

Detection Method of Cow Estrus Behavior in Natural Scenes Based on Improved YOLOv5

 ,
,
Abstract
:1. Introduction
2. Data Collection and Analysis
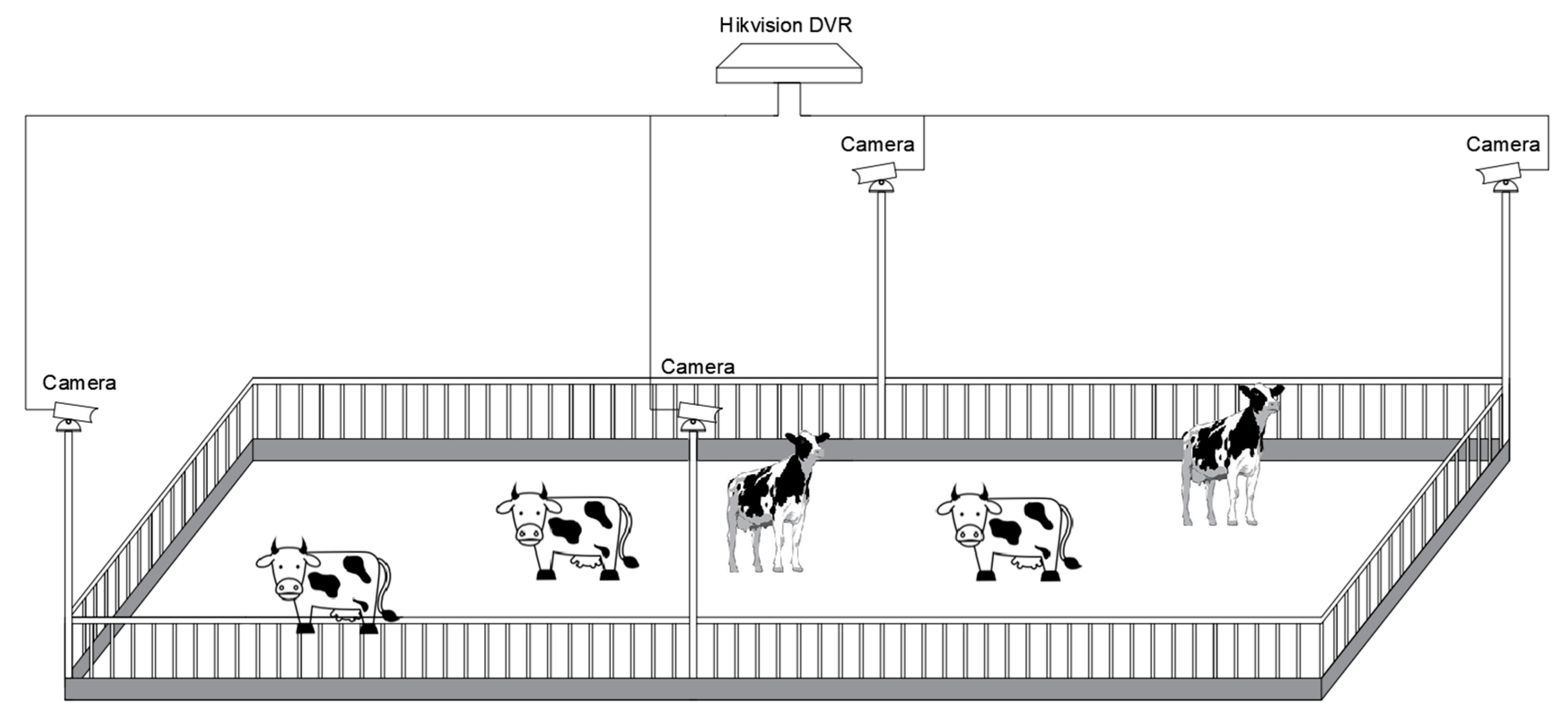
2.1. Data Sources
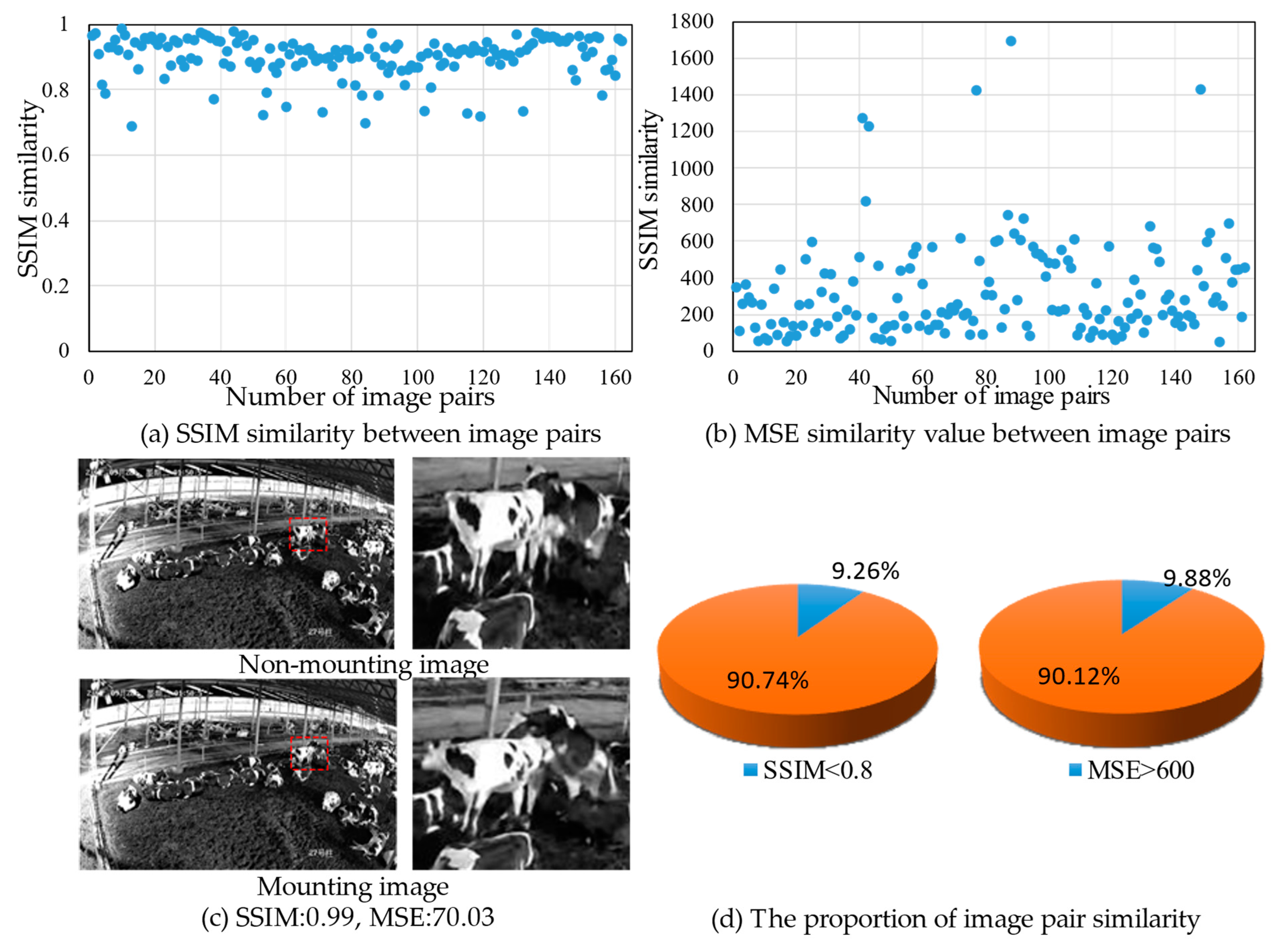
2.2. Data Analysis and Preprocessing
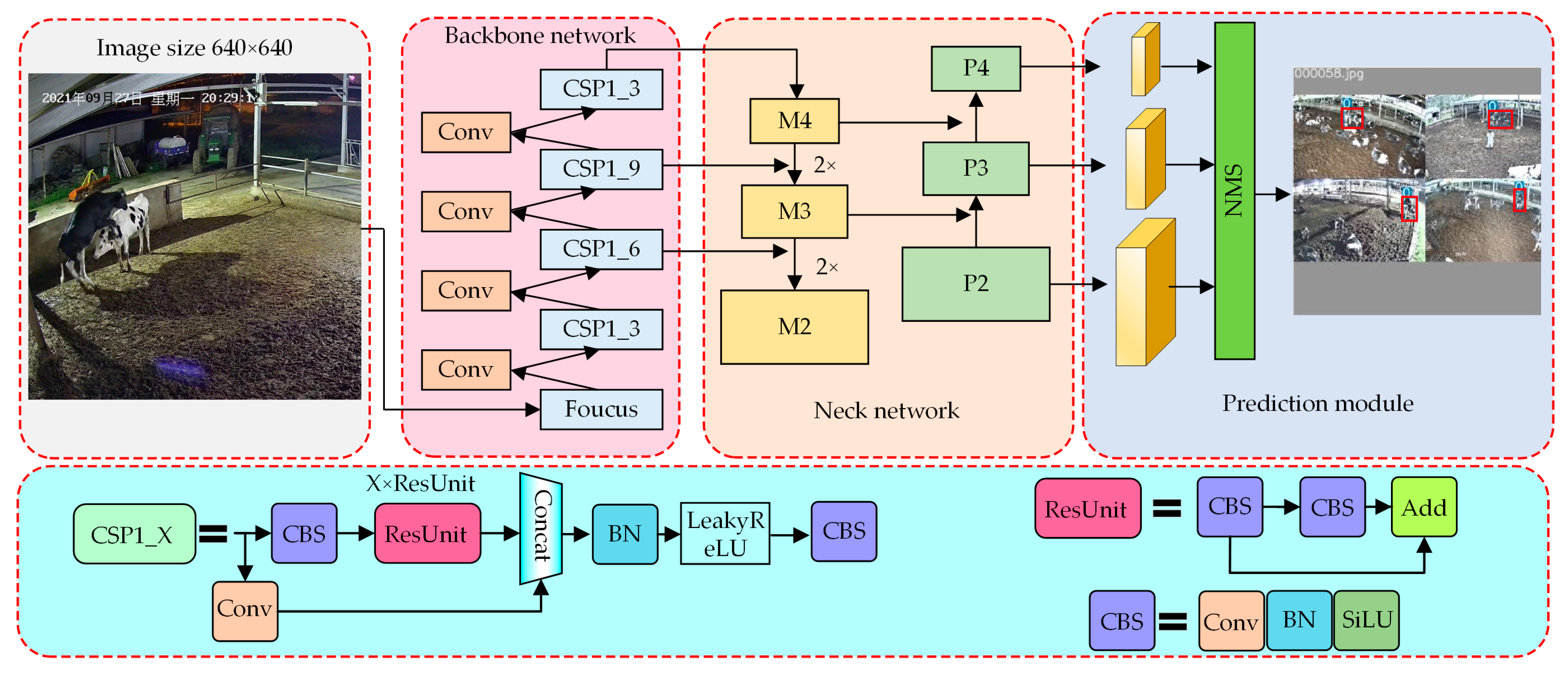
3. Methods
4. Experimental Results and Analysis
4.1. Experimental Parameter Settings
4.2. Base Model Selection
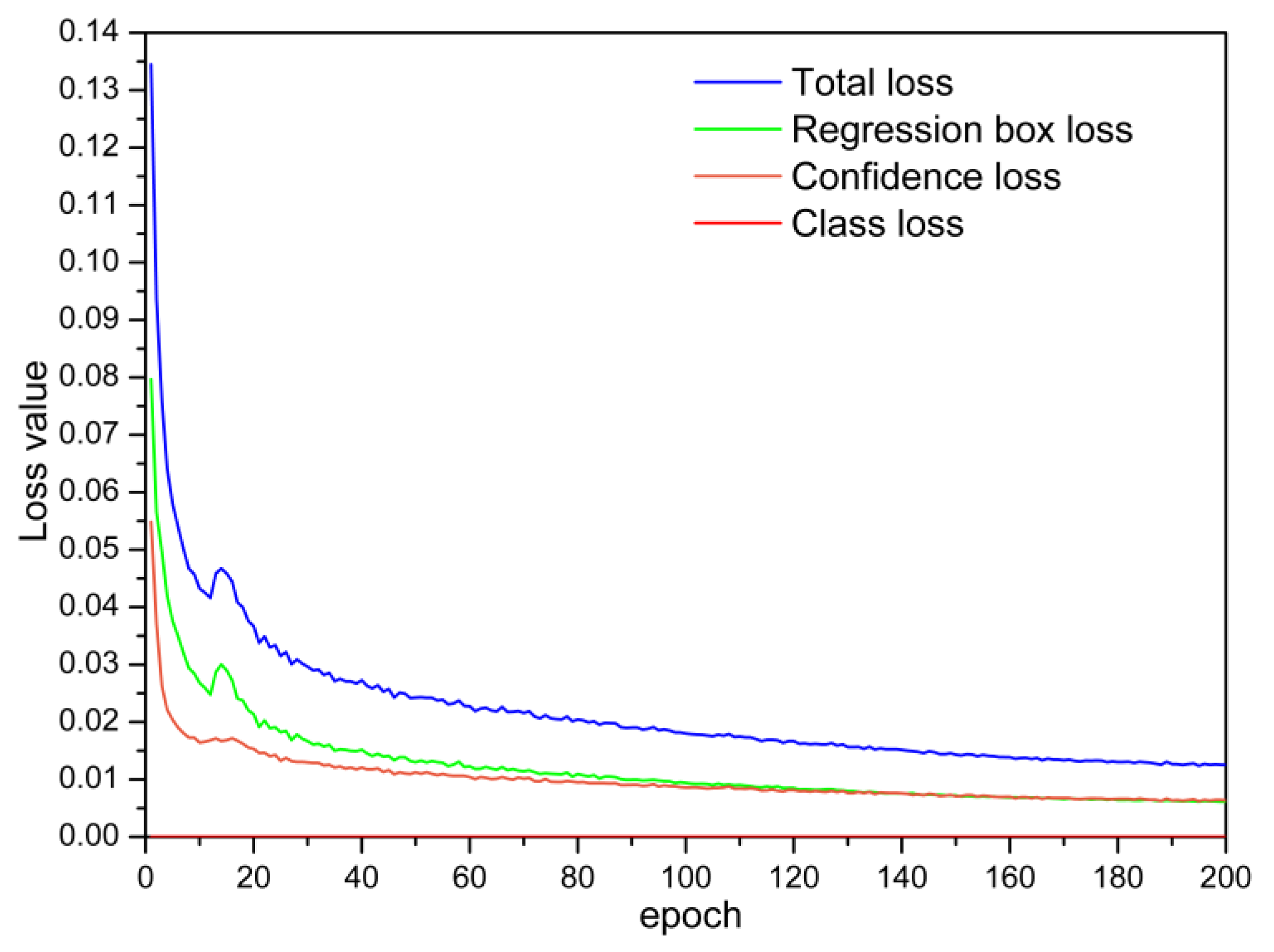
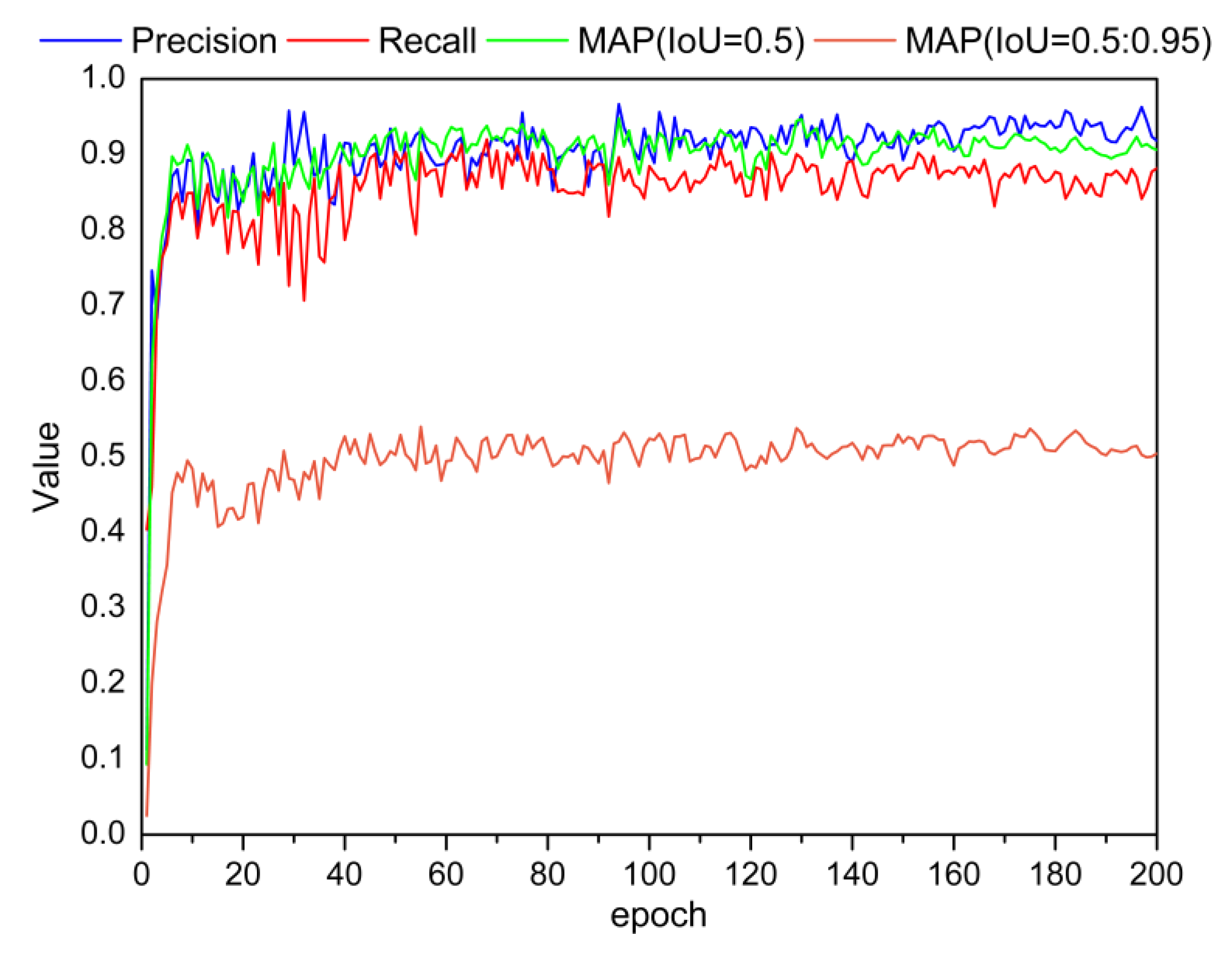
4.3. Model Training Results
4.4. Comparison of Detection Results of Different Models
4.5. Ablation Experiment
4.5.1. Comparison of the Ablation Results of Different Optimization Modules
4.5.2. Ablation Experiments with Different ASPP Modules
4.5.3. Ablation Experiments with Different Loss Functions
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- At-Taras, E.E.; Spahr, S.L. Detection and characterization of estrus in dairy cattle with an electronic heatmount detector and an electronic activity tag. J. Dairy Sci. 2001, 84, 792–798. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Norton, T. Behaviour recognition of pigs and cattle: Journey from computer vision to deep learning. Comput. Electron. Agric. 2021, 187, 106255. [Google Scholar]
- Reith, S.; Hoy, S. Automatic monitoring of rumination time for oestrus detection in dairy cattle. In Proceedings of the International Conference of Agricultural Engineering, Valencia, Spain, 8–12 July 2012; pp. 8–12. [Google Scholar]
- Mackay, J.; Deag, J.M.; Haskell, M.J. Establishing the extent of behavioural reactions in dairy cattle to a leg mounted activity monitor. Appl. Anim. Behav. Sci. 2012, 139, 35–41. [Google Scholar] [CrossRef]
- Aungier, S.; Roche, J.F.; Duffy, P.; Scully, S.; Crowe, M.A. The relationship between activity clusters detected by an automatic activity monitor and endocrine changes during the periestrous period in lactating dairy cows. J. Dairy Sci. 2015, 98, 1666–1684. [Google Scholar] [CrossRef] [PubMed]
- Schweinzer, V.; Gusterer, E.; Kanz, P.; Krieger, S.; Süss, D.; Lidauer, L.; Berger, A.; Kickinger, F.; Öhlschusterb, M.; Auer, W.; et al. Evaluation of an ear-attached accelerometer for detecting estrus events in indoor housed dairy cows. Theriogenology 2019, 130, 19–25. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Bell, M.; Liu, G. Potential of an activity index combining acceleration and location for automated estrus detection in dairy cows. Inf. Process. Agric. 2022, 9, 288–299. [Google Scholar] [CrossRef]
- Tian, F.; Cao, D.; Dong, X.; Zhao, X.; Li, F.; Wang, Z. Behavioural features recognition and oestrus detection based on fast approximate clustering algorithm in dairy cows. IOP Conf. Ser. Earth Environ. Sci. 2017, 69, 012069. [Google Scholar] [CrossRef]
- Fresno, M.; Macchi, A.; Marti, Z.; Dick, A.; Clausse, A. Application of color image segmentation to estrus detection. J. Vis. 2006, 9, 171–178. [Google Scholar] [CrossRef]
- Tsai, D.M.; Huang, C.Y. A motion and image analysis method for automatic detection of estrus and mating behaviour in cattle. Comput. Electron. Agric. 2014, 104, 25–31. [Google Scholar] [CrossRef]
- Gao, R.; Wang, R.; Feng, L.; Li, Q.; Wu, H. Dual-branch, efficient, channel attention-based crop disease identification. Comput. Electron. Agric. 2021, 190, 106410. [Google Scholar] [CrossRef]
- Wang, R.; Shi, Z.; Li, Q.; Gao, R.; Zhao, C.; Feng, L. Pig face recognition model based on a cascaded network. Appl. Eng. Agric. 2021, 37, 879–890. [Google Scholar] [CrossRef]
- Tu, S.; Yuan, W.; Liang, Y.; Wang, F.; Wan, H. Automatic detection and segmentation for group-housed pigs based on PigMS R-CNN. Sensors 2021, 21, 3251. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Kang, X.; Feng, N.; Liu, G. Automatic recognition of dairy cow mastitis from thermal images by a deep learning detector. Comput. Electron. Agric. 2020, 178, 105754. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Zhang, K.; Li, D.; Huang, J.; Chen, Y. Automated video behaviour recognition of pigs using two-stream convolutional networks. Sensors 2020, 20, 1085. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Yang, Q.; Xiao, D.; Cai, J. Pig mounting behaviour recognition based on video spatial–temporal features. Biosyst. Eng. 2021, 206, 55–66. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Han, J.; Norton, T. Classification of drinking and drinker-playing in pigs by a video-based deep learning method. Biosyst. Eng. 2020, 196, 1–14. [Google Scholar]
- Wang, M.; Oczak, M.; Larsen, M.; Bayer, F.; Maschat, K.; Baumgartner, J.; Rault, J.; Norton, T. A PCA-based frame selection method for applying CNN and LSTM to classify postural behaviour in sows. Comput. Electron. Agric. 2021, 189, 106351. [Google Scholar] [CrossRef]
- Ayadi, S.; Said, A.B.; Jabbar, R.; Aloulou, C.; Achballah, A.B. Dairy cow rumination detection: A deep learning approach. In Proceedings of the Distributed Computing for Emerging Smart Networks, Second International Workshop, DiCES-N 2020, Bizerte, Tunisia, 18 December 2020; pp. 123–139. [Google Scholar]
- Wu, D.; Wang, Y.; Han, M.; Song, L.; Shang, Y.; Zhang, X.; Song, H. Using a CNN-LSTM for basic behaviours detection of a single dairy cow in a complex environment. Comput. Electron. Agric. 2021, 182, 106016. [Google Scholar]
- Yin, X.; Wu, D.; Shang, Y.; Jiang, B.; Song, H. Using an EfficientNet-LSTM for the recognition of single Cow’s motion behaviours in a complicated environment. Comput. Electron. Agric. 2020, 177, 105707. [Google Scholar] [CrossRef]
- Liu, Z.; He, D. Recognition method of cow estrus behaviour based on convolutional neural network. Trans. Chin. Soc. Agric. Mach. 2019, 50, 186–193. [Google Scholar]
- Wang, S.; He, D. Estrus behaviour recognition of dairy cows based on improved YOLO v3 model. Trans. Chin. Soc. Agric. Mach. 2021, 52, 141–150. [Google Scholar]
- Ultralytics. YOLOv5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 May 2020).
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Ke, N.R.; Goyal, A.; Bilaniuk, O.; Binas, J.; Charlin, L.; Pal, C.; Bengio, Y. Sparse attentive backtracking: Long-range credit assignment in recurrent networks. arXiv 2017, arXiv:1711.02326. [Google Scholar] [CrossRef]
- Li, G.; Yun, I.; Kim, J.; Kim, J. DABNet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar] [CrossRef]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X. Alpha-IoU: A family of power intersection over union losses for bounding box regression. arXiv 2021, arXiv:2110.13675. [Google Scholar] [CrossRef]
- Li, Y.; Tang, J.L.; He, D.J. Research on behavior recognition of dairy goat based on multi-model fusion. In Proceedings of the 2021 6th International Conference on Multimedia and Image Processing, Zhuhai, China, 8–10 January 2021; pp. 62–66. [Google Scholar]
- Fuentes, A.; Yoon, S.; Park, J.; Park, D.S. Deep learning-based hierarchical cattle behavior recognition with spatio-temporal information. Comput. Electron. Agric. 2020, 177, 105627. [Google Scholar] [CrossRef]
- Li, D.; Chen, Y.; Zhang, K.; Li, Z. Mounting behaviour recognition for pigs based on deep learning. Sensors 2019, 19, 4924. [Google Scholar] [CrossRef]
- Zhang, Y.; Cai, J.; Xiao, D.; Li, Z.; Xiong, B. Real-time sow behavior detection based on deep learning. Comput. Electron. Agric. 2019, 163, 104884. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Z.; He, D.; Niu, J.; Tan, Y. Detection of cow mounting behavior using region geometry and optical flow characteristics. Comput. Electron. Agric. 2019, 163, 104828. [Google Scholar] [CrossRef]
- Li, Z.; Song, L.; Duan, Y.; Wang, Y.; Song, H. Basic motion behaviour recognition of dairy cows based on skeleton and hybrid convolution algorithms. Comput. Electron. Agric. 2022, 196, 106889. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Growth Periods | Number of Videos | Number of Images | Image Enhancement Methods | Image Resolution |
|---|---|---|---|---|
| Training set | 115 videos | 2668 images | Mosaic Enhancement | 2560 × 1440 |
| Test set | 29 videos | 675 images | —— | 2560 × 1440 |
| Total | 144 videos | 3343 images | —— | 2560 × 1440 |
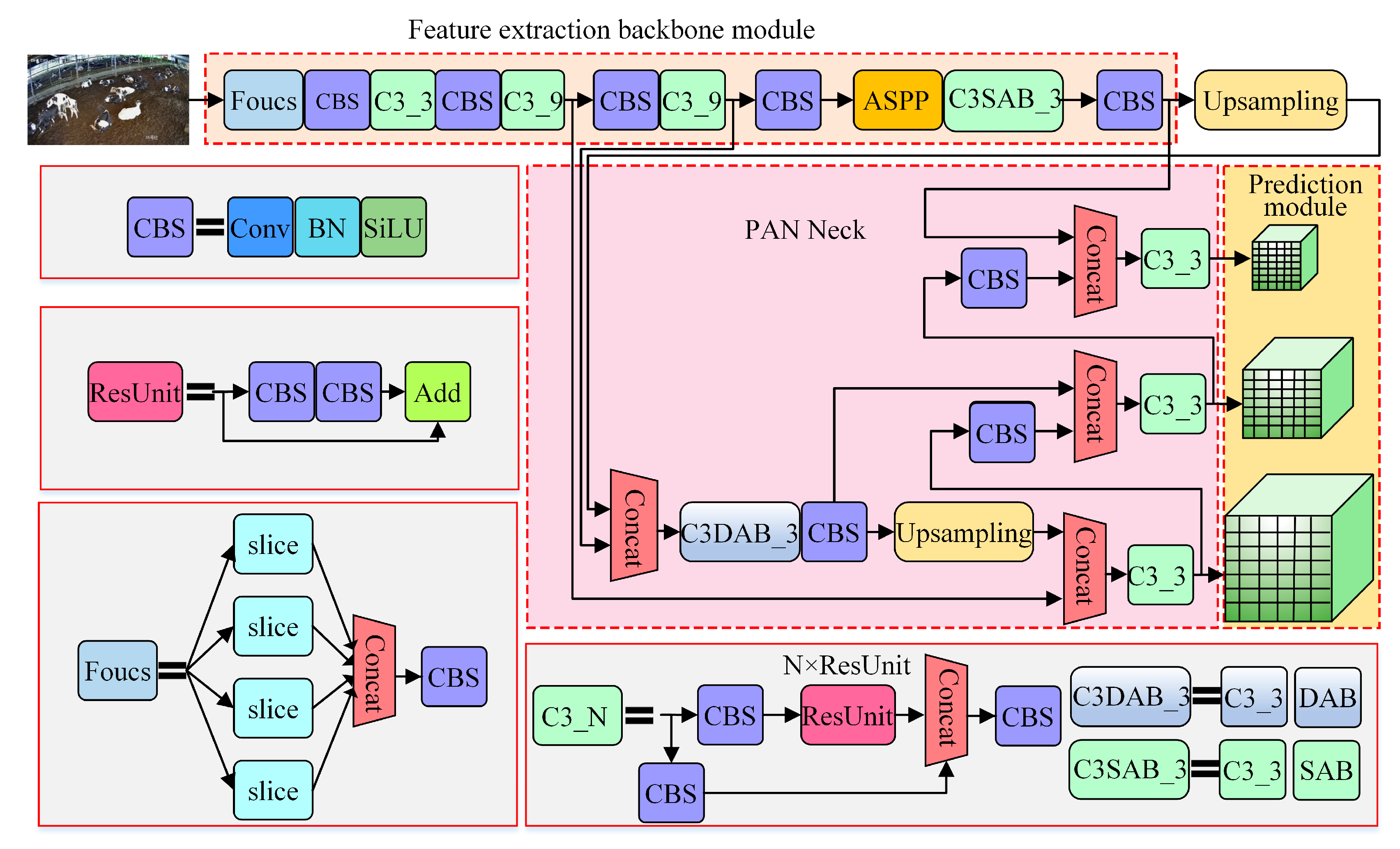
| Layers | Network Layer | Input Size | Step | Number of Channels |
|---|---|---|---|---|
| 1 | Focus | 640 × 640 × 3 | —— | 64 |
| 2 | CBS 3 × 3 | 320 × 320 × 64 | 2 | 128 |
| 3 | C3_3 | 160 × 160 × 128 | —— | 128 |
| 4 | CBS 3 × 3 | 160 × 160 × 128 | 2 | 256 |
| 5 | C3_9 | 80 × 80 × 256 | —— | 256 |
| 6 | CBS 3 × 3 | 80 × 80 × 256 | 2 | 512 |
| 7 | C3_9 | 40 × 40 × 512 | —— | 512 |
| 8 | CBS 3 × 3 | 40 × 40 × 512 | 2 | 1024 |
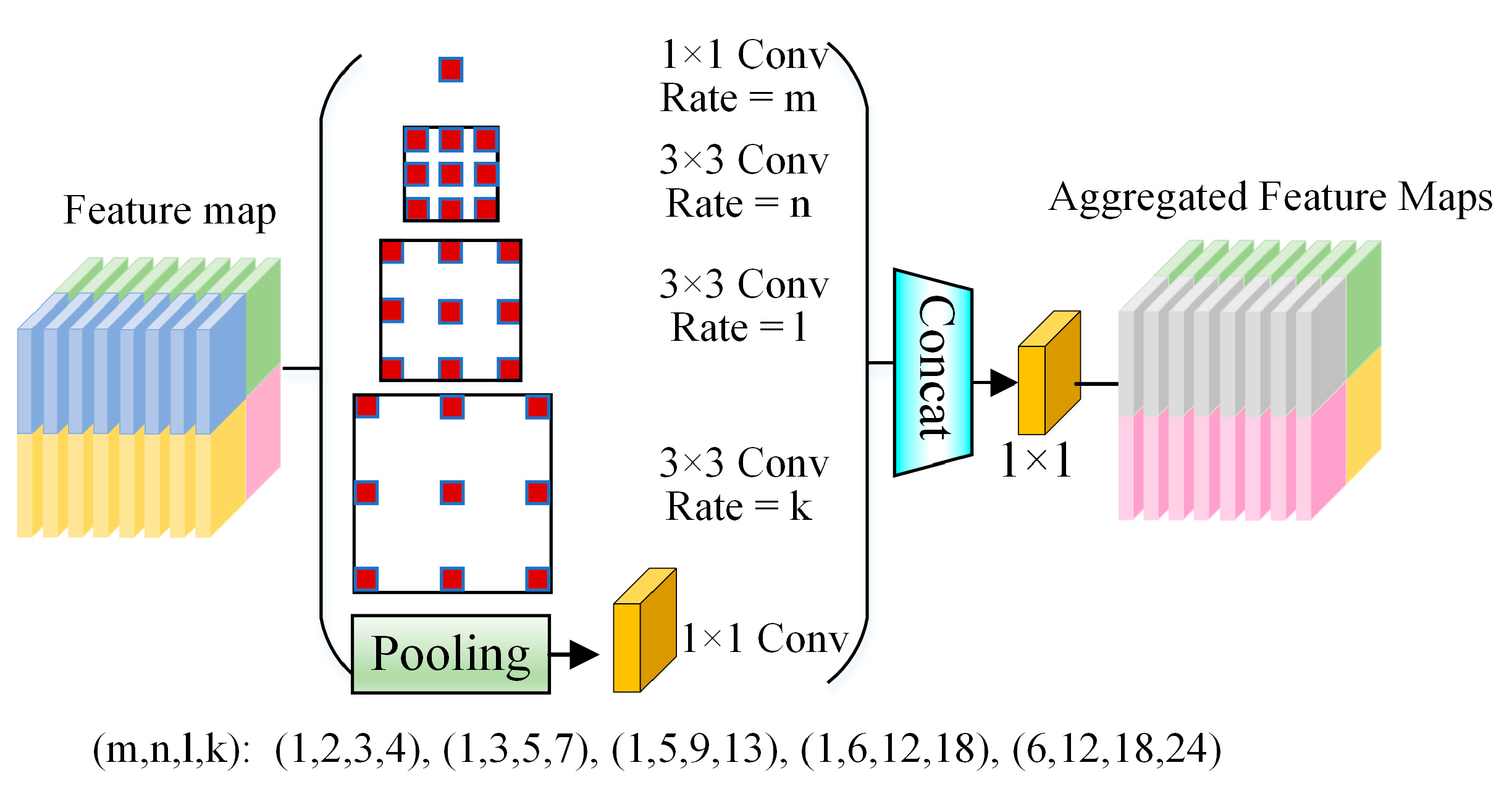
| 9 | ASPP | 20 × 20 × 1024 | —— | 1024 |
| 10 | C3SAB_3 | 20 × 20 × 1024 | —— | 1024 |
| 11 | CBS 1 × 1 | 20 × 20 × 1024 | 1 | 512 |
| 12 | Upsample | 20 × 20 × 512 | —— | —— |
| 13 | Concat | —— | —— | —— |
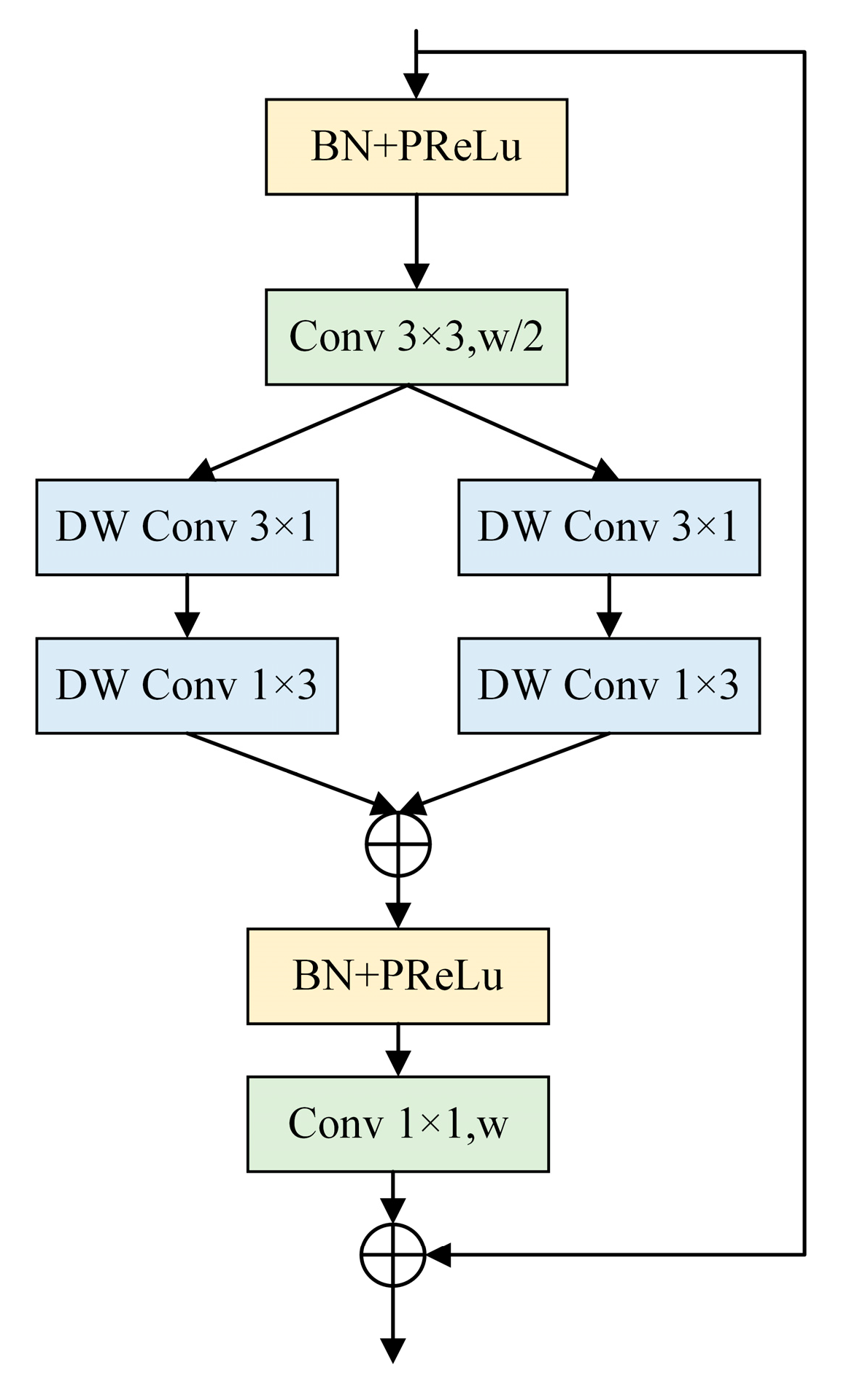
| 14 | C3DAB_3 | 40 × 40 × 512 | 512 | |
| 15 | CBS 1 × 1 | 40 × 40 × 512 | 1 | 256 |
| 16 | Upsample | 40 × 40 × 256 | —— | |
| 17 | Concat | —— | —— | |
| 18 | C3_3 | 80 × 80 × 256 | 256 | |
| 19 | CBS 3 × 3 | 80 × 80 × 256 | 2 | 256 |
| 20 | Concat | —— | —— | —— |
| 21 | C3_3 | 80 × 80 × 512 | —— | 512 |
| 22 | CBS 3 × 3 | 80 × 80 × 512 | 2 | 512 |
| 23 | Concat | —— | —— | —— |
| 24 | C3_3 | 80 × 80 × 512 | —— | 1024 |
| 25 | Detect | —— | —— | —— |
| Model | Precision/% | Recall/% | mAP/% (IoU = 0.5:0.95) | mAP/% (IoU = 0.5) | Speed/ms | Weight/MB | Parameter/M | GFLOPS |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 86.5 | 83.6 | 36.7 | 85.6 | 4.4 | 13.7 | 7.2 | 16.5 |
| YOLOv5m | 91.5 | 81.5 | 42.3 | 86.3 | 7.9 | 40.4 | 21.2 | 49.0 |
| YOLOv5l | 91.9 | 87.7 | 49.6 | 88.4 | 12.9 | 89.3 | 46.5 | 109.1 |
| YOLOv5x | 92.1 | 82.8 | 45.3 | 89.5 | 20 | 166.9 | 86.7 | 205.7 |
| Model | mAP (IoU = 0.5:0.95)/% | mAP (IoU = 0.5)/% | Speed/ms | Weight/MB |
|---|---|---|---|---|
| Faster RCNN | 46.2 | 83.6 | 91.7 | 315.0 |
| YOLOv3 | 36.5 | 83.9 | 14.3 | 117.67 |
| YOLOv5l | 49.6 | 88.4 | 12.9 | 89.3 |
| Ours (CEBD-YOLO) | 51.9 | 94.3 | 14.1 | 154.9 |
| Number | Model | Precision/% | Recall/% | mAP/% (IoU = 0.5:0.95) | mAP/% (IoU = 0.5) | Speed/ms | Weight/MB |
|---|---|---|---|---|---|---|---|
| 1 | YOLOv5l | 91.9 | 87.7 | 49.6 | 88.4 | 12.9 | 89.3 |
| 2 | YOLOv5l + New anchors | 91.2 | 85.3 | 46.8 | 91.2 | 12.8 | 89.4 |
| 3 | YOLOv5l + New anchors + ASPP | 91.4 | 91.7 | 54.9 | 93.4 | 16.5 | 152.4 |
| 4 | YOLOv5l + New anchors + ASPP + C3SAB | 94.4 | 89.0 | 55.2 | 93.8 | 16.3 | 152.4 |
| 5 | CEBD-YOLO (YOLOv5l + New anchors + ASPP + C3SAB + C3DAB) | 97.0 | 89.5 | 51.9 | 94.3 | 14.1 | 154.9 |
| Model | ASPP | Precision/% | Recall/% | mAP/% (IoU = 0.5:0.95) | mAP/% (IoU = 0.5) | Speed /ms | Weight/MB |
|---|---|---|---|---|---|---|---|
| CEBD-YOLO | (1,2,3,4) | 89.6 | 86.5 | 51.8 | 91.5 | 14.1 | 154.9 |
| (1,3,5,7) | 87.2 | 88.6 | 49.7 | 91.9 | 14.0 | 154.9 | |
| (1,5,9,13) | 97.0 | 89.5 | 51.9 | 94.3 | 14.1 | 154.9 | |
| (1,6,12,18) | 89.2 | 90.7 | 53.1 | 92.6 | 14.1 | 154.9 | |
| (6,12,18,24) | 94.2 | 86.4 | 51.8 | 92.6 | 14.8 | 170.9 |
| Model | Precision/% | Recall/% | mAP/% (IoU = 0.5:0.95) | mAP/% (IoU = 0.5) | Speed/ms | Weight/MB |
|---|---|---|---|---|---|---|
| DIoU | 95.2 | 90.1 | 50.3 | 92.5 | 13.9 | 154.9 |
| GIoU | 93.3 | 91.4 | 52.6 | 94.1 | 14.0 | 154.9 |
| Alpha-IoU [30] | 93.3 | 88.2 | 51.3 | 91.4 | 13.9 | 154.9 |
| Ours(CIoU) | 97.0 | 89.5 | 51.9 | 94.3 | 14.1 | 154.9 |
| Studies | Year | Species | Research Contents | Objects | Method | Accuracy |
|---|---|---|---|---|---|---|
| Li et al. [31] | 2021 | goat | Multi-behavior recognition | A dairy goat | AlexNet + ResNet50 + Vgg16 | 85.6% |
| Fuentes et al. [32] | 2020 | cow | Multi-behavior recognition | 27 cows | YOLOv3 + I3D | 85.6% |
| Li et al. [33] | 2019 | pig | Mounting detection | 4 pigs | Mask R-CNN | 91.47% |
| Zhang et al. [34] | 2019 | pig | Mounting detection | 4 pigs | SSD + MobileNet | 92.3% |
| Yang et al. [18] | 2021 | pig | Mounting detection | 4 pigs | Faster R-CNN + XGBoost | 95.15% |
| Guo et al. [35] | 2019 | cow | Mounting detection | 10 cows | Computer vision | 90.9% |
| Fuentes et al. [32] | 2020 | cow | Mounting detection | 27 cows | YOLOv3 + I3D | 82.1% |
| Li et al. [36] | 2022 | cow | Multi-behavior recognition | A cow | MiCT | 91.8% |
| Ours (CEBD-YOLO) | 2022 | cow | Mounting detection | 200 cows | YOLOv5 | 94.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Gao, Z.; Li, Q.; Zhao, C.; Gao, R.; Zhang, H.; Li, S.; Feng, L. Detection Method of Cow Estrus Behavior in Natural Scenes Based on Improved YOLOv5. Agriculture 2022, 12, 1339. https://doi.org/10.3390/agriculture12091339
Wang R, Gao Z, Li Q, Zhao C, Gao R, Zhang H, Li S, Feng L. Detection Method of Cow Estrus Behavior in Natural Scenes Based on Improved YOLOv5. Agriculture. 2022; 12(9):1339. https://doi.org/10.3390/agriculture12091339
Chicago/Turabian StyleWang, Rong, Zongzhi Gao, Qifeng Li, Chunjiang Zhao, Ronghua Gao, Hongming Zhang, Shuqin Li, and Lu Feng. 2022. "Detection Method of Cow Estrus Behavior in Natural Scenes Based on Improved YOLOv5" Agriculture 12, no. 9: 1339. https://doi.org/10.3390/agriculture12091339