
Rootstock’s and Cover-Crops’ Influence on Grape: A NIR-Based ANN Classification Model

Abstract
:1. Introduction
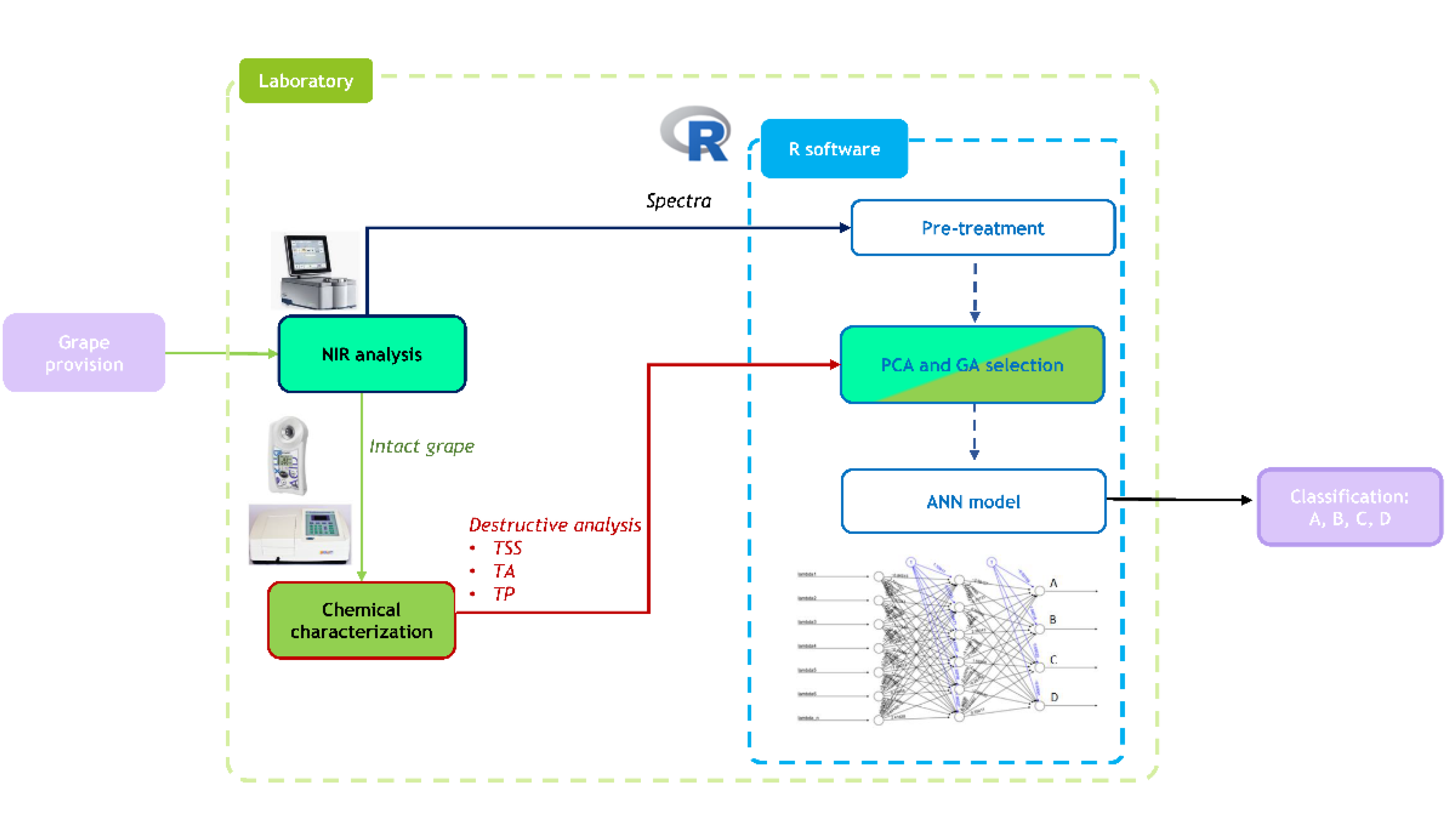
2. Materials and Methods
2.1. Grape Samples
2.2. NIR Spectroscopy
2.3. Statistical Analysis
3. Results
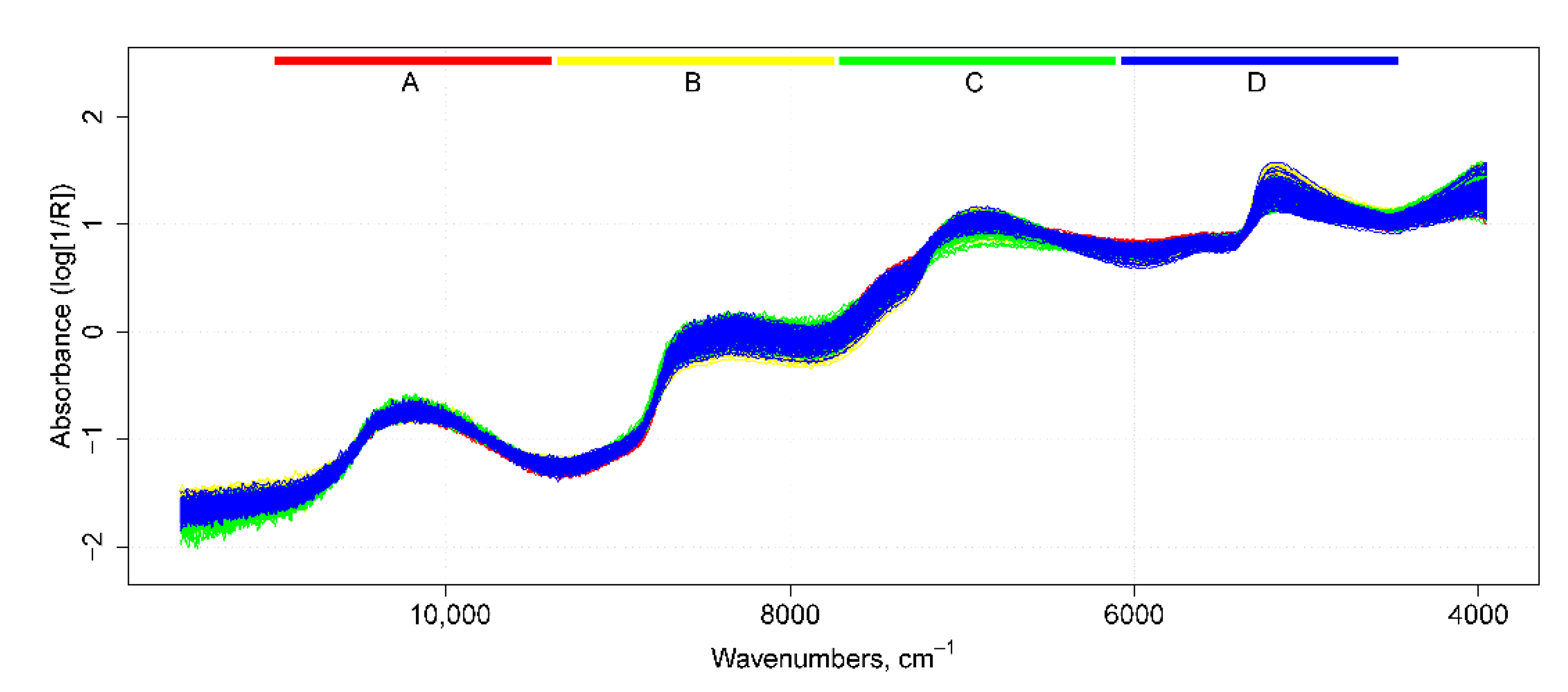
3.1. Maturity Parameters and Data Preparation
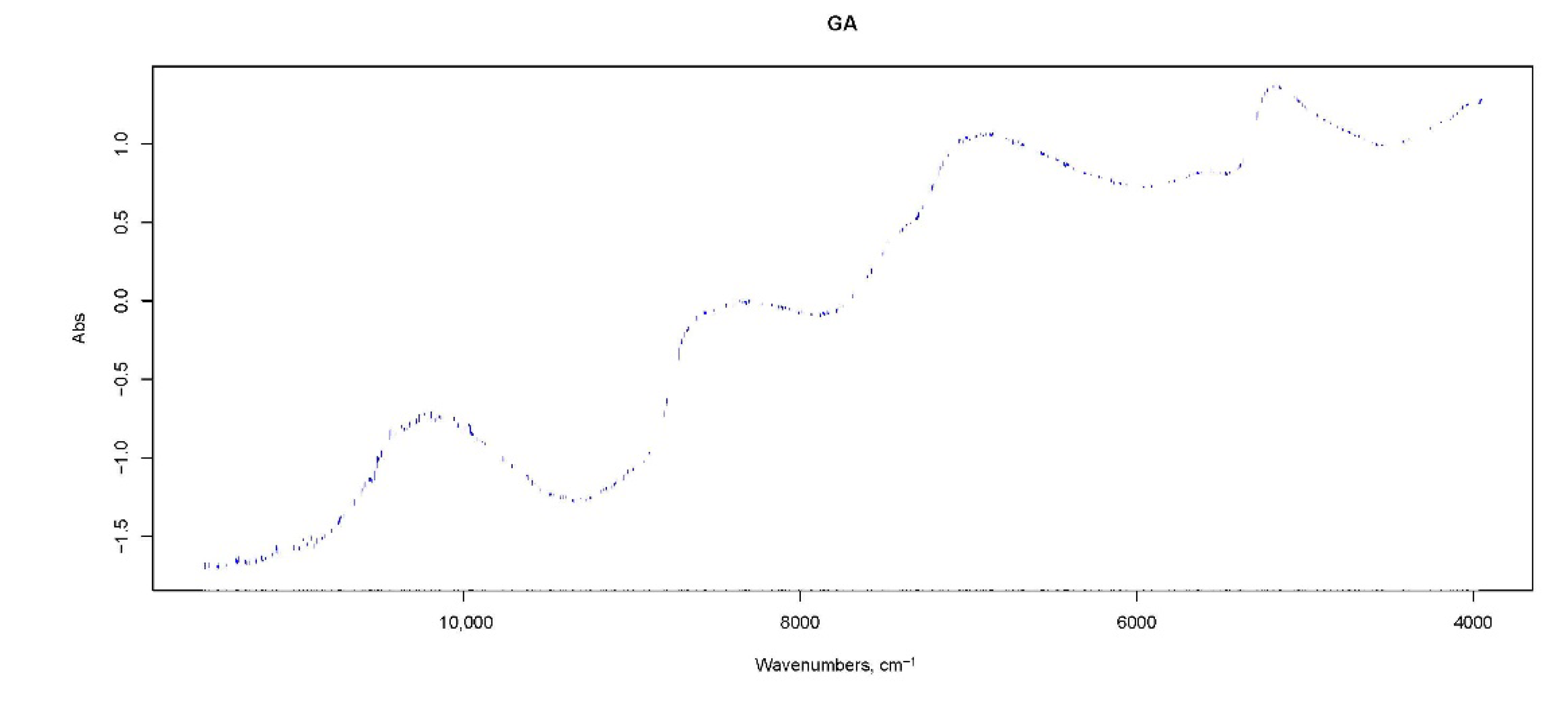
3.2. GA-Based Feature SelectionDone
3.3. Development of Supervised Classification Models
3.4. ANN Structure
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Cozzolino, D.; Roumeliotis, S.; Eglinton, J. Exploring the use of near infrared (NIR) reflectance spectroscopy to predict starch pasting properties in whole grain barley. Food Biophys. 2013, 8, 256–261. [Google Scholar] [CrossRef]
- Ali Shah, S.S.; Zeb, A.; Qureshi, W.S.; Arslan, M.; Malik, A.U.; Alasmary, W.; Alanazi, E. Towards fruit maturity estimation using NIR spectroscopy. Infrared Phys. Technol. 2020, 11, 103479. [Google Scholar] [CrossRef]
- Basile, B.; DeJong, T.M. La Riduzione del Vigore Delle Piante Arboree da Frutto Mediante il Portainnesto. Italus Hortus 2007, 14, 58–70. Available online: https://www.soihs.it/ItalusHortus/Review/Review%2006/Basile%20e%20De%20Jong.pdf (accessed on 1 January 2022).
- Habran, A.; Commisso, M.; Helwi, P.; Hilbert, G.; Negri, S.; Ollat, N.; Gomès, E.; van Leeuwen, C.; Guzzo, F.; Delrot, S. Roostocks/Scion/Nitrogen Interactions Affect Secondary Metabolism in the Grape Berry. Front. Plant Sci. 2016, 9, 1134. [Google Scholar] [CrossRef] [Green Version]
- Dong, D.; Shi, Y.N.; Mou, Z.M.; Chen, S.Y.; Zhao, D.K. Grafting: A potential method to reveal the differential accumulation mechanism of secondary metabolites. Hortic. Res. 2022, 28, uhac050. [Google Scholar] [CrossRef]
- Mercenaro, L.; Nieddu, G.; Pulina, P.; Porqueddu, C. Sustainable management of an intercropped Mediterranean vineyard. Agric. Ecosyst. Environ. 2014, 192, 95–104. [Google Scholar] [CrossRef]
- Guerra, B.; Steenwerth, K. Influence of floor management technique on grapevine growth, disease pressure, and juice and wine composition: A review. Am. J. Enol. Vitic. 2012, 63, 149–164. [Google Scholar] [CrossRef]
- Muscas, E.; Cocco, A.; Mercenaro, L.; Cabras, M.; Lentini, A.; Porqueddu, C.; Nieddu, G. Effects of vineyard floor cover crops on grapevine vigor, yield, and fruit quality, and the development of the vine mealybug under a Mediterranean climate. Agric. Ecosyst. Environ. 2017, 237, 203–212. [Google Scholar] [CrossRef]
- Tesic, D.; Keller, M.; Hutton, R.J. Influence of vineyard floor management practices on grapevine vegetative growth, yield, and fruit composition. Am. J. Enol. Vitic. 2007, 58, 1–11. [Google Scholar] [CrossRef]
- Ferrara, G.; Nigro, D.; Torres, R.; Gadaleta, A.; Fidelibus, M.W.; Mazzeo, A. Cover crops in the inter-row of a table grape vineyard managed with irrigation sensors: Effects on yield, quality and glutamine synthetase activity in leaves. Sci. Hortic. 2021, 281, 109963. [Google Scholar] [CrossRef]
- Naulleau, A.; Gary, C.; Prévot, L.; Hossard, L. Evaluating strategies for adaptation to climate change in grapevine production-a systematic review. Front. Plant Sci. 2021, 11, 607859. [Google Scholar] [CrossRef] [PubMed]
- Basile, T.; Marsico, A.D.; Perniola, R. NIR analysis of intact grape berries: Chemical and physical properties prediction using multivariate analysis. Foods 2021, 10, 113. [Google Scholar] [CrossRef] [PubMed]
- Nasirahmadi, A.; Hensel, O. Toward the next generation of digitalization in agriculture based on digital twin paradigm. Sensors 2022, 22, 498. [Google Scholar] [CrossRef] [PubMed]
- OIV (Organisation Internationale de la Vigne et du Vin). Compendium of International Methods of Analysis—OIV, Folin-Ciocalteu Index, Method OIV-MA-AS2-10: R2009; OIV: Paris, France, 2009. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 1 January 2022).
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Casas, P. Package “funModeling”. Exploratory Data Analysis and Data Preparation Tool-Box. 2020. Available online: https://cran.r-project.org/web/packages/funModeling/funModeling.pdf (accessed on 1 January 2022).
- Scrucca, L. GA: A Package for Genetic Algorithms in R. J. Stat. Softw. 2013, 53, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Willighagen, E.; Ballings, M. R Based Genetic Algorithm. 2022. Available online: https://cran.r-project.org/web/packages/genalg/genalg.pdf (accessed on 1 January 2022).
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Kalinowski, T.; Falbel, D.; Allaire, J.J.; Chollet, F.; Tang, Y.; Van Der Bijl, W.; Studer, M.; Keydana, S. R Interface to ‘Keras’. 2022. Available online: https://cran.r-project.org/web/packages/keras/keras.pdf (accessed on 1 January 2022).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Kucheryavskiy, S. mdatools—R package for chemometrics. Chemom. Intell. Lab. Syst. 2020, 198, 103937. [Google Scholar] [CrossRef]
- Masi, G.; Gentilesco, G.; Amendolagine, A.M.; Mazzone, F.; Roccotelli, S.; Caputo, A.R.; Tarricone, L. Effetti della gestione del suolo sulle performance della varietà ad uva da tavola Autumn Pearl in coltivazione bio: Primi risultati del progetto Oltre.bio (P.S.R. Regione Puglia 16.2). Procedings of the IX Convegno Nazionale di Viticoltura, Conegliano, Italy, 13–15 June 2022. [Google Scholar]
- Ullah, H.; Santiago-Arenas, R.; Ferdous, Z.; Attia, A.; Datta, A. Chapter Two—Improving water use efficiency, nitrogen use efficiency, and radiation use efficiency in field crops under drought stress: A review. In Advances in Agronomy; Sparks, D.L., Ed.; Elsevier: Amsterdam, The Netherlands; Academic Press: Cambridge, MA, USA, 2019; Volume 156, pp. 109–157. [Google Scholar] [CrossRef]
- Louw, E.D.; Theron, K.I. Robust prediction models for quality parameters in Japanese plums (Prunus salicina L.) using NIR spectroscopy. Postharvest Biol. Technol. 2010, 58, 176–184. [Google Scholar] [CrossRef]
- Huang, J.; Romero-Torres, S.; Moshgbar, M. Practical Considerations in Data Pre-Treatment for NIR and Raman Spectroscopy. Am. Pharm. Rev. 2010, 13, 116–127. Available online: https://www.americanpharmaceuticalreview.com/Featured-Articles/116330-Practical-Considerations-in-Data-Pre-treatment-for-NIR-and-Raman-Spectroscopy/ (accessed on 1 January 2022).
- Basile, T.; Marsico, A.D.; Perniola, R. Use of Artificial Neural Networks and NIR Spectroscopy for Non-Destructive Grape Texture Prediction. Foods 2022, 11, 281. [Google Scholar] [CrossRef]
- Cai, W.; Li, Y.; Shao, X. A variable selection method based on uninformative variable elimination for multivariate calibration of near-infrared spectra. Chemom. Intell. Lab. Syst. 2008, 90, 188–194. [Google Scholar] [CrossRef]
- Wutzl, B.; Leibnitz, K.; Rattay, F.; Kronbichler, M.; Murata, M.; Golaszewski, S.M. Genetic algorithms for feature selection when classifying severe chronic disorders of consciousness. PLoS ONE 2019, 14, e0219683. [Google Scholar] [CrossRef] [PubMed]
- Koljonen, J.; Nordling, T.E.M.; Alander, J.T. A review of genetic algorithms in near Infrared spectroscopy and chemometrics: Past and future. J. Near Infrared Spectrosc. 2008, 16, 189–197. [Google Scholar] [CrossRef]
- Kim, H.C.; Kim, D.; Bang, S.Y. Extensions of LDA by PCA mixture model and class-wise features. Pattern Recognit. 2003, 36, 1095–1105. [Google Scholar] [CrossRef]
- Li, Y.; Yang, H. Honey discrimination using visible and near-infrared spectroscopy. Int. Sch. Res. Not. 2012, 2012, 487040. [Google Scholar] [CrossRef] [Green Version]
- Trejos, J.; Villalobos-Arias, M.A.; Espinoza, J.L. Chapter 5: Variable Selection in Multiple Linear Regression Using a Genetic Algorithm. In Handbook of Research on Modern Optimization Algorithms and Applications in Engineering and Economics; Vasant, P., Weber, G.-W., Dieu, V.N., Eds.; IGI Global Publisher: Hershey, PA, USA, 2016; pp. 133–159. [Google Scholar]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Büchmann, N.B.; Josefsson, H.; Cowe, I.A. Performance of European Artificial Neural Network (ANN) calibrations for moisture and protein in cereals using the Danish Near-Infrared Transmission (NIT) network. Cereal Chem. J. 2001, 78, 572–577. [Google Scholar] [CrossRef]
- Kumar, D.; Pandey, A.; Sharma, N.; Flügel, W. Modeling Suspended Sediment Using Artificial Neural Networks and TRMM-3B42 Version 7 Rainfall Dataset. J. Hydrol. Eng. 2015, 20, C4014007. [Google Scholar] [CrossRef]
- Brownlee, J. Deep Learning with Python: Develop Deep Learning Models on Theano and TensorFlow using Keras, v1.9; Machine Learning Mastery: Melbourne, Australia, 2016. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016; ISBN-13: 978-0262035613. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Berry Weight (g) | TP (mg/Kg, as Catechin) | TSS (°Brix) | TA (g/L, as Tartaric Acid) |
|---|---|---|---|---|
| A | 6.59 ± 1.70 bc | 399.0 ± 91.6 a | 18.6 ± 4.0 | 60.1 ± 27.7 b |
| B | 8.46 ± 1.86 a | 310.0 ± 110.0 b | 20.1 ± 1.9 | 81.0 ± 16.9 a |
| C | 7.31 ± 1.77 b | 413.0 ± 95.5 a | 19.0 ± 1.0 | 60.1 ± 7.5 b |
| D | 6.09 ± 1.24 c | 305.0 ± 60.2 b | 18.2 ± 1.7 | 59.5 ± 6.0 b |
| p value | *** | *** | n.s. | * |
| Algorithm | Dataset | Accuracy | K |
|---|---|---|---|
| LDAwhole | Train | 0.64 | 0.52 |
| Test | 0.66 | 0.55 | |
| PCA-LDA | Train | 0.61 | 0.48 |
| Test | 0.61 | 0.47 | |
| GA-LDA | Train | 0.61 | 0.48 |
| Test | 0.58 | 0.44 | |
| ANN | 0.76 | 0.68 | |
| Prediction | Reference | |||
|---|---|---|---|---|
| A | B | C | D | |
| A | 10 | 1 | 2 | 1 |
| B | 2 | 11 | 2 | 2 |
| C | 1 | 3 | 9 | 0 |
| D | 3 | 2 | 5 | 17 |
| Prediction | Reference | |||
|---|---|---|---|---|
| A | B | C | D | |
| A | 9 | 2 | 1 | 3 |
| B | 3 | 11 | 4 | 4 |
| C | 1 | 4 | 9 | 1 |
| D | 3 | 0 | 4 | 12 |
| Prediction | Reference | |||
|---|---|---|---|---|
| A | B | C | D | |
| A | 8 | 0 | 1 | 3 |
| B | 2 | 13 | 3 | 6 |
| C | 1 | 2 | 11 | 0 |
| D | 5 | 2 | 3 | 11 |
| Prediction | Reference | |||
|---|---|---|---|---|
| A | B | C | D | |
| A | 13 | 0 | 3 | 5 |
| B | 0 | 15 | 0 | 2 |
| C | 2 | 2 | 15 | 2 |
| D | 1 | 0 | 0 | 11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basile, T.; Amendolagine, A.M.; Tarricone, L. Rootstock’s and Cover-Crops’ Influence on Grape: A NIR-Based ANN Classification Model. Agriculture 2023, 13, 5. https://doi.org/10.3390/agriculture13010005
Basile T, Amendolagine AM, Tarricone L. Rootstock’s and Cover-Crops’ Influence on Grape: A NIR-Based ANN Classification Model. Agriculture. 2023; 13(1):5. https://doi.org/10.3390/agriculture13010005
Chicago/Turabian StyleBasile, Teodora, Antonio Maria Amendolagine, and Luigi Tarricone. 2023. "Rootstock’s and Cover-Crops’ Influence on Grape: A NIR-Based ANN Classification Model" Agriculture 13, no. 1: 5. https://doi.org/10.3390/agriculture13010005