
SCE-LSTM: Sparse Critical Event-Driven LSTM Model with Selective Memorization for Agricultural Time-Series Prediction

 ,
,  and
and
Abstract
:1. Introduction
2. Literature Review
2.1. LSTM Model and Its Applications
2.2. Problems in LSTM Models and Modification to LSTM Models
2.3. How Selective Memorization Is Represented in Our Proposed Modification to LSTM Models
3. Methodology
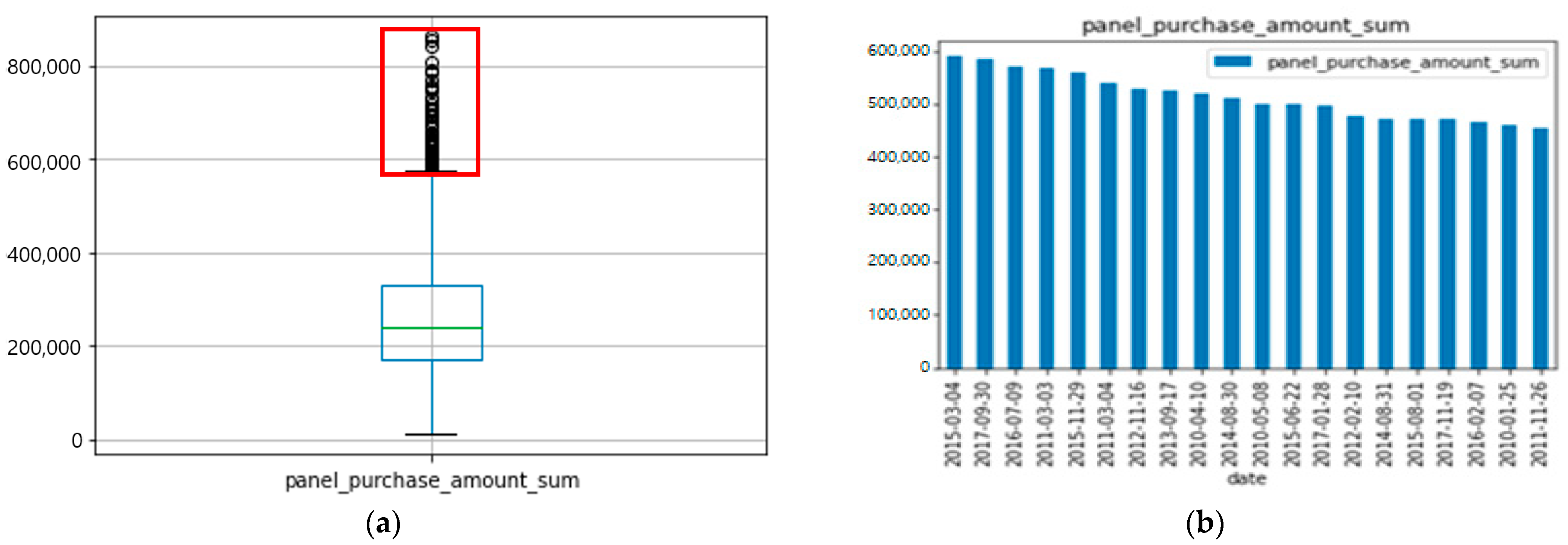
3.1. Defining the SCE in Time-Series Data
3.2. Defining the SCE in Time-Series Data Finding the SCE
| Algorithm 1 CalculateBolingerband (Y, X, d, z) |
Input
|
Output
|
Begin
|
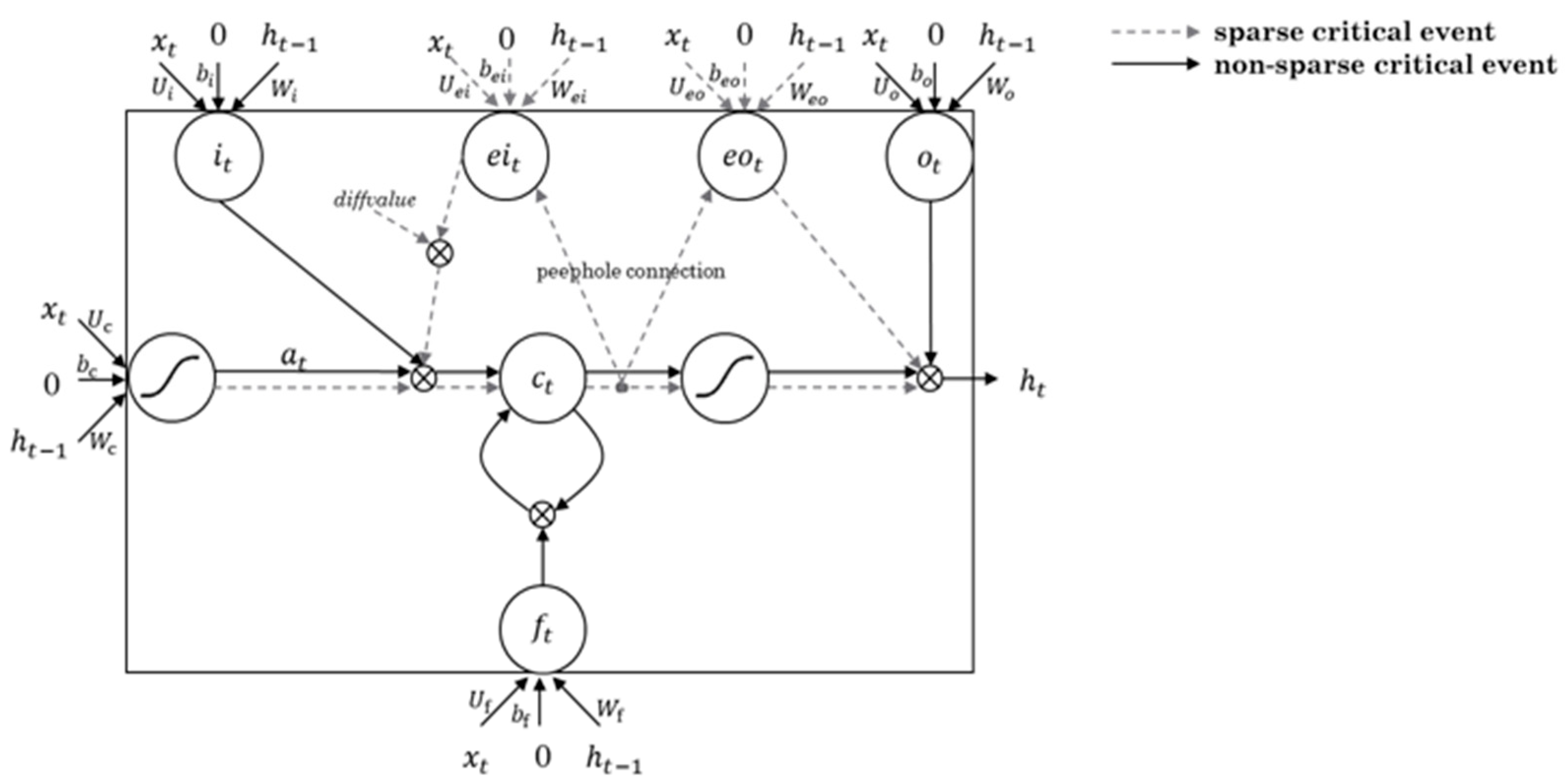
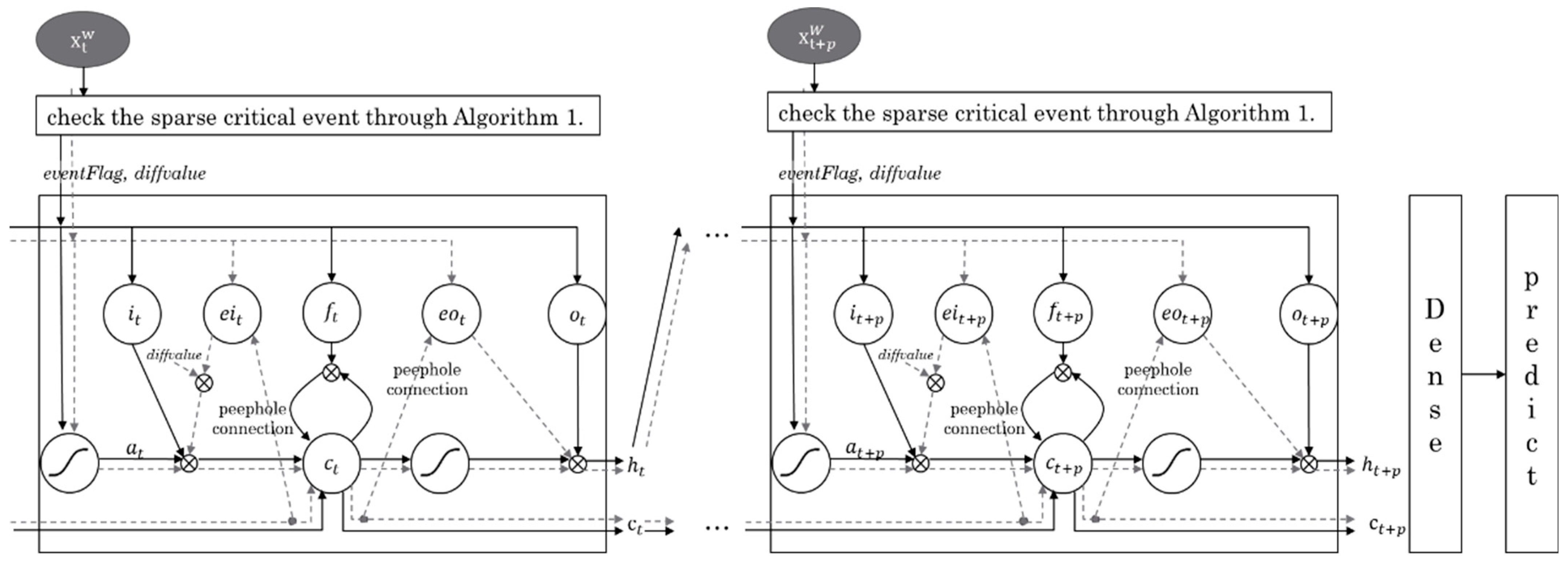
3.3. Designing SCE-LSTM Layer by Reflecting the SCE
| Algorithm 2 CheckSparseCriticalEvent (Y, X, start_index, end_index) |
Input
|
Output
|
Begin
|
| Algorithm 3 SCE-LSTM Cell (Y, X, start_index, d) |
Input
|
Output
|
Begin
|
| Algorithm 4 SCE-LSTM model (Y, X, p, d, pred_m) |
Input
|
Output
|
Begin
|
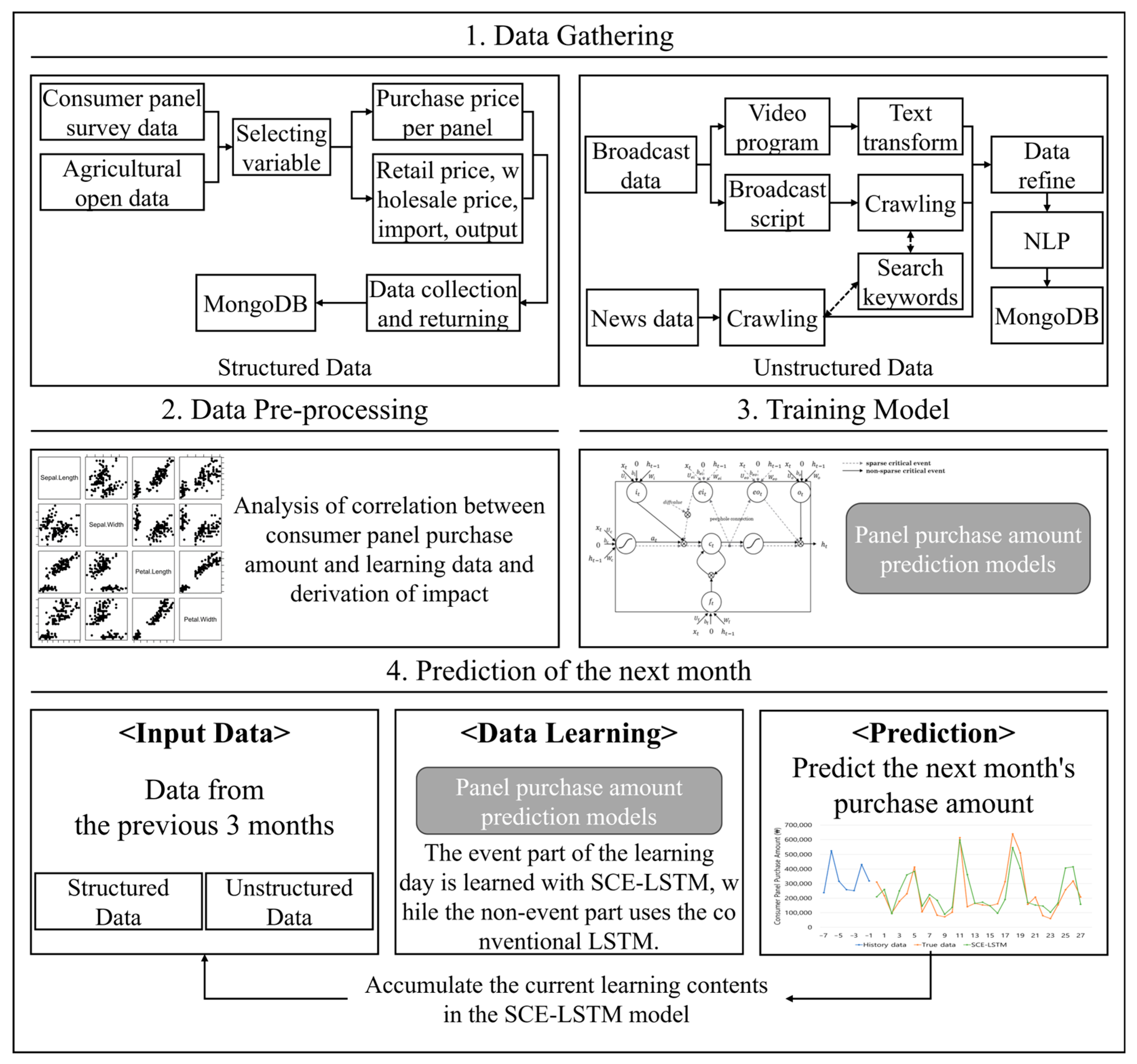
4. Predicting the Purchase Amount of Pork Meat Using the Proposed SCE-LSTM
4.1. Data Collection and Pre-Processing
4.2. Application of the Proposed SCE-LSTM
5. Performance Evaluation
5.1. Experimental Models
5.2. Evaluation Metrics
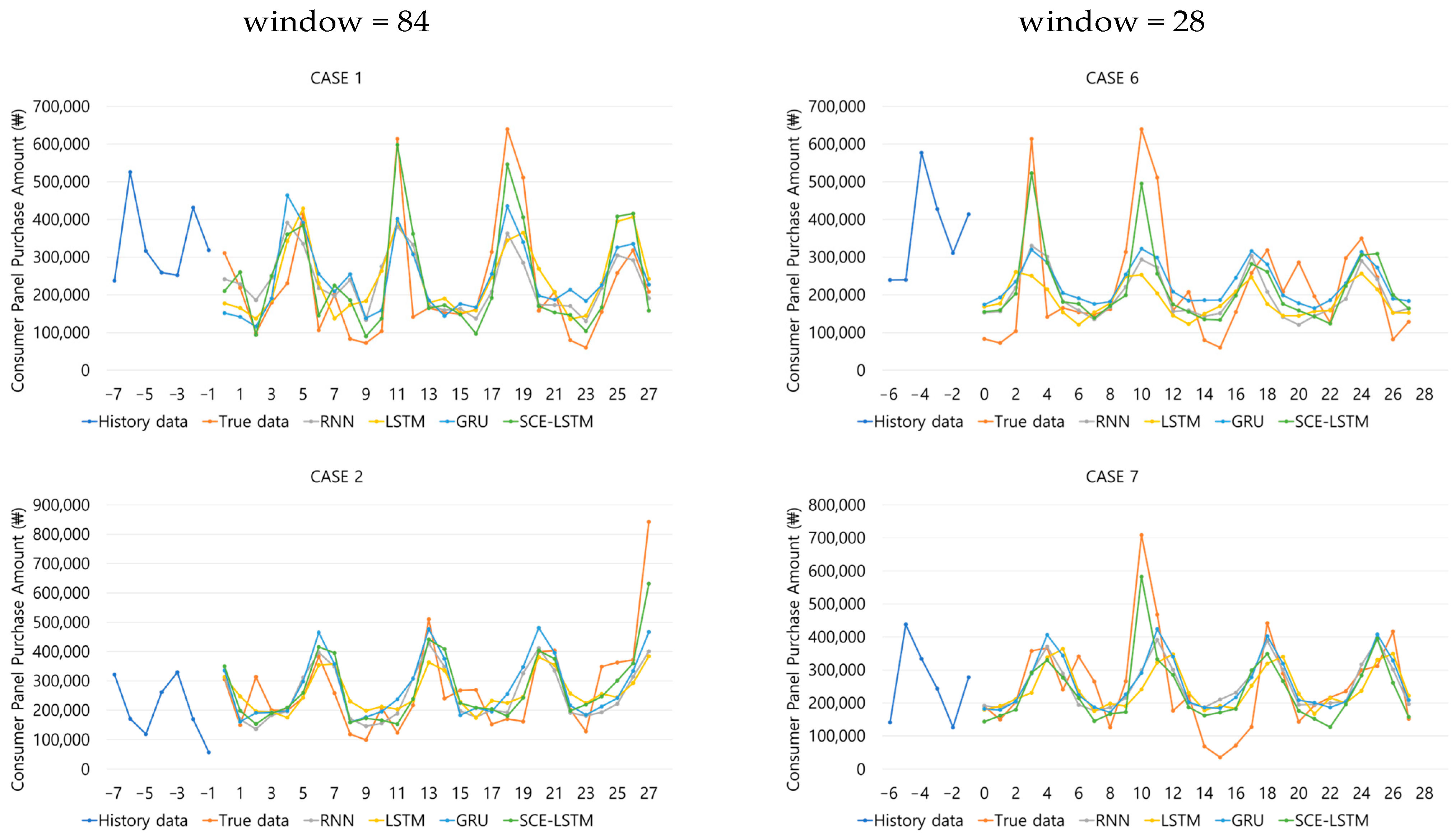
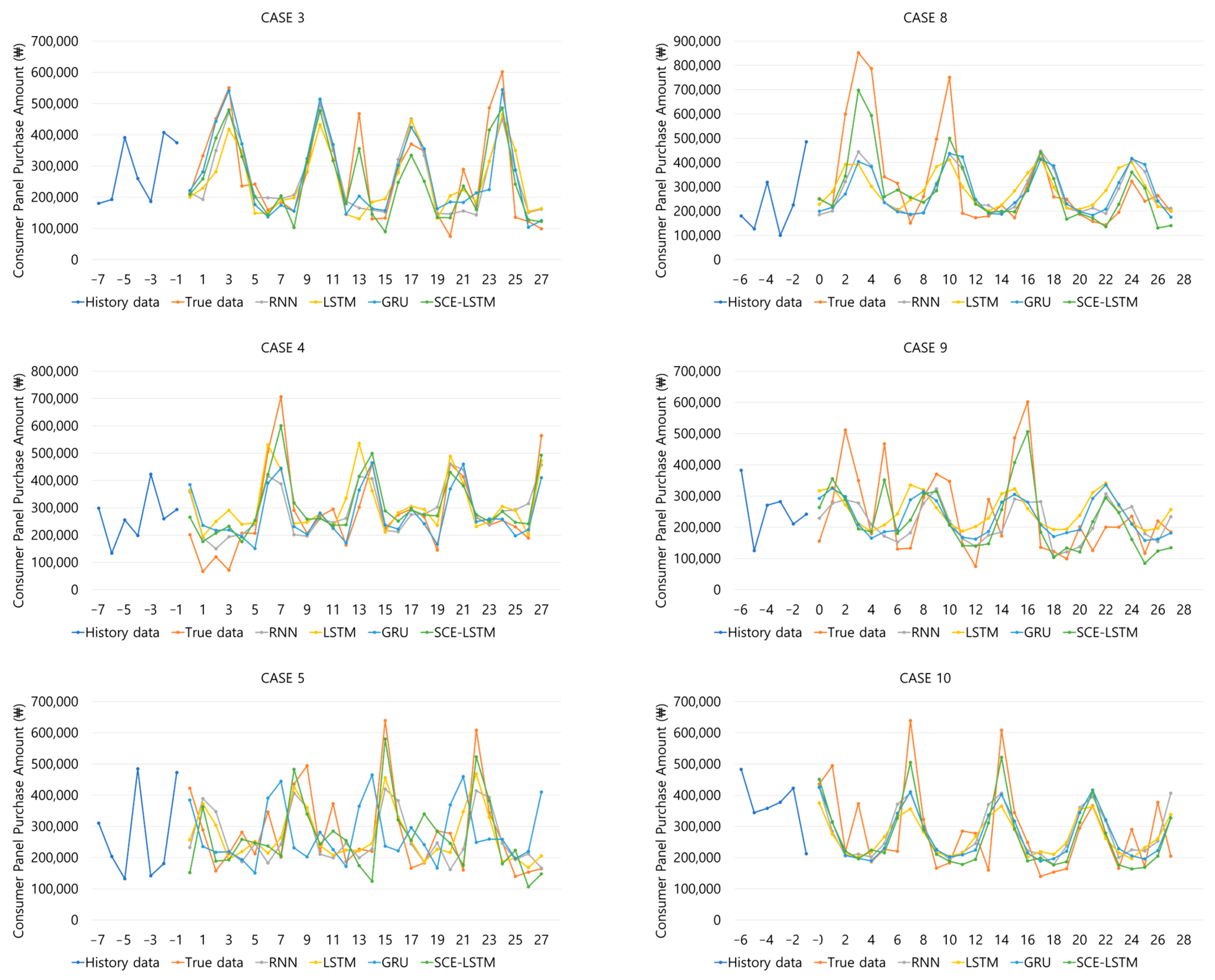
5.3. Model Hyperparameters and Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Neves, R.F.L. An Overview of Deep Learning Strategies for Time Series Prediction. Master’s Thesis, Instituto Superior Técnico, Lisboa, Portugal, 2018. [Google Scholar]
- Grossberg, S. Recurrent neural networks. Scholarpedia 2013, 8, 1888. [Google Scholar] [CrossRef]
- Li, Q.; Tan, J.; Wang, J.; Chen, H. A multimodal event-driven lstm model for stock prediction using online news. IEEE Trans. Knowl. Data Eng. 2020, 33, 3323–3337. [Google Scholar] [CrossRef]
- Lin, H.; Sun, Q. Crude oil prices forecasting: An approach of using CEEMDAN-based multi-layer gated recurrent unit networks. Energies 2020, 13, 1543. [Google Scholar] [CrossRef]
- Long, W.; Lu, Z.; Cui, L. Deep learning-based feature engineering for stock price movement prediction. Knowl.-Based Syst. 2019, 164, 163–173. [Google Scholar] [CrossRef]
- Ozbayoglu, A.M.; Gudelek, M.U.; Sezer, O.B. Deep learning for financial applications: A survey. Appl. Soft Comput. 2020, 93, 106384. [Google Scholar] [CrossRef]
- Wen, M.; Li, P.; Zhang, L.; Chen, Y. Stock market trend prediction using high-order information of time series. IEEE Access 2019, 7, 28299–28308. [Google Scholar] [CrossRef]
- Chuluunsaikhan, T.; Ryu, G.-A.; Yoo, K.-H.; Rah, H.; Nasridinov, A. Incorporating deep learning and news topic modeling for forecasting pork prices: The case of South Korea. Agriculture 2020, 10, 513. [Google Scholar] [CrossRef]
- Ryu, G.-A.; Nasridinov, A.; Rah, H.; Yoo, K.-H. Forecasts of the amount purchase pork meat by using structured and unstructured big data. Agriculture 2020, 10, 21. [Google Scholar] [CrossRef]
- Yoo, T.-W.; Oh, I.-S. Time series forecasting of agricultural products’ sales volumes based on seasonal long short-term memory. Appl. Sci. 2020, 10, 8169. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Li, Q.; Chen, Y.; Jiang, L.L.; Li, P.; Chen, H. A tensor-based information framework for predicting the stock market. ACM Trans. Inf. Syst. (TOIS) 2016, 34, 1–30. [Google Scholar] [CrossRef]
- Sun, T.; Wang, J.; Zhang, P.; Cao, Y.; Liu, B.; Wang, D. Predicting stock price returns using microblog sentiment for chinese stock market. In Proceedings of the 2017 3rd International Conference on Big Data Computing and Communications (BIGCOM), Chengdu, China, 10–11 August 2017; pp. 87–96. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Akita, R.; Yoshihara, A.; Matsubara, T.; Uehara, K. Deep learning for stock prediction using numerical and textual information. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Rodrigues, F.; Markou, I.; Pereira, F.C. Combining time-series and textual data for taxi demand prediction in event areas: A deep learning approach. Inf. Fusion 2019, 49, 120–129. [Google Scholar] [CrossRef]
- Hua, Y.; Zhao, Z.; Li, R.; Chen, X.; Liu, Z.; Zhang, H. Deep learning with long short-term memory for time series prediction. IEEE Commun. Mag. 2019, 57, 114–119. [Google Scholar] [CrossRef]
- Baytas, I.M.; Xiao, C.; Zhang, X.; Wang, F.; Jain, A.K.; Zhou, J. Patient subtyping via time-aware LSTM networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 65–74. [Google Scholar]
- Gravitz, L. The forgotten part of memory. Nature 2019, 571, S12. [Google Scholar] [CrossRef]
- Cherry, K. Reasons Why People Forget. 2021. Available online: https://www.verywellmind.com/explanations-for-forgetting-2795045 (accessed on 17 September 2023).
- Nørby, S. Why forget? On the adaptive value of memory loss. Perspect. Psychol. Sci. 2015, 10, 551–578. [Google Scholar] [CrossRef]
- Peng, J.; Sun, X.; Deng, M.; Tao, C.; Tang, B.; Li, W.; Wu, G.; Liu, Y.; Lin, T.; Li, H. Learning by Active Forgetting for Neural Networks. arXiv 2021, arXiv:2111.10831. [Google Scholar]
- Ivasic-Kos, M.; Host, K.; Pobar, M. Application of deep learning methods for detection and tracking of players. In Deep Learning Applications; IntechOpen: London, UK, 2021. [Google Scholar]
- Zhang, X.; Zhang, Y.; Lu, X.; Bai, L.; Chen, L.; Tao, J.; Wang, Z.; Zhu, L. Estimation of lower-stratosphere-to-troposphere ozone profile using long short-term memory (LSTM). Remote Sens. 2021, 13, 1374. [Google Scholar] [CrossRef]
- Chun, M.M.; Turk-Browne, N.B. Interactions between attention and memory. Curr. Opin. Neurobiol. 2007, 17, 177–184. [Google Scholar] [CrossRef]
- Kraft, R. Why We Forget. 2017. Available online: https://www.psychologytoday.com/ca/blog/defining-memories/201706/why-we-forget (accessed on 17 September 2023).
- Qi, L.; Khushi, M.; Poon, J. Event-driven LSTM for forex price prediction. In Proceedings of the 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 16–18 December 2020; pp. 1–6. [Google Scholar]
- Oliveira Pezente, A. Predictive Demand Models in the Food and Agriculture Sectors: An Analysis of the Current Models and Results of a Novel Approach Using Machine Learning Techniques with Retail Scanner Data. Bachelor’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2018. [Google Scholar]
- Song, Y.; Lee, J. Importance of event binary features in stock price prediction. Appl. Sci. 2020, 10, 1597. [Google Scholar] [CrossRef]
- Zhang, S.; Bahrampour, S.; Ramakrishnan, N.; Schott, L.; Shah, M. Deep learning on symbolic representations for large-scale heterogeneous time-series event prediction. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5970–5974. [Google Scholar]
- Bollinger, J. Using Bollinger Bands. Stock. Commod. 1992, 10, 47–51. [Google Scholar]
- Silva, D.B.; Cruz, P.P.; Gutierrez, A.M. Are the long–short term memory and convolution neural networks really based on biological systems? ICT Express 2018, 4, 100–106. [Google Scholar] [CrossRef]
- Uncapher, M.R.; Rugg, M.D. Selecting for Memory? The Influence of Selective Attention on the Mnemonic Binding of Contextual Information. J. Neurosci. 2009, 29, 8270–8279. [Google Scholar] [CrossRef] [PubMed]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J. Recurrent nets that time and count. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks, IJCNN 2000, Neural Computing: New Challenges and Perspectives for the New Millennium, Como, Italy, 27 July 2000; pp. 189–194. [Google Scholar]
- KOSIS (Korean Statistical Information System). Available online: https://kosis.kr/index/index.do (accessed on 17 September 2023).
- Hochreiter, S. Untersuchungen zu dynamischen neuronalen Netzen. Diploma Tech. Univ. München 1991, 91, 31. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Daily Amounts to Purchase Pork | Retail Price Meat | Wholesale Price Caress | News Frequency | News Command Frequency | TV Frequency | Blog Frequency | Blog Command Frequency | Suggested Issue |
|---|---|---|---|---|---|---|---|---|---|
| 3 March 2015 | 670,076 | 15,763 | 4596 | 68 | 74 | 0 | 12 | 18 | Pork Day |
| 4 March 2015 | 80,957 | 17,563 | 4728 | 9 | 0 | 30 | 7 | 12 | |
| 29 September 2017 | 206,260 | 23,276 | 4500 | 1 | 0 | 72 | 1 | 0 | Chuseok |
| 30 September 2017 | 790,229 | 23,276 | 4500 | 2 | 1 | 1 | 0 | 0 | |
| 8 July 2016 | 158,650 | 22,761 | 4697 | 6 | 107 | 0 | 0 | 0 | “Three Meals a Day“ TV program |
| 9 July 2016 | 730,378 | 22,761 | 4697 | 0 | 0 | 3 | 3 | 4 | |
| 3 March 2011 | 238,080 | 19,996 | 5982 | 13 | 13 | 8 | 106 | 53 | Soaring consumer prices |
| 3 March 2011 | 805,401 | 18,566 | 5936 | 6 | 6 | 0 | 178 | 110 | |
| 28 November 2015 | 751,194 | 20,488 | 4403 | 2 | 0 | 8 | 1 | 0 | - |
| 29 November 2015 | 191,110 | 20,488 | 4403 | 0 | 0 | 151 | 2 | 16 | |
| 3 March 2011 | 805,401 | 18,566 | 5936 | 6 | 6 | 0 | 178 | 110 | Soaring consumer prices |
| 4 March 2011 | 265,294 | 18,566 | 5936 | 3 | 0 | 4 | 136 | 137 | |
| 15 November 2012 | 167,373 | 14,400 | 3525 | 0 | 0 | 39 | 6 | 7 | Pork prices degradation |
| 16 November 2012 | 694,547 | 14,354 | 3525 | 3 | 0 | 3 | 7 | 0 | |
| 16 September 2013 | 230,070 | 18,349 | 3706 | 2 | 4 | 40 | 9 | 43 | Chuseok |
| 17 September 2013 | 754,870 | 18,482 | 3488 | 1 | 0 | 35 | 11 | 0 |
| Column | Description |
|---|---|
| retail_price_meat | Daily retail prices of pork belly meat |
| wholesale_price_carcass | Daily wholesale prices of pork carcass |
| pig_bred_number_quarter_before | Number of pigs bred in previous quarter |
| pig_slaughtered_number_quarter_before | Number of pigs slaughtered in previous quarter |
| wholesale_price_carcass_quarter_before | Daily wholesale prices of pork carcass in previous quarter |
| output_ton_year_before_carcass | Pork meat production in previous year (ton) |
| import_ton_year_before | Imported pork meat in previous year (ton) |
| monthly_sales_trend_ton_meat | Monthly sales trend of pork meat (ton) |
| Column | Description | Record Numbers |
|---|---|---|
| news_freq | Frequency of the appearance of the word in pig news contents | 6655 |
| emotions_number_angries | Frequency of sentiment for news content | 3979 |
| emotion_number_likes | 14,811 | |
| emotions_number_sads | 395 | |
| emotions_number_wants | 438 | |
| emotions_number_warms | 153 | |
| news_comment_freq | Frequency of the appearance of the word in pig news comment | 44,342 |
| news_positive_term_freq | Frequency of positive word appearance in pig news content | 35,319 |
| news_negative_term_freq | Frequency of negative word appearance in pig news content | 4429 |
| video_freq | Frequency of the appearance of the word in pig TV programs | 1529 |
| video_total_ranking_ave_p | Video total ranking average | 1529 |
| video_freq_times_viewrate | Video frequency times view rate | 1529 |
| video_positive_term_freq | Frequency of positive word appearance in pig TV programs content | 119,396 |
| video_negative_term_freq | Frequency of negative word appearance in pig TV programs content | 4745 |
| blog_freq | Frequency of the appearance of the word in pig blog | 75,035 |
| blog_comments | Frequency of word appearance in a pig blog comment | 109,950 |
| blog_likes | Frequency of sentiment for blog content | 70,025 |
| blog_positive_term_freq | Frequency of positive word appearance in pig blog content | 1,666,492 |
| blog_negative_term_freq | Frequency of negative word appearance in pig blog content | 56,870 |
| Test Case | Parameter | Error Rate | ||||||
|---|---|---|---|---|---|---|---|---|
| Window | Batch Size | Epoch | in Event Sequence | RMSE | MAE | MAPE | MPE | |
| 1 | 84 | 64 | 500 | Used | 0.11 | 0.09 | 35.48 | −6.60 |
| Not used | 0.16 | 0.12 | 49.09 | −17.50 | ||||
| 2 | 84 | 64 | 300 | Used | 0.08 | 0.06 | 23.80 | −3.17 |
| Not used | 0.13 | 0.10 | 36.44 | −9.36 | ||||
| 3 | 28 | 64 | 500 | Used | 0.14 | 0.11 | 48.70 | −20.65 |
| Not used | 0.15 | 0.13 | 61.83 | −39.95 | ||||
| 4 | 28 | 64 | 300 | Used | 0.14 | 0.11 | 50.25 | −24.68 |
| Not used | 0.14 | 0.11 | 41.58 | −2.44 | ||||
| 5 | 84 | 32 | 500 | Used | 0.09 | 0.08 | 32.61 | −11.56 |
| Not used | 0.10 | 0.08 | 33.49 | −13.64 | ||||
| 6 | 84 | 32 | 300 | Used | 0.09 | 0.07 | 30.87 | −12.52 |
| Not used | 0.10 | 0.08 | 33.90 | −13.86 | ||||
| 7 | 28 | 32 | 500 | Used | 0.16 | 0.12 | 66.33 | −45.59 |
| Not used | 0.16 | 0.12 | 64.31 | −39.60 | ||||
| 8 | 28 | 32 | 300 | Used | 0.16 | 0.12 | 72.91 | −57.40 |
| Not used | 0.15 | 0.12 | 70.66 | −52.69 | ||||
| Test Case | Method | Window | RMSE | MAE | MAPE | MPE | Parameter |
|---|---|---|---|---|---|---|---|
| 1 | RNN | 84 | 0.13 | 0.10 | 57.70 | −39.19 | batch size = 64 epoch = 300 |
| LSTM | 0.13 | 0.10 | 57.46 | −40.22 | |||
| GRU | 0.12 | 0.09 | 59.63 | −42.88 | |||
| SCE-LSTM | 0.11 | 0.09 | 45.93 | −25.97 | |||
| 2 | RNN | 84 | 0.13 | 0.09 | 32.18 | −6.83 | batch size = 64 epoch = 300 |
| LSTM | 0.13 | 0.09 | 36.26 | −14.83 | |||
| GRU | 0.12 | 0.09 | 34.64 | −16.95 | |||
| SCE-LSTM | 0.11 | 0.07 | 27.60 | −10.67 | |||
| 3 | RNN | 84 | 0.11 | 0.08 | 30.45 | −8.98 | batch size = 64 epoch = 300 |
| LSTM | 0.12 | 0.09 | 37.70 | −11.70 | |||
| GRU | 0.10 | 0.06 | 28.12 | −9.04 | |||
| SCE-LSTM | 0.08 | 0.06 | 22.55 | 1.95 | |||
| 4 | RNN | 84 | 0.11 | 0.08 | 38.96 | −25.21 | batch size = 64 epoch = 300 |
| LSTM | 0.12 | 0.08 | 48.46 | −38.02 | |||
| GRU | 0.10 | 0.07 | 38.43 | −20.91 | |||
| SCE-LSTM | 0.10 | 0.07 | 37.95 | −20.83 | |||
| 5 | RNN | 84 | 0.12 | 0.09 | 29.12 | −3.69 | batch size = 64 epoch = 300 |
| LSTM | 0.10 | 0.08 | 28.93 | −6.34 | |||
| GRU | 0.10 | 0.08 | 27.29 | −10.96 | |||
| SCE-LSTM | 0.10 | 0.07 | 26.20 | 0.15 | |||
| 6 | RNN | 28 | 0.14 | 0.10 | 51.00 | −20.08 | batch size = 64 epoch = 300 |
| LSTM | 0.16 | 0.11 | 55.67 | −19.22 | |||
| GRU | 0.13 | 0.10 | 62.31 | −42.22 | |||
| SCE-LSTM | 0.13 | 0.09 | 49.21 | −22.41 | |||
| 7 | RNN | 28 | 0.13 | 0.09 | 66.53 | −47.47 | batch size = 64 epoch = 300 |
| LSTM | 0.14 | 0.10 | 65.99 | −41.44 | |||
| GRU | 0.13 | 0.09 | 63.28 | −45.50 | |||
| SCE-LSTM | 0.13 | 0.10 | 59.76 | −27.30 | |||
| 8 | RNN | 28 | 0.18 | 0.12 | 32.07 | −2.84 | batch size = 64 epoch = 300 |
| LSTM | 0.19 | 0.12 | 34.93 | −10.59 | |||
| GRU | 0.19 | 0.13 | 34.42 | −3.81 | |||
| SCE-LSTM | 0.16 | 0.10 | 26.33 | 2.30 | |||
| 9 | RNN | 28 | 0.13 | 0.09 | 37.33 | −8.35 | batch size = 64 epoch = 300 |
| LSTM | 0.16 | 0.13 | 61.00 | −35.89 | |||
| GRU | 0.15 | 0.11 | 50.19 | −21.95 | |||
| SCE-LSTM | 0.14 | 0.11 | 41.58 | −2.44 | |||
| 10 | RNN | 28 | 0.12 | 0.09 | 32.26 | −11.04 | batch size = 64 epoch = 300 |
| LSTM | 0.13 | 0.09 | 32.55 | −7.99 | |||
| GRU | 0.11 | 0.09 | 29.32 | −6.81 | |||
| SCE-LSTM | 0.11 | 0.08 | 26.94 | −0.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, G.-A.; Chuluunsaikhan, T.; Nasridinov, A.; Rah, H.; Yoo, K.-H. SCE-LSTM: Sparse Critical Event-Driven LSTM Model with Selective Memorization for Agricultural Time-Series Prediction. Agriculture 2023, 13, 2044. https://doi.org/10.3390/agriculture13112044
Ryu G-A, Chuluunsaikhan T, Nasridinov A, Rah H, Yoo K-H. SCE-LSTM: Sparse Critical Event-Driven LSTM Model with Selective Memorization for Agricultural Time-Series Prediction. Agriculture. 2023; 13(11):2044. https://doi.org/10.3390/agriculture13112044
Chicago/Turabian StyleRyu, Ga-Ae, Tserenpurev Chuluunsaikhan, Aziz Nasridinov, HyungChul Rah, and Kwan-Hee Yoo. 2023. "SCE-LSTM: Sparse Critical Event-Driven LSTM Model with Selective Memorization for Agricultural Time-Series Prediction" Agriculture 13, no. 11: 2044. https://doi.org/10.3390/agriculture13112044