
A Unified Visual and Linguistic Semantics Method for Enhanced Image Captioning
Abstract
:1. Introduction
- We propose the “A Unified Visual and Linguistic Semantics Method” (UVLS), integrating CLIP and SegmentCLIP for image feature extraction. This framework aims to bridge the semantic gap in traditional image captioning, offering a more nuanced understanding of visual content.
- By incorporating a clustering mechanism into CLIP, called SegmentCLIP, the model enhances semantic relationships between visual and textual elements. This advancement enables a deeper interpretation of complex contextual semantics within images, leading to richer and more accurate image descriptions.
- Extensive experiments on real-word datasets are conducted to fully verify the effectiveness of our proposed UVLS.
2. Related Work
3. ProblemDefinition
4. Methodlogy
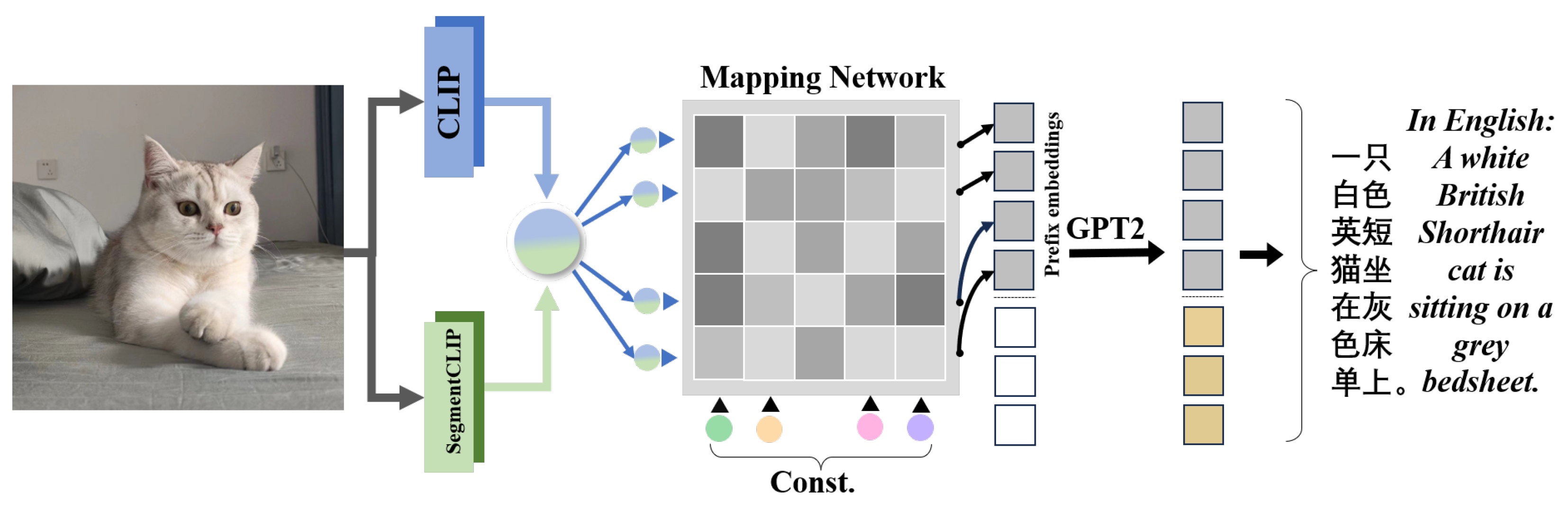
4.1. Overview
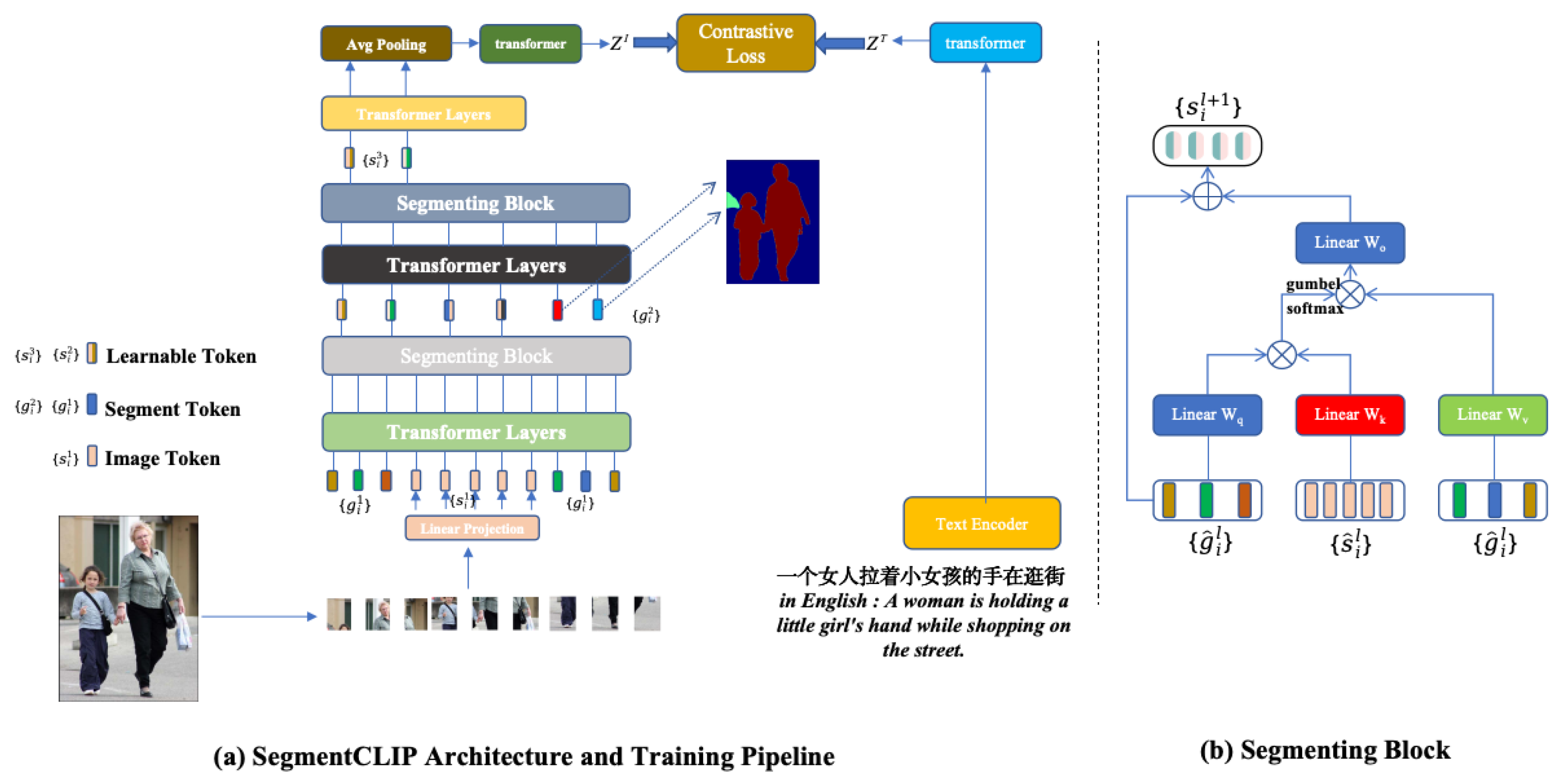
4.2. SegmentCLIP
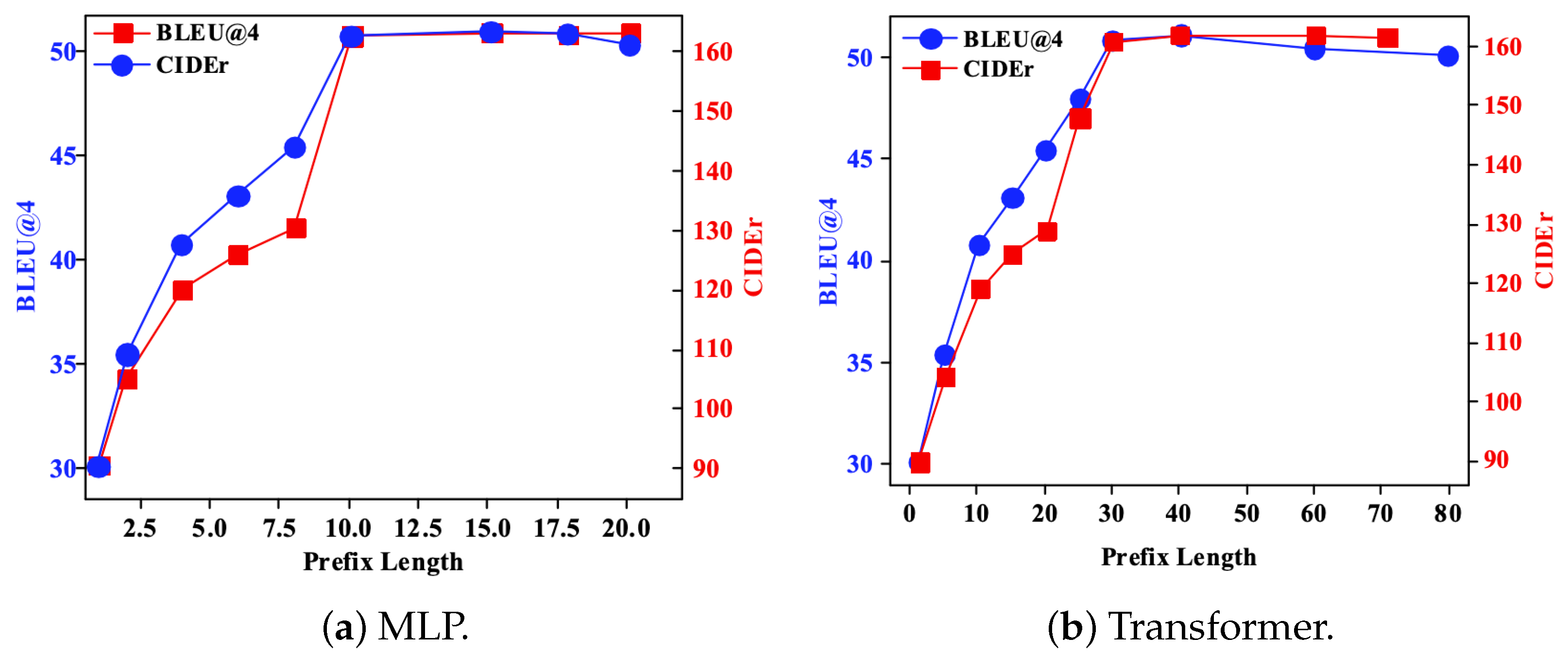
4.3. Parameter Analysis
4.4. CLIP
5. Experiments
5.1. Evaluation
5.2. Baselines
- CS-NIC [34]. The CS-NIC model excels in generating Chinese captions for images, employing Jieba for precise Chinese text segmentation, addressing the unique challenge of tokenizing Chinese without explicit word boundaries. Utilizing the pool5 layer of GoogLeNet, it effectively extracts image features, with a focus on convolutional neural network (CNN) technology for nuanced visual understanding. The model sets both visual and word embeddings to a size of 512, balancing rich representation with computational efficiency. For translation tasks, it favors Baidu’s service, noted for superior English–Chinese translation accuracy, underscoring its commitment to precision. CS-NIC stands out as a sophisticated tool, harmonizing advanced image processing and linguistic analysis, specifically optimized for the Chinese language image captioning domain. The CS-NIC model excels in generating Chinese captions for images through a bilingual approach, effectively integrating linguistic diversity into visual descriptions. However, its dependency on machine translation may compromise the depth and accuracy of the captions, posing challenges in fully capturing the nuances of human language.
- CIC [45]. The Convolutional Image Captioning (CIC) model represents a paradigm shift in automated image captioning, employing a convolutional neural network (CNN) instead of traditional recurrent neural network (RNN) methods. It features a four-component architecture including input and output embedding layers, image embedding, and a convolutional module with masked convolutions. This unique structure allows CIC to forgo RNN’s recurrent functions, leveraging a feed-forward deep network for direct modeling of image–word relations. The CIC model, therefore, offers a more efficient approach to image captioning, combining convolutional processing’s strengths with streamlined computational complexity. The CIC model stands out for its parallel processing efficiency, offering speedy training and competitive accuracy in image captioning by leveraging CNNs. Its primary limitation, however, lies in its potential struggle with long-range textual dependencies, which may impact the coherence of generated captions for complex visuals.
- SC [46]. The Stack-Cap (SC) model employs a unique coarse-to-fine sentence decoder for image captioning, comprising one coarse decoder and a sequence of attention-based fine decoders. This structure allows for the refined prediction of each word, using cues from the preceding decoder. Initially, the coarse decoder provides a basic description from global image features. In subsequent stages, each fine decoder enhances the image description, integrating both the image features and the output from the previous stage. This method involves using attention weights from one stage to inform the next, leading to progressively refined predictions. The architecture, with one coarse and several stacked fine decoders, demonstrates a sophisticated approach to incrementally improving image captions. The SC model excels in producing detailed image captions through a unique coarse-to-fine approach, effectively addressing the vanishing gradient issue. However, its multi-stage prediction framework increases training complexity and computational demands.
- Oscar [47]. The Oscar model introduces a pioneering approach in vision–language pre-training (VLP) by utilizing object tags as anchor points to facilitate the learning of semantic alignments between images and texts. This model significantly enhances the process of cross-modal representation learning by structuring input as triples of word sequences, object tags, and image region features. By leveraging detected object tags in images, Oscar efficiently aligns these with corresponding textual descriptions, thereby improving the accuracy and relevance of generated image captions. Pre-trained on a large dataset of 6.5 million text–image pairs, Oscar achieves state-of-the-art performance across multiple V + L tasks, demonstrating its effectiveness in bridging the semantic gap between visual content and language. This approach not only advances the field of image captioning but also contributes to a broader understanding and generation tasks in vision–language research, making it a valuable asset for future explorations in multimodal AI applications. The Oscar model enhances vision–language pre-training by utilizing object tags as anchor points, significantly boosting cross-modal learning. However, its effectiveness is contingent on the accuracy of the underlying object detection, which may restrict its adaptability and generalization across varied datasets.
- CLIPCAP [48]. The CLIPCAP model introduces a simplified yet effective method for image captioning, a key task in vision–language understanding. It uniquely employs CLIP encoding as a prefix in the captioning process, utilizing a straightforward mapping network followed by finetuning of a language model, specifically GPT2. This approach leverages the rich semantic features of the CLIP model, trained within a textual context, making it highly suitable for vision–language tasks. The integration of CLIP with a pre-trained language model enables comprehensive understanding of both visual and textual data. Remarkably, this model requires relatively brief training and can generate meaningful captions without the need for additional annotations or extensive pre-training, making it adept at handling large-scale and diverse datasets. The CLIPCAP model efficiently integrates CLIP’s visual encodings with a streamlined mapping network for rapid and resource-efficient caption generation, yet its dependence on pre-trained encodings may constrain its adaptability to diverse or novel imagery.
5.3. Performance Comparison
5.4. Ablation Studies
5.5. Case Studies
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Derkar, S.B.; Biranje, D.; Thakare, L.P.; Paraskar, S.; Agrawal, R. Captiongenx: Advancements in deep learning for automated image captioning. In Proceedings of the 2023 3rd Asian Conference on Innovation in Technology, Pune, India, 25–27 August 2023; pp. 1–8. [Google Scholar]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Feng, Y.; Ma, L.; Liu, W.; Luo, J. Unsupervised image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4125–4134. [Google Scholar]
- Zeng, A.; Attarian, M.; Ichter, B.; Choromanski, K.; Wong, A.; Welker, S.; Florence, P. Socratic models: Composing zero-shot multimodal reasoning with language. arXiv 2022, arXiv:2204.00598. [Google Scholar]
- Ghanem, F.A.; Padma, M.C.; Alkhatib, R. Automatic short text summarization techniques in social media platforms. Future Internet 2023, 15, 311. [Google Scholar] [CrossRef]
- Can, Y.S.; Mahesh, B.; André, E. Approaches, applications, and challenges in physiological emotion recognition—A tutorial overview. Proc. IEEE 2023, 111, 1287–1313. [Google Scholar] [CrossRef]
- Stefanini, M.; Cornia, M.; Baraldi, L.; Cascianelli, S.; Fiameni, G.; Cucchiara, R. From show to tell: A survey on deep learning-based image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 539–559. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Hao, Y.; Li, L.; Yin, J.; Liu, A.; Mao, Z.; Chen, Z.; Gao, X. Task-adaptive attention for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 43–51. [Google Scholar] [CrossRef]
- Herdade, S.; Kappeler, A.; Boakye, K.; Soares, J. Image captioning: Transforming objects into words. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; p. 32. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Hierarchy parsing for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2621–2629. [Google Scholar]
- He, S.; Liao, W.; Tavakoli, H.R.; Yang, M.; Rosenhahn, B.; Pugeault, N. Image captioning through image transformer. In Proceedings of the Asian Conference on Computer Vision (ACCV), Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2048–2057. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. Clipcap: Clip prefix for image captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
- Xu, J.; De Mello, S.; Liu, S.; Byeon, W.; Breuel, T.; Kautz, J.; Wang, X. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 18134–18144. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Liu, X.; Xu, Q.; Wang, N. A survey on deep neural network-based image captioning. Vis. Comput. 2019, 35, 445–470. [Google Scholar] [CrossRef]
- Geetha, G.; Kirthigadevi, T.; Ponsam, G.G.; Karthik, T.; Safa, M. Image captioning using deep convolutional neural networks. Proc. J. Phys. Conf. Ser. 2020, 1712, 012015. [Google Scholar] [CrossRef]
- Liu, S.; Bai, L.; Hu, Y.; Wang, H. Image captioning based on deep neural networks. Proc. Matec Web Conf. 2018, 232, 01052. [Google Scholar] [CrossRef]
- Yang, L.; Wang, H.; Tang, P.; Li, Q. CaptionNet: A tailor-made recurrent neural network for generating image descriptions. IEEE Trans. Multimed. 2020, 23, 835–845. [Google Scholar] [CrossRef]
- Chen, X.; Ma, L.; Jiang, W.; Yao, J.; Liu, W. Regularizing rnns for caption generation by reconstructing the past with the present. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 8–22 June 2018; pp. 7995–8003. [Google Scholar]
- Wang, J.; Wang, W.; Wang, L.; Wang, Z.; Feng, D.D.; Tan, T. Learning visual relationship and context-aware attention for image captioning. Pattern Recognit. 2020, 98, 107075. [Google Scholar] [CrossRef]
- Wang, C.; Shen, Y.; Ji, L. Geometry attention transformer with position-aware LSTMs for image captioning. Expert Syst. Appl. 2022, 201, 117174. [Google Scholar] [CrossRef]
- Zohourianshahzadi, Z.; Kalita, J.K. Neural attention for image captioning: Review of outstanding methods. Artif. Intell. Rev. 2022, 7, 3833–3862. [Google Scholar] [CrossRef]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Pedersoli, M.; Lucas, T.; Schmid, C.; Verbeek, J. Areas of attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1242–1250. [Google Scholar]
- Wang, W.; Chen, Z.; Hu, H. Hierarchical attention network for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8957–8964. [Google Scholar]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.; Gao, J. Unified vision-language pre-training for image captioning and vqa. In Proceedings of the AAAI Conference on Artificial Intelligence; Association for the Advancement of Artificial Intelligence: New York, NY, USA, 2020; Volume 34, pp. 13041–13049. [Google Scholar]
- Wang, W.; Yang, Z.; Xu, B.; Li, J.; Sun, Y. ViLTA: Enhancing vision-language pre-training through textual augmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3158–3169. [Google Scholar]
- Li, Y.; Fan, J.; Pan, Y.; Yao, T.; Lin, W.; Mei, T. Uni-EDEN: Universal encoder-decoder network by multi-granular vision-language pre-training. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 48. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, J.; Zheng, H.; Zhao, B.; Li, Y.; Yan, B.; Liang, R.; Wang, W.; Zhou, S.; Lin, G.; Fu, Y. AI challenger: A large-scale dataset for going deeper in image understanding. arXiv 2017, arXiv:1711.06475. [Google Scholar]
- Li, X.; Lan, W.; Dong, J.; Liu, H. Adding chinese captions to images. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; pp. 271–275. [Google Scholar]
- Li, X.; Xu, C.; Wang, X.; Lan, W.; Jia, Z.; Yang, G.; Xu, J. COCO-CN for cross-lingual image tagging, captioning, and retrieval. IEEE Trans. Multimed. 2019, 21, 2347–2360. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. Meteor: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out 2004, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Dosovitskiy, A. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Rush, A.M. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Virtual Event, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5561–5570. [Google Scholar]
- Gu, J.; Cai, J.; Wang, G.; Chen, T. Stack-captioning: Coarse-to-fine learning for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; p. 32. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 121–137. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2019, arXiv:2101.00190. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Lang. | Images | Captions | Caption Vocabulary |
|---|---|---|---|---|
| AIC-ICC | zh | 300 K | 1500 K | 7654 |
| Flickr8k-CN | zh | 8000 | 40,000 | 1447 |
| COCO-CN | zh | 2041 | 101,705 | 2069 |
| Datasets | Model | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|---|
| AIC-ICC | CS-NIC | 62.8 | 48.0 | 37.0 | 28.7 | 30.7 | 51.8 | 74.6 |
| CIC | 66.3 | 52.5 | 41.7 | 33.2 | 33.3 | 56.5 | 92.3 | |
| SC | 73.0 | 60.3 | 49.6 | 41.0 | 35.3 | 60.3 | 116.6 | |
| Oscar | 74.4 | 65.1 | 50.6 | 43.1 | 36.5 | 62.4 | 140.5 | |
| CLIPCAP | 76.7 | 65.1 | 55.0 | 46.4 | 38.8 | 64.0 | 151.2 | |
| Ours; UVLS | 79.7 | 68.9 | 59.1 | 50.7 | 40.1 | 66.2 | 164.2 | |
| Flickr8k-CN | CS-NIC | 63.2 | 50.2 | 38.4 | 28.1 | 31 | 54.7 | 81.6 |
| CIC | 68.7 | 55.5 | 43.3 | 31.6 | 33.2 | 59 | 96 | |
| SC | 73.3 | 59.7 | 47.3 | 35.9 | 35.3 | 61 | 121.3 | |
| Oscar | 80.4 | 69.5 | 59.4 | 50 | 41.2 | 67.3 | 160.5 | |
| CLIPCAP | 84.4 | 72.3 | 62.1 | 52 | 43.9 | 70.3 | 170.2 | |
| Ours; UVLS | 90.7 | 75.9 | 67.1 | 56.7 | 48.1 | 76.2 | 184.2 | |
| COCO-CN | CS-NIC | 42.7 | 31.6 | 16.9 | 10.5 | 5.6 | 24.9 | 50.3 |
| CIC | 50.1 | 42.2 | 27.6 | 20.6 | 7.3 | 26.9 | 65.9 | |
| SC | 59.5 | 42.3 | 35.7 | 24.6 | 10.6 | 30.9 | 80.8 | |
| Oscar | 69.4 | 58.3 | 48.6 | 38.5 | 20.4 | 46.3 | 107.8 | |
| CLIPCAP | 71.8 | 61.2 | 50.9 | 41.4 | 25.4 | 55.7 | 110.4 | |
| Ours; UVLS | 74.7 | 64.8 | 56.0 | 49.3 | 30.6 | 58.4 | 124.2 |
| Model | Params (M) | Training Time (h) |
|---|---|---|
| CS-NIC | 31 | 40 (GTX3090 (NVIDIA, Santa Clara, CA, USA)) |
| CIC | 42 | 56 (GTX3090) |
| SC | 64 | 80 (GTX3090) |
| Oscar | 135 | 200 (GTX3090) |
| CLIPCAP | 156 | 20 (GTX3090) |
| Ours; MLP+GPT2 tuning | 175 | 24 (GTX3090) |
| Ours; Transformer | 63 | 23 (GTX3090) |
| Model | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | METEOR | ROUGE | CIDEr |
|---|---|---|---|---|---|---|---|
| CLIPCAP | 76.7 | 65.1 | 55.0 | 46.4 | 38.8 | 64.0 | 151.2 |
| SegmentCLIP | 74.2 | 63.4 | 53.8 | 45.2 | 37.6 | 63.7 | 150.4 |
| Ours; Transformer | 79.2 | 68.4 | 58.6 | 50.1 | 40.3 | 66.1 | 164.9 |
| Ours; MLP+GPT2 tuning | 79.7 | 68.9 | 59.1 | 50.7 | 40.1 | 66.2 | 164.2 |
| Image |  |  |  |  |
| CS-NIC | 一个女人在喂羊 | 运动员在打网球 | 两个小女孩在房间玩耍 | 两个拳击手在打拳击 |
| in English | A woman is feeding sheep. | The athlete is playing tennis. | Two little girls are playing in the room. | Two boxers are boxing. |
| CIC | 女人在喂养羊 | 运动员在网球场打网球 | 两个女孩在更衣室玩耍 | 拳击手在擂台打拳击 |
| in English | The woman is feeding the sheep. | The athlete is playing tennis on a tennis court. | Two girls are playing in the dressing room. | The boxer is fighting in the ring. |
| SC | 穿着蓝色衣服的女人在喂养小羊 | 带着头巾的运动员在网球场打网球 | 两个穿着裙子的女孩在更衣室玩耍 | 两个拳击手在擂台打拳击 |
| in English | woman dressed in blue is feeding a lamb. | The athlete wearing a headband is playing tennis on a tennis court. | Two girls wearing dresses are playing in the dressing room. | Two boxers are fighting in the ring. |
| Oscar | 身穿蓝色衣服的女子在和小羊玩耍 | 穿着蓝色衣服的运动员在打网球 | 两个穿着裙子的小女孩在房间玩 | 两个拳击手在擂台比赛 |
| in English | The woman in blue clothes is playing with a lamb. | The athlete dressed in blue is playing tennis. | Two little girls wearing dresses are playing in the room. | Two boxers are competing in the ring. |
| CLIPCAP | 身穿蓝色衣服的女人在和一头白色的羊一起玩耍 | 穿着蓝色短袖的运动员在打网球 | 两个穿着裙子的小女孩在更衣室换衣服 | 两个拳击运动员在八角笼打拳击 |
| in English | A woman in blue clothes is playing with a white sheep. | The athlete wearing a blue short-sleeved shirt is playing tennis. | Two little girls wearing dresses are changing clothes in the dressing room. | Two boxing athletes are fighting in an octagon cage. |
| Ours | 一个身穿蓝色衣服的女人在和一头白色的羊一起玩耍 | 穿着蓝色短袖的运动员在网球场打网球 | 穿红色裙子的小女孩拉着另一个穿黑色裙子的女孩的衣服 | 带着红色拳套的拳击运动员一拳打在了另一个拳击运动员的下巴 |
| in English | A woman wearing blue clothes is playing with a white sheep. | The athlete wearing a blue short-sleeved shirt is playing tennis on a tennis court. | The little girl wearing a red dress is pulling on the clothes of another girl wearing a black dress. | The boxer with red gloves landed a punch on the chin of another boxer. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, J.; Tang, T. A Unified Visual and Linguistic Semantics Method for Enhanced Image Captioning. Appl. Sci. 2024, 14, 2657. https://doi.org/10.3390/app14062657
Peng J, Tang T. A Unified Visual and Linguistic Semantics Method for Enhanced Image Captioning. Applied Sciences. 2024; 14(6):2657. https://doi.org/10.3390/app14062657
Chicago/Turabian StylePeng, Jiajia, and Tianbing Tang. 2024. "A Unified Visual and Linguistic Semantics Method for Enhanced Image Captioning" Applied Sciences 14, no. 6: 2657. https://doi.org/10.3390/app14062657