
A 1D-SP-Net to Determine Early Drought Stress Status of Tomato (Solanum lycopersicum) with Imbalanced Vis/NIR Spectroscopy Data

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
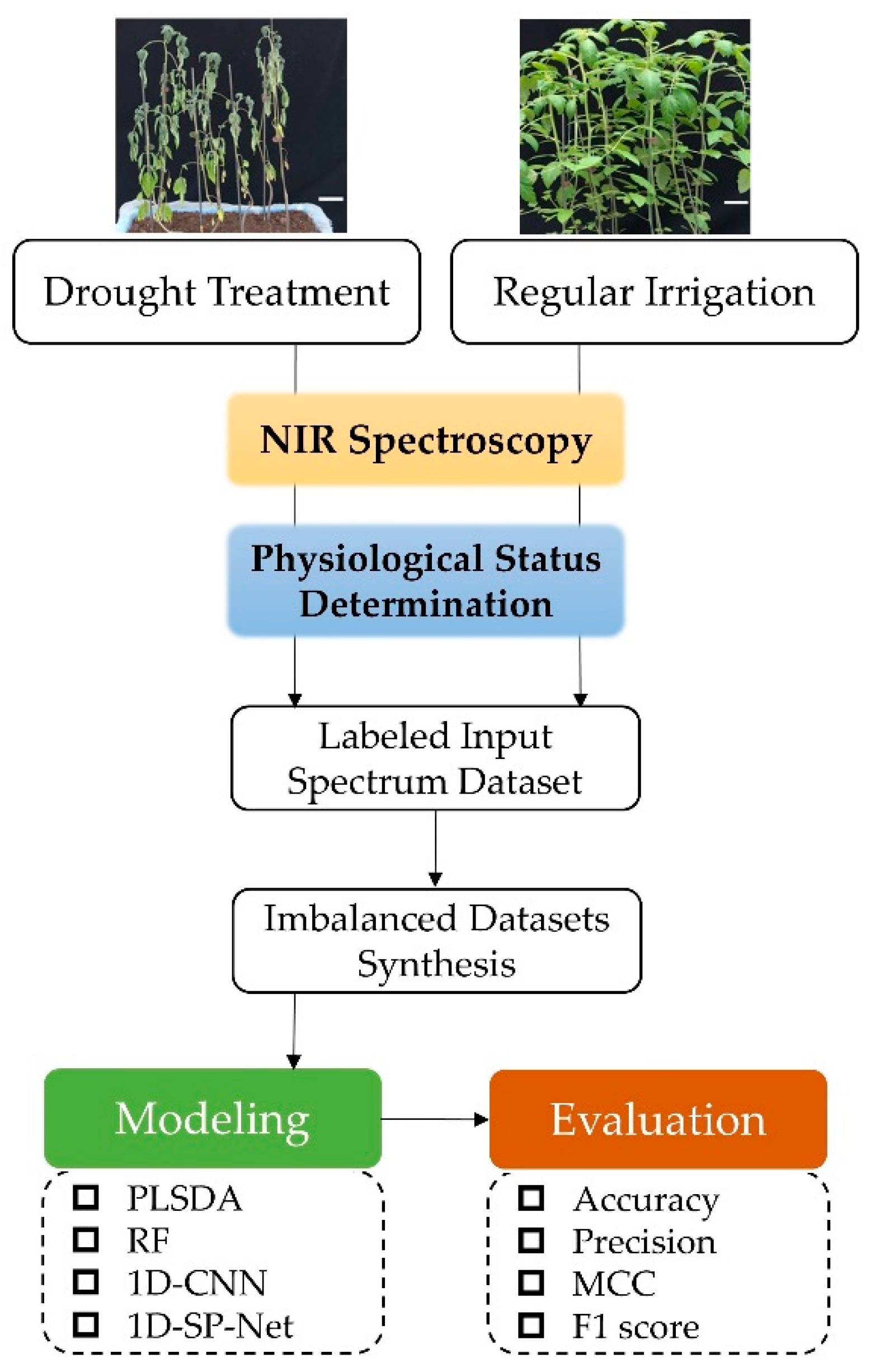
2.1. Experimental Materials and Drought Treatment
2.2. Collection of Physiological Parameters
2.3. Physiological Status Determination
2.4. Collection of NIR Spectral Data
2.5. Estimation of the Extent of Imbalance and Data Set Synthesis
2.6. Model Construction
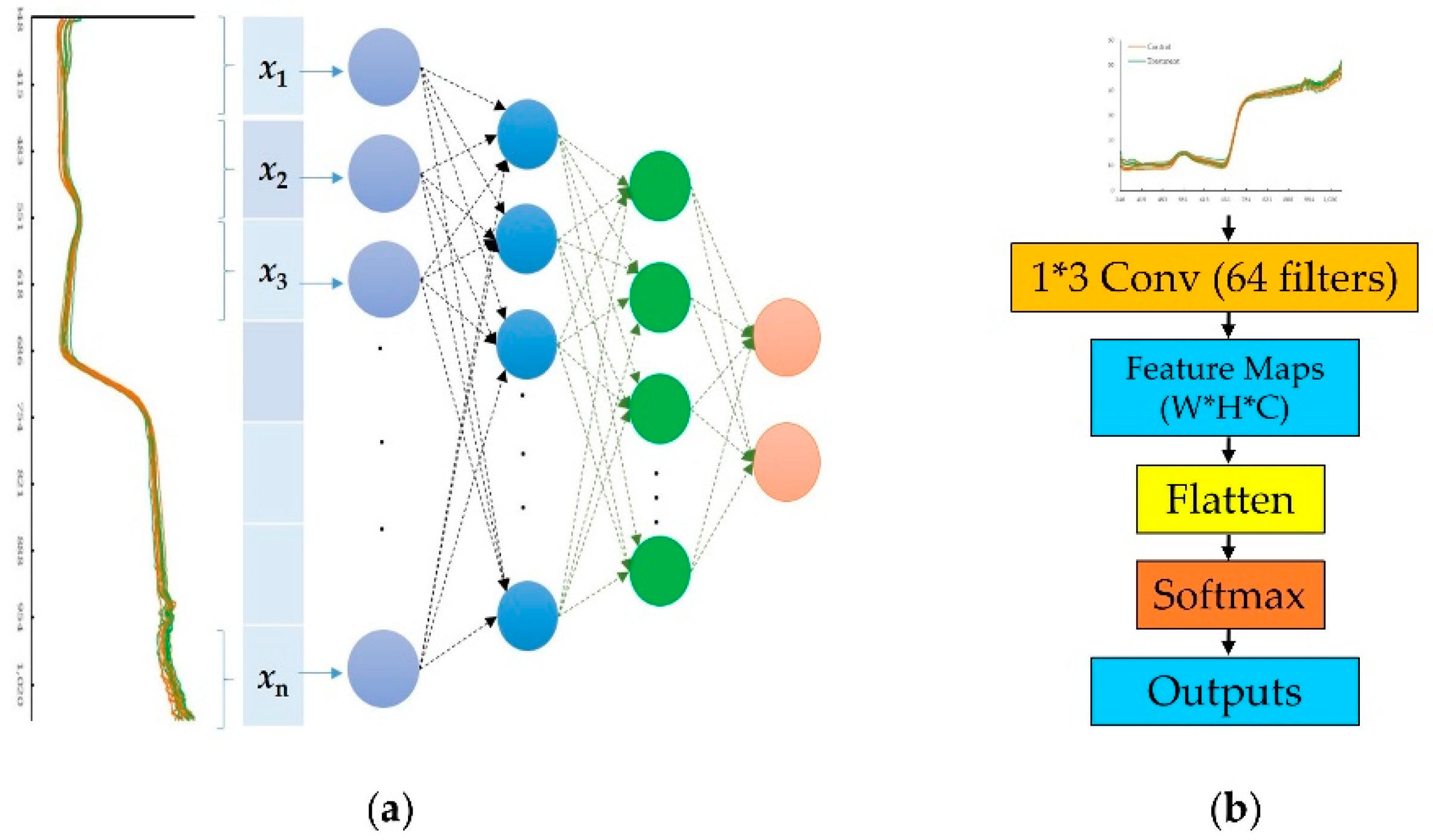
2.6.1. One Dimension Convolutional Neural Network (1D-CNN)
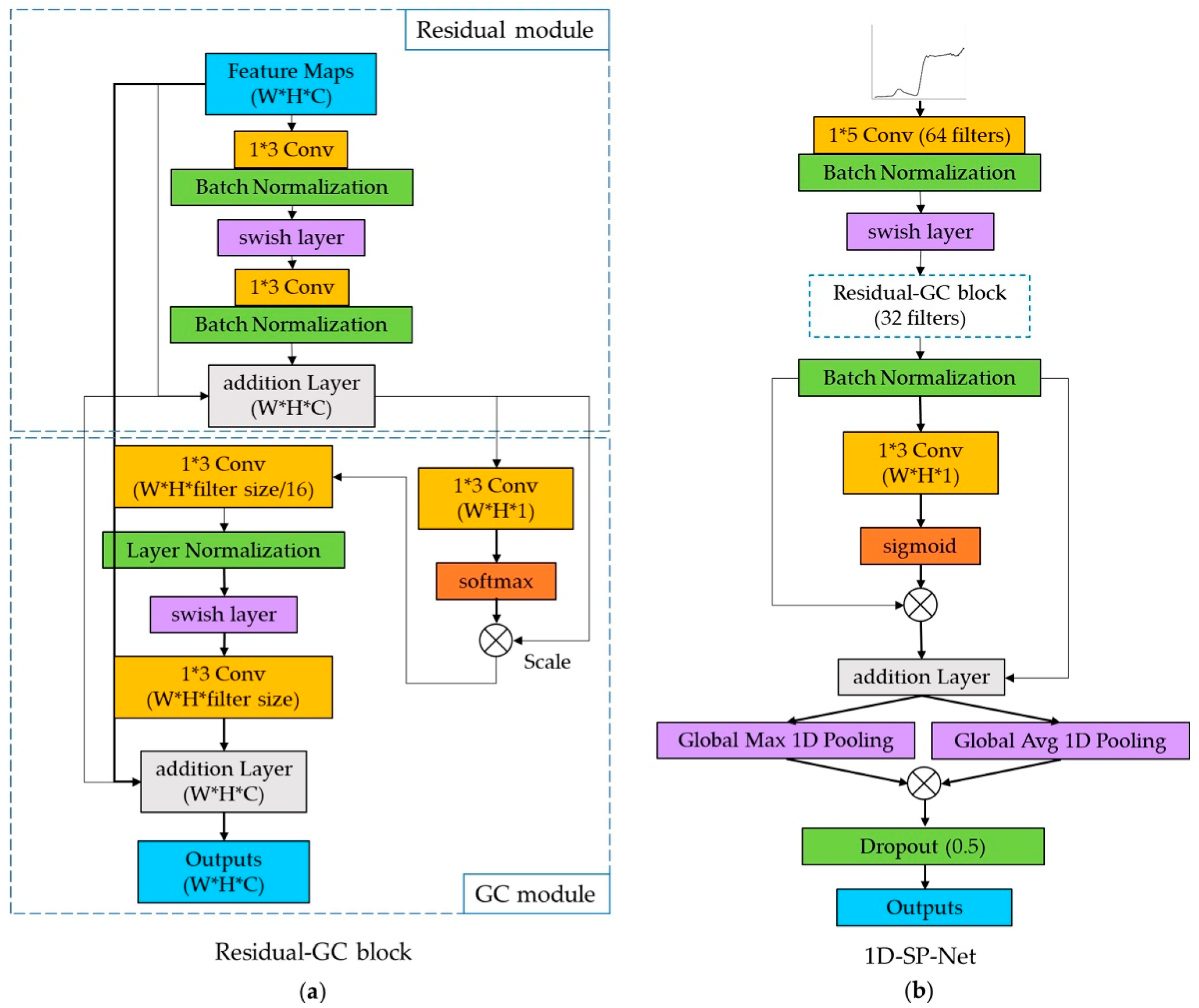
2.6.2. One Dimension Spectrogram Power Net (1D-SP-Net)
2.6.3. Partial Least Squares Discriminant Analysis (PLSDA)
2.6.4. Random Forest (RF)
2.7. Model Performance Metrics
3. Results and Discussion
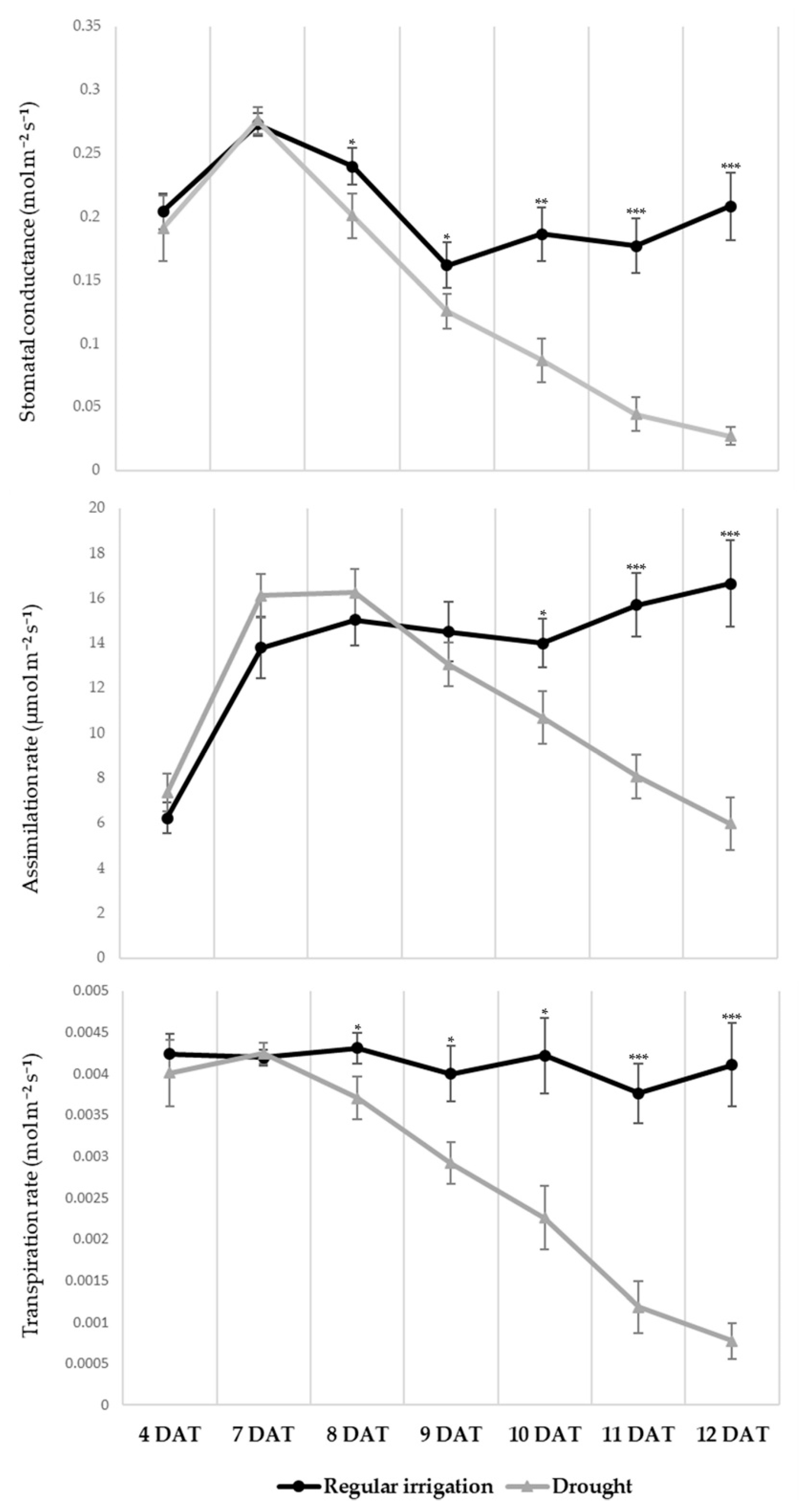
3.1. Morphological and Physiological Alteration under Drought Treatment
3.2. Comparison of Model Performance
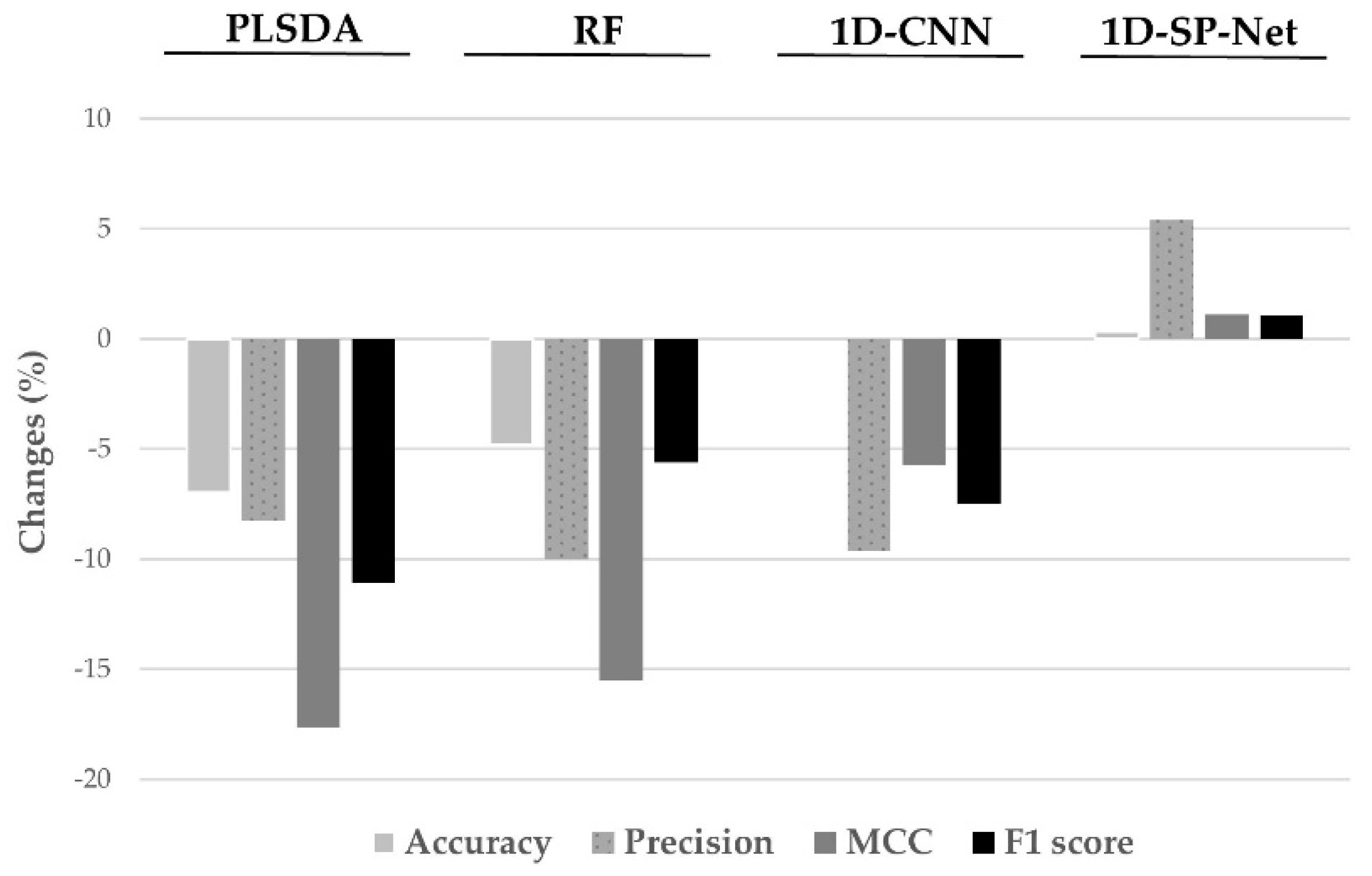
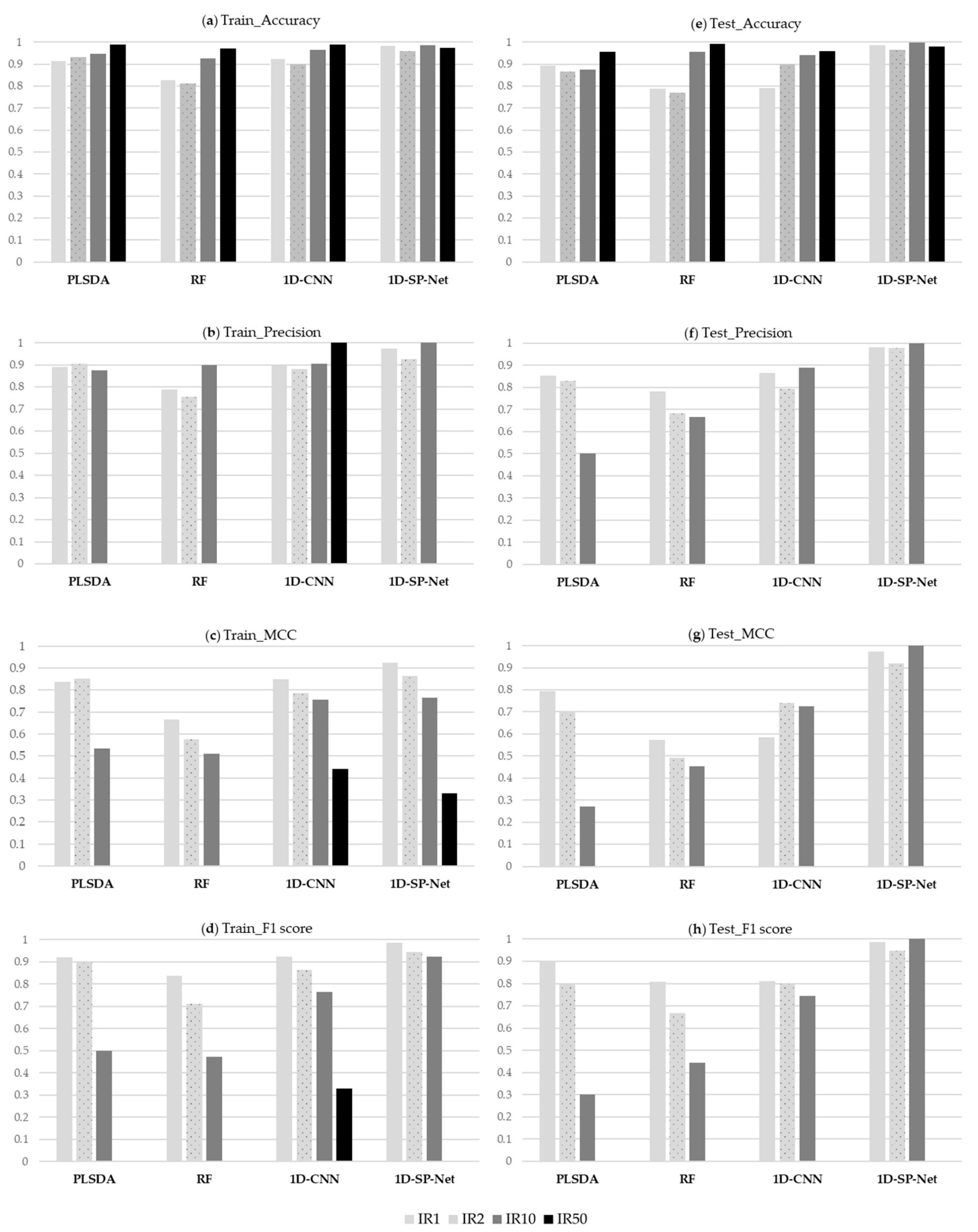
3.3. Effects of the Extent of Imbalance on Model Performance
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Taiz, L.; Zeiger, E.; Møller, I.M.; Murphy, A. Plant Physiology and Development, 6th ed.; Sinauer Associates Incorporated: Sunderland, MA, USA, 2015; p. 761. [Google Scholar]
- Zhao, Y.; Jiang, B.; Huo, Y.; Yi, H.; Tian, H.; Wu, H.; Wang, R.; Zhao, J.; Wang, F. A high-performance database management system for managing and analyzing large-scale SNP data in plant genotyping and breeding applications. Agriculture 2021, 11, 1027. [Google Scholar] [CrossRef]
- Marsh, J.I.; Hu, H.; Gill, M.; Batley, J.; Edwards, D. Crop breeding for a changing climate: Integrating phenomics and genomics with bioinformatics. Theor. Appl. Genet. 2021, 134, 1677–1690. [Google Scholar] [CrossRef] [PubMed]
- Singh, P.; Pandey, P.C.; Petropoulos, G.P.; Pavlides, A.; Srivastava, P.K.; Koutsias, N.; Deng, K.A.K.; Bao, Y. Hyperspectral remote sensing in precision agriculture: Present status, challenges, and future trends. In Hyperspectral Remote Sensing; Elsevier: Amsterdam, The Netherlands, 2020; pp. 121–146. [Google Scholar]
- Liaghat, S.; Ehsani, R.; Mansor, S.; Shafri, H.Z.M.; Meon, S.; Sankaran, S.; Azam, S.H.M.N. Early detection of basal stem rot disease (Ganoderma) in oil palms based on hyperspectral reflectance data using pattern recognition algorithms. Int. J. Remote Sens. 2014, 35, 3427–3439. [Google Scholar] [CrossRef]
- Mohd Asaari, M.S.; Mishra, P.; Mertens, S.; Dhondt, S.; Inzé, D.; Wuyts, N.; Scheunders, P. Close-range hyperspectral image analysis for the early detection of stress responses in individual plants in a high-throughput phenotyping platform. ISPRS J. Photogramm. Remote Sens. 2018, 138, 121–138. [Google Scholar] [CrossRef]
- Jamalluddin, N.; Massawe, F.J.; Mayes, S.; Ho, W.K.; Singh, A.; Symonds, R.C. Physiological screening for drought tolerance traits in vegetable amaranth (Amaranthus tricolor) germplasm. Agriculture 2021, 11, 994. [Google Scholar] [CrossRef]
- Alseekh, S.; Bermudez, L.; de Haro, L.A.; Fernie, A.R.; Carrari, F. Crop metabolomics: From diagnostics to assisted breeding. Metab. Off. J. Metab. Soc. 2018, 14. [Google Scholar] [CrossRef] [Green Version]
- Distelfeld, A.; Avni, R.; Fischer, A.M. Senescence, nutrient remobilization, and yield in wheat and barley. J. Exp. Bot. 2014, 65, 3783–3798. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.X.; Chen, X.; Li, Y.W.; Zhao, H.M.; Xiang, L.; Li, H.; Cai, Q.Y.; Feng, N.X.; Mo, C.H.; Wong, M.H. A visual leaf zymography technique for the in situ examination of plant enzyme activity under the stress of environmental pollution. J. Agric. Food Chem. 2020, 68, 14015–14024. [Google Scholar] [CrossRef]
- Janni, M.; Gulli, M.; Maestri, E.; Marmiroli, M.; Valliyodan, B.; Nguyen, H.T.; Marmiroli, N. Molecular and genetic bases of heat stress responses in crop plants and breeding for increased resilience and productivity. J. Exp. Bot. 2020, 71, 3780–3802. [Google Scholar] [CrossRef]
- Huang, L.; Wu, K.; Huang, W.; Dong, Y.; Ma, H.; Liu, Y.; Liu, L. Detection of fusarium head blight in wheat ears using continuous wavelet analysis and PSO-SVM. Agriculture 2021, 11, 998. [Google Scholar] [CrossRef]
- Ribera-Fonseca, A.; Jorquera-Fontena, E.; Castro, M.; Acevedo, P.; Parra, J.C.; Reyes-Diaz, M. Exploring VIS/NIR reflectance indices for the estimation of water status in high bush blueberry plants grown under full and deficit irrigation. Sci. Hortic. 2019, 256, 108557. [Google Scholar] [CrossRef]
- Diago, M.P.; Fernández-Novales, J.; Gutiérrez, S.; Marañón, M.; Tardaguila, J. Development and validation of a new methodology to assess the vineyard water status by on-the-go near infrared spectroscopy. Front. Plant Sci. 2018, 9, 59. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Steidle Neto, A.J.; de O Moura, L.; de C. Lopes, D.; de A Carlos, L.; Martins, L.M.; de C Louback Ferraz, L. Non-destructive prediction of pigment content in lettuce based on visible-NIR spectroscopy. J. Sci. Food Agric. 2017, 97, 2015–2022. [Google Scholar] [CrossRef] [PubMed]
- Jensen, J.R. Remote Sensing of the Environment: An Earth Resource Perspective 2/e; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Nie, P.; Xia, Z.; Sun, D.W.; He, Y. Application of visible and near infrared spectroscopy for rapid analysis of chrysin and galangin in Chinese propolis. Sensors 2013, 13, 10539–10549. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barker, M.J.; Hussan, S.R.; Lovergne, L.; Untereiner, V.; Hughes, C.; Lukaszewski, R.A.; Thiéfinbg, G.; Sockalingum, G.D. Developing and understanding biofluid vibrational spectroscopy: A critical review. Chem. Soc. Rev. 2016, 45, 1803–1818. [Google Scholar] [CrossRef] [Green Version]
- Pandiselvam, R.; Mahanti, N.K.; Manikantan, M.R.; Kothakota, A.; Chakraborty, S.K.; Ramesh, S.V.; Beegum, P.S. Rapid detection of adulteration in desiccated coconut powder: Vis-NIR spectroscopy and chemometric approach. Food Control 2022, 133, 108588. [Google Scholar] [CrossRef]
- Das, B.; Manohara, K.K.; Mahajan, G.R.; Sahoo, R.N. Spectroscopy based novel spectral indices, PCA- and PLSR-coupled machine learning models for salinity stress phenotyping of rice. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2020, 229, 117983. [Google Scholar] [CrossRef]
- Marín-Ortiz, J.C.; Gutierrez-Toro, N.; Botero-Fernández, V.; Hoyos-Carvajal, L.M. Linking physiological parameters with visible/near-infrared leaf reflectance in the incubation period of vascular wilt disease. Saudi J. Biol. Sci. 2020, 27, 8899. [Google Scholar] [CrossRef]
- Genc, L.; Inalpulat, M.; Kizil, U.; Mirik, M.; Smith, S.E.; Mendes, M. Determination of water stress with spectral reflectance on sweet corn (Zea mays L.) using classification tree (CT) analysis. Zemdirb. Agric. 2013, 100, 81–90. [Google Scholar] [CrossRef]
- Tu, Y.-K.; Chen, H.-W.; Fang, S.-L.; Yao, M.-H.; Tseng, Y.-Y.; Kuo, B.-J. Establishing of early discrimination methods for drought stress of tomato by using environmental parameters and NIR spectroscopy in greenhouse. Acta Hortic. 2021, 1311, 501–512. [Google Scholar] [CrossRef]
- Osco, L.P.; Ramos, A.P.M.; Moriya, É.A.S.; Bavaresco, L.G.; de Lima, B.C.; Estrabis, N.; Pereira, D.R.; Creste, J.E.; Júnior, J.M.; Gonçalves, W.N.; et al. Modeling hyperspectral response of water-stress induced lettuce plants using artificial neural networks. Remote Sens. 2019, 11, 2797. [Google Scholar] [CrossRef] [Green Version]
- Maimaitiyiming, M.; Ghulam, A.; Bozzolo, A.; Wilkins, J.L.; Kwasniewski, M.T. Early detection of plant physiological responses to different levels of water stress using reflectance spectroscopy. Remote Sens. 2017, 9, 745. [Google Scholar] [CrossRef] [Green Version]
- Ihuoma, S.O.; Madramootoo, C.A. Sensitivity of spectral vegetation indices for monitoring water stress in tomato plants. Comput. Electron. Agric. 2019, 163. [Google Scholar] [CrossRef]
- Romero, A.P.; Alarcón, A.; Valbuena, R.I.; Galeano, C.H. Physiological assessment of water stress in potato using spectral information. Front. Plant Sci. 2017, 8, 1608. [Google Scholar] [CrossRef] [PubMed]
- Sanseechan, P.; Panduangnate, L.; Saengprachatanarug, K.; Wongpichet, S.; Taira, E.; Posom, J. A portable near infrared spectrometer as a non-destructive tool for rapid screening of solid density stalk in a sugarcane breeding program. Sens. Bio-Sens. Res. 2018, 20, 34–40. [Google Scholar] [CrossRef]
- Gutiérrez, S.; Tardaguila, J.; Fernández-Novales, J.; Diago, M.P. Data mining and NIR spectroscopy in viticulture: Applications for plant phenotyping under field conditions. Sensors 2016, 16, 236. [Google Scholar] [CrossRef] [Green Version]
- Vilmus, I.; Ecarnot, M.; Verzelen, N.; Roumet, P. Monitoring nitrogen leaf resorption kinetics by near-infrared spectroscopy during grain filling in durum wheat in different nitrogen availability conditions. Crop Sci. 2014, 54, 284–296. [Google Scholar] [CrossRef]
- Omena-Garcia, R.P.; Oliveira Martins, A.; Medeiros, D.B.; Vallarino, J.G.; Mendes Ribeiro, D.; Fernie, A.R.; Araújo, W.L.; Nunes-Nesi, A. Growth and metabolic adjustments in response to gibberellin deficiency in drought stressed tomato plants. Environ. Exp. Bot. 2019, 159, 95–107. [Google Scholar] [CrossRef]
- Giordano, M.; Petropoulos, S.A.; Rouphael, Y. Response and defence mechanisms of vegetable crops against drought, heat and salinity stress. Agriculture 2021, 11, 463. [Google Scholar] [CrossRef]
- Liang, G.; Liu, J.; Zhang, J.; Guo, J. Effects of drought stress on photosynthetic and physiological parameters of tomato. J. Am. Soc. Hortic. Sci. 2020, 145, 12–17. [Google Scholar] [CrossRef] [Green Version]
- Dardenne, P.; Sinnaeve, G.; Baeten, V. Multivariate calibration and chemometrics for near infrared spectroscopy: Which method? J. Near Infrared Spectrosc. 2000, 8, 229–237. [Google Scholar] [CrossRef]
- Boulesteix, A.L.; Strimmer, K. Partial least squares: A versatile tool for the analysis of high-dimensional genomic data. Brief. Bioinform. 2006, 8, 32–44. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, B.C.; Yun, Y.H.; Liang, Y.Z.; Cao, D.S.; Xu, Q.S.; Yi, L.Z.; Huang, X. A new strategy to prevent over-fitting in partial least squares models based on model population analysis. Anal. Chim. Acta 2015, 880, 32–41. [Google Scholar] [CrossRef] [PubMed]
- Gowen, A.A.; Downey, G.; Esquerre, C.; O’Donnell, C.P. Preventing over-fitting in PLS calibration models of near-infrared (NIR) spectroscopy data using regression coefficients. J. Chemom. 2011, 25, 375–381. [Google Scholar] [CrossRef]
- Chen, Y.Y.; Wang, Z.B. Quantitative analysis modeling of infrared spectroscopy based on ensemble convolutional neural networks. Chemometr. Intell. Lab. Syst. 2018, 181, 1–10. [Google Scholar] [CrossRef]
- De Santana, F.B.; de Souza, A.M.; Poppi, R.J. Visible and near infrared spectroscopy coupled to random forest to quantify some soil quality parameters. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2018, 191, 454–462. [Google Scholar] [CrossRef] [PubMed]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C.; Villa-Vialaneix, N. Random forests for big data. Big Data Res. 2017, 9, 28–46. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE Inst. Electr. Electron. Eng. 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Giménez, M.; Palanca, J.; Botti, V. Semantic-based padding in convolutional neural networks for improving the performance in natural language processing. A case of study in sentiment analysis. Neurocomputing 2020, 378, 315–323. [Google Scholar] [CrossRef]
- Kruthika, K.R.; Rajeswari; Maheshappa, H.D. CBIR system using Capsule Networks and 3D CNN for Alzheimer’s disease diagnosis. Inform. Med. Unlocked 2019, 14, 59–68. [Google Scholar] [CrossRef]
- Kuo, C.-E.; Chen, G.-T.; Liao, P.-Y. An EEG spectrogram-based automatic sleep stage scoring method via data augmentation, ensemble convolution neural network, and expert knowledge. Biomed. Signal Process. Control 2021, 70, 102981. [Google Scholar] [CrossRef]
- Acquarelli, J.; van Laarhoven, T.; Gerretzen, J.; Tran, T.N.; Buydens, L.M.C.; Marchiori, E. Convolutional neural networks for vibrational spectroscopic data analysis. Anal. Chim. Acta 2017, 954, 22–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malek, S.; Melgani, F.; Bazi, Y. One-dimensional convolutional neural networks for spectroscopic signal regression. J. Chemom. 2018, 32, e2977. [Google Scholar] [CrossRef]
- Zhu, R.; Guo, Y.; Xue, J.H. Adjusting the imbalance ratio by the dimensionality of imbalanced data. Pattern Recognit. Lett. 2020, 133, 217–223. [Google Scholar] [CrossRef]
- Lee, W.; Jun, C.H.; Lee, J.S. Instance categorization by support vector machines to adjust weights in AdaBoost for imbalanced data classification. Inf. Sci. 2017, 381, 92–103. [Google Scholar] [CrossRef]
- Somasundaram, A.; Reddy, U.S. Modelling a stable classifier for handling large scale data with noise and imbalance. In Proceedings of the 2017 International Conference on Computational Intelligence in Data Science, Chennai, India, 2–3 June 2017. [Google Scholar] [CrossRef]
- Nemoto, K.; Hamaguchi, R.; Imaizumi, T.; Hikosaka, S. Classification of rare building change using CNN with multi-class focal loss. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Ding, W.; Huang, D.Y.; Chen, Z.; Yu, X.; Lin, W. Facial action recognition using very deep networks for highly imbalanced class distribution. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Kuala Lumpur, Malaysia, 12–15 December 2017. [Google Scholar] [CrossRef]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3573–3587. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. arXiv 2018, arXiv:1711.07971v3. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for activation functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsk, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Chevallier, S.; Bertrand, D.; Kohler, A.; Courcoux, P. Application of PLS-DA in multivariate image analysis. J. Chemom. 2006, 20, 221–229. [Google Scholar] [CrossRef]
- Susič, N.; Žibrat, U.; Širca, S.; Strajnar, P.; Razinger, J.; Knapič, M.; Vončina, A.; Urek, G.; Gerič Stare, B. Discrimination between abiotic and biotic drought stress in tomatoes using hyperspectral imaging. Sens. Actuators B Chem. 2018, 273, 842–852. [Google Scholar] [CrossRef] [Green Version]
- Wehner, G.; Balko, C.; Ordon, F. Experimental design to determine drought stress response and early leaf senescence in barley (Hordeum vulgare L.). Bio-Protocol 2016, 6, e1749. [Google Scholar] [CrossRef] [Green Version]
- Cruz de Carvalho, M.H.; Laffray, D.; Louguet, P. Comparison of the physiological responses of Phaseolus vulgaris and Vigna unguiculata cultivars when submitted to drought conditions. Environ. Exp. Bot. 1998, 40, 197–207. [Google Scholar] [CrossRef]
- Strajnar, P.; Širca, S.; Urek, G.; Šircelj, H.; Železnik, P.; Vodnik, D. Effect of Meloidogyne ethiopica parasitism on water management and physiological stress in tomato. Eur. J. Plant Pathol. 2012, 132, 49–57. [Google Scholar] [CrossRef]
- Zhao, S.; Peng, Y.; Liu, J.; Wu, S. Tomato leaf disease diagnosis based on improved convolution neural network by attention module. Agriculture 2021, 11, 651. [Google Scholar] [CrossRef]
- Valverde-Albacete, F.J.; Peláez-Moreno, C. 100% Classification accuracy considered harmful: The normalized information transfer factor explains the accuracy paradox. PLoS ONE 2014, 9, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Chicco, D.; Warrens, M.J.; Jurman, G. The matthews correlation coefficient (MCC) is more informative then Cohen’s Kappa and brier score in binary classification assessment. IEEE Access 2021, 9, 78368–78381. [Google Scholar] [CrossRef]
- Pillai, I.; Fumera, G.; Roli, F. Designing multi-label classifiers that maximize F measures: State of the art. Pattern Recognit. 2017, 61, 394–404. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| True Condition | |||
|---|---|---|---|
| Positive | Negative | ||
| Predicted Condition | |||
| Positive | True positive (TP) a | False positive (FP) b | |
| Negative | False negative (FN) c | True negative (TN) d | |
| Model | Training | Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | Precision (%) | MCC | F1 Score | Accuracy (%) | Precision (%) | MCC | F1 Score | |
| PLSDA | 93.2 | 90.4 | 0.85 | 0.90 | 86.7 | 82.9 | 0.70 | 0.80 |
| RF | 81.1 | 75.6 | 0.58 | 0.71 | 77.2 | 68.4 | 0.49 | 0.67 |
| 1D-CNN | 90.0 | 88.0 | 0.79 | 0.87 | 90.0 | 80.0 | 0.74 | 0.80 |
| 1D-SP-Net | 96.0 a | 93.1 | 0.91 | 0.94 | 96.3 | 98.0 | 0.92 | 0.95 |
| Dataset | Type | Imbalance Ratio | Major Class b | Minor Class c |
|---|---|---|---|---|
| IR1 | Synthetic a | 1 | 189 | 189 |
| IR2 | Original dataset | 2 | 246 | 132 |
| IR10 | Synthetic | 10 | 340 | 38 |
| IR50 | Synthetic | 50 | 370 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, Y.-K.; Kuo, C.-E.; Fang, S.-L.; Chen, H.-W.; Chi, M.-K.; Yao, M.-H.; Kuo, B.-J. A 1D-SP-Net to Determine Early Drought Stress Status of Tomato (Solanum lycopersicum) with Imbalanced Vis/NIR Spectroscopy Data. Agriculture 2022, 12, 259. https://doi.org/10.3390/agriculture12020259
Tu Y-K, Kuo C-E, Fang S-L, Chen H-W, Chi M-K, Yao M-H, Kuo B-J. A 1D-SP-Net to Determine Early Drought Stress Status of Tomato (Solanum lycopersicum) with Imbalanced Vis/NIR Spectroscopy Data. Agriculture. 2022; 12(2):259. https://doi.org/10.3390/agriculture12020259
Chicago/Turabian StyleTu, Yuan-Kai, Chin-En Kuo, Shih-Lun Fang, Han-Wei Chen, Ming-Kun Chi, Min-Hwi Yao, and Bo-Jein Kuo. 2022. "A 1D-SP-Net to Determine Early Drought Stress Status of Tomato (Solanum lycopersicum) with Imbalanced Vis/NIR Spectroscopy Data" Agriculture 12, no. 2: 259. https://doi.org/10.3390/agriculture12020259