
Multi-Feature Optimization Study of Soil Total Nitrogen Content Detection Based on Thermal Cracking and Artificial Olfactory System


Abstract
:1. Introduction
2. Materials and Methods
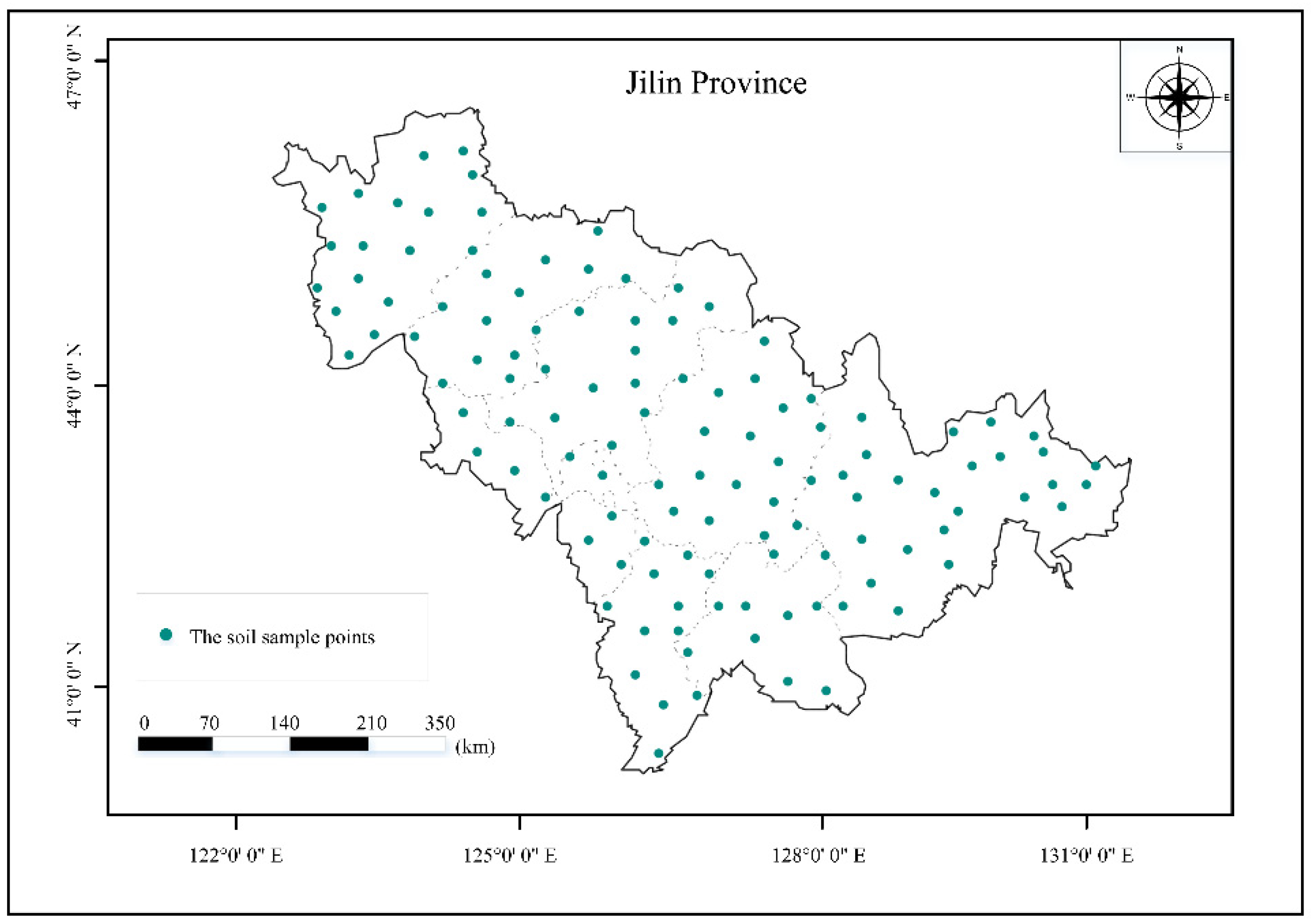
2.1. Study Area and Soil Samples
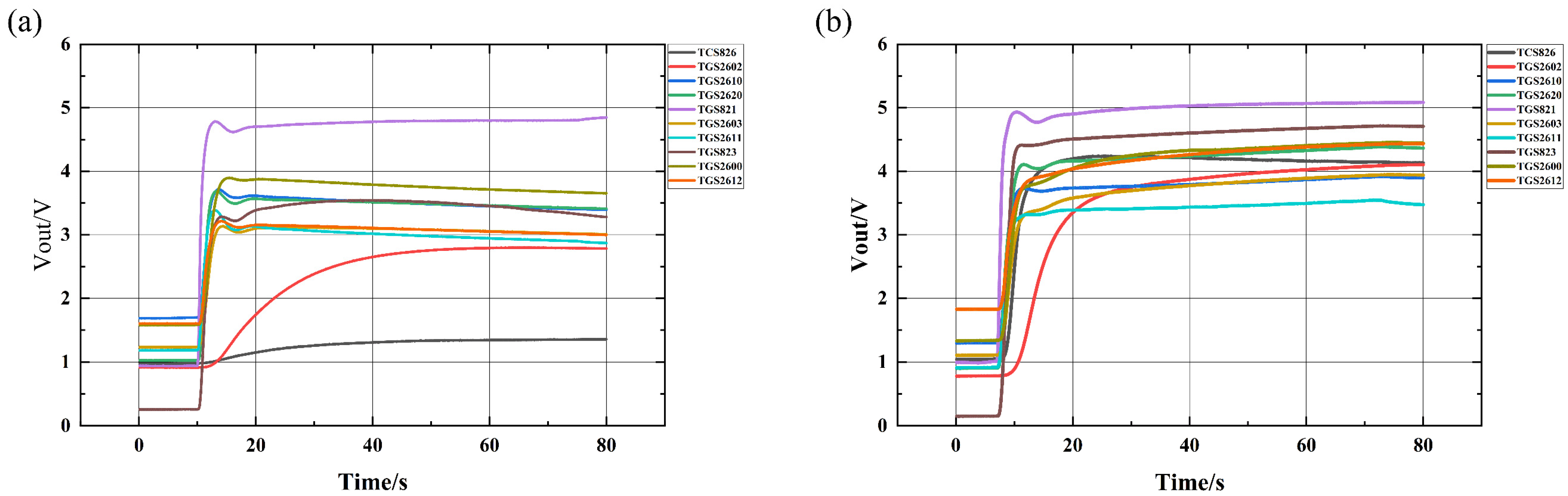
2.2. Research on Artificial Olfactory System
2.3. Feature Extraction
2.4. Training Set and Test Set Division
2.5. Sensor Array for Full Nitrogen Feature Space Response
2.6. Multi-Feature Optimization Methods and Pattern Recognition Prediction Models
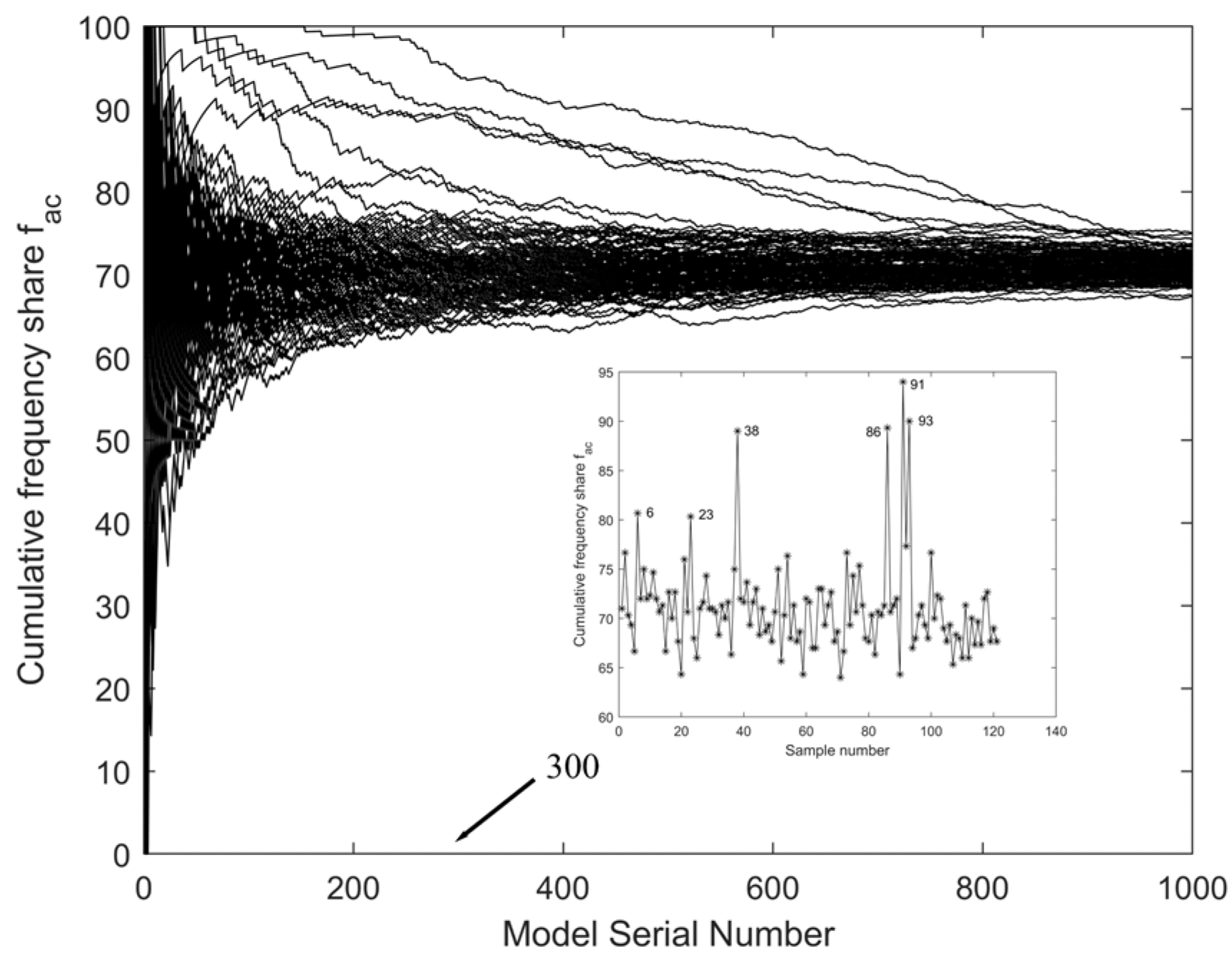
2.6.1. Abnormal Sample Removal Method
2.6.2. Monte Carlo Cross Validation Method
2.6.3. K-Means LOOCV Cross Validation
- (1)
- Spatial clustering of soil olfaction based on K-means clustering with a set number of clusters.
- (2)
- The classes with fewer samples in the clustering are treated as suspect samples and used as the test set for the BPNN model.
- (3)
- The remaining samples with suspected anomalies removed are taken as the training set and used to train a BPNN prediction model.
- (4)
- The input prediction of the test set with the trained model gives the corresponding prediction results and the relative error δ between the predicted and measured values is calculated.
- (5)
- Set the threshold value. If the value is greater than the threshold, it is considered an abnormal sample, otherwise it is considered a normal sample.
2.7. Feature Dimensionality Reduction Methods
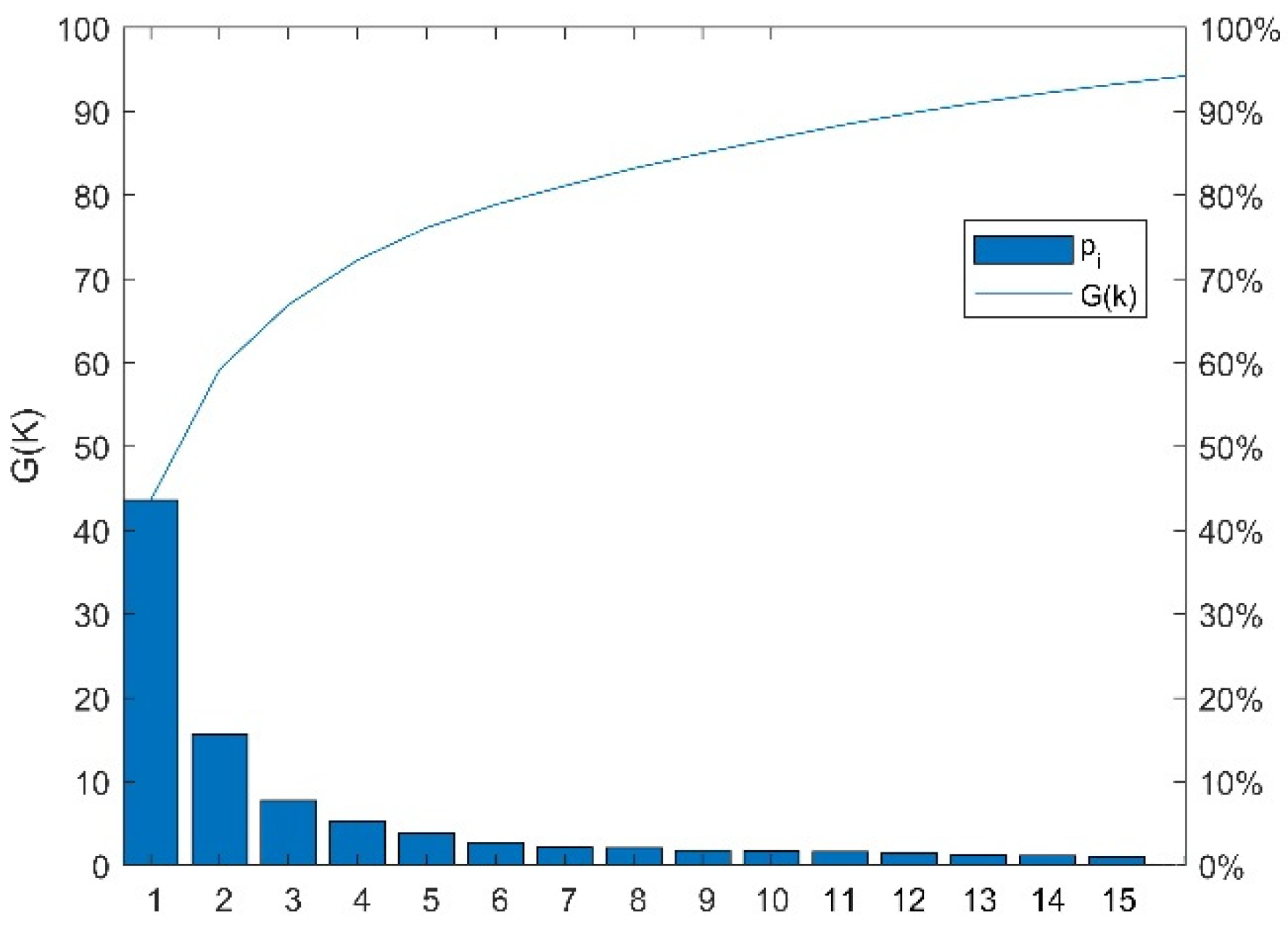
2.7.1. Principal Component Analysis
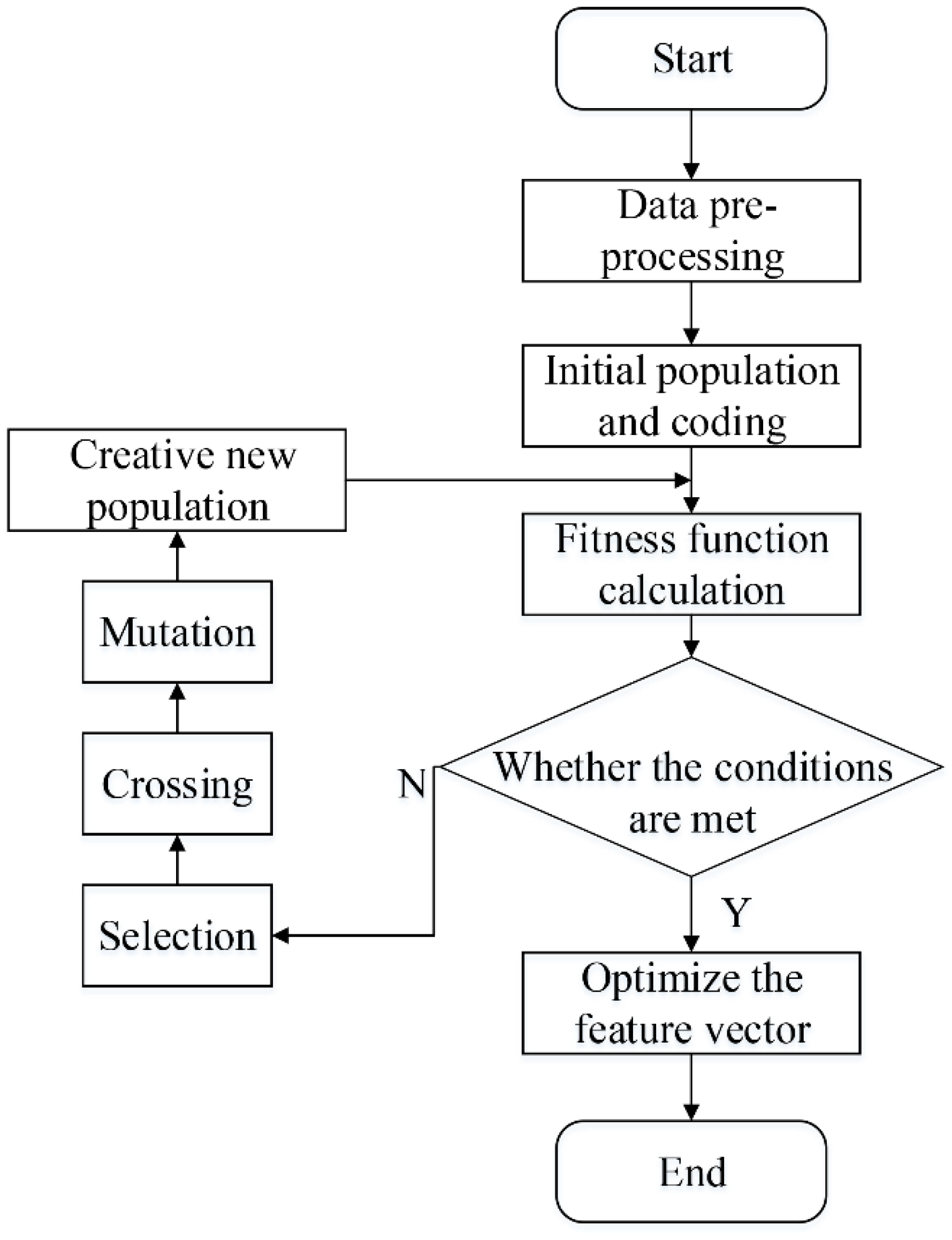
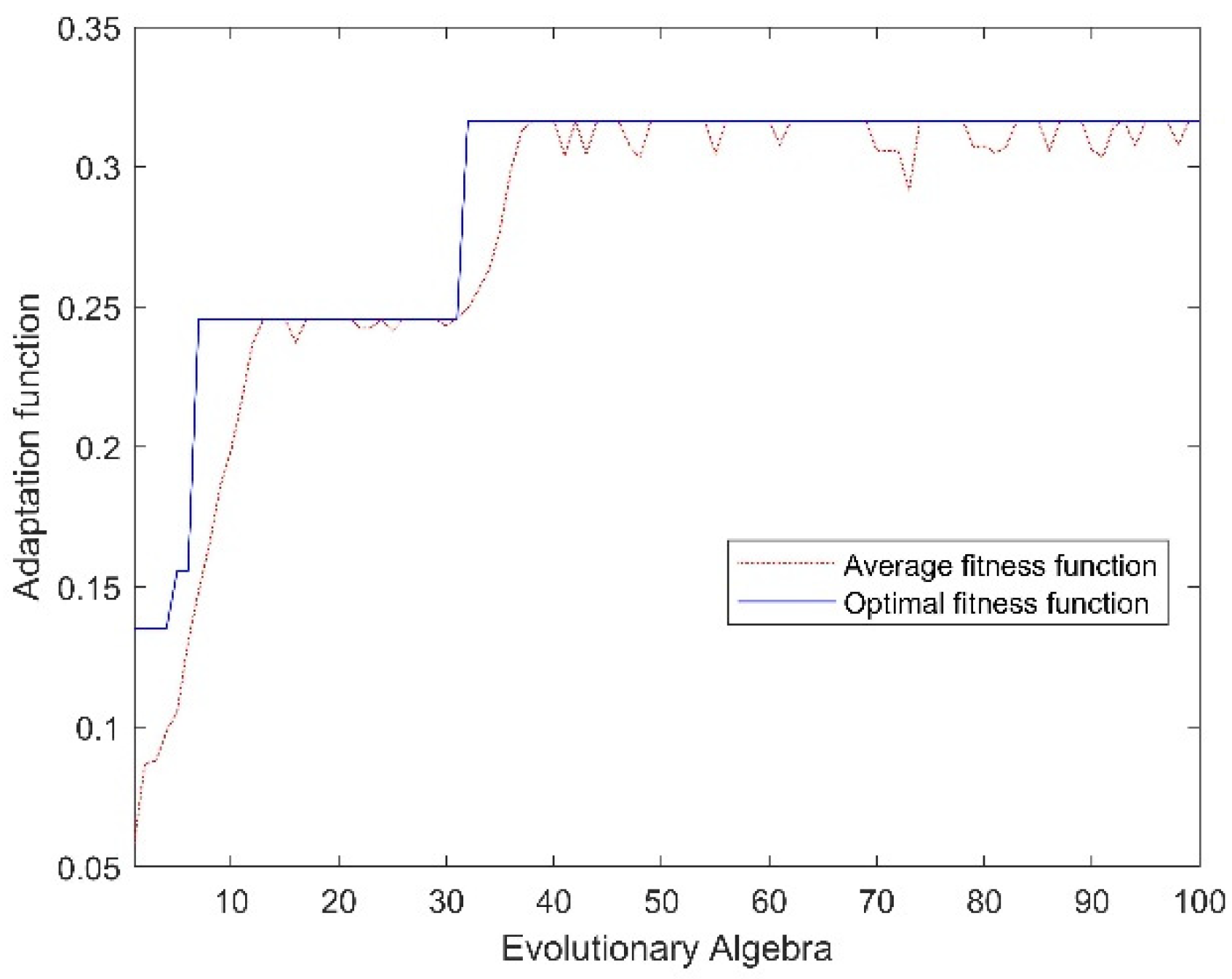
2.7.2. GA-BP Optimization
2.8. Pattern Recognition Prediction Model for Artificial Olfactory System
2.8.1. BPNN Prediction Algorithm
2.8.2. ELM Prediction Model
2.8.3. PLSR Prediction Model
2.8.4. Model Evaluation Metrics
3. Results and Discussion
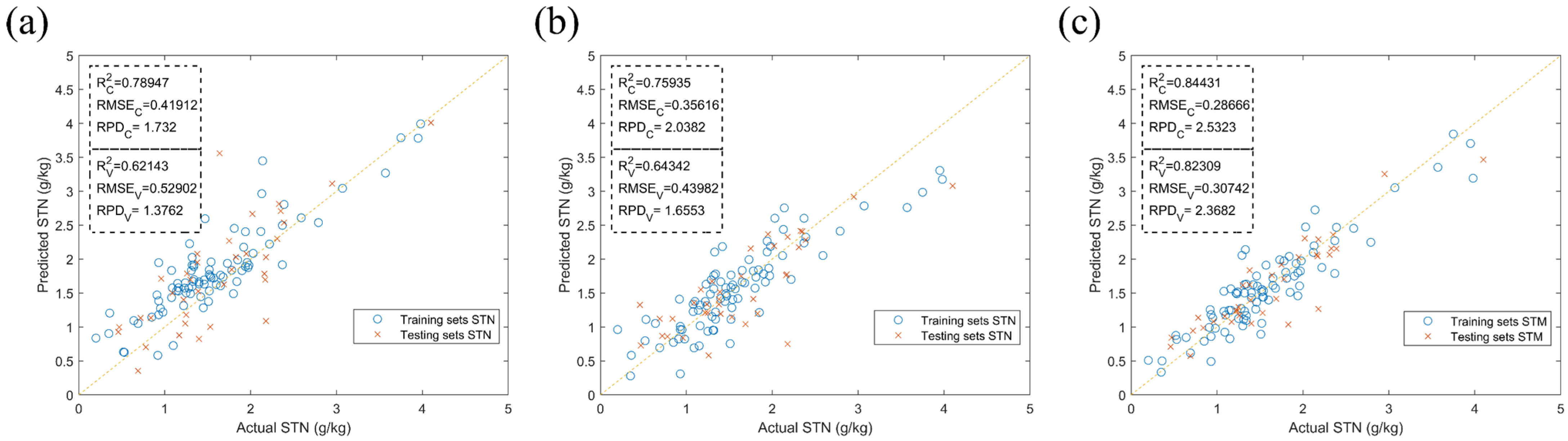
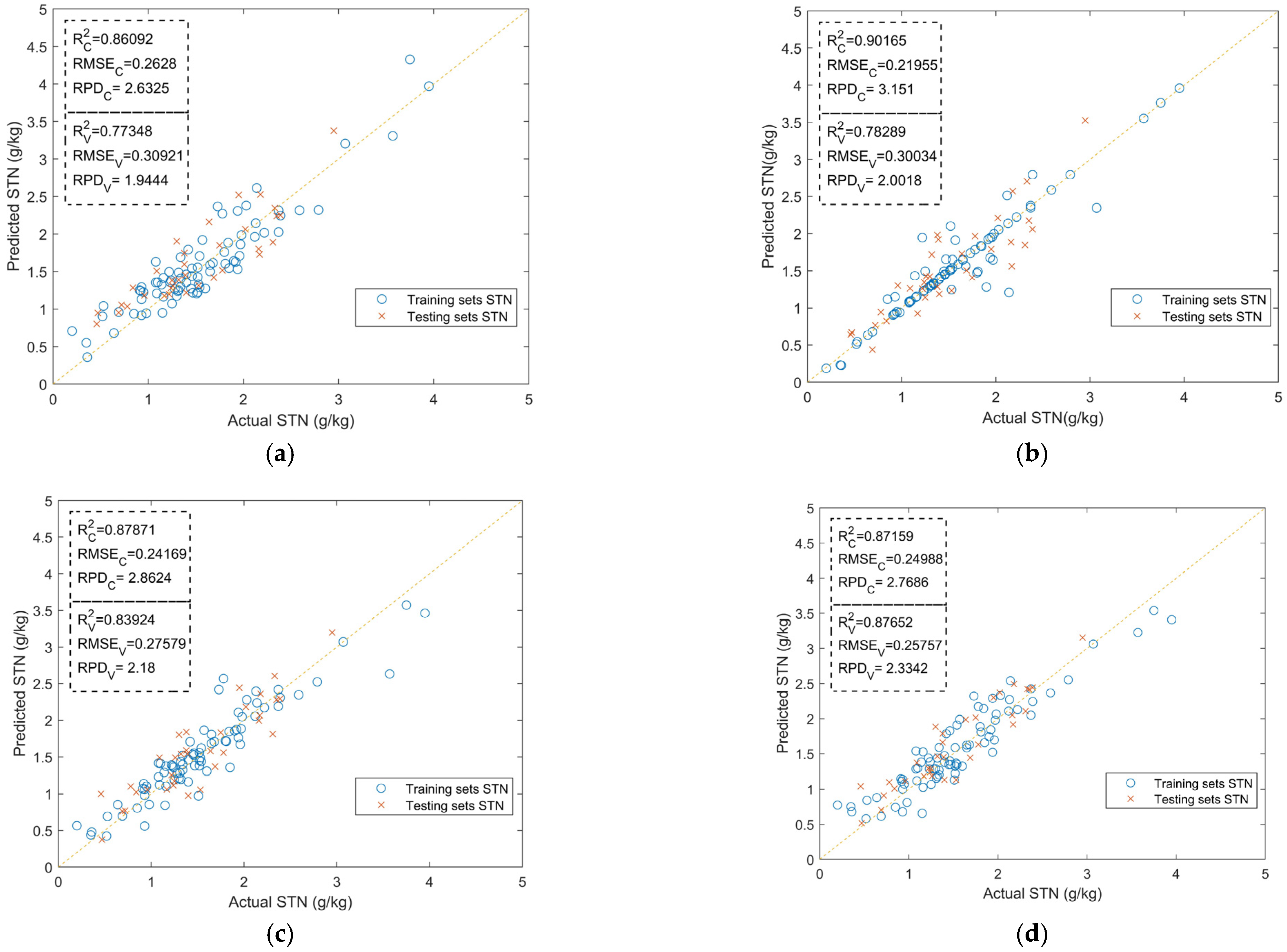
3.1. Preliminary Modeling Results
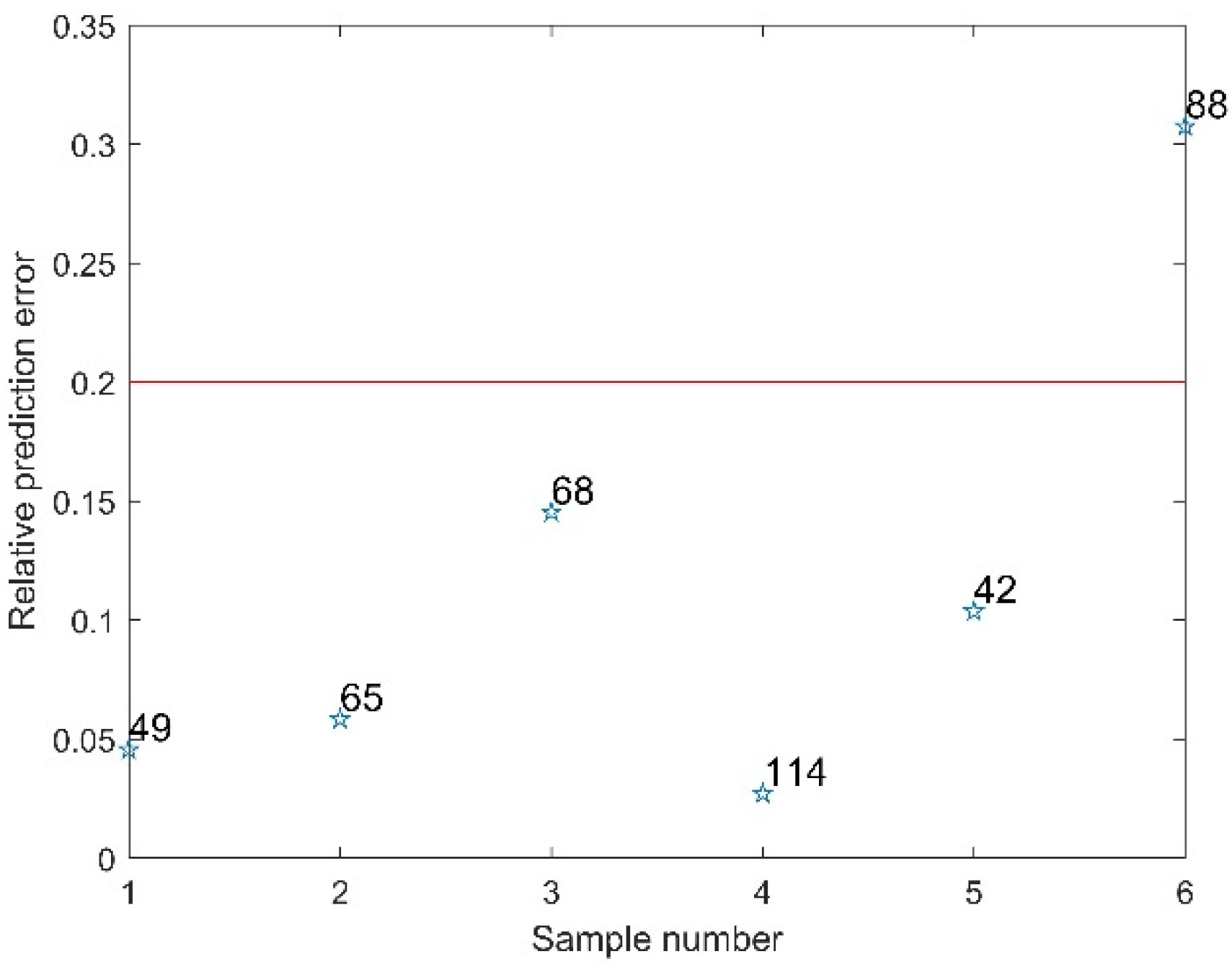
3.2. Abnormal Sample Rejection Results
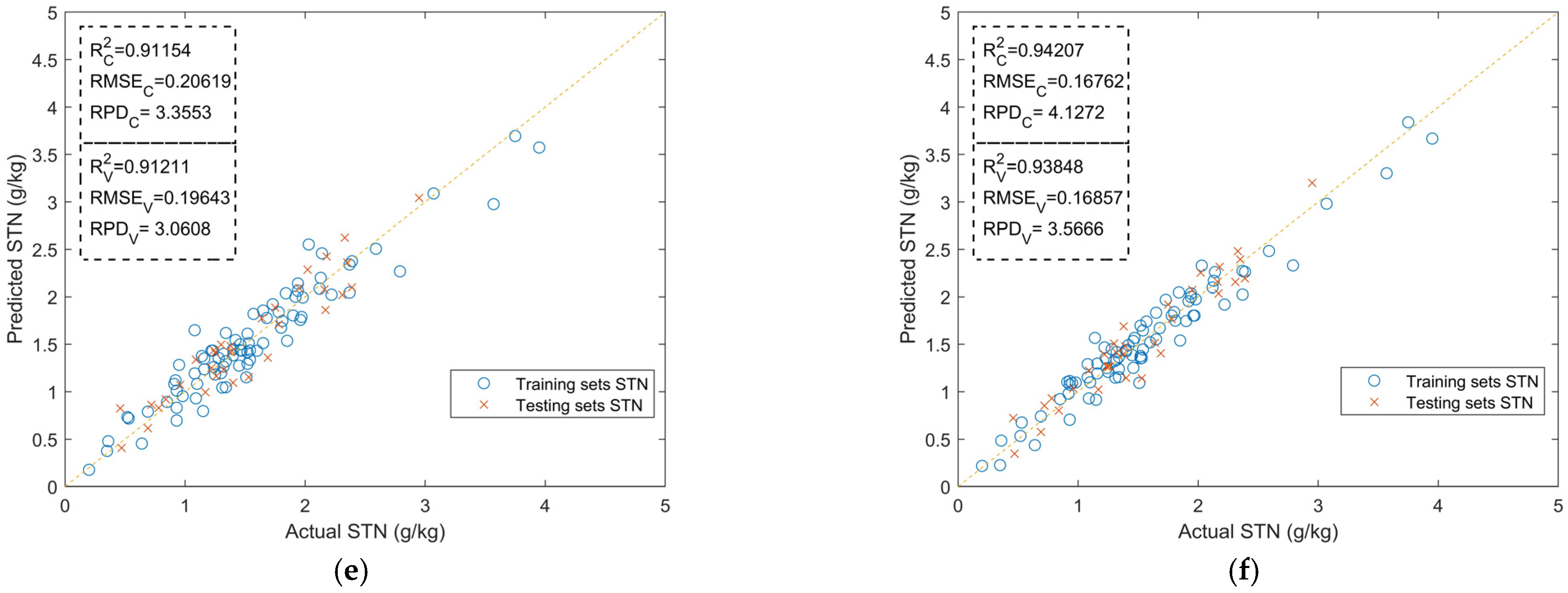
3.3. Feature Optimization Results
3.4. Discussion
4. Conclusions
- (1)
- All two sample rejection methods had gains in the accuracy of soil total nitrogen content prediction. The most significant effect of ISTNFS rejection was MCCV, and the BPNN model indexes improved by 21.76% and 30.34% and reduced by 36.64% in RMSEV compared to R2V and RPDV before the rejection treatment.
- (2)
- After MCCV to eliminate abnormal samples, GA-BP method has more advantages than PCA method in soil feature space (USTNFS) dimensionality reduction processing under the same model, and can achieve higher prediction performance.
- (3)
- After optimizing the treatment of ISTNFS using MCCV and GA-BP methods, the prediction performance of the three models, BPNN, ELM, and PLSR, increased by 45.45%, 41.01%, and 50.60% for RPD, 25.98%, 36.33%, and 14.01% for R2, and reduced by 76.14%, 70.75%, and 82.36%.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, X.; Gao, Y.; Liu, Z.; Zhang, M.; Wan, Y.; Yu, X.; Liu, W.; Li, L. Development of a predictive tool for rapid assessment of soil total nitrogen in wheat-corn double cropping system with hyperspectral data. Environ. Pollut. Bioavailab. 2019, 31, 272–281. [Google Scholar] [CrossRef]
- Li, M.; Li, R.; Zhang, J.; Wu, T.; Liu, S.; Hei, Z.; Qiu, S. Effects of the integration of mixed-cropping and rice–duck co-culture on rice yield and soil nutrients in southern China. J. Sci. Food Agric. 2020, 100, 277–286. [Google Scholar] [CrossRef] [PubMed]
- Klem, K.; Záhora, J.; Zemek, F.; Trunda, P.; Tůma, I.; Novotná, K.; Hodaňová, P.; Rapantová, B.; Hanuš, J.; Vavříková, J.; et al. Interactive effects of water deficit and nitrogen nutrition on winter wheat remote rensing methods for their detection. Agric. Water Manag. 2018, 210, 171–184. [Google Scholar] [CrossRef]
- Lin, L.; Gao, Z.; Liu, X. Estimation of soil total nitrogen using the synthetic color learning machine (SCLM) method and hyperspectral Data. Geoderma 2020, 380, 114664. [Google Scholar] [CrossRef]
- Li, H.; Yao, Y.; Zhang, X.; Zhu, H.; Wei, X. Changes in soil physical and hydraulic properties following the conversion of forest to cropland in the black soil region of northeast China. Catena 2021, 198, 104986. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, Y.; Yao, X.; Cao, W.; Ma, X.; Zhu, Y. Estimating model of soil total nitrogen content based on near-infrared spectroscopy analysis. Trans. CSAE 2012, 28, 183–188, (In Chinese with English Abstract). [Google Scholar] [CrossRef]
- Zhang, D.; Zhao, Y.; Qin, K. A new spectral parametric model for predicting nutrient content of black soils. Spectrosc. Spectr. Anal. 2018, 38, 2932–2936, (In Chinese with English Abstract). [Google Scholar]
- Li, H.; Jia, S.; Le, Z. Quantitative analysis of soil total nitrogen using hyperspectral imaging technology with extreme learning machine. Sensors 2019, 19, 4355. [Google Scholar] [CrossRef] [Green Version]
- Pechanec, V.; Mráz, A.; Rozkošný, L.; Vyvlečka, P. Usage of airborne hyperspectral imaging data for identifying spatial variability of soil nitrogen content. ISPRS Int. J. Geo-Inf. 2021, 10, 355. [Google Scholar] [CrossRef]
- Cheng, Z.; Lu, Z. A novel efficient feature dimensionality reduction method and its application in engineering. Complexity 2018, 2018, 2879640. [Google Scholar] [CrossRef] [Green Version]
- Shi, B.; Zhao, L.; Liu, W.; Wang, H.; Zhu, D.; Yin, J. Analysis of abnormal samples detected by NIR spectroscopy of apple internal quality. Trans. Chin. Soc. Agric. Mach. 2010, 42, 132–137, (In Chinese with English Abstract). [Google Scholar] [CrossRef]
- Ma, J.; Yuan, Y. Dimension reduction of image deep feature using PCA. J. Vis. Commun. Image Represent. 2019, 63, 102578. [Google Scholar] [CrossRef]
- Xu, K.; Wang, J.; Wei, Z.; Deng, F. An optimization of the MOS electronic nose sensor array for the detection of Chinese pecan quality. J. Food Eng. 2017, 203, 25–31. [Google Scholar] [CrossRef]
- Pham, V.; Weindorf, D.C.; Dang, T. Soil profile analysis using interactive visualizations, machine learning, and deep learning. Comput. Electron. Agric. 2021, 191, 106539. [Google Scholar] [CrossRef]
- Morellos, A.; Pantazi, X.-E.; Moshou, D.; Alexandridis, T.; Whetton, R.; Tziotzios, G.; Wiebensohn, J.; Bill, R.; Mouazen, A.M. Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS-NIR spectroscopy. Biosyst. Eng. 2016, 152, 104–116. [Google Scholar] [CrossRef] [Green Version]
- Olaya, J.F.C.; Ordoñez, M.C.; Salcedo, J.R. Impact of nutritional management on available mineral nitrogen and soil quality properties in coffee agroecosystems. Agriculture 2019, 9, 260. [Google Scholar] [CrossRef] [Green Version]
- Gu, S.; Wang, J.; Wang, Y. Early discrimination and growth tracking of aspergillus spp. contamination in rice kernels using electronic nose. Food Chem. 2019, 292, 325–335. [Google Scholar] [CrossRef]
- Wang, X.; Zhou, W.; Liang, G.; Song, D.; Zhang, X. Characteristics of maize biochar with different pyrolysis temperatures and its effects on organic carbon, nitrogen and enzymatic activities after addition to fluvo-aquic soil. Sci. Total Environ. 2015, 538, 137–144. [Google Scholar] [CrossRef]
- Liu, R.; Chen, W.; Xu, K.; Qiu, Q.; Cui, H. Application of rapid singularity detection in Near-Infrared Spectroscopy for milk composition measurement. Spectrosc. Spectr. Anal. 2005, 25, 207–210, (In Chinese with English Abstract). [Google Scholar] [CrossRef]
- Shapiro, A. Monte Carlo sampling methods. Handb. Oper. Res. Manag. Sci. 2003, 10, 353–425. [Google Scholar] [CrossRef]
- Li, X.; Wei, Y.; Xu, J.; Xu, N.; He, Y. Quantitative visualization of lignocellulose components in transverse sections of moso bamboo based on ftir macro- and micro-spectroscopy coupled with chemometrics. Biotechnol. Biofuels 2018, 11, 263. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Hu, Y.; Wu, S.; Sun, X.; Dou, S.; Miao, Y.; Dou, Y. A study of Near-Infrared Spectral singular sample rejection method. J. Food Sci. Technol. 2014, 32, 74–79, (In Chinese with English Abstract). [Google Scholar] [CrossRef]
- Li, J.; Sun, L.; Li, Y.; Lu, Y.; Pan, X.; Zhang, X.; Liu, Y.; Song, Z. Rapid prediction of acid detergent fiber content in corn stover based on NIR-Spectroscopy technology. Optik 2019, 180, 34–45. [Google Scholar] [CrossRef]
- Jirayucharoensak, S.; Pan-Ngum, S.; Israsena, P. EEG-Based emotion recognition using deep learning network with principal component based covariate shift adaptation. Sci. World J. 2014, 2014, 627892. [Google Scholar] [CrossRef] [Green Version]
- Assi, K. Traffic crash severity prediction—A synergy by hybrid principal component analysis and machine learning models. Int. J. Environ. Res. Public Health 2020, 17, 7598. [Google Scholar] [CrossRef]
- He, H.; Tian, C.; Jin, G.; Han, K. Principal component analysis and fisher discriminant analysis of environmental and ecological quality, and the impacts of coal mining in an environmentally sensitive area. Environ. Monit. Assess. 2020, 192, 207. [Google Scholar] [CrossRef]
- Wang, J. Analysis of sports performance prediction model based on GA-BP neural network algorithm. Comput. Intell. Neurosci. 2021, 2021, 4091821. [Google Scholar] [CrossRef]
- Wang, L.; Bi, X. Risk assessment of knowledge fusion in an innovation ecosystem based on a GA-BP neural network. Cogn. Syst. Res. 2020, 66, 201–210. [Google Scholar] [CrossRef]
- Jiang, G.; Grafton, M.; Pearson, D.; Bretherton, M.; Holmes, A. Integration of precision farming data and spatial statistical modelling to interpret field-scale maize productivity. Agriculture 2019, 9, 237. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Yang, D.; Wu, J.; Meng, X.; Li, X.; Wu, G.; Miao, Z.; Chu, R.; Yu, S. Prediction of temperature and CO concentration fields based on BPNN in low-temperature coal oxidation. Thermochim. Acta 2021, 695, 178820. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, J.; Yu, B.; Yu, Y. Construction of BPNN-based optimization model for spherical bow resistance reduction. J. Dalian Univ. Technol. 2021, 61, 160–171, (In Chinese with English Abstract). [Google Scholar] [CrossRef]
- Yin, S.; Liu, H.; Duan, Z. Hourly PM2.5 Concentration multi-step forecasting method based on extreme learning machine, boosting algorithm and error correction model. Digit. Signal Process. 2021, 118, 103221. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, B. Prediction of soil salinity with soil-reflected spectra: A comparison of two regression methods. Sci. Rep. 2019, 9, 5067. [Google Scholar] [CrossRef]
- Wang, Y.; Li, M.; Li, L.; Ning, J.; Zhang, Z. Green analytical assay for the quality assessment of tea by using pocket-sized NIR spectrometer. Food Chem. 2021, 345, 128816. [Google Scholar] [CrossRef]
- Zhu, L.; Jia, H.; Chen, Y.; Wang, Q.; Li, M.; Huang, D.; Bai, Y. A novel method for soil organic matter determination by using an artificial olfactory system. Sensors 2019, 19, 3417. [Google Scholar] [CrossRef] [Green Version]
- Dai, Y.; Zhou, B.; Wang, J. Application of electronic nose in detection of cotton bollworm infestation at an early stage. Trans. CSAE 2020, 36, 313–320, (In Chinese with English Abstract). [Google Scholar] [CrossRef]
- Michael, V.; Joachim, B.; Joachim, H.; Heinz-Christian, F. Comparing different multivariate calibration methods for the determination of soil organic carbon pools with visible to near infrared spectroscopy. Geoderma 2011, 1, 198–205. [Google Scholar] [CrossRef]
- Zulj, S.; Carvalho, P.; Ribeiro, R.T.; Andrade, R.; Magjarevic, R. Data size considerations and hyperparameter choices in case-based rea-soning approach to glucose prediction. Biocybern. Biomed. Eng. 2021, 41, 733–745. [Google Scholar] [CrossRef]
- Nakatsu, R.T. An Evaluation of Four Resampling Methods Used in Machine Learning Classification. IEEE Intell. Syst. 2020, 36, 51–57. [Google Scholar] [CrossRef]
- Barrow, D.K.; Crone, S.F. Cross-validation aggregation for combining autoregressive neural network forecasts. Int. J. Forecast. 2016, 32, 1120–1137. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Type | Detection of Gas Types | Measurement Range |
|---|---|---|
| TGS826 | Ammonia | 30–300 ppm |
| TGS2602 | Toluene, ammonia, hydrogen sulfide | 1–30 ppm |
| TGS2610 | Tropane, butane | 500–10,000 ppm |
| TGS2620 | Ethanol, organic solvent | 50–5000 ppm |
| TGS821 | Hydrogen | 100–1000 ppm |
| TGS2603 | Trimethylamine, methyl mercaptan, etc. | 1–10 ppm |
| TGS2611 | Methane, natural gas | 500–10,000 ppm |
| TGS823 | Methane, ethanol vapor | 50–300 ppm |
| TGS2600 | Hydrogen, alcohol, etc. | 1–30 ppm |
| TGS2612 | methane, propane, isobutane | 3000–9000 ppm |
| Dataset | STN (g kg−1) | Mean Values (g kg−1) | Variance (g kg−1) |
|---|---|---|---|
| Training set | 1.42, 1.65, 1.81, 1.39, 1.38, 1.75, 1.17, 1.25, 0.84, 1.46, 1.38, 1.80, 1.64, 1.27, 1.33, 0.20, 1.85, 1.5, 2.18, 1.90, 2.38, 0.52, 1.29, 0.36, 1.35, 2.18, 1.15, 0.93, 2.02, 0.35, 1.51, 2.14, 1.73, 1.56, 1.32, 1.66, 1.57, 1.40, 1.34, 1.18, 0.68, 1.26, 1.14, 0.92, 0.64, 1.09, 1.83, 0.72, 1.52, 1.24, 1.93, 1.76, 2.12, 1.94, 1.92, 0.47, 1.69, 1.97, 0.95, 1.22, 1.84, 2.33, 2.13, 1.08, 2.35, 4.10, 1.47, 0.78, 1.07, 2.03, 2.31, 1.28, 2.37, 1.78, 1.70, 1.10, 1.53, 2.79, 3.95, 3.75, 1.41, 3.07, 1.30, 1.20, 0.46 | 1.56 | 0.51 |
| Test set | 1.95, 1.98, 1.16, 3.57, 1.53, 1.45, 3.98, 0.98, 2.44, 1.06, 0.94, 0.90, 1.52, 1.23, 1.68, 2.22, 0.91, 1.37, 2.17, 1.21, 1.96, 0.69, 1.54, 0.85, 1.48, 1.30, 1.40, 0.53, 2.39, 1.34, 2.59, 1.60, 0.96, 2.95, 1.31, 2.16 | 1.64 | 0.60 |
| Class Number | Number of Samples | Sample Number |
|---|---|---|
| Class 1 | 17 | 5 16 18 32 39 41 45 63 75 76 80 81 82 84 85 93 118 |
| Class 2 | 6 | 20 29 43 73 86 113 |
| Class 3 | 16 | 1 13 62 72 74 79 92 102 103 104 111 115 116 119 120 121 |
| Class 4 | 18 | 17 19 22 27 28 30 35 40 44 48 58 78 83 89 91 97 109 117 |
| Class 5 | 13 | 3 8 9 10 14 25 34 47 56 61 77 96 107 |
| Class 6 | 4 | 49 65 68 114 |
| Class 7 | 2 | 42 88 |
| Class 8 | 18 | 4 6 11 15 23 24 26 38 51 52 69 90 100 101 105 106 108 112 |
| Class 9 | 14 | 2 12 21 31 46 50 54 59 60 64 66 70 87 98 |
| Class 10 | 13 | 7 33 36 37 53 57 67 71 94 95 99 110 |
| Types of Rejection Methods | Number of Training Set Samples | Test Set Number of Samples | Number of Neurons in the Hidden Layer | BPNN Model Test Set Prediction Performance | ||
|---|---|---|---|---|---|---|
| R2V | RMSEV | RPDV | ||||
| MCCV | 81 | 34 | 8 | 0.75671 | 0.33517 | 1.7938 |
| K-means LOOCV | 84 | 36 | 8 | 0.69951 | 0.42919 | 1.6728 |
| Models | Feature Space of Optimization Process | R2V | RMSEV | RPDV |
|---|---|---|---|---|
| BPNN | Unoptimized | 0.62143 | 0.52902 | 1.3762 |
| MCCV | 0.75671 | 0.33517 | 1.6553 | |
| MCCV + GA − BP | 0.78289 | 0.30034 | 2.0018 | |
| ELM | Unoptimized | 0.64342 | 0.43982 | 1.6553 |
| MCCV | 0.82808 | 0.29323 | 2.0504 | |
| MCCV + GA − BP | 0.87652 | 0.25757 | 2.3342 | |
| PLSR | Unoptimized | 0.82309 | 0.30742 | 2.3682 |
| MCCV | 0.89342 | 0.19556 | 3.0305 | |
| MCCV + GA − BP | 0.93848 | 0.16857 | 3.5666 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Zhu, Q.; Xia, X.; Li, M.; Huang, D. Multi-Feature Optimization Study of Soil Total Nitrogen Content Detection Based on Thermal Cracking and Artificial Olfactory System. Agriculture 2022, 12, 37. https://doi.org/10.3390/agriculture12010037
Liu H, Zhu Q, Xia X, Li M, Huang D. Multi-Feature Optimization Study of Soil Total Nitrogen Content Detection Based on Thermal Cracking and Artificial Olfactory System. Agriculture. 2022; 12(1):37. https://doi.org/10.3390/agriculture12010037
Chicago/Turabian StyleLiu, He, Qinghui Zhu, Xiaomeng Xia, Mingwei Li, and Dongyan Huang. 2022. "Multi-Feature Optimization Study of Soil Total Nitrogen Content Detection Based on Thermal Cracking and Artificial Olfactory System" Agriculture 12, no. 1: 37. https://doi.org/10.3390/agriculture12010037