Evaluation of Agricultural Machinery Operational Benefits Based on Semi-Supervised Learning

Abstract
:1. Introduction
2. Analysis of Agricultural Machinery Operation Data
3. Indicator Selection
4. Operational Benefits Evaluation
4.1. Improved LSSVM by Particle Swarm Optimization
4.2. Semi-Supervised Learning Algorithm Training Model
- Mark a part of the data set, and divide the marked data into training samples and test samples;
- The marked training samples are trained to obtain the training model;
- The training model is used to predict all unlabelled samples;
- Set the top N prediction tags with the highest score and accuracy above a certain threshold as “pseudo tags”;
- Put the samples with “pseudo tags” into the training sample set, and combine the new training sample set to retrain the model;
- Repeat steps 2–5 until the training samples are no longer increased;
- Use the generated training model to predict the marked test samples.
- Calculate the maximum class spacing Lmax of the original sample set;
- Calculate the maximum distance L from a pseudo label sample to the original sample;
- If L ≤ Lmax, put the sample into the original sample set; otherwise, put the sample back into the unlabelled sample set;
- Update Lmax and repeat steps 2–4 to screen all newly generated samples;
- Retrain the model with a new sample set.
5. Benefit Evaluation Verification and Method Application
5.1. Data Preprocessing
- Screen out data with incomplete information. Due to the problem of data collection and transmission, part of the data is lost, which will result in incomplete evaluation indicators, and these data need to be deleted in advance;
- Delete abnormal operation data. The obvious abnormal data of some indicators caused by manual input errors should be deleted, and the daily operation area of some agricultural machinery is too low for reference, so it needs to be deleted as well;
- Cluster data to remove noise points and outliers;
- Select representative data for manual scoring, in part as training samples and in part as test samples.
5.2. Semi-Supervised Training Model
- Bp neural network is selected to train the training set model, and error samples are manually checked and relabelled;
- Conduct training on unclassified samples, and select the top N with the highest score over 98 to enter the training set;
- Repeat step 2 until the number of times reached or the number of training sets does not change;
- Test the test set.
- The accuracy of the training model does not strictly change with the increase in the number of training samples, but fluctuates;
- With the increase in training samples, misclassified samples will inevitably appear, which will affect the accuracy of model training.
5.3. Recommended Combination of Agricultural Machinery and Tools
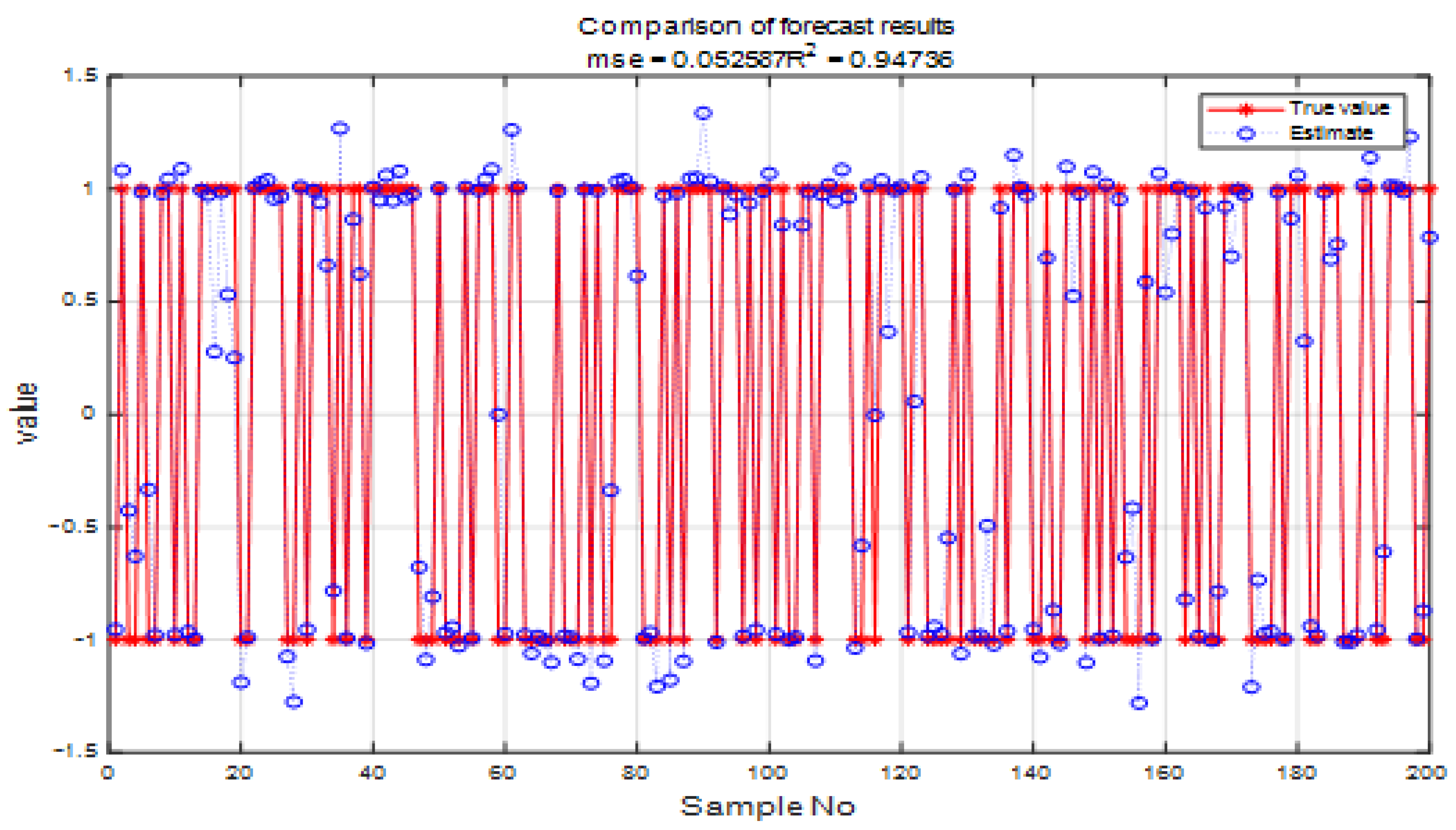
5.4. Analysis of Experimental Results
6. Conclusions
- (1)
- PSO algorithm is used to improve the parameter optimization process of LSSVM. According to its own optimal solution and the global optimal solution, the particle updates its speed and position after each iteration, so as to better find the fastest direction and optimal solution in the iterative process;
- (2)
- In view of the problems such as large quantities of operation data, time-consuming and laborious sample labelling, and easily made mistakes, a semi-supervised learning method is proposed. A small number of labelled samples are used for training, and a model is generated to predict unlabelled samples. “Pseudo labels” are added to the unlabelled samples whose accuracies are above the threshold. After screening, training samples are added to increase the number of training samples, and to improve the generalization ability and accuracy of the training model;
- (3)
- Using the LSSVM training model improved by the PSO method, the accuracy of the improved model is increased from 94.43% to 96.83% using the self-learning method, and the optimal combination of agricultural machines is recommended according to the operating efficiency, so as to increase the cooperative efficiency.
- (4)
- Although the accuracy has improved a little, the model still needs to be optimised. The next step is to give different weights to different indicators, which to increase the scientificity of the model. In the combination recommendation of agricultural machinery, the method used is statistical analysis based on the evaluation results. The next research focus is to find more accurate recommendation methods and obtain more scientific recommendations of agricultural implement combinations.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kou, Z.; Wu, C. Smartphone based operating behaviour modelling of agricultural machinery. IFAC-Pap. 2018, 51, 521–525. [Google Scholar] [CrossRef]
- Jha, K.; Doshi, A.; Patel, P.; Shah, M. A comprehensive review on automation in agriculture using artificial intelligence. Artif. Intell. Agric. 2019, 2, 1–12. [Google Scholar] [CrossRef]
- Parvin, N.; Coucheney, E.; Gren, I.-M.; Andersson, H.; Elofsson, K.; Jarvis, N.; Keller, T. On the relationships between the size of agricultural machinery, soil quality and net revenues for farmers and society. Soil Secur. 2022, 6, 100044. [Google Scholar] [CrossRef]
- Wang, P.; Meng, Z.; An, X.; Chen, J.; Li, W. Relationship between Agricultural Machinery Power and Agricultural Machinery Subsoiling Operation. Trans. Chin. Soc. Agric. Mach. 2019, 50, S1. [Google Scholar]
- Shevtsov, V.G.; Lavrov, A.; Godzhaev, Z.A.; Kryazhkov, V.M.; Gurulev, G.S. The Development of the Russian Agricultural Tractor Market from 2008 to 2014. In Proceedings of the SAE 2016 Commercial Vehicle Engineering Congress, Rosemont, IL, USA, 4–6 October 2016. [Google Scholar]
- Godzhaev, Z.; Vim, F.S.A.C.; Beylis, V.; Lavrov, A.; Shevtsov, V. Standards and Forecasting of Agricultural Production Needs in Machinery. Elektrotekhnol. Elektrooborud. APK 2020, 41, 151–158. [Google Scholar] [CrossRef]
- Godzhayev, Z.A.; Lavrov, A.V.; Shevtsov, V.G.; Zubina, V.A. The methodology for assessing the level of localization of agricultural tractors production. Trakt. Sel Hozmashiny 2020, 87, 18–24. [Google Scholar] [CrossRef]
- Shevtsov, V.; Lavrov, A.; Izmailov, A.; Lobachevskii, Y. Formation of Quantitative and Age Structure of Tractor Park in the Conditions of Limitation of Resources of Agricultural Production. Lunión Méd. Can. 2015, 114, 182-4–187-9. [Google Scholar]
- Adamchuk, V.I.; Grisso, R.; Kocher, M.F. Spatial Variability of Field Machinery Use and Efficiency. In GIS Applications in Agriculture; CRC Press: Boca Raton, FL, USA, 2011; pp. 135–146. [Google Scholar]
- Askari, M.; Abbaspour-Gilandeh, Y.; Taghinezhad, E.; El Shal, A.M.; Hegazy, R.; Okasha, M. Applying the Response Surface Methodology (RSM) Approach to Predict the Tractive Performance of an Agricultural Tractor during Semi-Deep Tillage. Agriculture 2021, 11, 1043. [Google Scholar] [CrossRef]
- Seyyedhasani, H.; Dvorak, J.S. Using the Vehicle Routing Problem to reduce field completion times with multiple machines. Comput. Electron. Agric. 2017, 134, 142–150. [Google Scholar] [CrossRef] [Green Version]
- Conesa-Muñoz, J.; Pajares, G.; Ribeiro, A. Mix-opt: A new route operator for optimal coverage path planning for a fleet in an agricultural environment. Expert Syst. Appl. 2016, 54, 364–378. [Google Scholar] [CrossRef]
- Durczak, K.; Ekielski, A.; Kozłowski, R.; Żelaziński, T.; Pilarski, K. A computer system supporting agricultural machinery and farm tractor purchase decisions. Heliyon 2020, 6, e05039. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.; Lu, D.; Yan, J. Evaluating the impact of land fragmentation on the cost of agricultural operation in the southwest mountainous areas of China. Land Use Policy 2020, 99, 105099. [Google Scholar] [CrossRef]
- Ren, W.; Wen, J.; Hu, Y.; Li, J. Maintenance service network redesign for geographically distributed moving assets using NSGA-II in agriculture. Comput. Electron. Agric. 2019, 169, 105170. [Google Scholar] [CrossRef]
- Guo, X.; Yan, X.; Chen, Z.; Meng, Z. A Novel Closed-Loop System for Vehicle Speed Prediction Based on APSO LSSVM and BP NN. Energies 2021, 15, 21. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, K.; Chen, Y.; Dai, Y.; Liu, Z.; Zhao, K.; Wang, H.; Peng, Z. An Ultra-Fast Power Prediction Method Based on Simplified LSSVM Hyperparameters Optimization for PV Power Smoothing. Energies 2021, 14, 5752. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, S. Sparse algorithm for robust LSSVM in primal space. Neurocomputing 2018, 275, 2880–2891. [Google Scholar] [CrossRef] [Green Version]
- Baziyad, A.G.; Nouh, A.S.; Ahmad, I.; Alkuhayli, A. Application of Least-Squares Support-Vector Machine Based on Hysteresis Operators and Particle Swarm Optimization for Modeling and Control of Hysteresis in Piezoelectric Actuators. Actuators 2022, 11, 217. [Google Scholar] [CrossRef]
- Jin, Z.; Chen, G.; Yang, Z. Rolling Bearing Fault Diagnosis Based on WOA-VMD-MPE and MPSO-LSSVM. Entropy 2022, 24, 927. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Liang, C.; Lu, W.; Li, C.; Zhao, S.; Wang, B. Forecasting of Short-Term Daily Tourist Flow Based on Seasonal Clustering Method and PSO-LSSVM. ISPRS Int. J. Geo-Inf. 2020, 9, 676. [Google Scholar] [CrossRef]
- Wu, D.; Shang, M.; Luo, X.; Xu, J.; Yan, H.; Deng, W.; Wang, G. Self-training semi-supervised classification based on density peaks of data. Neurocomputing 2018, 275, 180–191. [Google Scholar] [CrossRef]
- Sun, F.; Fang, F.; Wang, R.; Wan, B.; Guo, Q.; Li, H.; Wu, X. An Impartial Semi-supervised Learning Strategy for Imbalanced Classification on VHR Images. Sensors 2020, 20, 6699. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.; Huang, G.; Chi, D. Classification of the Complex Agricultural Planting Structure with a Semi-Supervised Extreme Learning Machine Framework. Remote Sens. 2020, 12, 3708. [Google Scholar] [CrossRef]
- Heo, J.; Payne, W.V.; Domanski, P.A.; Du, Z. Self Training of a Fault-Free Model for Residential Air Conditioner Fault Detection and Diagnostics Self Training of a Fault-Free Model for Residential Air Conditioner Fault Detection and Diagnostics; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MA, USA, 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Power (Horsepower) | Machine Width (mm) | Operation Area (mu) | Duration (min) |
|---|---|---|---|
| 210 | 3900 | 15.16 | 33 |
| 210 | 3900 | 59.48 | 123 |
| 210 | 2400 | 152.79 | 337.2 |
| Power (Horsepower) | Machine Width (mm) | Operation Area (mu) | Duration (min) |
|---|---|---|---|
| 90 | 2600 | 308.75 | 781.2 |
| 130 | 3900 | 324.62 | 286.2 |
| 150 | 3900 | 329.57 | 290.4 |
| Power (Horsepower) | Machine Width (mm) | Operation Area (mu) | Pass Rate (%) |
|---|---|---|---|
| 200 | 3600 | 76.09 | 84 |
| 140 | 3900 | 172.73 | 45 |
| 200 | 3600 | 191.65 | 69 |
| Power (Horsepower) | Machine Width (mm) | Operation Area (mu) | Area of Repeated Operation (mu) |
|---|---|---|---|
| 130 | 2600 | 245.5 | 48.46 |
| 200 | 3600 | 155.07 | 64.55 |
| 180 | 3900 | 683.48 | 93.97 |
| Method | Time Consumption (s) | Accuracy (%) |
|---|---|---|
| lssvm | 48 | 92.89 |
| PSO+LSSVM | 26 | 94.43 |
| BP network | 71 | 92.16 |
| Logistic regression | 26 | 91.73 |
| Width (mm) | 1300 | 1950 | 2100 | 2600 | 3000 | 3400 | 3900 | 4200 | |
|---|---|---|---|---|---|---|---|---|---|
| Power | |||||||||
| 90 | 0.45 | 0.41 | 0.36 | 0.38 | 0.29 | 0.12 | - | - | |
| 110 | 0.32 | 0.38 | 0.49 | 0.33 | 0.42 | 0.31 | - | - | |
| 130 | 0.53 | 0.34 | 0.41 | 0.59 | 0.35 | 0.46 | 0.32 | 0.26 | |
| 150 | 0.24 | 0.36 | 0.41 | 0.45 | 0.63 | 0.4 | 0.36 | 0.15 | |
| 180 | - | 0.38 | 0.46 | 0.38 | 0.66 | 0.51 | 0.35 | 0.43 | |
| 200 | - | - | 0.41 | 0.38 | 0.39 | 0.58 | 0.45 | 0.43 | |
| 220 | - | - | 0.35 | 0.49 | 0.42 | 0.51 | 0.67 | 0.49 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhao, B.; Zhang, W.; Wei, L.; Zhou, L. Evaluation of Agricultural Machinery Operational Benefits Based on Semi-Supervised Learning. Agriculture 2022, 12, 2075. https://doi.org/10.3390/agriculture12122075
Li Y, Zhao B, Zhang W, Wei L, Zhou L. Evaluation of Agricultural Machinery Operational Benefits Based on Semi-Supervised Learning. Agriculture. 2022; 12(12):2075. https://doi.org/10.3390/agriculture12122075
Chicago/Turabian StyleLi, Yashuo, Bo Zhao, Weipeng Zhang, Liguo Wei, and Liming Zhou. 2022. "Evaluation of Agricultural Machinery Operational Benefits Based on Semi-Supervised Learning" Agriculture 12, no. 12: 2075. https://doi.org/10.3390/agriculture12122075