
DSCNN-LSTMs: A Lightweight and Efficient Model for Epilepsy Recognition
 ,
,
Abstract
:1. Introduction
- (1)
- The DSCNN is used to extract spatial features from EEG signals, which can distinguish signals to the greatest extent.
- (2)
- The output of DSCNN is regarded as the input to train the LSTMs model, which can solve the problem of gradient disappearance and gradient explosion in the long sequence training process. Moreover, the temporal characteristics of the EEG signals can be extracted by LSTMs. These features are mainly needed for modeling calculation, but also indirectly help neurologists in clinical diagnosis.
- (3)
- The model has less pre-processing of raw data, and in the future, it may be combined with existing wearable technology and smart phones, which can accurately detect and predict the development of epilepsy seizures, providing more universal applications for patients, caregivers, clinicians, and researchers.
2. Materials and Methods
2.1. EEG Data
- (a)
- First state: recording of EEG signals in healthy subjects while their eyes are open.
- (b)
- Second state: recording of EEG signals in healthy subjects with their eyes closed.
- (c)
- Third state: interictal EEG signals were recorded from the healthy hippocampal area of the epileptic patients.
- (d)
- Fourth state: interictal EEG signals were recorded at the site of the epileptic’s brain tumor.
- (e)
- Fifth state: seizure activity EEG signals were recorded from the epileptic patients.
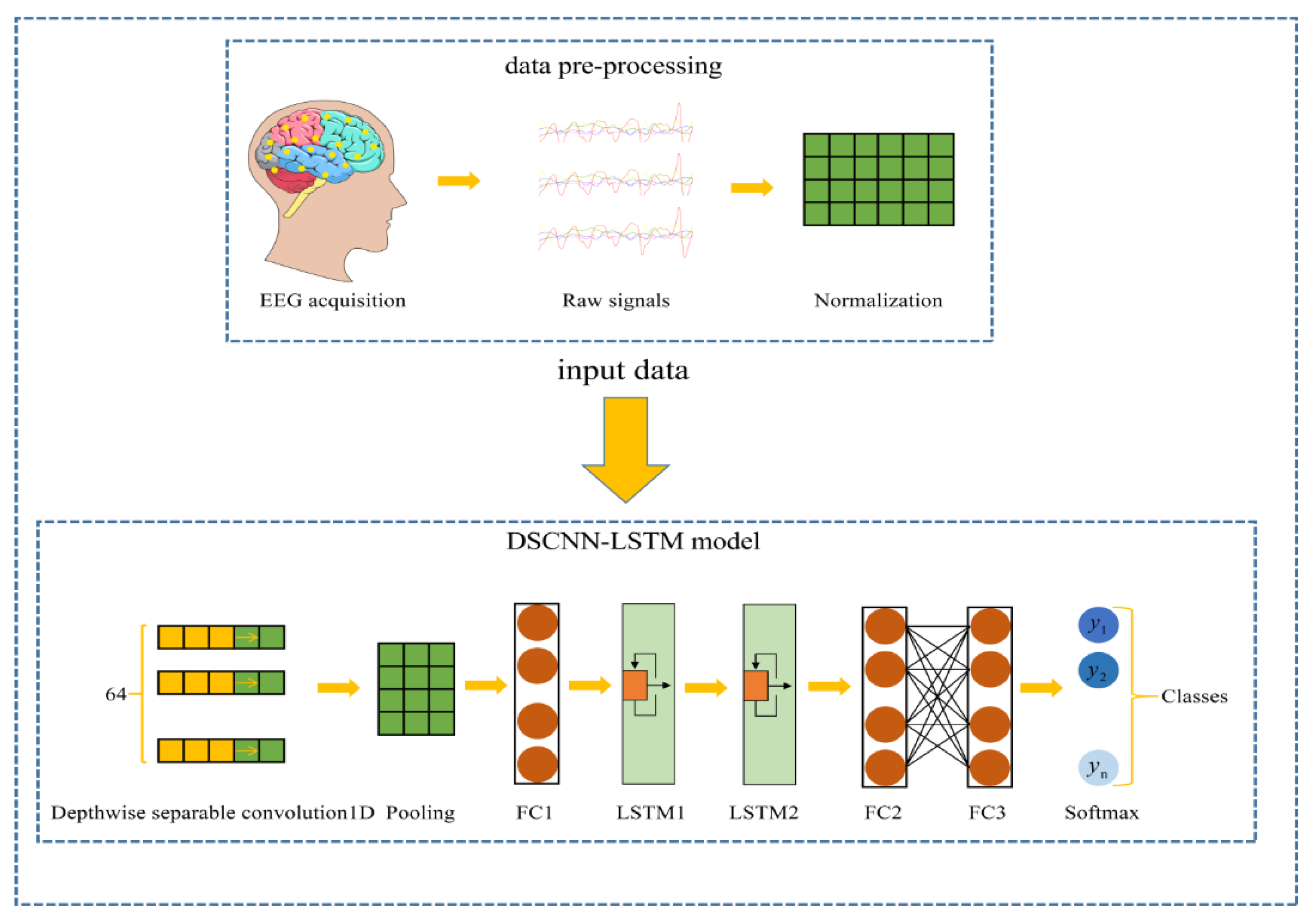
2.2. Data Pre-Processing
2.3. 1D-CNN and 1D-DSCNN
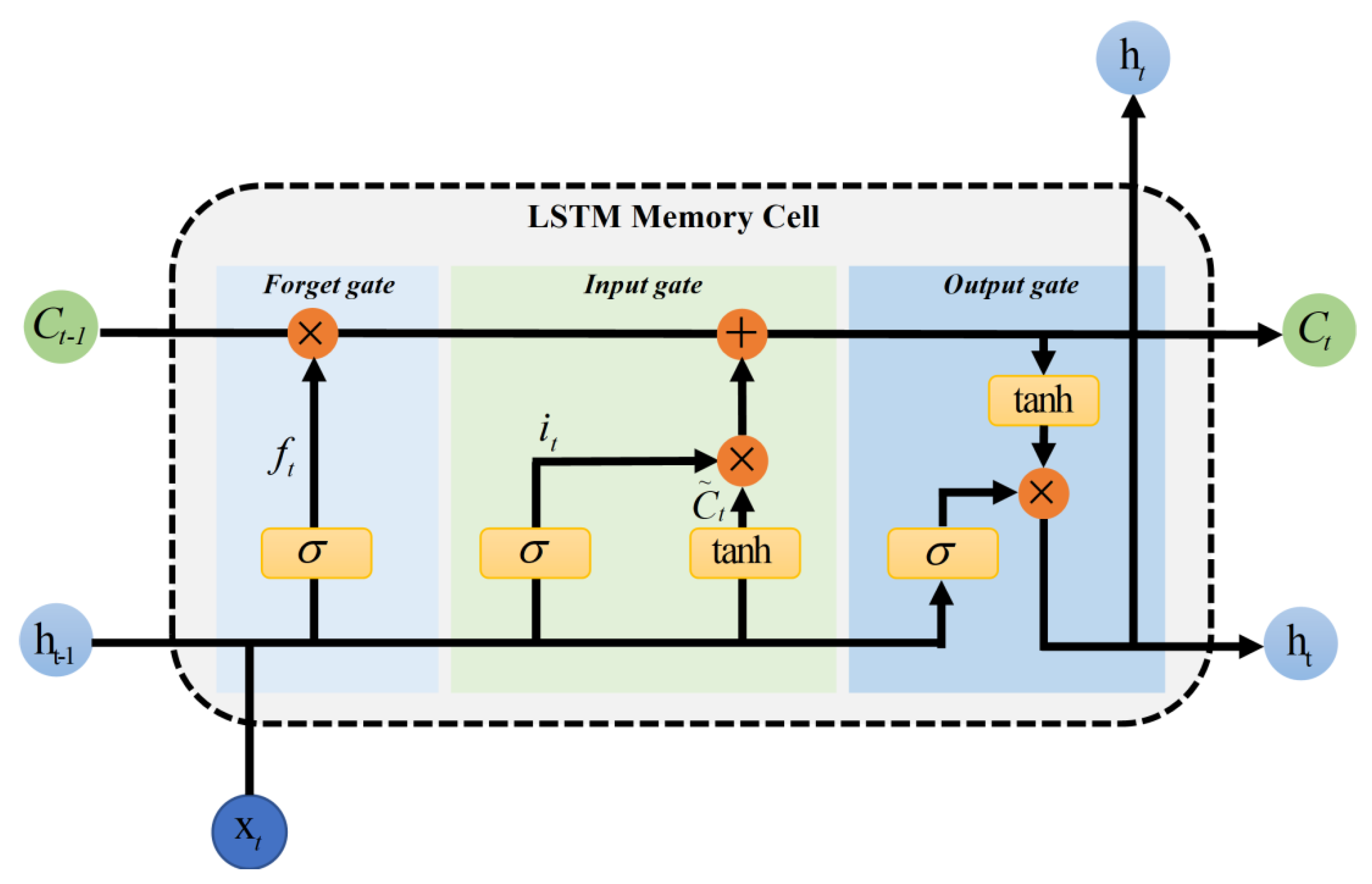
2.4. Long Short-Term Memory Networks
2.5. 1D DSCNN-2LSTMs Model
2.6. Evaluation Indicators
3. Experimental Results and Analysis
3.1. Experimental Setup
3.2. The Results Analysis
3.2.1. LSTMs Layer Selection
3.2.2. Resolve Class Imbalances
3.2.3. Ablation Experiments
3.2.4. Binary Recognition Task
3.2.5. Five-Class Recognition Task
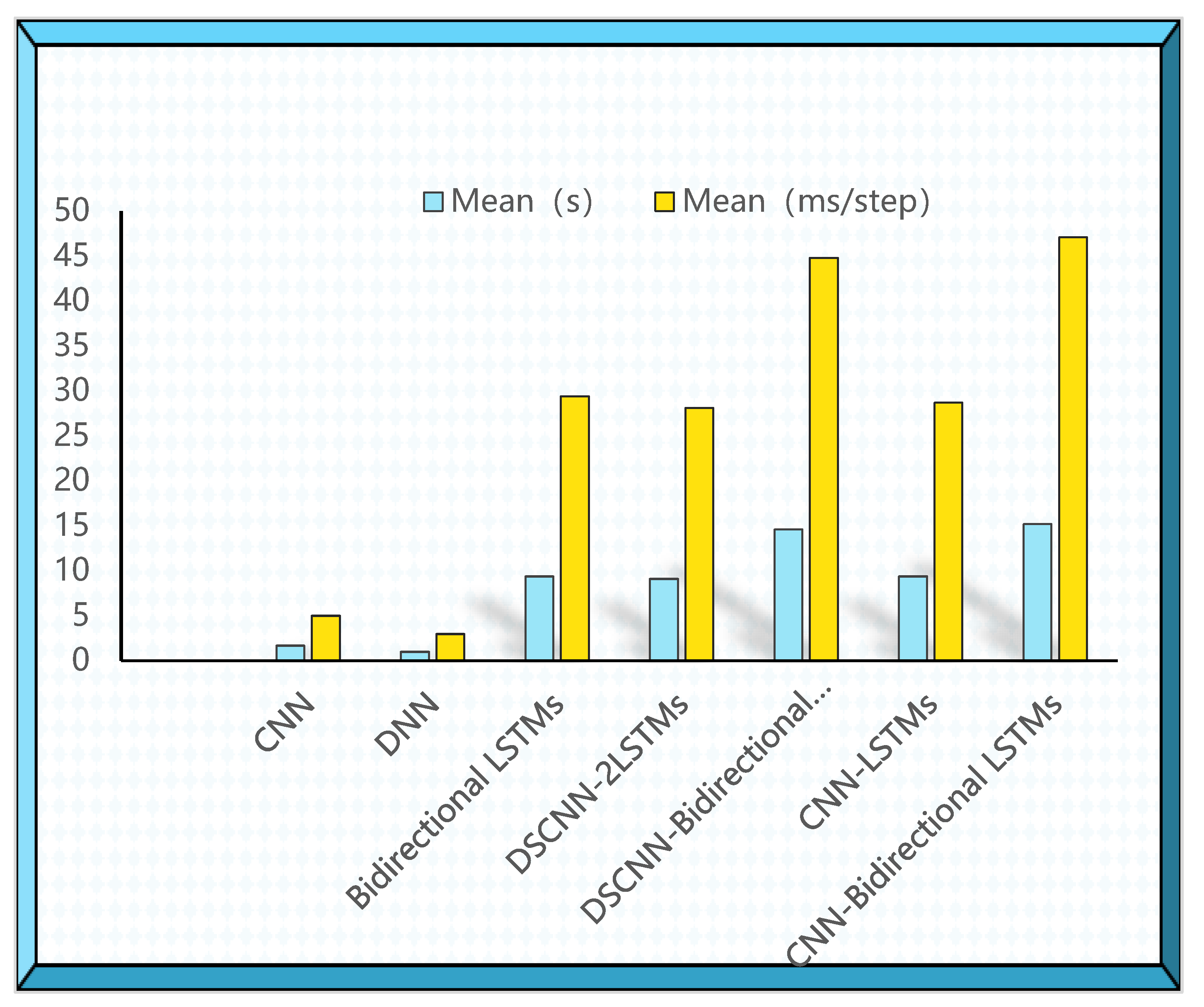
3.2.6. Compare with Other Cross-Validation Models
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Amirmasoud, A.; Behroozi, M.; Shalchyan, V.; Daliri, M.R. Classification of epileptic EEG signals by wavelet based CFC. In Proceedings of the 2018 Electric Electronics, Computer Science, Biomedical Engineerings’ Meeting (EBBT), Istanbul, Turkey, 18–19 April 2018. [Google Scholar]
- Patrick, K.; Brodie, M.J. Early identification of refractory epilepsy. N. Engl. J. Med. 2000, 342, 314–319. [Google Scholar]
- Sylvia, B.; Garg, L.; Audu, E.E. A novel method of EEG data acquisition, feature extraction and feature space creation for early detection of epileptic seizures. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016. [Google Scholar]
- Shoeibi, A.; Ghassemi, N.; Khodatars, M.; Jafari, M. Applications of epileptic seizures detection in neuroimaging modalities using deep learning techniques: Methods, challenges, and future works. arXiv 2021, arXiv:2105.14278. [Google Scholar]
- Beeraka, S.M.; Kumar, A.; Sameer, M.; Ghosh, S.; Gupta, B. Accuracy Enhancement of Epileptic Seizure Detection: A Deep Learning Approach with Hardware Realization of STFT. Circuits, Syst. Signal Process. 2021, 41, 461–484. [Google Scholar] [CrossRef]
- Wang, B.; Guo, J.; Yan, T.; Ohno, S.; Kanazawa, S.; Huang, Q.; Wu, J. Neural Responses to Central and Peripheral Objects in the Lateral Occipital Cortex. Front. Hum. Neurosci. 2016, 10, 54. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, T.; Dong, X.; Mu, N.; Liu, T.; Chen, D.; Deng, L.; Wang, C.; Zhao, L. Positive Classification Advantage: Tracing the Time Course Based on Brain Oscillation. Front. Hum. Neurosci. 2018, 11, 659. [Google Scholar] [CrossRef] [Green Version]
- Ren, G.-P.; Yan, J.-Q.; Yu, Z.-X.; Wang, D.; Li, X.-N.; Mei, S.-S.; Dai, J.-D.; Li, Y.-L.; Wang, X.-F.; Yang, X.-F. Automated Detector of High Frequency Oscillations in Epilepsy Based on Maximum Distributed Peak Points. Int. J. Neural Syst. 2017, 28, 1750029. [Google Scholar] [CrossRef]
- Sun, C.; Cui, H.; Zhou, W.; Nie, W.; Wang, X.; Yuan, Q. Epileptic seizure detection with EEG textural features and imbalanced classification based on EasyEnsemble learning. Int. J. Neural Syst. 2019, 29, 1950021. [Google Scholar] [CrossRef]
- Cogan, D.; Birjandtalab, J.; Nourani, M.; Harvey, J.; Nagaraddi, V. Multi-Biosignal Analysis for Epileptic Seizure Monitoring. Int. J. Neural Syst. 2016, 27, 1650031. [Google Scholar] [CrossRef]
- Zhang, J.; Zou, J.; Wang, M.; Chen, L.; Wang, C.; Wang, G. Automatic detection of interictal epileptiform discharges based on time-series sequence merging method. Neurocomputing 2013, 110, 35–43. [Google Scholar] [CrossRef]
- Aarabi, A.; Fazel-Rezai, R.; Aghakhani, Y. A fuzzy rule-based system for epileptic seizure detection in intracranial EEG. Clin. Neurophysiol. 2009, 120, 1648–1657. [Google Scholar] [CrossRef]
- Boashash, B.; Azemi, G. A review of time–frequency matched filter design with application to seizure detection in multichannel newborn EEG. Digit. Signal Process. 2014, 28, 28–38. [Google Scholar] [CrossRef]
- Subasi, A.; Gursoy, M.I. EEG signal classification using PCA, ICA, LDA and support vector machines. Expert Syst. Appl. 2010, 37, 8659–8666. [Google Scholar] [CrossRef]
- Asif, U.; Roy, S.; Tang, J.; Harrer, S. SeizureNet: Multi-spectral deep feature learning for seizure type classification. In Machine Learning in Clinical Neuroimaging and Radiogenomics in Neuro-Oncology; Springer: Berlin/Heidelberg, Germany, 2020; pp. 77–87. [Google Scholar]
- Acharya, U.R.; Oh, S.L.; Hagiwara, Y.; Tan, J.H.; Adeli, H. Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals. Comput. Biol. Med. 2018, 100, 270–278. [Google Scholar] [CrossRef] [PubMed]
- Antoniades, A.; Spyrou, L.; Took, C.C.; Sanei, S. Deep learning for epileptic intracranial EEG data. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016. [Google Scholar]
- Hussein, R.; Palangi, H.; Ward, R.; Wang, Z.J. Epileptic seizure detection: A deep learning approach. arXiv 2018, arXiv:1803.09848. [Google Scholar]
- Tsiouris, K.M.; Pezoulas, V.C.; Zervakis, M.; Konitsiotis, S.; Koutsouris, D.D.; Fotiadis, D.I. A Long Short-Term Memory deep learning network for the prediction of epileptic seizures using EEG signals. Comput. Biol. Med. 2018, 99, 24–37. [Google Scholar] [CrossRef] [PubMed]
- Ullah, I.; Hussain, M.; Qazi, E.-U.; Aboalsamh, H. An automated system for epilepsy detection using EEG brain signals based on deep learning approach. Expert Syst. Appl. 2018, 107, 61–71. [Google Scholar] [CrossRef] [Green Version]
- Lin, Q.; Ye, S.-Q.; Huang, X.-M.; Li, S.-Y.; Zhang, M.-Z.; Xue, Y.; Chen, W.-S. Classification of epileptic EEG signals with stacked sparse autoencoder based on deep learning. Int. Conf. Intell. Comput. 2016, 9773, 802–810. [Google Scholar]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Wei, X.; Zhou, L.; Chen, Z.; Zhang, L.; Zhou, Y. Automatic seizure detection using three-dimensional CNN based on multi-channel EEG. BMC Med. Inform. Decis. Mak. 2018, 18, 71–80. [Google Scholar] [CrossRef] [Green Version]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Hochreiter, S. The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 061907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Michelucci, U. Applied Deep Learning: A Case-Based Approach to Understanding Deep Neural Networks; Apress: New York, NY, USA, 2018. [Google Scholar]
- Hartmann, M.; Koren, J.; Baumgartner, C.; Duun-Henriksen, J.; Gritsch, G.; Kluge, T.; Perko, H.; Fürbass, F. Seizure detection with deep neural networks for review of two-channel electroencephalogram. Epilepsia 2022. [Google Scholar] [CrossRef]
- Abou Jaoude, M.; Jing, J.; Sun, H.; Jacobs, C.S.; Pellerin, K.R.; Westover, M.B.; Cash, S.S.; Lam, A.D. Detection of mesial temporal lobe epileptiform discharges on intracranial electrodes using deep learning. Clin. Neurophysiol. 2020, 131, 133–141. [Google Scholar] [CrossRef]
- de Jong, J.; Cutcutache, L.; Page, M.; Elmoufti, S.; Dilley, C.; Fröhlich, H.; Armstrong, M. Towards realizing the vision of precision medicine: AI based prediction of clinical drug response. Brain 2021, 144, 1738–1750. [Google Scholar] [CrossRef]
- Gleichgerrcht, E.; Keller, S.; Drane, D.L.; Munsell, B.C.; Davis, K.A.; Kaestner, E.; Weber, B.; Krantz, S.; Vandergrift, W.A.; Edwards, J.C.; et al. Temporal Lobe Epilepsy Surgical Outcomes Can Be Inferred Based on Structural Connectome Hubs: A Machine Learning Study. Ann. Neurol. 2020, 88, 970–983. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Output Shape | Parameters |
|---|---|---|---|
| separable_conv1d | Separable_Conv1d | (None, 176, 64) | 131 |
| max_pooling1d | MaxPooling1D | (None, 88, 64) | 0 |
| dense_1 | Dense | (None, 88, 256) | 16,640 |
| dropout | Dropout | (None, 88, 256) | 0 |
| lstm_1 | LSTM | (None, 88, 64) | 82,176 |
| lstm_2 | LSTM | (None, 64) | 33,024 |
| dense_2 | Dense | (None, 64) | 4160 |
| dense_3 | Dense | (None, 6) | 390 |
| Methods | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSCNN-1LSTM | 97.65% | 98.26% | 98.00% | 97.91% | 98.43% | 98.35% | 98.17% | 98.43% | 98.70% | 80.00% | 96.39% |
| DSCNN-2LSTM | 99.57% | 99.13% | 99.57% | 99.65% | 99.13% | 99.30% | 99.48% | 99.39% | 99.48% | 99.91% | 99.46% |
| DSCNN-3LSTM | 98.78% | 98.26% | 98.70% | 98.26% | 97.91% | 98.35% | 98.7% | 81.22% | 98.87% | 98.61% | 96.76% |
| Methods | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSCNN-1LSTMs | 70.52% | 72.78% | 72.87% | 72.00% | 77.22% | 76.00% | 74.78% | 78.52% | 75.48% | 74.52% | 74.46% |
| DSCNN-2LSTMs | 75.91% | 75.48 | 77.39% | 77.74% | 80.78% | 76.43% | 79.65% | 74.96% | 76.35% | 81.13% | 77.58% |
| DSCNN-3LSTMs | 76.52% | 68.61% | 79.04% | 73.04% | 74.09% | 78.09% | 74.09% | 78.00% | 77.22% | 81.30% | 76.00% |
| Method | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSCNN-2LSTMs | 99.13% | 99.13% | 99.48% | 99.57% | 99.13% | 99.39% | 98.17% | 99.39% | 99.48% | 99.30% | 99.21% |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| DSCNN | 97.17% | 96.81% | 97.21% | 97.01% |
| LSTMs | 93.30% | 93.00% | 93.47% | 93.03% |
| DSCNN-2LSTMs | 99.57% | 98.79% | 98.79% | 98.79% |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| DSCNN | 74.78% | 74.86% | 74.65% | 74.76% |
| LSTMs | 57.57% | 57.47% | 57.47% | 56.62% |
| DSCNN-2LSTMs | 81.30% | 79.21% | 79.95% | 79.59% |
| Methods | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSCNN | 98.09% | 97.83% | 98.17% | 98.26% | 97.74% | 98.17% | 97.39% | 98.26% | 80.78% | 98.17% | 96.28% |
| LSTMs | 95.04% | 97.22% | 79.48% | 77.83% | 81.65% | 97.57% | 94.61% | 81.22% | 97.74% | 96.52% | 89.88% |
| DSCNN-2LSTMs | 99.57% | 99.13% | 99.57% | 99.65% | 99.13% | 99.30% | 99.48% | 99.39% | 99.48% | 99.91% | 99.46% |
| Methods | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSCNN | 60.70% | 63.04% | 64.35% | 62.26% | 62.35% | 63.48% | 64.17% | 60.61% | 63.74% | 63.22% | 62.79% |
| LSTM | 58.09% | 54.61% | 55.91% | 49.83% | 60.26% | 57.91% | 58.00% | 57.74% | 57.13% | 59.13% | 56.86% |
| DSCNN-2LSTMs | 75.91% | 75.48% | 77.39% | 77.74% | 80.78% | 76.43% | 79.65% | 74.96% | 76.35% | 81.13% | 77.58% |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| CNN | 97.13% | 94.24% | 92.34% | 93.28% |
| DNN | 96.35% | 95.18% | 87.50% | 91.18% |
| Bidirectional LSTMs | 97.96% | 97.80% | 97.61% | 98.21% |
| DSCNN-2LSTMs | 99.57% | 98.79% | 98.79% | 98.79% |
| DSCNN-Bidirectional LSTMs | 98.91% | 98.60% | 98.60% | 98.60% |
| CNN-LSTMs | 98.39% | 98.60% | 98.01% | 98.40% |
| CNN-Bidirectional LSTMs | 98.87% | 98.60% | 98.60% | 98.60% |
| AdaBoost | 93.60% | 93.61% | 93.44% | 93.43% |
| KNN | 92.21% | 92.77% | 92.30% | 91.05% |
| Random Forest | 97.13% | 97.21% | 97.42% | 97.01% |
| SVM | 82.26% | 85.55% | 82.23% | 75.78% |
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| CNN | 67.30% | 67.73% | 66.76% | 67.05% |
| DNN | 68.78% | 67.63% | 67.67% | 66.91% |
| DSCNN | 74.78% | 74.86% | 74.65% | 74.76% |
| Bidirectional LSTMs | 74.52% | 74.75% | 74.36% | 74.36% |
| DSCNN-2LSTMs | 81.30% | 79.21% | 79.95% | 79.59% |
| DSCNN-Bidirectional LSTM | 77.04% | 77.04% | 77.12% | 77.08% |
| CNN-LSTM | 78.00% | 78.06% | 78.06% | 77.95% |
| CNN-Bidirectional LSTM | 79.13% | 79.16% | 79.13% | 79.36% |
| AdaBoost | 41.73% | 41.57% | 42.83% | 37.59% |
| KNN | 50.65% | 58. 99% | 50.65% | 48.34% |
| Random Forest | 67.69% | 67.52% | 67.66% | 67.19% |
| SVM | 26.39% | 33.31% | 26.40% | 26.79% |
| Methods | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN | 98.35% | 97.91% | 98.26% | 97.74% | 97.48% | 98.78% | 97.48% | 98.35% | 98.70% | 98.26% | 98.13% |
| DNN | 97.22% | 98.00% | 97.22% | 97.57% | 96.70% | 97.65% | 96.09% | 98.00% | 98.26% | 97.48% | 97.41% |
| Bidirectional LSTM | 98.00% | 97.57% | 98.26% | 98.00% | 97.57% | 98.17% | 97.57% | 98.52% | 99.04% | 98.09% | 98.07% |
| DSCNN-2LSTM | 99.57% | 99.13% | 99.57% | 99.65% | 99.13% | 99.30% | 99.48% | 99.39% | 99.48% | 99.91% | 99.46% |
| DSCNN-Bidirectional LSTM | 98.96% | 98.52% | 98.70% | 98.78% | 98.00% | 99.30% | 98.43% | 99.13% | 99.04% | 98.52% | 98.73% |
| CNN-LSTM | 98.70% | 98.35% | 99.3% | 98.96% | 97.83% | 98.43% | 98.35% | 98.87% | 99.13% | 98.43% | 98.63% |
| CNN-Bidirectional LSTM | 98.52% | 98.43% | 98.35% | 99.04% | 97.22% | 98.61% | 98.17% | 98.09% | 98.70% | 98.52% | 98.36% |
| AdaBoost | 93.56% | 94.17% | 93.65% | 94.78% | 94.43% | 94.78% | 94.00% | 93.91% | 95.91% | 94.43% | 94.36% |
| KNN | 91.91% | 93.47% | 92.95% | 91.91% | 92.17% | 93.21% | 92.34% | 90.69% | 94.78% | 92.00% | 92.54% |
| Random Forest | 97.65% | 97.13% | 97.04% | 97.65% | 96.95% | 97.91% | 96.60% | 98.26% | 98.08% | 97.82% | 97.50% |
| SVM | 80.60% | 83.04% | 81.39% | 79.56% | 83.21% | 81.65% | 81.13% | 83.21% | 82.69% | 82.34% | 81.88% |
| Methods | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 | K10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN | 72.87% | 72.43% | 76.09% | 75.30% | 74.52% | 75.30% | 77.22% | 75.91% | 74.26% | 77.57% | 75.14% |
| DNN | 66.87% | 66.70% | 70.00% | 65.83% | 67.22% | 69.65% | 68.52% | 66.78% | 68.35% | 66.26% | 67.61% |
| Bidirectional LSTM | 75.30% | 74.09% | 75.04% | 74.00% | 75.04% | 75.48% | 74.70% | 73.39% | 75.22% | 75.13% | 74.73% |
| DSCNN-2LSTM | 75.91% | 75.48% | 77.39% | 77.74% | 80.78% | 76.43% | 79.65% | 74.96% | 76.35% | 81.13% | 77.58% |
| DSCNN-Bidirectional LSTM | 77.22% | 76.43% | 76.52% | 77.65% | 71.48% | 74.43% | 74.61% | 76.17% | 74.52% | 80.35% | 75.93% |
| CNN-LSTM | 73.39% | 75.91% | 79.22% | 77.04% | 78.26% | 78.35% | 79.13% | 77.04% | 78.17% | 80.26% | 77.67% |
| CNN-Bidirectional LSTM | 79.04% | 77.48% | 81.13% | 75.48% | 79.65% | 80.61% | 78.96% | 73.22% | 74.70% | 79.13% | 77.94% |
| AdaBoost | 43.56% | 41.47% | 44.17% | 43.73% | 42.00% | 45.21% | 42.78% | 41.65% | 44.17% | 41.82% | 43.05% |
| KNN | 45.91% | 50.60% | 49.13% | 46.43% | 47.73% | 48.86% | 46.69% | 49.04% | 45.47% | 46.00% | 47.58% |
| Random Forest | 70.60% | 69.91% | 72.95% | 70.26% | 70.78% | 71.47% | 69.04% | 68.78% | 68.34% | 70.34% | 70.24% |
| SVM | 28.17% | 26.52% | 26.26% | 24.34% | 25.91% | 26.86% | 25.21% | 27.73% | 27.30% | 28.60% | 26.69% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Ma, Y.; Wang, R.; Yuan, B.; Jiang, R.; Yang, Q.; Li, W.; Sun, J. DSCNN-LSTMs: A Lightweight and Efficient Model for Epilepsy Recognition. Brain Sci. 2022, 12, 1672. https://doi.org/10.3390/brainsci12121672
Huang Z, Ma Y, Wang R, Yuan B, Jiang R, Yang Q, Li W, Sun J. DSCNN-LSTMs: A Lightweight and Efficient Model for Epilepsy Recognition. Brain Sciences. 2022; 12(12):1672. https://doi.org/10.3390/brainsci12121672
Chicago/Turabian StyleHuang, Zhentao, Yahong Ma, Rongrong Wang, Baoxi Yuan, Rui Jiang, Qin Yang, Weisu Li, and Jingbo Sun. 2022. "DSCNN-LSTMs: A Lightweight and Efficient Model for Epilepsy Recognition" Brain Sciences 12, no. 12: 1672. https://doi.org/10.3390/brainsci12121672