
Multi-Temporal Data Fusion in MS and SAR Images Using the Dynamic Time Warping Method for Paddy Rice Classification


Abstract
:1. Introduction
2. Research Materials and Design
2.1. Research Materials
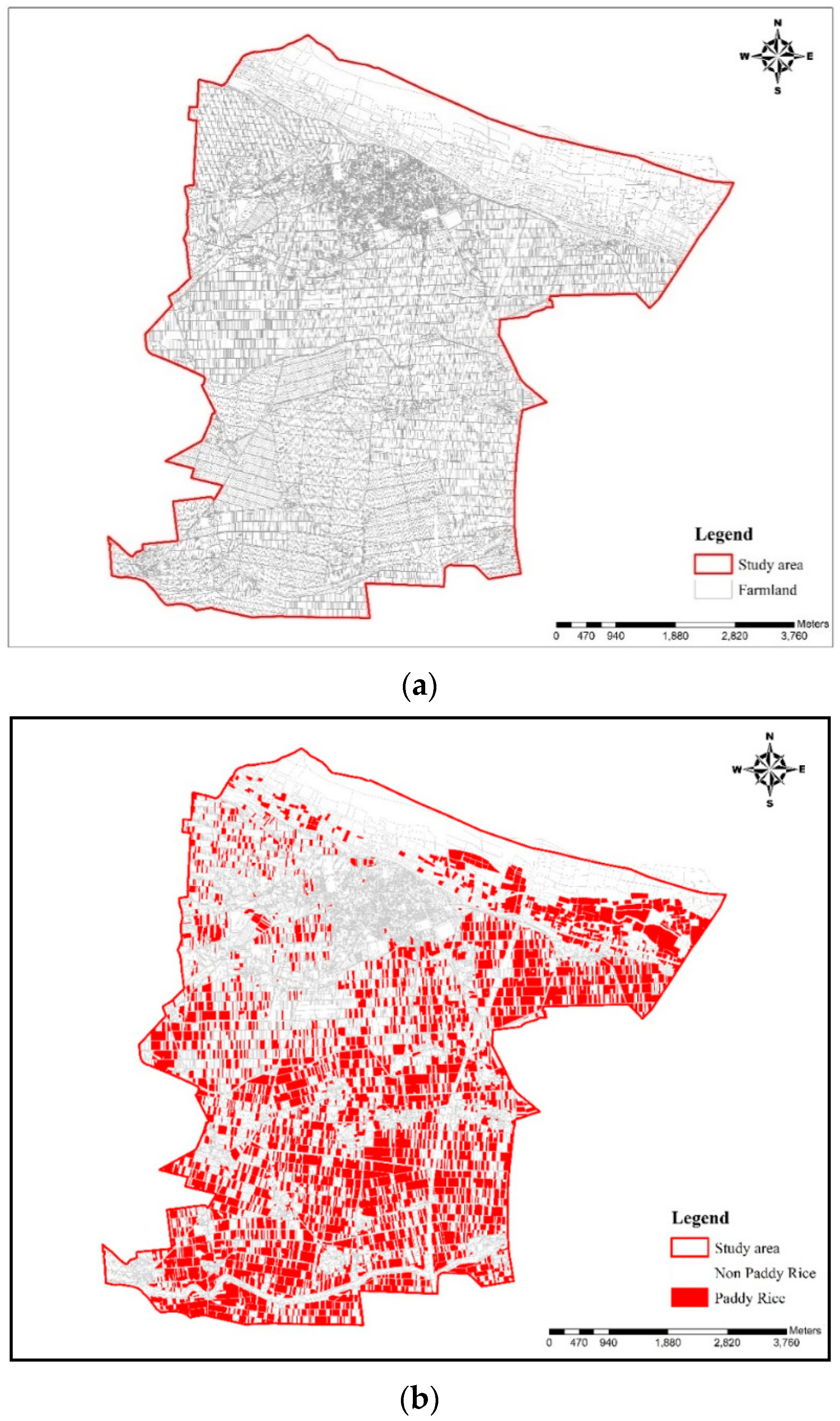
2.1.1. Research Site
2.1.2. Research Data
SPOT 6 Images
Sentinel-1A Images
2.2. Research Design
- Image feature calculation and dataset construction: In the optical image part, in addition to the four basic bands of red light (Red), green light (Green), blue light (Blue), and near-infrared light (NIR), this research included Ratio Vegetation Index (RVI) and Normalized Difference Vegetation Index (NDVI) and four Co-occurrence matrix (Gray Level Co-Occurrence Matrix, GLCM) texture indexes, including Homogeneity, Contrast, Dissimilarity, and Entropy, making a total of 19 types of feature information. It is worth mentioning that GLCM and associated texture features are image analysis techniques. An image is composed of pixels, each with an intensity (a specific gray level) suitable to apply GLCM, as different combinations of gray levels often co-occur in an image or image section. Texture feature calculations use the contents of GLCM to measure the variation in intensity (image texture) at the pixel of interest; on the other hand, the radar part uses C-band synthetic aperture radar (SAR) of two polarized images, called VV and VH. In addition to VV and VH, the 4 aforementioned kinds of texture information were also adopted. There was a total of 10 types of feature information. The features are shown in Table 2. In addition, the variation of satellite images for different time features could become a key factor when observing paddy rice and non-paddy rice patterns. We assign this part of the data as Label A.
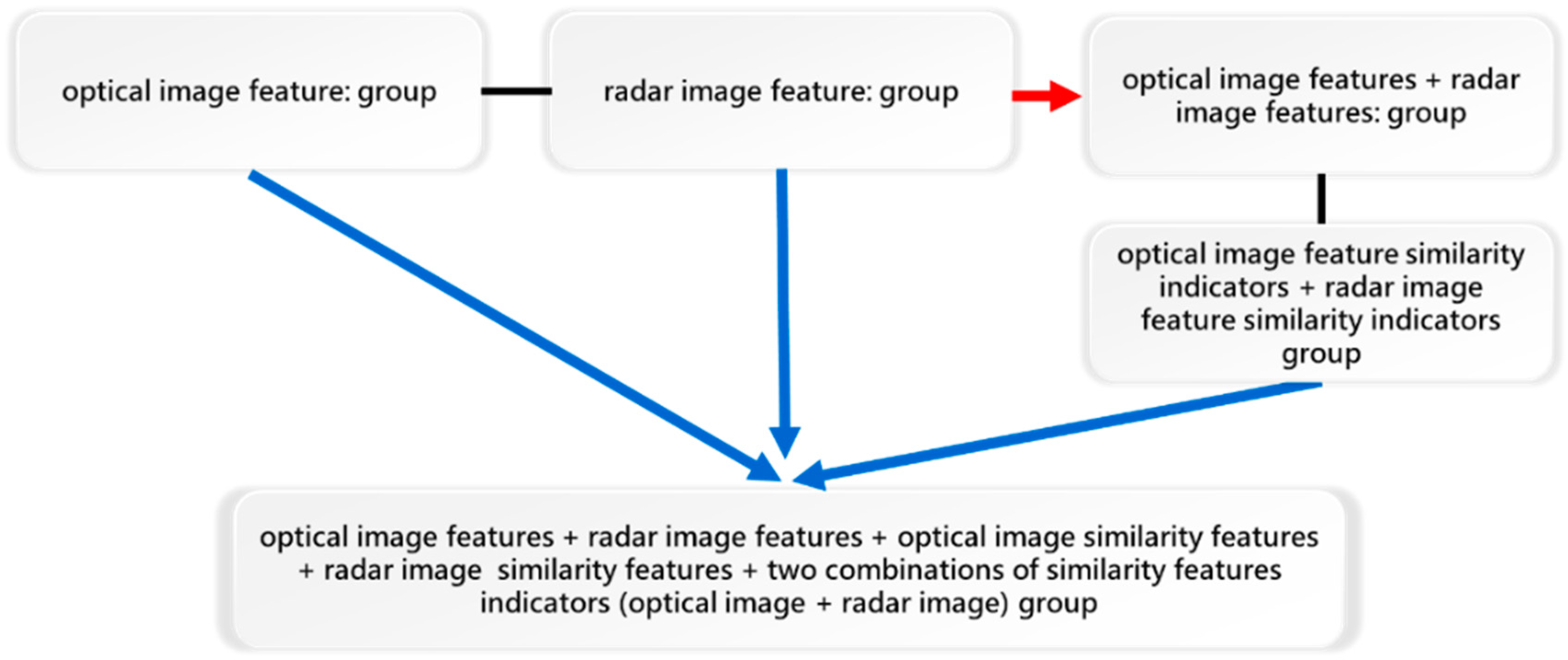
- Classification algorithm: This study used Support Vector Machine (SVM), Neural Network (NN), and C5.0 Decision Tree (DT) machine learning algorithm models. We conducted the training and verification of the models. The model training and verification rate ranged from 70% (37,227 patches) to 30% (15,985 patches). This further illustrates that the design of this research is different from the traditional method. We applied the three classification methods with two direct classification methods and a hybrid classification method to perform better classification outcomes. Direct classification methods use three machine learning models to directly classify the image data information (optical, index, and texture) features (Label A data set). Generally speaking, paddy rice is a long-period crop that requires an indicator and involves the combination of optical, index, and texture features for recording the variation over a long period. Hence, this study adopted two stages to solve the problem. The first stage was to import the image data to three classifiers (SVM, DT, and NN). The second stage was to extract the confusion samples (or patches) from the first stage to employ a new factor (DTW), which considers the time variation factor to improve classification performance. Specifically, this new ancillary information (DTW) was used for the dynamic calculation of the two-time series, and Euclidean distance matrices were computed one by one. For example, optical image characteristic band B to band G is one group, band B to band R is another group, etc. All combinations had to be calculated. The total number of feature information groups reached 26 levels. It was necessary to add 351 combinations of optical feature similarity. The similarity index between the two-time series features was produced, and the dataset was consolidated by the combination of the time series in patch features. The 351 combinations contained Optical Image Feature Similarity (171 attributes), Radar Image Feature Similarity (28 attributes), and the two combinations of feature similarity indicator (optical image + radar image) groups (152 at-tributes). Therefore, in this study, all data combinations were generated to form a DTW index (Figure 5). We hope this process can resolve the confusion around classification patches (samples). In the meantime, the inconsistent patches from the classification model were further refined.
- The comparison of classification: The training model accuracy had two parts. The first part was the result of the direct classification method, which was assigned as Label B. The second part was the result of the hybrid classification, which was assigned Label C. The comparison items were computed from an analysis of commission errors and omission errors. The overall accuracy and kappa values were also employed. We also compared the performance of Label B and Label C.
3. Research Methods
3.1. Support Vector Machine
3.2. Neural Network
3.3. Decision Tree
3.4. DTW Methods
3.5. Accuracy Verification
3.6. Model Software
4. Results and Discussion
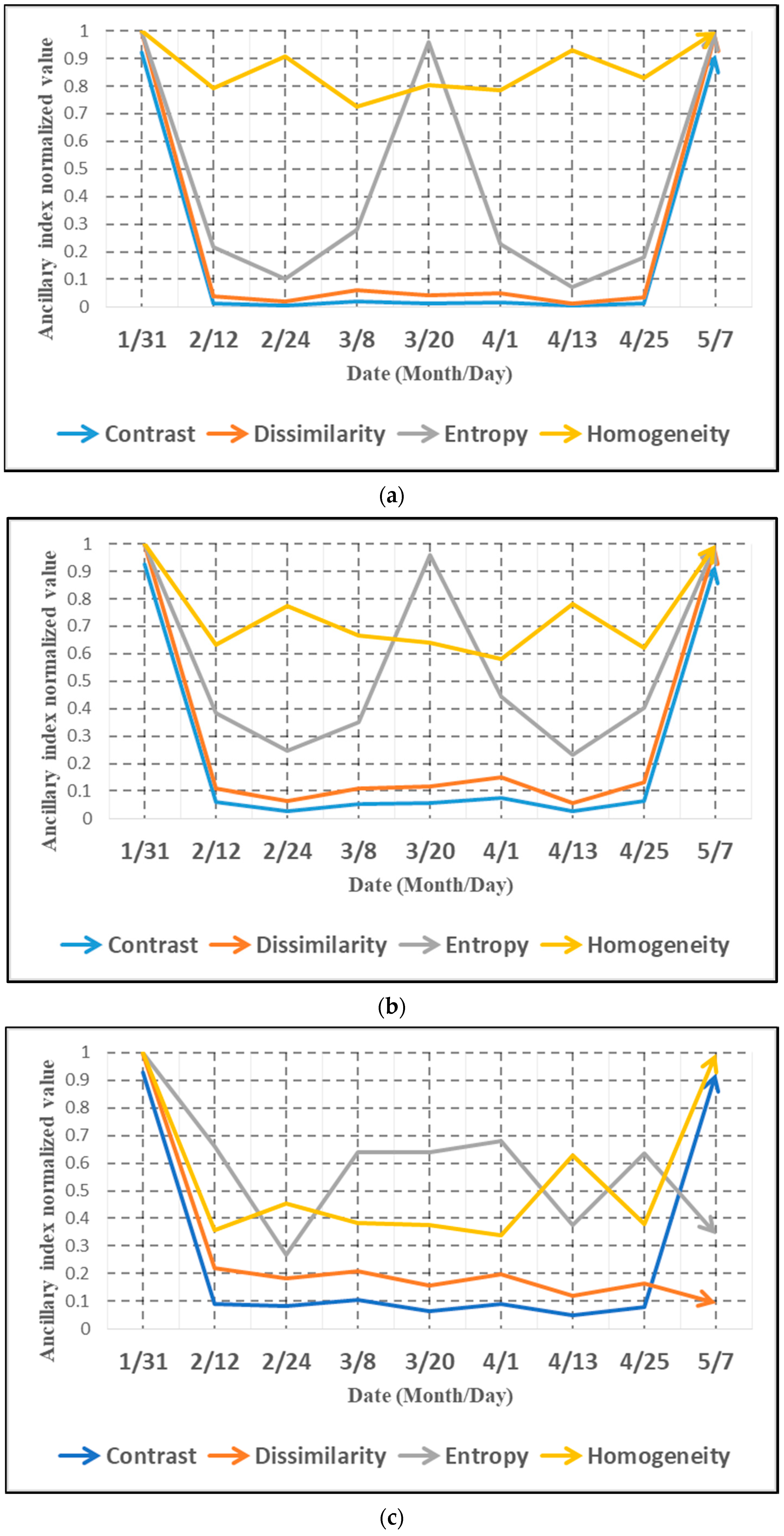
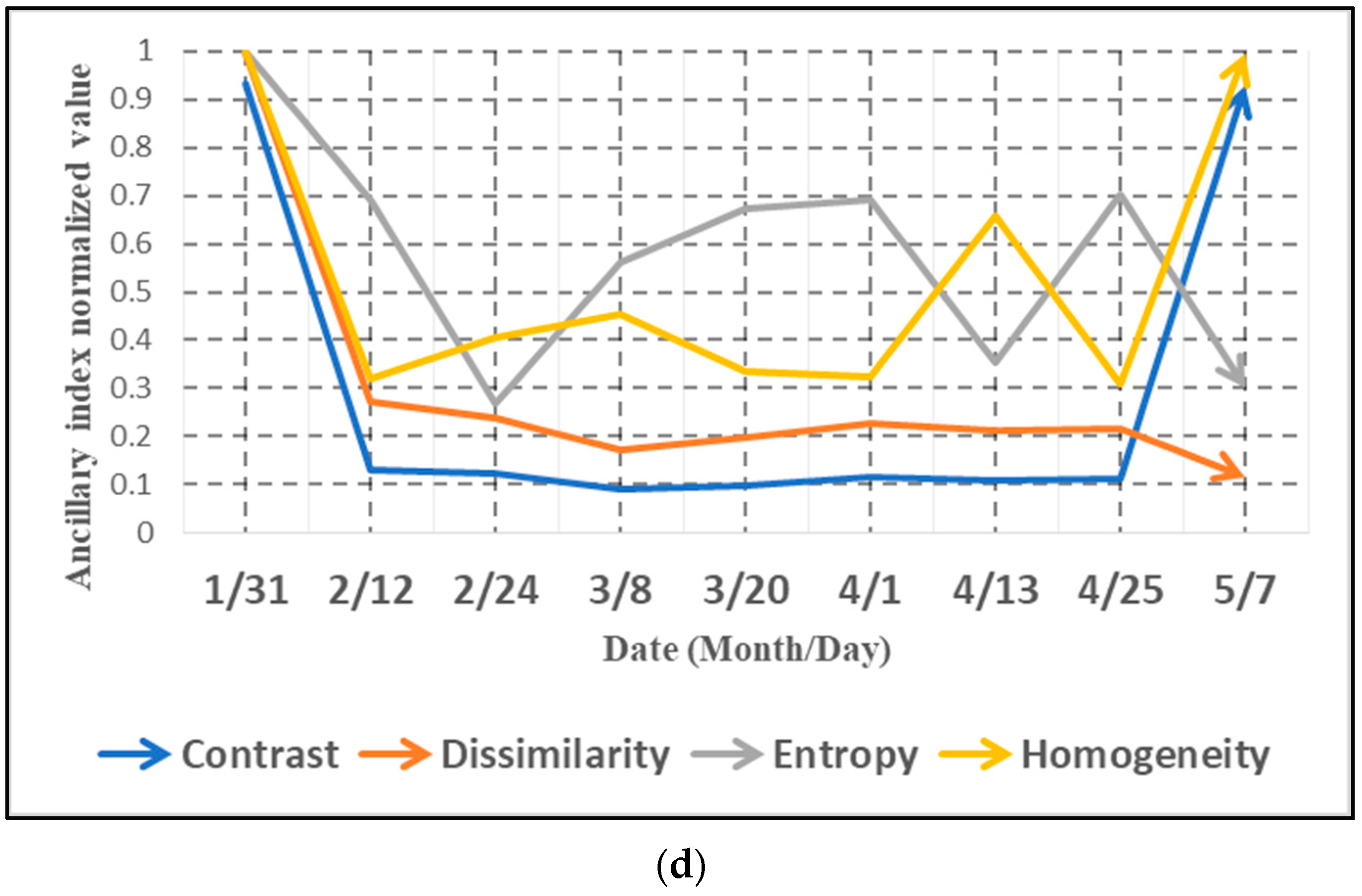
4.1. Examples of Optical and Radar Timing Characteristics Data
4.2. Comparison on Direct Classification Method and Hybrid Classification Method
4.2.1. Direct Classification Method
4.2.2. Hybrid Classification
5. Summary and Conclusions
- This study used SPOT6 optical images and Sentinel-1A radar images as the materials of research, which differs from the mainstream use of image fusion in the interpretation in past studies. The massive time series features in the datasets are integrated into a simple index to present the data dimensions in a single dataset. This approach provides new possibilities for subsequent analysis of information considering different scales of data.
- The homogeneity and entropy in radar images provides some new information in time series analysis, which greatly helps the classification of paddy rice. It is found that the behavior of time variations can distinguish paddy rice and non-paddy rice easily.
- This study uses the “direct classification method” and “hybrid classification method” for comparison. The characteristic information of optical satellite images and radar images is applied to directly perform classification methods for their behaviors. The results show that the overall accuracy results of the direct classification method are 91.7% (kappa value 0.72, SVM), 89.5% (kappa value 0.66, NN), and 93.26% (kappa value 0.76, DT). In the second stage of classification, the patches were classified optically with DTW feature information using three approaches, and neutral patches were added in the first stage, producing the overall accuracy results of 94.43% (kappa value is 0.80, SVM), 92.63% (kappa value is 0.74, NN), and 94.71% (kappa value is 0.81, DT). This also proves the DTW is robust.
- This result renders a feasible way to integrate radar feature information with optical feature information, especially in multi-period data. The optical images in different periods are difficult to obtain due to the influence of weather conditions. Radar images can be obtained regularly since cloud and fog interference can be avoided. A possible solution has been designed to overcome their disadvantages, which could lead to better classification performance. Considering those various restrictions, it is especially suitable for small farmland areas and fragile landscapes.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kumar, S.; Mishra, S.; Khanna, P. Precision sugarcane monitoring using SVM classifier. Procedia Comput. Sci. 2017, 122, 881–887. [Google Scholar] [CrossRef]
- Wan, S.; Wang, Y.P. The comparison of density-based clustering approach among different machine learning models on paddy rice image classification of multispectral and hyperspectral image data. Agriculture 2020, 10, 465. [Google Scholar] [CrossRef]
- De Bernardis, C.; Vicente-Guijalba, F.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Contribution to real-time estimation of crop phenological states in a dynamical framework based on NDVI time series: Data fusion with SAR and temperature. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3512–3523. [Google Scholar] [CrossRef] [Green Version]
- Onojeghuo, A.O.; Blackburn, G.A.; Wang, Q.; Atkinson, P.M.; Kindred, D.; Miao, Y. Mapping paddy rice fields by applying machine learning algorithms to multi-temporal Sentinel-1A and Landsat data. Int. J. Remote Sens. 2018, 39, 1042–1067. [Google Scholar] [CrossRef] [Green Version]
- Betbeder, J.; Laslier, M.; Corpetti, T.; Pottier, E.; Corgne, S.; Hubert-Moy, L. Multi-temporal optical and radar da-ta fusion for crop monitoring: Application to an intensive agricul-tural area in Brittany (France). In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1493–1496. [Google Scholar]
- Esteban, J.; Starr, A.; Willetts, R.; Hannah, P.; Bryanston-Cross, P. A Review of data fusion models and architectures: Towards engineering guidelines. Neural Comput. 2005, 14, 273–281. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Liu, X.; Liu, M. Assimilating remote sensing phenological information into the WOFOST model for rice growth simulation. Remote Sens. 2019, 11, 268. [Google Scholar] [CrossRef] [Green Version]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Waske, B. A review of the application of optical and radar remote sensing data fusion to land use mapping and monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef] [Green Version]
- Lei, T.C.; Wan, S.; Wu, S.C.; Wang, H.P. A new approach of ensemble learning technique to resolve the uncertainties of paddy area through image classification. Remote Sens. 2020, 12, 3666. [Google Scholar] [CrossRef]
- Petitjean, F.; Ketterlin, A.; Gancearski, P. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognit. 2011, 44, 678–693. [Google Scholar] [CrossRef]
- Wang, M.; Wang, J.; Chen, L. Mapping paddy rice using weakly supervised Long Short-term Memory Network with time Series sentinel optical and SAR Images. Agriculture 2020, 10, 483. [Google Scholar] [CrossRef]
- Gella, G.W.; Bijker, W.; Belgiu, M. Mapping crop types in complex farming areas using SAR imagery with dynamic time warping. ISPRS J. Photogramm. Remote Sens. 2021, 175, 171–183. [Google Scholar] [CrossRef]
- Viana, C.M.; Girão, I.; Rocha, J. Long-term satellite image time-series for land use/land cover change detection using refined open source data in a rural region. Remote Sens. 2019, 11, 1104. [Google Scholar] [CrossRef] [Green Version]
- Cheng, K.; Wang, J. Forest-type classification using time-weighted Dynamic Time Warping analysis in mountain areas: A case study in southern China. Forests 2019, 10, 1040. [Google Scholar] [CrossRef] [Green Version]
- Guan, X.; Huang, C.; Liu, G.; Meng, X.; Liu, Q. Mapping rice cropping systems in Vietnam using an NDVI-based time-series similarity measurement based on DTW distance. Remote Sens. 2016, 8, 19. [Google Scholar] [CrossRef] [Green Version]
- Moola, W.S.; Bijker, W.; Belgiu, M.; Li, M. Vegetable mapping using fuzzy classification of Dynamic Time Warping distances from time series of Sentinel-1A images. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102405. [Google Scholar] [CrossRef]
- Guan, X.D.; Liu, G.H.; Huang, C.; Meng, X.L.; Liu, Q.S.; Wu, C.; Ablat, X.; Chen, Z.R.; Wang, Q. An Open-boundary locally weighted Dynamic Time Warping method for cropland mapping. ISPRS Int. J. Geo-Inf. 2018, 7, 75. [Google Scholar] [CrossRef] [Green Version]
- Manabe, V.D.; Melo, M.R.; Rocha, J.V. Framework for mapping integrated crop-livestock systems in Mato Grosso, Brazil. Remote Sens. 2018, 10, 1322. [Google Scholar] [CrossRef] [Green Version]
- Csillik, O.; Belgiu, M.; Asner, G.P.; Kelly, M. Object-Based time-constrained Dynamic Time Warping classification of crops using Sentinel-2. Remote Sens. 2019, 11, 1257. [Google Scholar] [CrossRef] [Green Version]
- Dong, Q.; Chen, X.; Chen, J.; Zhang, C.S.; Liu, L.; Cao, X.; Zang, Y.Z.; Zhu, X.F.; Cui, X.H. Mapping winter wheat in North China using Sentinel 2A/B data: A method based onvphenology-Time Weighted Dynamic Time Warping. Remote Sens. 2020, 12, 1274. [Google Scholar] [CrossRef] [Green Version]
- Zhao, F.; Yang, G.; Yang, X.; Cen, H.; Zhu, Y.; Han, S.; Yang, H.; He, Y.; Zhao, C. Determination of key phenological phases of winter wheat based on the time-weighted Dynamic Time Warping algorithm and MODIS time-series data. Remote Sens. 2021, 13, 1836. [Google Scholar] [CrossRef]
- Zhao, F.; Yang, G.J.; Yang, H.; Zhu, Y.H.; Meng, Y.; Han, S.Y.; Bu, X.L. Short and medium-term prediction of winter wheat NDVI based on the DTW–LSTM combination method and MODIS time series data. Remote Sens. 2021, 13, 4660. [Google Scholar] [CrossRef]
- European Space Agency—ESA. Available online: https://step.esa.int/main/toolboxes/snap/ (accessed on 1 May 2018).
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Wan, S.; Yeh, M.L.; Ma, H.L. An innovative intelligent system with integrated CNN and SVM: Considering various crops through hyperspectral image data. ISPRS Int. J of Geo-Inform. 2021, 10, 242. [Google Scholar] [CrossRef]
- Werbos, P.J. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Ph.D. Thesis, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]
- Kumar, A.; Kim, J.; Lyndon, D.; Fulham, M.; Feng, D. An ensemble of fine-tuned convolutional Neural Networks for medical image classification. IEEE J. Biomed. Health Inform. 2017, 21, 31–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bazzi, H.; Baghdadi, N.; Hajj, E.M.; Zribi, M.; Minh, D.H.T.; Ndikumana, E.; Courault, D.; Belhouchette, H. Mapping paddy rice using Sentinel-1 SAR time series in camargue, France. Remote Sens. 2019, 11, 887. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Gong, Y.; Fang, S.; Duan, B.; Yuan, N.; Peng, Y.; Zhu, R. Combining Spectral and Texture Features of UAV Images for the Remote Estimation of Rice LAI throughout the Entire Growing Season. Remote Sens. 2021, 13, 3001. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Number of Patches | Area (ha) |
|---|---|---|
| Paddy Rice | 7699 | 1634.96 |
| Non-Paddy Rice | 45,513 | 3379.83 |
| Total | 53,212 | 5014.80 |
| Vegetation Index | Formula |
|---|---|
| RVI (Ratio Vegetation Index) | |
| NDVI (Normalized Difference Vegetation Index) | |
| PVI (Perpendicular Vegetation Index) | |
| SAVI (Soil-adjusted Vegetation Index) | |
| TSAVI (Transformed Soil-adjusted Vegetation Index) | |
| CMFI (Cropping Management Factor Index) | |
| GI (Greenness Index) | |
| IPVI (Infrared Percentage Vegetation Index) | |
| MSAVI (Modified Soil-adjusted Vegetation Index) | |
| OSAVI (Optimization Soil adjusted Vegetation Index) | |
| GESAVI (Generalize Soil- adjusted Vegetation Index) | |
| HOM (Homogeneity) | |
| CON (Contrast) | |
| DIS (Dissimilarity) | |
| ENT (Entropy) |
| SVM | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Direct Classification | Paddy Rice | 7173 | 3868 | 11,041 | 0.65 |
| Non-Paddy Rice | 526 | 41,645 | 42,171 | 0.99 | |
| Sum of Rows | 7699 | 45,513 | 53,212 | ||
| User’s Accuracy | 0.93 | 0.92 | |||
| Accuracy | 91.74% | ||||
| kappa | 0.72 | ||||
| NN | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Direct Classification | Paddy Rice | 7075 | 4958 | 12,033 | 0.59 |
| Non-Paddy Rice | 624 | 40,555 | 41,179 | 0.99 | |
| Sum of Rows | 7699 | 45,513 | 53,212 | ||
| User’s Accuracy | 0.92 | 0.89 | |||
| Accuracy | 89.51% | ||||
| kappa | 0.66 | ||||
| DT | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Direct Classification | Paddy Rice | 7250 | 3139 | 10,389 | 0.70 |
| Non-Paddy Rice | 449 | 42,374 | 42,823 | 0.99 | |
| Sum of Rows | 7699 | 45,513 | 53,212 | ||
| User’s Accuracy | 0.94 | 0.93 | |||
| Accuracy | 93.26% | ||||
| kappa | 0.76 | ||||
| Ground Truth | Producer’s Accuracy | ||||
|---|---|---|---|---|---|
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Consistency of Classification | Paddy Rice | 6904 | 2208 | 9112 | 0.76 |
| Non-Paddy Rice | 292 | 39,680 | 39,972 | 0.99 | |
| Sum of Rows | 7196 | 41,888 | 49,084 | ||
| User’s Accuracy | 0.96 | 0.95 | |||
| Accuracy | 94.91% | ||||
| kappa | 0.82 | ||||
| SVM | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Inconsistency of Classification | Paddy Rice | 269 | 1660 | 1929 | 0.14 |
| Non-Paddy Rice | 234 | 1965 | 2199 | 0.89 | |
| Sum of Rows | 503 | 3625 | 4128 | ||
| User’s Accuracy | 0.53 | 0.54 | |||
| Accuracy | 54.12% | ||||
| kappa | 0.03 | ||||
| NN | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Inconsistency of Classification | Paddy Rice | 171 | 2750 | 2921 | 0.06 |
| Non-Paddy Rice | 332 | 875 | 1207 | 0.72 | |
| Sum of Rows | 503 | 3625 | 4128 | ||
| User’s Accuracy | 0.34 | 0.24 | |||
| Accuracy | 25.34% | ||||
| kappa | −0.14 | ||||
| DT | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Inconsistency of Classification | Paddy Rice | 346 | 931 | 1277 | 0.27 |
| Non-Paddy Rice | 157 | 2694 | 2851 | 0.94 | |
| Sum of Rows | 503 | 3625 | 4128 | ||
| User’s Accuracy | 0.69 | 0.74 | |||
| Accuracy | 73.64% | ||||
| kappa | 0.26 | ||||

| SVM | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Hybrid Classification | Paddy Rice | 7360 | 2626 | 9986 | 0.74 |
| Non-Paddy Rice | 339 | 42,887 | 43,226 | 0.99 | |
| Sum of Rows | 7699 | 45,513 | 53,212 | ||
| User’s Accuracy | 0.96 | 0.94 | |||
| Accuracy | 94.43% | ||||
| kappa | 0.80 | ||||
| NN | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Hybrid Classification | Paddy Rice | 7184 | 3407 | 10,591 | 0.68 |
| Non-Paddy Rice | 515 | 42,106 | 42,621 | 0.99 | |
| Sum of Rows | 7699 | 45,513 | 53,212 | ||
| User’s Accuracy | 0.93 | 0.93 | |||
| Accuracy | 92.63% | ||||
| kappa | 0.74 | ||||
| DT | Ground Truth | Producer’s Accuracy | |||
| Paddy Rice | Non-Paddy Rice | Sum of Columns | |||
| Hybrid Classification | Paddy Rice | 7397 | 2512 | 9909 | 0.75 |
| Non-Paddy Rice | 302 | 43,001 | 43,303 | 0.99 | |
| Sum of Rows | 7699 | 45,513 | 53,212 | ||
| User’s Accuracy | 0.96 | 0.94 | |||
| Accuracy | 94.71% | ||||
| kappa | 0.81 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, T.C.; Wan, S.; Wu, Y.C.; Wang, H.-P.; Hsieh, C.-W. Multi-Temporal Data Fusion in MS and SAR Images Using the Dynamic Time Warping Method for Paddy Rice Classification. Agriculture 2022, 12, 77. https://doi.org/10.3390/agriculture12010077
Lei TC, Wan S, Wu YC, Wang H-P, Hsieh C-W. Multi-Temporal Data Fusion in MS and SAR Images Using the Dynamic Time Warping Method for Paddy Rice Classification. Agriculture. 2022; 12(1):77. https://doi.org/10.3390/agriculture12010077
Chicago/Turabian StyleLei, Tsu Chiang, Shiuan Wan, You Cheng Wu, Hsin-Ping Wang, and Chia-Wen Hsieh. 2022. "Multi-Temporal Data Fusion in MS and SAR Images Using the Dynamic Time Warping Method for Paddy Rice Classification" Agriculture 12, no. 1: 77. https://doi.org/10.3390/agriculture12010077