

Pig Face Recognition Based on Metric Learning by Combining a Residual Network and Attention Mechanism


Abstract
:1. Introduction
2. Related Work
3. Materials
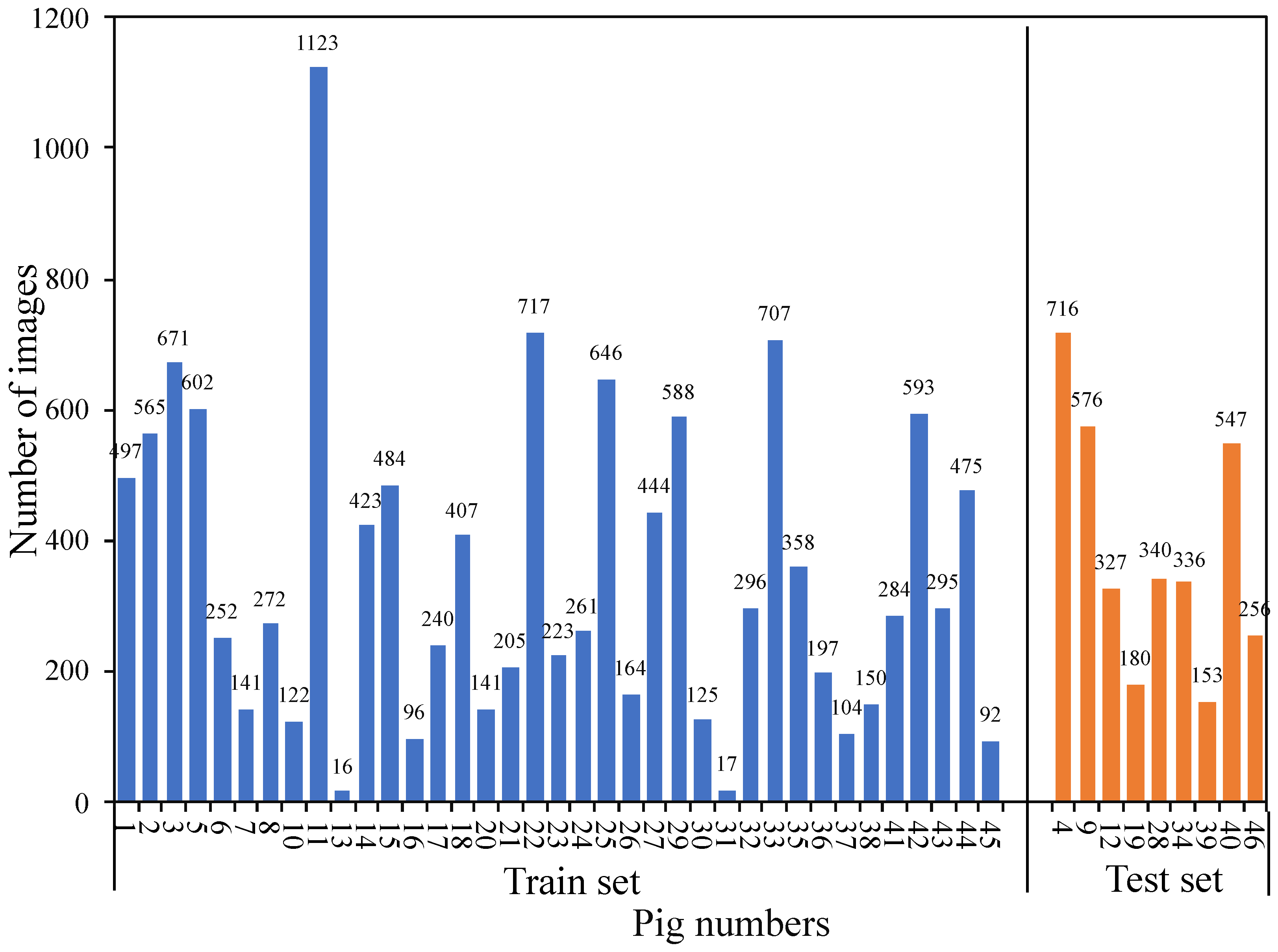
3.1. Data Acquisition
3.2. Data Preprocessing
4. Methods
4.1. MobileFaceNet
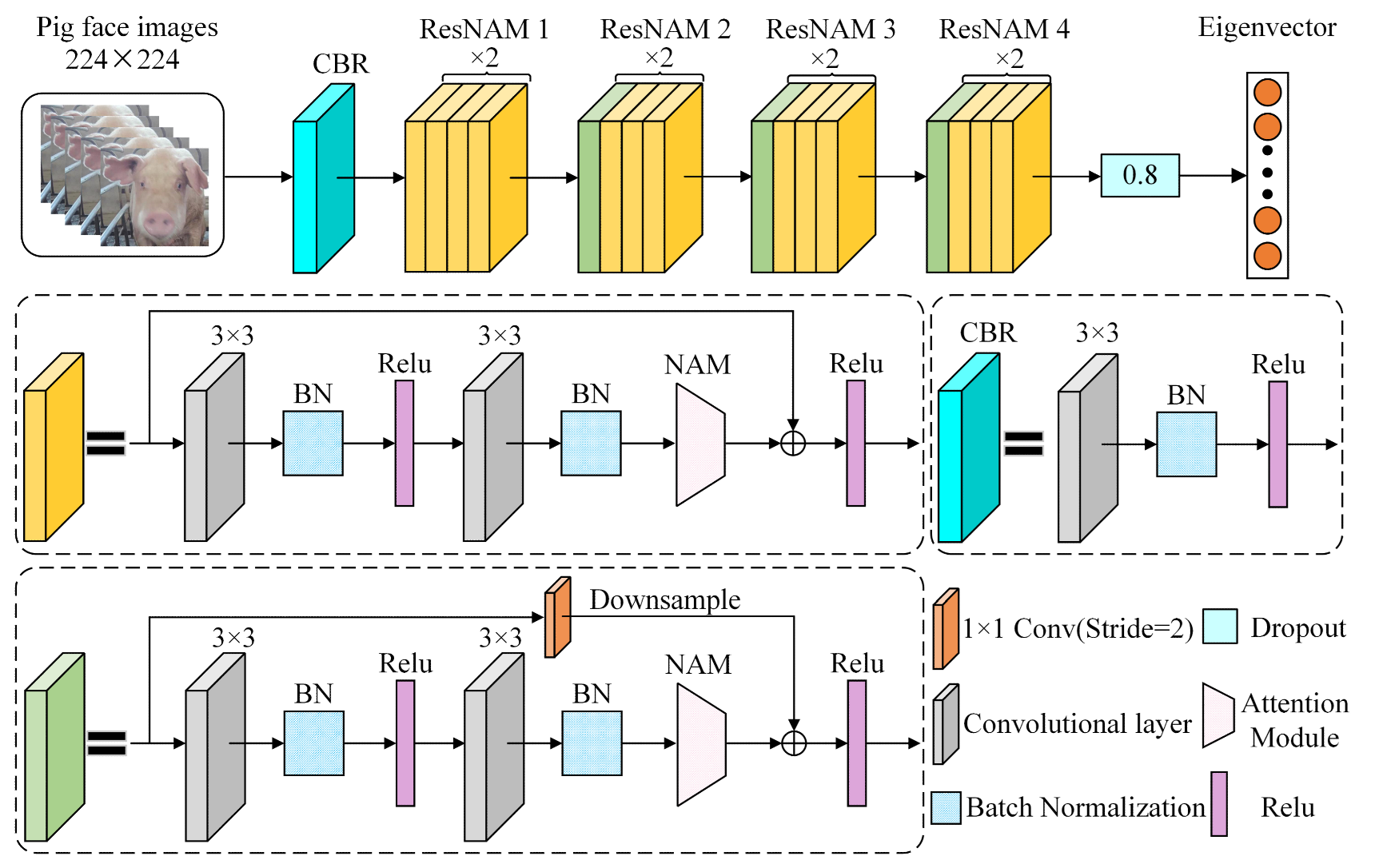
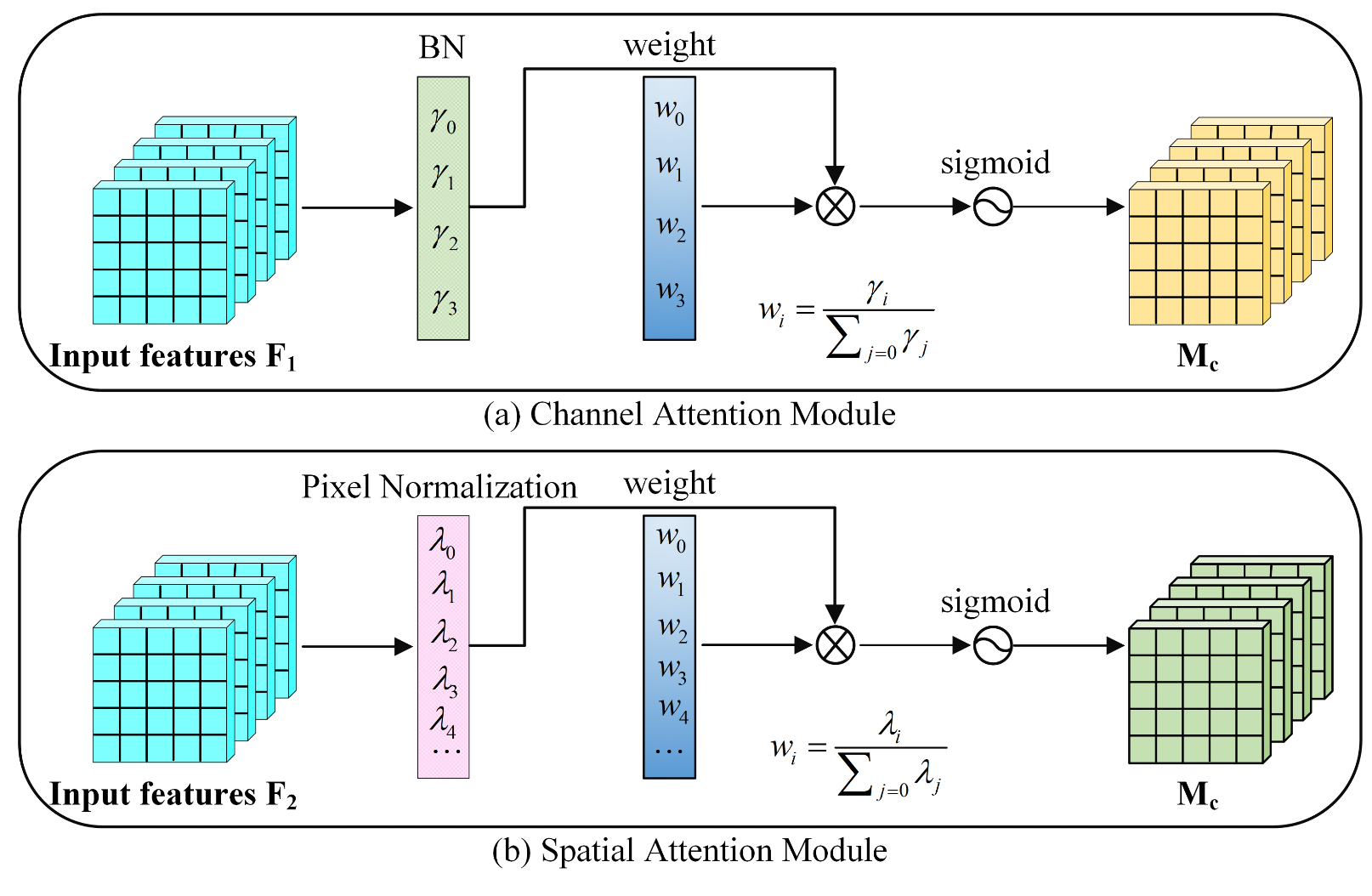
4.2. Feature Extraction Backbone Network with a Normalized Attention Mechanism
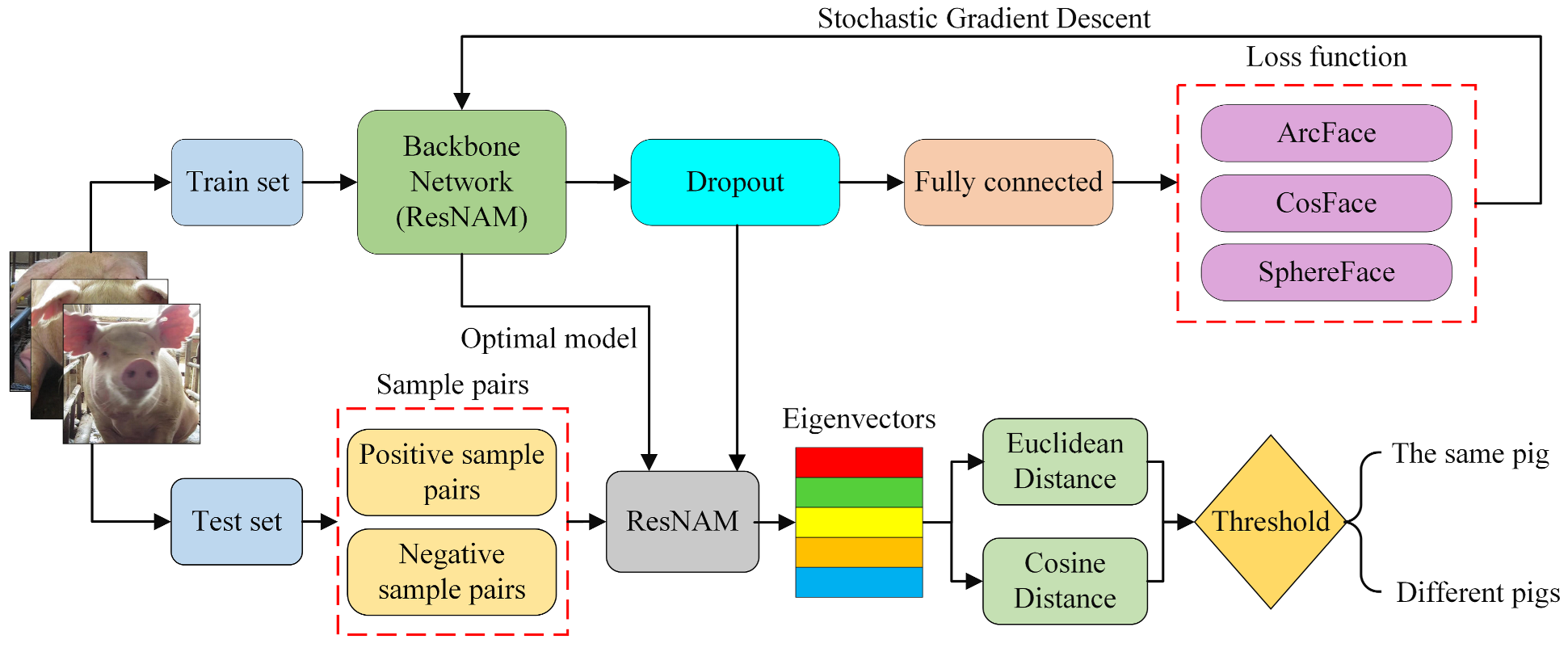
4.3. An Open-Set Recognition Method for Pig Faces
5. Experiment
5.1. Experimental Settings
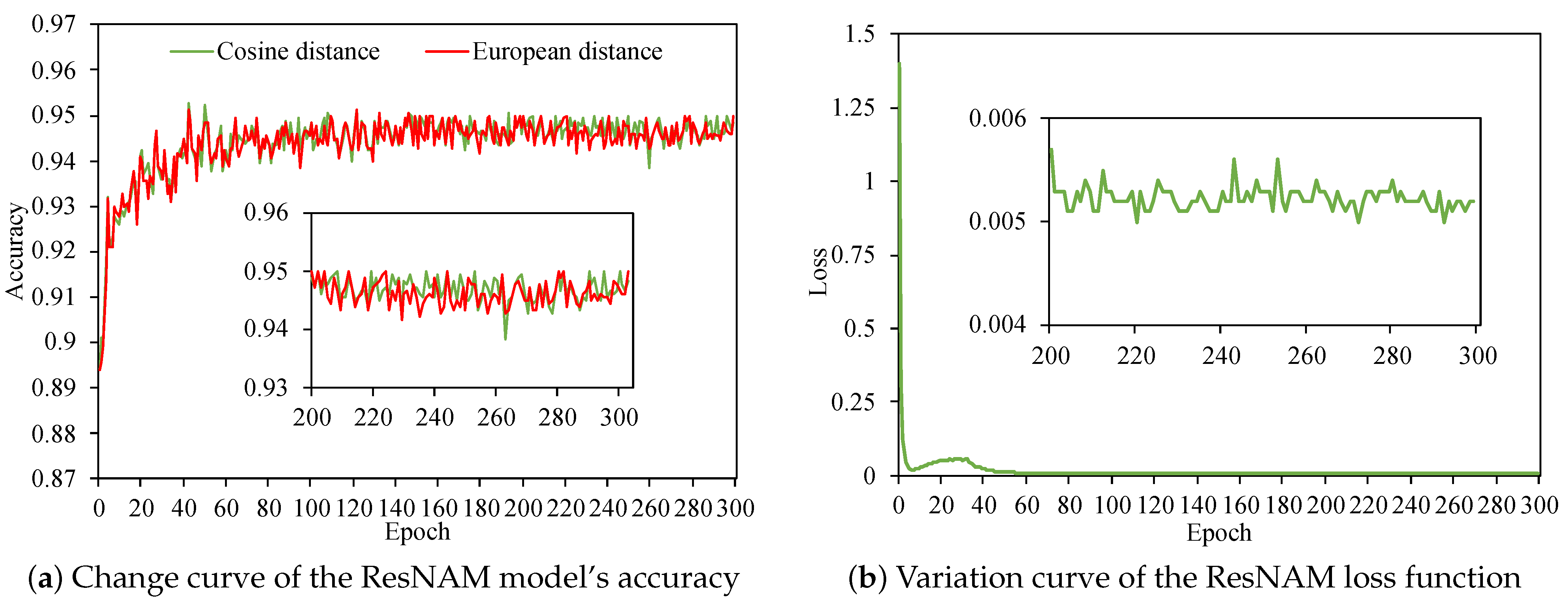
5.2. Results of Training
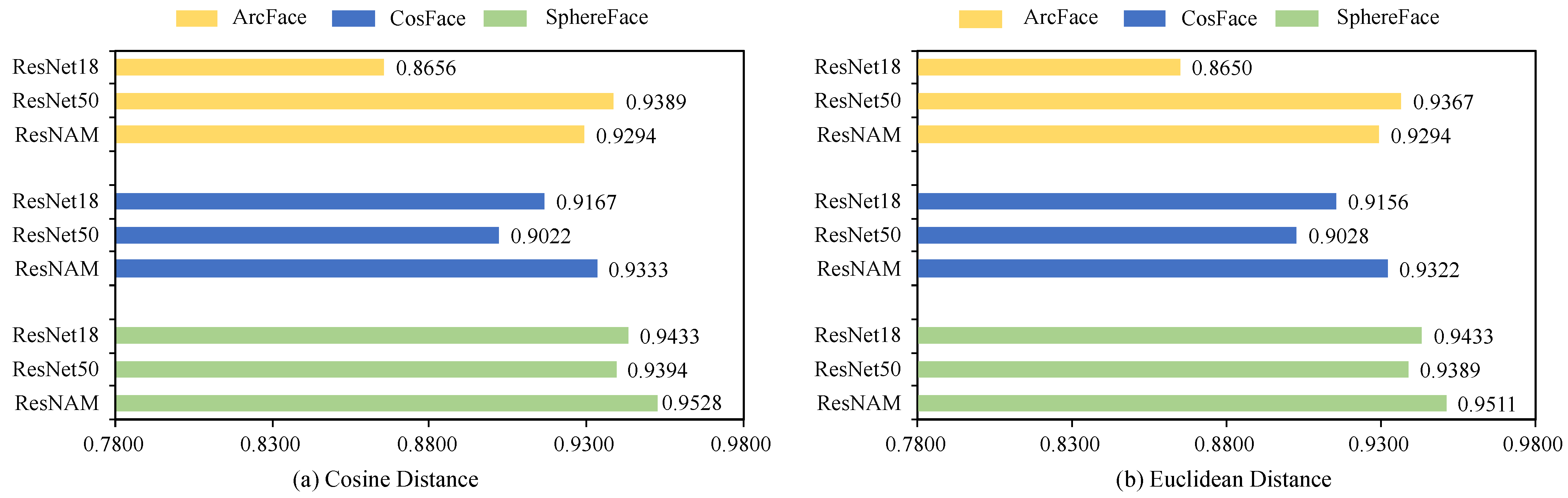
5.3. Ablation Study
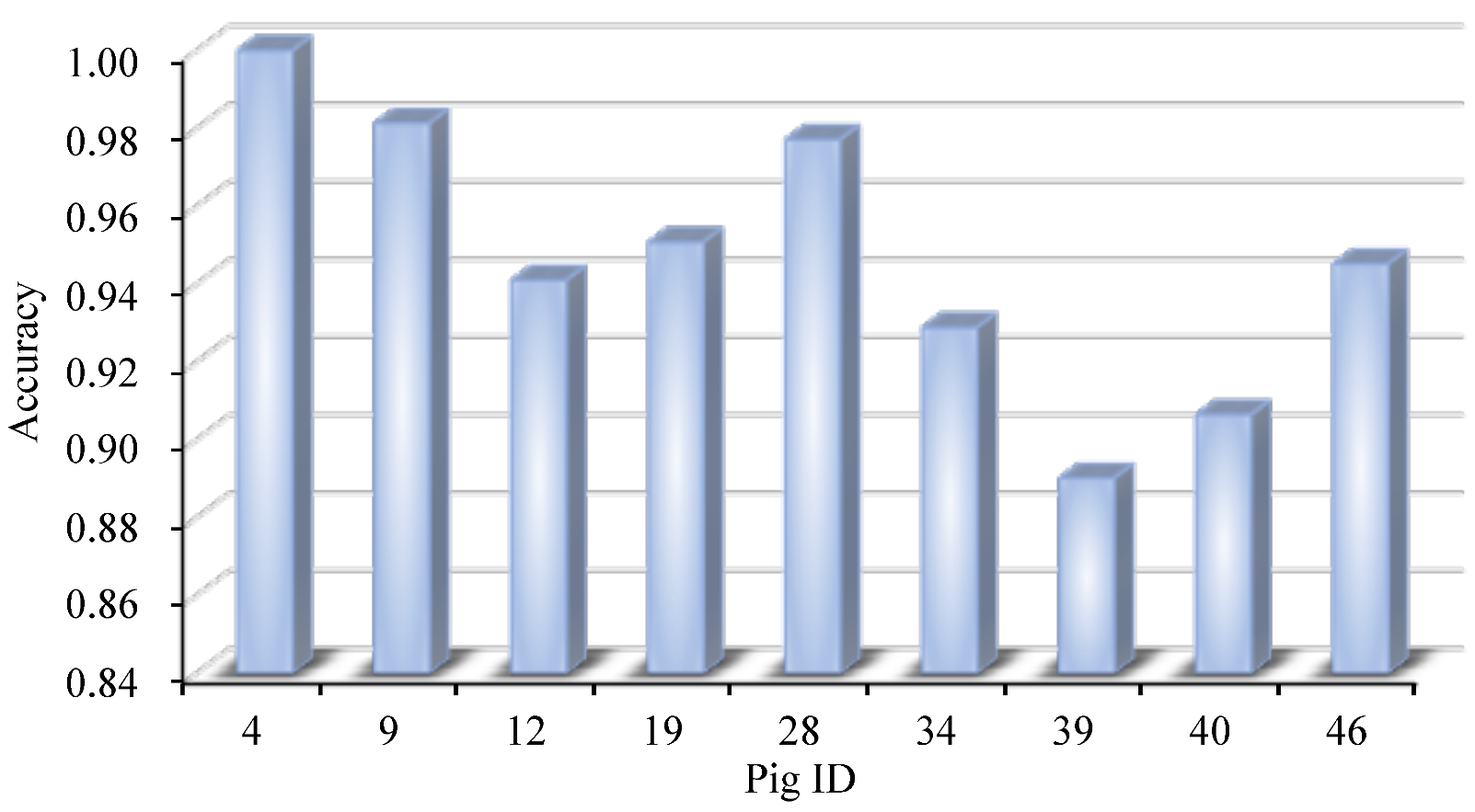
5.3.1. Discussion and Analysis
5.3.2. Comparison with Existing Studies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adrion, F.; Kapun, A.; Eckert, F.; Holland, E.M.; Staiger, M.; Götz, S.; Gallmann, E. Monitoring trough visits of growing-finishing pigs with UHF-RFID. Comput. Electron. Agric. 2018, 144, 144–153. [Google Scholar] [CrossRef]
- Kashiha, M.; Bahr, C.; Ott, S.; Moons, C.P.H.; Niewold, T.A.; Ödberg, F.O.; Berckmans, D. Automatic identification of marked pigs in a pen using image pattern recognition. Comput. Electron. Agric. 2013, 93, 111–120. [Google Scholar] [CrossRef]
- Zhao, K.; Jin, X.; Ji, J.; Wang, J.; Ma, H.; Zhu, X. Individual identification of Holstein dairy cows based on detecting and matching feature points in body images. Biosyst. Eng. 2019, 181, 128–139. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, Q.; Yin, X.; Wu, D.; Song, H.; He, D. FLYOLOv3 deep learning for key parts of dairy cow body detection. Comput. Electron. Agric. 2019, 166, 104982. [Google Scholar] [CrossRef]
- Li, S.; Fu, L.; Sun, Y.; Mu, Y.; Chen, L.; Li, J.; Gong, H. Individual dairy cow identification based on lightweight convolutional neural network. PLoS ONE 2021, 16, e0260510, Publisher: Public Library of Science. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Wang, Y.; Han, M.; Song, L.; Shang, Y.; Zhang, X.; Song, H. Using a CNN-LSTM for basic behaviors detection of a single dairy cow in a complex environment. Comput. Electron. Agric. 2021, 182, 106016. [Google Scholar] [CrossRef]
- Kumar, S.; Pandey, A.; Sai Ram Satwik, K.; Kumar, S.; Singh, S.K.; Singh, A.K.; Mohan, A. Deep learning framework for recognition of cattle using muzzle point image pattern. Measurement 2018, 116, 1–17. [Google Scholar] [CrossRef]
- Salama, A.; Hassanien, A.E.; Fahmy, A. Sheep Identification Using a Hybrid Deep Learning and Bayesian Optimization Approach. IEEE Access 2019, 7, 31681–31687. [Google Scholar] [CrossRef]
- Hu, H.; Dai, B.; Shen, W.; Wei, X.; Sun, J.; Li, R.; Zhang, Y. Cow identification based on fusion of deep parts features. Biosyst. Eng. 2020, 192, 245–256. [Google Scholar] [CrossRef]
- Shen, W.; Hu, H.; Dai, B.; Wei, X.; Sun, J.; Jiang, L.; Sun, Y. Individual identification of dairy cows based on convolutional neural networks. Multimed. Tools Appl. 2020, 79, 14711–14724. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Nice, France, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Andrew, W.; Gao, J.; Mullan, S.; Campbell, N.; Dowsey, A.W.; Burghardt, T. Visual identification of individual Holstein-Friesian cattle via deep metric learning. Comput. Electron. Agric. 2021, 185, 106133. [Google Scholar] [CrossRef]
- Hansen, M.F.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.M.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- Marsot, M.; Mei, J.; Shan, X.; Ye, L.; Feng, P.; Yan, X.; Li, C.; Zhao, Y. An adaptive pig face recognition approach using Convolutional Neural Networks. Comput. Electron. Agric. 2020, 173, 105386. [Google Scholar] [CrossRef]
- Wang, K.; Chen, C.; He, Y. Research on pig face recognition model based on keras convolutional neural network. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2020; p. 032030. [Google Scholar]
- Wang, Z.; Liu, T. Two-stage method based on triplet margin loss for pig face recognition. Comput. Electron. Agric. 2022, 194, 106737. [Google Scholar] [CrossRef]
- Gao, J.; Burghardt, T.; Andrew, W.; Dowsey, A.W.; Campbell, N.W. Towards Self-Supervision for Video Identification of Individual Holstein-Friesian Cattle: The Cows2021 Dataset. arXiv 2021, arXiv:2105.01938. [Google Scholar]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Li, Y.; Cao, Z.; Wu, S. CattleFaceNet: A cattle face identification approach based on RetinaFace and ArcFace loss. Comput. Electron. Agric. 2022, 193, 106675. [Google Scholar] [CrossRef]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar] [CrossRef] [Green Version]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Guo, J.; Yang, J.; Xue, N.; Kotsia, I.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5962–5979. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large Margin Cosine Loss for Deep Face Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5265–5274. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. BAM: Bottleneck Attention Module. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices. In Proceedings of the Biometric Recognition; Springer International Publishing: Cham, Switzerland, 2018. Lecture Notes in Computer Science. pp. 428–438. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Shi, Z.; Li, Q.; Gao, R.; Zhao, C.; Feng, L. Pig Face Recognition Model Based on a Cascaded Network. Appl. Eng. Agric. 2021, 37, 879–890. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Pigs | Number of Images | Number of Positive Sample | Number of Negative Sample | Number of Generated Image Pairs |
|---|---|---|---|---|
| 37 | 12,993 | |||
| 9 | 3431 | 900 | 900 | 1800 |
| Model | Loss Function | Accuracy | Model Weight/MB | |
|---|---|---|---|---|
| Cosine Distance | Euclidean Distance | |||
| ResNet18 | ArcFace | 86.56% | 86.50% | 42.78 MB |
| CosFace | 91.67% | 91.56% | 42.78 MB | |
| SphereFace | 94.33% | 94.33% | 42.78 MB | |
| ResNet50 | ArcFace | 93.89% | 93.67% | 90.27 MB |
| CosFace | 90.22% | 90.28% | 90.27 MB | |
| SphereFace | 93.94% | 93.89% | 90.27 MB | |
| ResNAM | ArcFace | 92.94% | 92.94% | 42.83 MB |
| CosFace | 93.33% | 93.22% | 42.83 MB | |
| SphereFace | 95.28% | 95.11% | 42.83 MB | |
| Number | Model | Loss Function | Accuracy | Model Weight/MB | |
|---|---|---|---|---|---|
| Cosine Distance | Euclidean Distance | ||||
| NO.1 | ResNet18+BAM | ArcFace | 90.44% | 90.44% | 42.91 MB |
| CosFace | 91.61% | 91.50% | 42.91 MB | ||
| SphereFace | 95.11% | 95.22% | 42.91 MB | ||
| NO.2 | ResNet18+CBAM | ArcFace | 91.89% | 91.83% | 43.16 MB |
| CosFace | 90.00% | 90.00% | 43.16 MB | ||
| SphereFace | 93.94% | 93.83% | 43.16 MB | ||
| NO.3 | ResNet18+NAM (Ours: ResNAM) | ArcFace | 92.94% | 92.94% | 42.83 MB |
| CosFace | 93.33% | 93.22% | 42.83 MB | ||
| SphereFace | 95.28% | 95.11% | 42.83 MB | ||
| Model | Accuracy | |
|---|---|---|
| Cosine Distance | Euclidean Distance | |
| MobileFaceNet | 92.44% | 92.67% |
| Ours | 95.28% | 95.11% |
| Number | Model | Loss Function | Accuracy | Model Weight/MB | |
|---|---|---|---|---|---|
| Cosine Distance | Euclidean Distance | ||||
| NO.1 | ResNet18+BAM | ArcFace | 90.44% | 90.44% | 42.91 MB |
| CosFace | 91.61% | 91.50% | 42.91 MB | ||
| SphereFace | 95.11% | 95.22% | 42.91 MB | ||
| NO.2 | ResNet18+CBAM | ArcFace | 91.89% | 91.83% | 43.16 MB |
| CosFace | 90.00% | 90.00% | 43.16 MB | ||
| SphereFace | 93.94% | 93.83% | 43.16 MB | ||
| NO.3 | ResNet18+NAM (Ours: ResNAM) | ArcFace | 92.94% | 92.94% | 42.83 MB |
| CosFace | 93.33% | 93.22% | 42.83 MB | ||
| SphereFace | 95.28% | 95.11% | 42.83 MB | ||
| Test | Cosine Distance | Euclidean Distance | ||
|---|---|---|---|---|
| The Best Threshold | Accuracy | The Best Threshold | Accuracy | |
| NO.1 | 0.745 | 96.667% | 0.510 | 96.667% |
| NO.2 | 0.745 | 95.556% | 0.510 | 95.556% |
| NO.3 | 0.745 | 94.444% | 0.510 | 94.444% |
| NO.4 | 0.745 | 93.333% | 0.500 | 91.667% |
| NO.5 | 0.745 | 95.556% | 0.510 | 95.556% |
| NO.6 | 0.745 | 95.000% | 0.510 | 95.000% |
| NO.7 | 0.745 | 94.444% | 0.510 | 94.444% |
| NO.8 | 0.745 | 97.222% | 0.510 | 97.222% |
| NO.9 | 0.745 | 92.778% | 0.510 | 92.778% |
| NO.10 | 0.745 | 97.778% | 0.510 | 97.778% |
| average accuracy | —— | 95.278% | —— | 95.111% |
| Data | Cosine Distance | Euclidean Distance | ||
|---|---|---|---|---|
| The Best Threshold | Accuracy | The Best Threshold | Accuracy | |
| test set | 0.745 | 95.278% | 0.500 | 95.111% |
| 0.510 | 95.278% | |||
| Method | Studies | Year | Species | Objects | Backbone | Accuracy |
|---|---|---|---|---|---|---|
| Closed-set recognition | Hansen et al. [15] | 2018 | pig | 10 pigs | VGG | 96.7% |
| Marsot et al. [16] | 2020 | pig | 10 pigs | Two Haar feature+ CNN | 83.0% | |
| Salama et al. [8] | 2019 | sheep | 52 sheeps | AlexNet | 98.0% | |
| Wang et al. [17] | 2020 | pig | 10 pigs | LeNet-5 | 97.6% | |
| Wang et al. [29] | 2021 | pig | 46 pigs | ResNet50 | 97.66% | |
| Wang et al. [18] | 2022 | pig | 28 pigs | DenseNet 121 | 94.04% | |
| Open-set recognition | Andrew et al. [14] | 2021 | cow | 46 cows | CNN | 93.8% |
| Xu et al. [20] | 2022 | cow | 90 cows | CattleFaceNet | 91.35% | |
| Ours (ResNAM) | 2022 | pig | 46 pigs | ResNAM | 95.28% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Gao, R.; Li, Q.; Dong, J. Pig Face Recognition Based on Metric Learning by Combining a Residual Network and Attention Mechanism. Agriculture 2023, 13, 144. https://doi.org/10.3390/agriculture13010144
Wang R, Gao R, Li Q, Dong J. Pig Face Recognition Based on Metric Learning by Combining a Residual Network and Attention Mechanism. Agriculture. 2023; 13(1):144. https://doi.org/10.3390/agriculture13010144
Chicago/Turabian StyleWang, Rong, Ronghua Gao, Qifeng Li, and Jiabin Dong. 2023. "Pig Face Recognition Based on Metric Learning by Combining a Residual Network and Attention Mechanism" Agriculture 13, no. 1: 144. https://doi.org/10.3390/agriculture13010144