
Mathematical Modeling of COVID-19 Cases and Deaths and the Impact of Vaccinations during Three Years of the Pandemic in Peru


 , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
- Cases: Total confirmed cases of COVID-19. Counts can include probable cases, where reported (from 6 March 2020 to 20 March 2023).
- Deaths: Total deaths attributed to COVID-19. Counts can include probable deaths, where reported (from 6 March 2020 to 20 March 2023).
- People vaccinated: Total number of people who received at least one vaccine dose (from 9 February 2021 to 20 March 2023).
2.2. Mathematical Modeling
2.3. Statistical Analysis
2.3.1. Normality Tests for the Variables: Cases, Deaths, and People Vaccinated
2.3.2. Correlation Test between People Vaccinated and Cases
2.3.3. Correlation Test between People Vaccinated and Deaths
2.3.4. Causality Tests for the Variables: Cases, Deaths, and People Vaccinated
2.3.5. Stationarity Tests for the Variables: Cases, Deaths, and People Vaccinated
2.3.6. Information Criteria for Determining the Lag-Orders
2.3.7. Comparison of Modeled Variables against Real Data
3. Results
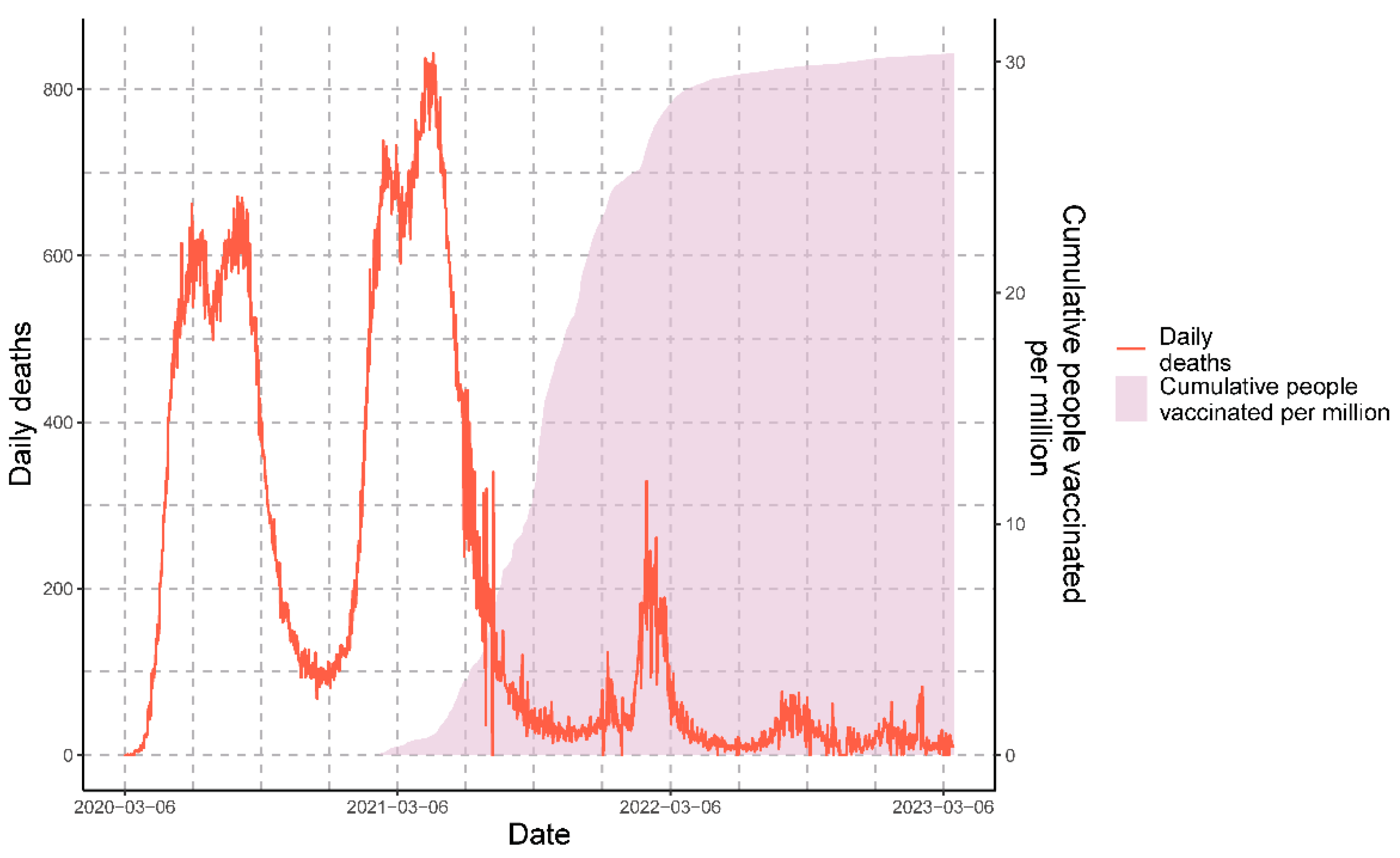
3.1. Epidemiological Panorama of COVID-19 in Peru
3.2. Mathematical Modeling
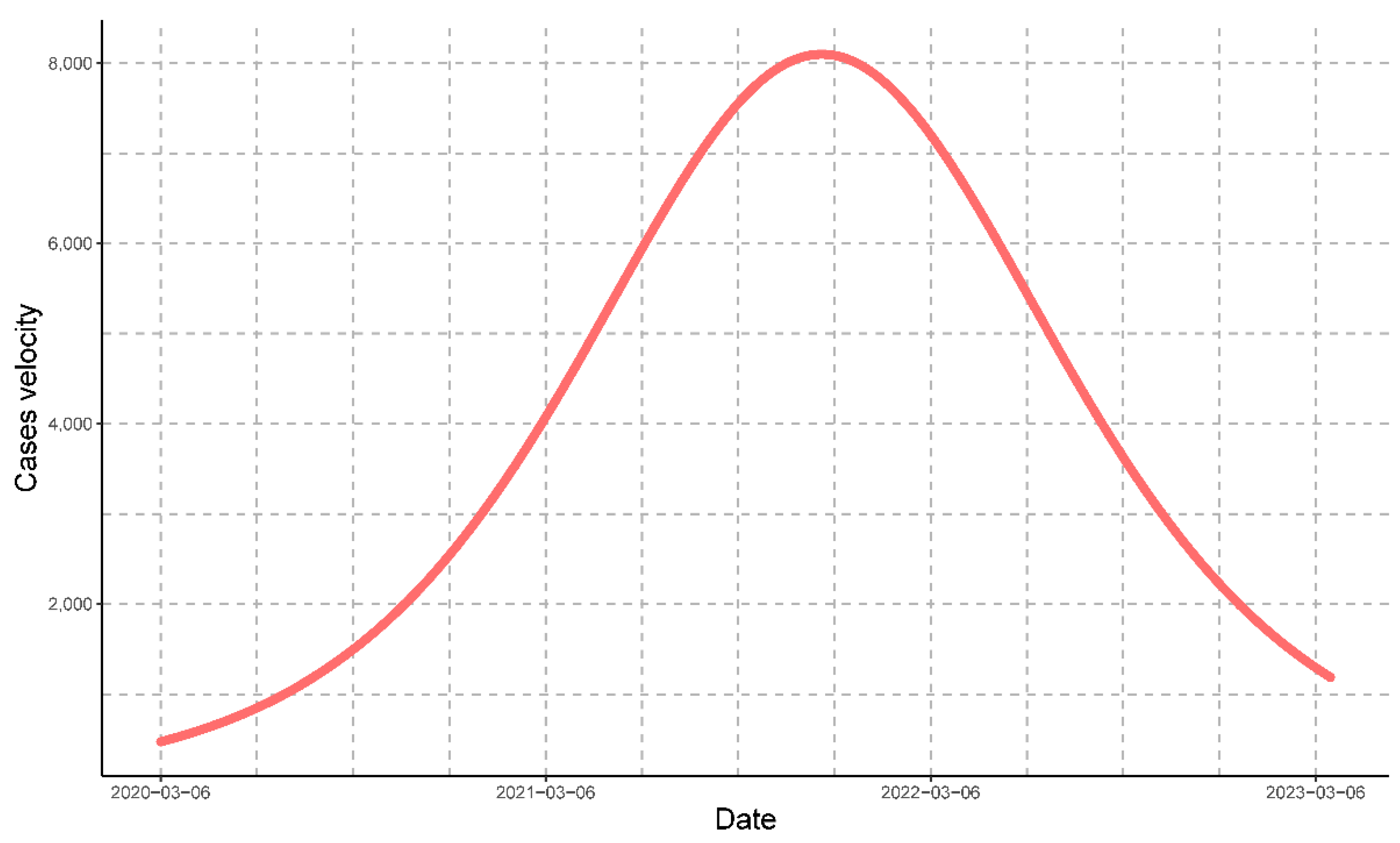
3.2.1. Mathematical Modeling for Cases
3.2.2. Mathematical Modeling for Deaths
3.2.3. Mathematical Modeling for People Vaccinated
3.3. Statistical Analysis
3.3.1. Normality Tests for the Variables: Cases, Deaths, and People Vaccinated
3.3.2. Correlation Test between People Vaccinated and Cases
3.3.3. Correlation Test between People Vaccinated and Deaths
3.3.4. Information Criteria for Determining the Lag Orders
3.3.5. Stationarity Tests for the Variables: Cases, Deaths, and People Vaccinated
3.3.6. Causality Tests between the Variables: Cases, Deaths, and People Vaccinated
3.3.7. Comparison of Modeled Variables against Real Data
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Zhao, X.; Huang, B.; Shi, W.; Lu, R.; et al. A Novel Coronavirus from Patients with Pneumonia in China, 2019. N. Engl. J. Med. 2020, 382, 727–733. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; McGoogan, J.M. Characteristics of and Important Lessons from the Coronavirus Disease 2019 (COVID-19) Outbreak in China: Summary of a Report of 72314 Cases From the Chinese Center for Disease Control and Prevention. JAMA 2020, 323, 1239–1242. [Google Scholar] [CrossRef] [PubMed]
- WHO Coronavirus (COVID-19) Dashboard. Available online: https://covid19.who.int/ (accessed on 20 March 2023).
- Kolahchi, Z.; De Domenico, M.; Uddin, L.Q.; Cauda, V.; Grossmann, I.; Lacasa, L.; Grancini, G.; Mahmoudi, M.; Rezaei, N. COVID-19 and Its Global Economic Impact. Adv. Exp. Med. Biol. 2021, 1318, 825–837. [Google Scholar] [CrossRef] [PubMed]
- Markov, P.V.; Ghafari, M.; Beer, M.; Lythgoe, K.; Simmonds, P.; Stilianakis, N.I.; Katzourakis, A. The Evolution of SARS-CoV-2. Nat. Rev. Microbiol. 2023, 21, 361–379. [Google Scholar] [CrossRef]
- Jiang, X.; Rayner, S.; Luo, M.-H. Does SARS-CoV-2 Has a Longer Incubation Period than SARS and MERS? J. Med. Virol. 2020, 92, 476–478. [Google Scholar] [CrossRef]
- Guan, W.-J.; Ni, Z.-Y.; Hu, Y.; Liang, W.-H.; Ou, C.-Q.; He, J.-X.; Liu, L.; Shan, H.; Lei, C.-L.; Hui, D.S.C.; et al. Clinical Characteristics of Coronavirus Disease 2019 in China. N. Engl. J. Med. 2020, 382, 1708–1720. [Google Scholar] [CrossRef]
- Lotfi, M.; Hamblin, M.R.; Rezaei, N. COVID-19: Transmission, Prevention, and Potential Therapeutic Opportunities. Clin. Chim. Acta 2020, 508, 254–266. [Google Scholar] [CrossRef]
- Thanh Le, T.; Andreadakis, Z.; Kumar, A.; Gómez Román, R.; Tollefsen, S.; Saville, M.; Mayhew, S. The COVID-19 Vaccine Development Landscape. Nat. Rev. Drug Discov. 2020, 19, 305–306. [Google Scholar] [CrossRef]
- Creech, C.B.; Walker, S.C.; Samuels, R.J. SARS-CoV-2 Vaccines. JAMA 2021, 325, 1318–1320. [Google Scholar] [CrossRef]
- Ghazy, R.M.; Ashmawy, R.; Hamdy, N.A.; Elhadi, Y.A.M.; Reyad, O.A.; Elmalawany, D.; Almaghraby, A.; Shaaban, R.; Taha, S.H.N. Efficacy and Effectiveness of SARS-CoV-2 Vaccines: A Systematic Review and Meta-Analysis. Vaccines 2022, 10, 350. [Google Scholar] [CrossRef]
- Carabelli, A.M.; Peacock, T.P.; Thorne, L.G.; Harvey, W.T.; Hughes, J.; COVID-19 Genomics UK Consortium; Peacock, S.J.; Barclay, W.S.; de Silva, T.I.; Towers, G.J.; et al. SARS-CoV-2 Variant Biology: Immune Escape, Transmission and Fitness. Nat. Rev. Microbiol. 2023, 21, 162–177. [Google Scholar] [CrossRef] [PubMed]
- COVID-19 Forecasting Team Variation in the COVID-19 Infection-Fatality Ratio by Age, Time, and Geography during the Pre-Vaccine Era: A Systematic Analysis. Lancet 2022, 399, 1469–1488. [CrossRef]
- Bouchnita, A.; Chekroun, A.; Jebrane, A. Mathematical Modeling Predicts That Strict Social Distancing Measures Would Be Needed to Shorten the Duration of Waves of COVID-19 Infections in Vietnam. Front. Public Health 2020, 8, 559693. [Google Scholar] [CrossRef] [PubMed]
- Alanazi, S.A.; Kamruzzaman, M.M.; Alruwaili, M.; Alshammari, N.; Alqahtani, S.A.; Karime, A. Measuring and Preventing COVID-19 Using the SIR Model and Machine Learning in Smart Health Care. J. Healthc. Eng. 2020, 2020, 8857346. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Peng, Y.; Sun, K. SEIR Modeling of the COVID-19 and Its Dynamics. Nonlinear Dyn. 2020, 101, 1667–1680. [Google Scholar] [CrossRef] [PubMed]
- Ghostine, R.; Gharamti, M.; Hassrouny, S.; Hoteit, I. An Extended SEIR Model with Vaccination for Forecasting the COVID-19 Pandemic in Saudi Arabia Using an Ensemble Kalman Filter. Mathematics 2021, 9, 636. [Google Scholar] [CrossRef]
- Loli Piccolomini, E.; Zama, F. Monitoring Italian COVID-19 Spread by a Forced SEIRD Model. PLoS ONE 2020, 15, e0237417. [Google Scholar] [CrossRef]
- Fonseca i Casas, P.; García i Carrasco, V.; Garcia i Subirana, J. SEIRD COVID-19 Formal Characterization and Model Comparison Validation. Appl. Sci. 2020, 10, 5162. [Google Scholar] [CrossRef]
- Fang, Y.; Nie, Y.; Penny, M. Transmission Dynamics of the COVID-19 Outbreak and Effectiveness of Government Interventions: A Data-Driven Analysis. J. Med. Virol. 2020, 92, 645–659. [Google Scholar] [CrossRef]
- Attanayake, A.M.C.H.; Perera, S.S.N.; Jayasinghe, S. Phenomenological Modelling of COVID-19 Epidemics in Sri Lanka, Italy, the United States, and Hebei Province of China. Comput. Math. Methods Med. 2020, 2020, 6397063. [Google Scholar] [CrossRef]
- Wolter, N.; Jassat, W.; Walaza, S.; Welch, R.; Moultrie, H.; Groome, M.; Amoako, D.G.; Everatt, J.; Bhiman, J.N.; Scheepers, C.; et al. Early Assessment of the Clinical Severity of the SARS-CoV-2 Omicron Variant in South Africa: A Data Linkage Study. Lancet 2022, 399, 437–446. [Google Scholar] [CrossRef] [PubMed]
- Venancio-Guzmán, S.; Aguirre-Salado, A.I.; Soubervielle-Montalvo, C.; Jiménez-Hernández, J.D.C. Assessing the Nationwide COVID-19 Risk in Mexico through the Lens of Comorbidity by an XGBoost-Based Logistic Regression Model. Int. J. Environ. Res. Public Health 2022, 19, 11992. [Google Scholar] [CrossRef] [PubMed]
- Shmueli, L. Predicting Intention to Receive COVID-19 Vaccine among the General Population Using the Health Belief Model and the Theory of Planned Behavior Model. BMC Public Health 2021, 21, 804. [Google Scholar] [CrossRef]
- Khoury, D.S.; Cromer, D.; Reynaldi, A.; Schlub, T.E.; Wheatley, A.K.; Juno, J.A.; Subbarao, K.; Kent, S.J.; Triccas, J.A.; Davenport, M.P. Neutralizing Antibody Levels Are Highly Predictive of Immune Protection from Symptomatic SARS-CoV-2 Infection. Nat. Med. 2021, 27, 1205–1211. [Google Scholar] [CrossRef] [PubMed]
- Kot, M. Elements of Mathematical Ecology, 1st ed.; Cambridge University Press: Cambridge, UK, 2001; pp. 3–12. [Google Scholar]
- Bacaër, N. Verhulst and the Logistic Equation (1838). In A Short History of Mathematical Population Dynamics, 1st ed.; Bacaër, N., Ed.; Springer: London, UK, 2011; pp. 35–39. [Google Scholar]
- Wickham, H.; Bryan, J. R Packages, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2023; pp. 1–381. [Google Scholar]
- Pereira, S.M.C.; Leslie, G. Hypothesis Testing. Aust. Crit. Care 2009, 22, 187–191. [Google Scholar] [CrossRef]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation Coefficients: Appropriate Use and Interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Amblard, P.-O.; Michel, O.J.J. The Relation between Granger Causality and Directed Information Theory: A Review. Entropy 2013, 15, 113–143. [Google Scholar] [CrossRef]
- Bruns, S.B.; Stern, D.I. Lag Length Selection and P-Hacking in Granger Causality Testing: Prevalence and Performance of Meta-Regression Models. Empir. Econ. 2019, 56, 797–830. [Google Scholar] [CrossRef]
- Stokes, P.A.; Purdon, P.L. A Study of Problems Encountered in Granger Causality Analysis from a Neuroscience Perspective. Proc. Natl. Acad. Sci. USA 2017, 114, E7063–E7072. [Google Scholar] [CrossRef]
- Cheung, Y.-W.; Lai, K.S. Lag Order and Critical Values of the Augmented Dickey-Fuller Test. J. Bus. Econ. Stat. 1995, 13, 277–280. [Google Scholar] [CrossRef]
- Kihoro, J.M.; Otieno, R.O.; Wafula, C. Seasonal Time Series Forecasting: A Comparative Study of Arima and Ann Models. Afr. J. Sci. Technol. 2004, 5, 41–49. [Google Scholar] [CrossRef]
- Jewell, N.P.; Lewnard, J.A.; Jewell, B.L. Predictive Mathematical Models of the COVID-19 Pandemic: Underlying Principles and Value of Projections. JAMA 2020, 323, 1893–1894. [Google Scholar] [CrossRef] [PubMed]
- Hsiang, S.; Allen, D.; Annan-Phan, S.; Bell, K.; Bolliger, I.; Chong, T.; Druckenmiller, H.; Huang, L.Y.; Hultgren, A.; Krasovich, E.; et al. The Effect of Large-Scale Anti-Contagion Policies on the COVID-19 Pandemic. Nature 2020, 584, 262–267. [Google Scholar] [CrossRef] [PubMed]
- Chimmula, V.K.R.; Zhang, L. Time Series Forecasting of COVID-19 Transmission in Canada Using LSTM Networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef] [PubMed]
- Anastassopoulou, C.; Russo, L.; Tsakris, A.; Siettos, C. Data-Based Analysis, Modelling and Forecasting of the COVID-19 Outbreak. PLoS ONE 2020, 15, e0230405. [Google Scholar] [CrossRef]
- Petropoulos, F.; Makridakis, S. Forecasting the Novel Coronavirus COVID-19. PLoS ONE 2020, 15, e0231236. [Google Scholar] [CrossRef]
- Kumari, N.; Sharma, S. Modeling the Dynamics of Infectious Disease under the Influence of Environmental Pollution. Int. J. Appl. Comput. Math 2018, 4, 84. [Google Scholar] [CrossRef]
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J. Welcome to the Tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Mishra, P.; Pandey, C.M.; Singh, U.; Gupta, A.; Sahu, C.; Keshri, A. Descriptive Statistics and Normality Tests for Statistical Data. Ann. Card. Anaesth. 2019, 22, 67–72. [Google Scholar] [CrossRef]
- Walzer, P.; Estève, C.; Barben, J.; Menu, D.; Cuenot, C.; Manckoundia, P.; Putot, A. Impact of Influenza Vaccination on Mortality in the Oldest Old: A Propensity Score-Matched Cohort Study. Vaccines 2020, 8, 356. [Google Scholar] [CrossRef]
- Shiba, K.; Kawahara, T. Using Propensity Scores for Causal Inference: Pitfalls and Tips. J. Epidemiol. 2021, 31, 457–463. [Google Scholar] [CrossRef]
- Zhong, H.; Li, W.; Boarnet, M.G. A Two-Dimensional Propensity Score Matching Method for Longitudinal Quasi-Experimental Studies: A Focus on Travel Behavior and the Built Environment. Environ. Plan. B Urban Anal. City Sci. 2021, 48, 2110–2122. [Google Scholar] [CrossRef]
- Hardgrave, H.; Wells, A.; Nigh, J.; Klutts, G.; Krinock, D.; Osborn, T.; Bhusal, S.; Rude, M.K.; Burdine, L.; Giorgakis, E. COVID-19 Mortality in Vaccinated vs. Unvaccinated Liver & Kidney Transplant Recipients: A Single-Center United States Propensity Score Matching Study on Historical Data. Vaccines 2022, 10, 1921. [Google Scholar] [CrossRef] [PubMed]
- Son, C.-S.; Jin, S.-H.; Kang, W.-S. Propensity-Score-Matched Evaluation of Adverse Events Affecting Recovery after COVID-19 Vaccination: On Adenovirus and mRNA Vaccines. Vaccines 2022, 10, 284. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Li, X.; Wu, X.; Qiu, H.; Shi, H.; AME Big-Data Clinical Trial Collaborative Group. Propensity Score Analysis for Time-Dependent Exposure. Ann. Transl. Med. 2020, 8, 246. [Google Scholar] [CrossRef] [PubMed]
- Wijn, S.R.W.; Rovers, M.M.; Hannink, G. Confounding Adjustment Methods in Longitudinal Observational Data with a Time-Varying Treatment: A Mapping Review. BMJ Open 2022, 12, e058977. [Google Scholar] [CrossRef] [PubMed]
- Asghar, Z. Simulation Evidence on Granger Causality in Presence of a Confounding Variable. Int. J. Appl. Econom. Quant. Stud. 2008, 5, 71–86. [Google Scholar]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Coefficient of Determination R-Squared Is More Informative than SMAPE, MAE, MAPE, MSE and RMSE in Regression Analysis Evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Härdle, W.K.; Simar, L. Conjoint Measurement Analysis. In Applied Multivariate Statistical Analysis, 2nd ed.; Härdle, W.K., Simar, L., Eds.; Springer: Berlin, Germany, 2015; pp. 473–486. [Google Scholar]
- Mishra, B.K.; Keshri, A.K.; Saini, D.K.; Ayesha, S.; Mishra, B.K.; Rao, Y.S. Mathematical Model, Forecast and Analysis on the Spread of COVID-19. Chaos Solitons Fractals 2021, 147, 110995. [Google Scholar] [CrossRef]
- Soto-Cabezas, M.G.; Reyes, M.F.; Soriano, A.N.; Rodríguez, J.P.V.; Ibargüen, L.O.; Martel, K.S.; Jaime, N.F.; Munayco, C.V. COVID-19 among Amazonian Indigenous in Peru: Mortality, Incidence, and Clinical Characteristics. J. Public Health 2022, 44, e359–e365. [Google Scholar] [CrossRef]
- Grillo Ardila, E.K.; Santaella-Tenorio, J.; Guerrero, R.; Bravo, L.E. Mathematical Model and COVID-19. Colomb. Med. 2020, 51, e4277. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Cases | Deaths | People Vaccinated |
|---|---|---|---|
| t1 | 642 | 343 | 222 |
| A | 2,245,146 | 110,184 | 15,348,800 |
| t2 | 1109 | 1109 | 769 |
| B | 4,489,377 | 219,648 | 30,374,977 |
| t3 | 876 | 726 | 496 |
| I | 3,889,029 | 210,672 | 29,526,095 |
| M | 4,834,759 | 220,528 | 30,429,043 |
| a | 4.1998 | 3.2259 | 3.5568 |
| Q | 66.673 | 25.176 | 35.051 |
| k | −0.0067 | −0.0083 | −0.0133 |
| tc | 627 | 389 | 268 |
| Maximum speed at tc | 8098 | 459 | 101,175 |
| Maximum value at tc | 2,418,709 | 141,432 | 19,890,913 |
| Time Series | Lag-Order AIC | AIC Value | Lag-Order BIC | BIC Value |
|---|---|---|---|---|
| People vaccinated | 9 | 24,998.81 | 9 | 25,053.94 |
| Cases | 10 | 19,654.12 | 10 | 19,714.27 |
| Deaths | 16 | 10,476.19 | 15 | 10,562.1 |
| Pair of Time Series | Lag-Order AIC | AIC Value | Lag-Order BIC | BIC Value |
|---|---|---|---|---|
| Deaths–people vaccinated | 21 | 24,296.05 | 15 | 24,464.87 |
| Cases–people vaccinated | 21 | 24,305.82 | 15 | 24,472.33 |
| Pair of Time Series | Deaths → Vaccinated | Vaccinated → Deaths | Cases → Vaccinated | Vaccinated → Cases |
|---|---|---|---|---|
| p-Value | 0.1828 | 0.01608 | 0.6495 | 0.9276 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marín-Machuca, O.; Chacón, R.D.; Alvarez-Lovera, N.; Pesantes-Grados, P.; Pérez-Timaná, L.; Marín-Sánchez, O. Mathematical Modeling of COVID-19 Cases and Deaths and the Impact of Vaccinations during Three Years of the Pandemic in Peru. Vaccines 2023, 11, 1648. https://doi.org/10.3390/vaccines11111648
Marín-Machuca O, Chacón RD, Alvarez-Lovera N, Pesantes-Grados P, Pérez-Timaná L, Marín-Sánchez O. Mathematical Modeling of COVID-19 Cases and Deaths and the Impact of Vaccinations during Three Years of the Pandemic in Peru. Vaccines. 2023; 11(11):1648. https://doi.org/10.3390/vaccines11111648
Chicago/Turabian StyleMarín-Machuca, Olegario, Ruy D. Chacón, Natalia Alvarez-Lovera, Pedro Pesantes-Grados, Luis Pérez-Timaná, and Obert Marín-Sánchez. 2023. "Mathematical Modeling of COVID-19 Cases and Deaths and the Impact of Vaccinations during Three Years of the Pandemic in Peru" Vaccines 11, no. 11: 1648. https://doi.org/10.3390/vaccines11111648