
Detection and Analysis of Sow Targets Based on Image Vision

Abstract
:1. Introduction
2. Materials and Methods
2.1. Animal and Housing
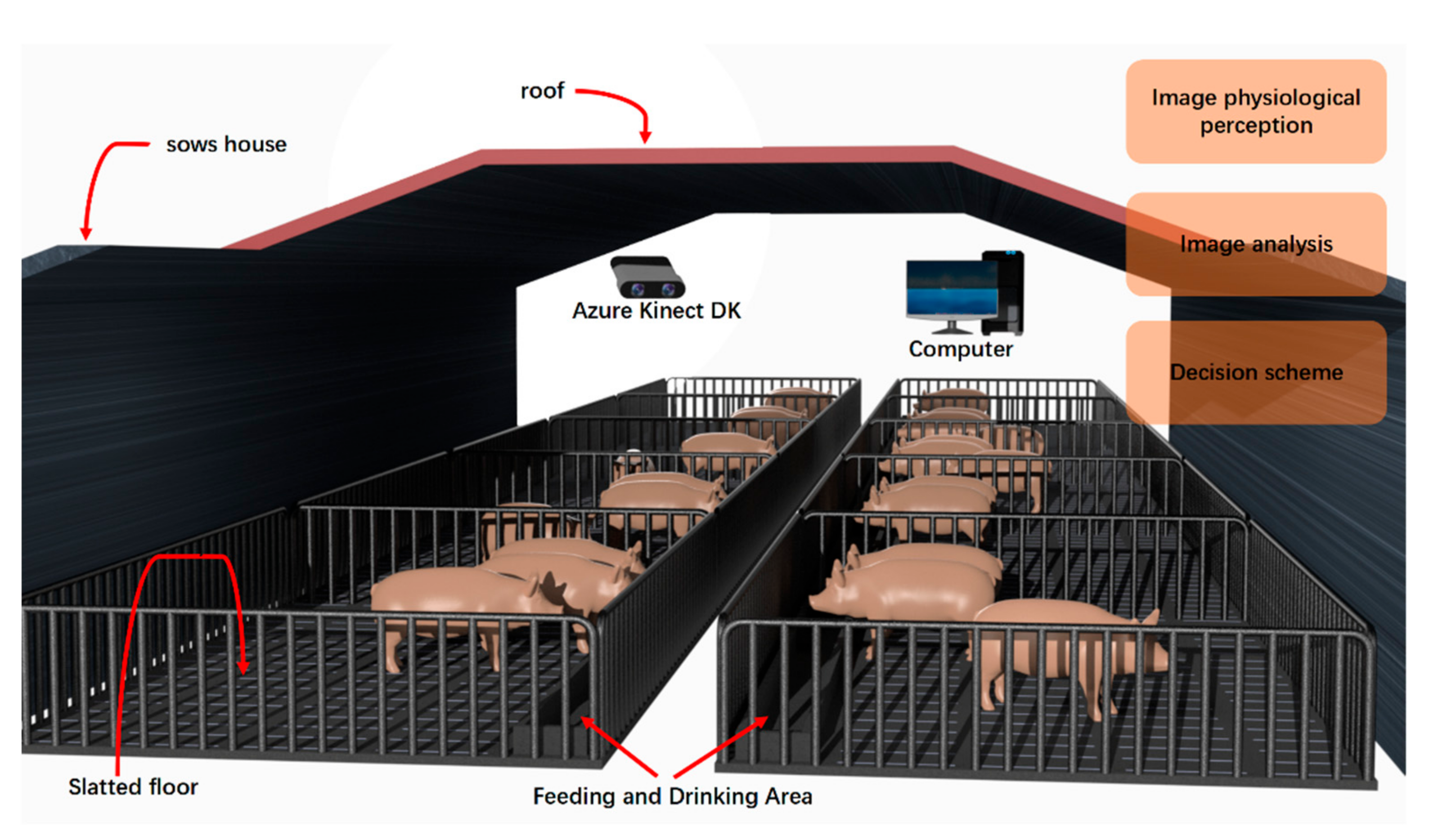
2.2. Data Acquisition Platform
- The collected video set in .mkv format was processed into .JPG format images through Python language, and then labeled with the Labelme software to form a .json format file.
- In the training process, to increase the robustness of the Convolutional Neural Network, the input image of the sow was augmented. The data augmentation mainly used horizontal and vertical flipping, cropping, scale transformation, and rotation. The diversity of the data was also increased in this process.
2.3. Model Development
2.3.1. Development of the Sow Detection Model Based on Unet-Attention
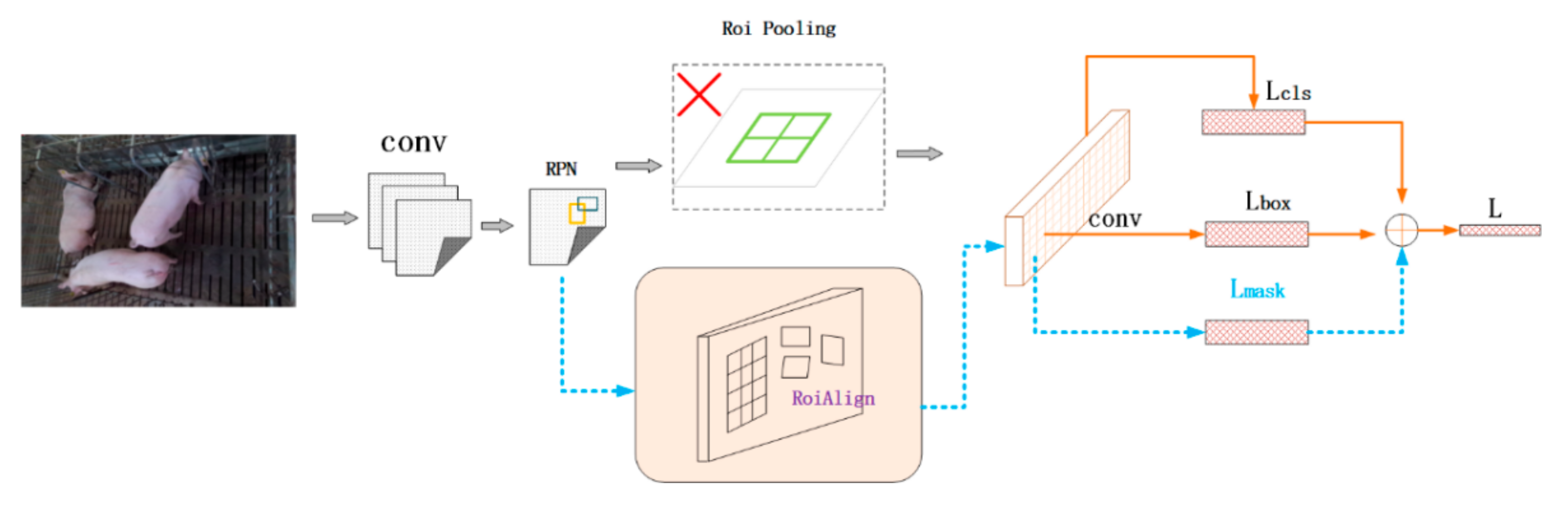
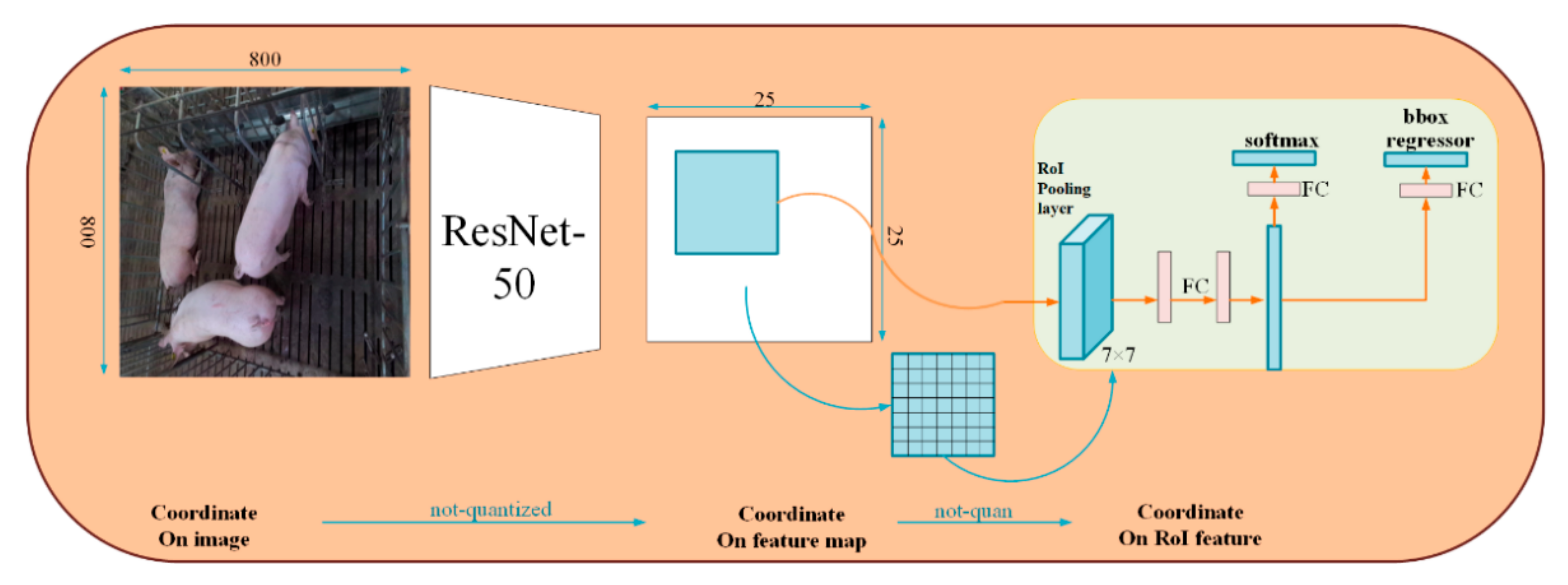
2.3.2. Development of Sow Detection Model Based on Mask-RCNN
2.4. Assessment of the Model
2.5. Sow Behavior Recognition Based on Image Segmentation
3. Results and Discussions
3.1. Performance of the Developed Models
3.2. Analysis of Poor Segmentation
3.3. Image Recognition of Sow Behaviors and Positions
3.4. Application of the Sow Target Detection Model and Its Perspectives
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hoy, S. Precision pig farming. Innovative Technologies and decision models for pig farming. Tierärztl. Prax. Ausg. Grosstiere/Nutztiere 2009, 37, 184. [Google Scholar]
- Peltoniemi, O.; Oliviero, C.; Yun, J.; Grahofer, A.; Björkman, S. Management practices to optimize the parturition process in the hyperprolific sow. J. Anim. Sci. 2020, 98, S96–S106. [Google Scholar] [CrossRef]
- Kashiha, M.; Bahr, C.; Haredasht, S.A.; Ott, S.; Moons, C.P.; Niewold, T.A.; Ödberg, F.O.; Berckmans, D. The automatic monitoring of pigs water use by cameras. Comput. Electron. Agric. 2013, 90, 164–169. [Google Scholar] [CrossRef]
- Lao, F.; Brown-Brandl, T.; Stinn, J.P.; Liu, K.; Teng, G.; Xin, H. Automatic recognition of lactating sow behaviors through depth image processing. Comput. Electron. Agric. 2016, 125, 56–62. [Google Scholar] [CrossRef] [Green Version]
- Weng, R.-C. Variations in the body surface temperature of sows during the post weaning period and its relation to subsequent reproductive performance. Asian-Australas. J. Anim. Sci. 2020, 33, 1138–1147. [Google Scholar] [CrossRef]
- Lopes, T.P.; Padilla, L.; Bolarin, A.; Rodriguez-Martinez, H.; Roca, J. Ovarian follicle growth during lactation determines the reproductive performance of weaned sows. Animals 2020, 10, 1012. [Google Scholar] [CrossRef] [PubMed]
- Iida, R.; Pineiro, C.; Koketsu, Y. Removal of sows in Spanish breeding herds due to lameness: Incidence, related factors and reproductive performance of removed sows. Prev. Veter.-Med. 2020, 179, 105002. [Google Scholar] [CrossRef] [PubMed]
- Hwang, J.; Yoe, H. Study of the Ubiquitous Hog Farm System Using Wireless Sensor Networks for Environmental Monitoring and Facilities Control. Sensors 2010, 10, 10752–10777. [Google Scholar] [CrossRef] [PubMed]
- Thongkhuy, S.; Chuaychu, S.B.; Burarnrak, P.; Ruangjoy, P.; Juthamanee, P.; Nuntapaitoon, M.; Tummaruk, P. Effect of backfat thickness during late gestation on farrowing duration, piglet birth weight, colostrum yield, milk yield and reproductive performance of sows. Livest. Sci. 2020, 234, 103983. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Han, J.; Norton, T. Recognition of feeding behavior of pigs and determination of feeding time of each pig by a video-based deep learning method. Comput. Electron. Agri. 2020, 176, 105642. [Google Scholar] [CrossRef]
- Ott, S.; Moons, C.P.H.; Kashiha, M.A.; Bahr, C.; Tuyttens, F.A.M.; Berckmans, D.; Niewold, T.A. Automated video analysis of pig activity at pen level highly correlates to human observations of behavioral activities. Livest. Sci. 2014, 160, 132–137. [Google Scholar] [CrossRef]
- Riekert, M.; Klein, A.; Adrion, F.; Hoffmann, C.; Gallmann, E. Automatically detecting pig position and posture by 2D camera imaging and deep learning. Comput. Electron. Agric. 2020, 174, 105391. [Google Scholar] [CrossRef]
- Marsot, M.; Mei, J.; Shan, X.; Ye, L.; Feng, P.; Yan, X.; Li, C.; Zhao, Y. An adaptive pig face recognition approach using Convolutional Neural Networks. Comput. Electron. Agric. 2020, 173, 105386. [Google Scholar] [CrossRef]
- Zhuang, X.; Zhang, T. Detection of sick broilers by digital image processing and deep learning. Biosyst. Eng. 2019, 179, 106–116. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Hossain, S.; Lee, D.-J. Deep learning-based real-time multiple-object detection and tracking from aerial imagery via a flying robot with gpu-based embedded devices. Sensors 2019, 19, 3371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, C.; Ling, Y.; Yang, X.; Jin, W.; Zheng, C. Multi-view object detection based on deep learning. Appl. Sci. 2018, 8, 1423. [Google Scholar] [CrossRef] [Green Version]
- Algarni, A.D. Efficient object detection and classification of heat emitting objects from infrared images based on deep learning. Multimed. Tools Appl. 2020, 79, 13403–13426. [Google Scholar] [CrossRef]
- Lu, S.; Wang, B.; Wang, H.; Chen, L.; Linjian, M.; Zhang, X. A real-time object detection algorithm for video. Comput. Electr. Eng. 2019, 77, 398–408. [Google Scholar] [CrossRef]
- Aziz, L.; Salam, S.B.H.; Sheikh, U.U.; Ayub, S. Exploring deep learning-based architecture, strategies, applications and current trends in generic object detection: A comprehensive review. IEEE Access 2020, 8, 170461–170495. [Google Scholar] [CrossRef]
- Bamne, B.; Shrivastava, N.; Parashar, L.; Singh, U. Transfer learning-based Object Detection by using Convolutional Neural Networks. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 328–332. [Google Scholar]
- Yann, L.C.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Poursaberi, A.; Bahr, C.; Pluk, A.; Van Nuffel, A.; Berckmans, D. Real-time automatic lameness detection based on back posture extraction in dairy cattle: Shape analysis of cow with image processing techniques. Comput. Electron. Agric. 2010, 74, 110–119. [Google Scholar] [CrossRef]
- Salau, J.; Haas, J.H.; Junge, W.; Thaller, G. Automated calculation of udder depth and rear leg angle in Holstein-Friesian cows using a multi-Kinect cow scanning system. Biosyst. Eng. 2017, 160, 154–169. [Google Scholar] [CrossRef]
- Traffano-Schiffo, M.V.; Castro-Giraldez, M.; Colom, R.J.; Fito, P.J. Development of a spectrophotometric system to detect white striping physiopathy in whole chicken carcasses. Sensors 2017, 17, 1024. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Sturm, B.; Edwards, S.; Jeppsson, K.-H.; Olsson, A.-C.; Müller, S.; Hensel, O. Deep learning and machine vision approaches for posture detection of individual pigs. Sensors 2019, 19, 3738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Gray, H.; Ye, X.; Collins, L.; Allinson, N. Automatic individual pig detection and tracking in pig farms. Sensors 2019, 19, 1188. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Chung, Y.; Choi, Y.; Sa, J.; Kim, H.; Chung, Y.; Park, D.; Kim, H. Depth-based detection of standing-pigs in moving noise environments. Sensors 2017, 17, 2757. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Zhang, J.; Zhu, M.; Wu, J.; Kong, F. Review of automatic detection of pig behaviors by using image analysis. IOP Conf. Ser. Earth Environ. Sci. 2017, 69, 012096. [Google Scholar] [CrossRef]
- Gangsei, L.E.; Kongsro, J. Automatic segmentation of Computed Tomography (CT) images of domestic pig skeleton using a 3D expansion of Dijkstra’s algorithm. Comput. Electron. Agric. 2016, 121, 191–194. [Google Scholar] [CrossRef]
- Guo, Y.-Z.; Zhu, W.-X.; Jiao, P.-P.; Ma, C.-H.; Yang, J.-J. Multi-object extraction from topview group-housed pig images based on adaptive partitioning and multilevel thresholding segmentation. Biosyst. Eng. 2015, 135, 54–60. [Google Scholar] [CrossRef]
- Hansen, M.F.; Smith, M.L.; Smith, L.N.; Salter, M.G.; Baxter, E.; Farish, M.; Grieve, B. Towards on-farm pig face recognition using convolutional neural networks. Comput. Ind. 2018, 98, 145–152. [Google Scholar] [CrossRef]
- Hu, J.-Y.; Shi, C.-J.R.; Zhang, J.-S. Saliency-based YOLO for single target detection. Knowl. Inf. Syst. 2021, 63, 717–732. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Rueckert, D. Attention u-net learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870v3. [Google Scholar]
- Tu, S.; Liu, H.; Li, J.; Huang, J.; Li, B.; Pang, J.; Xue, Y. Instance Segmentation Based on Mask Scoring R-CNN for Group-housed Pigs. Presented at the 2020 International Conference on Computer Engineering and Application (ICCEA); Institute of Electrical and Electronics Engineers (IEEE), Piscataway Township, NJ, USA, 18–20 March 2020; pp. 458–462. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2018, arXiv:1708.02002. [Google Scholar]
- Simonsen, H.B. Behavior and distribution of fattening pigs in the multi-activity pen. Appl. Anim. Behav. Sci. 1990, 27, 311–324. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porto, S.M.C.; Arcidiacono, C.; Anguzza, U.; Cascone, G. A computer vision-based system for the automatic detection of lying behavior of dairy cows in free-stall barns. Biosyst. Eng. 2013, 115, 184–194. [Google Scholar] [CrossRef]
- Viazzi, S.; Bahr, C.; Van Hertem, T.; Schlageter-Tello, A.; Romanini, C.; Halachmi, I.; Lokhorst, C.; Berckmans, D. Comparison of a three-dimensional and two-dimensional camera system for automated measurement of back posture in dairy cows. Comput. Electron. Agric. 2014, 100, 139–147. [Google Scholar] [CrossRef]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion Loss: Detecting Pedestrians in a Crowd. arXiv 2018, arXiv:1711.07752. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-Aware R-CNN: Detecting Pedestrians in a Crowd. In Proceedings of the Transactions on Petri Nets and Other Models of Concurrency XV, Munich, Germany, 8–14 September 2018; pp. 657–674. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sun, L.; Li, Y.; Zou, Y. Pig image segmentation method based on improved Graph Cut algorithm. Nongye Gongcheng Xuebao/Trans. Chin. Soc. Agric. Eng. 2017, 33, 196–202. [Google Scholar]
- Yang, L.; Zhu, W.X. Image segmentation of pig using wavelet modulus and edge growth. Appl. Mech. Mater. 2014, 687–691, 3695–3698. [Google Scholar] [CrossRef]
- Zhang, Y.; Cai, J.; Xiao, D.; Li, Z.; Xiong, B. Real-time sow behavior detection based on deep learning. Comput. Electron. Agric. 2019, 163, 104884. [Google Scholar] [CrossRef]
- Liu, B.; Zhu, W.; Ji, B.; Ma, C. Automatic registration of IR and optical pig images based on contour match of radial line feature points. Trans. Chin. Soc. Agric. Eng. 2013, 29, 153–160. [Google Scholar]
- Carillo, F.; Abeni, F. An Estimate of the Effects from Precision Livestock Farming on a Productivity Index at Farm Level. Some Evidences from a Dairy Farms’ Sample of Lombardy. Animals 2020, 10, 1781. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Sturm, B.; Olsson, A.-C.; Jeppsson, K.-H.; Müller, S.; Edwards, S.; Hensel, O. Automatic scoring of lateral and sternal lying posture in grouped pigs using image processing and Support Vector Machine. Comput. Electron. Agric. 2019, 156, 475–481. [Google Scholar] [CrossRef]
- Ammendrup, S.; Füssel, A.E. Legislative requirements for the identification and traceability of farm animals within the European Union. Rev. Sci. Tech. 2001, 20, 437–444. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zamora-Izquierdo, M.A.; Santa, J.; Martínez, J.A.; Martínez, V.; Skarmeta, A.F. Smart farming IoT platform based on edge and cloud computing. Biosyst. Eng. 2019, 177, 4–17. [Google Scholar] [CrossRef]
- Banhazi, T.M.; Lehr, H.; Black, J.L.; Crabtree, H.; Schofield, P.; Tscharke, M.; Berckmans, D. Berckmans precision livestock farming: An international review of scientific and commercial aspects. Int. J. Agric. Boil. Eng. 2012, 5, 1–9. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AP | IoU | Area | maxDets |
|---|---|---|---|---|
| Mask-RCNN | 0.772 | 0.50:0.95 | all | 100 |
| 0.968 | 0.50 | all | 100 | |
| 0.948 | 0.75 | all | 100 | |
| 0.000 | 0.50:0.95 | small | 100 | |
| 0.083 | 0.50:0.95 | medium | 100 | |
| 0.792 | 0.50:0.95 | large | 100 | |
| UNet-Attention | 0.010 | 0.50:0.95 | all | 100 |
| 0.025 | 0.50 | all | 100 | |
| 0.006 | 0.75 | all | 100 | |
| 0.000 | 0.50:0.95 | small | 100 | |
| 0.000 | 0.50:0.95 | medium | 100 | |
| 0.046 | 0.50:0.95 | large | 100 | |
| 0.010 | 0.50:0.95 | all | 100 |
| Model | AR | IoU | Area | maxDets |
|---|---|---|---|---|
| Mask-RCNN | 0.291 | 0.50:0.95 | all | 1 |
| 0.802 | 0.50:0.95 | all | 10 | |
| 0.802 | 0.50:0.95 | all | 100 | |
| 0.000 | 0.50:0.95 | small | 100 | |
| 0.135 | 0.50:0.95 | medium | 100 | |
| 0.823 | 0.50:0.95 | large | 100 | |
| UNet-Attention | 0.004 | 0.50:0.95 | all | 1 |
| 0.030 | 0.50:0.95 | all | 1 | |
| 0.167 | 0.50:0.95 | all | 5 | |
| 0.000 | 0.50:0.95 | small | 100 | |
| 0.000 | 0.50:0.95 | medium | 100 | |
| 0.176 | 0.50:0.95 | large | 100 |
| Task | AP | AP50 | AP75 | APsmall | APmedium | APlarge |
|---|---|---|---|---|---|---|
| Bbox | 0.6586 | 0.9668 | 0.8543 | 0.0000 | 0.1010 | 0.6751 |
| Segm | 0.7720 | 0.9682 | 0.9480 | 0.0000 | 0.0826 | 0.7925 |
| 1 | 2 | 3 | 4 | 5 | 6 | Average Value | Mean Square Error | |
|---|---|---|---|---|---|---|---|---|
| Lying time/h | 13.5 | 12 | 11 | 13 | 14 | 12.5 | 12.67 | 1.08 |
| Standing time/h | 10.5 | 12 | 13 | 11 | 10 | 11.5 | 11.33 | 1.08 |
| Drinking time/h | 3.5 | 3.0 | 3.0 | 3.5 | 3.5 | 3.0 | 3.25 | 0.27 |
| Feeding time/h | 0.5 | 0.4 | 0.5 | 0.4 | 0.25 | 0.3 | 0.391 | 0.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, K.; Zong, C.; Yang, T.; Peng, S.; Zhu, P.; Wang, H.; Teng, G.; Du, X. Detection and Analysis of Sow Targets Based on Image Vision. Agriculture 2022, 12, 73. https://doi.org/10.3390/agriculture12010073
Lei K, Zong C, Yang T, Peng S, Zhu P, Wang H, Teng G, Du X. Detection and Analysis of Sow Targets Based on Image Vision. Agriculture. 2022; 12(1):73. https://doi.org/10.3390/agriculture12010073
Chicago/Turabian StyleLei, Kaidong, Chao Zong, Ting Yang, Shanshan Peng, Pengfei Zhu, Hao Wang, Guanghui Teng, and Xiaodong Du. 2022. "Detection and Analysis of Sow Targets Based on Image Vision" Agriculture 12, no. 1: 73. https://doi.org/10.3390/agriculture12010073