1. Introduction
Obtaining a clear and haze-free image is crucial in photography and computer vision applications. Due to the presence of a large amount of dust, smoke, mist, or other floating particles in the atmosphere, when the camera captures images in this environment, significant quality degradation often occurs in the resulting images. These degradations, in turn, may have a negative impact on the performance of many computer vision systems [
1,
2,
3,
4], such as detection, tracking, and classification. Therefore, restoring clean images from damaged inputs through image dehazing is extremely important in the field of computer vision.
To overcome quality issues caused via haze in captured images, the atmospheric scattering model [
5,
6,
7] has been proposed to restore clean images; it can be formally written as follows:
where
is the observed hazy image,
is the true scene radiance,
is the global atmospheric light,
is the medium transmission map, and
x is the pixel index in the observed hazy image
I. Furthermore, the medium transmission map can be expressed as follows:
where
is the distance from the scene point to the camera, and
represents the attenuation coefficient of the atmosphere.
From Equation (
1), it can be seen that the dehazing process requires the accurate estimation of the transmission map and atmospheric light. A small portion of research mainly focuses on estimating atmospheric light [
8,
9,
10,
11,
12], but the accuracy of the atmospheric light obtained will directly affect the results after dehazing and excessive errors will lead to a decrease in the dehazing performance on the image. Alternative other algorithms focus more on accurately estimating transmission maps, and the estimation of a transmission map mainly falls into two categories: prior-based methods [
13,
14] and learning-based methods [
15,
16]. In order to compensate for information loss during image processing, some methods use different priors to obtain atmospheric light and transmission maps. For example, Berman et al. [
17] proposed a non-local prior-based dehazing algorithm based on the assumption that the colors of clean images are well approximated by different colors. Based on the difference in brightness, the saturation of blurred images is blurred, and color attenuation prior (CAP) [
18] is proposed to estimate scene depth. The image prior obtained using prior-based algorithms can easily be inconsistent with practice, which may lead to incorrect transmission approximations. Learning-based methods are effective and superior to prior based-algorithms, exhibiting significant performance improvements. In [
19], two subnetworks were designed to estimate the transmission map and atmospheric light, respectively. In [
20], the authors created three different images from the hazy image and fused the results of the three images after dehazing. However, deep learning-based methods require training on a large number of real hazy images and their corresponding images without haze. The methods of estimating atmospheric light and transmission maps separately have made significant progress, but both have limitations. On the one hand, the inaccurate estimation of transmission maps may lead to low image quality; on the other hand, the separate estimation of atmospheric light and transmission maps leads to difficulties in finding the inherent relationship between them.
In order to find the intrinsic relationship between the parameters of Equation (
1), Boyi Li et al. [
21] first proposed a dehazing model that does not estimate
and
. This model directly generates clean images from blurred images, rather than relying on any separate intermediate parameter estimation steps. Recently, many methods have used end-to-end learning instead of atmospheric scattering models to directly obtain clean images from networks [
22,
23,
24,
25]. Another widely used method tends to predict the residual of potential haze-free images or haze-free images relative to hazy images, as they often achieve better performance [
26,
27,
28,
29,
30]. Although these recent dehazing methods have made significant progress, due to the complex haze distribution and the difficulty in collecting image pairs during the training process, it is easy to lose image details during the dehazing process using limited a dataset.
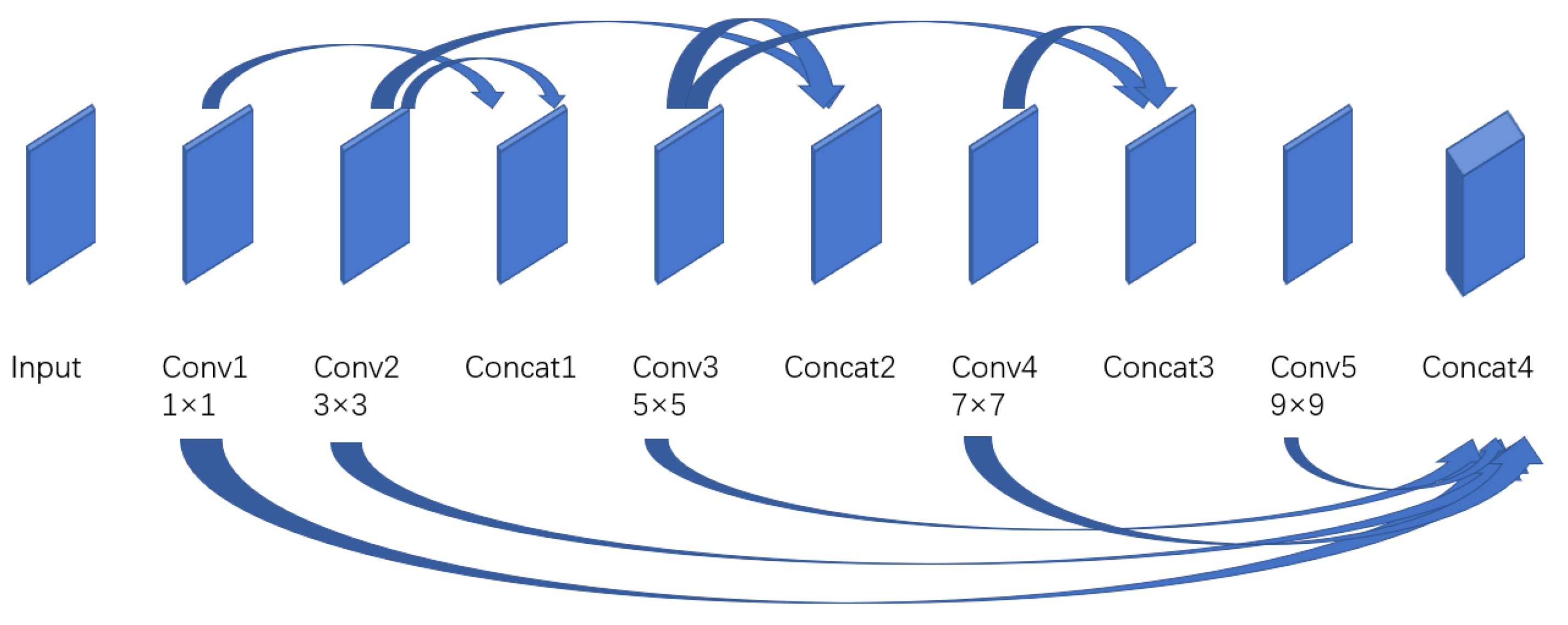
Due to the difficulty in collecting image pairs during the training process, IFE-Net uses end-to-end models, adaptively learns network features, and adopts multiscale feature extraction to better extract information. In addition, parallel convolutional layers of different sizes are used to extract features from input images of different scales [
31,
32]. This feature extraction structure is conducive to preserving more information and reducing the loss of image details.
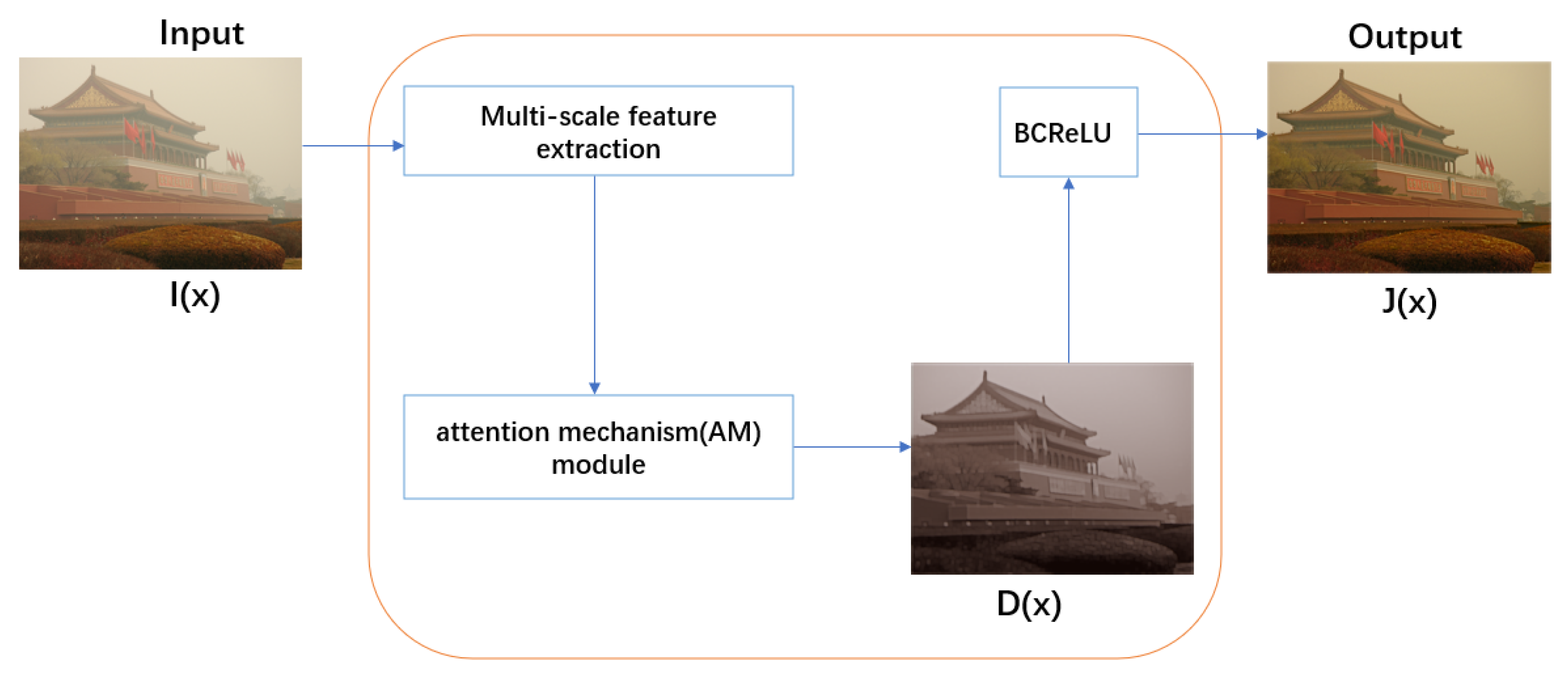
Considering the potential cumulative error caused via the separate estimation of atmospheric light and the transmission map, IFE-Net unifies atmospheric light and transmission maps as one parameter to directly obtain a clean image. In addition, attention mechanisms have been widely applied in the design of neural networks [
19,
33,
34,
35,
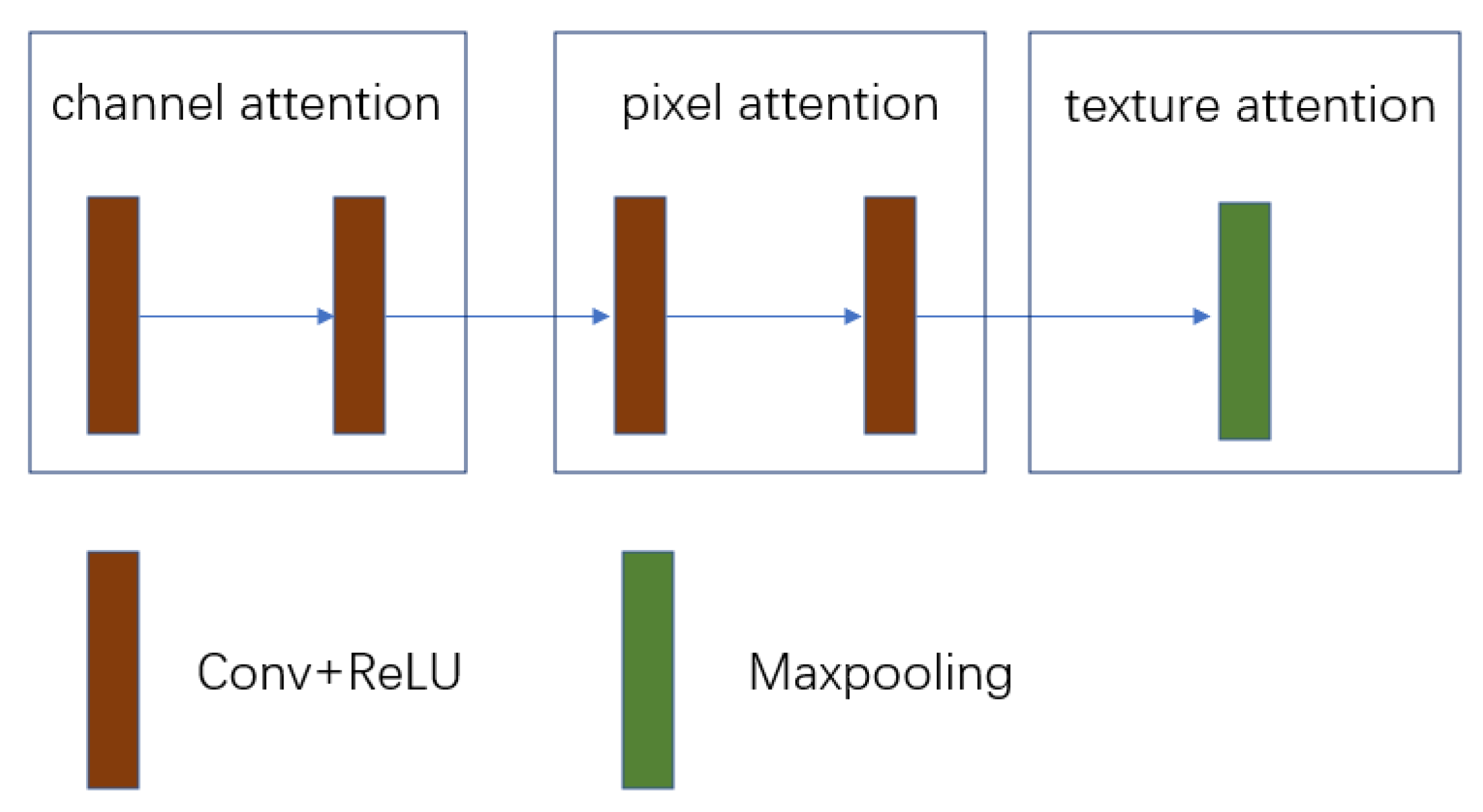
36], which can provide additional flexibility in the network. Inspired by these works and considering the different weights of features in different regions, a feature attention mechanism module called attention mechanism (AM) is designed in the network, which processes different types of information more effectively.
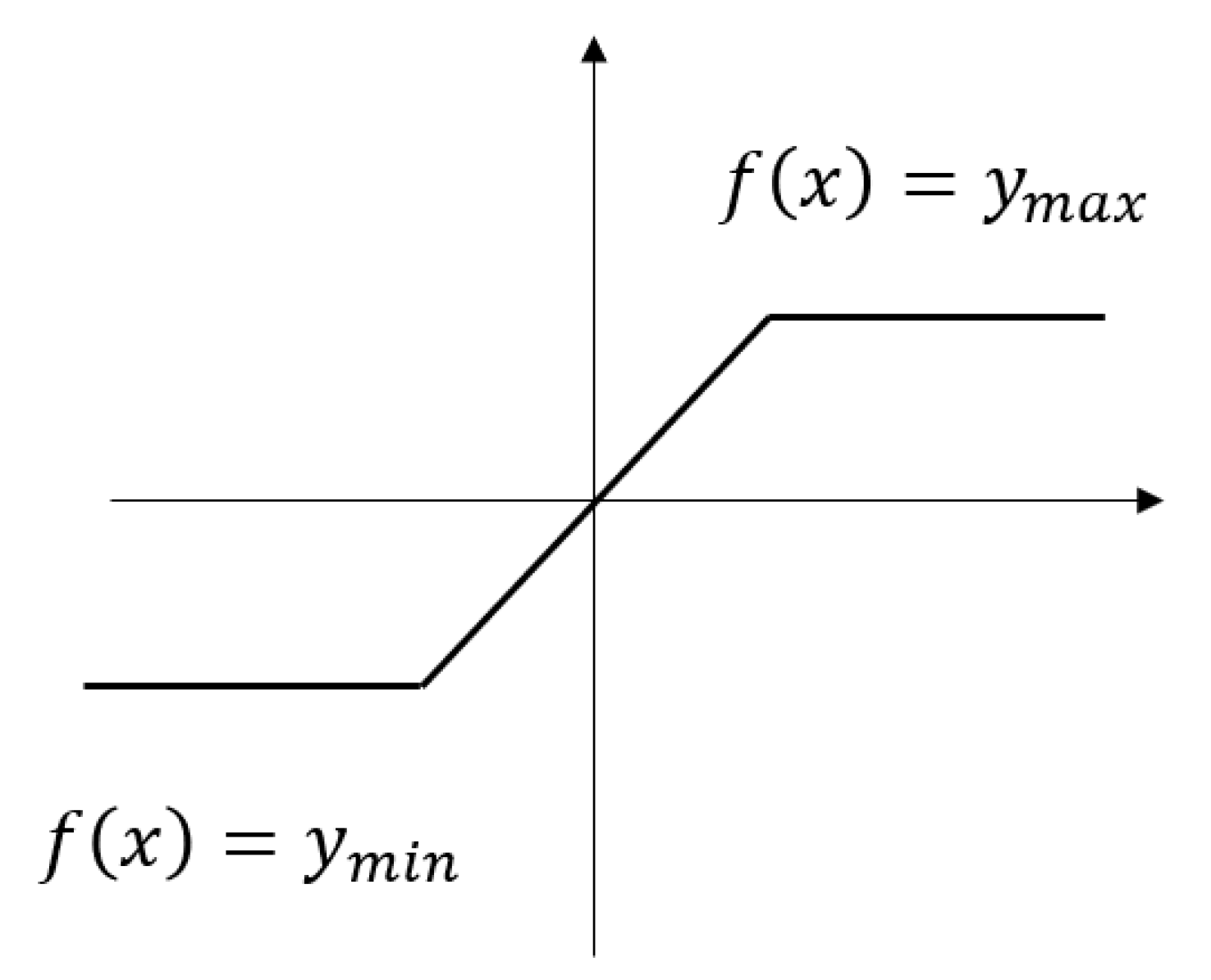
In deep learning networks, the activation function is a nonlinear function that enables neural networks to learn and represent complex patterns and relationships. The selection of the final activation function has a significant impact on the output results of the model, as different activation functions have different characteristics and applicable scenarios. We considered that the output of the last layer of the image after dehazing should have upper and lower boundaries. In IFE-Net, we designed a new activation function called a bilateral constrained rectifier linear unit (BCReLU). The specific details of BCReLU and its comparison with other activation results in the network are detailed in
Section 3.2.3.
The main contributions are as follows:
IFE-Net directly produces the clean image from a hazy image, rather than estimating the transmission map and atmospheric light separately. All parameters of IFE-Net are estimated in a unified model.
We propose a novel attention mechanism (AM) module, which consists of a channel attention mechanism, pixel attention mechanism, and texture attention. This module has different weighted information for different features and focuses more on strong features in areas with thick haze.
A bilateral constrained rectifier linear unit (BCReLU) is proposed in IFE-Net. To our knowledge, no one else has proposed BCReLU. Its significance in obtaining image restoration is demonstrated through experiments.
The experiments show that IFE-Net performs well both qualitatively and quantitatively. The extensive experimental results also illustrate the effectiveness of IFE-Net.
2. Related Work
Recently, single-image dehazing has attracted widespread attention in the field of computer vision. Due to the unknown global atmospheric light and transmission map, single-image dehazing is an inherently ill-posed problem. Many different methods have been proposed to address the issue. These methods can be roughly divided into prior-based and learning-based methods. The main difference between these two methods is that the prior-based methods mainly utilize prior statistical knowledge and hand-crafted features to process the hazy images, while the learning-based methods can automatically learn from the training set through a neural network and save it in the network’s weights.
Single-image dehazing methods that extensively utilize prior knowledge have emerged. A patch-based dark channel prior (DCP) [
11] method proposed by He et al. is one of the representative prior methods. Based on the assumption that hazy images may have extremely low intensity in at least one color channel, DCP uses an atmospheric scattering model for haze removal. Pixel-based dehazing methods [
37,
38] provide another solution to estimate the transmission map; however, pixel-based dehazing methods may result in insufficient information and an inability to estimate transmission maps. In addition, a method for establishing a linear model based on local prior images was proposed by Zhu et al. [
18] to restore depth information. Although prior-based methods have achieved good results, the existence of priors is conditional. These hand-crafted priors are only applicable to specific cases and may not be applicable in changing scenarios.
The human brain is able to quickly distinguish hazy regions in natural images without other information, and convolutional neural networks have been inspired by this to be applied in image dehazing. These learning-based methods demonstrate extremely strong capabilities in dehazing. For example, Cai et al. [
31] proposed Dehaze-Net, which is a trainable end-to-end network consisting of four parts: feature extraction; multiscale mapping; local extremum; and nonlinear regression. It is used to estimate the transmission map, and then the output transmission map is restored to a clean image through an atmospheric scattering model. Ren et al. [
39] further proposed a multiscale convolutional neural network (MSCNN) for estimating scene transmission maps. Qin et al. [
36] proposed an end-to-end feature fusion attention network (FFA-Net) to directly recover clean images, taking into account different weighted information. Due to the difficulty in obtaining paired clean images and hazy images in nature, Li et al. [
40] studied the implementation of image dehazing without training on real clean image sets on the ground. These learning-based methods have achieved good performance in dehazing and are more widely used in image dehazing.
5. Conclusions
We proposed a novel end-to-end adaptive enhancement dehazing network, called IFE-Net, to address the challenge of single-image dehazing. IFE-Net consists of a multiscale feature extraction block, an attention mechanism (AM) module, and a bilateral constrained rectifier linear unit (BCReLU). Considering the cumulative errors that may arise from estimating atmospheric light and transmission maps separately, IFE-Net estimates a parameter that is unified by both. Its novel network design effectively performs feature extraction. In addition, we designed an attention mechanism (AM) module to address the varying importance of information in different regions. The importance of BCReLU in image restoration was also demonstrated through experiments. We compared IFE-Net with other dehazing methods using PSNR and SSIM, and the results show that IFE-Net achieved good scores for both indicators. At the same time, we used subjective criteria to analyze the results obtained via different methods on natural hazy images. Our conclusion is that the proposed IFE-Net combines feature extraction blocks, attention mechanism, and a BCReLU activation function, making it significantly effective in natural and synthetic image dehazing. Although our IFE-Net has a simple structure, it shows strong capabilities in haze removal. The experimental results confirm the superiority and efficiency of IFE-Net. At present, IFE-Net has achieved good results in dehazing, and another promising area for our future research is to apply it to image enhancement algorithms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}