
Cross-Feature Transfer Learning for Efficient Tensor Program Generation

Abstract
:1. Introduction
- Conducted a thorough examination of existing research to extract and assimilate insights from the combined neural network and hardware features.
- Formulated a proposed methodology grounded in the principles of minimizing kernel measurements and leveraging efficient transfer learning.
- Implemented an optimized tuner based on the aforementioned key points and showcased results for heterogeneous transfer learning. The outcomes demonstrated comparable or improved mean inference time, accompanied by a noteworthy 3×–5× reduction in tuning time and up to a 53% reduction in dataset size.
2. Background and Related Work
2.1. Cross-Device Learning
2.2. Machine Learning-Based Autotuners
2.3. Hardware-Aware Autotuners
3. Design and Implementation
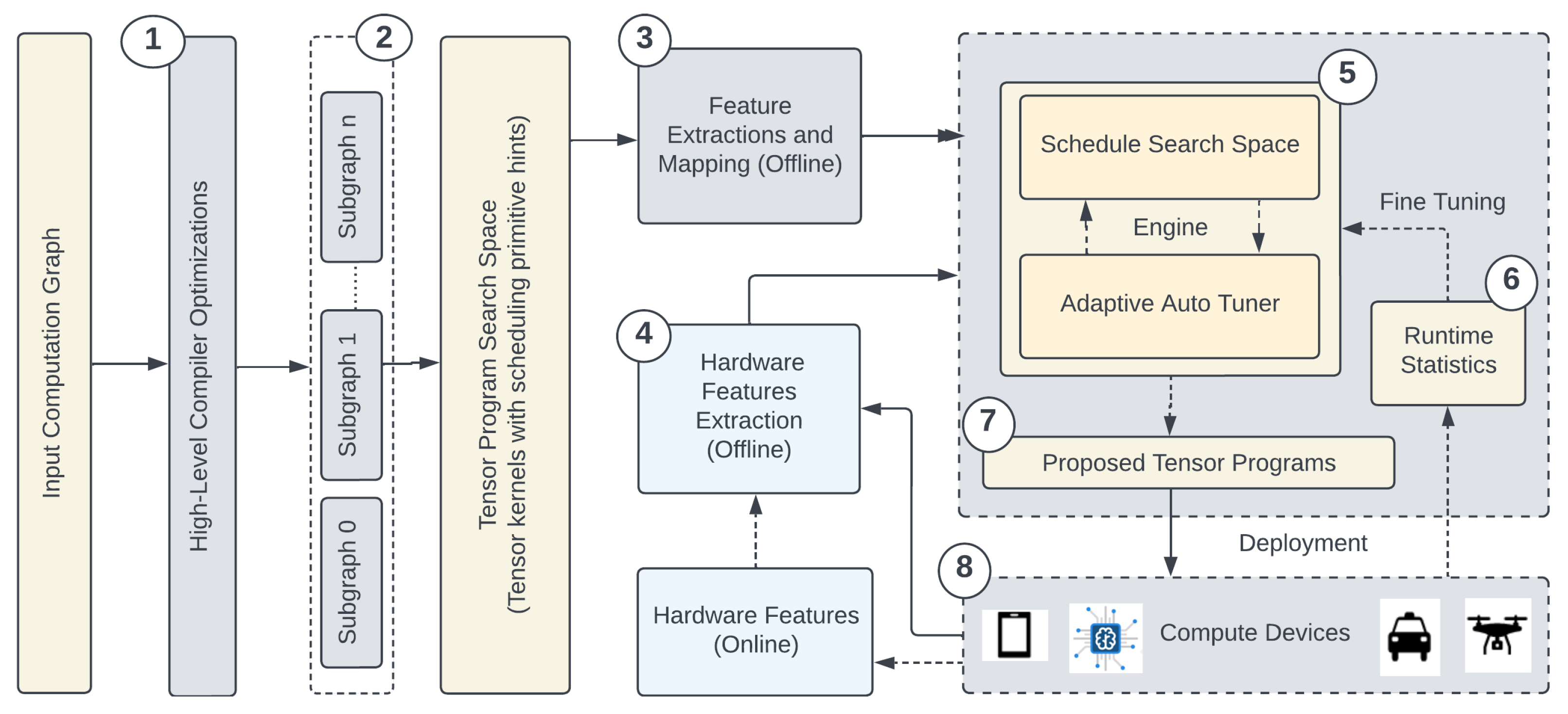
3.1. End-to-End Execution Steps of the Framework
- The user initiates the workflow by providing the computational framework in a supported format, such as TensorFlow, ONNX [44], or PyTorch.
- The framework undertakes high-level optimization and subgraph partitioning, resulting in the generation of smaller subgraphs. These subgraphs constitute the candidates for the search space for subsequent feature extraction operations. Measurements are performed on these subgraphs for a particular hardware configuration. The outcomes are subsequently stored in individual JSON [45] files for each subgraph, encompassing schedule primitive hints and the execution time for each auto-generated tensor program.
- Domain-specific information, encompassing details like kernel dimensions and tensor operations, is preserved from the subgraphs, forming a distinctive feature set.
- For each data-point entry or kernel, critical hardware information is meticulously recorded, including hardware architecture, maximum thread count, register allocation, and threads per block. This data constitutes the static hardware dataset.
- A probabilistic and exploratory study is conducted on this feature set to identify features of significant importance. This hardware characterization plays a pivotal role in mapping features from the source hardware to the target hardware, ensuring compatibility. The autotuner is trained using this dataset, extending the principles of a one-shot tuner [10]. This training equips the autotuner with the capability to generate tensor programs on the target device automatically, with or without retraining.
- For users seeking fine-tuning capabilities, the framework offers the option to fine-tune the autotuner using online hardware features. Experimental work includes selective task retraining and a methodology inspired by the Lottery Ticket Hypothesis-based technique [20]. Our approach reduces retraining time and minimizes the dataset size required for fine-tuning. The utilization of attention heads supports memory-augmented fine-tuning via bidirectional LSTM [46]. Given the framework’s attention-based training strategy, the autotuner model undergoes a comprehensive training phase only once, mitigating the necessity for extensive data on the target device for full retraining.
- Following the execution of steps 5 and 6, a set of top-k tensor programs is generated. To facilitate user selection based on specified metrics, we employ ranking loss. This ensures that users have the flexibility to choose a tensor program from the top-k list according to their preferences and the defined metric.
- Finally, the proposed tensor programs are deployed on the target hardware, and their performance is rigorously evaluated.
3.2. Hardware-Aware Kernel Sampling
3.3. Autotuner Architecture
4. Evaluation
4.1. Experimental Setup
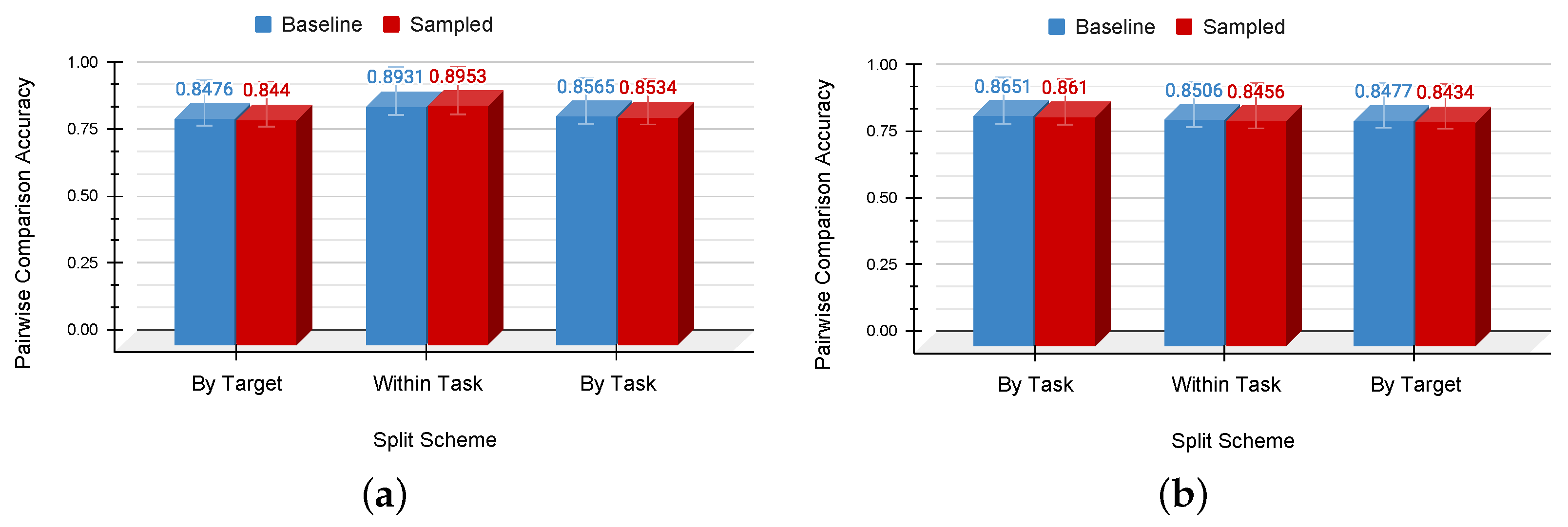
4.2. Dataset Sampling
| Listing 1. A Sample Measured Record On A64FX. |
| { “i”: [[“[\“fb4a01c3da78ae0da8352ece38076266\”, 1, 8, 8, 960, 5, 5, 960, 1, 1, 1, 1, 960, 1, 8, 8, 960]”, “llvm -keys=arm_cpu,cpu -device= arm_cpu -link-params=0”, [24, 64, 64, 0, 0, 0, 0, 0], “”, 2, []], [[], [[“CI”, 10], [“CI”, 9], [“CI”, 8], [“CI”, 7], [“CI”, 6], [“CI”, 5], [“SP”, 3, 0, 1, [1, 1, 1], 1], [“SP”, 3, 4, 8, [2, 2, 2], 1], [“SP”, 3, 8, 8, [4, 1, 2], 1], [“SP”, 3, 12, 960, [16, 12, 1], 1], [“SP”, 3, 16, 5, [1], 1], [“SP”, 3, 18, 5, [1], 1], [“RE”, 3, [0, 4, 8, 12, 1, 5, 9, 13, 16, 18, 2, 6, 10, 14, 17, 19, 3, 7, 11, 15]], [“ CA”, 1, 3, 4], [“FU”, 3, [0, 1, 2, 3, 4]], [“AN”, 3, 0, 3], [“FU”, 11, [0, 1, 2, 3]], [“AN”, 11, 0, 3], [“PR”, 3, 0, “ auto_unroll_max_step$64”], [“AN”, 3, 15, 2]]]], “r”: [[0.000601874, 0.000620504, 0.000601334, 0.000600345, 0.000598904, 0.000599284, 0.000599315, 0.000600214], 0, 6.08456, 1700954668], “v”: “v0.6” } |
- within_task
- –
- The dataset is divided into training and testing sets based on the measurement record.
- –
- Features are extracted for each task, shuffled, and then randomly partitioned.
- by_task
- –
- A learning task is employed to randomly partition the dataset based on the features of the learning task.
- by_target
- –
- Partitioning is executed based on the hardware parameters.
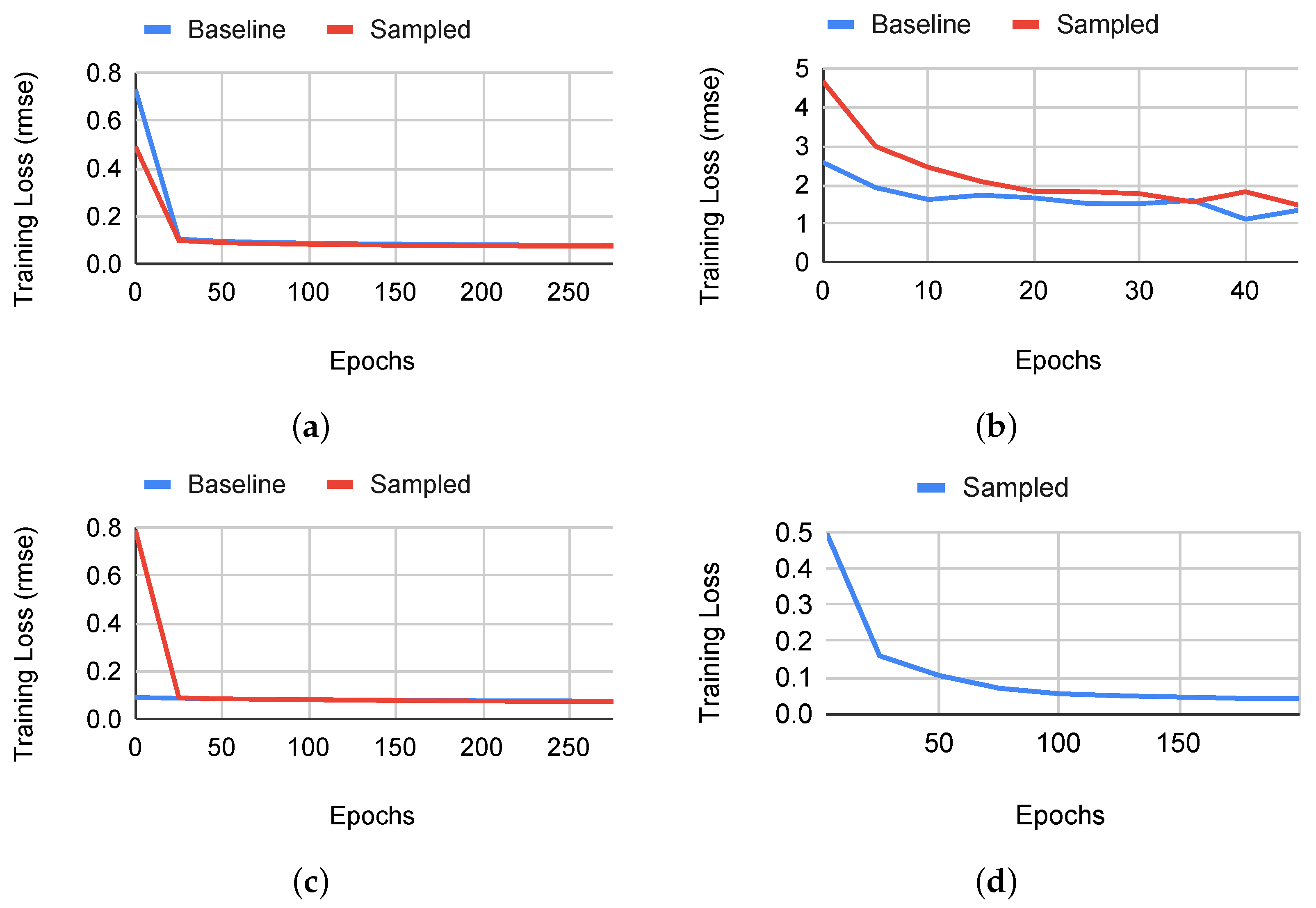
4.3. Tensor Program Tuning
4.4. Evaluation of Heterogeneous Transfer Learning
5. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sabne, A. XLA: Compiling Machine Learning for Peak Performance. 2020. Available online: https://www.tensorflow.org/xla (accessed on 30 November 2023).
- Chen, T.; Moreau, T.; Jiang, Z.; Zheng, L.; Yan, E.; Shen, H.; Cowan, M.; Wang, L.; Hu, Y.; Ceze, L.; et al. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 578–594. [Google Scholar]
- Rotem, N.; Fix, J.; Abdulrasool, S.; Catron, G.; Deng, S.; Dzhabarov, R.; Gibson, N.; Hegeman, J.; Lele, M.; Levenstein, R.; et al. Glow: Graph lowering compiler techniques for neural networks. arXiv 2018, arXiv:1805.00907. [Google Scholar]
- Kjolstad, F.; Kamil, S.; Chou, S.; Lugato, D.; Amarasinghe, S. The Tensor Algebra Compiler. Proc. ACM Program. Lang. 2017, 1, 1–29. [Google Scholar] [CrossRef]
- Li, M.; Liu, Y.; Liu, X.; Sun, Q.; You, X.; Yang, H.; Luan, Z.; Gan, L.; Yang, G.; Qian, D. The deep learning compiler: A comprehensive survey. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 708–727. [Google Scholar] [CrossRef]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. {TensorFlow}: A system for {Large-Scale} machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Chen, T.; Zheng, L.; Yan, E.; Jiang, Z.; Moreau, T.; Ceze, L.; Guestrin, C.; Krishnamurthy, A. Learning to optimize tensor programs. In Proceedings of the Advances in Neural Information Processing System, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Ryu, J.; Park, E.; Sung, H. One-shot tuner for deep learning compilers. In Proceedings of the 31st ACM SIGPLAN International Conference on Compiler Construction, Seoul, Republic of Korea, 2–3 April 2022; pp. 89–103. [Google Scholar]
- Zheng, L.; Liu, R.; Shao, J.; Chen, T.; Gonzalez, J.E.; Stoica, I.; Ali, A.H. Tenset: A large-scale program performance dataset for learned tensor compilers. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), Virtual, 6 December 2021. [Google Scholar]
- Gibson, P.; Cano, J. Transfer-Tuning: Reusing Auto-Schedules for Efficient Tensor Program Code Generation. In Proceedings of the 31st International Conference on Parallel Architectures and Compilation Techniques (PACT), Chicago, IL, USA, 8–12 October 2022. [Google Scholar]
- Verma, G.; Raskar, S.; Xie, Z.; Malik, A.M.; Emani, M.; Chapman, B. Transfer Learning Across Heterogeneous Features For Efficient Tensor Program Generation. In Proceedings of the 2nd International Workshop on Extreme Heterogeneity Solutions, New York, NY, USA, 17–18 May 2023. ExHET 23. [Google Scholar] [CrossRef]
- Verma, G. Efficient Transfer Tuning Tenset. 2022. Available online: https://github.com/xintin/TransferLearn_HetFeat_TenProgGen (accessed on 1 January 2020).
- Verma, G.; Finviya, S.; Malik, A.M.; Emani, M.; Chapman, B. Towards neural architecture-aware exploration of compiler optimizations in a deep learning {graph} compiler. In Proceedings of the 19th ACM International Conference on Computing Frontiers, Turin, Italy, 17–19 May 2022; pp. 244–250. [Google Scholar]
- Mendis, C.; Renda, A.; Amarasinghe, S.; Carbin, M. Ithemal: Accurate, portable and fast basic block throughput estimation using deep neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 4505–4515. [Google Scholar]
- Siddiqui, T.; Jindal, A.; Qiao, S.; Patel, H.; Le, W. Cost models for big data query processing: Learning, retrofitting, and our findings. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 99–113. [Google Scholar]
- Zhang, H.; Li, Y.; Deng, Z.; Liang, X.; Carin, L.; Xing, E. Autosync: Learning to synchronize for data-parallel distributed deep learning. Adv. Neural Inf. Process. Syst. 2020, 33, 906–917. [Google Scholar]
- Zhai, Y.; Zhang, Y.; Liu, S.; Chu, X.; Peng, J.; Ji, J.; Zhang, Y. Tlp: A deep learning-based cost model for tensor program tuning. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; Volume 2, pp. 833–845. [Google Scholar]
- Zhao, Z.; Shuai, X.; Bai, Y.; Ling, N.; Guan, N.; Yan, Z.; Xing, G. Moses: Efficient exploitation of cross-device transferable features for tensor program optimization. arXiv 2022, arXiv:2201.05752. [Google Scholar]
- Kaufman, S.; Phothilimthana, P.; Zhou, Y.; Mendis, C.; Roy, S.; Sabne, A.; Burrows, M. A learned performance model for tensor processing units. Proc. Mach. Learn. Syst. 2021, 3, 387–400. [Google Scholar]
- Cummins, C.; Petoumenos, P.; Wang, Z.; Leather, H. End-to-end deep learning of optimization heuristics. In Proceedings of the 2017 26th International Conference on Parallel Architectures and Compilation Techniques (PACT), Portland, OR, USA, 9–13 September 2017; pp. 219–232. [Google Scholar]
- Adams, A.; Ma, K.; Anderson, L.; Baghdadi, R.; Li, T.M.; Gharbi, M.; Steiner, B.; Johnson, S.; Fatahalian, K.; Durand, F.; et al. Learning to optimize halide with tree search and random programs. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Jung, W.; Dao, T.T.; Lee, J. DeepCuts: A deep learning optimization framework for versatile GPU workloads. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual, 20–25 June 2021; pp. 190–205. [Google Scholar]
- Nakandala, S.; Saur, K.; Yu, G.I.; Karanasos, K.; Curino, C.; Weimer, M.; Interlandi, M. A tensor compiler for unified machine learning prediction serving. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), Virtual, 4–6 November 2020; pp. 899–917. [Google Scholar]
- Zhang, M.; Li, M.; Wang, C.; Li, M. Dynatune: Dynamic tensor program optimization in deep neural network compilation. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Ansel, J.; Kamil, S.; Veeramachaneni, K.; Ragan-Kelley, J.; Bosboom, J.; O’Reilly, U.M.; Amarasinghe, S. Opentuner: An extensible framework for program autotuning. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation, Edmonton, AB, Canada, 24–27 August 2014; pp. 303–316. [Google Scholar]
- Verma, G.; Gupta, Y.; Malik, A.M.; Chapman, B. Performance evaluation of deep learning compilers for edge inference. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 858–865. [Google Scholar]
- Zheng, L.; Jia, C.; Sun, M.; Wu, Z.; Yu, C.H.; Haj-Ali, A.; Wang, Y.; Yang, J.; Zhuo, D.; Sen, K.; et al. Ansor: Generating {High-Performance} Tensor Programs for Deep Learning. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), Virtual, 4–6 November 2020; pp. 863–879. [Google Scholar]
- Steiner, B.; Cummins, C.; He, H.; Leather, H. Value learning for throughput optimization of deep learning workloads. Proc. Mach. Learn. Syst. 2021, 3, 323–334. [Google Scholar]
- Whaley, R.C.; Dongarra, J.J. Automatically tuned linear algebra software. In Proceedings of the SC’98: Proceedings of the 1998 ACM/IEEE Conference on Supercomputing, Orlando, FL, USA, 7–13 November 1998; p. 38. [Google Scholar]
- Mendis, C.; Yang, C.; Pu, Y.; Amarasinghe, D.; Carbin, M. Compiler auto-vectorization with imitation learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Mutlu, E.; Tian, R.; Ren, B.; Krishnamoorthy, S.; Gioiosa, R.; Pienaar, J.; Kestor, G. Comet: A domain-specific compilation of high-performance computational chemistry. In Proceedings of the Languages and Compilers for Parallel Computing: 33rd International Workshop, LCPC 2020, Virtual Event, 14–16 October 2020; Revised Selected Papers. Springer: Berlin/Heidelberg, Germany, 2022; pp. 87–103. [Google Scholar]
- Bradbury, J.; Frostig, R.; Hawkins, P.; Johnson, M.J.; Leary, C.; Maclaurin, D.; Necula, G.; Paszke, A.; VanderPlas, J.; Wanderman-Milne, S.; et al. JAX: Composable Transformations of Python+NumPy Programs. 2018. Available online: https://github.com/google/jax (accessed on 30 November 2023).
- Valiev, M.; Bylaska, E.J.; Govind, N.; Kowalski, K.; Straatsma, T.P.; Van Dam, H.J.J.; Wang, D.; Nieplocha, J.; Aprà, E.; Windus, T.L.; et al. NWChem: A comprehensive and scalable open-source solution for large scale molecular simulations. Comput. Phys. Commun. 2010, 181, 1477–1489. [Google Scholar] [CrossRef]
- Bi, J.; Li, X.; Guo, Q.; Zhang, R.; Wen, Y.; Hu, X.; Du, Z.; Song, X.; Hao, Y.; Chen, Y. BALTO: Fast tensor program optimization with diversity-based active learning. In Proceedings of the Eleventh International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Liu, L.; Shen, M.; Gong, R.; Yu, F.; Yang, H. Nnlqp: A multi-platform neural network latency query and prediction system with an evolving database. In Proceedings of the 51st International Conference on Parallel Processing, Bordeaux, France, 29 August–1 September 2022; pp. 1–14. [Google Scholar]
- Zhu, H.; Wu, R.; Diao, Y.; Ke, S.; Li, H.; Zhang, C.; Xue, J.; Ma, L.; Xia, Y.; Cui, W.; et al. {ROLLER}: Fast and Efficient Tensor Compilation for Deep Learning. In Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), Carlsbad, CA, USA, 11–13 July 2022; pp. 233–248. [Google Scholar]
- Zheng, S.; Liang, Y.; Wang, S.; Chen, R.; Sheng, K. Flextensor: An automatic schedule exploration and optimization framework for tensor computation on heterogeneous system. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 859–873. [Google Scholar]
- Xu, Z.; Xu, J.; Peng, H.; Wang, W.; Wang, X.; Wan, H.; Dai, H.; Xu, Y.; Cheng, H.; Wang, K.; et al. ALT: Breaking the Wall between Data Layout and Loop Optimizations for Deep Learning Compilation. In Proceedings of the Eighteenth European Conference on Computer Systems, Rome, Italy, 8–12 May 2023; pp. 199–214. [Google Scholar]
- Ahn, B.H.; Kinzer, S.; Esmaeilzadeh, H. Glimpse: Mathematical embedding of hardware specification for neural compilation. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; pp. 1165–1170. [Google Scholar]
- Li, M.; Yang, H.; Zhang, S.; Yu, F.; Gong, R.; Liu, Y.; Luan, Z.; Qian, D. Exploiting Subgraph Similarities for Efficient Auto-tuning of Tensor Programs. In Proceedings of the 52nd International Conference on Parallel Processing, Salt Lake City, UT, USA, 7–10 August 2023; pp. 786–796. [Google Scholar]
- Mu, P.; Liu, Y.; Wang, R.; Liu, G.; Sun, Z.; Yang, H.; Luan, Z.; Qian, D. HAOTuner: A Hardware Adaptive Operator Auto-Tuner for Dynamic Shape Tensor Compilers. IEEE Trans. Comput. 2023, 72, 3178–3190. [Google Scholar] [CrossRef]
- Bai, J.; Lu, F.; Zhang, K. ONNX: Open Neural Network Exchange. 2019. Available online: https://github.com/onnx/onnx (accessed on 1 January 2020).
- Pezoa, F.; Reutter, J.L.; Suarez, F.; Ugarte, M.; Vrgoč, D. Foundations of JSON schema. In Proceedings of the 25th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Montreal, QC, Canada, 11–15 May 2016; pp. 263–273. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; KDD ’16. pp. 785–794. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: Hoboken, NJ, USA, 1994. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Hardware Platform | Processor | Remarks |
|---|---|---|
| Intel Platinum 8272CL @ 2.60 GHz | CPU | 16 cores, AVX-512 |
| AMD EPYC 7452 @ 2.35 GHz | CPU | 4 cores, AVX-2 |
| ARM Graviton2 | CPU | 16 cores, Neon |
| NVIDIA Tesla T4 | GPU | Turing Architecture |
| NVIDIA GeForce RTX 2080 | GPU | Turing Architecture |
| NVIDIA A100 | GPU | Ampere Architecture |
| NVIDIA A40 | GPU | Ampere Architecture |
| NVIDIA H100 | GPU | Hopper Architecture |
| Intel Gold 5115 @ 2.40 GHz | CPU | 40 cores, Xeon |
| ARM A64FX | CPU | 48 cores, aarch64 |
| Hardware Parameter | Definition | Hardware Class | Value (Bytes) |
|---|---|---|---|
| cache_line_bytes | chunks of memory handled by the cache | CPU; GPU | 64 |
| max_local_memory_per_block | maximum local memory per block in bytes | GPU | 2,147,483,647 |
| max_shared_memory_per_block | maximum shared memory per block in bytes | GPU | 49,152 |
| max_threads_per_block | maximum number of threads per block | GPU | 1024 |
| max_vthread_extent | maximum extent of virtual threading | GPU | 8 |
| num_cores | number of cores in the compute hardware | CPU | 24 |
| vector_unit_bytes | width of vector units in bytes | CPU; GPU | 64, 16 |
| warp_size | thread numbers of a warp | GPU | 32 |
| Sampled Kernels | #Kernel_Shapes | Max GFLOPs | Tensor Shape | Mean Execution Time (ms) | |||||
|---|---|---|---|---|---|---|---|---|---|
| CPU | GPU | CPU | GPU | EPYC-7452 | Graviton2 | Platinum-8272 | T4 | ||
| T_add | 229 | 388 | 8.59 | 8.59 | [4, 256, 1024] | 180.97 | 81.25 | 92.86 | 4.31 |
| Conv2dOutput | 60 | 27 | 1.20 | 1.07 | [4, 64, 64, 32] | 40.94 | 14.21 | 19.11 | 2.07 |
| T_divide | 24 | 69 | 0.003 | 0.003 | [8, 1, 1, 960] | 0.07 | 0.05 | 0.11 | 0.10 |
| T_fast_tanh | 9 | 9 | 0.008 | 0.008 | [4, 1024] | 0.43 | 0.43 | 0.53 | 0.97 |
| T_multiply | 105 | 150 | 8.92 | 8.92 | [4, 256, 4096] | 320.74 | 48.08 | 95.65 | 0.55 |
| T_relu | 300 | 1257 | 73.46 | 73.46 | [4, 144, 72, 8, 64] | 0.52 | 5.70 | 0.72 | 0.23 |
| T_softmax_norm | 27 | 27 | 0.016 | 0.016 | [4, 16, 256, 256] | 1.01 | 2.78 | 4.08 | 0.19 |
| T_tanh | 9 | 9 | 0.905 | 0.629 | [8, 96, 96, 3] | 5.55 | 33.48 | 50.55 | 0.16 |
| conv2d_winograd | 0 | 33 | NA | 0.868 | NA | NA | NA | NA | 0.93 |
| Hyperparameter | Value |
|---|---|
| Batch | 16, 32, 64, 256, 512 |
| Epoch | 100, 200, 400 |
| Learning Rate | |
| Attention Head (fine-tuning) | 6 |
| #Unrolling Steps for Attention Head | 2 |
| Optimizer | Adam |
| Primitive | Meaning |
|---|---|
| AN | Annotation Step |
| FU | Fuse Step |
| PR | Pragma Step |
| RE | Reorder Step |
| SP | Split Step |
| FSP | Follow Split Step |
| FFSP | Follow Fused Split Step |
| SA | Storage Align Step |
| CA | Compute At Step |
| CI | Compute In-line Step |
| CR | Compute Root Step |
| CHR | Cache Read Step |
| CHW | Cache Write Step |
| RF | Rfactor Step |
| H100 | A64FX | ||
|---|---|---|---|
| Sequence Length | Total Occurrence (%) | Sequence Length | Total Occurrence (%) |
| 37 | 46.41 | 21 | 20.89 |
| 36 | 12.59 | 20 | 20.21 |
| 39 | 5.56 | 16 | 11.06 |
| 38 | 5.00 | 17 | 8.91 |
| 32 | 4.62 | 19 | 7.29 |
| Target Hardware | Dataset | Size | XGBoost (Train-Time (sec)) | MLP (Train-Time (sec)) | LightGBM (Train-Time (sec)) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Within_Task | By_Task | By_Target | Within_Task | By_Task | By_Target | Within_Task | By_Task | By_Target | |||
| GPU | Baseline | 16 G | 1504 | 1440 | 454 | 3000 | 2434 | 3150 | 1574 | 780 | 4680 |
| Sampled | 9 G | 1406 | 1169 | 339 | 1968 | 1655 | 2464 | 1175 | 595 | 3637 | |
| CPU | Baseline | 11 G | 1490 | 1265 | 428 | 3143 | 2623 | 2043 | 1131 | 636 | 3946 |
| Sampled | 6.8 G | 905 | 780 | 354 | 2091 | 1672 | 1270 | 489 | 387 | 2435 | |
| Target Hardware | Baseline Dataset | Sampled Dataset | ||
|---|---|---|---|---|
| W/o Transfer Tuning | W/ Transfer Tuning | W/o Transfer Tuning | W/ Transfer Tuning | |
| A64FX (CPU) | 66.81 | 149.5 | 58.7 | 112.43 |
| Xeon (CPU) | 91.34 | 282.2 | 85.22 | 189.25 |
| A40 (GPU) | 627 | 416 | 599 | 175 |
| A100 (GPU) | 578 | 391 | 585 | 400 |
| H100 (GPU) | 128.12 | 67.30 | 93.42 | 54.25 |
| RTX2080 (GPU) | 18.67 | 27.68 | 17.37 | 841.74 |
| Target Hardware | Network | Without Transfer Tuning | With Transfer Tuning | ||
|---|---|---|---|---|---|
| Time-to-Tune | Mean Inference Time | Time-to-Tune | Mean Inference Time | ||
| CPU | Incpetion_v3 | 614 | 75.27 | 61 | 73.80 |
| MobileNet_v3 | 236 | 5.48 | 71 | 5.57 | |
| ResNet_50 | 128 | 11.93 | 86 | 12.12 | |
| GPU | Incpetion_v3 | 2510 | 28.72 | 191 | 28.73 |
| MobileNet_v3 | 1092 | 1.72 | 136 | 1.75 | |
| ResNet_50 | 817 | 3.79 | 226 | 3.78 | |
| Target Hardware | TenSet XGB | Our Tuner | ||
|---|---|---|---|---|
| Top-1 (%) | Top-5 (%) | Top-1 (%) | Top-5 (%) | |
| H100 | 83.94 | 95.81 | 85.67 | 96.08 |
| A64FX | 72.6 | 92.49 | 77.04 | 91.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verma, G.; Raskar, S.; Emani, M.; Chapman, B. Cross-Feature Transfer Learning for Efficient Tensor Program Generation. Appl. Sci. 2024, 14, 513. https://doi.org/10.3390/app14020513
Verma G, Raskar S, Emani M, Chapman B. Cross-Feature Transfer Learning for Efficient Tensor Program Generation. Applied Sciences. 2024; 14(2):513. https://doi.org/10.3390/app14020513
Chicago/Turabian StyleVerma, Gaurav, Siddhisanket Raskar, Murali Emani, and Barbara Chapman. 2024. "Cross-Feature Transfer Learning for Efficient Tensor Program Generation" Applied Sciences 14, no. 2: 513. https://doi.org/10.3390/app14020513