
Study on the Detection of Defoliation Effect of an Improved YOLOv5x Cotton
 ,
, 
Abstract
:1. Introduction
2. Materials Acquisition
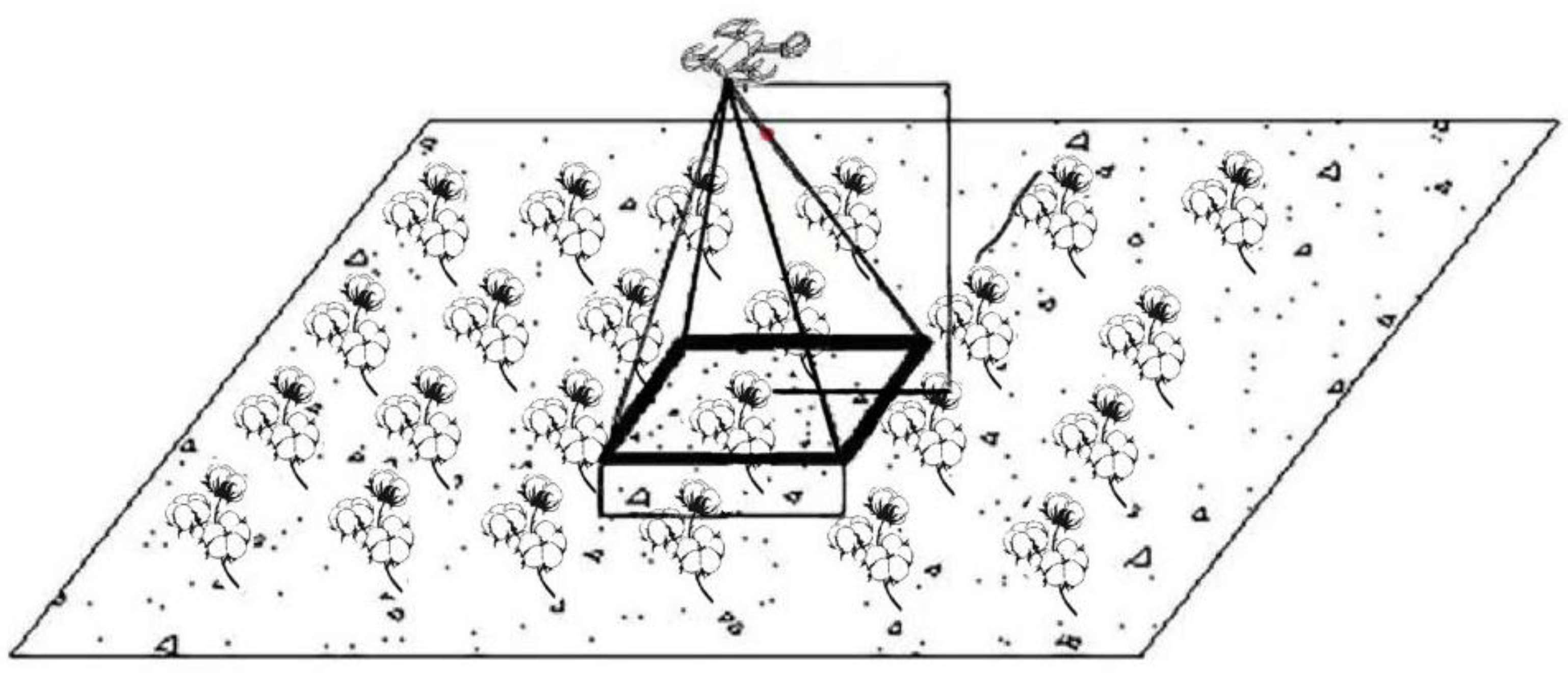
2.1. Experiment Device and Materials
2.2. Image Marking
3. Test Method
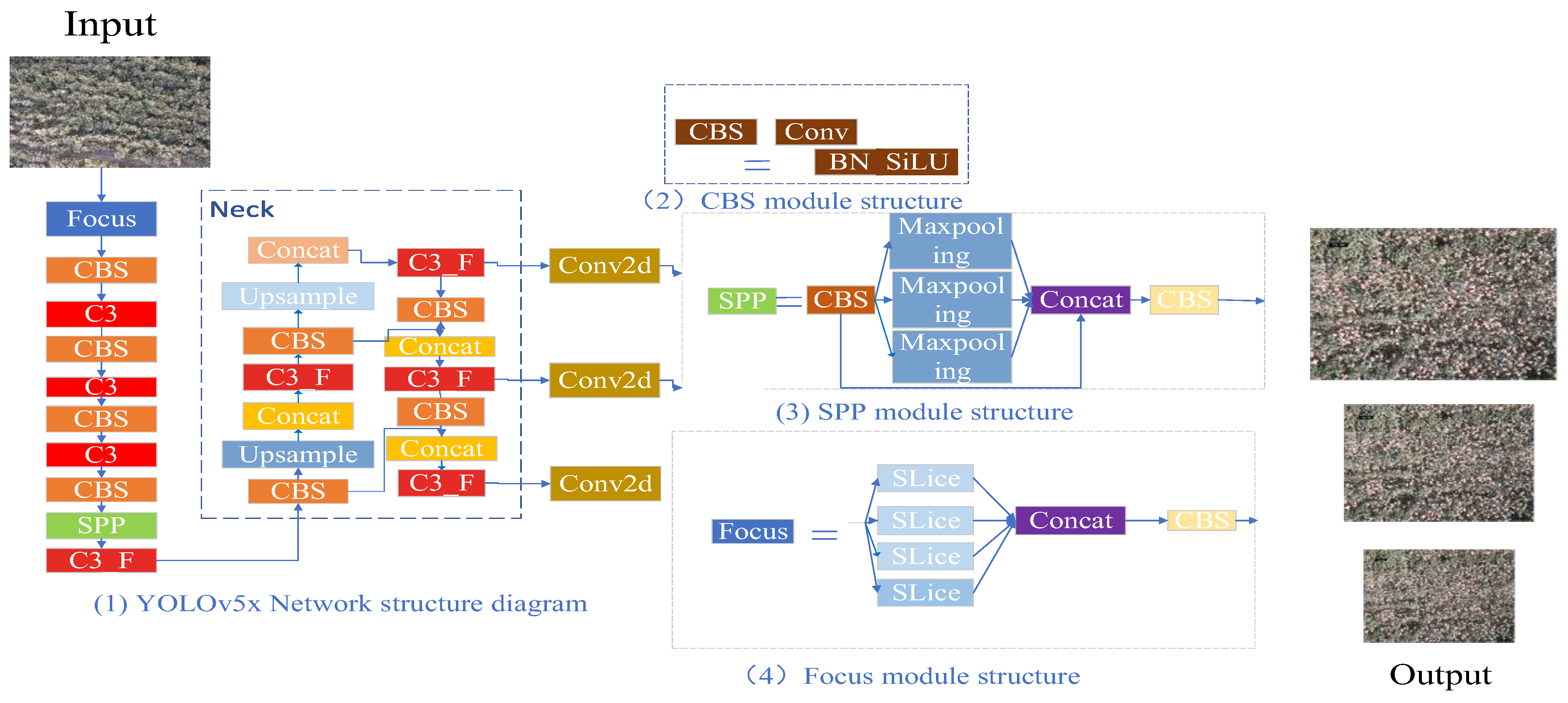
3.1. Detection Method Based on YOLOv5x
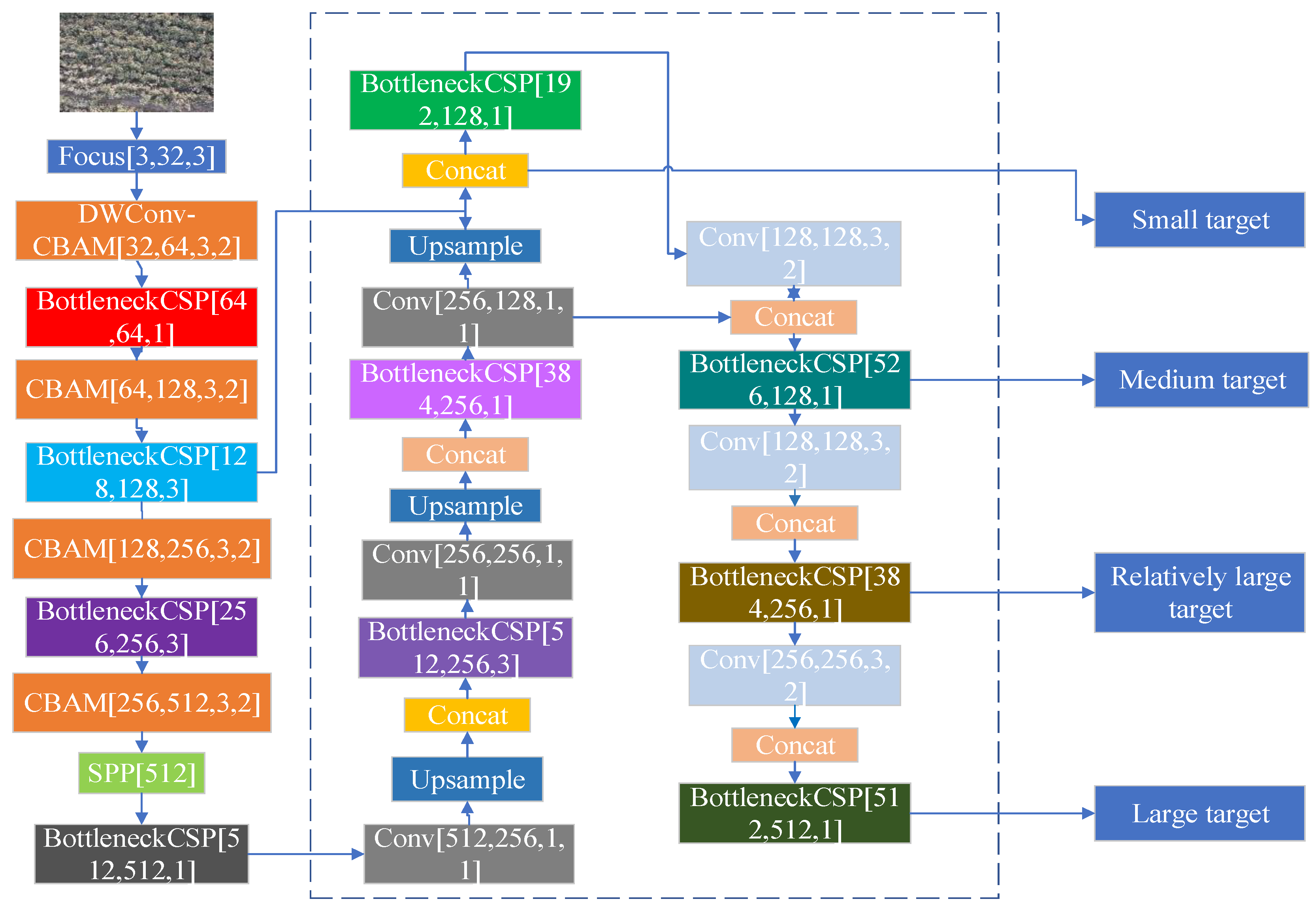
3.2. Detection Method Based on Improved YOLOv5x
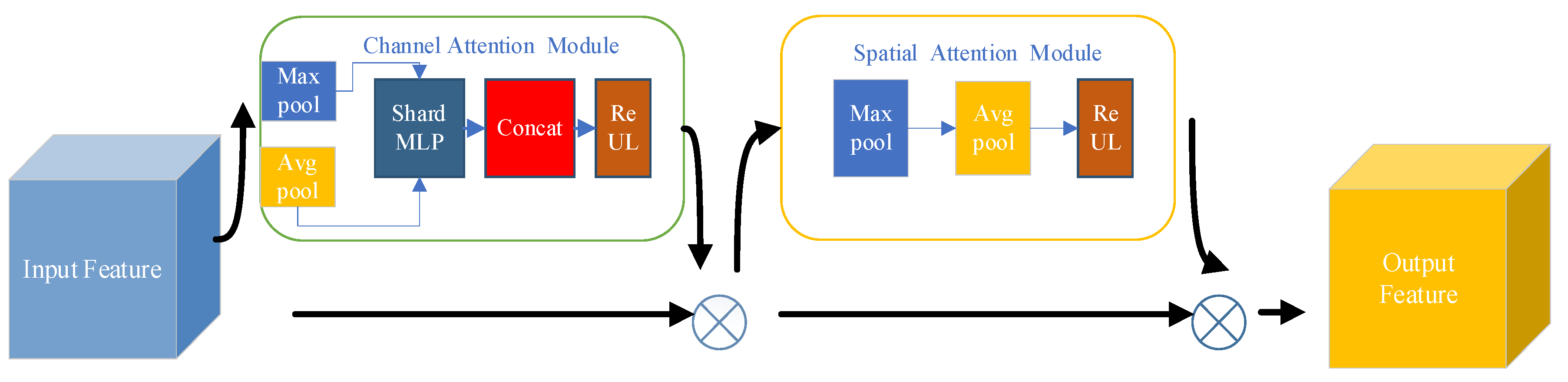
3.2.1. Attention Module (CBAM)
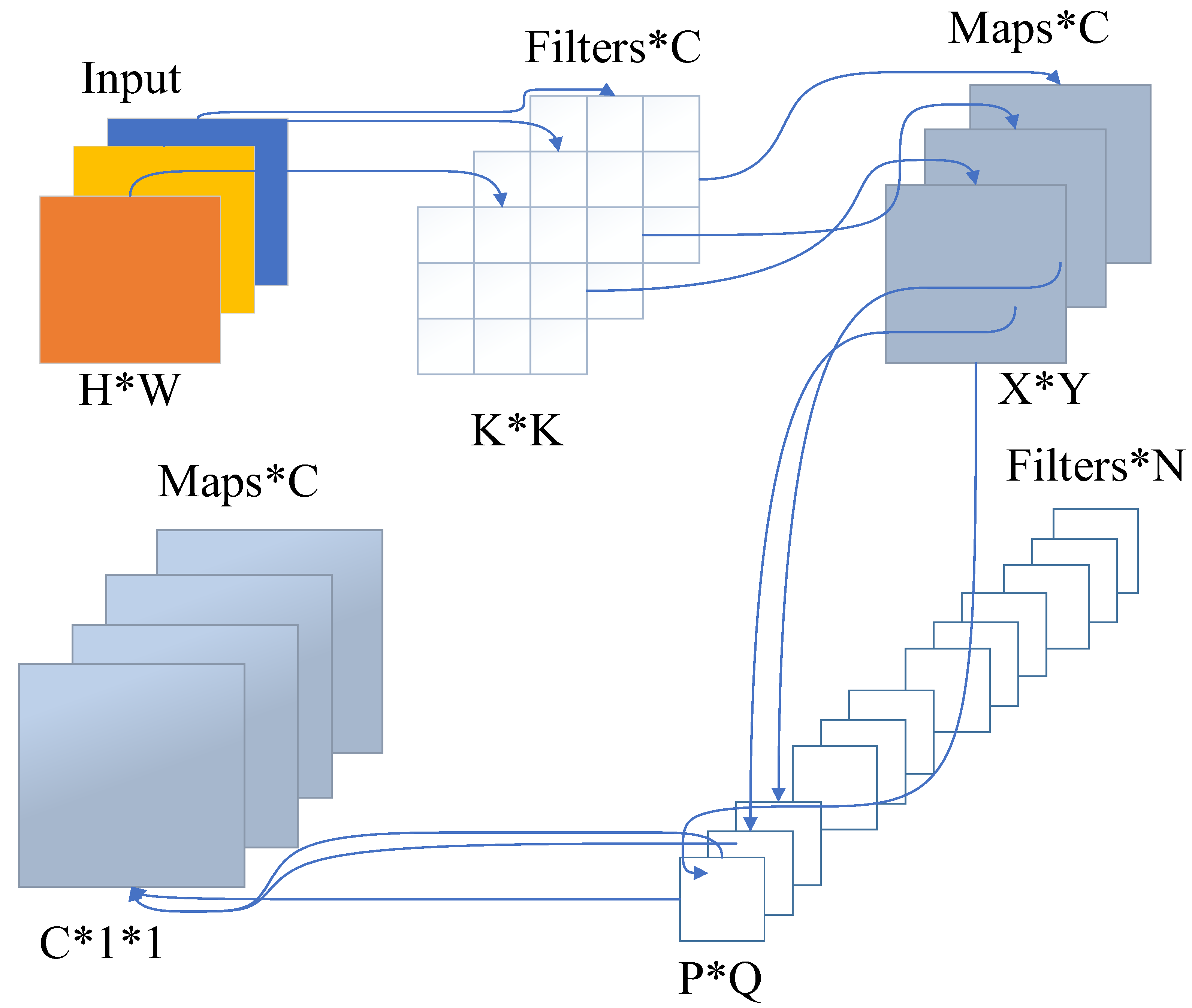
3.2.2. Deep Convolutional Neural Network
3.3. Small Size Cotton Detection Layer
4. Results
4.1. Training Platform
4.2. Network Training and Detection
4.2.1. Algorithm Training Parameters
4.2.2. Algorithm Training Parameters
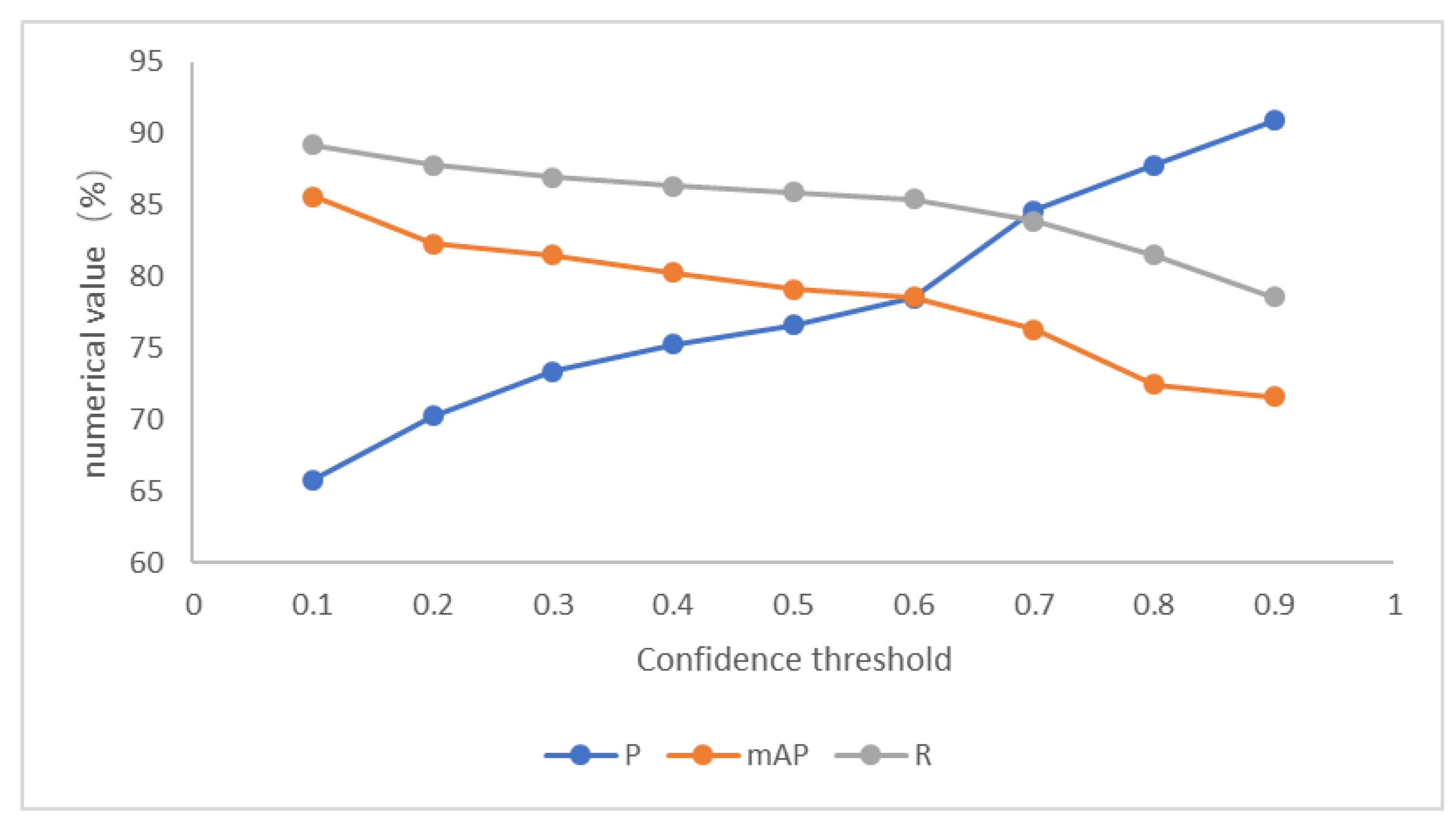
4.2.3. Determination of Optimal Threshold
4.3. Analysis of Test Results
4.4. Ablation Test
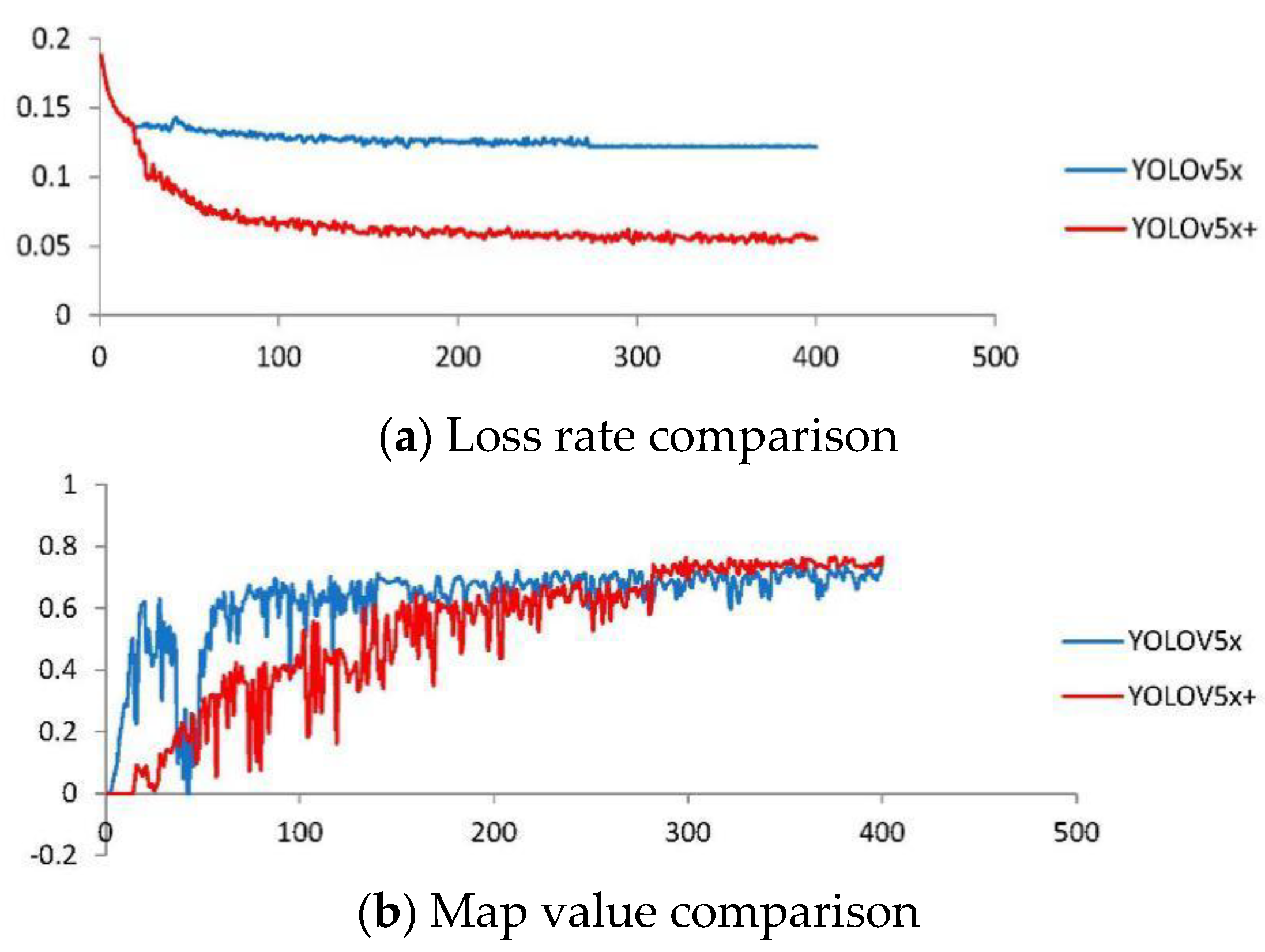
4.5. Comparison of Different Network Model Training
4.6. Analysis of Test Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lv, X.; Liang, B.; Zhang, L.; Ma, F.; Wang, H.; Liu, Y.; Gao, P.; Zhang, Z.; Hou, T. Construction of an Agricultural Big Data Plat-form for XPCC Cotton Production. J. Agric. Big Data 2020, 2, 70–78. [Google Scholar] [CrossRef]
- Mao, S.; Li, Y.; Wang, Z.; Lei, Y.; Huang, Q.; Wang, W.; Yang, B.; Feng, L.; Li, P. Transformation and Upgrading of China’s Cotton Industry under the Background of Agricultural High-quality Development. Agric. Outlook 2018, 14, 39–45. [Google Scholar]
- Chen, M.; Yang, Y.; Wang, Y.; Tian, J.; Xu, S.; Liu, N.; Dangke Zhang, W. Plant Type Characteristics and Evolution of Main Economic Characters in Early Maturing Upland Cotton Cultivar Replacement in Xinjiang. Sci. Agric. Sin. 2019, 52, 3279–3290. [Google Scholar] [CrossRef]
- Liu, C. Effects of Different Defoliants and Their Influence on Cotton Yield and Quality; Tarim University: Alar, China, 2021. [Google Scholar] [CrossRef]
- Zhou, X.; Qin, Q.; Wang, L.; Li, L.; Hu, C.; Hong, X.; Wang, W.; Zhu, H. Influence of Defoliant on Defoliation Effect and Fiber Quality of Cotton under Two Kinds of Mechanical Harvesting Modes. J. Agric. Sci. Technol. 2020, 22, 144–152. [Google Scholar] [CrossRef]
- Ma, Q.; Li, J.; Ning, X.; Liu, P.; Deng, F.; Lin, H. Analysis on the of chemical defoliation and ripening of Xinluzao 60 under two kinds of mechanical cotton-picking planting modes. J. Chin. Agric. Mach. 2020, 41, 139–144. [Google Scholar] [CrossRef]
- Li, J.; Jia, F.; Sun, F.; Liu, A.; Shi, Y.; Gong, J.; Shang, H.; Wang, T.; Gong, W.; Jia, X.; et al. Quantitative Trait Locus Mapping of Number and Percentage of Cracked and Open Bolls in Gossypium hirsutum L. Cotton Sci. 2013, 25, 471–477. [Google Scholar]
- Wang, Y.; Cai, H.; Sun, L. Using Deep Learning Algorithms to Improve Energy Resolution in the Semileptonic Decays. Wuhan Univ. J. Nat. Sci. 2022, 27, 161–168. [Google Scholar] [CrossRef]
- Zhao, X.; Wu, B.; Wang, Y.; Li, W.; Cui, D. Numerical taxonomy of Prunus Linn sensu lato based on floral characteristics. J. Plant Resour. Environ. 2021, 30, 20–28. [Google Scholar] [CrossRef]
- Song, Z.; Wang, J.; Zheng, L.; Tie, J.; Zhu, Z. Research on citrus pest identification based on Binary Faster R-CNN. J. Chin. Agric. Mach. 2022, 43, 150–158. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, M.; Liu, Z.; Huang, M.; Li, X. Identification and Counting Method of Potted Kumquat Fruits Based on Point Cloud Registration. J. Agric. Mach. 2022, 53, 209–216. [Google Scholar] [CrossRef]
- Ali, B.; Karim, F.; Ali, M. SWP-LeafNET: A novel multistage approach for plant leaf identification based on deep CNN. Expert Syst. Appl. 2022, 202, 117470. [Google Scholar]
- Ning, J.; Ni, J.; He, Y.; Li, L.; Zhao, Z.; Zhang, Z. Recognition of mulched farmland from UAV multispectral remote sensing images based on convolutional attention. J. Agric. Mach. 2021, 52, 213–220. [Google Scholar] [CrossRef]
- Jin, X.; Bagavathiannan, M.; McCullough, P.E.; Chen, Y.; Yu, J. A deep learning-based method for classification, detection, and localization of weeds in turfgrass. Pest Manag. Sci. 2022. early view. [Google Scholar] [CrossRef] [PubMed]
- Chen, S. Development of Plant Growth Information Acquisition and Analysis System Based on Android Platform; Xi’an University of Technology: Xi’an, China, 2019. [Google Scholar]
- Peng, M.; Xia, J.; Peng, H. Efficient recognition of cotton and weed in field based on Faster R-CNN by integrating FPN. Trans. Chin. Soc. Agric. Eng. 2019, 35, 202–209. [Google Scholar] [CrossRef]
- Yao, Q.; Gu, J.; Lv, J.; Guo, L.; Tang, J.; Yang, B.; Xu, W. Automatic detection model for pest damage symptoms on rice canopy based on improved RetinaNet. Trans. Chin. Soc. Agric. Eng. 2020, 36, 182–188. [Google Scholar] [CrossRef]
- Li, T.; Sun, M.; Ding, X.; Li, Y.; Zhang, G.; Shi, G.; Li, W. Tomato recognition method at the ripening stage based on YOLOv4 and HSV. Trans. Chin. Soc. Agric. Eng. 2021, 37, 183–190. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wu, M.; Wu, J.; Zhang, C.; Zhu, L. Detection of foreign fiber in cotton based on improved YOLOv3. Chin. J. Liq. Cryst. Disp. 2020, 35, 1195–1203. [Google Scholar] [CrossRef]
- Gu, W. Nondestructive Testing of Cotton Seed Appearance Quality Based on MACHINE Vision; Huazhong Agricultural University: Wuhan, China, 2021. [Google Scholar]
- He, S. Research on the Recognition of Cotton Main Stem Growth Points Based on Machine Vision; Hebei Agricultural University: Baoding, China, 2021. [Google Scholar]
- Ouyang, Y. Research on Cotton Terminal Bud Recognition Method Based on Depth Algorithm Compression; Huazhong University of Science and Technology: Wuhan, China, 2021. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–16 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise Separable Convolutions for Neural Machine Translation. arXiv 2017, arXiv:1706.03059. [Google Scholar]
- Wang, C.Y.; Liao HY, M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3:An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4:Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5x | |
|---|---|---|---|---|
| CSP | 1 | 2 | 3 | 4 |
| Number of convolutional kernels | 32 | 48 | 64 | 80 |
| Feature map size | 30,430,432 | 30,430,448 | 30,430,464 | 30,430,480 |
| Model | CBAM | DWConv | Small Size Cotton Detection Layer | P/% | R/% | Map/% | Parameter Quantity | Detection Time/ms |
|---|---|---|---|---|---|---|---|---|
| YOLOv5x | × | × | × | 82.37 | 80.32 | 73.32 | 6 187 024 | 43.78 |
| A | √ | × | × | 84.59 | 82.96 | 72.43 | 4 082 034 | 49.21 |
| B | × | √ | × | 84.13 | 85.41 | 73.54 | 6 820 835 | 43.12 |
| C | × | × | √ | 86.64 | 84.40 | 75.19 | 6 759 216 | 65.76 |
| YOLOv5x+ | √ | √ | √ | 90.95 | 89.16 | 78.47 | 5 626 486 | 63.43 |
| P/% | R/% | Map/% | Detection Time/ms | |
|---|---|---|---|---|
| ResNet-50 | 80.10 | 71.67 | 71.14 | 74.86 |
| ResNet-18 | 79.13 | 67.14 | 70.58 | 80.16 |
| DesNet-201 | 84.30 | 74.95 | 75.58 | 69.73 |
| YOLOv5x+ | 90.95 | 89.16 | 78.47 | 63.43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, X.; Hu, C.; Dai, F.; Xing, J.; Wang, E.; Du, Z.; Wang, L.; Guo, W. Study on the Detection of Defoliation Effect of an Improved YOLOv5x Cotton. Agriculture 2022, 12, 1583. https://doi.org/10.3390/agriculture12101583
Wang X, Wang X, Hu C, Dai F, Xing J, Wang E, Du Z, Wang L, Guo W. Study on the Detection of Defoliation Effect of an Improved YOLOv5x Cotton. Agriculture. 2022; 12(10):1583. https://doi.org/10.3390/agriculture12101583
Chicago/Turabian StyleWang, Xingwang, Xufeng Wang, Can Hu, Fei Dai, Jianfei Xing, Enyuan Wang, Zhenhao Du, Long Wang, and Wensong Guo. 2022. "Study on the Detection of Defoliation Effect of an Improved YOLOv5x Cotton" Agriculture 12, no. 10: 1583. https://doi.org/10.3390/agriculture12101583