
Plant Disease Detection Strategy Based on Image Texture and Bayesian Optimization with Small Neural Networks

Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Dataset
- ✓
- Although the dataset preserves a certain homogeneity in the image capture conditions, such as the distance from the camera to the leaves, some classes were collected in different places. Moreover, in the original works [10,23], it is not indicated whether the tomato varieties are identical or different in each class. Therefore, there is uncertainty in this regard.
- ✓
- Some morphological features of the leaves could be due to phenotypic and genotypic aspects of the variety and not necessarily a consequence of the disease. For example, in [24], the authors classified the silhouette of the leaves, obtaining an accuracy of 52.3% based on the ResNet-50 model.
- ✓
- The dataset was made with images captured in different lighting and background conditions for each class, resulting in a classification bias. This was detected by the same authors in [24], who classified the backgrounds of the images, obtaining an accuracy of 62.3%. They recommend performing segmentation and eliminating the background before any classification procedure.
- ✓
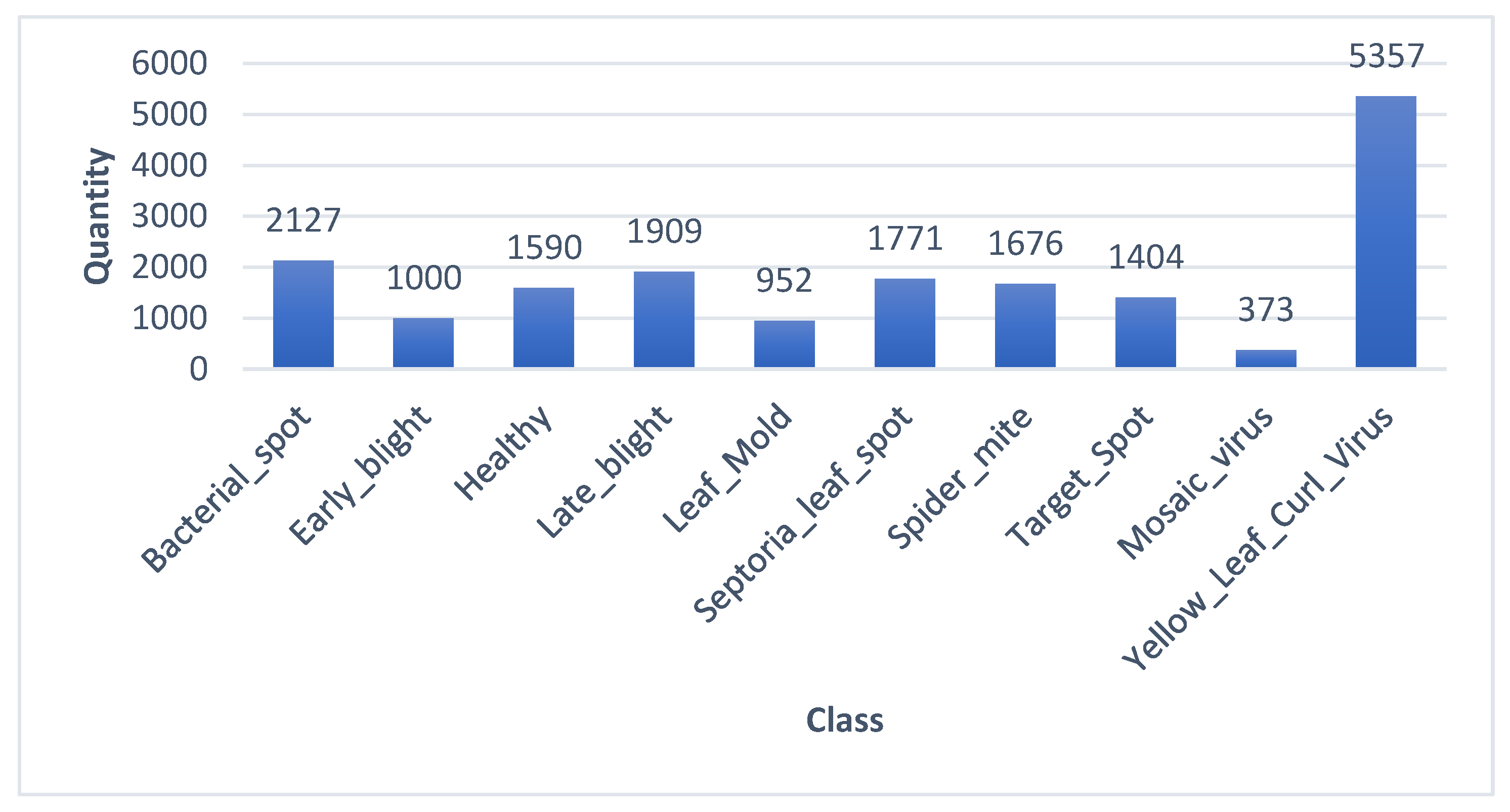
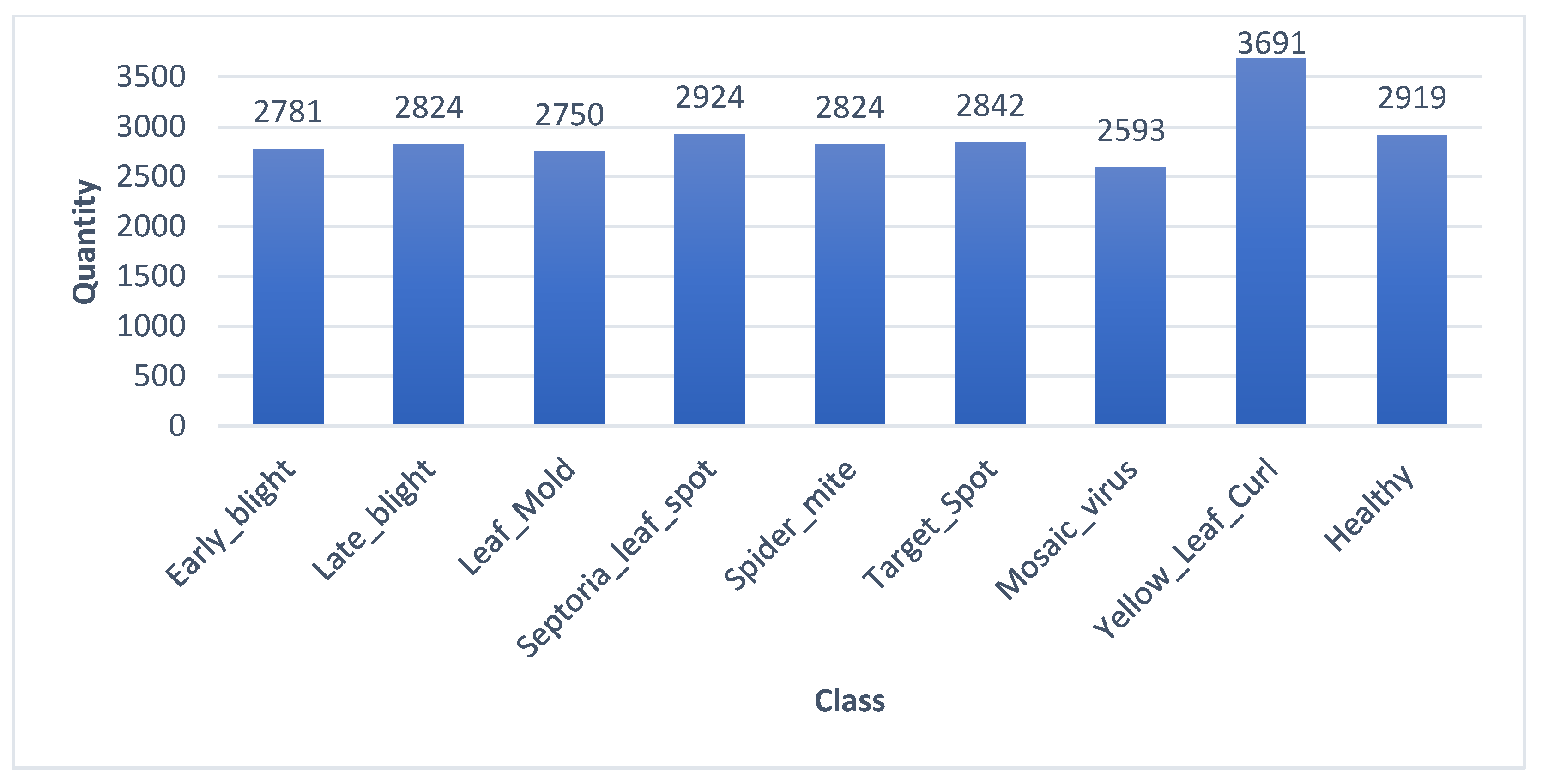
- The dataset significantly differs in the number of images for some classes. An imbalance of the classes can be observed mainly between the mosaic virus class and the yellow leaf curl class, as seen in Figure 2.
3.2. Metrics
- Accuracy (1): The overall accuracy of a model is simply the number of correct predictions divided by the total number of predictions. The model’s prediction accuracy is measured as a percentage value between 0 and 1, with a value of 1 indicating a perfectly performing model. Accuracy can be defined as the ratio of correct predictions to the total number of predictions.
- Precision (2): Measures how well the model correctly identifies the positive class. Using only this metric to optimize a model would minimize false positives.
- Recall (3): Measures how good the model is at correctly predicting all positive observations in the dataset. However, it does not include information on false positives.
- F1-score (4): The harmonic mean of Precision and Recall. The F1-score returns a number in a range between 0 and 1. If the value is 1, this indicates perfect Precision and Recall. If the value is 0, the Precision or Recall is 0. The higher the value of F1, it can be said that there is better the balance between the two metrics.where:
- TP (True Positives): The number of positive observations the model correctly predicted as positive.
- FP (False Positive): The number of negative observations the model incorrectly predicted as positive.
- TN (True Negative): The number of negative observations the model correctly predicted as negative.
- FN (False Negative): The number of positive observations the model incorrectly predicted as negative.
3.3. Convolutional Neural Networks (CNNs) Selected for This Research
3.4. Method for Hyperparameter Optimization
- Optimization with Genetic Algorithms does not require any probabilistic model and works directly with the objective function. On the other hand, Bayesian Optimization uses a surrogate function, making it more efficient in using computational resources since it simplifies the original function, typically unknown in the case of neural networks.
- This means that fewer experiments are needed to achieve acceptable results. Furthermore, although in some studies, the results with Genetic Algorithms are better, the difference is insignificant.
- Genetic Algorithms have excellent parallelism capabilities, so the genetic algorithm performs very well when solutions are stored in memory, which can be improved over time. On the other hand, Bayesian Optimization cannot exploit parallelism because each experiment depends on the previous one. This makes optimization with Genetic Algorithms a more computationally demanding method.
- More characteristics differentiate them, but for this study, the requirement of less computational capacity by Bayesian Optimization makes it more suitable for selecting hyperparameters. Consequently, this was the method selected.
4. Results and Analysis
4.1. Effect of Leaf Shape on Disease Classification
- ✓
- Binary segmentation was performed with Naïve Bayes classifier to obtain the silhouette of the leaves (Figure 3).
- ✓
- Data augmentation was performed to eliminate the negative effect of data imbalance over the silhouette dataset.
- ✓
- Training of the ResNet-50 model was carried out with the binary images, similar to [24].
- ✓
- The hyperparameters used for model training were learning rate = 0.00234, optimizer = SGD (Stochastic Gradient Descent), epochs = 20, loss = categorical cross-entropy.

4.2. Plant Disease Detection Strategy Based on Image Texture
- (a)
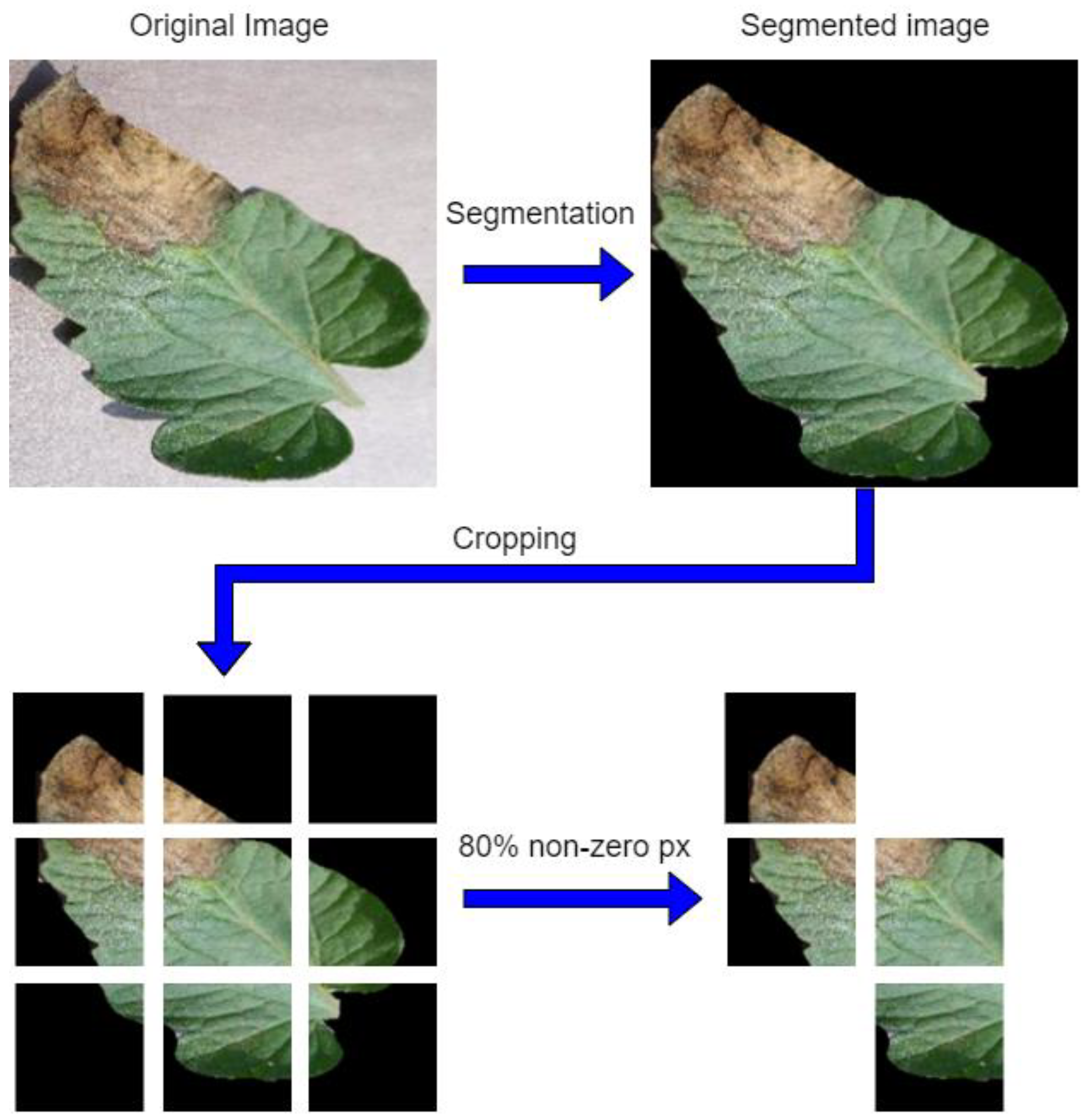
- The original images were segmented to remove background noise. This was performed with the segmentation method based on the machine learning Naive Bayes Algorithm.
- (b)
- The segmented image was subdivided into nine tiles of 85 × 85 × 3 pixels each, and only those with more than 80% of pixels corresponding to the object of interest (the leaves) were selected; the other tiles were eliminated (Figure 6).
- (c)
- The selected tiles formed the dataset for training. Figure 7 shows an example of each class of the new dataset. The bacterial spot class was removed because it presents different stages of the disease in the original dataset, which represents an additional challenge since the early stages present significant similarities with the healthy class and do not allow its correct classification.
4.3. Data Balance
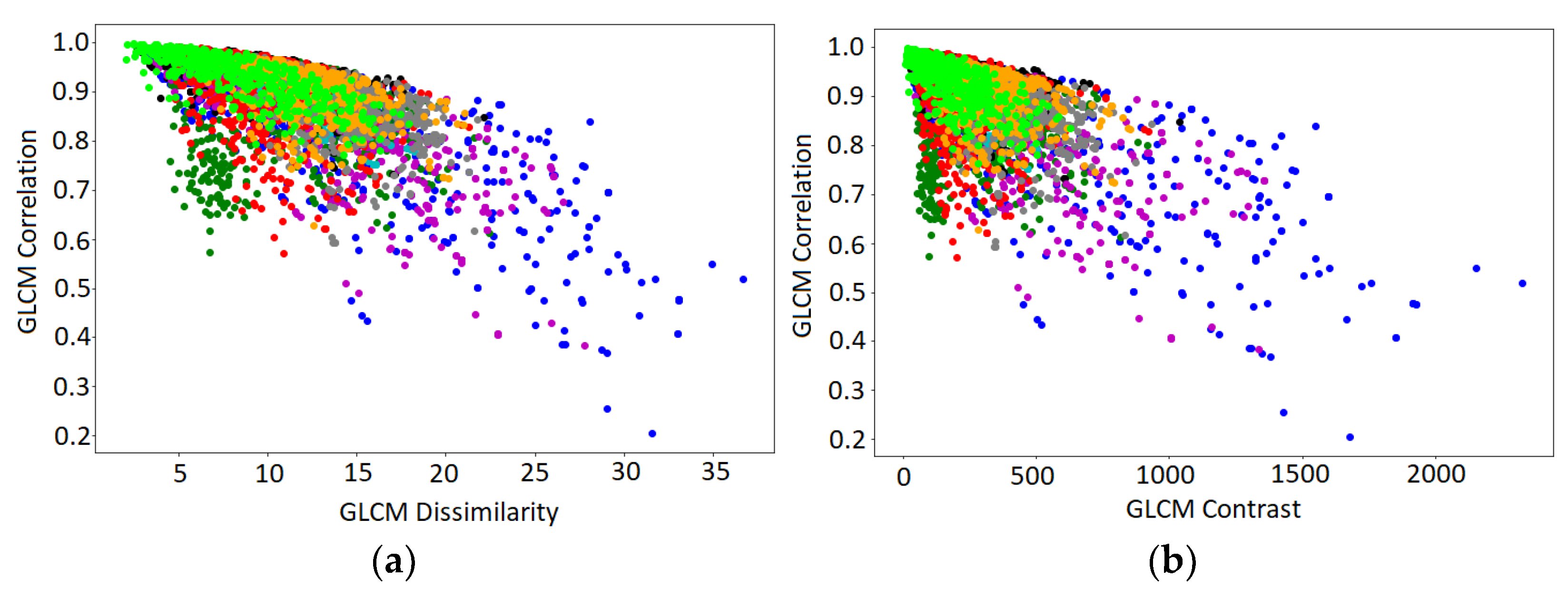
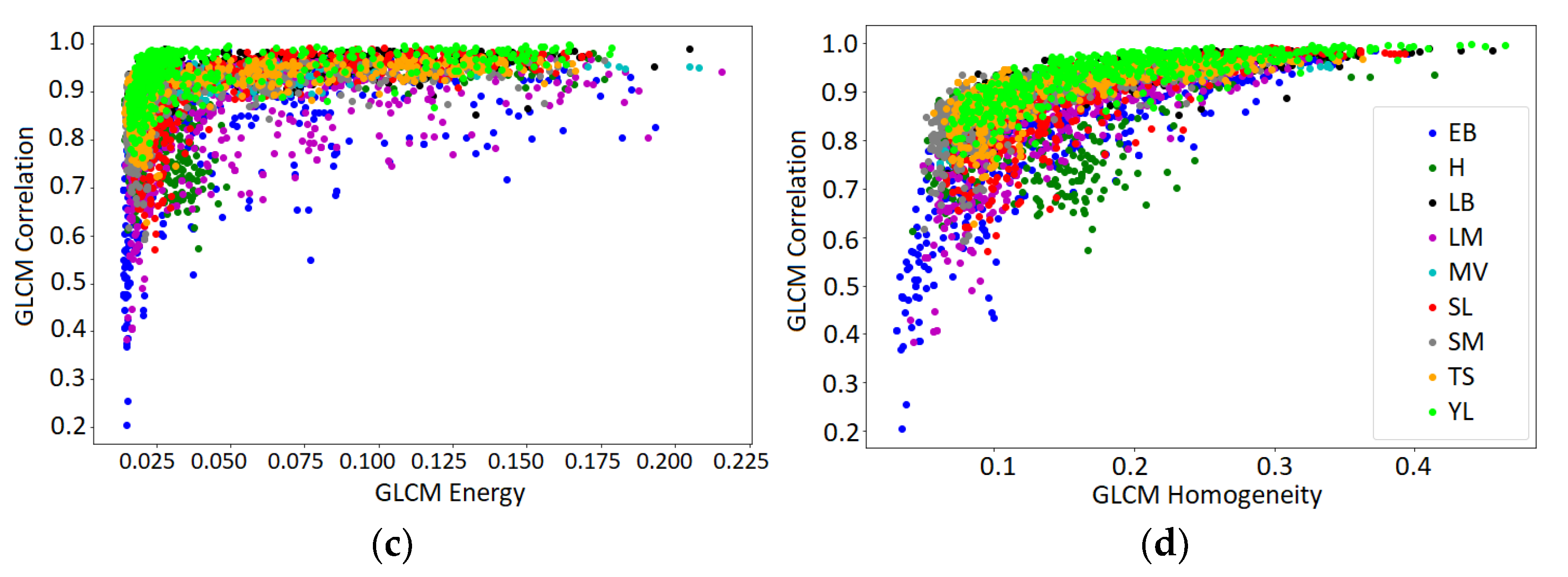
4.4. Predictive Power of Texture Features
- i = row number.
- j = column number.
- µ = mean of the GLCM (an estimate of all pixel intensities that contribute to the GLCM).
- σ = variance of the pixel intensities that contribute to the GLCM.
- C = element ij of the normalized GLCM.
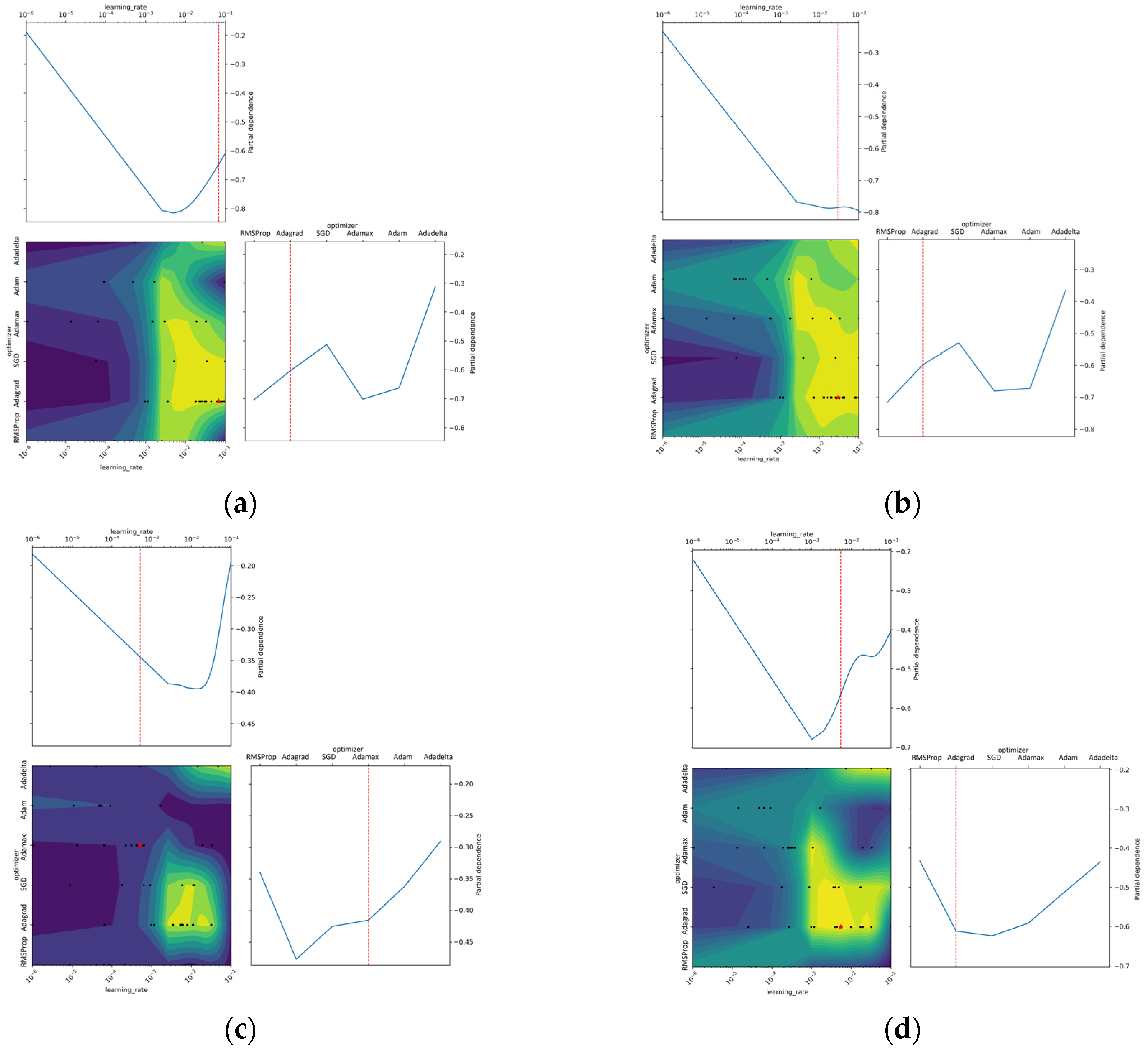
4.5. Hyperparameter Optimization
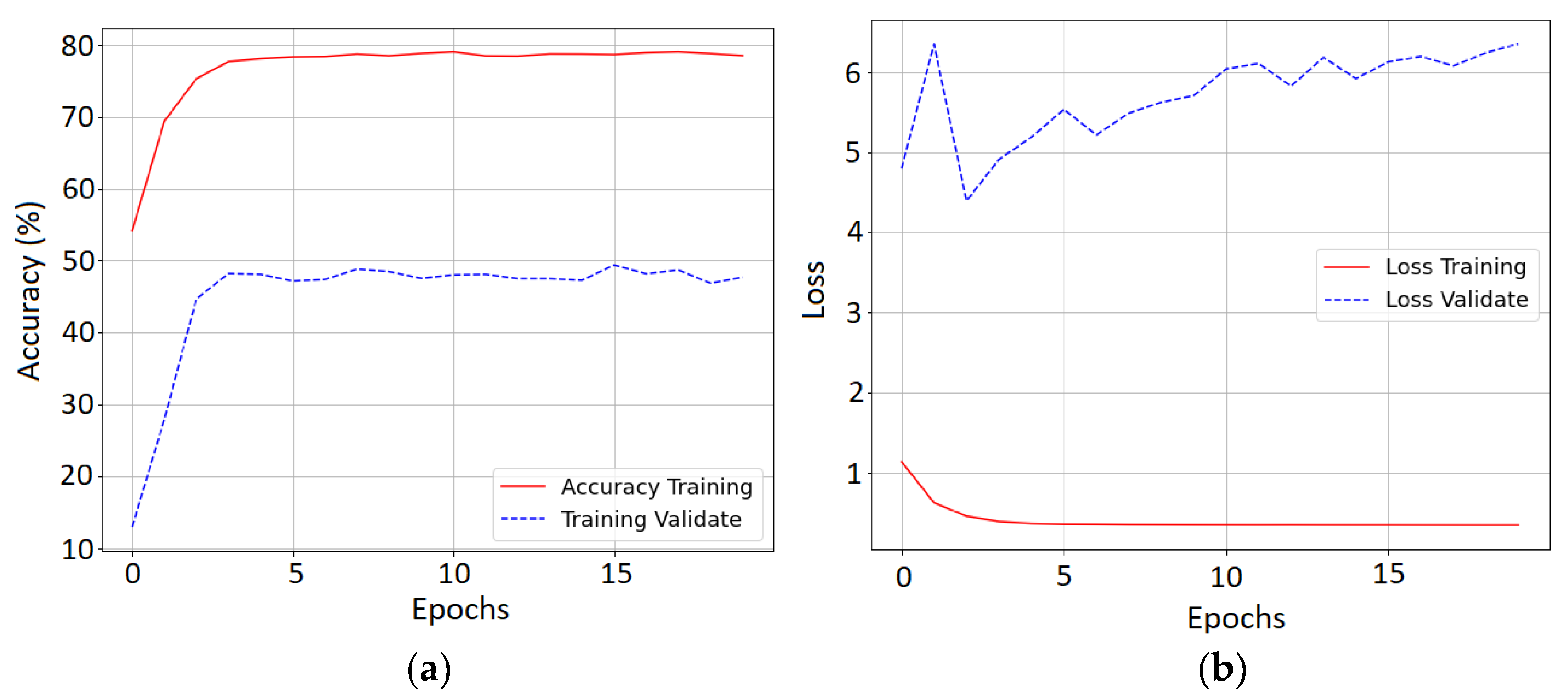
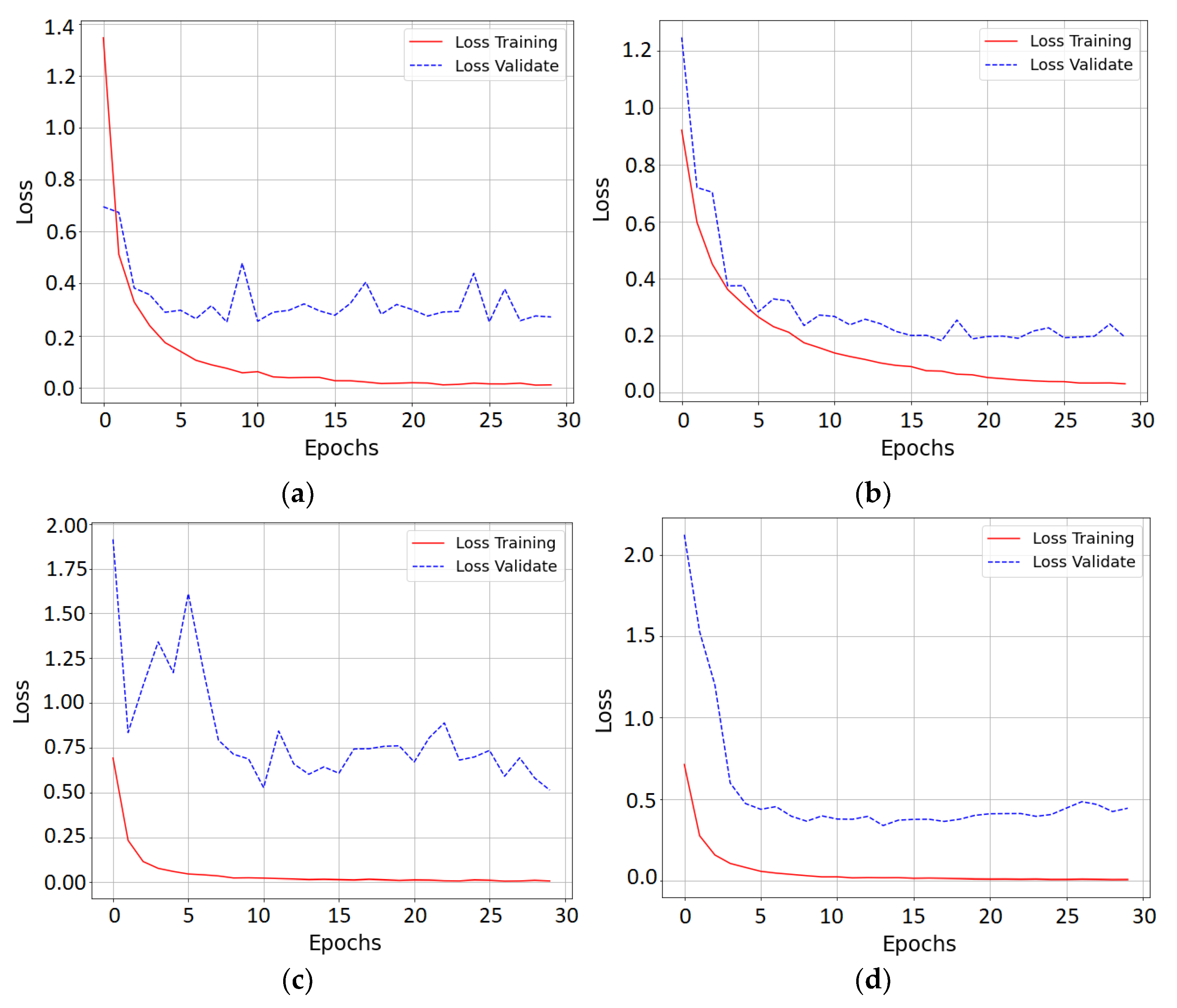
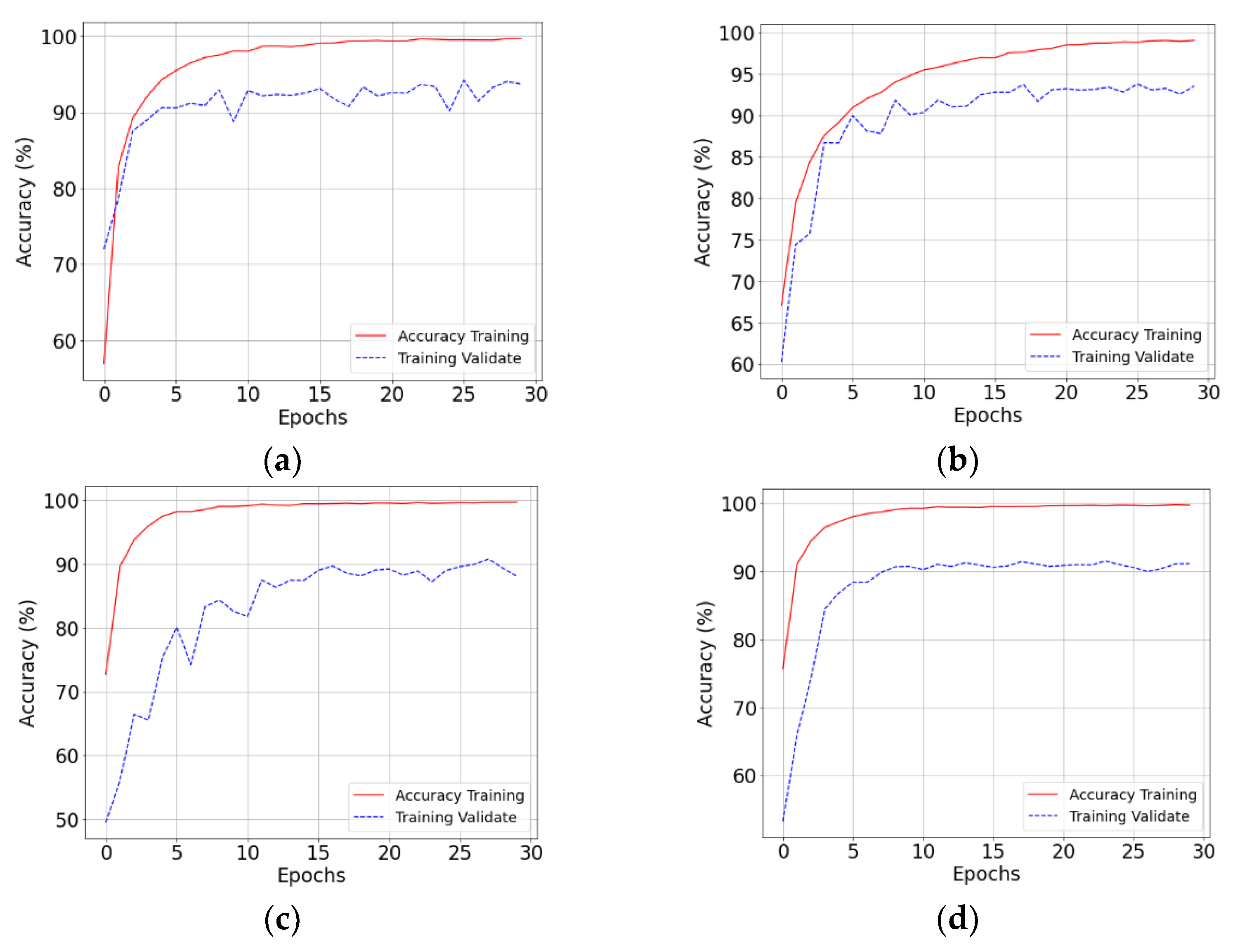
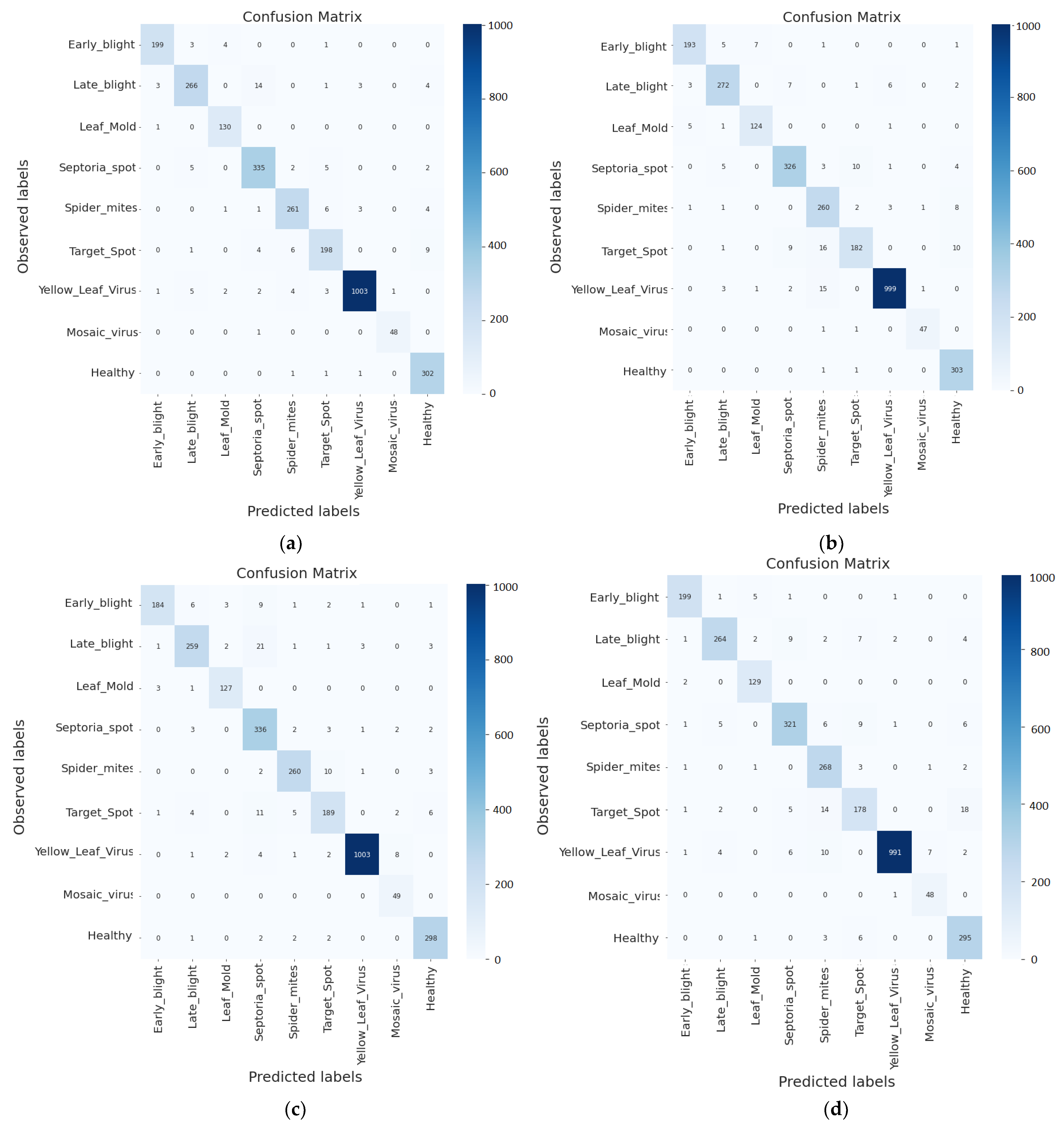
4.6. Training Results
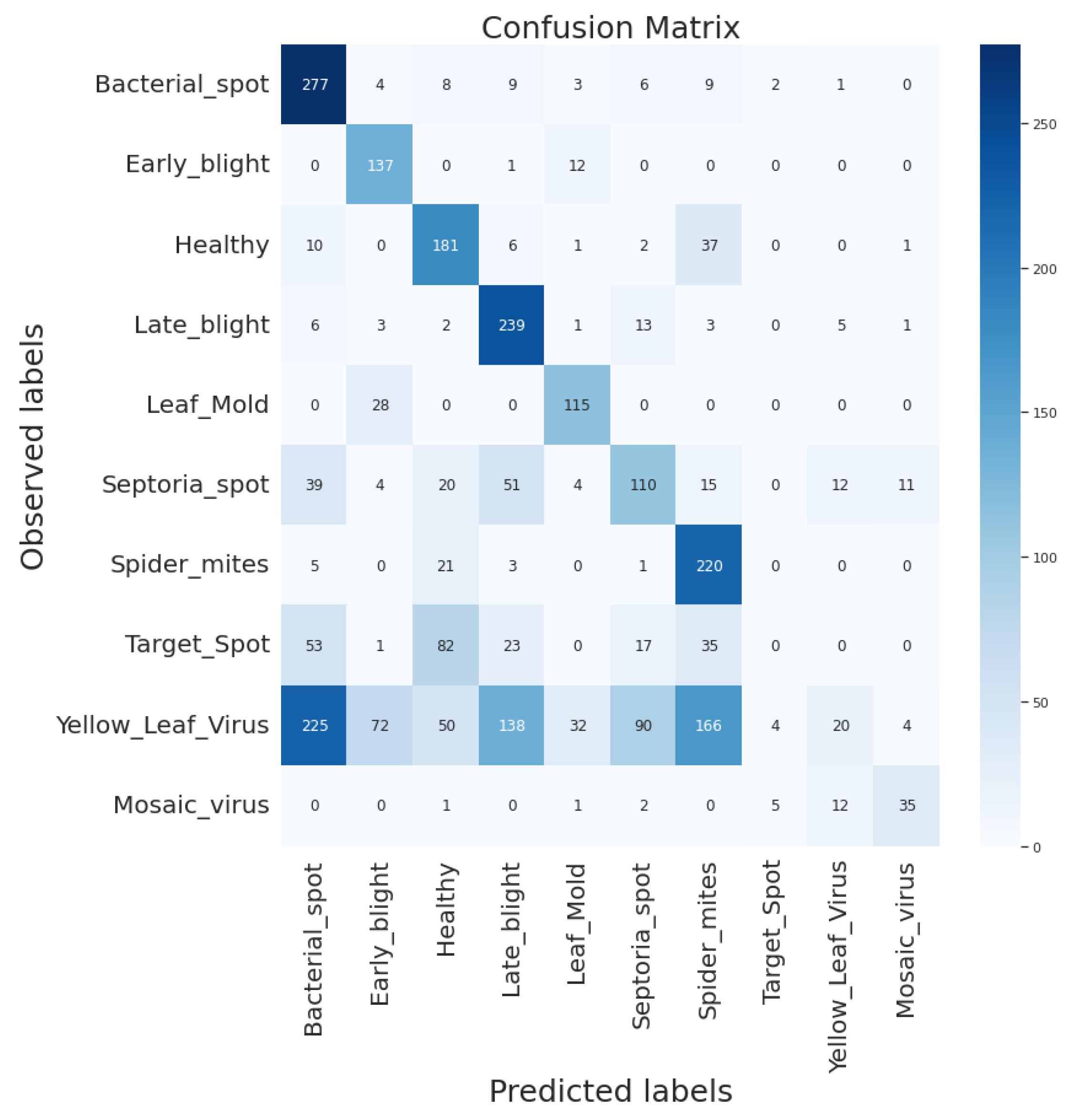
4.7. Analysis
- i.
- The loss of crops represents high costs. Consequently, action must be taken quickly to control the disease’s focus and not apply chemical agents to larger areas.
- ii.
- The correct detection of the disease is necessary so as not to apply the wrong control agents, which can cause an increase in the resistance of the disease to subsequent controls.
5. Conclusions, Limitations, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- FAO. New Standards to Curb the Global Spread of Plant Pests and Diseases. 2019. Available online: https://www.fao.org/news/story/en/item/1187738/icode/ (accessed on 26 June 2022).
- Vishnoi, V.K.; Kumar, K.; Kumar, B. Plant disease detection using computational intelligence and image processing. J. Plant Dis. Prot. 2020, 128, 19–53. [Google Scholar] [CrossRef]
- Shurtleff, M.C.; Pelczar, M.J.; Kelman, A.; Pelczar, R.M. Plant disease. In Plant Pathology; Encyclopedia Britannica: Chicago, IL, USA, 2020; Available online: https://www.britannica.com/science/plant-disease (accessed on 3 March 2022).
- Balram, G.; Kumar, K.K. Smart farming: Disease detection in crops. Int. J. Eng. Technol. 2018, 7, 33–36. [Google Scholar] [CrossRef] [Green Version]
- Nagaraju, M.; Chawla, P. Systematic review of deep learning techniques in plant disease detection. Int. J. Syst. Assur. Eng. Manag. 2020, 11, 547–560. [Google Scholar] [CrossRef]
- Hlaing, C.S.; Zaw, S.M.M. Tomato Plant Diseases Classification Using Statistical Texture Feature and Color Feature. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 439–444. [Google Scholar] [CrossRef]
- Ahmad, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U.; Anwar, S.; Anjum, M.R. Leaf Image-Based Plant Disease Identification Using Color and Texture Features. Wirel. Pers. Commun. 2021, 121, 1139–1168. [Google Scholar] [CrossRef]
- Anjna; Sood, M.; Singh, P.K. Hybrid System for Detection and Classification of Plant Disease Using Qualitative Texture Features Analysis. Procedia Comput. Sci. 2020, 167, 1056–1065. [Google Scholar] [CrossRef]
- Hossain, E.; Hossain, F.; Rahaman, M. A Color and Texture Based Approach for the Detection and Classification of Plant Leaf Disease Using KNN Classifier. Available online: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8679247&casa_token=5JO9r1u5jY0AAAAA:OJrFyWAj5u93OE_CTKS3rBwjh0vBLhk3FpYeHtDvAp_bY4cz4l67Fbu1cTCoLgDqKjnplV6DoyFS&tag=1 (accessed on 21 August 2022).
- Hughes, D.P.; Salathé, M. An Open Access Repository of Images on Plant Health to Enable the Development of Mobile Disease Diagnostics. 2015. Available online: https://doi.org/10.48550/ARXIV.1511.08060 (accessed on 20 July 2021).
- Hidayatuloh, A.; Nursalman, M.; Nugraha, E. Identification of Tomato Plant Diseases by Leaf Image Using Squeezenet Model. In Proceedings of the 2018 International Conference on Information Technology Systems and Innovation (ICITSI), Bandung, Indonesia, 22–26 October 2018. [Google Scholar]
- Kaur, M.; Bhatia, R. Development of an improved tomato leaf disease detection and classification method. In Proceedings of the 2019 IEEE Conference on Information and Communication Technology, Baghdad, Iraq, 15–16 April 2019; pp. 1–5. [Google Scholar]
- Agarwal, M.; Singh, A.; Arjaria, S.; Sinha, A.; Gupta, S. ToLeD: Tomato Leaf Disease Detection using Convolution Neural Network. Procedia Comput. Sci. 2020, 167, 293–301. [Google Scholar] [CrossRef]
- Gunarathna, M.; Rathnayaka, R. Experimental Determination of CNN Hyper-Parameters for Tomato Disease Detection using Leaf Images. In Proceedings of the 2nd International Conference on Advancements in Computing, Malabe, Sri Lanka, 10–11 December 2020; pp. 464–469. [Google Scholar] [CrossRef]
- Hong, H.; Lin, J.; Huang, F. Tomato disease detection and classification by deep learning. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering, Fuzhou, China, 12–14 June 2020; pp. 25–29. [Google Scholar]
- Jiang, D.; Li, F.; Yang, Y.; Yu, S. A Tomato Leaf Diseases Classification Method Based on Deep Learning. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 1446–1450. [Google Scholar] [CrossRef]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Plant Disease Classification: A Comparative Evaluation of Convolutional Neural Networks and Deep Learning Optimizers. Plants 2020, 9, 1319. [Google Scholar] [CrossRef] [PubMed]
- Kibriya, H.; Rafique, R.; Ahmad, W.; Adnan, S. Tomato Leaf Disease Detection Using Convolution Neural Network. In Proceedings of the 18th International Bhurban Conference on Applied Sciences and Technologies, Islamabad, Pakistan, 12–16 January 2021; pp. 346–351. [Google Scholar] [CrossRef]
- Peyal, H.I.; Shahriar, S.M.; Sultana, A.; Jahan, I.; Mondol, H. Detection of Tomato Leaf Diseases Using Transfer Learning Architectures: A Comparative Analysis. In Proceedings of the 2021 International Conference on Automation, Control and Mechatronics for Industry 4.0 (ACMI), Rajshahi, Bangladesh, 8–9 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Sujatha, R.; Chatterjee, J.M.; Jhanjhi, N.; Brohi, S.N. Performance of deep learning vs machine learning in plant leaf disease detection. Microprocess. Microsyst. 2020, 80, 103615. [Google Scholar] [CrossRef]
- Younis, H.; Khan, M.Z.; Mukhtar, H. Robust Optimization of MobileNet for Plant Disease Classification with Fine Tuned Parameters. In Proceedings of the2021 International Conference on Artificial Intelligence, Suzhou, China, 15–17 October 2021; pp. 146–151. [Google Scholar] [CrossRef]
- Panno, S.; Davino, S.; Caruso, A.G.; Bertacca, S.; Crnogorac, A.; Mandić, A.; Noris, E.; Matić, S. A Review of the Most Common and Economically Important Diseases That Undermine the Cultivation of Tomato Crop in the Mediterranean Basin. Agronomy 2021, 11, 2188. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7, 1419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wspanialy, P.; Moussa, M. A detection and severity estimation system for generic diseases of tomato greenhouse plants. Comput. Electron. Agric. 2020, 178, 105701. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 17, 168–192. [Google Scholar] [CrossRef]
- Howard, A.G. Mobile Nets: Efficient Convolutional Neural Networks for Mobile Vision Applications. 2017. Available online: http://arxiv.org/abs/1704.04861 (accessed on 20 July 2021).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.v. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 10691–10700. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5MB Model Size. 2016. Available online: http://arxiv.org/abs/1602.07360 (accessed on 20 July 2021).
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Jiménez, B.; Lázaro, J.L.; Dorronsoro, J.R. Finding optimal model parameters by deterministic and annealed focused grid search. Neurocomputing 2009, 72, 2824–2832. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization Yoshua Bengio. 2012. Available online: http://scikit-learn.sourceforge.net (accessed on 20 July 2021).
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter optimization for machine learning models based on Bayesian optimization b. J. Electron. Sci. 2019, 17, 26–40. [Google Scholar] [CrossRef]
- Aszemi, N.M.; Dominic, P. Hyperparameter Optimization in Convolutional Neural Network using Genetic Algorithms. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 269–278. Available online: www.ijacsa.thesai.org (accessed on 10 August 2021). [CrossRef] [Green Version]
- Liashchynskyi, P.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. 2017. Available online: http://arxiv.org/abs/1912.06059 (accessed on 8 July 2022).
- Alibrahim, H.; Ludwig, S.A. Hyperparameter Optimization: Comparing Genetic Algorithm against Grid Search and Bayesian Optimization. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), 28 June–1 July 2021; pp. 1551–1559. [Google Scholar] [CrossRef]
- González, J. Still Optimizing in the Dark? Bayesian Optimization for Model Configuration and Experimental Design. University of Sheffield, Sheffield, UK. 2016. Available online: http://javiergonzalezh.github.io/presentations/talk_groningen2016.pdf (accessed on 10 August 2022).
- Bochinski, E.; Senst, T.; Sikora, T. Hyper-parameter optimization for convolutional neural network committees based on evolutionary algorithms. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3924–3928. [Google Scholar] [CrossRef] [Green Version]
- Tani, L.; Rand, D.; Veelken, C.; Kadastik, M. Evolutionary algorithms for hyperparameter optimization in machine learning for application in high energy physics. Eur. Phys. J. C 2021, 81, 170. [Google Scholar] [CrossRef]
- Moosbauer, J.; Herbinger, J.; Casalicchio, G.; Lindauer, M.; Bischl, B. Explaining Hyperparameter Optimization via Partial Dependence Plots. Adv. Neural. Inf. Process Syst. 2021, 3, 2280–2291. [Google Scholar]
- Raheja, J.L.; Kumar, S.; Chaudhary, A. Fabric defect detection based on GLCM and Gabor filter: A comparison. Optik 2013, 124, 6469–6474. [Google Scholar] [CrossRef]
- Liu, X.; Aldrich, C. Deep Learning Approaches to Image Texture Analysis in Material Processing. Metals 2022, 12, 355. [Google Scholar] [CrossRef]
- Louppe, G.; Head, T.; Kumar, M.; Nahrstaedt, H.; Shcherbatyi, L. Scikit-Optimize. Available online: https://github.com/scikit-optimize (accessed on 5 June 2022).
- Molnar, C. Interpretable Machine Learning A Guide for Making Black Box Models Explainable. 2019. Available online: http://leanpub.com/interpretable-machine-learning (accessed on 10 August 2022).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Precision | Recall | F1-Score | Samples |
|---|---|---|---|---|
| Bacterial spot | 0.4504 | 0.8683 | 0.5931 | 319 |
| Early blight | 0.5502 | 0.9133 | 0.6867 | 150 |
| Healthy | 0.4959 | 0.7605 | 0.6003 | 238 |
| Late blight | 0.5085 | 0.8755 | 0.6433 | 273 |
| Leaf mold | 0.6805 | 0.8042 | 0.7372 | 143 |
| Septoria spot | 0.4564 | 0.4135 | 0.4339 | 266 |
| Spider mites | 0.4536 | 0.8800 | 0.5986 | 250 |
| Target spot | 0.0000 | 0.0000 | 0.0000 | 211 |
| Yellow leaf virus | 0.4000 | 0.0250 | 0.0470 | 801 |
| Mosaic virus | 0.6731 | 0.6250 | 0.6481 | 56 |
| Accuracy | 0.4928 | 2707 | ||
| Macro avg | 0.4669 | 0.6165 | 0.4988 | 2707 |
| Weighted avg | 0.4334 | 0.4928 | 0.3898 | 2707 |
| Class | Train | Validation | Test | Total |
|---|---|---|---|---|
| Early_blight | 2031 | 543 | 207 | 2781 |
| Late_blight | 2016 | 517 | 291 | 2824 |
| Leaf_Mold | 2088 | 531 | 131 | 2750 |
| Septoria_leaf_spot | 2014 | 561 | 349 | 2924 |
| Spider_mite | 2015 | 533 | 276 | 2824 |
| Target_Spot | 2084 | 540 | 218 | 2842 |
| Mosaic_virus | 2042 | 502 | 49 | 2593 |
| Yellow_Leaf_Curl | 2167 | 503 | 1021 | 3691 |
| Healthy | 2055 | 559 | 305 | 2919 |
| Total | 18,512 | 4789 | 2847 | 26,148 |
| Percentage | 71% | 18% | 11% | 100% |
| Model | Optimizer | Learning Rate | Accuracy |
|---|---|---|---|
| MobileNet | Adagrad | 0.06851166 | 0.9197443 |
| MobileNetV2 | Adagrad | 0.00537715 | 0.9088542 |
| SqueezeNet | Adagrad | 0.02899546 | 0.8979640 |
| NasNetMobile | Adamax | 0.00051483 | 0.8411458 |
| ShuffleNet | Adagrad | 0.03231302 | 0.8671875 |
| MobileNetV3 | SGD | 0.03170745 | 0.3214962 |
| EfficientNetB0 | Adamax | 1.06 × 10−6 | 0.1387311 |
| Model | Accuracy | Precision | Recall | F1-Score | Parameters | MB * |
|---|---|---|---|---|---|---|
| MobileNet | 96.31% | 95.55% | 95.93% | 95.72% | 3,762,056 | 28.7 |
| SqueezeNet | 95.05% | 93.98% | 93.95% | 93.91% | 120,760 | 1.2 |
| NasNetMobile | 95.01% | 92.73% | 94.22% | 93.29% | 5,495,132 | 64.7 |
| MobileNetV2 | 94.59% | 92.35% | 94.20% | 93.17% | 3,741,448 | 28.8 |
| ShuffleNet | 91.50% | 89.36% | 90.80% | 89.93% | 969,256 | 8.2 |
| Class | Precision | Recall | F1-Score | Samples |
|---|---|---|---|---|
| Early blight | 0.9755 | 0.9614 | 0.9684 | 207 |
| Healthy | 0.9408 | 0.9902 | 0.9649 | 305 |
| Late blight | 0.9500 | 0.9141 | 0.9317 | 273 |
| Leaf mold | 0.9489 | 0.9924 | 0.9701 | 131 |
| Septoria spot | 0.9384 | 0.9599 | 0.9490 | 349 |
| Spider mites | 0.9526 | 0.9457 | 0.9491 | 250 |
| Target spot | 0.9209 | 0.9083 | 0.9145 | 218 |
| Yellow leaf virus | 0.9931 | 0.9824 | 0.9877 | 1021 |
| Mosaic virus | 0.9796 | 0.9796 | 0.9796 | 305 |
| Accuracy | 0.9631 | 2847 | ||
| Macro avg | 0.9555 | 0.9593 | 0.9572 | 2847 |
| Weighted avg | 0.9634 | 0.9631 | 0.9631 | 2847 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Restrepo-Arias, J.F.; Branch-Bedoya, J.W.; Awad, G. Plant Disease Detection Strategy Based on Image Texture and Bayesian Optimization with Small Neural Networks. Agriculture 2022, 12, 1964. https://doi.org/10.3390/agriculture12111964
Restrepo-Arias JF, Branch-Bedoya JW, Awad G. Plant Disease Detection Strategy Based on Image Texture and Bayesian Optimization with Small Neural Networks. Agriculture. 2022; 12(11):1964. https://doi.org/10.3390/agriculture12111964
Chicago/Turabian StyleRestrepo-Arias, Juan Felipe, John W. Branch-Bedoya, and Gabriel Awad. 2022. "Plant Disease Detection Strategy Based on Image Texture and Bayesian Optimization with Small Neural Networks" Agriculture 12, no. 11: 1964. https://doi.org/10.3390/agriculture12111964