assumption 3 (Mixed reality tasks). Each task may be a mixed reality task, i.e., completing the task may require the collaboration of several simple robots. We assume that each task can be completed by a single robot; although it may take a long time. However, in the following section, we will also discuss a particular case where some tasks require at least a certain number of robots.
Assumption 4 (Prior information about the robots). Each robot ai. knows only its utility function πi for each task and not the utility functions of the other robots πj. However, through communication, the robots are informed which task is currently selected by a neighboring individual. Note that each robot does not necessarily have to know the true information all the time. Additionally, each robot can have its local information. This assumption guarantees the distributed decision making of robots because each robot only knows and cares about its utility functions.
2.2. A Game-Based Model for Multitasking Robots
Next, we transform the multi-task multi-robot problem into an anonymous game problem where an individual can selfishly prefer tasks based on its preferences (see
Figure 1).
Definition 1. An instance of a GRoup Robot Partitioning and Placement Event (GRPE) is a three tuple (A, T, P) comprising: (i) N robots A = {a1, a2, …, aN}; (ii) a set of tasks T = T* ∪ {tφ}; and (iii) robot preference relations comprising N tuples P = (P1, P2, …, PN). For each robot ai, Pi describes its preference relation for the set of task-combination pairs , where X* = T* × {1, 2, …, N}. The task-combination pair (tj, m) is interpreted as “performing task tj with m collaborators”. Any pair indicates that robot ai strongly prefers x1 to x2, implying indifference to the preference of x1 over x2. Similarly, denotes a weak preference for the robot ai. x1∼i x2 indicates that their preferences are indifferent.
Definition 2. Consider an instance (A, T, P) where the task robot is defined as a set separating the robots in set A, where Sj ⊆ A is the group performing a particular task tj such that and . is the set of robots that choose the empty task. Given an assignment Π, Π(i) denotes the index of tasks a robot gives to robot ai. For example, SΠ(i) denotes the group where the robot belongs, i.e., SΠ(i) = {Sj ∈ Π | ai ∈ Sj}. GRPE aims to identify a stable robot task allocation that all robots agree on, based on a Nash equilibrium defined as follows:
Definition 3. A task allocation Π is considered to be a Nash equilibrium if for every robot ai ∈ A, there exists . In other words, in a Nash equilibrium, each robot prefers its current set of tasks to join the others. Therefore, each robot will not have any conflicts with his group, and no robot will unilaterally deviate from its current decision.
Nash equilibrium is a state, in which each robot does not want to change its own choice, because only its own change cannot improve its own utility. In this state, the communication burden is reduced in a swarm [
35,
36]. During the convergence to a Nash-stable state, when a robot is willing to deviate, it does not need permission from the other robots. This property may be different from other solution concepts. Therefore, each robot must only be informed of its decision to change without negotiation. This reduces the communication loss between robots in the proposed approach.
For the sake of the evolutionary study, we consider scenarios where the group robot’s adaptability depended on the work done. Thus, we establish assumptions on how the task set
T at any time affected the group productivity
ω when allocating tasks to underwater population robots. Then, we supposed that the geometric mean of these production values was proportional to the group fitness over time. When performing a task, we expected that the ratio of tasks
tj to
T would define productivity over a specific period:
where
tj/
T is the percentage of work completed, and 0 <
β < 1 is a weighting parameter that indicates the relative significance of tasks
tj and
T. As σ reduces, Equation (4) quickly approaches 0, satisfying a Gaussian distribution when
tj/
T =
β. Here, we assume that there is an optimal task allocation ratio for each scenario. This proportion was assumed to be a parameter
β, so when the actual distribution proportion was close to this value, the output value of utility is close to the optimal value. Thus, we used a function similar to Gaussian distribution to simulate such a hypothesis.
In the following experiments, we evaluated the capacity of the underwater robotic swarm to reach different adaptive collaborator distributions by considering various values and demonstrated that the population conducted both jobs concurrently because of the proliferation of several components. In our experiments, if a task was assigned but was not completed, the added value of benefit for the whole group was 0.
2.3. Preference Suppression
This section presents the key conditions for suppressing the robot preferences, enables the proposed approach to provide all the desirable properties described in
Section 1, and then explains their implications.
Definition 4. Consider an instance (A, T, P) where the preference relation of robot ai holds for task tj, if for any there are , so that . For example, suppose that mi has the following relation: This preference relation reveals that robot ai must cope with task t1 and for task t2 . Based on Definition 4: The preference relation for task t1 is consistent with the previous one, while the preference for task t2 is inverse. This paper considers that each robot has preferences for all given tasks and prefers to perform a task with a smaller number of collaborators, i.e., they are socially inhibited.
Social inhibition corresponds to a situation where a single robot’s utility function should decrease monotonically as the group size increases because engineering applications frequently lead to social restrictions. For instance, the overall work capacity produced by several collaborating robots does not rise according to robot interference. Assuming individual work productivity to be a measure of individual utility, the individual utility declines monotonically as the number of collaborators increases. Another illustration is that the individual utility of robots is reduced when several robots utilize the same resources concurrently, e.g., traffic congestion affects travel time. Furthermore, the non-superadditive scenario is more plausible than the superadditive case because subjects in a superadditive environment always attempt to collaborate, but individuals in a non-superadditive environment may not always strive to cooperate. When individuals form a group, whether they cooperate or influence each other is related to their choices, environment, and tasks. Note that the proposed framework can accommodate selfish individuals who greedily follow their personal preferences and altruistic individuals with reciprocal properties as long as the preferences have social disincentives. This implies that the framework can be used for group systems of different organizations.
2.4. Stability of Nash Equilibrium
Definition 5. This work employs the term iteration to denote an iterative phase where a single arbitrary robot compares the set of available tasks given to an existing robot and then updates the assignment according to the personal preferences of the assigned exclusion. Here, the robot conducting the iteration is named the decision robot. All robots consecutively perform the same process in the next iteration until each robot does not deviate from a particular task, which is effectively a Nash-stable allocation.
Assumption 5. The application requires a mutually exclusive algorithm to select decision robots during each iteration. Hence, this section assumes that all robots are fully connected and that they somehow select and understand the decision robots through this connection. However, in the next section, we present a distributed algorithm that allows the proposed method to be executed under strongly connected communication networks and even in an asynchronous manner.
Lemma 1. Consider an instance (A, T, P) and assume that a new robot , holds a preference relation for each task T, where a Nash-stable allocation has been established. Then, the maximum number of iterations required for the new instance , where , : (i) also satisfies social inhibition; (ii) contains a stable Nash allocation; and (iii) converges again to a Nash-stable allocation .
Proof. Given a task assignment Π, Equation (7) provides the number of additional robots tolerated in the population for robot
ai. Because of socially inhibited preferences, this value satisfies the following characteristics: (i) if Π is a Nash equilibrium, for each robot
ai, there exists Δ
Π(i) ≥ 0; (ii) Δ
Π(i) < 0 indicates that robot
ai is willing to deviate to another set in the next iteration; and (iii) for a robot
ai that deviated during the last iteration and updated its allocation to Π, we consider
.
From Definition 4, it is evident that the new instance still possesses social inhibition. Assuming that Π0 denotes a Nash-stable allocation in the original instance when a new robot conducts a task in T and creates a new task allocation Π1, then ΔΠ1(r) ≥ 0 as presented in proof (iii) above. If no robot aq ∈ A with ΔΠ1(q) < 0 exists, then Π1 is Nash-stable. Lemma 1 is essential for the existence and convergence of Nash-stable distributions and a fast adaptation to dynamic environments. □
Theorem 1. If an instance (A, T, P) of GRPE has social inhibition, then the number of iterations required to determine a Nash-stable allocation is at most .
Proof. Assume a Nash-stable allocation in an instance with only one robot. Then, we add another arbitrary robot, find a Nash-stable allocation for this new instance, and repeat the process until all robots are included. From Lemma 1, if a new robot is added to an instance where the current allocation is Nash stable, then the maximum number of iterations required to find a new Nash-stable allocation is the number of existing robots plus 1. Thus, the maximum number of iterations required to find a Nash-stable allocation for an instance (
A,
T,
P) is:
□
3. Distributed Algorithms
In the previous section, we assumed that under a fully connected network, only one robot is selected as the decision robot during each iteration. In contrast, this section proposes a decentralized algorithm (see Algorithm 1) under a strongly connected network, where each robot makes decisions based on its local information and simultaneously influences its neighbors. Nevertheless, because of the distributed mutually exclusive subroutines, we prove that Theorem 1 still holds. The details of the decentralized master algorithm are presented below. It should be noted that distributed decision making is a possible scenario in future practical applications because individuals are not always able to share information.
| Algorithm 1: Decision-making algorithm for robot ai |
| 1: Initialize: T*, πi(tj, p), xij, Sj, Sk for all and . |
| 2: while true do |
| 3: |
| 4: for do |
| 5: for do |
| 6: for do |
| 7: |
| 8: Join Sk and update |
| 9: end for |
| 10: end for |
| 11: end for |
| 12: end while |
| 13: return: Optimal value of |
Each robot ai has some local variables , the satisfied variable, and ri and si (lines 1–2), where is the robot’s locally known assignment, satisfied is a binary variable indicating whether the robot is satisfied with , and thus does not wish to deviate from its current set, and is an integer variable indicating how many times it has evolved, i.e., the number of updating iterations before that moment. si ∈ [0, 1] is a uniform random variable generated over time acting as a random timestamp. We consider , where the robot ai checks which group is the most popular among the other groups and we assume that the other robots are still in the existing group (line 5). Then, if the robot is more popular than the current group, the newly discovered group is added. In this example, the robot updates to reflect its new decision, adds ri, and generates a new random timestamp si (rows 6–10). In any case, the robot determines that the currently selected set is the most preferred, and therefore, the robot is satisfied (line 11). The robot ai generates and sends a message: to its neighboring robots and vice versa (line 13).
Since each robot simultaneously updates its locally known allocations, one of these should be updated by the decision robot in the previous iteration. We refer to this division as the effective division at iteration time. The distributed collision avoidance example enables the robot to identify valid allocations among all locally known current allocations, even in strongly connected networks and asynchronous environments. The above assumptions prevent robots from competing for the same task. Before executing this subroutine, each robot ai collects all messages received from its neighboring robots (including Mi). Using this message set, the robot checks whether its allocation Πi is valid. If any other allocation Πk exists, such that , then the robot considers Πk to be more valid than Πi. If rk = ri and sk > si, Πk and Πi evolved simultaneously, but the former has a higher timestamp. Since Πk is considered more efficient, the robot ai must recheck whether there is a higher priority coalition that provides Πk in the next iteration. Therefore, the robot sets the satisfaction to false. After completing this subroutine, and depending on satisfaction, each robot performs the decision process (lines 4–12 in Algorithm 1) again and/or shares the existing locally known allocation with its neighboring robots (line 13 in Algorithm 1).
Thus, the distributed collision avoidance algorithm ensures that only one valid allocation dominates (or will eventually dominate, depending on the communication network) over any other allocation. In other words, multiple allocations evolve locally, but given a strongly connected network, one of them will eventually survive. From the allocation perspective, this can be seen as evolving from a random sequence of robots under a fully connected network. Hence, allocation becomes Nash stable in polynomial time, as shown in Theorem 1. In an extreme case, we may end up with multiple Nash-stable allocations. Nevertheless, because of the collision avoidance algorithm, one of them can be selected by the robot allocation. All these features reveal that a robot using Algorithm 1 can find a Nash-stable allocation in a decentralized manner and Theorem 1 still holds.
4. Performance Analysis
First, we discuss the running time of the proposed framework for finding Nash-stable allocations, referring to the unit time required per robot to execute the main loop of Algorithm 1 (lines 4–15). Depending on the communication network considered, and in particular, if it is not fully connected, some given robots may have to execute this loop to share their locally known allocation information without affecting ri (line 1). Since this process requires a unit time step, we refer to it as a virtual iteration to distinguish it from a (normal) iteration that increases ri.
Note that this virtual iteration occurs at most dG times consecutively before the normal iteration occurs, where dG is the graph diameter of the communication network. Thus, according to Theorem 1, the total time step required to find a Nash-stable allocation is O(dGN2). In the case of a fully connected network, it becomes O(N2) since dG = 1. Note that the complexity of our algorithm is less than the centralized algorithm, i.e., O(N2*Nt).
Given a locally known effective allocation (line 5 in Algorithm 1), every robot studies Nt + 1 optional task coalition pairs in each iteration, including tφ. Thus, the computational overhead per robot and iteration is O(Nt). Considering the total time step required, the running time of the proposed algorithm can be limited to O(dGNtN2). Since Theorem 1 is conservatively analyzed, the actual running time can be much smaller than the bound.
This section investigates a lower bound (or approximation ratio) on the suboptimality of the proposed framework considering global utility, i.e., the objective function in (1). Given an allocation Π, the global utility value can be equivalently rewritten as:
Note that we derive {
xij} from Equation (1) and Π from Equation (6), and vice versa. Let the JGRPE and JOPT represent the global utility and optimal value of the Nash-stable allocation obtained by the proposed framework. In this paper, the fraction of the JGRPE relative to JOPT is the suboptimality of the GRPE, denoted as:
The lower bound for suboptimality can be determined by the following theorem.
Theorem 2. Given a Nash-stable allocation Π obtained from GRPE, its suboptimality based on the global utility has lower bound:where Proof. Let Π* denote the optimal allocation of the objective function in Equation (6). Given a Nash-stable allocation Π, from Definition 3, it holds that ∀
ai ∈ A:
where
denotes task
tj ∈
T to which robot
ai should be added according to the optimal allocation Π*, and
Sj ∈ Π is the set of tasks
tj whose cooperators follow a Nash-stable allocation Π.
The right-hand side of Inequality (12) can be rewritten as:
where
, and
is the ideal combination of tasks
that maximizes the objective function.
When summing all robots, the inequality in (12) is expressed as:
The left-hand side of Inequality (14) is the value of the objective function for the Nash-stable allocation Π, JGRPE, and the first term on the right-hand side is the optimal value, JOPT. The second term on the right-hand side can be interpreted as the sum of the utility loss per robot because of the delay in making decisions about its optimal task, given that the other robots still follow the Nash-stable allocation.
The upper bound on the second term is defined as
The highest value is
where
Therefore, Equation (14) can be rewritten as:
□
The two sides are divided by JGRPE and rearranged to obtain a suboptimal lower bound on the Nash-stable allocation (10).
The suggested framework also applies to dynamic environments, such as unexpected additions or losses of robots or tasks, because of its fast convergence to Nash-stable allocations. According to Lemma 1, if a new robot joins an ongoing task whose allocation has already been determined, the number of iterations required to converge to a new Nash-stable allocation is, at most, the number of all robots. The framework can respond to any environmental changes by establishing a new consistent task allocation in polynomial time.
In this framework, for each iteration, each robot does not need to wait or ensure that its locally known information has been propagated to some neighborhood group. Instead, as described in Remark 5, it is sufficient for the robot to receive local information from one of its neighbors, decide, and send the updated assignment back to some of its neighbors. Temporary disconnection or non-operation of some robots may also lead to virtual iterations. However, it does not affect the existence, convergence, and suboptimality of Nash-stable allocations in the proposed framework, as verified in
Section 5.
5. Results and Discussion
This section provides a concise and precise description of the experimental results, their interpretation, and some conclusions.
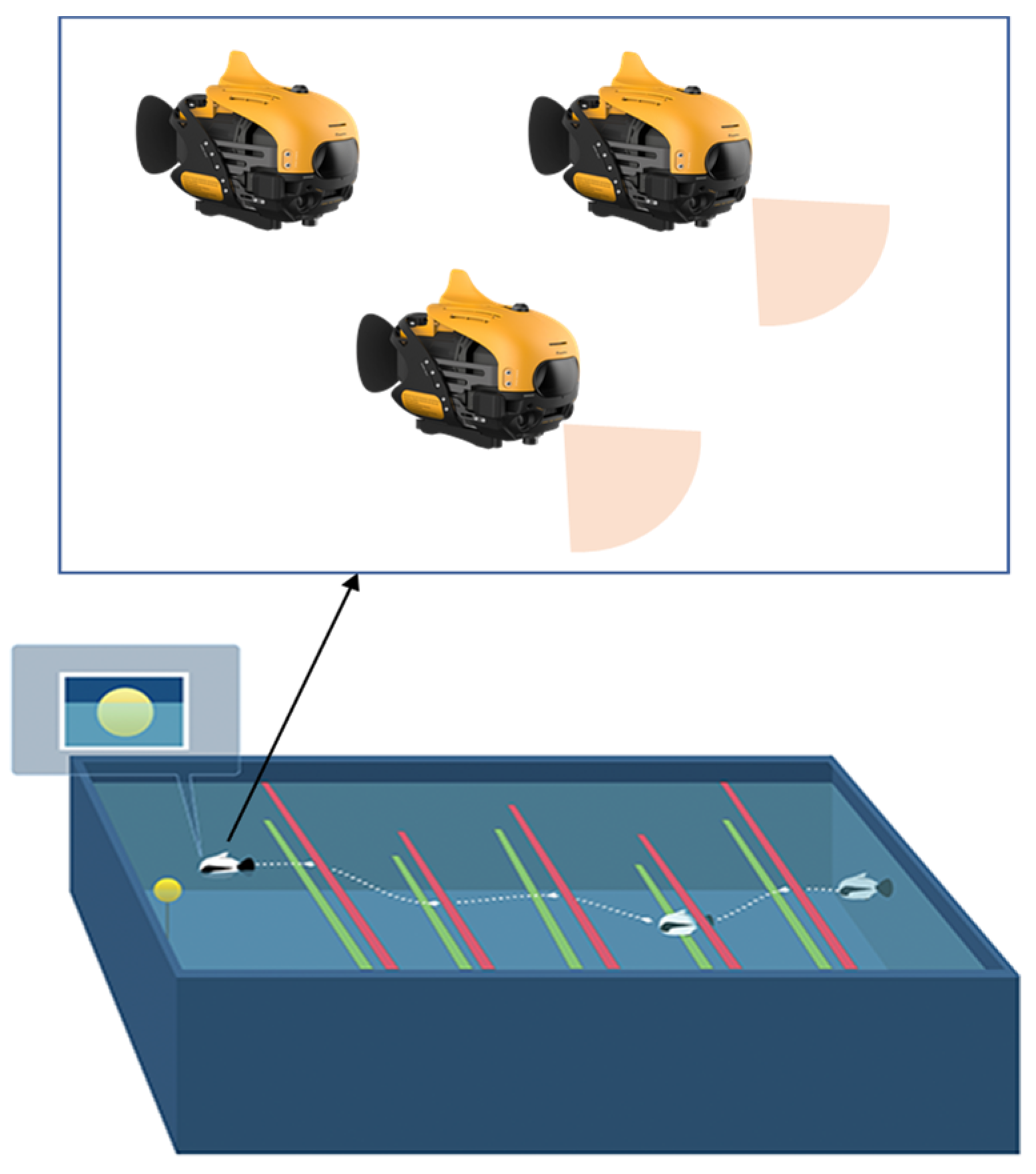
We applied the proposed framework and algorithms to a practical underwater multi-robot system and evaluated its performance in an underwater robot swarm game and task assignment. According to the practical application requirements, the tasks in the following experiments were tightly coupled, i.e., completing each task required multiple robots to collaborate, N robots were reasonably assigned to tasks at T stations, and the robots conducted the task assignment decision process in a distributed and self-organizing manner. Several targets to be searched were placed in a rasterized two-dimensional rectangular region and that an individual robot searched for a target when it moves to its location. Different robotic fishes could repeatedly search for each target, but each robot could not repeatedly search for the same target. The target’s location and number were random quantities. We assumed that robots could use different strategies, i.e., altruistic or selfish. Altruism referred to sharing information in the search process with other robots, while selfishness meant that robots only cared about their search and were unwilling to share information. Robots could reduce blind searches after obtaining information shared by others, improving search efficiency. Note that sharing information meant paying extra costs. Here, altruistic robots slowed down because of information sharing.
Figure 2,
Figure 3,
Figure 4 and
Figure 5 show the effects of selfish and altruistic behavior on a collaborative search in a swarm of underwater robots.
Figure 2 illustrates the number of underwater robots
N = 3 (two yellow, one blue, and one white robotic fish), all with altruistic behavior. This experiment involved a single target (the balloon in the lifebuoy) randomly distributed in a 700 × 1500 water space. In
Figure 2a, the robots were initially in a random decision-making state for the task requirements. Over time, the algorithm iterated, and the robots made ad hoc decisions about the task while locally interacting with each other (
Figure 2b–e). Eventually, as illustrated in
Figure 2f, after 83 s of iteration, the robots aggregated to form a stable Nash partition, and the entire robotic system achieved stable decision results.
To verify the proposed framework’s completion efficiency under selfish behavior,
Figure 3 displays how the underwater robots completed the collaborative search task when all robots were selfish while the remaining parameters were preserved.
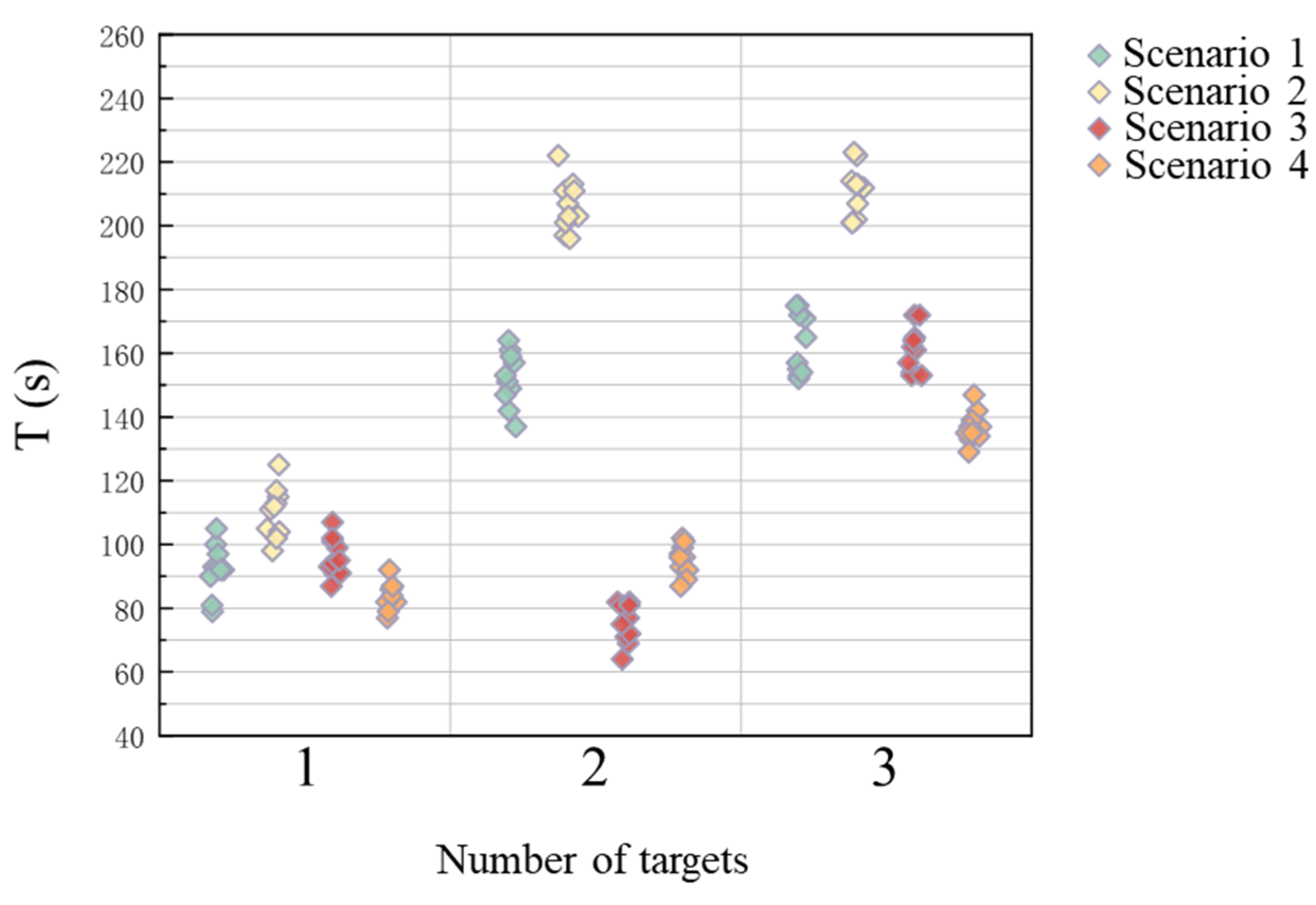
Figure 3 highlights that selfish versus altruistic behavior did not significantly affect the collaborative search completion efficiency when the number of robots and the communication network strength were equal. Therefore, we also explored increasing the number of targets to three with the multi-robot system containing two altruistic and one selfish individual (
Figure 4). We found that mixed robot groups collaborated more efficiently than single selfish or altruistic robots. Additionally, we explored the effect of different target and robot number pairings on the collaborative searching of robot swarms. To eliminate randomness, 10 independent experiments were conducted for each scenario, with the experimental records presented in
Figure 5.
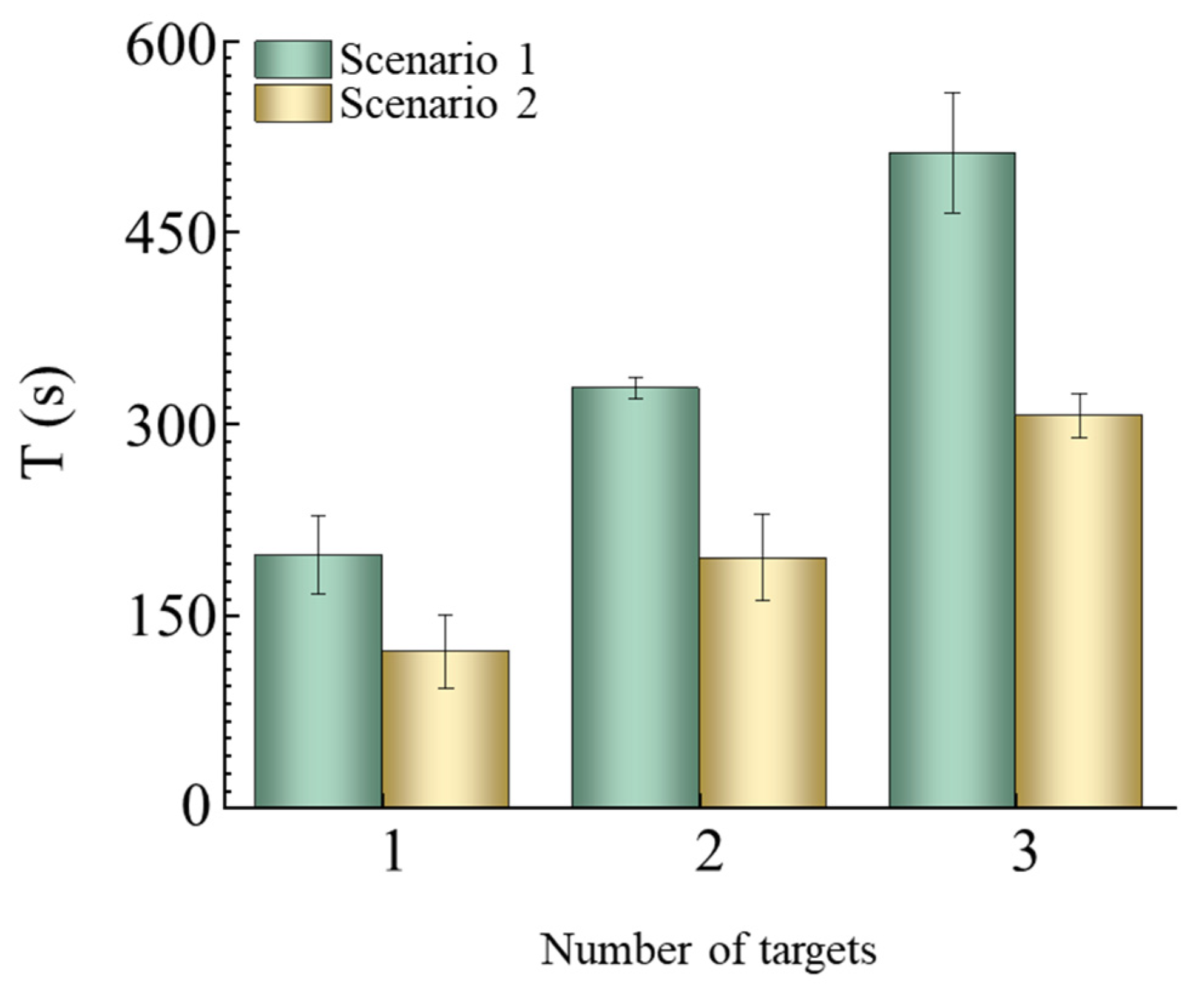
Figure 6 compares the average efficiency based on the standard errors from
Figure 5.
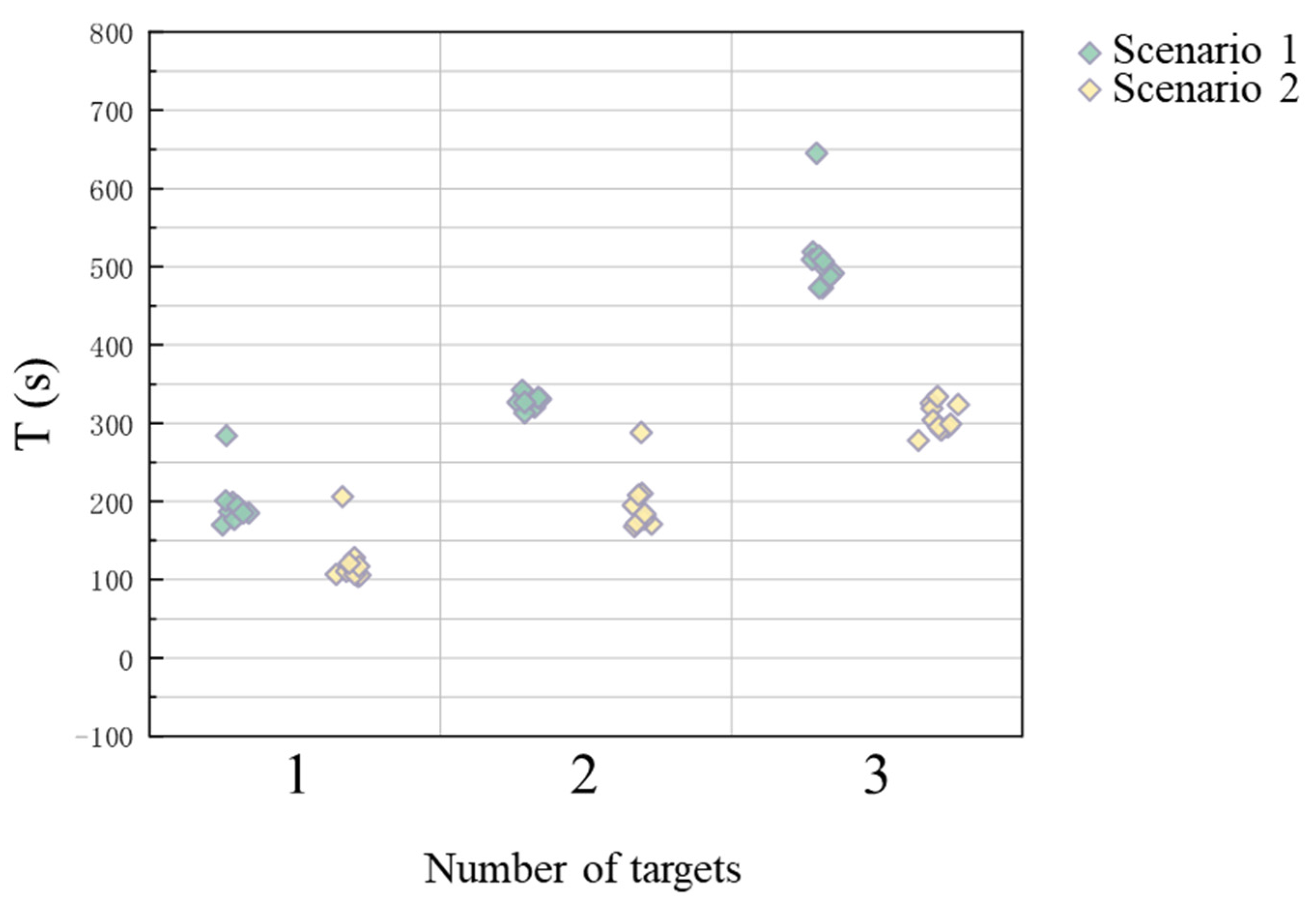
Next, we applied the proposed theoretical framework to underwater robot swarm assignment experiments. Several pending resource point locations were set within a rasterized two-dimensional rectangular region, and when a robot fish moved to a resource point location, we considered that it had searched for that resource point. The resource point locations and the number of resources were random quantities. The robots were divided into two classes: Class A comprised the searching robots, and Class B included the carrying robots. Class A robots had a search-based strategy, and when they searched for a resource point, they share information with the other robots, i.e., coordinates of the resource point and the number of resources. Accordingly, Class B involved the carrying robots who move back and forth between the resource point and the swarm base to simulate carrying based on the information obtained by Class A robots. Class B robots implemented a random wandering strategy if there was no resource information in the swarm. Similarly, we explored the effect on robot swarm task allocation with different resource points and number pairings and conducted 10 independent experiments. The corresponding experimental results are illustrated in
Figure 7 and
Figure 8.
The difference between our two experiments was that in the first experiment, only a search taskwas considered, while in the second experiment, the robots conducted tasks in addition to searching. This is important as the latter experiment considers applications of various complexity. The experimental results demonstrate the complexity of cooperation between individuals and the effectiveness of modeling using game theory.
6. Conclusions
This paper introduced the concept of game theory to the swarm game and task assignment decision of underwater robots in complex environments. The underwater robots were defined as selfish and altruistic individuals capable of independent thinking and maximizing the benefits by interacting with local state information to achieve the distributed self-organized task assignments of multi-robot systems in stochastic environments. This paper delved into the key issues in the robot swarm process and the game theory Nash equilibrium. Finally, the proposed model and algorithm were verified experimentally, demonstrating that the decision framework afforded appealing robustness, scalability, and performance for dynamic task assignments. Our results proved the feasibility of employing game theory to model and analyze the task allocation of robot swarms. The experimental results also demonstrated the effectiveness of this analysis method, suggesting that the proposed method can effectively deals with uncertain task scenarios, it can, therefore, be used to design and implement algorithms.
In future research, we aim to improve the constraints according to practical application requirements, improve the task model and decision framework, and conduct preliminary multi-robot multi-tasking application research to extend our method to more practical task allocation requirements. Specifically, from a theoretical perspective, we will establish a model closer to the experiment to support practical applications. From an application perspective, we will expand our experiments to real application scenarios, such as actual work scenes, and implement our method on complex tasks, such as underwater environment detection and rescue. Our work is expected to enable appealing results for tasks with strong randomness and uncertainty.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}