
3D Point Cloud on Semantic Information for Wheat Reconstruction

Abstract
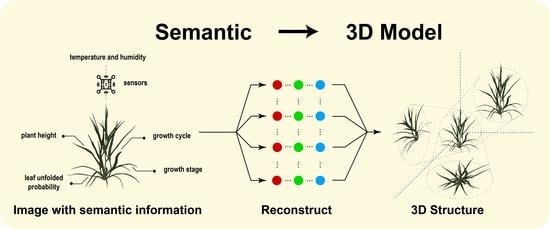
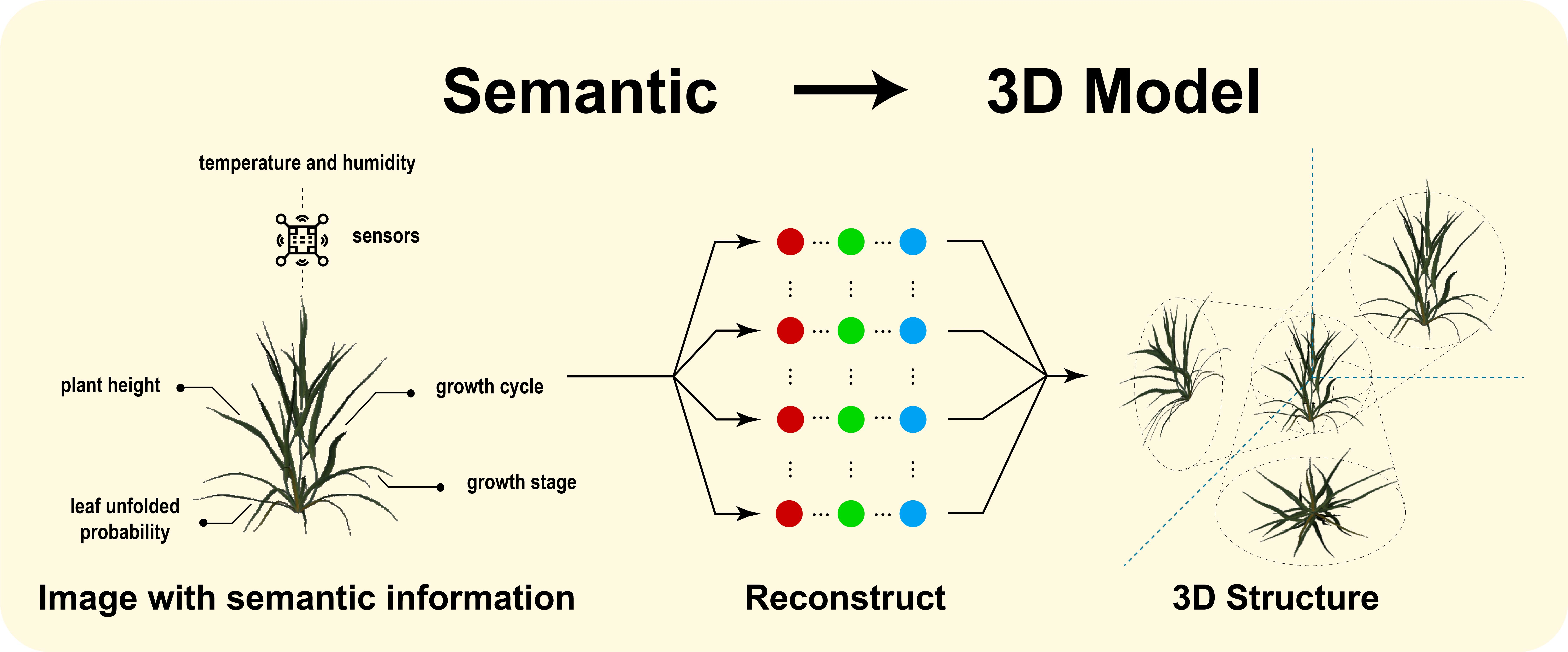
:
1. Introduction
- A wheat dataset is proposed, which contains wheat data annotation for object detection, text-to-image, and 3D point cloud; it can be used by other researchers.
- The method of object detection is used to automatically detect when wheat enters each growth stage.
- We proposed a method to reconstruct a 3D point cloud model of wheat by text description; the method is based on multi-task cooperation.
2. Related Work
- Deep Learning in Wheat Breeding
- Object Detection Algorithms
- Text-to-Image Algorithms
- Reconstruction of Wheat 3D Model
3. Materials and Methods
3.1. Materials
3.1.1. RGB Image and Semantic Information
3.1.2. Data Preprocessing
3.2. Methods
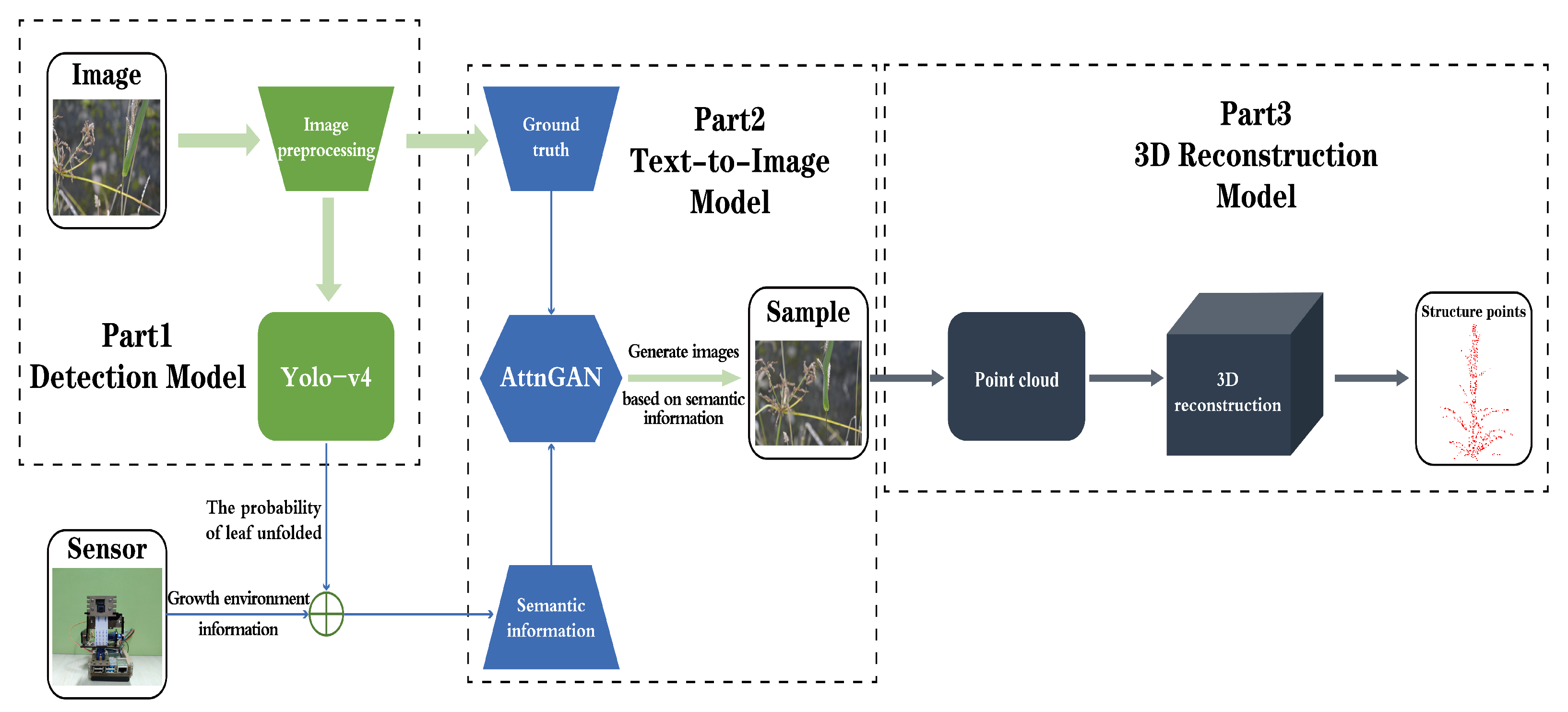
3.2.1. Detection Model
3.2.2. Text-to-Image Model
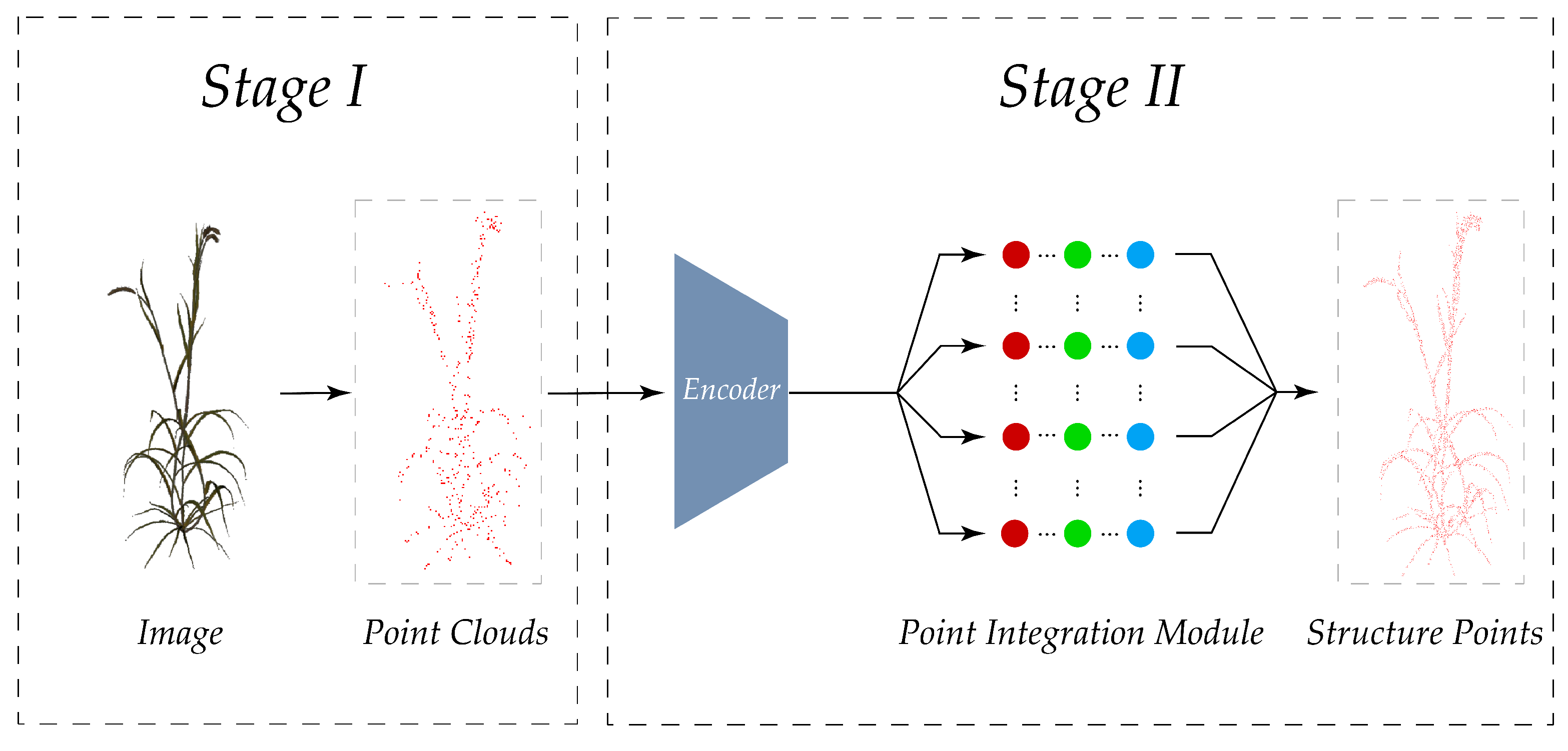
3.2.3. Three-Dimensional Point Cloud Model
4. Experiments
4.1. Experimental Results
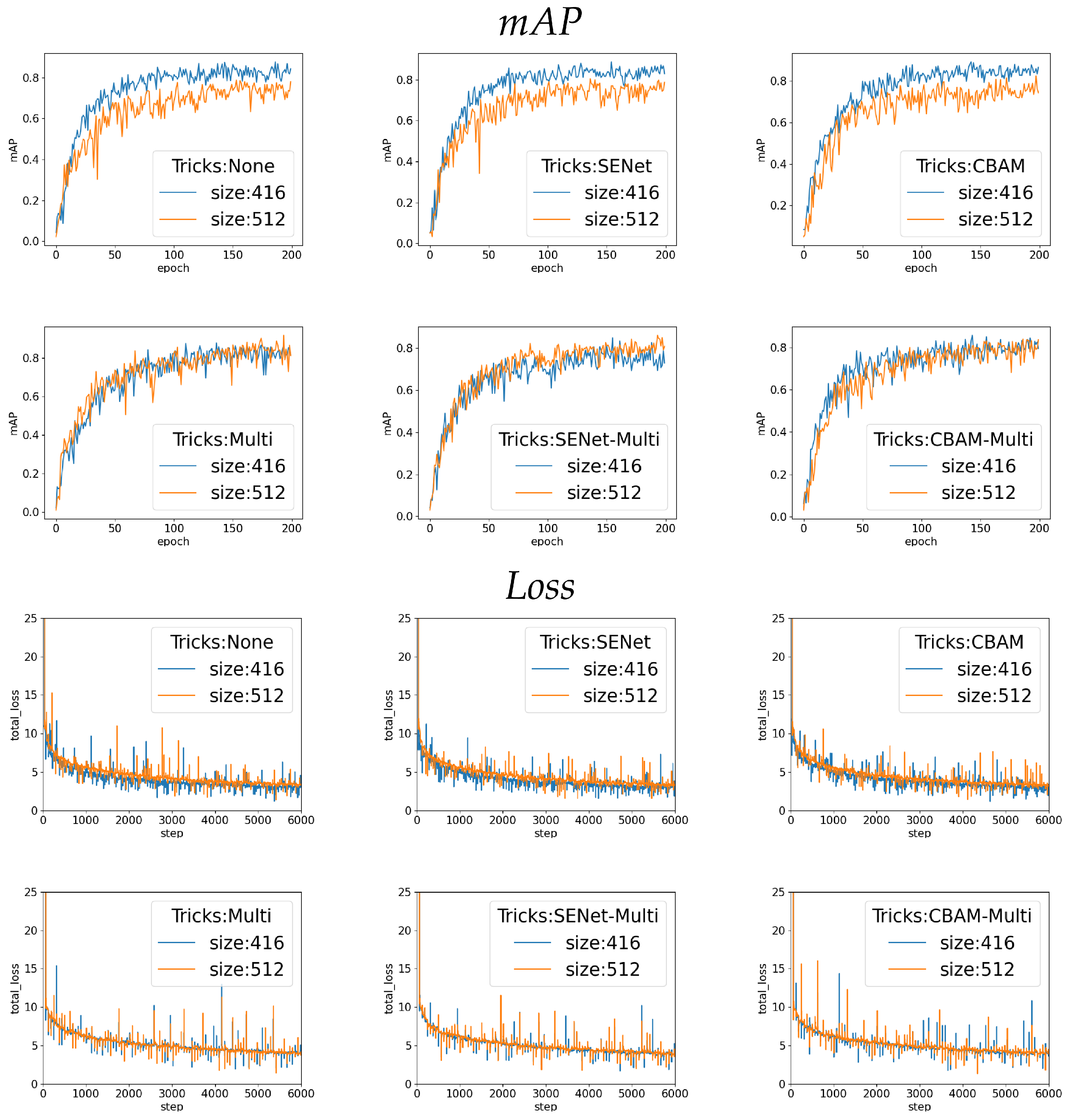
- The attention mechanism and multi-scale training are helpful to improve mAP value; when the image size is 416, the mAP value using SENet or CBAM is 0.015 higher than using multi-scale training. However, when the image size is 512, the mAP value using multi-scale training is 0.1 higher than using SENet or CBAM.
- When the attention mechanism is used together with multi-scale training, the improvement in experimental results is not obvious; especially when the image size is 416, the map value was even reduced. This shows that the combination of multi-scale training and an attention mechanism requires a larger image size to provide more information.
- When using CBAM, the mAP value is 0.01 higher than using SENet in all experiments. Additionally, it can be seen from the training process that the loss decreases more smoothly when using CBAM. The reason is that CBAM has one more spatial attention than SENet.
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shiferaw, B.; Prasanna, B.M.; Hellin, J.; Bänziger, M. Crops that feed the world 6. Past successes and future challenges to the role played by maize in global food security. Food Secur. 2011, 3, 307. [Google Scholar] [CrossRef] [Green Version]
- Tilman, D.; Balzer, C.; Hill, J.; Befort, B.L. Global food demand and the sustainable intensification of agriculture. Proc. Natl. Acad. Sci. USA 2011, 108, 20260–20264. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zadoks, J.C.; Chang, T.T.; Konzak, C.F. A decimal code for the growth stages of cereals. Weed Res. 1974, 14, 415–421. [Google Scholar] [CrossRef]
- Sadeghi-Tehran, P.; Sabermanesh, K.; Virlet, N.; Hawkesford, M.J. Automated method to determine two critical growth stages of wheat: Heading and flowering. Front. Plant Sci. 2017, 8, 252. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Barratt, S.; Sharma, R. A note on the inception score. arXiv 2018, arXiv:1801.01973. [Google Scholar]
- Senapati, N.; Stratonovitch, P.; Paul, M.J.; Semenov, M.A. Drought tolerance during reproductive development is important for increasing wheat yield potential under climate change in Europe. J. Exp. Bot. 2019, 70, 2549–2560. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Li, T.; Hao, C.; Wang, Y.; Chen, X.; Zhang, X. Ta GS 5-3A, a grain size gene selected during wheat improvement for larger kernel and yield. Plant Biotechnol. J. 2016, 14, 1269–1280. [Google Scholar] [CrossRef]
- Hassan, M.A.; Yang, M.; Rasheed, A.; Yang, G.; Reynolds, M.; Xia, X.; Xiao, Y.; He, Z. A rapid monitoring of NDVI across the wheat growth cycle for grain yield prediction using a multi-spectral UAV platform. Plant Sci. 2019, 282, 95–103. [Google Scholar] [CrossRef]
- Wolanin, A.; Mateo-García, G.; Camps-Valls, G.; Gómez-Chova, L.; Meroni, M.; Duveiller, G.; Liangzhi, Y.; Guanter, L. Estimating and understanding crop yields with explainable deep learning in the Indian Wheat Belt. Environ. Res. Lett. 2020, 15, 024019. [Google Scholar] [CrossRef]
- Wang, X.; Xuan, H.; Evers, B.; Shrestha, S.; Pless, R.; Poland, J. High-throughput phenotyping with deep learning gives insight into the genetic architecture of flowering time in wheat. GigaScience 2019, 8, giz120. [Google Scholar]
- Zhong, L.; Hu, L.; Zhou, H.; Tao, X. Deep learning based winter wheat mapping using statistical data as ground references in Kansas and northern Texas, US. Remote Sens. Environ. 2019, 233, 111411. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 2015, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 2016, 379–387. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2014, 2672–2680. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Yu, T.; Meng, J.; Yuan, J. Multi-view harmonized bilinear network for 3d object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 186–194. [Google Scholar]
- Liu, Y.; Fan, B.; Meng, G.; Lu, J.; Xiang, S.; Pan, C. Densepoint: Learning densely contextual representation for efficient point cloud processing. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5239–5248. [Google Scholar]
- Boulch, A. ConvPoint: Continuous convolutions for point cloud processing. Comput. Graph. 2020, 88, 24–34. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3d point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9621–9630. [Google Scholar]
- Fang, W.; Feng, H.; Yang, W.; Duan, L.; Chen, G.; Xiong, L.; Liu, Q. High-throughput volumetric reconstruction for 3D wheat plant architecture studies. J. Innov. Opt. Health Sci. 2016, 9, 1650037. [Google Scholar] [CrossRef]
- Lassale, C.; Guilbert, C.; Keogh, J.; Syrette, J.; Lange, K.; Cox, D. Estimating food intakes in Australia: Validation of the Commonwealth Scientific and Industrial Research Organisation (CSIRO) food frequency questionnaire against weighed dietary intakes. J. Hum. Nutr. Diet. 2009, 22, 559–566. [Google Scholar] [CrossRef] [PubMed]
- Pound, M.P.; French, A.P.; Murchie, E.H.; Pridmore, T.P. Automated recovery of three-dimensional models of plant shoots from multiple color images. Plant Physiol. 2014, 166, 1688–1698. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, N.; Liu, L.; Cui, Z.; Chen, R.; Ceylan, D.; Tu, C.; Wang, W. Unsupervised Learning of Intrinsic Structural Representation Points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9121–9130. [Google Scholar]
- Gay, W. DHT11 sensor. In Advanced Raspberry Pi; Springer: Berlin/Heidelberg, Germany, 2018; pp. 399–418. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Reed, S.E.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning what and where to draw. Adv. Neural Inf. Process. Syst. 2016, 2016, 217–225. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 2017, 5099–5108. [Google Scholar]
- Yue, Y.; Finley, T.; Radlinski, F.; Joachims, T. A support vector method for optimizing average precision. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 271–278. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Kempthorne, D.M.; Turner, I.W.; Belward, J.A.; McCue, S.W.; Barry, M.; Young, J.; Dorr, G.J.; Hanan, J.; Zabkiewicz, J.A. Surface reconstruction of wheat leaf morphology from three-dimensional scanned data. Funct. Plant Biol. 2015, 42, 444–451. [Google Scholar] [CrossRef] [Green Version]
- Gibbs, J.A.; Pound, M.; French, A.P.; Wells, D.M.; Murchie, E.; Pridmore, T. Approaches to three-dimensional reconstruction of plant shoot topology and geometry. Funct. Plant Biol. 2017, 44, 62–75. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SENet | CBAM | Mutil-Scale | Size | mAP |
|---|---|---|---|---|
| 416 | 0.877 | |||
| 512 | 0.788 | |||
| √ | 416 | 0.887 | ||
| √ | 416 | 0.893 | ||
| √ | 416 | 0.876 | ||
| √ | √ | 416 | 0.849 | |
| √ | √ | 416 | 0.859 | |
| √ | 512 | 0.804 | ||
| √ | 512 | 0.825 | ||
| √ | 512 | 0.917 | ||
| √ | √ | 512 | 0.841 | |
| √ | √ | 512 | 0.862 |
| DAMSM | Inception Score | R-Precision | |
|---|---|---|---|
| 0.1 | 4.08 ± 0.03 | 16.47 ± 4.72 | |
| √ | 0.1 | 4.25 ± 0.04 | 16.87 ± 5.23 |
| 1 | 4.33 ± 0.02 | 33.46 ± 4.34 | |
| √ | 1 | 4.37 ± 0.01 | 35.72 ± 4.88 |
| 5 | 4.36 ± 0.03 | 57.62 ± 5.33 | |
| √ | 5 | 4.39 ± 0.02 | 58.64 ± 5.28 |
| 10 | 4.38 ± 0.05 | 62.68 ± 4.26 | |
| √ | 10 | 4.41 ± 0.03 | 64.78 ± 5.12 |
| 50 | 4.31 ± 0.02 | 57.68 ± 4.56 | |
| √ | 50 | 4.35 ± 0.05 | 58.94 ± 4.34 |
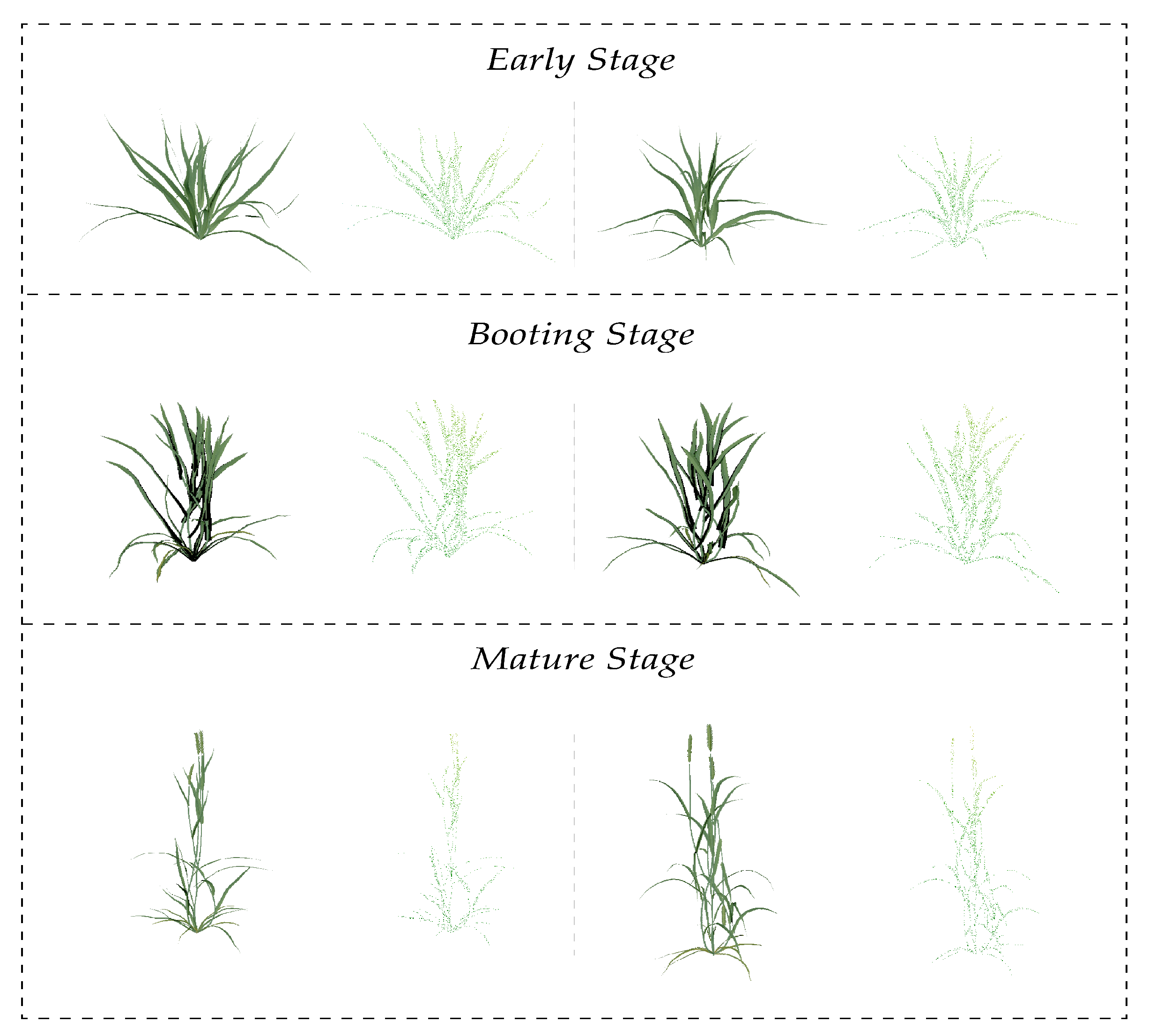
| Stage | Sample Num | Average Distance (%) |
|---|---|---|
| Early | 256 | 0.487 |
| Early | 512 | 0.136 |
| Early | 1024 | 0.036 |
| Booting | 256 | 0.544 |
| Booting | 512 | 0.097 |
| Booting | 1024 | 0.022 |
| Mature | 256 | 0.479 |
| Mature | 512 | 0.067 |
| Mature | 1024 | 0.014 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Zhang, J.; Wu, K.; Zhang, X.; Sun, J.; Peng, S.; Li, J.; Wang, M. 3D Point Cloud on Semantic Information for Wheat Reconstruction. Agriculture 2021, 11, 450. https://doi.org/10.3390/agriculture11050450
Yang Y, Zhang J, Wu K, Zhang X, Sun J, Peng S, Li J, Wang M. 3D Point Cloud on Semantic Information for Wheat Reconstruction. Agriculture. 2021; 11(5):450. https://doi.org/10.3390/agriculture11050450
Chicago/Turabian StyleYang, Yuhang, Jinqian Zhang, Kangjie Wu, Xixin Zhang, Jun Sun, Shuaibo Peng, Jun Li, and Mantao Wang. 2021. "3D Point Cloud on Semantic Information for Wheat Reconstruction" Agriculture 11, no. 5: 450. https://doi.org/10.3390/agriculture11050450