
Transformer Help CNN See Better: A Lightweight Hybrid Apple Disease Identification Model Based on Transformers

Abstract
:1. Introduction
- (1)
- We propose using the Transformer structure to solve the problem that the complex background of apple disease images and the slight contrast between the disease area and the background in apple disease recognition using CNN can easily cause confusion and affect the identification effect. Vision Transformer, based on the self-attention mechanism, can guide the CNN structure to focus on the effective features for identification results and make the CNN see better.
- (2)
- We adopt lightweight designs and improve the patch embedding method of Transformer. The depthwise separable convolution reduces the computational complexity of the convolution structure, and the Global Average Pooling reduces the computational complexity of the Transformer structure to linear complexity before performing the attention operation. The improved overlapping patch embedding approach promotes the information exchange between adjacent patches, preserves the information of image edges, and ensures the continuity of image local information.
- (3)
- An effective, lightweight apple disease-identification model is proposed. ConvViT fully combines the advantages of CNN and Transformer and obtains competitive results on the self-built apple disease dataset with much lower parameters and computational effort than other similar identification effect models.
2. Materials and Methods
2.1. Apple Leaf Disease Dataset
2.2. Methods
2.2.1. Model Overview
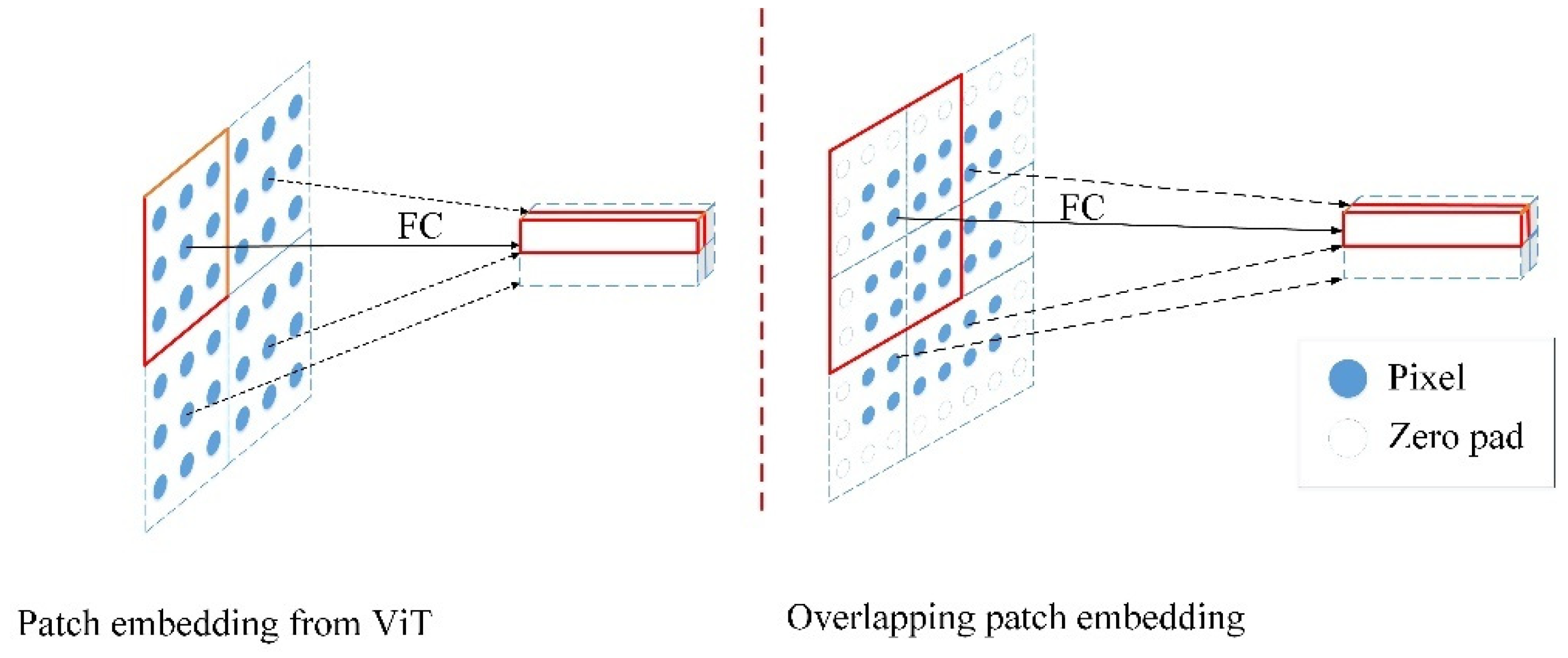
2.2.2. Overlapping Patch Embedding
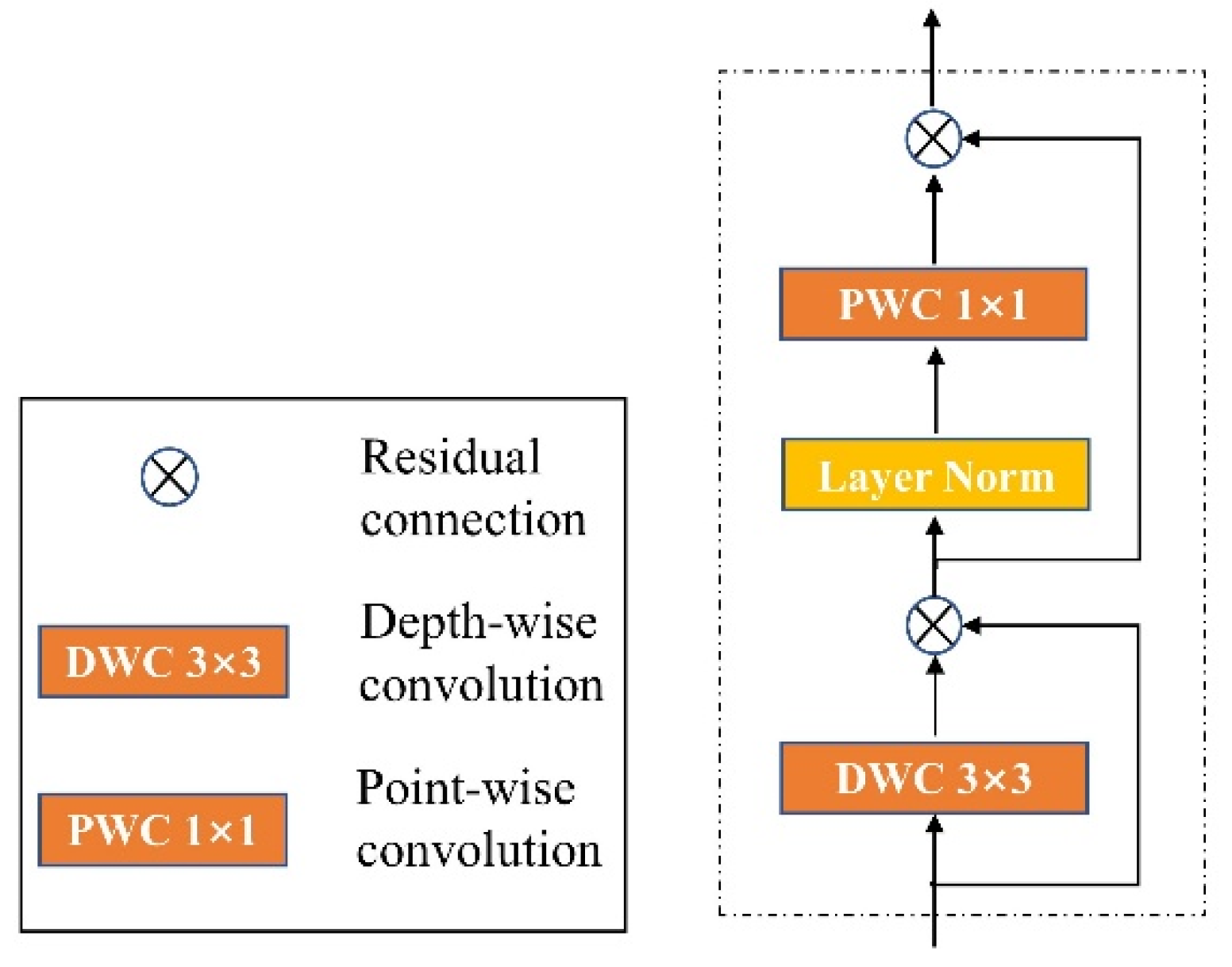
2.2.3. The Design of Convolution Structure
2.2.4. The Design of Transformer Structure
2.3. Evaluation Indicators and Experimental Environment
2.3.1. Evaluation Indicators
2.3.2. Experimental Parameters Settings
3. Results
3.1. Comparisons with State-of-the-Art Methods
3.2. Analysis of Model Performance on Each Apple Disease Category
3.3. Is the Combination of Convolution Structure and Transformer Structure Reasonable?
3.4. Is the Overlapping Patch Embedding Valid?
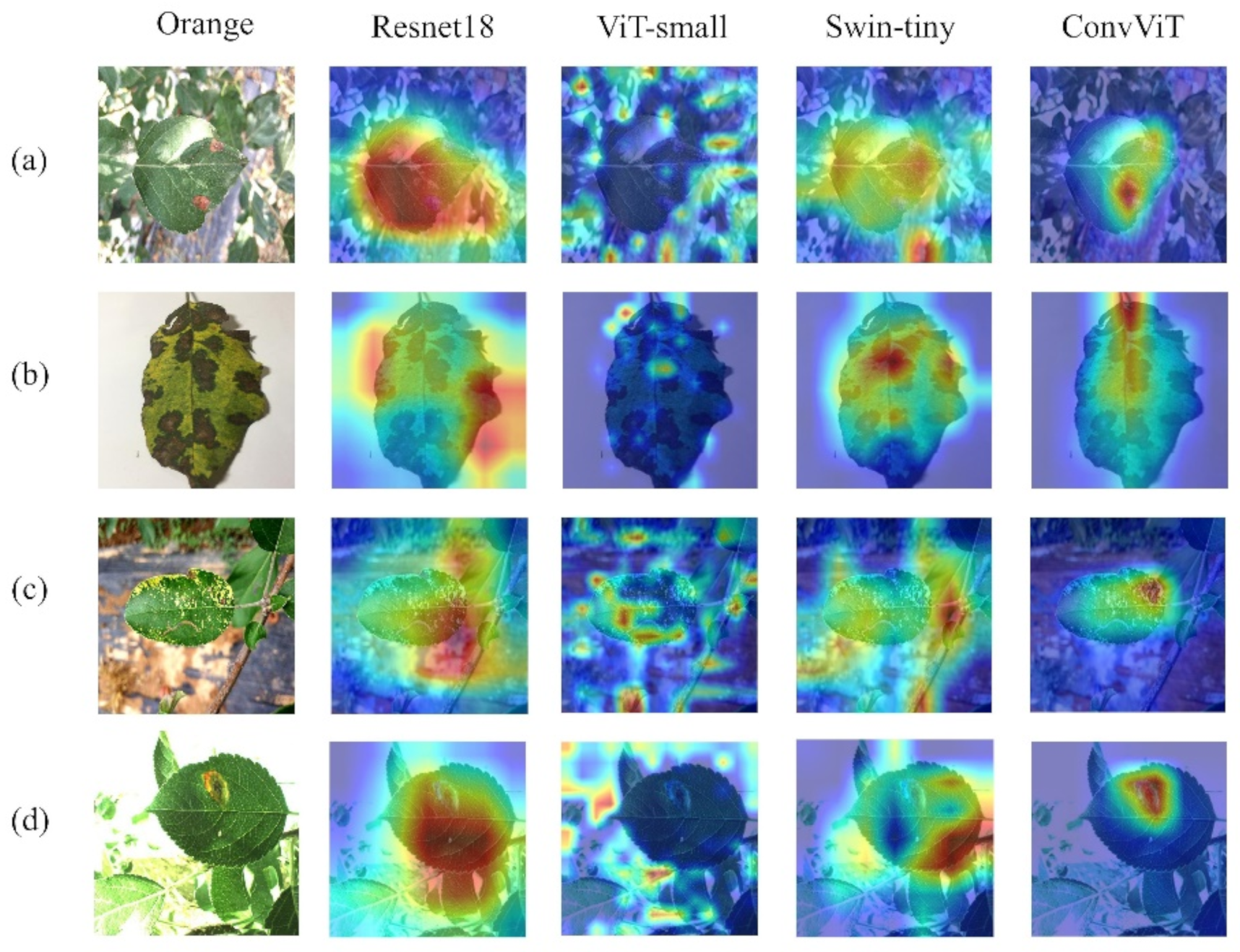
3.5. Visualization of Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| ViT | Vision Transformer |
| FLOPs | Floating Point Operations |
References
- Huo, X.; Liu, T.; Liu, J.; Wei, Y.; Yao, X.; Ma, X.; Lu, F. 2020 China Apple Industry Development Report (Simplified Version). Chin. Fruit 2022, 42, 1–6. [Google Scholar]
- Wang, N.; Ning, F.; Lu, S. Research on identification method of apple leaf diseases based on support vector machine. Shandong Agric. 2015, 141, 122–125. [Google Scholar]
- Li, C.; Pang, J.; Zhang, S. Apple leaf disease identification method based on feature fusion and local discriminant mapping. Guangdong Agric. Sci. 2016, 43, 134–139. [Google Scholar]
- Shi, Y.; Huang, W.; Zhang, S. Apple disease recognition based on two-dimensionality subspace learning. Comput. Eng. Appl. 2017, 53, 180–184. [Google Scholar]
- Liu, B.; Zhang, Y.; He, D.; Li, Y. Identification of apple leaf diseases based on deep convolutional neural networks. Symmetry 2017, 10, 11. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Zhang, Q.; Li, P. Apple disease recognition based on improved deep convolution neural network. J. For. Eng. 2019, 4, 107–112. [Google Scholar]
- Chao, X.; Sun, G.; Zhao, H.; Li, M.; He, D. Identification of apple tree leaf diseases based on deep learning models. Symmetry 2020, 12, 1065. [Google Scholar] [CrossRef]
- Zeng, W.; Li, M. Crop leaf disease recognition based on Self-Attention convolutional neural network. Comput. Electron. Agric. 2020, 172, 105341. [Google Scholar] [CrossRef]
- Wang, P.; Niu, T.; Mao, Y.; Zhang, Z.; Liu, B.; He, D. Identification of Apple Leaf Diseases by Improved Deep Convolutional Neural Networks With an Attention Mechanism. Front. Plant Sci. 2021, 12, 723294. [Google Scholar] [CrossRef]
- Bi, C.; Wang, J.; Duan, Y.; Fu, B.; Kang, J.R.; Shi, Y. MobileNet based apple leaf diseases identification. Mob. Netw. Appl. 2022, 27, 172–180. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F.E.H.; Feng, J.; Yan, S. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 558–567. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. PVT v2: Improved baselines with Pyramid Vision Transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Adam, H. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, CA, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Elvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Zhang, S.; Zhang, S.; Zhang, C.; Wang, X.; Shi, Y. Cucumber leaf disease identification with global pooling dilated convolutional neural network. Comput. Electron. Agric. 2019, 162, 422–430. [Google Scholar] [CrossRef]
- Zhang, P.; Yang, L.; Li, D. EfficientNet-B4-Ranger: A novel method for greenhouse cucumber disease recognition under natural complex environment. Comput. Electron. Agric. 2020, 176, 105652. [Google Scholar] [CrossRef]
- Gao, R.; Wang, R.; Feng, L.; Li, Q.; Wu, H. Dual-branch, efficient, channel attention-based crop disease identification. Comput. Electron. Agric. 2021, 190, 106410. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, H.; Guo, W.; Han, X.; Chen, C.; Wu, H. EFDet: An efficient detection method for cucumber disease under natural complex environments. Comput. Electron. Agric. 2021, 189, 106378. [Google Scholar] [CrossRef]
- Zhang, J.; Karkee, M.; Zhang, Q.; Zhang, X.; Yaqoob, M.; Fu, L.; Wang, S. Multi-class object detection using faster R-CNN and estimation of shaking locations for automated shake-and-catch apple harvesting. Comput. Electron. Agric. 2020, 173, 105384. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Xu, Z.; Jia, R.; Sun, H.; Liu, Q.; Cui, Z. Light-YOLOv3: Fast method for detecting green mangoes in complex scenes using picking robots. Appl. Intell. 2020, 50, 4670–4687. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yamaguchi, Y. An attribution-based pruning method for real-time mango detection with YOLO network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Zhang, S.; You, Z.; Wu, X. Plant disease leaf image segmentation based on superpixel clustering and EM algorithm. Neural Comput. Appl. 2019, 31, 1225–1232. [Google Scholar] [CrossRef]
- Xiong, Y.; Liang, L.; Wang, L.; She, J.; Wu, M. Identification of cash crop diseases using automatic image segmentation algorithm and deep learning with expanded dataset. Comput. Electron. Agric. 2020, 177, 105712. [Google Scholar] [CrossRef]
- Karlekar, A.; Seal, A. SoyNet: Soybean leaf diseases classification. Comput. Electron. Agric. 2020, 172, 105342. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease | Number of Images |
|---|---|
| Alternaria leaf spot | 3211 |
| Brown spot | 3393 |
| Gray spot | 2886 |
| Mosaic | 2925 |
| Rust | 3419 |
| Total | 15,834 |
| Stage | Operator | Input Channel | Output Channel | Kernel Size | Stride |
|---|---|---|---|---|---|
| Patch embedding | Overlapping | 3 | 3 | 3 | 2 |
| Stage1 | 3 | 3 | 3 | 1 | |
| Downsample | 3 | 6 | 3 | 2 | |
| Stage2 | 6 | 6 | 3 | 2 | |
| Downsample | 6 | 12 | 3 | 2 | |
| Stage3 | 12 | 12 | 3 | 1 | |
| 12 | 12 | ||||
| Downsample | 12 | 24 | 3 | 2 | |
| Stage4 | 24 | 24 | 3 | 1 | |
| 24 | 24 | ||||
| Feature Fusion | Avg pooling | 48 | 48 | 7 | 1 |
| Model | Accuracy | Params | FLOPs | Recall | Precision | F1 Score |
|---|---|---|---|---|---|---|
| Vgg16 | 96.13% | 138 M | 15.5 G | 96.2% | 96.19% | 96.20% |
| Resnet18 | 95.19% | 11.5 M | 1.71 G | 95.19% | 95.27% | 95.23% |
| MobilenetV3 | 87.42% | 5.4 M | 0.22 G | 87.11% | 87.27% | 87.19% |
| Efficientnet-b0 | 90.44% | 5.3 M | 0.41 G | 90.19% | 90.23% | 90.21% |
| ViT-small | 96.51% | 22 M | 4.24 G | 96.27% | 96.35% | 96.31% |
| DeiT-small | 95.56% | 5.0 M | 1.3 G | 95.66% | 95.65% | 95.66% |
| Swin-tiny | 96.94% | 29 M | 4.5 G | 95.19% | 95.27% | 95.23% |
| ConvViT (ours) | 96.85% | 9.5 M | 0.98 G | 95.19% | 95.21% | 95.19% |
| Model | Block Num | Stage 1 | Stage 2 | Stage 3 | Stage 4 |
|---|---|---|---|---|---|
| ConvViT1 | Conv | 2 | 2 | 6 | 1 |
| Trans | 1 | ||||
| ConvViT2 | Conv | 2 | 2 | 6 | 2 |
| Trans | |||||
| ConvViT | Conv | 2 | 2 | 2 | 1 |
| Trans | 4 | 1 | |||
| ConvViT4 | Conv | 2 | 2 | ||
| Trans | 6 | 2 |
| Model | Accuracy | Params | FLOPs |
|---|---|---|---|
| ConvViT1 | 85.99% | 11.6 M | 1.56 G |
| ConvViT2 | 75.73% | 12.6 M | 1.7 G |
| ConvViT | 96.85% | 9.5 M | 0.98 G |
| ConvViT4 | 80.56% | 7.2 M | 0.73 G |
| Model | Identification Accuracy |
|---|---|
| ConvViT | 95.36% |
| ConvViT+ | 96.85% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Li, S. Transformer Help CNN See Better: A Lightweight Hybrid Apple Disease Identification Model Based on Transformers. Agriculture 2022, 12, 884. https://doi.org/10.3390/agriculture12060884
Li X, Li S. Transformer Help CNN See Better: A Lightweight Hybrid Apple Disease Identification Model Based on Transformers. Agriculture. 2022; 12(6):884. https://doi.org/10.3390/agriculture12060884
Chicago/Turabian StyleLi, Xiaopeng, and Shuqin Li. 2022. "Transformer Help CNN See Better: A Lightweight Hybrid Apple Disease Identification Model Based on Transformers" Agriculture 12, no. 6: 884. https://doi.org/10.3390/agriculture12060884