
Machine Learning Techniques for Estimating Soil Moisture from Smartphone Captured Images


Abstract
:1. Introduction
- A comparison has been established among the ML models throughout the experiment research to find a better, more efficient model for soil moisture estimation.
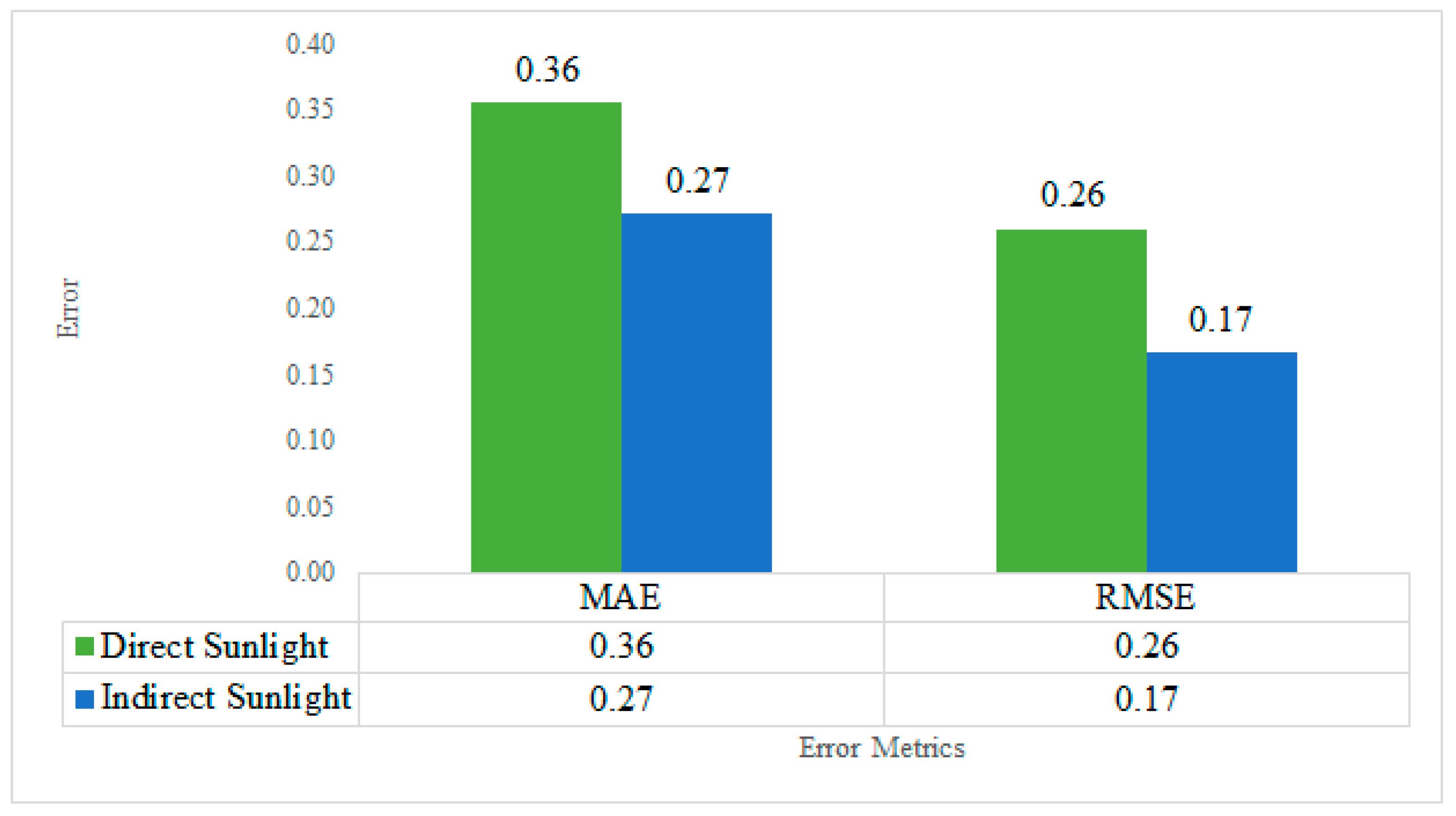
- A comparative analysis of the research findings has been presented to understand the differences in moisture accuracy using various smartphone devices and direct and indirect sunlight conditions during soil image capture.
2. Related Works
2.1. Machine Learning Models for Soil Moisture Prediction
2.2. Image Capturing Devices
2.3. Lighting Conditions during Image Capture
3. Materials and Methodology
3.1. Soil Samples
3.1.1. Fields of Study
3.1.2. Soil Analysis and Soil Imaging
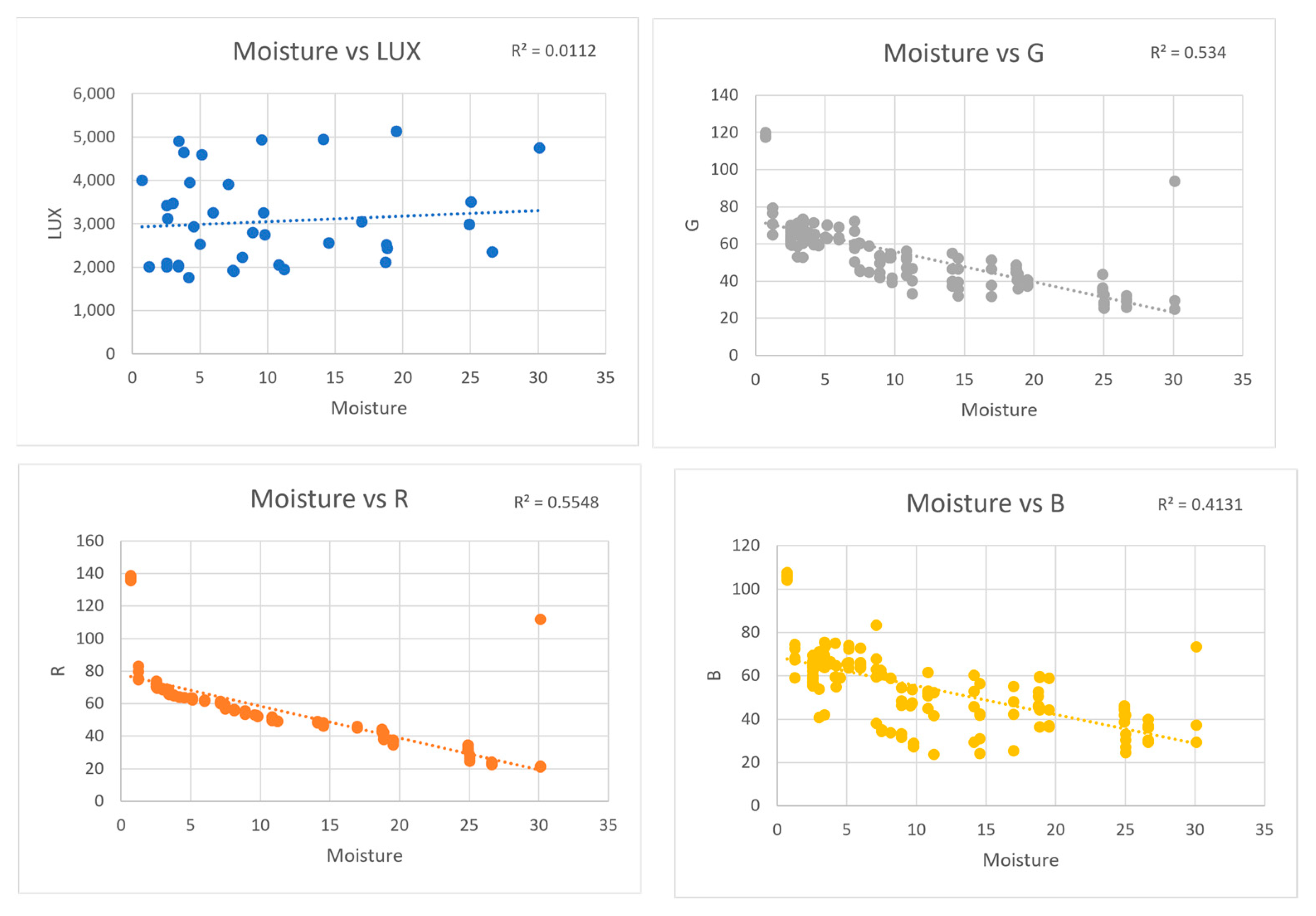
3.2. Soil Image Analysis
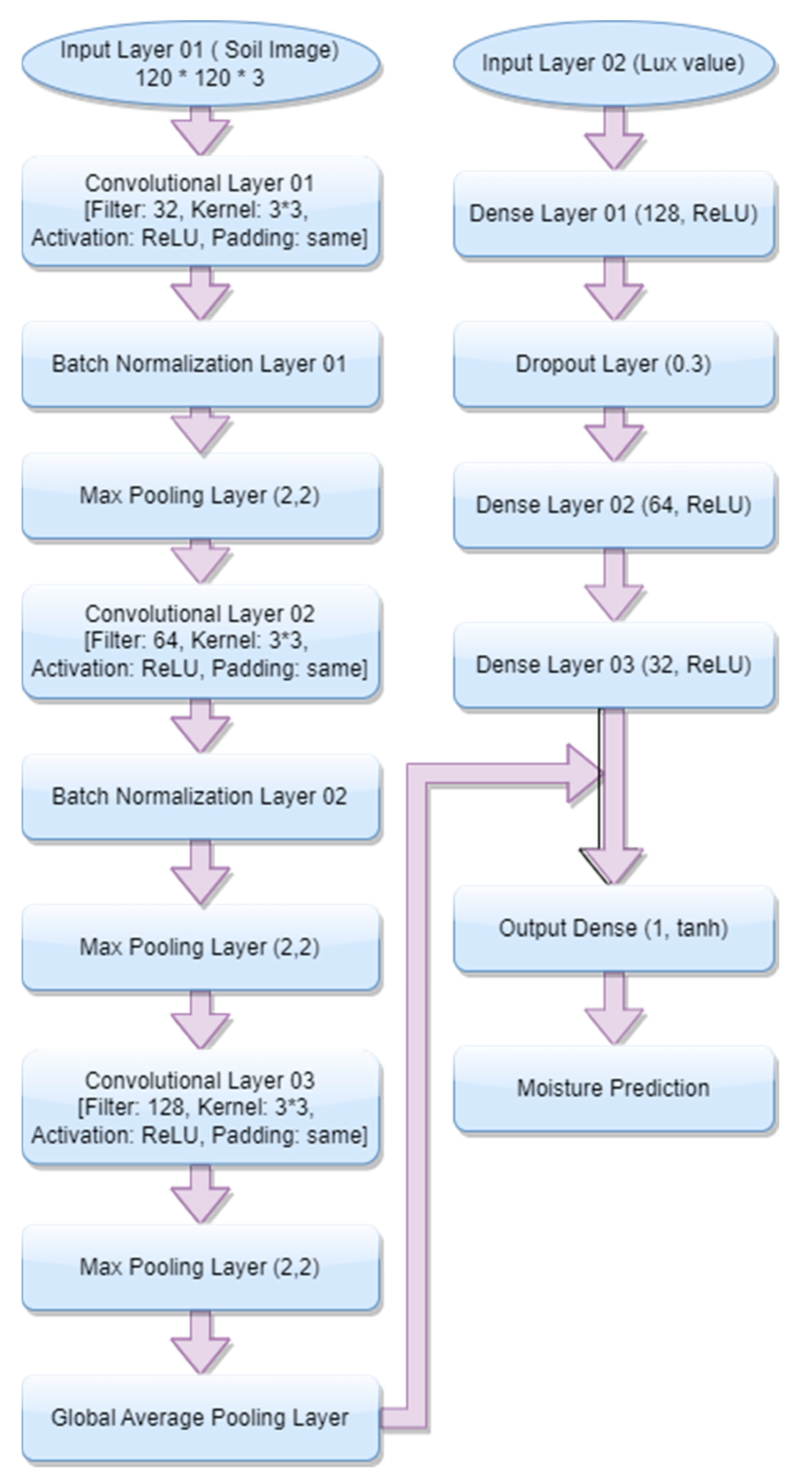
3.3. Machine Learning Models
3.4. Cross-Validation Techniques and Evaluation Metrics
3.5. Experimental Setting
3.5.1. Models Setting
3.5.2. Feature Scaling
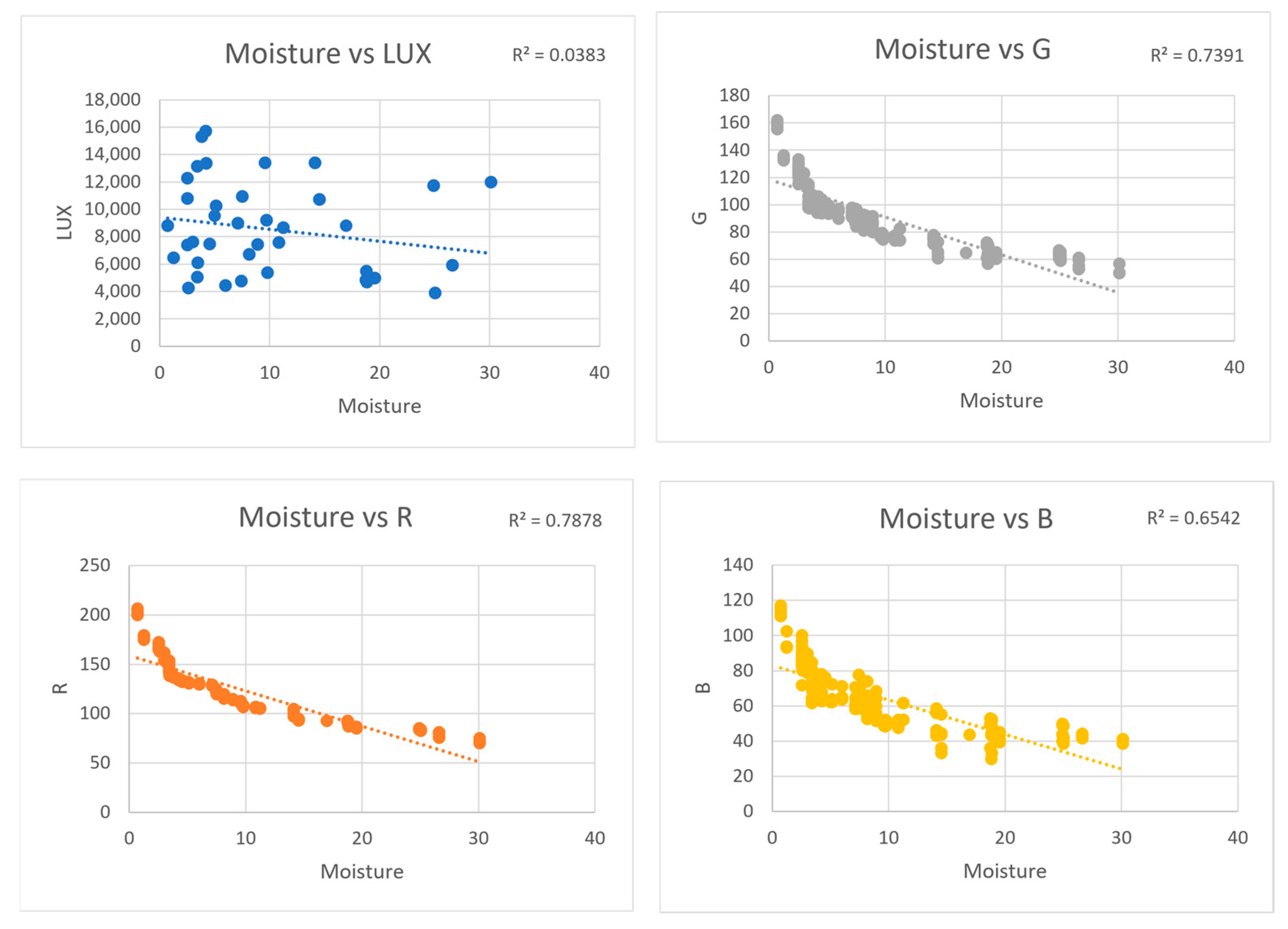
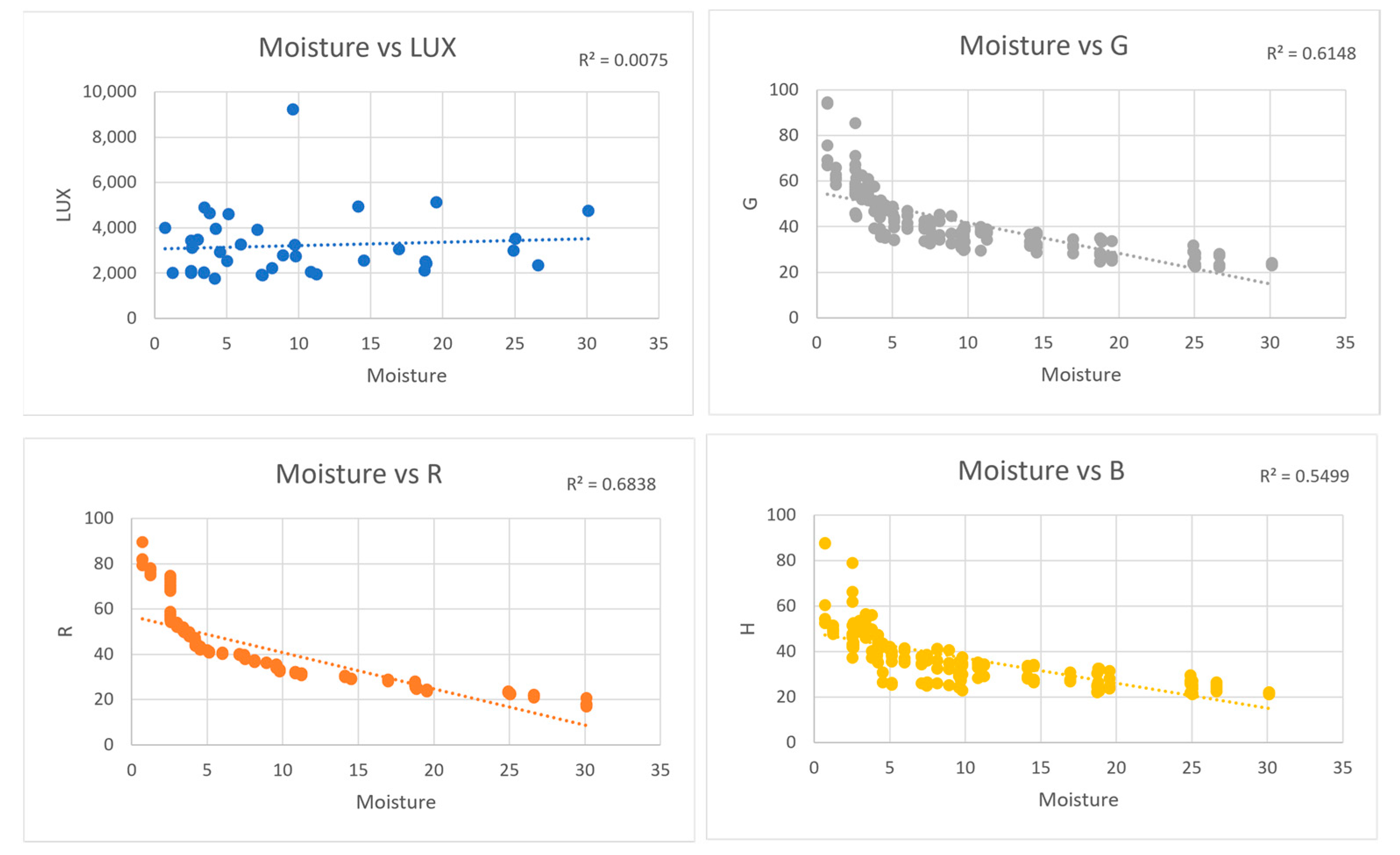
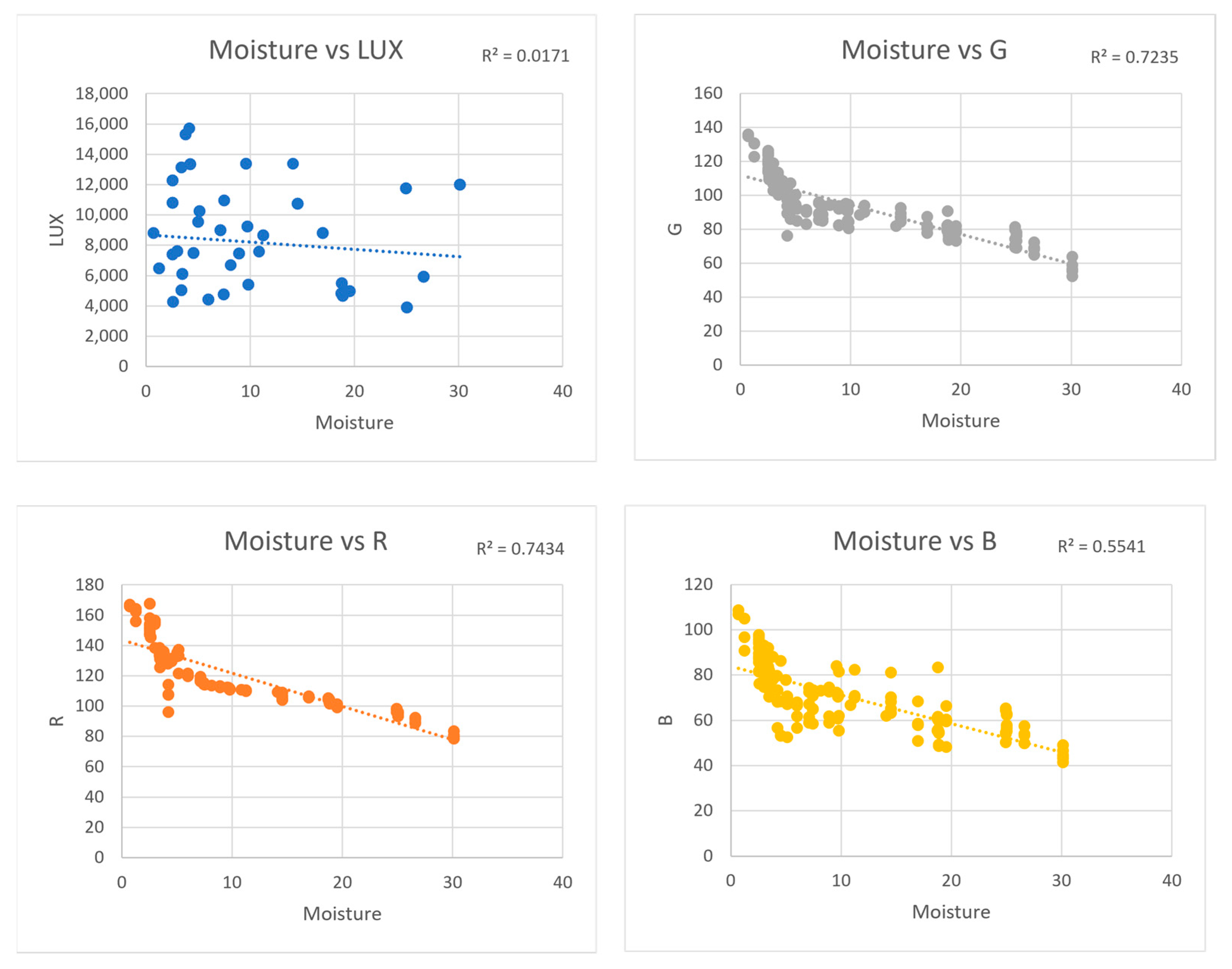
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | artificial neural network | MLR | multiple linear regression |
| CNN | convolutional neural network | MSE | mean squared error |
| DL | deep learning | OLS | ordinary least squares |
| FDR | frequency domain reflectometry | PLS | partial least squares |
| GPR | Gaussian process regression | RF | random forest |
| GPS | global positioning system | RMSE | root mean square error |
| LCCC | Lin’s concordance correlation coefficient | RPD | ratio of performance to deviation |
| LM | light meter | RPIQ | ratio of performance to interquartile distance |
| LR | linear regression | SM | soil moisture |
| MAE | mean absolute error | SVM | support vector machine |
| MLP | multilayer perceptron | SVR | support vector regression |
| ML | machine learning | TDR | time domain reflectometry |
References
- Chatterjee, S.; Dey, N.; Sen, S. Soil moisture quantity prediction using optimized neural supported model for sustainable agricultural applications. Sustain. Comput. Inform. Syst. 2020, 28, 100279. [Google Scholar] [CrossRef]
- Pekel, E. Estimation of soil moisture using decision tree regression. Theor. Appl. Climatol. 2020, 139, 1111–1119. [Google Scholar] [CrossRef]
- Prakash, S.; Sekhar, S. Soil moisture prediction using shallow neural network. Int. J. Adv. Res. Eng. Technol. 2020, 11, 426–435. [Google Scholar] [CrossRef]
- Han, J.; Mao, K.; Xu, T.; Guo, J.; Zuo, Z.; Gao, C. A soil moisture estimation framework based on the CART algorithm and its application in China. J. Hydrol. 2018, 563, 65–75. [Google Scholar] [CrossRef]
- Zanetti, S.S.; Cecílio, R.A.; Alves, E.G.; Silva, V.H.; Sousa, E.F. Estimation of the moisture content of tropical soils using colour images and artificial neural networks. Catena 2015, 135, 100–106. [Google Scholar] [CrossRef]
- Aitkenhead, M.J.; Poggio, L.; Wardell-Johnson, D.; Coull, M.C.; Rivington, M.; Black, H.I.J.; Yacob, G.; Boke, S.; Habte, M. Estimating soil properties from smartphone imagery in Ethiopia. Comput. Electron. Agric. 2020, 171, 105322. [Google Scholar] [CrossRef]
- Dos Santos, J.F.C.; Silva, H.R.F.; Pinto, F.A.C.; De Assis, I.R. Use of digital images to estimate soil moisture. Rev. Bras. Eng. Agric. E Ambient. 2016, 20, 1051–1056. [Google Scholar] [CrossRef]
- Saad Hajjar, C.; Hajjar, C.; Esta, M.; Ghorra Chamoun, Y. Machine learning methods for soil moisture prediction in vineyards using digital images. In Proceedings of the E3S Web of Conferences: 2020 11th International Conference on Environmental Science and Development (ICESD 2020), Barcelona, Spain, 10–12 February 2020; EDP Sciences: Les Ulis, France, 2020; Volume 167, p. 7. [Google Scholar] [CrossRef]
- Zheng, L.; Li, M.; Sun, J.; Zhang, X.; Zhao, P. Estimating soil moisture based on image processing technologies. In Applications of Digital Image Processing XXVIII; SPIE: Bellingham, WA, USA, 2005; Volume 5909, pp. 548–555. [Google Scholar] [CrossRef]
- Persson, M. Estimating Surface Soil Moisture from Soil Color Using Image Analysis. Vadose Zone J. 2005, 4, 1119–1122. [Google Scholar] [CrossRef]
- Taneja, P.; Vasava, H.K.; Daggupati, P.; Biswas, A. Multi-algorithm comparison to predict soil organic matter and soil moisture content from cell phone images. Geoderma 2021, 385, 114863. [Google Scholar] [CrossRef]
- Dudley, R.J. The Use of Colour in the Discrimination Between Soils. J. Forensic Sci. Soc. 1975, 15, 209–218. [Google Scholar] [CrossRef]
- Han, P.; Dong, D.; Zhao, X.; Jiao, L.; Lang, Y. A smartphone-based soil color sensor: For soil type classification. Comput. Electron. Agric. 2016, 123, 232–241. [Google Scholar] [CrossRef]
- Pegalajar, M.C.; Ruiz, L.G.B.; Sánchez-Marañón, M.; Mansilla, L. A Munsell colour-based approach for soil classification using Fuzzy Logic and Artificial Neural Networks. Fuzzy Sets Syst. 2020, 401, 38–54. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, Y.; Shao, M.; Horton, R. Estimating soil water content from surface digital image gray level measurements under visible spectrum. Can. J. Soil Sci. 2011, 91, 69–76. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Yang, L.; Liu, S.; Tsoka, S.; Papageorgiou, L.G. A regression tree approach using mathematical programming. Expert Syst. Appl. 2017, 78, 347–357. [Google Scholar] [CrossRef] [Green Version]
- Uyanık, G.K.; Güler, N. A Study on Multiple Linear Regression Analysis. Procedia-Soc. Behav. Sci. 2013, 106, 234–240. [Google Scholar] [CrossRef] [Green Version]
- Tabari, H.; Sabziparvar, A.A.; Ahmadi, M. Comparison of artificial neural network and multivariate linear regression methods for estimation of daily soil temperature in an arid region. Meteorol. Atmos. Phys. 2011, 110, 135–142. [Google Scholar] [CrossRef]
- Abdi, H. Partial least squares regression and projection on latent structure regression (PLS Regression). Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 97–106. [Google Scholar] [CrossRef]
- Radhika, Y.; Shashi, M. Atmospheric Temperature Prediction using Support Vector Machines. Int. J. Comput. Theory Eng. 2009, 1, 55–58. [Google Scholar] [CrossRef] [Green Version]
- Sakti, M.B.G.; Komariah; Ariyanto, D.P. Sumani Estimating soil moisture content using red-green-blue imagery from digital camera. In IOP Conference Series: Earth and Environmental Science; Institute of Physics Publishing: Bristol, UK, 2018; Volume 200, p. 012004. [Google Scholar] [CrossRef] [Green Version]
- Swetha, R.K.; Bende, P.; Singh, K.; Gorthi, S.; Biswas, A.; Li, B.; Weindorf, D.C.; Chakraborty, S. Predicting soil texture from smartphone-captured digital images and an application. Geoderma 2020, 376, 114562. [Google Scholar] [CrossRef]
- Kirillova, N.P.; Kemp, D.B.; Artemyeva, Z.S. Colorimetric analysis of soil with flatbed scanners. Eur. J. Soil Sci. 2017, 68, 420–433. [Google Scholar] [CrossRef] [Green Version]
- Fan, Z.; Herrick, J.E.; Saltzman, R.; Matteis, C.; Yudina, A.; Nocella, N.; Crawford, E.; Parker, R.; Van Zee, J. Measurement of Soil Color: A Comparison Between Smartphone Camera and the Munsell Color Charts. Soil Sci. Soc. Am. J. 2017, 81, 1139–1146. [Google Scholar] [CrossRef]
- Choodum, A.; Kanatharana, P.; Wongniramaikul, W.; Nic Daeid, N. Using the iPhone as a device for a rapid quantitative analysis of trinitrotoluene in soil. Talanta 2013, 115, 143–149. [Google Scholar] [CrossRef]
- Tominaga, S.; Nishi, S.; Ohtera, R. Measurement and estimation of spectral sensitivity functions for mobile phone cameras. Sensors 2021, 21, 4985. [Google Scholar] [CrossRef]
- Friederichsen, P. Recent Advances in Smartphone Computational Photography. Sch. Horiz. Univ. Minn. Morris Undergrad. J. 2021, 8, 4. [Google Scholar]
- Ismail, A.H.; Azmi, M.S.M.; Hashim, M.A.; Ayob, M.N.; Hashim, M.S.M.; Hassrizal, H.B. Development of a webcam based lux meter. In Proceedings of the 2013 IEEE Symposium on Computers & Informatics (ISCI), Langkawi, Malaysia, 7–9 April 2013; IEEE: New York, NY, USA; pp. 70–74. [Google Scholar] [CrossRef]
- Sharma, R.; Kamble, S.S.; Gunasekaran, A.; Kumar, V.; Kumar, A. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput. Oper. Res. 2020, 119, 104926. [Google Scholar] [CrossRef]
- Prakash, S.; Sharma, A.; Sahu, S.S. SOIL MOISTURE PREDICTION USING MACHINE LEARNING. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20 April 2018; IEEE: New York, NY, USA; pp. 1–6. [Google Scholar] [CrossRef]
- Gill, M.K.; Asefa, T.; Kemblowski, M.W.; McKee, M. SOIL MOISTURE PREDICTION USING SUPPORT VECTOR MACHINES. J. Am. Water Resour. Assoc. JAWRA 2007, 42, 1033–1046. [Google Scholar] [CrossRef]
- Lee, C.S.; Sohn, E.; Park, J.D.; Jang, J.D. Estimation of soil moisture using deep learning based on satellite data: A case study of South Korea. GISci. Remote Sens. 2019, 56, 43–67. [Google Scholar] [CrossRef]
- Cawley, G.C.; Talbot, N.L.C. Efficient approximate leave-one-out cross-validation for kernel logistic regression. Mach. Learn. 2008, 71, 243–264. [Google Scholar] [CrossRef] [Green Version]
- Brovelli, M.A.; Crespi, M.; Fratarcangeli, F.; Giannone, F.; Realini, E. Accuracy assessment of high resolution satellite imagery orientation by leave-one-out method. ISPRS J. Photogramm. Remote Sens. 2008, 63, 427–440. [Google Scholar] [CrossRef]
- Wang, W.; Lu, Y. Analysis of the Mean Absolute Error (MAE) and the Root Mean Square Error (RMSE) in Assessing Rounding Model. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2018; Volume 324. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.L.; Shalabh; Garg, G. Coefficient of determination for multiple measurement error models. J. Multivar. Anal. 2014, 126, 137–152. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Zhang, X.; Deng, L.; Zhang, S. Prediction of viscosity of imidazolium-based ionic liquids using MLR and SVM algorithms. Comput. Chem. Eng. 2016, 92, 37–42. [Google Scholar] [CrossRef]
- Zhao, C.Y.; Zhang, H.X.; Zhang, X.Y.; Liu, M.C.; Hu, Z.D.; Fan, B.T. Application of support vector machine (SVM) for prediction toxic activity of different data sets. Toxicology 2006, 217, 105–119. [Google Scholar] [CrossRef]
- Elbisy, M.S. Support Vector Machine and regression analysis to predict the field hydraulic conductivity of sandy soil. KSCE J. Civ. Eng. 2015, 19, 2307–2316. [Google Scholar] [CrossRef]
- Wang, B.; Chen, J.; Li, X.; Wang, Y.N.; Chen, L.; Zhu, M.; Yu, H.; Kühne, R.; Schüürmann, G. Estimation of soil organic carbon normalized sorption coefficient (Koc) using least squares-support vector machine. QSAR Comb. Sci. 2009, 28, 561–567. [Google Scholar] [CrossRef]
- Liu, F.; Jiang, Y.; He, Y. Variable selection in visible/near infrared spectra for linear and nonlinear calibrations: A case study to determine soluble solids content of beer. Anal. Chim. Acta 2009, 635, 45–52. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
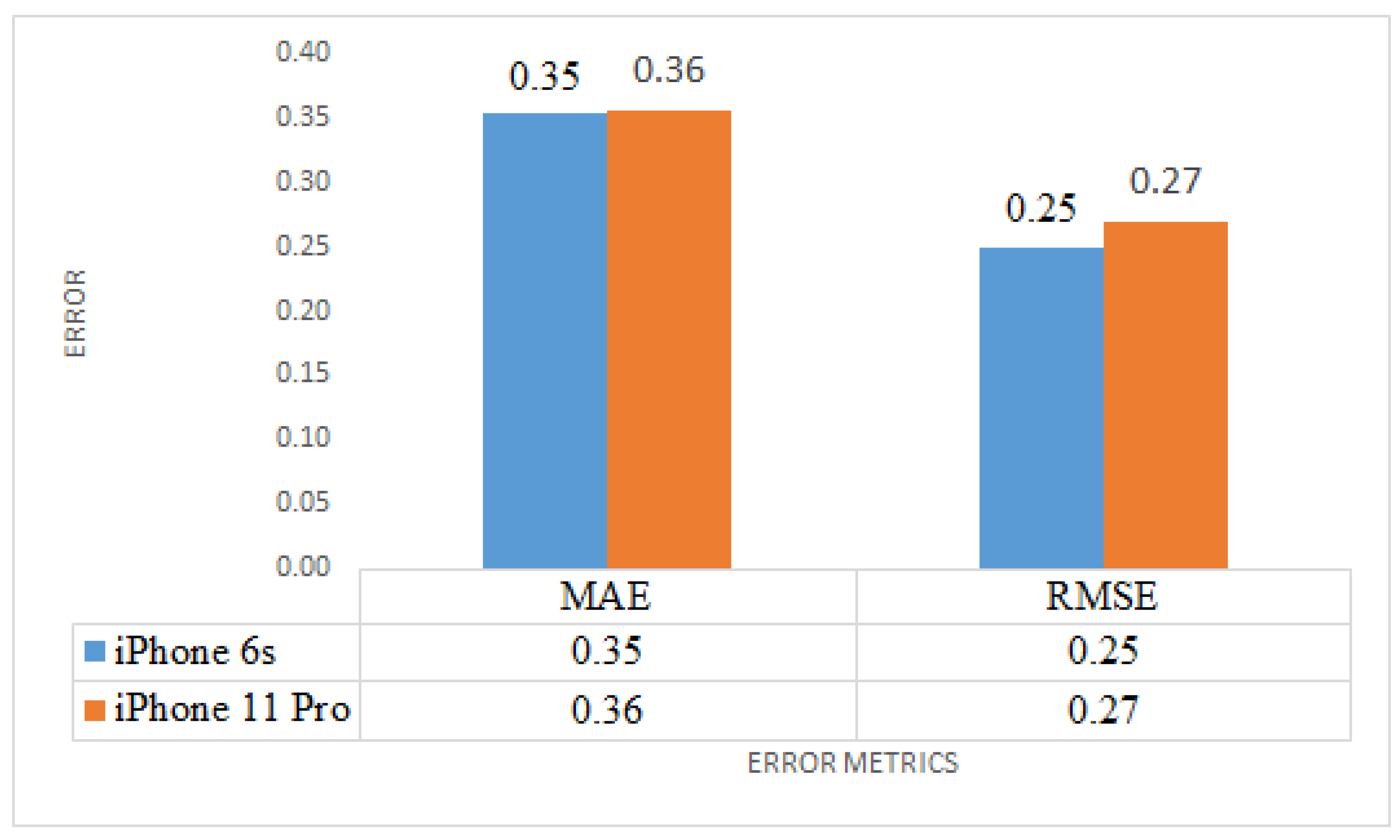{kind=link}
| No. | ML Model | Description |
|---|---|---|
| 01 | Artificial Neural Network (ANN) | An ANN model is a subset of machine learning and is the heart of deep learning. It consists of input, hidden, and output layers. In addition, it includes multiple connected processing units that work together to process information [16]. |
| 02 | Cubist | A Cubist model is an addition to Quinlan’s M5 approach. Though it generates a tree, each path of the tree is reduced to a rule, and linear regression models are contained in the terminal nodes. In addition, rules are pruned or combined to simplify the model [17]. |
| 03 | Convolutional Neural Network (CNN) | A CNN is a subclass of an ANN. Input, hidden, and output layers make up its structure. It is used especially for image recognition [16]. |
| 04 | Gaussian Process Regression (GPR) | A GPR model is a kernel-based machine learning model used for accurate predictions [11]. |
| 05 | Linear Regression (LR) | An LR model displays the relation of two variables for prediction. A simple linear regression model implements an independent variable to predict a dependent variable. Nevertheless, multiple linear regression is a supervised ML algorithm with multiple independent variables and a single dependent variable for regression [18]. |
| 06 | Multilayer Perceptron (MLP) | An MLP network is an ANN that comprises a group of units with an input layer, one or more hidden layers, and a single output layer. Output activation in the computation nodes is generated by a nonlinear activation function named the sigmoid function. The model uses a backpropagation algorithm to train regressions [19]. |
| 07 | Partial Least Squares (PLS) | A PLS regression uses a set of independent predictors or variables to predict a group of dependent variables. It is handy when there are strong collinear predictors or more predictors than observations, and regression of Ordinary Least Squares (OLS) produces coefficients with high standard errors or fails [20]. |
| 08 | Support Vector Regression (SVR) | An SVR known as a Support Vector Machine (SVM) regression is applied to predict numeric values rather than classifications. It is a proficient prediction model that recognizes the existence of nonlinearity in the data. A straight line is required to fit the data in SVR and is called a hyperplane [21]. |
| 09 | Random Forest (RF) | An RF is a supervised ML algorithm accepted for classification and regression. It is constructed from decision tree algorithms that predict behavior and outcome [16]. |
| 10 | Regression Trees | Regression trees evaluate the association between dependent and independent variables [16]. |
| Paper | Experimental Details | Limitation(s) |
|---|---|---|
| [6] | Model(s): ANN and PLS Best Performances: ANN trained with RGB color space and site-specific data (land cover, vegetative cover, canopy cover, altitude, profile depth, slope, landform, and topography) Soil Sample Size: 273 samples Sample Collection: Halaba area of southwest Ethiopia | Although the paper indicated that grouping samples by soil type increased model performance, grouping samples according to the soil types was not done. |
| [8] | Model(s): SVR and MLP Best Performances: SVR Soil Sample Size: Thirty-five soil samples of six soil types Sample Collection: Chateau Kefraya terroirs in Lebanon | Many other factors, such as the soil’s physical, chemical, and biological components, could have been responsible for the soil color variation along with soil moisture. However, these properties were not evaluated in the research. |
| [10] | Model(s): Simple LR model Best Performances: Satisfactory result was found using a simple LR model Soil Sample Size: Five soils (four are natural soils, and one is fine sand) have up to twenty-seven samples for each soil Sample Collection: Four places (Löddeköpinge, Värpinge, Lund, and Odarslöv) in Sweden | Based on the limited data, the paper presented that soil color and soil moisture were strongly related. It also found that soils became darker when soil moisture increased. However, some lighter soil colors indicated the highest soil moisture in the research. Further investigation was needed with extensive data. |
| [22] | Model(s): LR models Best Performances: Moderate accuracy by LR Soil Sample Size: Eight samples of Alfisol soil type Sample Collection: Karanganyar District, Indonesia | Soil moisture estimation was moderately accurate (65%). Moreover, samples were collected from a single area, and the scope for samples from other geographical sectors was not considered. |
| [7] | Model(s): Simple LR model and Multiple Linear Regression (MLR) models Best Performances: Simple LR model or MLR model based on soil types Soil Sample Size: Six soil samples Sample Collection: Federal University of Viçosa (UFV) | Soil moisture was predicted from the soil surface, which may differ from the inner soil sample. Another limitation was that soil characteristics must be analyzed before the model selection, which was not done. Moreover, the result may not be satisfactory for all soil classes because complementary studies were not conducted for different soil classes to predict soil moisture. |
| [11] | Model(s): 24 ML models (6 LR models, 4 GPR models, 3 Decision Tree models, 6 SVM, 4 Ensembles of Decision Tree models, and ANN) Best Performances: GPR model and Cubist model Soil Sample Size: Twenty-five samples from two agricultural fields Sample Collection: MacDonald Campus Farm, McGill University, Quebec, Canada | High moisture content was found in the dark-colored soils. However, soil color may be related to soil type contrasts, textural differences, and other factors such as topography, geology, climate, and so on, which were not considered explicitly. |
| [5] | Model(s): ANNs Best Performances: ANN with the tan-sigmoid transfer function and a hidden layer containing 12 neurons Soil Sample Size: Three types of soil Sample Collection: Alegre, Espírito Santo, Brazil; and Guaçuí, Espírito Santo, Brazil | No experiments were conducted for a more robust characterization of soil color variation to estimate the soil moisture content. |
| [23] | Model(s): ANNs Best Performances: ANN with the tan-sigmoid transfer function and a hidden layer containing 12 neurons Soil Sample Size: Three types of soil Sample Collection: Alegre, Espírito Santo, Brazil; and Guaçuí, Espírito Santo, Brazil | No experiments were conducted for a more robust characterization of soil color variation to estimate the soil moisture content. |
| [9] | Model(s): MLR Best Performances: MLR with G (Green), B (Blue), H (Hue), and S (Saturation) input parameters Soil Sample Size: Samples from 40 test sites Sample Collection: A farmland in Beijing, China | The research was done based on a single soil type. Therefore, heterogeneous soil types were not considered, which might present a different result. |
| No. | Area Name | Total Soil Samples | Collection Date |
|---|---|---|---|
| 01 | Granville Park, Merrylands, NSW, 2160 | 08 | 31 January 2022 |
| 02 | Merrylands Park, Merrylands, NSW, 2160 | 09 | 02 February 2022 |
| 03 | Freame Park, Mays Hill, NSW, 2145 | 03 | 02 March 2022 |
| 04 | Jones Park Parramatta, Parramatta, NSW, 2145 | 07 | 02 March 2022 |
| 05 | Civic Park, Pendle Hill, NSW, 2145 | 05 | 02 March 2022 |
| 06 | Boyne Avenue Park, Pendle Hill, NSW, 2145 | 03 | 16 March 2022 |
| 07 | Daley St Reserve, Pendle Hill, NSW 2145 | 03 | 16 March 2022 |
| Moisture | |
|---|---|
| Minimum | 0.71 |
| Maximum | 30.11 |
| Mean | 10.50 |
| Standard Deviation | 8.30 |
| Dataset No. | Description | Total Instances |
|---|---|---|
| Dataset 01 | Images were taken with the iPhone 6s in direct sunlight | 171 |
| Dataset 02 | Images were taken with the iPhone 6s in indirect sunlight | 186 |
| Dataset 03 | Images were taken with the iPhone 11 Pro in direct sunlight | 135 |
| Dataset 04 | Images were taken with the iPhone 11 Pro in indirect sunlight | 137 |
| Dataset 01 | Dataset 02 | Dataset 03 | Dataset 04 | |
|---|---|---|---|---|
| Sample 9 (0.71% Moisture) |  |  |  |  |
| Sample 15 (14.54% Moisture) |  |  |  |  |
| Sample 33 (25.04% Moisture) |  |  |  |  |
| Sample 13 (30.11% Moisture) |  |  |  |  |
| Dataset | Model | MAE | RMSE | |
|---|---|---|---|---|
| MLR | 0.45 | 0.26 | 0.09 | |
| Dataset 01 | SVR | 0.49 | 0.31 | 0.01 |
| CNN | 0.50 | 0.29 | −0.52 | |
| MLR | 0.35 | 0.15 | 0.60 | |
| Dataset 02 | SVR | 0.54 | 0.37 | −0.43 |
| CNN | 0.58 | 0.43 | −1.38 | |
| MLR | 0.45 | 0.26 | 0.06 | |
| Dataset 03 | SVR | 0.51 | 0.33 | −0.13 |
| CNN | 0.57 | 0.42 | −1.40 | |
| MLR | 0.39 | 0.18 | 0.54 | |
| Dataset 04 | SVR | 0.47 | 0.30 | −0.09 |
| CNN | 0.44 | 0.27 | −0.12 |
| Dataset | Model | MAE | RMSE | |
|---|---|---|---|---|
| MLR | 0.21 | 0.26 | −0.12 | |
| Dataset 01 | SVR | 0.17 | 0.22 | 0.14 |
| CNN | 0.56 | 0.39 | −3.61 | |
| MLR | 0.13 | 0.16 | 0.65 | |
| Dataset 02 | SVR | 0.05 | 0.06 | 0.96 |
| CNN | 0.47 | 0.27 | −3.96 | |
| MLR | 0.21 | 0.26 | −0.17 | |
| Dataset 03 | SVR | 0.16 | 0.24 | 0.34 |
| CNN | 0.50 | 0.30 | −4.53 | |
| MLR | 0.14 | 0.19 | 0.44 | |
| Dataset 04 | SVR | 0.08 | 0.11 | 0.85 |
| CNN | 0.50 | 0.30 | −4.53 |
| Dataset | Model | MAE | RMSE | |
|---|---|---|---|---|
| MLR | 0.46 | 0.26 | 0.05 | |
| Dataset 01 | SVR | 0.40 | 0.22 | 0.31 |
| CNN | 0.49 | 0.28 | −0.65 | |
| MLR | 0.36 | 0.16 | 0.67 | |
| Dataset 02 | SVR | 0.22 | 0.06 | 0.95 |
| CNN | 0.49 | 0.30 | −1.08 | |
| MLR | 0.45 | 0.26 | 0.21 | |
| Dataset 03 | SVR | 0.40 | 0.24 | 0.34 |
| CNN | 0.49 | 0.29 | −0.63 | |
| MLR | 0.38 | 0.19 | 0.53 | |
| Dataset 04 | SVR | 0.27 | 0.10 | 0.88 |
| CNN | 0.44 | 0.22 | −0.38 |
| Model | MAE | RMSE | |
|---|---|---|---|
| MLR | 0.48 | 0.28 | 0.02 |
| SVR | 0.45 | 0.26 | 0.18 |
| CNN | 0.48 | 0.28 | 0.04 |
| Model | MAE | RMSE | |
|---|---|---|---|
| MLR | 0.94 | 0.90 | −12.93 |
| SVR | 0.48 | 0.28 | −0.03 |
| CNN | 0.59 | 0.45 | −1.58 |
| Model | MAE | RMSE | |
|---|---|---|---|
| MLR | 0.50 | 0.29 | −0.09 |
| SVR | 0.47 | 0.28 | −0.06 |
| CNN | 0.53 | 0.32 | −0.37 |
| Model | MAE | RMSE | |
|---|---|---|---|
| MLR | 0.48 | 0.32 | −0.38 |
| SVR | 0. 49 | 0.32 | −0.37 |
| CNN | 0.50 | 0.35 | −0.58 |
| Validation Technique | Model | MAE | RMSE | |
|---|---|---|---|---|
| MLR | 0.46 | 0.26 | 0.18 | |
| Holdout cross-validation | SVR | 0.46 | 0.27 | 0.17 |
| CNN | 0.48 | 0.28 | 0.07 | |
| MLR | 0.27 | 0.26 | 0.12 | |
| K-fold Cross-Validation | SVR | 0.15 | 0.20 | 0.48 |
| CNN | 0.51 | 0.31 | −0.44 | |
| MLR | 0.45 | 0.26 | 0.12 | |
| Leave-one-out cross-validation | SVR | 0.38 | 0.20 | 0.50 |
| CNN | 0.51 | 0.32 | −0.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, M.R.H.; Kabir, M.A. Machine Learning Techniques for Estimating Soil Moisture from Smartphone Captured Images. Agriculture 2023, 13, 574. https://doi.org/10.3390/agriculture13030574
Hossain MRH, Kabir MA. Machine Learning Techniques for Estimating Soil Moisture from Smartphone Captured Images. Agriculture. 2023; 13(3):574. https://doi.org/10.3390/agriculture13030574
Chicago/Turabian StyleHossain, Muhammad Riaz Hasib, and Muhammad Ashad Kabir. 2023. "Machine Learning Techniques for Estimating Soil Moisture from Smartphone Captured Images" Agriculture 13, no. 3: 574. https://doi.org/10.3390/agriculture13030574