
Optimizing Data Processing: A Comparative Study of Big Data Platforms in Edge, Fog, and Cloud Layers


Abstract
:1. Introduction
- We conduct an extensive performance comparison of the edge-/fog-based processing of big data management frameworks against other cloud-based solutions. Our analysis covers the deployment of three different big data platforms based on three data processing applications.
- We present interesting findings that suggest that an edge- and fog-based big data management platform is a viable and promising option for applications where local processing power of local data is desired.
- We further explore the impact of the deployment of edge- and fog-based big data management frameworks and present recommendations regarding how to better use big data management frameworks for data science applications. In addition, we discuss the research challenges and opportunities in building a more practical edge-/fog-based big data management system.
2. Related Work
2.1. Capability of Resource-Constrained Devices
2.2. Improvement of Big Data Processing Platforms for Edge Devices
2.3. Comparative Studies of Big Data Processing Platforms
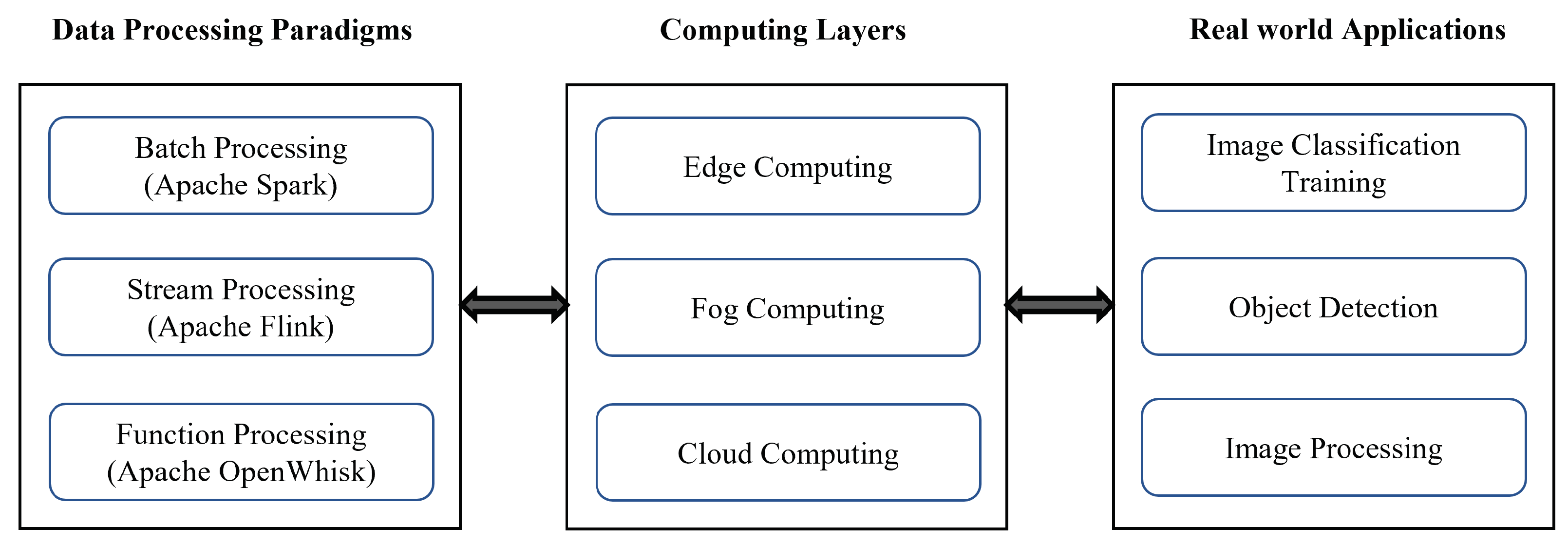
3. Target Data Processing and Computing
3.1. Three Data Processing Paradigms
3.1.1. Batch Processing
3.1.2. Stream Processing
3.1.3. Function Processing
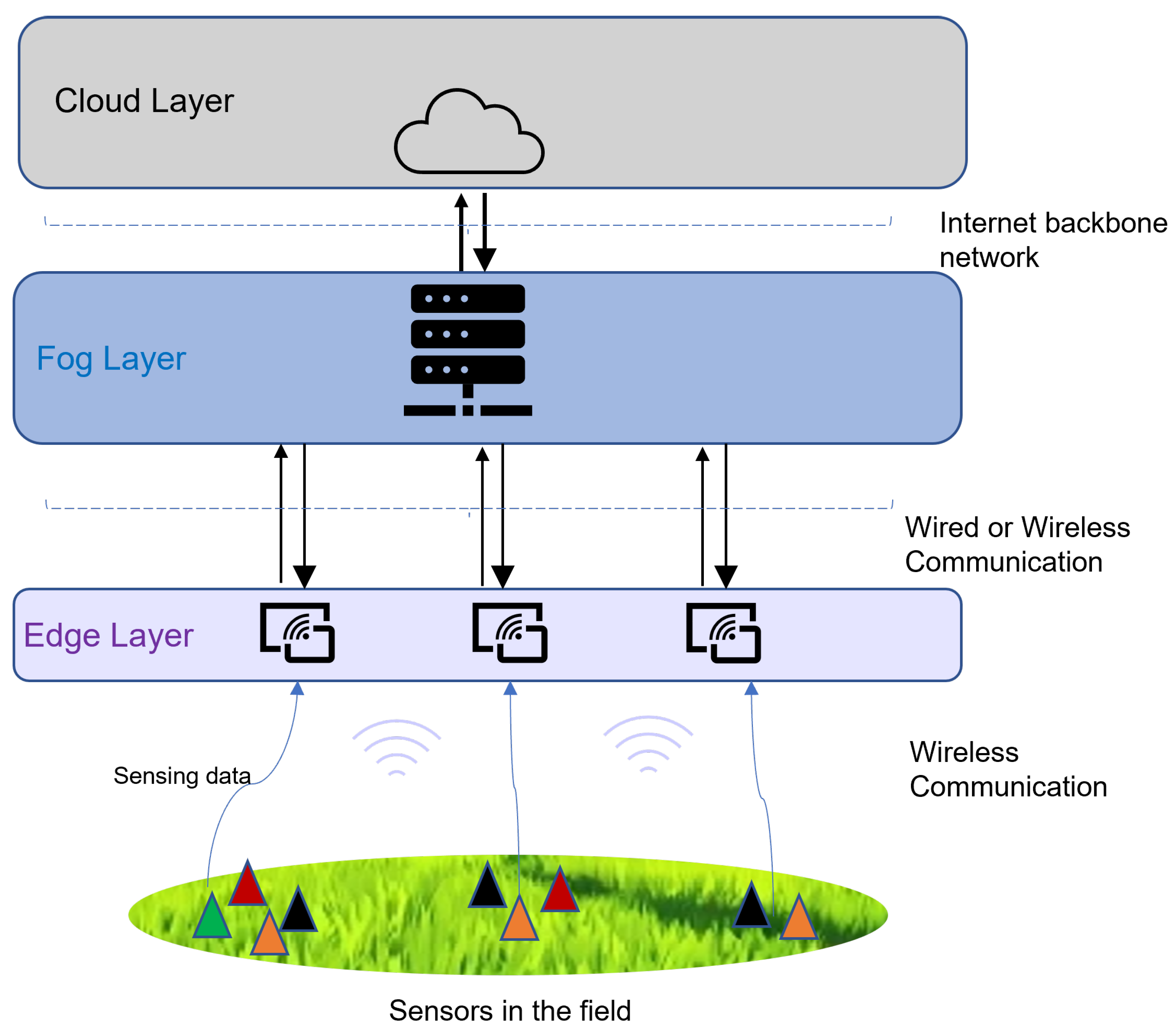
3.2. Computing in the Edge/Fog Layer
4. Experiments and Results
4.1. Experimental Methodology
4.1.1. Image Classification
4.1.2. Object Detection
4.1.3. Image Processing
4.1.4. Experimental Testbed Configuration
4.2. Results
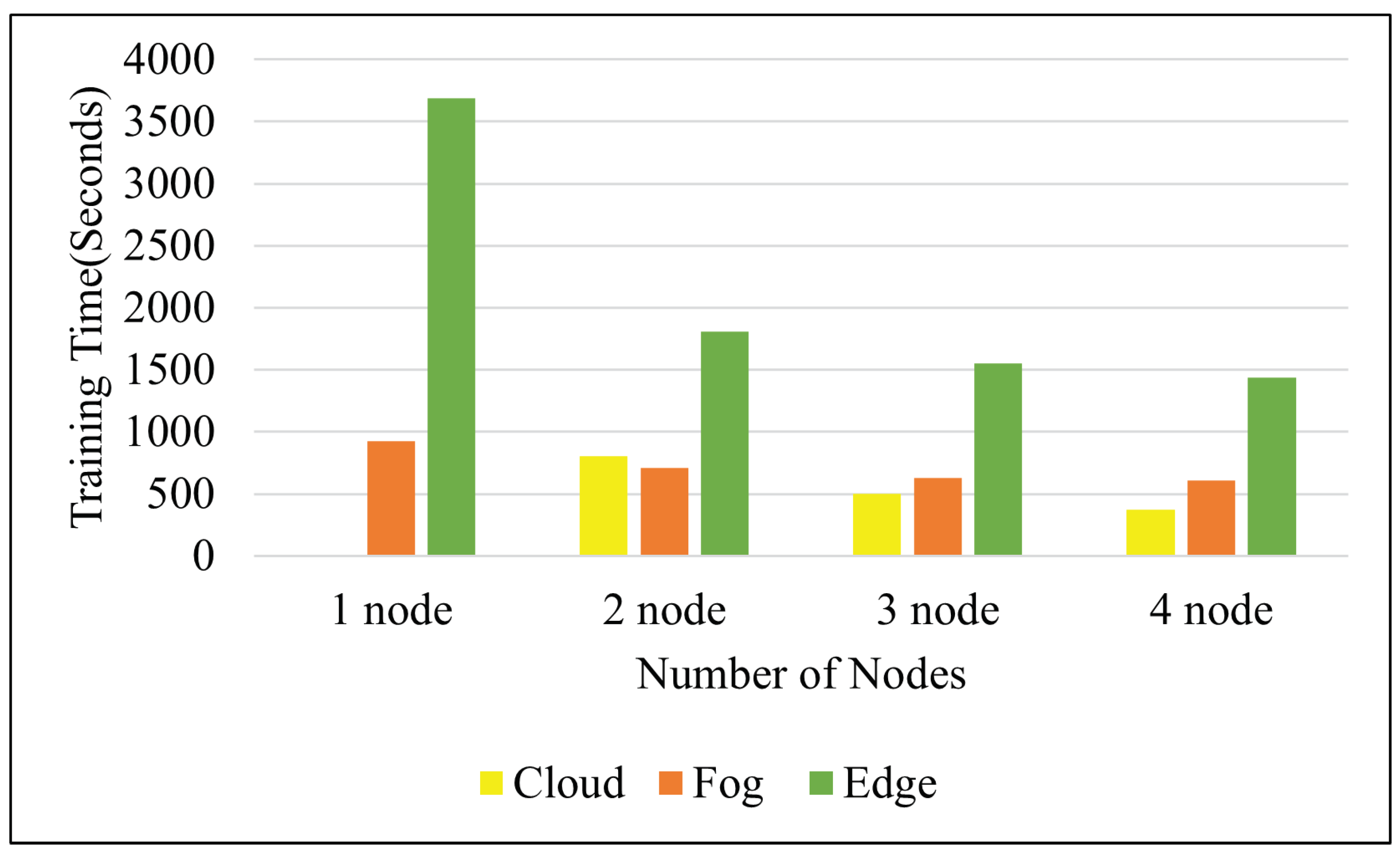
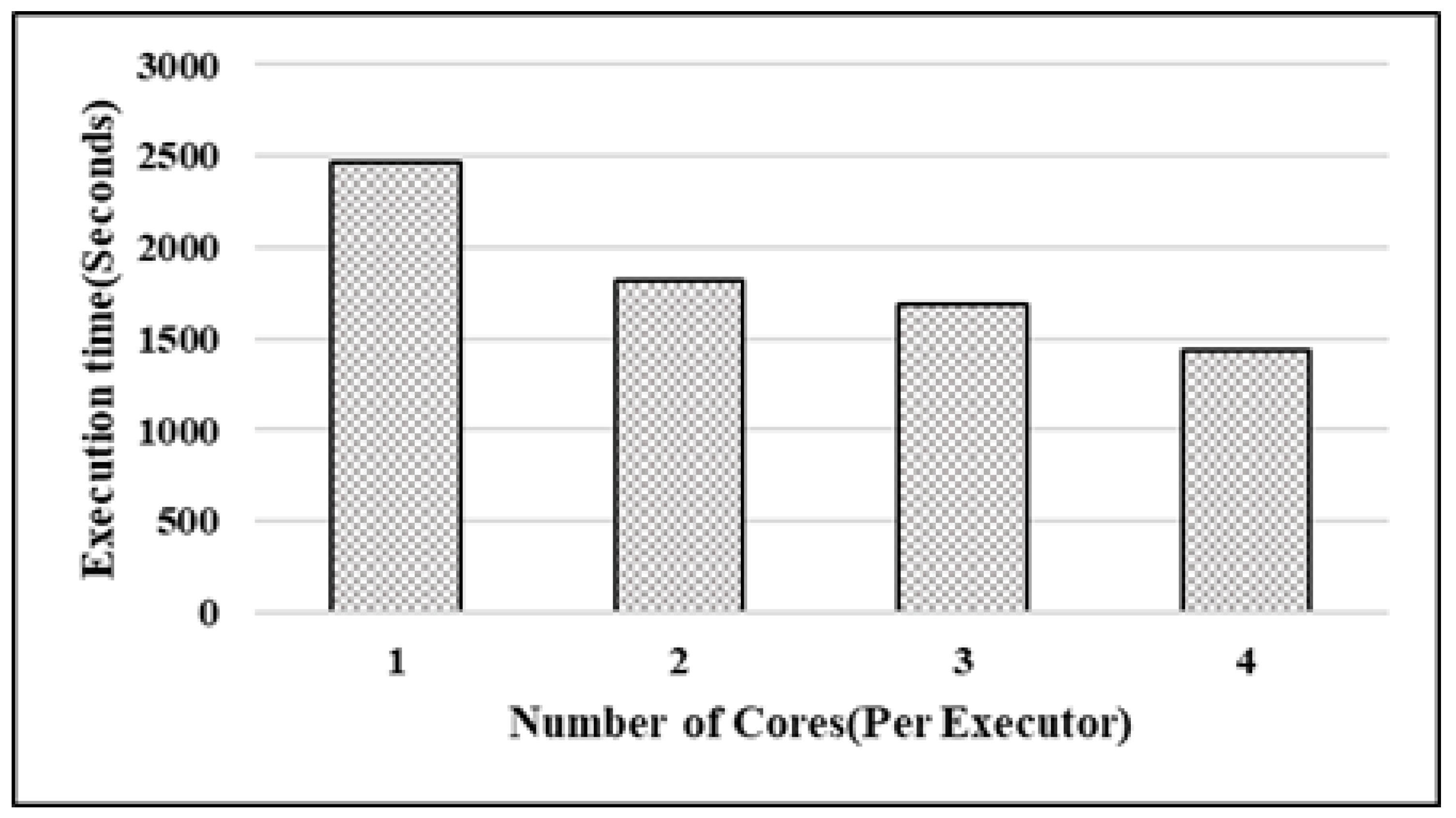
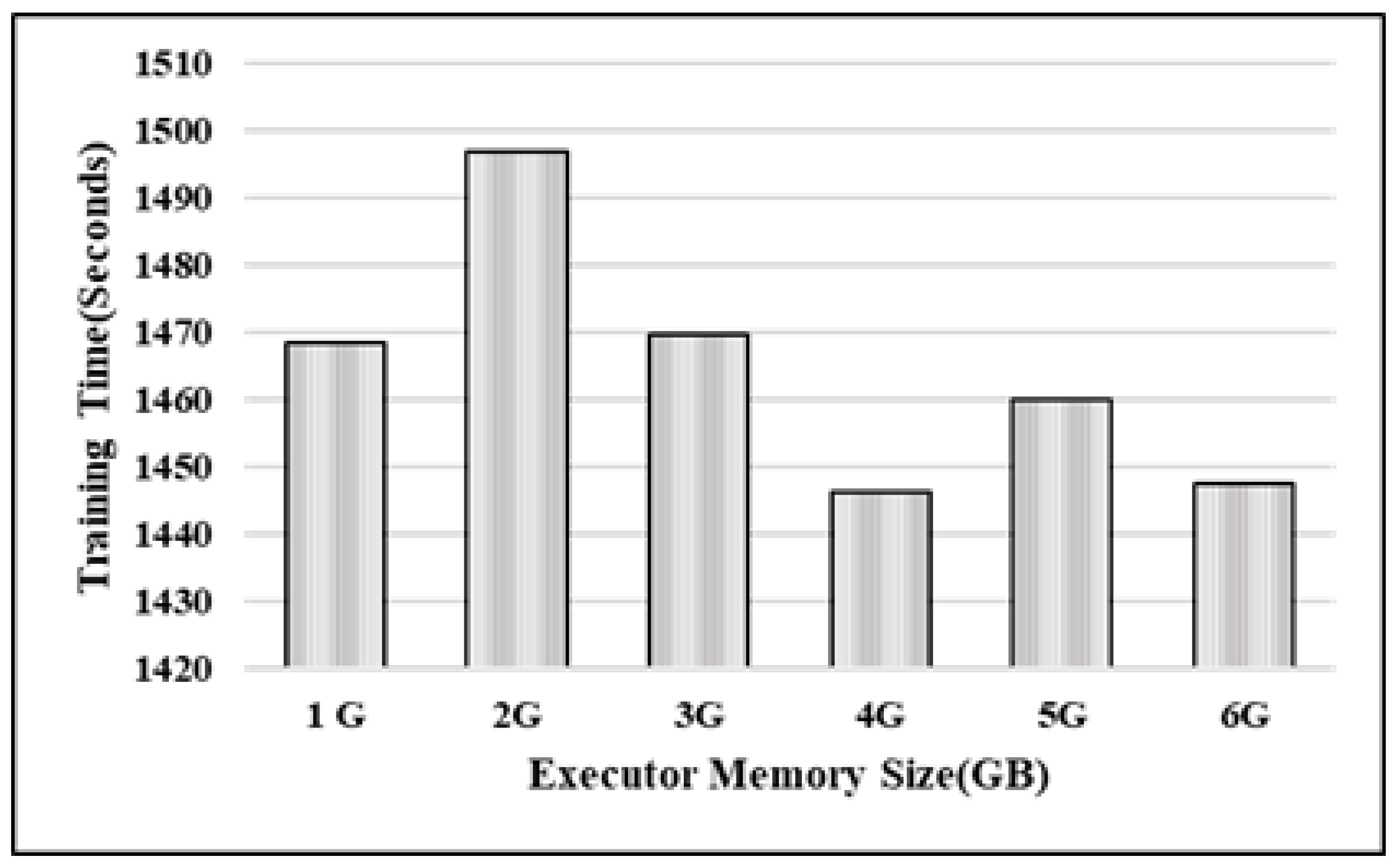
4.2.1. Image Classification as Batch Processing
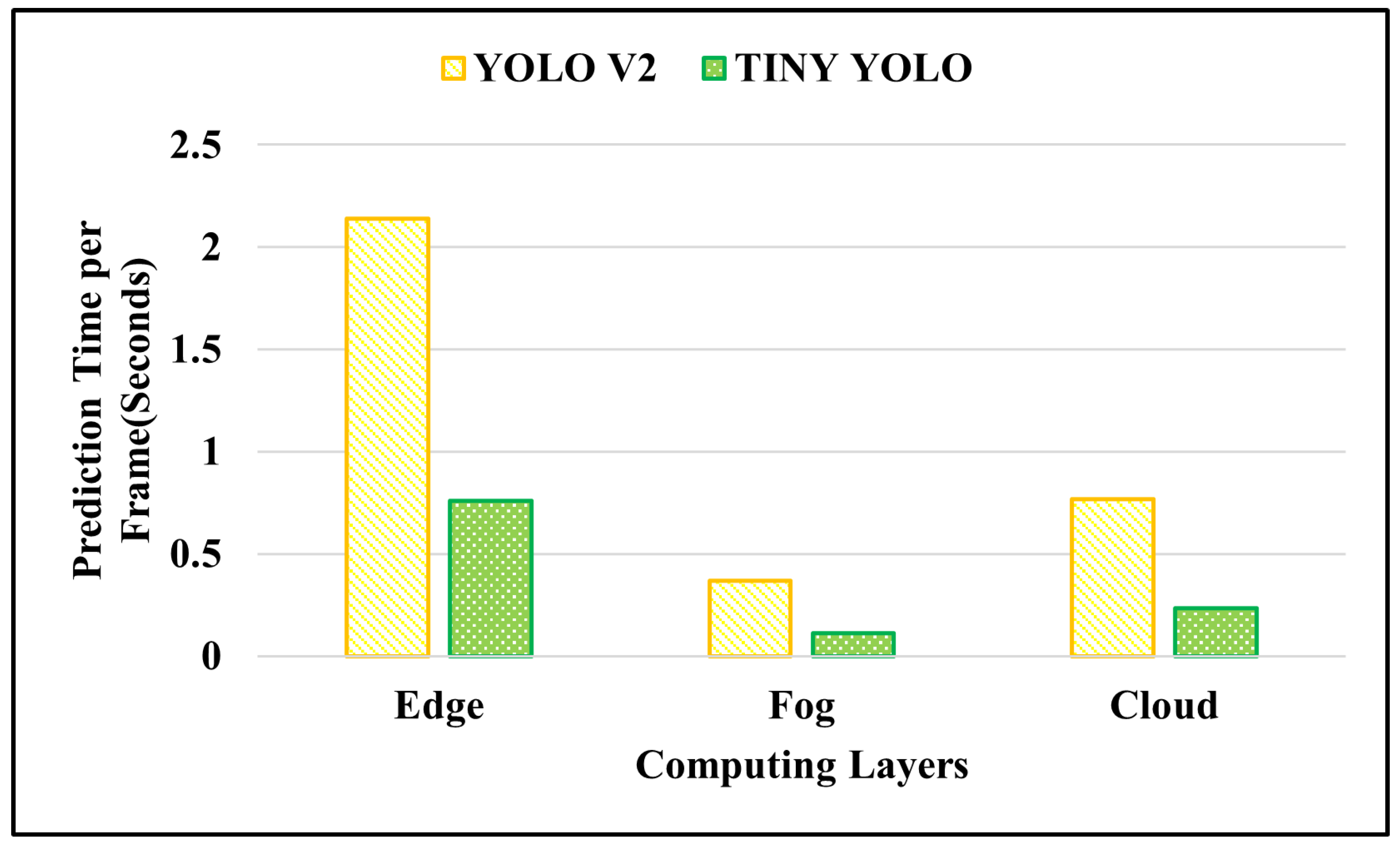
4.2.2. Object Detection as Stream Processing
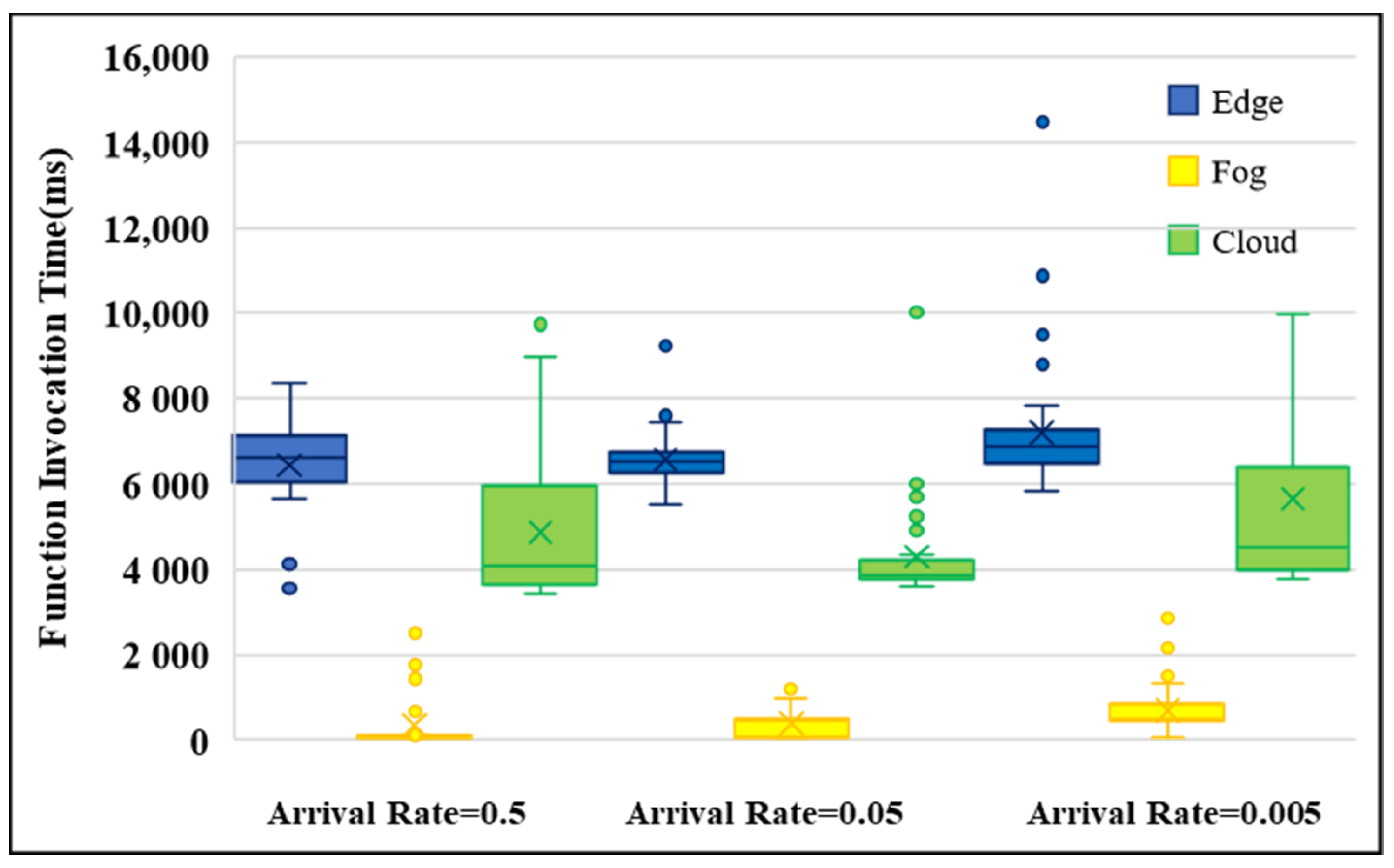
4.2.3. Image Processing as Function Processing
5. Discussion and Recommendations
5.1. Discussion
- Training of large and complex models: For batch processing, we can only leverage an MLP model, which encompasses the Spark machine learning library, because there are compatibility issues with edge-layer devices when using a distributed deep learning library on Spark, such as BigDL, Horovod, or TensorflowonSpark, while we can easily leverage them in the fog and cloud layers to exploit the collaborative power of nodes in the cluster for the training of large and complex models.
- Non-parallelizable tasks: Our target context and environment involve the utilization of locally available resources in a collaborative way to solve big data problems. Thus, the tasks needed to be parallelized and distributed among the cluster nodes. However, the tasks were not parallelizable and needed a single computing power source to run; these types of tasks are not suitable for the target environment.
- Cluster setup overhead: We argue that the setup of a big data processing cluster can be achieved with little effort, as long as it is placed within the local network, allowing for collaborative utilization of locally available devices.
5.2. Recommendations
- Deploying Spark in the edge computing layer can be a reasonable option if (a) the dataset size for training is small, (b) a long training time is tolerable for the business objective, and (c) only machine learning algorithms included in the Spark MLlib library are used. Our experiments reported in Section 4.2.1 were conducted under such a scenario and confirmed that training can be performed in the edge layer, achieving reasonable performance.
- When training large and complex models, it is necessary to use a distributed deep learning library on Spark, which is still not available or compatible with edge resources. Fog-layer Spark deployment is recommended for model training, where we can utilize the collaborative power of nodes in the cluster and a distributed deep learning library for speedup, as the cloud EMR cluster incurs high costs when sending large amounts of data to the cloud.
- Cloud EMR clusters are more suitable for the processing of extremely large datasets and when the throughput is important.
- Fog-layer-based stream processing achieves the best performance in terms of both the prediction time and detection rate. Although we can appropriately deploy the Flink streaming platform in the edge layer, the prediction time and detection rate are significantly low due to the size of the object detection model, which is hosted in resource-constrained devices.
- The advantage is pronounced only when multiple video streams are distributed to several nodes in the cluster and when real-time data analytics tasks that do not involve large computations in each individual task are distributed and parallelized among the nodes in the cluster.
- The fog computing layer is recommended for function processing, in which we observe the lowest latency for function invocations compared to the edge and cloud layers.
- Function processing is best-suited for applications with uniform and regular arrival patterns. Specifically, for the applications, the time between function invocations is not too long (i.e., function inactivity time), which can lead to cold-start latency, and the time between function invocations is not too short, which can lead to increased latency when serving multiple synchronous requests at the same time.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EMR | Elastic MapReduce |
| DL | Deep learning |
| IoT | Internet of Things |
| GPU | Graphical processing unit |
| AI | Artificial intelligence |
| MLP | Multilayer perceptron |
| YOLO | You Only Look Once |
| AWS | Amazon Web Services |
| LAN | Local area network |
| VM | Virtual machine |
| CPU | Central processing unit |
| Mem | Memory |
| MLLib | Machine learning library |
References
- Rani, S.; Chauhan, M.; Kataria, A.; Khang, A. IoT Equipped Intelligent Distributed Framework for Smart Healthcare Systems. In Towards the Integration of IoT, Cloud and Big Data: Services, Applications and Standards; Rishiwal, V., Kumar, P., Tomar, A., Malarvizhi Kumar, P., Eds.; Springer Nature Singapore: Singapore, 2023; pp. 97–114. [Google Scholar] [CrossRef]
- Sarker, I.H.; Khan, A.I.; Abushark, Y.B.; Alsolami, F. Internet of Things (IoT) Security Intelligence: A Comprehensive Overview, Machine Learning Solutions and Research Directions. Mob. Netw. Appl. 2023, 28, 296–312. [Google Scholar] [CrossRef]
- Mukati, N.; Namdev, N.; Dilip, R.; Hemalatha, N.; Dhiman, V.; Sahu, B. Healthcare Assistance to COVID-19 Patient using Internet of Things (IoT) Enabled Technologies. Mater. Today Proc. 2023, 80, 3777–3781. [Google Scholar] [CrossRef] [PubMed]
- The Top 10 IoT Segments in 2018—Based on 1,600 Real IoT Projects. Available online: https://iot-analytics.com/top-10-iot-segments-2018-real-iot-projects/ (accessed on 20 July 2023).
- Alhaidari, F.; Rahman, A.; Zagrouba, R. Cloud of Things: Architecture, applications and challenges. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 5957–5975. [Google Scholar] [CrossRef]
- Turukmane, A.V.; Pradeepa, M.; Reddy, K.S.S.; Suganthi, R.; Riyazuddin, Y.; Tallapragada, V.S. Smart farming using cloud-based Iot data analytics. Meas. Sens. 2023, 27, 100806. [Google Scholar] [CrossRef]
- Alam, T. Cloud-Based IoT Applications and Their Roles in Smart Cities. Smart Cities 2021, 4, 1196–1219. [Google Scholar] [CrossRef]
- Rajabion, L.; Shaltooki, A.A.; Taghikhah, M.; Ghasemi, A.; Badfar, A. Healthcare big data processing mechanisms: The role of cloud computing. Int. J. Inf. Manag. 2019, 49, 271–289. [Google Scholar] [CrossRef]
- Bonomi, F.; Milito, R.; Zhu, J.; Addepalli, S. Fog Computing and Its Role in the Internet of Things. In Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, MCC ’12, New York, NY, USA, 17 August 2012; pp. 13–16. [Google Scholar] [CrossRef]
- Johri, P.; Balu, V.; Jayaprakash, B.; Jain, A.; Thacker, C.; Kumari, A. Quality of service-based machine learning in fog computing networks for e-healthcare services with data storage system. Soft Comput. 2023. [Google Scholar] [CrossRef]
- Azizi, S.; Farzin, P.; Shojafar, M.; Rana, O. A scalable and flexible platform for service placement in multi-fog and multi-cloud environments. J. Supercomput. 2023. [Google Scholar] [CrossRef]
- Karatas, M.; Eriskin, L.; Deveci, M.; Pamucar, D.; Garg, H. Big Data for Healthcare Industry 4.0: Applications, challenges and future perspectives. Expert Syst. Appl. 2022, 200, 116912. [Google Scholar] [CrossRef]
- Agapito, G.; Cannataro, M. An Overview on the Challenges and Limitations Using Cloud Computing in Healthcare Corporations. Big Data Cogn. Comput. 2023, 7, 68. [Google Scholar] [CrossRef]
- Quy, V.K.; Hau, N.V.; Anh, D.V.; Ngoc, L.A. Smart healthcare IoT applications based on fog computing: Architecture, applications and challenges. Complex Intell. Syst. 2022, 8, 3805–3815. [Google Scholar] [CrossRef] [PubMed]
- Yi, S.; Hao, Z.; Qin, Z.; Li, Q. Fog Computing: Platform and Applications. In Proceedings of the 2015 Third IEEE Workshop on Hot Topics in Web Systems and Technologies (HotWeb), Washington, DC, USA, 12–13 November 2015; pp. 73–78. [Google Scholar] [CrossRef]
- Muniswamaiah, M.; Agerwala, T.; Tappert, C.C. Fog Computing and the Internet of Things (IoT): A Review. In Proceedings of the 2021 8th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2021 7th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Washington, DC, USA, 26–28 June 2021; pp. 10–12. [Google Scholar] [CrossRef]
- Saini, K.; Kalra, S.; Sood, S.K. An Integrated Framework for Smart Earthquake Prediction: IoT, Fog, and Cloud Computing. J. Grid Comput. 2022, 20, 17. [Google Scholar] [CrossRef]
- Verma, P.; Tiwari, R.; Hong, W.C.; Upadhyay, S.; Yeh, Y.H. FETCH: A Deep Learning-Based Fog Computing and IoT Integrated Environment for Healthcare Monitoring and Diagnosis. IEEE Access 2022, 10, 12548–12563. [Google Scholar] [CrossRef]
- Alazzam, H.; AbuAlghanam, O.; Sharieh, A. Best path in mountain environment based on parallel A* algorithm and Apache Spark. J. Supercomput. 2022, 78, 5075–5094. [Google Scholar] [CrossRef]
- Bagui, S.; Walauskis, M.; DeRush, R.; Praviset, H.; Boucugnani, S. Spark Configurations to Optimize Decision Tree Classification on UNSW-NB15. Big Data Cogn. Comput. 2022, 6, 38. [Google Scholar] [CrossRef]
- Chebbi, I.; Mellouli, N.; Farah, I.R.; Lamolle, M. Big Remote Sensing Image Classification Based on Deep Learning Extraction Features and Distributed Spark Frameworks. Big Data Cogn. Comput. 2021, 5, 21. [Google Scholar] [CrossRef]
- Ed-daoudy, A.; Maalmi, K.; El Ouaazizi, A. A scalable and real-time system for disease prediction using big data processing. Multimed. Tools Appl. 2023, 82, 30405–30434. [Google Scholar] [CrossRef]
- Kumari, A.; Behera, R.K.; Sahoo, B.; Misra, S. Role of Serverless Computing in Healthcare Systems: Case Studies. In Proceedings of the Computational Science and Its Applications—ICCSA 2022 Workshops; Gervasi, O., Murgante, B., Misra, S., Rocha, A.M.A.C., Garau, C., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 123–134. [Google Scholar]
- Bac, T.P.; Tran, M.N.; Kim, Y. Serverless Computing Approach for Deploying Machine Learning Applications in Edge Layer. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Republic of Korea, 12–15 January 2022; pp. 396–401. [Google Scholar] [CrossRef]
- Kong, L.; Tan, J.; Huang, J.; Chen, G.; Wang, S.; Jin, X.; Zeng, P.; Khan, M.; Das, S.K. Edge-Computing-Driven Internet of Things: A Survey. ACM Comput. Surv. 2022, 55, 1–44. [Google Scholar] [CrossRef]
- Singh, R.; Gill, S.S. Edge AI: A survey. Internet Things Cyber-Phys. Syst. 2023, 3, 71–92. [Google Scholar] [CrossRef]
- Apache Spark. Available online: https://spark.apache.org/ (accessed on 8 August 2023).
- Apache Flink. Available online: https://flink.apache.org/ (accessed on 8 August 2023).
- Apache OpenWhisk. Available online: https://openwhisk.apache.org/ (accessed on 8 August 2023).
- Baresi, L.; Filgueira Mendonça, D. Towards a Serverless Platform for Edge Computing. In Proceedings of the 2019 IEEE International Conference on Fog Computing (ICFC), Prague, Czech Republic, 24–26 June 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Xu, J.; Palanisamy, B.; Wang, Q.; Ludwig, H.; Gopisetty, S. Amnis: Optimized stream processing for edge computing. J. Parallel Distrib. Comput. 2022, 160, 49–64. [Google Scholar] [CrossRef]
- Karimov, J.; Rabl, T.; Katsifodimos, A.; Samarev, R.; Heiskanen, H.; Markl, V. Benchmarking Distributed Stream Data Processing Systems. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1507–1518. [Google Scholar] [CrossRef]
- Tekdogan, T.; Cakmak, A. Benchmarking Apache Spark and Hadoop MapReduce on Big Data Classification. In Proceedings of the 2021 5th International Conference on Cloud and Big Data Computing, ICCBDC ’21, New York, NY, USA, 17–18 March 2021; pp. 15–20. [Google Scholar] [CrossRef]
- Veiga, J.; Expósito, R.R.; Pardo, X.C.; Taboada, G.L.; Tourifio, J. Performance evaluation of big data frameworks for large-scale data analytics. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 424–431. [Google Scholar] [CrossRef]
- Grambow, M.; Pfandzelter, T.; Burchard, L.; Schubert, C.; Zhao, M.; Bermbach, D. BeFaaS: An Application-Centric Benchmarking Framework for FaaS Platforms. In Proceedings of the 2021 IEEE International Conference on Cloud Engineering (IC2E), San Francisco, CA, USA, 4–8 October 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Yu, T.; Liu, Q.; Du, D.; Xia, Y.; Zang, B.; Lu, Z.; Yang, P.; Qin, C.; Chen, H. Characterizing Serverless Platforms with Serverlessbench. In Proceedings of the 11th ACM Symposium on Cloud Computing, SoCC ’20, New York, NY, USA, 19–21 October 2020; pp. 30–44. [Google Scholar] [CrossRef]
- Baller, S.P.; Jindal, A.; Chadha, M.; Gerndt, M. DeepEdgeBench: Benchmarking Deep Neural Networks on Edge Devices. In Proceedings of the 2021 IEEE International Conference on Cloud Engineering (IC2E), San Francisco, CA, USA, 4–8 October 2021; pp. 20–30. [Google Scholar] [CrossRef]
- Feng, H.; Mu, G.; Zhong, S.; Zhang, P.; Yuan, T. Benchmark Analysis of YOLO Performance on Edge Intelligence Devices. Cryptography 2022, 6, 16. [Google Scholar] [CrossRef]
- Hao, C.; Dotzel, J.; Xiong, J.; Benini, L.; Zhang, Z.; Chen, D. Enabling Design Methodologies and Future Trends for Edge AI: Specialization and Codesign. IEEE Des. Test 2021, 38, 7–26. [Google Scholar] [CrossRef]
- Rausch, T.; Hummer, W.; Muthusamy, V.; Rashed, A.; Dustdar, S. Towards a Serverless Platform for Edge AI. In Proceedings of the 2nd USENIX Workshop on Hot Topics in Edge Computing (HotEdge 19), Renton, WA, USA, 9 July 2019. [Google Scholar]
- Pfandzelter, T.; Bermbach, D. tinyFaaS: A Lightweight FaaS Platform for Edge Environments. In Proceedings of the 2020 IEEE International Conference on Fog Computing (ICFC), Sydney, NSW, Australia, 21–24 April 2020; pp. 17–24. [Google Scholar] [CrossRef]
- Smith, C.P.; Jindal, A.; Chadha, M.; Gerndt, M.; Benedict, S. FaDO: FaaS Functions and Data Orchestrator for Multiple Serverless Edge-Cloud Clusters. In Proceedings of the 2022 IEEE 6th International Conference on Fog and Edge Computing (ICFEC), Messina, Italy, 16–19 May 2022; pp. 17–25. [Google Scholar] [CrossRef]
- Großmann, M.; Ioannidis, C.; Le, D.T. Applicability of Serverless Computing in Fog Computing Environments for IoT Scenarios. In Proceedings of the 12th IEEE/ACM International Conference on Utility and Cloud Computing Companion, UCC ’19 Companion, Auckland, New Zealand, 2–5 December 2019; pp. 29–34. [Google Scholar] [CrossRef]
- Tzenetopoulos, A.; Apostolakis, E.; Tzomaka, A.; Papakostopoulos, C.; Stavrakakis, K.; Katsaragakis, M.; Oroutzoglou, I.; Masouros, D.; Xydis, S.; Soudris, D. FaaS and Curious: Performance Implications of Serverless Functions on Edge Computing Platforms. In Proceedings of the High Performance Computing: ISC High Performance Digital 2021 International Workshops, Frankfurt am Main, Germany, June 24–July 2, 2021, Revised Selected Papers 36; Jagode, H., Anzt, H., Ltaief, H., Luszczek, P., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 428–438. [Google Scholar] [CrossRef]
- Ab Wahab, M.N.; Nazir, A.; Zhen Ren, A.T.; Mohd Noor, M.H.; Akbar, M.F.; Mohamed, A.S.A. Efficientnet-Lite and Hybrid CNN-KNN Implementation for Facial Expression Recognition on Raspberry Pi. IEEE Access 2021, 9, 134065–134080. [Google Scholar] [CrossRef]
- James, N.; Ong, L.Y.; Leow, M.C. Exploring Distributed Deep Learning Inference Using Raspberry Pi Spark Cluster. Future Internet 2022, 14, 220. [Google Scholar] [CrossRef]
- Curtin, B.H.; Matthews, S.J. Deep Learning for Inexpensive Image Classification of Wildlife on the Raspberry Pi. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 82–87. [Google Scholar] [CrossRef]
- Apache Hadoop. Available online: https://hadoop.apache.org/ (accessed on 8 August 2023).
- Kimovski, D.; Mathá, R.; Hammer, J.; Mehran, N.; Hellwagner, H.; Prodan, R. Cloud, Fog, or Edge: Where to Compute? IEEE Internet Comput. 2021, 25, 30–36. [Google Scholar] [CrossRef]
- Lee, E.; Oh, H.; Park, D. Big Data Processing on Single Board Computer Clusters: Exploring Challenges and Possibilities. IEEE Access 2021, 9, 142551–142565. [Google Scholar] [CrossRef]
- Pfandzelter, T.; Bermbach, D. IoT Data Processing in the Fog: Functions, Streams, or Batch Processing? In Proceedings of the 2019 IEEE International Conference on Fog Computing (ICFC), Prague, Czech Republic, 24–26 June 2019; pp. 201–206. [Google Scholar] [CrossRef]
- Salloum, S.; Dautov, R.; Chen, X.; Peng, P.X.; Huang, J.Z. Big data analytics on Apache Spark. Int. J. Data Sci. Anal. 2016, 1, 145–164. [Google Scholar] [CrossRef]
- Markovic, A.; Kolovos, D.; Soares Indrusiak, L. Distributed Data Locality-Aware Job Allocation. In Proceedings of the SC ’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, SC-W ’23, New York, NY, USA, 12–17 November 2023; pp. 2089–2096. [Google Scholar] [CrossRef]
- Apache Storm. Available online: https://storm.apache.org/ (accessed on 8 August 2023).
- Apache Kafka. Available online: https://kafka.apache.org/ (accessed on 8 August 2023).
- Carbone, P.; Ewen, S.; Fóra, G.; Haridi, S.; Richter, S.; Tzoumas, K. State Management in Apache Flink®: Consistent Stateful Distributed Stream Processing. Proc. VLDB Endow. 2017, 10, 1718–1729. [Google Scholar] [CrossRef]
- OpenFaaS. Available online: https://www.openfaas.com/ (accessed on 8 August 2023).
- Knative. Available online: https://knative.dev/docs/ (accessed on 8 August 2023).
- Javed, H.; Toosi, A.N.; Aslanpour, M.S. Serverless Platforms on the Edge: A Performance Analysis. In New Frontiers in Cloud Computing and Internet of Things; Buyya, R., Garg, L., Fortino, G., Misra, S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 165–184. [Google Scholar] [CrossRef]
- BigDL. Available online: https://github.com/intel-analytics/BigDL (accessed on 8 November 2023).
- Tensor Flow on Spark. Available online: https://github.com/yahoo/TensorFlowOnSpark (accessed on 8 November 2023).
- Grover, D.; Toghi, B. MNIST Dataset Classification Utilizing k-NN Classifier with Modified Sliding-Window Metric. In Advances in Computer Vision: Proceedings of the 2019 Computer Vision Conference (CVC); Arai, K., Kapoor, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 21, pp. 583–591. [Google Scholar]
- Cheng, K.; Tahir, R.; Eric, L.K.; Li, M. An analysis of generative adversarial networks and variants for image synthesis on MNIST dataset. Multimed. Tools Appl. 2020, 79, 13725–13752. [Google Scholar] [CrossRef]
- Japa, L.; Serqueira, M.; Mendonça, I.; Aritsugi, M.; Bezerra, E.; González, P.H. A Population-Based Hybrid Approach for Hyperparameter Optimization of Neural Networks. IEEE Access 2023, 11, 50752–50768. [Google Scholar] [CrossRef]
- Assefi, M.; Behravesh, E.; Liu, G.; Tafti, A.P. Big data machine learning using apache spark MLlib. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3492–3498. [Google Scholar] [CrossRef]
- Object Detection on Apache Flink. Available online: https://github.com/mk-hasan/Flink-Kuberenets (accessed on 24 August 2023).
- Lin, J.; Liu, D.; Li, H.; Wu, F. M-LVC: Multiple Frames Prediction for Learned Video Compression. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3543–3551. [Google Scholar] [CrossRef]
- Ha, T.W.; Kang, J.M.; Kim, M.H. Real-Time Deep Learning-Based Anomaly Detection Approach for Multivariate Data Streams with Apache Flink. In Proceedings of the ICWE 2021 Workshops; Bakaev, M., Ko, I.Y., Mrissa, M., Pautasso, C., Srivastava, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 39–49. [Google Scholar]
- AWS Samples. Available online: https://github.com/aws-samples/lambda-refarch-imagerecognition/ (accessed on 3 August 2023).
- Ali, A.; Pinciroli, R.; Yan, F.; Smirni, E. Optimizing Inference Serving on Serverless Platforms. Proc. VLDB Endow. 2022, 15, 2071–2084. [Google Scholar] [CrossRef]
- Shwe, T.; Aritsugi, M. Towards an edge-fog-cloud serverless continuum for IoT data processing pipeline. In Proceedings of the 2024 IEEE International Conference on Big Data and Smart Computing (BigComp), Bangkok, Thailand, 18–21 February 2024. [Google Scholar]
- Lean OpenWhisk. Available online: https://github.com/kpavel/incubator-openwhisk/tree/lean (accessed on 1 August 2023).
- Ahmed, N.; Barczak, A.; Susnjak, T.; Rashid, M. A Comprehensive Performance Analysis of Apache Hadoop and Apache Spark for Large Scale Data Sets Using HiBench. J. Big Data 2020, 7, 110. [Google Scholar] [CrossRef]
- Mostafaeipour, A.; Jahangard, A.; Ahmadi, M.; Arockia Dhanraj, J. Investigating the performance of Hadoop and Spark platforms on machine learning algorithms. J. Supercomput. 2021, 77, 1273–1300. [Google Scholar] [CrossRef]
- Roy, R.B.; Patel, T.; Tiwari, D. IceBreaker: Warming Serverless Functions Better with Heterogeneity. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’22, Lausanne, Switzerland, 28 February–4 March 2022; pp. 753–767. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, L.; Li, Y.; Zhang, H.; Li, J.; Zhao, M.; Chen, X.; Li, K. INFless: A Native Serverless System for Low-Latency, High-Throughput Inference. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’22, Lausanne, Switzerland, 28 February–4 March 2022; pp. 768–781. [Google Scholar] [CrossRef]
- Liu, X.; Wen, J.; Chen, Z.; Li, D.; Chen, J.; Liu, Y.; Wang, H.; Jin, X. FaaSLight: General Application-Level Cold-Start Latency Optimization for Function-as-a-Service in Serverless Computing. ACM Trans. Softw. Eng. Methodol. 2023, 32, 1–29. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Processing Paradigm | Edge | Fog | Cloud |
|---|---|---|---|
| Batch Processing | Raspberry Pi (four-node cluster; CPU: four cores/node; Mem: 8 GB/node; Spark 3.3.1) | Ubuntu VM (four-node cluster; CPU: four cores/node; Mem: 8 GB/node; Spark 3.3.1) | Amazon EMR (four-node cluster; c5a.xlarge type; CPU: four cores/node; Mem: 7.5 GB/node; Spark 3.3.2) |
| Stream Processing | Raspberry Pi (four-node cluster; CPU: four cores/node; Mem: 8 GB/node; Flink 1.16.0) | Ubuntu VM (four-node cluster; CPU: four cores/node; Mem: 8 GB/node; Flink 1.16.0) | Amazon EMR (four-node cluster; c3.2xlarge type; CPU: 8 cores/node; Mem: 15 GB/node; Flink 1.17.0) |
| Function Processing | Raspberry Pi 4 (standalone; CPU: four cores; Mem: 8 GB; Lean OpenWhisk [72]) | Ubuntu VM (standalone; CPU: four cores; Mem: 8 GB; OpenWhisk 1.0.0) | AWS Lambda |
| Computing Layer | Detection Rate |
|---|---|
| Edge | 4.49 |
| Fog | 35.50 |
| Cloud | 16.72 |
| Description | Edge | Fog |
|---|---|---|
| CPU | <1% | <1% |
| Memory | 3.13% | 23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shwe, T.; Aritsugi, M. Optimizing Data Processing: A Comparative Study of Big Data Platforms in Edge, Fog, and Cloud Layers. Appl. Sci. 2024, 14, 452. https://doi.org/10.3390/app14010452
Shwe T, Aritsugi M. Optimizing Data Processing: A Comparative Study of Big Data Platforms in Edge, Fog, and Cloud Layers. Applied Sciences. 2024; 14(1):452. https://doi.org/10.3390/app14010452
Chicago/Turabian StyleShwe, Thanda, and Masayoshi Aritsugi. 2024. "Optimizing Data Processing: A Comparative Study of Big Data Platforms in Edge, Fog, and Cloud Layers" Applied Sciences 14, no. 1: 452. https://doi.org/10.3390/app14010452