1. Introduction
The parametric route of productivity and efficiency analysis using the production frontier framework has come a long way from deterministic frontier analysis using Ordinary Least Squares (OLS) regression [
1] to Corrected Ordinary Least Squares (COLS) regression [
2]. After the Stochastic Frontier Model (SFM) was proposed independently by Aigner et al. [
3] and Meeusen and Van den Broeck [
4], which was a breakthrough and by far the most popular. since then, stochastic frontier models have been applied to analyze technical efficiency [
5,
6,
7], cost efficiency [
8,
9], energy efficiency [
10], trade potential [
11], and total factor productivity [
9,
12,
13] etc. Therefore, the stochastic frontier model has been used extensively, and applied in various fields.
The SFM is essentially a linear regression model with two error components: a two-sided term that captures random variation of the production frontier across firms (i.e., a conventional random error,
) and a one-sided term that measures inefficiency relative to the frontier (i.e., the inefficiency component,
). The key assumption in the SFM is the independence between the inefficiency component and the random error term. Some scholars have relaxed this assumption in SFM by using copula functions. For example, Smith [
14] first proposed an SFM allowing for dependence between the two error components using copula functions, which can be used to capture rank correlation and tail dependence between these two error components, thus lifting the restrictive assumption of independence between the inefficiency component and the random error. Mehdi and Hafner [
15] proposed a bootstrap algorithm to estimate the copula-based SFM. Wiboonpongse et al. [
16] proposed a simulated maximum likelihood method (SMLE), which has numerical and computational advantages over the numerical integration method used by Smith [
14]. Since the structure of the dependence of the two error components is unknown, Wiboonpongse et al. [
16] systematically considered a number of copula families, such as Student-t, Clayton, Gumbel and Joe families, including their relevant rotated versions, to select the best fit model based on established and well-known AIC and BIC criteria. Bonanno et al. [
17] further considered asymmetry of random error as the basis of dependent error components. Similarly, Amsler et al. [
18] applied copula to measure time dependence in stochastic frontier model, and Lai and Kumbhakar [
19] measured the dependence between the time-varying and time-invariant components. Wei et al. [
20] constructed an asymmetric dependence in the stochastic frontier model using skew normal copula.
Based on the above literature, we see that the copula-based SFM has been widely applied and extended. However, the consequences of the assumption of independence of error components remain unclear. It is also not clear if when the inefficiency effect (i.e., heterogeneity) is absent in the copula-based SFM, the parameter and efficiency estimates remain correct. In addition, which limitation is more serious, the assumption of independence of error components or missing heterogeneity? Therefore, the main motivation of this paper is to clarify the consequence of missing inefficiency effects and/or ignoring dependency in error components in the copula-based SFM. The contribution of this study are three-fold. First, we adopt the approach proposed by Wiboonpongse et al. [
16] and Sriboochitta [
21] and extend it further by developing a model to jointly estimate the copula-based SFM along with heterogeneity in a single stage, as done by Battese and Coelli [
22] for the conventional SFM, which is a new contribution to the existing literature on productivity and efficiency analysis. In addition, the consequences arising from the independence assumption of error components and the lack of heterogeneity are fully revealed and interpreted, respectively. Then, we apply this framework to a sample of 300 rice farmers from northern Thailand and demonstrate relative merit of the copula based SFM as compared to the conventional SFM with respect to estimation efficiency of the parameters of the production frontier and the inefficiency effects functions, estimates of the mean technical efficiency scores, distribution of the technical efficiency scores and shift in the relative ranking of the individual farmers between the two models.
The rest of the paper is organized as follows.
Section 2 introduces the family of copula functions considered in this study to select the best fit model.
Section 3 presents the structure of the copula-based stochastic frontier model.
Section 4 presents the empirical results.
Section 5 concludes and draws policy implications.
3. Simulation Study
Is the simulated maximum likelihood estimation suitable for the copula-based stochastic frontier model with heterogeneity? What are consequences of ignoring dependent error components and/or heterogeneity in stochastic frontier model? To answer these questions, we performed a simulation experiment. Following the simulation experiments of Wei et al. [
44], Liu et al. [
45] and Zhu et al. [
46], we randomly drew datasets from a copula-based stochastic frontier model with heterogeneity. The simulated process of this experiment can be illustrated as follows:
First, we set up the equation, , , where vi is standard normal distributed. is N(0.7zi, 1) truncated on the left at zero. The Kendall’s tau between two error components is assumed to be 0.6. The variables, x and z, are simulated from standard normal distribution, respectively. To check the impact of sample size on estimation, the sample size was set at 500, 1000 and 2000, respectively.
Second, we randomly drew numbers using Clayton copula corresponding to , and obtained v and w by using the inverse functions. Thus, we could obtain y from the equation .
Third, we fixed R = 200 and maximized the simulated log-likelihood using the BFGS algorithm in the R statistical software for six models: the traditional SFM or copula-based SFM with the assumption of independence in error components (Model 1), the traditional SFM with heterogeneity or independent copula-based SFM with heterogeneity (Model 2), the Gaussian copula-based SFM with mis-specified dependent error components (Model 3), the Gaussian copula-based SFM with heterogeneity and mis-specified dependent error components (Model 4), the Clayton copula-based SFM (Model 5), and the Clayton copula-based SFM with heterogeneity and dependent error components (Model 6). Therefore, Model 1 ignores dependency of error components and heterogeneity. Thus, from the estimation of Model 1, we can see the impact of the traditional assumption of independent error components and homogeneity on parameter estimation. Model 2 is the traditional stochastic frontier with heterogeneity. Thus, the influence of assuming independent error components along with heterogeneity on parameter estimation can be found. We specify a wrong dependency structure between error components in Model 3 and Model 4. Then the simulation result can demonstrate that the consequence of the wrong specification of dependency structure. In Model 5, we correctly set the dependent error components but ignore heterogeneity. Therefore, the simulation results of the Model 5 can reflect the consequences of ignoring dependency in error components only. Finally, the simulation results of the Model 6 can demonstrate whether the proposed model is unbiased and robust.
Last, we randomly generated 100 datasets from Model 6 and estimated the parameters of Models 1–6. We then computed percent bias of the estimates and TE scores in all five models. On this basis, we also drew 100 datasets from Model 1, and used Model 6 to fit these datasets (opposite data) without heterogeneity and dependence. This simulation experiment can further illustrate whether the proposed model is more general.
Table 1 shows percent bias of Models 1–6. Model 6 is the best fit. The percentage of bias in estimates on average is the smallest of all the six models, and most of the estimates are the smallest as well, except
β1. However, the percent bias of parameter
β1 is tiny, and is less than 0.5% in all different sample sizes. These results imply that the proposed model, i.e., the copula-based SFM with dependent error components and heterogeneity, is rational and unbiased. Second, the performance of Model 5 is only inferior to that of model 6, and Model 1 is the worst in terms of percent bias on average. On the one hand, it shows that the assumption of independence of error components and ignoring heterogeneity lead to biased parameter estimation. On the other hand, it can be seen that the bias caused by independent error components is very large, while the bias caused by ignoring heterogeneity is relatively small, i.e., comparing Models 1–3. Third, we see that all parameters of Model 1 and Model 2 are underestimated, except for
β1. Fourth, neither the assumption of independence nor the neglect of heterogeneity can cause
β1 to be underestimated or overestimated. Fifth, the underestimation of
σw is the most serious among all the parameters. In Model 1, the percent bias of
σw is more than 90%, and it is also more than 85% in Model 2. The underestimation of
σw can give rise to overestimation of technical efficiency scores. Furthermore, all parameters in Model 3 and Model 4 are highly biased except
β1, which implies the mis-specification of dependency structure can also generate serious consequence. Even if Model 4 includes heterogeneity of inefficiency, most of the estimates are still biased. P
AIC is the proportion of the model selection attained using AIC. It always selects Model 6 as expected. All values in the last column are quite small, which verifies that the proposed model is unbiased even if the data is independent and homogenous. This is also consistent with the fact that the proposed model nests the traditional stochastic frontier model. Finally, we can find that the sample size of 500 is large enough because increasing sample size does not improve measures of unbiasedness.
Figure 1 displays histograms of TE scores for Models 1–6 and True parameters. In the 100 datasets, we randomly select a set of data sets with a sample size of 1000 to estimate technical efficiency. The TE scores of Model 6 are the closest to the true TE in terms of the shape of the histogram and the range of TE scores. The TE scores of Model 1 are above 0.99, which represent the biggest difference from the true TE. The TE scores of Models 2–5 are also much different from the true scores, and overestimate TE scores at some points. The TE scores of Model 1 and Model 3 are more biased than Model 2 and Model 4. Therefore, independence assumption or mis-specified dependency structure of error components has much bigger impact on TE scores than ignoring heterogeneity.
Figure 2 shows differences between the estimated TE scores of Model 6 and True TE under the data generating process of traditional SFM. It is obvious that the estimated TE scores of Model 6 are quite similar to the True TE.
Through the above simulation experiments, we can draw the following conclusions: (1) the lack of heterogeneity and the independence assumption of error components can lead to biased estimates of parameters and technical efficiency, and the independence assumption will lead to greater biased estimates; (2) the estimation of copula-based SFM with dependent error components and heterogeneity is unbiased and robust; (3) once the error components are correlated and inefficiency is heterogeneous at the mean, the traditional SFM can cause great deviation in parameter estimates and technical efficiency scores; (4) once the error components are correlated, the SFM with heterogeneity also cause deviation in parameter estimates and technical efficiency scores; (5) the proposed model has good performance even if the data do not have dependent error components and heterogeneity.
4. Application to Rice Producers
We now know from the simulation results that our proposed model is general and flexible, and it nests other specification of SFMs. Therefore, we used the copula-based stochastic frontier with dependent error components and heterogeneity and the traditional stochastic frontier model with heterogeneity (i.e., the inefficiency effects stochastic frontier model of Battese and Coelli [
22]) in this empirical application. It is noteworthy that more copula families were applied in the case. A total of 300 rice farmers from the Kamphaeng Phet province of Thailand constituted the sample of the study. The Kamphaeng Phet province is one of the most important rice production areas in the north of Thailand. The total rice area of the province is estimated at 1,436,934 rai (i.e., 290,909 ha), which represents 3% of total rice area of Thailand. The Ping river and the Bhumibol dam on the Ping river provide convenient condition for planting rice in this province. A random sampling procedure was employed to select the rice farmers. Details of output and input data were collected from these rice farmers using face to face interviews using graduate-level research students of the Chiang Mai University, Chiang Mai, Thailand. The data were collected during the crop year of 2012.
4.1. The Empirical Model
The empirical model is specified with a restricted Translog stochastic production frontier function:
and
where
Yi is the wheat output (including grain equivalent of straw output);
Xij is
jth input for the
ith farmer;
Rim is the dummy variable for farms located in the plain land and farms located in slopes,
vi is the two sided random error,
wi is the one sided half-normal error, ln is the natural logarithm,
Zid variables representing socio-economic characteristics of the farm to explain inefficiency,
ei is the truncated random variable;
α0,
αj,
βj,
δ0,
φk and
δd are the parameters to be estimated. In order to interpret the first order coefficients,
αj, directly as elasticities, all ln
Xs variables in Equation (18) are mean-corrected (i.e.,
).
A total of five production inputs (X) and two regional dummies (R) were used in the production function, and four variables representing socio-economic characteristics of the farmer (Z) were included in the inefficiency effects model as predictors of technical inefficiency. The production inputs are land (rai), labour (person days), material inputs (which includes inorganic fertilizers, pesticides, and seeds) (baht), mechanical power (baht), and irrigation (baht), and the factors explaining farmers technical inefficiencies are experience (number of years growing rice), family size (number of persons per household), education (completed year of schooling) and the share of hired labour used in growing rice (proportion of total labour).
4.2. Empirical Results
A total of nine copulas from six families were considered to identify the best fit model. These were Gaussian copula, T copula, Frank copula, rotated Clayton copula (90°), rotated Clayton copula (270°), rotated Gumbel copula (90°), rotated Gumbel copula (270°), rotated Joe copula (90°) and rotated Joe copula (270°). The Gaussian copula was estimated first to obtain initial values and determine the sign of the correlation between v and w. If it was negative, the rotated copulas (90°) and (270°) were used instead.
We now turn to the empirical results of this study.
Table 2 presents the AIC and BIC for each copula-based SFM with dependent error components and heterogeneity. The traditional SFM with heterogeneity can be regarded as independent copula-based model, whereas other copula-based models nest the traditional SFM with heterogeneity. According to both criteria, the best model is the one based on the rotated Clayton 90° copula (R-Clayton 90 °C). This result confirms the need to relax the assumption of independence between the inefficiency and random error components of the SFM. According to the feature of R-Clayton 90 °C, there exists a negative dependence between
w and
v, which has a negative tail dependence. When w is small, technical efficiency score is high and the random error is large. This phenomenon implies that some points have high technical efficiency and are much higher than the regression line. In addition, the likelihood ratio (LR) test was used to test the null hypothesis of independence between v and w, against the alternative hypothesis of a dependence structure characterized by each of the copula families. The LR test statistic has approximately a chi-squared distribution with degrees of freedom equal to the difference of the number of parameters of the conventional SFM with heterogeneity and the relevant copula-based SFM with dependent error components and heterogeneity. The results are presented in the last column of
Table 2, which confirm that the null hypothesis of independence of error components is strongly rejected in all the models at 5% level of significance at least. More importantly, we compare the best model, R-Clayton 90 °C, with a model that has no explanatory variables in the inefficiency term by using LR test. The LR statistics is −2 × (318.5683 − 336.0464) = 34.9563, which is statistically significant at the 1% level. Thus, the R-Clayton 90 °C with covariates in the inefficiency term has better performance in this study.
Table 3 presents the parameter estimates of the chosen copula-based R-Clayton 90° SFM with dependent error components and heterogeneity and the conventional SFM with independent error components and heterogeneity jointly in a single stage using simulated MLE. It is clear from
Table 3 that the estimation efficiency is better for the copula-based model with dependent error components and heterogeneity where a higher proportion of the coefficients on the variables is significantly different from zero compared to the conventional SFM with heterogeneity. For example, in the R-Clayton 90° SFM with a dependent error component and heterogeneity, 15 coefficients on the input variables were significantly different from zero at the 5% level compared to only 10 coefficients on the input variables significantly different from zero at 10% level, at least in the conventional SFM with heterogeneity.
The results of the model diagnostics presented in the lower panel of
Table 3 further confirm the dependence structure of the error components. The estimated correlation coefficients between the inefficiency component and the random error were found to be significantly negatively correlated, i.e., both Kendall’s tau and Spearman’s rho are estimated at −0.22 (
p < 0.05) and −0.33 (
p < 0.01), respectively. Wiboonpongse et al. [
16] reported significantly positive correlation of Kendall’s tau and Spearman’s rho coefficients, implying that the nature of dependence is not universal and vary from case to case. The parameter γ, which measures the relative importance of the technical inefficiency term, is close to one (0.99), thereby confirming that a significant level of inefficiency is present in the data.
Since we have subtracted the means of the variables (i.e.,
), the coefficients of the first order terms can be directly read as production elasticities [
6]. The results of the R-Clayton 900 SFM with dependent error components and heterogeneity reveal that land, material inputs and labour are the significant drivers of rice productivity, whereas in the conventional SFM with heterogeneity, only land seems to be the significant driver of rice productivity, thereby providing a misleading conclusion. Land, material inputs and labour are normally the most important drivers of productivity of rice production [
47,
48].
4.3. Technical Efficiency Distribution
The distribution of technical efficiency scores and the summary statistics are presented in
Table 4 for the conventional SFM with heterogeneity and R-Clayton 90° SFM with dependent error components and heterogeneity. It is clear from
Table 4 that the conventional SFM with heterogeneity overestimates technical efficiency levels, and there are differences in the distribution of individual farmers within individual technical efficiency intervals in this case. The mean technical efficiency score from the copula-based model is significantly lower by two points (
p < 0.01). In the copula-based SFM with dependent error components and heterogeneity, 29.3% of the farmers are operating at efficiency level of 91% or above, whereas the corresponding figure is 42.3% in the conventional SFM with heterogeneity.
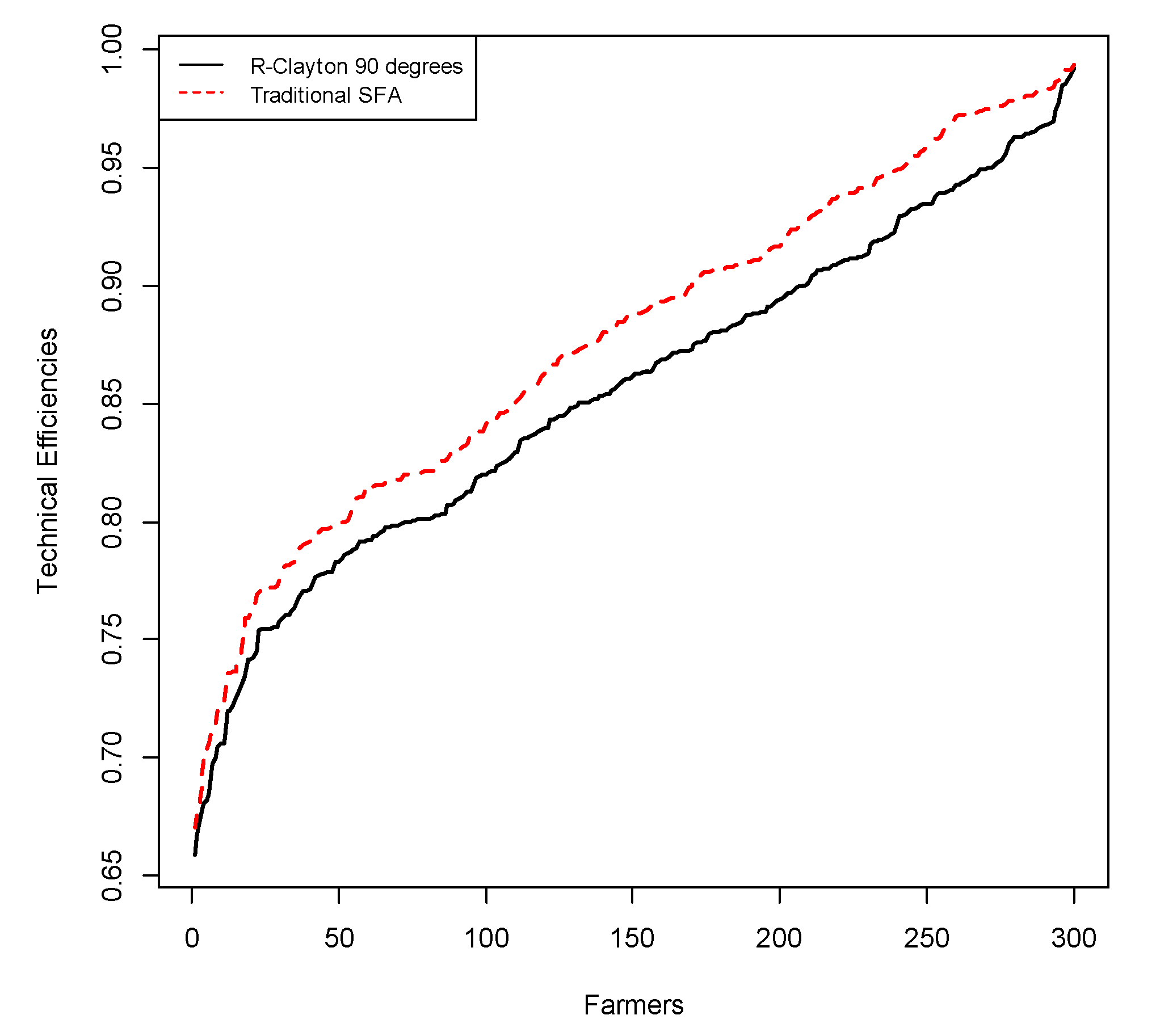
Figure 3 presents the cumulative distribution of the technical efficiency scores of the conventional SFM with heterogeneity and copula-based SFM with dependent error components and heterogeneity, which shows large differences as well.
Table 5 presents the shifts in the relative ranks of the top five and bottom five farmers with respect to technical efficiency scores between the conventional SFM with heterogeneity and the copula-based SFM with dependent error components and heterogeneity, thereby, confirming the trends shown in
Figure 3.
Figure 4 shows the differences of technical efficiency scores between the copula-based SFM with dependent error components and heterogeneity and the conventional SFM with heterogeneity. We can see that the technical efficiency scores are mostly overestimated as compared to the conventional SFM with heterogeneity. Finally,
Table 6 shows that the maximum level of difference in efficiency score is five points and the minimum level of difference is two points between the conventional SFM with heterogeneity and copula-based SFM with dependent error components and heterogeneity, respectively.
4.4. Determinants of Technical Efficiency
The mid-panel of
Table 3 presents the results of the inefficiency effects function. Once again, the determinants of technical inefficiency of the copula-based SFM with dependent error components and heterogeneity are different from the traditional SFM with heterogeneity. For example, coefficients on the three of the four socio-economic factors used to explain observed farm specific inefficiency were significantly different from zero at the 1% level at least in the copula-based SFM with dependent error components and heterogeneity, whereas only one variable (i.e., the share of hired labour) was found to be significantly different from zero at the 1% level in the conventional SFM with heterogeneity. Results from the copula-based SFM with dependent error components and heterogeneity reveal that experienced farmers (i.e., older farmers), dependency pressure (larger family size) and the use of hired labour are significantly associated with technical inefficiency, while education has no influence. These results are not unexpected and conform to the literature. For example, Coelli et al. [
49] noted that dependency pressure as well as farmers’ experience is negatively associated with technical efficiency in modern rice cultivation in Bangladesh. Similarly, Rahman and Rahman [
48] noted that the share of family supplied labour is technically efficient in rice farming in Bangladesh, implying that the use of hired labour is relatively inefficient.
5. Conclusions and Discussion
This study reveals the consequences of assuming independence of error components and ignoring heterogeneity of inefficiency in copula-based SFMs, proposes a copula-based stochastic frontier model with dependent error components and heterogeneity, and empirically applies this to a sample of rice producers from northern Thailand.
The traditional SFM assumes independent error components and does not include heterogeneity (inefficiency effects). Ignoring dependent error components and heterogeneity in the traditional stochastic frontier model lead to the underestimation of model parameters and serious overestimation of technical efficiency. The stochastic frontier model with heterogeneity, namely, the inefficiency frontier model, still assumes independent error components. This assumption also underestimates parameters and produces biased TE scores. In the copula-based stochastic frontier model with dependent error components only (i.e., [
14,
16]), parameter estimation and TE scores are still biased to some extent due to lack of heterogeneity (inefficiency effects). Therefore, we can conclude that if error components are correlated and heterogeneity exist in the data, the copula-based stochastic frontier with dependent error components and heterogeneity is the best choice. The copula-based stochastic frontier with dependent error components and heterogeneity nests other three models. Therefore, the model proposed in this paper is very flexible.
The empirical case study results also raise the question of reliability of the results obtained from the conventional SFM with heterogeneity. Therefore, for reliable and robust interpretation of results, one may need to test the assumption of independence of the error components, and undertake appropriate measures since violation of this restrictive assumption leads to biased efficiency scores and identification of fewer actual predictors of productivity and efficiency of the firms under investigation, thereby leading to biased and/or misleading conclusions. To sum up, the copula-based models with dependent error components and heterogeneity are more general than the standard SFM model, so we can test validity of the assumption of the independence of the inefficiency component and avoid bias that could arise in the estimated results. The empirical application of our proposed model proves that although the overall underlying production structure of rice farmers are not fundamentally different from what can be discerned from the traditional SFM with independent error components and heterogeneity, our results are more accurate, unbiased and robust with respect to identification of significant production drivers and heterogeneity (i.e., inefficiency effects variables), TE estimates and distribution of TE scores across individual farmers.
Based on our empirical findings, we propose the following policy suggestions for the Thai government and rice farmers. (1) The Thai government should attempt to narrow differences in technical efficiency among rice farmers. This can be achieved by promoting advanced planting technology and technical training to rice farming population. (2) Government should invest in promoting use of agricultural machinery which could replace part of the labor force used in rice farming. Mechanization of agricultural production cannot only improve production efficiency but can also save labor.
Although the proposed model is general and flexible, there are still some questions that need to be explored. One is to investigate the asymmetric effects of independent variables and covariate variables. The asymmetry of datasets may have an impact on estimation. The other area of investigation is to understand how the proposed model effects TFP estimation and its subsequent decomposition into finer components.









{kind=link}
{kind=link}
{kind=link}
{kind=link}