
Improved Cotton Seed Breakage Detection Based on YOLOv5s

Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Data Acquisition and Preprocessing
2.2. Damaged Cottonseed Detection Network
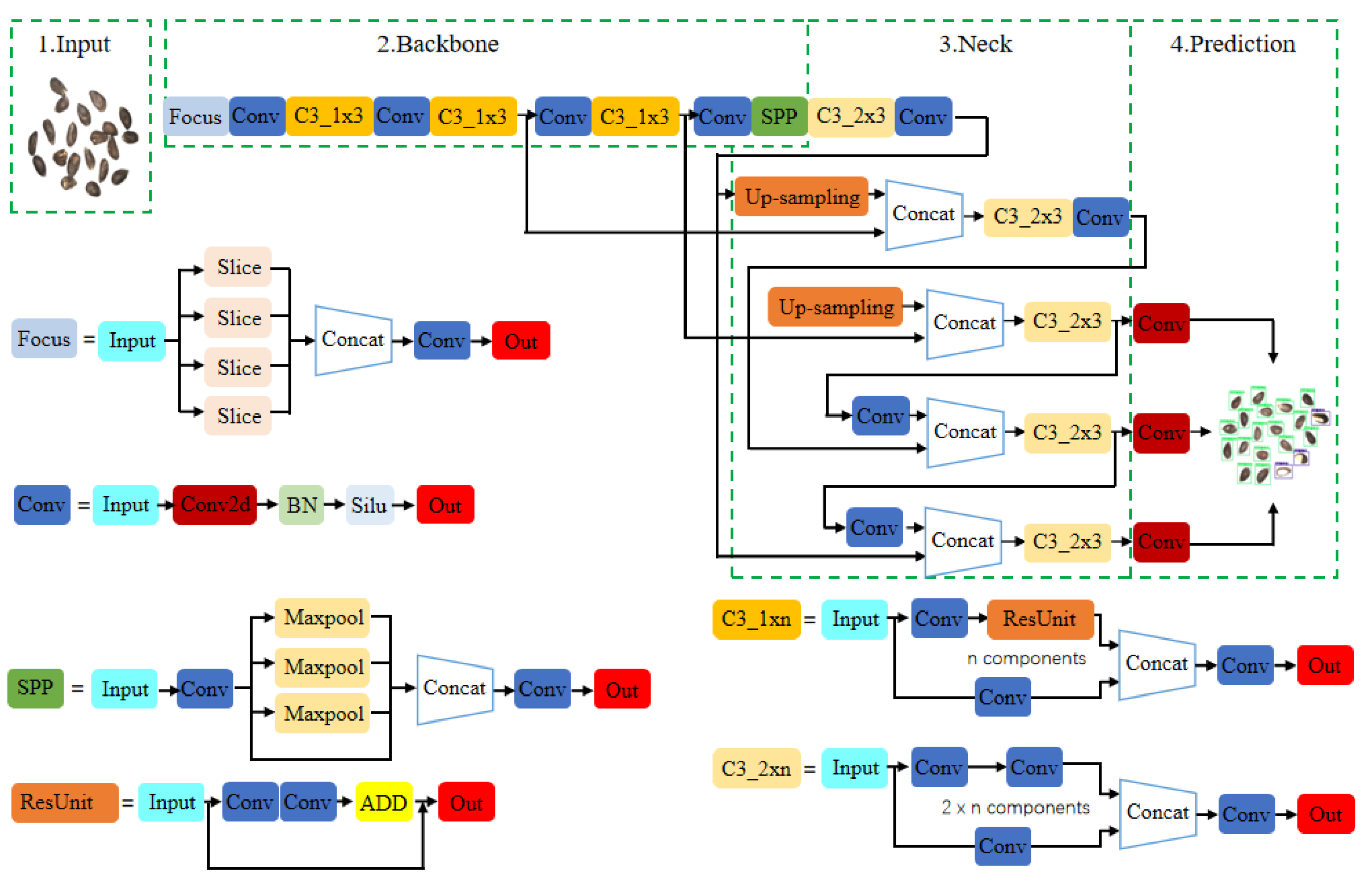
2.2.1. YOLOv5s Network Structure
2.2.2. Optimization of Backbone Network Layer
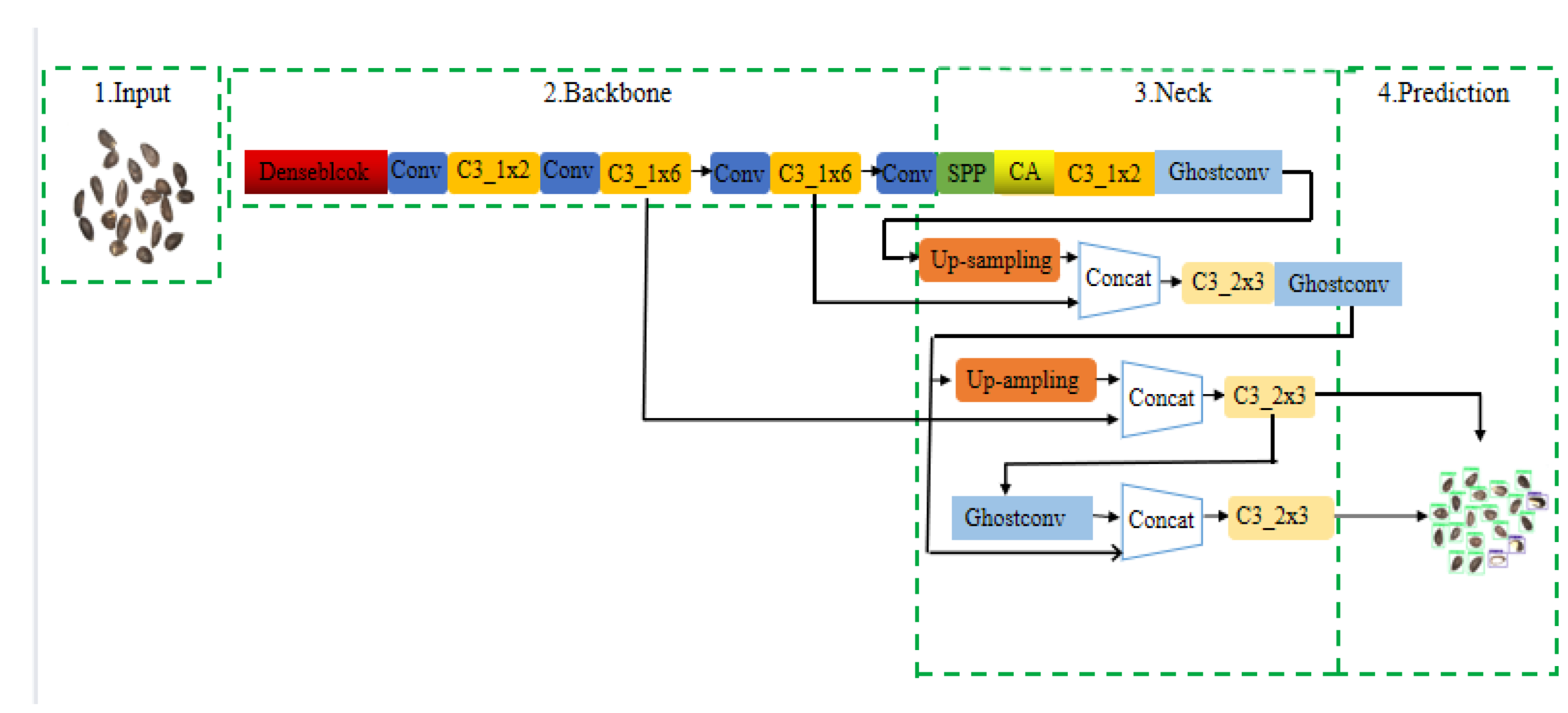
2.2.3. Denseblock Module
2.2.4. Embedded Collaborative Attention Mechanism
2.2.5. Ghostconv Convolution
2.2.6. Reduce the Detection Layer
2.2.7. Optimization of Loss Function
2.2.8. Improved YOLOv5s Network Structure
2.3. Model Training Metrics
2.4. Experimental Equipment and Parameter Settings
2.5. Training Results of Population Cottonseed Damage Model Based on YOLOv5s
3. Analysis of Results
3.1. Model Training Results
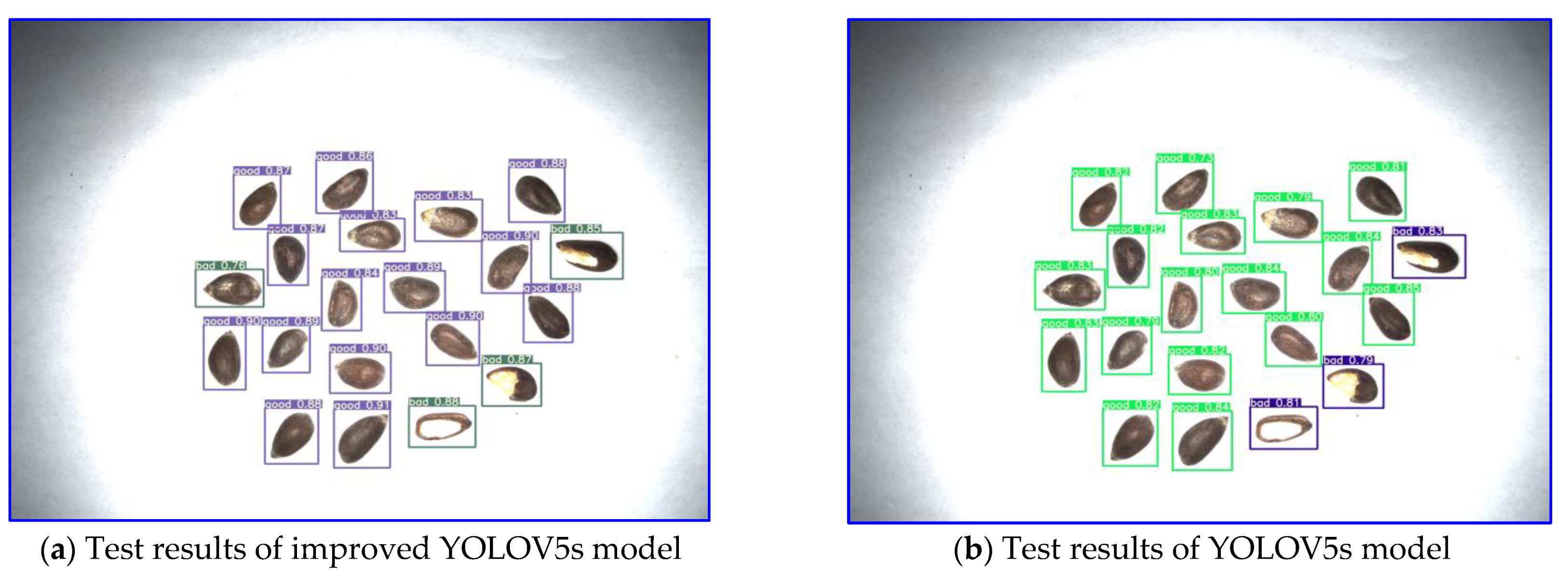
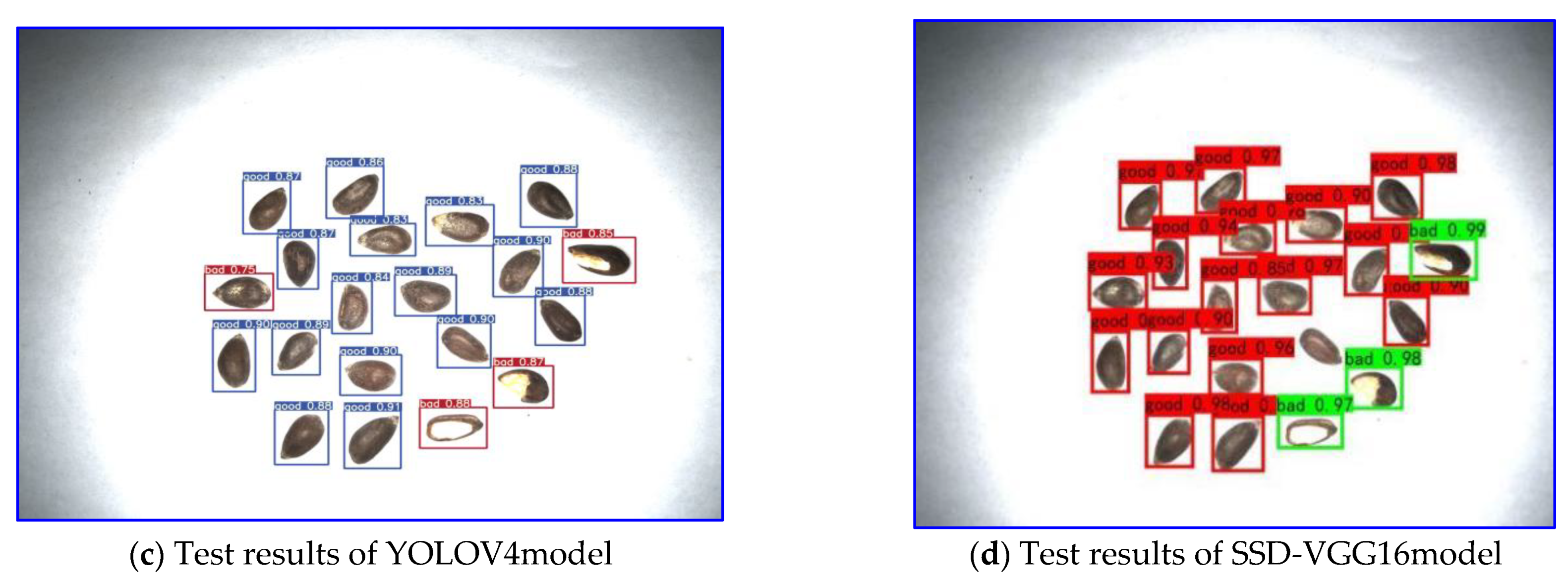
3.2. Analysis of Test Results under Different Models
3.3. Ablation Experiments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, L.; Zhang, K.; Yang, G.; Chu, J. Gesture recognition using dual-stream CNN based on fusion of sEMG energy kernel phase portrait and IMU amplitude image. Biomed. Signal Process. Control 2022, 73, 103364. [Google Scholar] [CrossRef]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef] [PubMed]
- Zhao-Zhao, J.; Yu-Fu, Z. Research on Application of Improved YOLO V3 Algorithm in Road Target Detection. J. Phys. Conf. Ser. 2020, 1654, 012060. [Google Scholar] [CrossRef]
- Ahmad, T.; Ma, Y.; Yahya, M.; Ahmad, B.; Nazir, S.; Haq, A.U. Object Detection through Modified YOLO Neural Network. Sci. Program. 2020, 2020, 8403262. [Google Scholar] [CrossRef]
- Jabir, B.; Falih, N. Deep learning-based decision support system for weeds detection in wheat fields. Int. J. Electr. Comput. Eng. 2022, 12, 816–825. [Google Scholar] [CrossRef]
- Tong, Y.; Ma, H.; Zhang, S.; Wu, X.; Chen, W. Research on Object Detection in Campus Scene Based on Faster R-CNN. J. Phys. Conf. Ser. 2022, 2203, 012050. [Google Scholar] [CrossRef]
- Wang, Y.; Cui, G.; Wang, S.; Zhang, J. Preceding Vehicle Detection Based on Optimized Faster R-CNN Algorithm. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021. [Google Scholar] [CrossRef]
- Yi, Z.; Yongliang, S.; Jun, Z. An improved tiny-yolov3 pedestrian detection algorithm. Optik 2019, 183, 17–23. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, W. Face Mask Wearing Detection Algorithm Based on Improved YOLO-v4. Sensors 2021, 21, 3263. [Google Scholar] [CrossRef]
- Hongwen, Y.; Zhenyu, L.; Qingliang, C.; Zhiwei, H.; Wen, L.Y. Detection of facial gestures of group pigs based on improved Tiny-YOLO. Trans. Chin. Soc. Agric. Eng. 2019, 35, 169–179. [Google Scholar]
- Yuanbing, L. Identification and Classification Method of Agricultural Diseases and Insect Pests Based on Yolov3. In Proceedings of the 2021 International Conference on Applied Mathematics, Modeling and Computer Simulation (AMMCS 2021), Wuhan, China, 13–14 November 2021; pp. 538–547. [Google Scholar]
- Du, S.; Zhang, P.; Zhang, B.; Xu, H. Weak and Occluded Vehicle Detection in Complex Infrared Environment Based on Improved YOLOv4. IEEE Access 2021, 9, 25671–25680. [Google Scholar] [CrossRef]
- Hou, X.; Ma, J.; Zang, S. Airborne infrared aircraft target detection algorithm based on YOLOv4-tiny. J. Phys. Conf. Ser. 2021, 1865, 042007. [Google Scholar] [CrossRef]
- Wang, G.; Ding, H.; Li, B.; Nie, R.; Zhao, Y. Trident-YOLO: Improving the precision and speed of mobile device object detection. IET Image Process. 2021, 16, 145–157. [Google Scholar] [CrossRef]
- Shi, D.; Tang, H. A New Multiface Target Detection Algorithm for Students in Class Based on Bayesian Optimized YOLOv3 Model. J. Electr. Comput. Eng. 2022, 2022, 1–12. [Google Scholar] [CrossRef]
- Xiao, X.; Huang, J.; Li, M.; Xu, Y.; Zhang, H.; Wen, C.; Dai, S. Fast recognition method for citrus under complex environments based on improved YOLOv3. J. Eng. 2022, 2022, 148–159. [Google Scholar] [CrossRef]
- Wang, H.; Shang, S.; Wang, D.; He, X.; Feng, K.; Zhu, H. Plant Disease Detection and Classification Method Based on the Optimized Lightweight YOLOv5 Model. Agriculture 2022, 12, 931. [Google Scholar] [CrossRef]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Fu, D.; Gao, L.; Hu, T.; Wang, S.; Liu, W. Research on Safety Helmet Detection Algorithm of Power Workers Based on Improved YOLOv5. J. Physics: Conf. Ser. 2022, 2171, 012006. [Google Scholar] [CrossRef]
- Zhang, X.; Yan, M.; Zhu, D.; Guan, Y. Marine ship detection and classification based on YOLOv5 model. J. Phys. Conf. Ser. 2022, 2181, 012025. [Google Scholar] [CrossRef]
- Song, Q.; Li, S.; Bai, Q.; Yang, J.; Zhang, X.; Li, Z.; Duan, Z. Object Detection Method for Grasping Robot Based on Improved YOLOv5. Micromachines 2021, 12, 1273. [Google Scholar] [CrossRef]
- Tian, M.; Liao, Z. Research on Flower Image Classification Method Based on YOLOv5. J. Phys. Conf. Ser. 2021, 2024, 012022. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Yan, J.; Qiu, X.; Yao, X.; Tian, Y.; Zhu, Y.; Cao, W. A Wheat Spike Detection Method in UAV Images Based on Improved YOLOv5. Remote Sens. 2021, 13, 3095. [Google Scholar] [CrossRef]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A Real-Time Detection Algorithm for Kiwifruit Defects Based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Jabir, B.; Falih, N.; Rahmani, K. Accuracy and Efficiency Comparison of Object Detection Open-Source Models. Int. J. Online Biomed. Eng. 2021, 17, 165–184. [Google Scholar] [CrossRef]
- Zhang, C.; Li, T.; Zhang, W. The Detection of Impurity Content in Machine-Picked Seed Cotton Based on Image Processing and Improved YOLO V4. Agronomy 2021, 12, 66. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Projects | Annotation Information | Training Sets | Testing Set | ||
|---|---|---|---|---|---|
| Intact Cotton Seeds (Good) Broken Cotton Seeds (Bad) | Number of Images | Number of Cotton Seeds | Number of Images | Number of Cotton Seeds | |
| Before data expansion | 450 | 9000 | 50 | 1000 | |
| After data expansion | 1350 | 24,000 | 150 | 3000 | |
| Parameters | Values |
|---|---|
| Input size | 640 × 640 |
| Batch size | 16 |
| Classes | 2 |
| Epoch | 300 |
| Learning rate | 0.01 |
| Termination learning rate | 0.2 |
| IOU threshold | 0.5 |
| Optimizer Prediction box size | SGD [10, 13, 16, 30, 33, 23] [30, 61, 62, 45, 59, 119] |
| Scale layer | [128, 256] |
| Models | Expanded Data | Denseblock | CoordAtt | Neck | CIOU Loss Function | Ghostconv | P | R | Map (%) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 82.7 | 87.9 | 91.7 | ||||||
| YOLOv5s | √ | 87.6 | 86.0 | 92.8 | |||||
| YOLOv5s | √ | √ | 86.1 | 86.5 | 93.4 | ||||
| YOLOv5s | √ | √ | √ | 87.8 | 90.1 | 94.5 | |||
| YOLOv5s | √ | √ | √ | √ | 87.4 | 90.3 | 95.0 | ||
| YOLOv5s | √ | √ | √ | √ | √ | 86.1 | 90.7 | 95.3 | |
| YOLOv5s | √ | √ | √ | √ | √ | √ | 92.4 | 91.7 | 98.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Lv, Z.; Hu, Y.; Dai, F.; Zhang, H. Improved Cotton Seed Breakage Detection Based on YOLOv5s. Agriculture 2022, 12, 1630. https://doi.org/10.3390/agriculture12101630
Liu Y, Lv Z, Hu Y, Dai F, Zhang H. Improved Cotton Seed Breakage Detection Based on YOLOv5s. Agriculture. 2022; 12(10):1630. https://doi.org/10.3390/agriculture12101630
Chicago/Turabian StyleLiu, Yuanjie, Zunchao Lv, Yingyue Hu, Fei Dai, and Hongzhou Zhang. 2022. "Improved Cotton Seed Breakage Detection Based on YOLOv5s" Agriculture 12, no. 10: 1630. https://doi.org/10.3390/agriculture12101630