1. Introduction
The last decade has witnessed GPUs acting as a rising star in a myriad of domains, including scientific computing, big data analysis and machine learning. Programmers writing such workloads tend to offload performance-critical calculations to the GPUs [
1,
2,
3] while leaving the CPUs only for control flow and inter-process communication management. These operations include general matrix multiplication (GEMM) and Convolution (Conv); both take a large portion of the layers in recent eye-catching big data and deep learning applications. Offloading GEMM and Conv operations to GPUs could obtain ten- to thousand-fold performance increases.
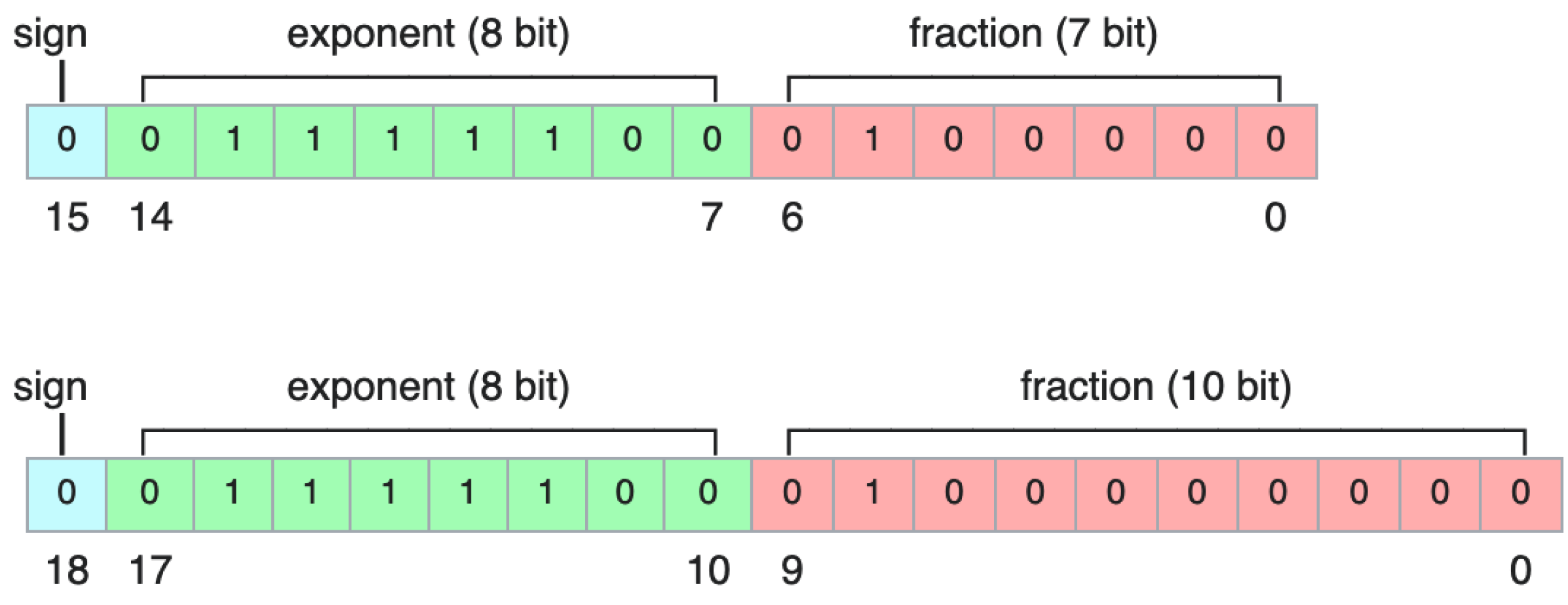
In certain scenarios, there is no need to use data types with a wider bitwidth in calculations. For example, in the first few loops of iterative numeric algorithms like the Euler method, it is unnecessary to use high-precision data in calculations due to the existence of a large difference between the current numeric solution and the real target. In addition, for some inference tasks like classification, the final goal is to distinguish the category corresponding to the maximal value in the score vector. Thus, using high-precision data types like
fp64 or
fp32 would be wasteful for both off-chip and on-chip resources including memory bandwidth, registers and ALU usage. Harnessing mixed-precision data (
Figure 1) brings the opportunities of deploying real-time tasks on resource-limited devices [
4,
5].
Recently, quantized neural network models have been proposed to reduce the model size and required computation, thus improving the overall performance. From an architectural perspective, NVIDIA has embedded a transformer engine into its latest data center, the
Hopper GPU architecture [
6], to accelerate emerging transformer calculations for language models. In addition, special floating point formats like
tf16 and
tf32 (also called
e8m7 and
e8m10, respectively, where
tf stands for tensor format) are designed to boost the quantized NN workloads as they require much lower transferring bandwidths, registers and on-chip memory resources for storage while achieving negligible errors compared with the traditional IEEE-754 version. Exploiting these new data formats in some language model workloads like BERT has achieved significant performance increases in recent NVIDIA GPUs [
7].
To meet these emerging requirements for both the algorithm design and the workload characteristics, hardware vendors like NVIDIA and AMD both integrate application-specific integrated circuits (ASICs) into their latest products. NVIDIA announced their first-generation Tensor Core (TC) together with the release of the
Volta data center GPU architecture in 2017 and then revised the TC over several generations. AMD followed a technical route, naming their analogous component the Matrix Core (MC) in their MI100 series data center GPU. This algorithm–architecture co-design marked a huge success with the fact that mainstream deep learning frameworks like PyTorch have embraced these designs with the help of vendor-provided high-performance libraries like cuDNN, cuBLAS and MIOpen [
8]. Other vendors like Google and Tesla have also presented proprietary ASIC accelerators like TPU [
9] and Dojo [
10], aiming to accelerate the quantized workloads by exploiting special hardware components to calculate low-precision types of data elements.
However, most of these vendor libraries are proprietary. NVIDIA makes them opaque to advance the first-party software ecosystem. Although AMD has made their implementation of MIOpen and the corresponding
rocWMMA (Wave-level Matrix Multiply Accumulation) for the HIP software stack open-source [
11], it is not well studied yet, since matrix cores are only available on its CDNA architecture realized in MI100 and later products. When using APIs from opaque libraries, the runtime will automatically select the “best” algorithm based on the user-provided problem size and data layout. This automatic mechanism works well in most cases, but outliers still exist whereby the chosen configuration is not suitable for the user’s input. For instance, in big data analysis and processing, the programmer needs various custom kernels to handle incoming data streams and extract key features from them; to this end, one may wish to have a library containing kernels with higher customizability while maintaining performance with minimal programming and maintenance efforts.
Realizing the need for a community-driven high-performance GPU kernel library with user customizability, NVIDIA announced CUTLASS, an open-source codebase to provide concepts, primitives, kernels and programming models on top of CUDA. CUTLASS is a template C++ library targeting GEMM, SpGEMM (sparse GEMM) and convolution kernels that are widely used in both AI and HPC applications. With the C++ template, CUTLASS implements zero-cost abstraction and compile-time polymorphism that supports varying data types. More importantly, CUTLASS offers a system of concepts, interfaces and approaches that allows users to easily split and distribute work items into different granularities of resource organizations.
Figure 2 demonstrates a representative workflow pipeline in a CUTLASS GEMM kernel. Initially, the whole problem is parallelized by splitting the output matrix into multiple tiles. Each CTA (Cooperative Thread Array, also known as a
thread block) is responsible for loading, calculating and then storing each tile in the output matrix. Inside each CTA, 32 consecutive threads are organized as
warps and get executed on the
SM (Streaming Multiprocessor) in the lock-step fashion. In each iteration, each warp will try to load a tile of input matrix elements from global memory to shared memory, and synchronize at the CTA level to ensure all required data in current iteration are ready in shared memory. Then, the required CTA data in shared memory are further split into warp-level tiles to load into per-thread registers for calculation. Right after the data preparation is complete, the result tile will be computed depending on which hardware units are used (traditional CUDA Core for the SIMT fashion, Tensor Core for WMMA fashion). When the primary calculation is accomplished, some extra steps including scaling, clamping or rounding need to be conducted (called
epilogue) before the output elements are stored back to global memory. As we can see, the whole pipeline including work item distribution and parallel execution is hierarchically organized corresponding to the hardware architecture, which is the core design of CUTLASS and other GPU-based accelerating algorithms.
2. Materials and Methods
2.1. GPU Architecture and Programming Model
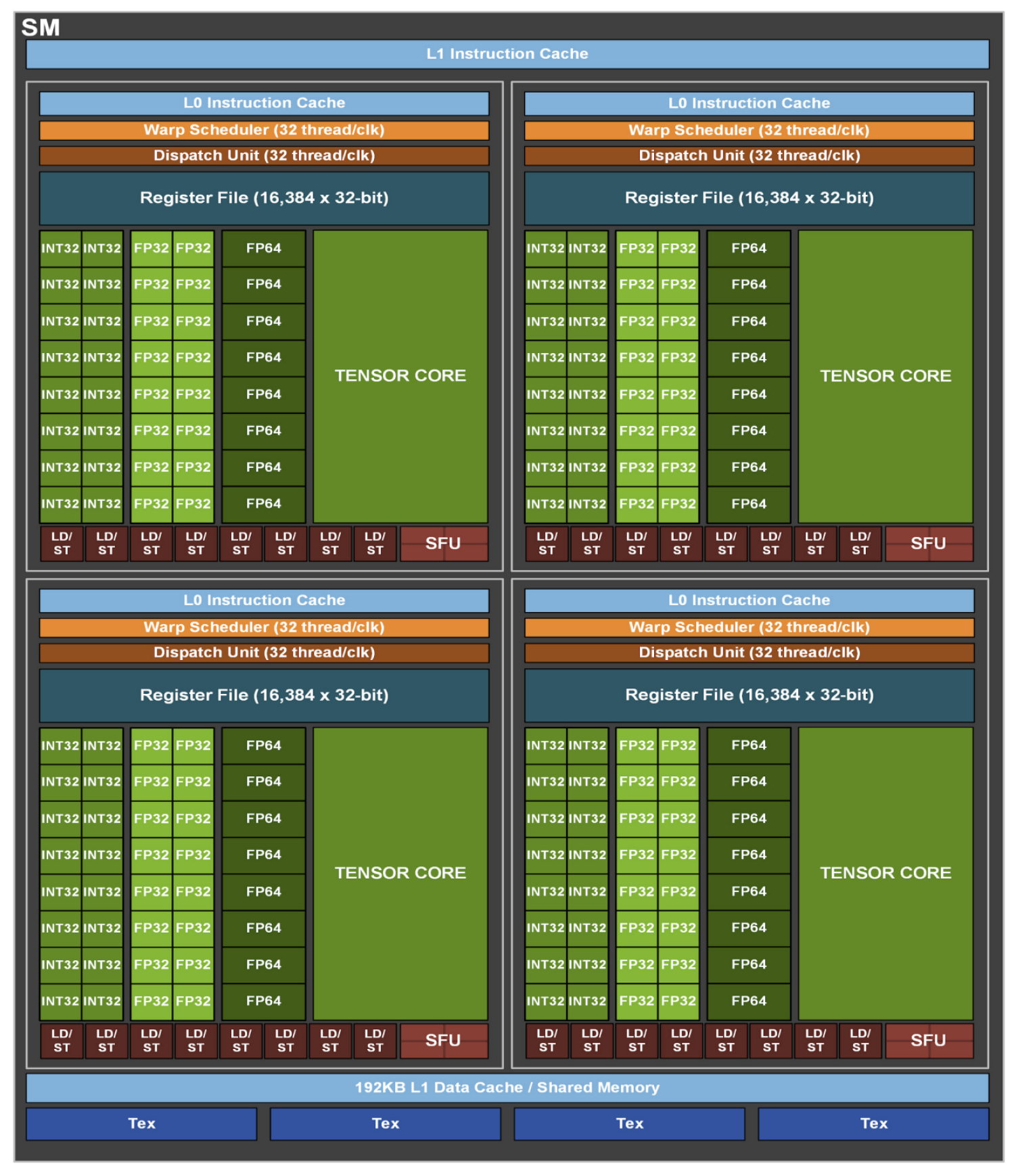
The concept of a general purpose GPU was introduced in 2006.
Figure 3 illustrates the SM architecture in NVIDIA’s
Ampere GPU. As we can see, each SM contains four sub-processors, with integer and floating point units (CUDA Cores) inside. Besides, as aforementioned, NVIDIA has added Tensor Cores into the SM since the
Volta generation. CTAs are scheduled to sub-processors for execution based on the granularity of warp (32 consecutive threads in CUDA). Instructions from the warp may be issued and executed on CUDA Cores, Tensor Cores or the LD/ST units to fetch data from shared memory or global memory. Warps are swapped out and switched to the stall state while they are waiting for the necessary and dependent data from lower cache levels or off-chip memory. The warp scheduler is responsible for switching between the ready and stalled warps to hide memory access latency of LD/ST instructions, making the GPU a throughput-oriented processor compared to the CPU, which is latency-oriented.
CUDA provides three warp-level collaborative APIs and specific C++ templated types for programmers to exploit the WMMA function. Listing 1 is the brief C++ statement sequence using WMMA APIs.
| Listing 1. C++ statement using WMMA APIs |
// define the register fragment
wmma::fragment<wmma::matrix_a, M, N, K, half, wmma::col_major> a_frag;
// load a tile of matrix A to regiter fragment
wmma::load_matrix_sync(a_frag, A, M);
// warp matrix multiply operation
wmma::mma_sync(c_frag, a_frag, b_frag, c_frag);
// store the tile of output matrix C
wmma::store_matrix_sync(C, c_frag, N, wmma::mem_row_major); |
The wmma::fragment is a templated type defined in C++ to describe the shape, layout and element type of the tile to be loaded into GPU registers. It is used to determine the number of registers required to store the loaded elements. Then, for the wmma::load_matrix_sync and wmma::store_matrix_sync APIs, they are defined to load and store the matrix tiles between global memory and registers. The sync suffix indicates that the substantial calculation instructions will not be issued until the dependent data are stored in the registers, compared with some asynchronous version of memory access instructions added to CUDA recently. wmma::mma_sync is used to conduct the computation on the registers given by the input fragments, which is also a synchronous version.
It should be emphasized that CUDA only supports WMMA operations on some fixed shapes of matrix tiles for a specific data type. For instance, current WMMA implementation requires a tile for matrix A, and tile for matrix B, thus producing a output tile for matrix C. Note that the tile shape constraints may vary from different generations of GPUs and for one specific data type (like half, i.e., fp16); there are more than one shape option for the register fragment.
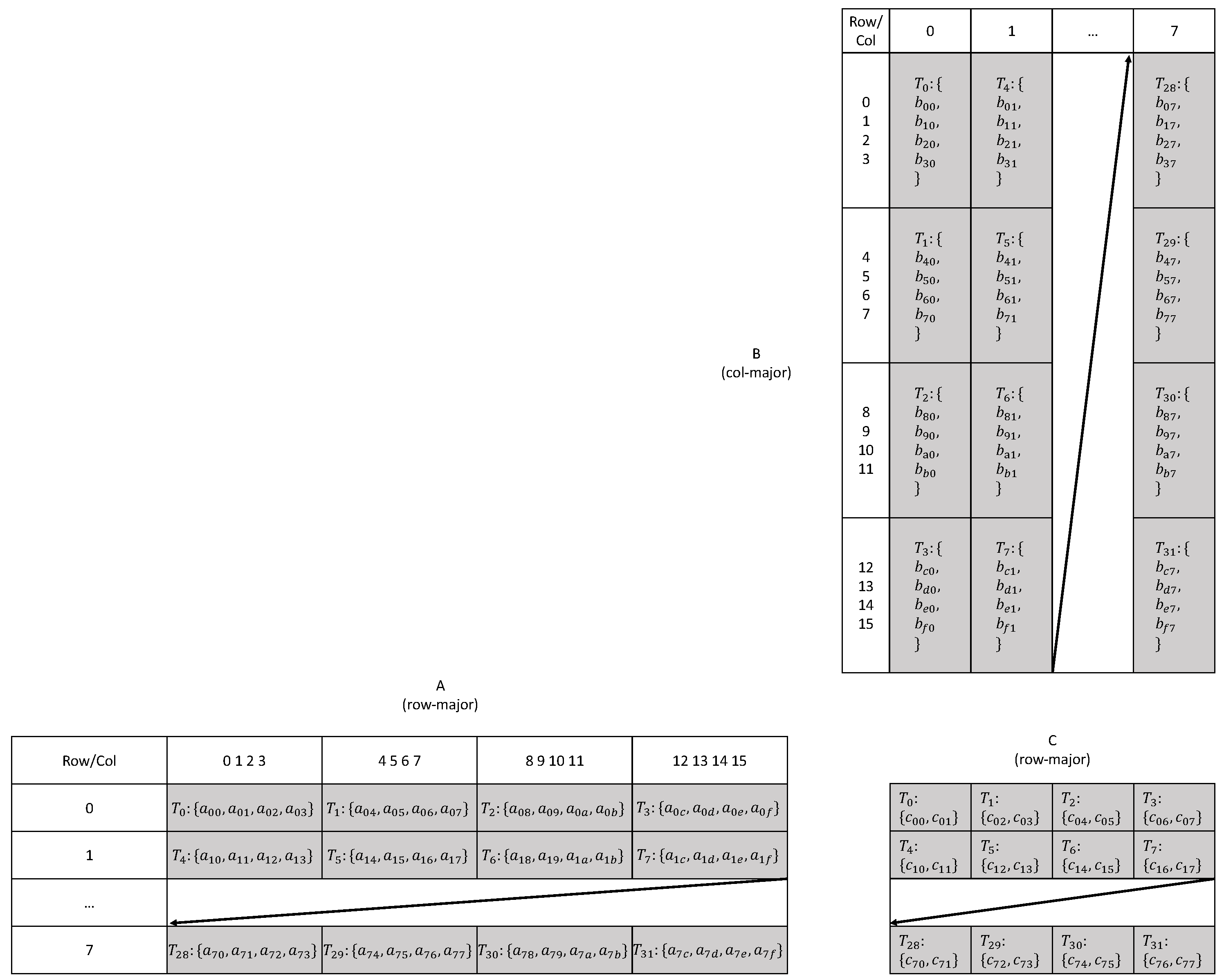
Figure 4 illustrates the data layout and orchestration of corresponding threads. Elements from input tiles are scattered among different thread private registers; during the
mma_sync operation, inter-thread register sharing is necessary for the Tensor Core to fetch data from different threads to produce the accumulated tile.
2.2. Accelerating GEMM on GPU
GEMM is a widely used operator in data intensive applications. The computing pattern of the fully connected layer in deep neural networks is GEMM in fact, and countless engineering problems depend on GEMM in their computation. GEMM is defined as follows:
where
and
are given scalars. In reality, the output matrix
D is usually the same as the input matrix
C (like the bias tensor in the fully connected layer).
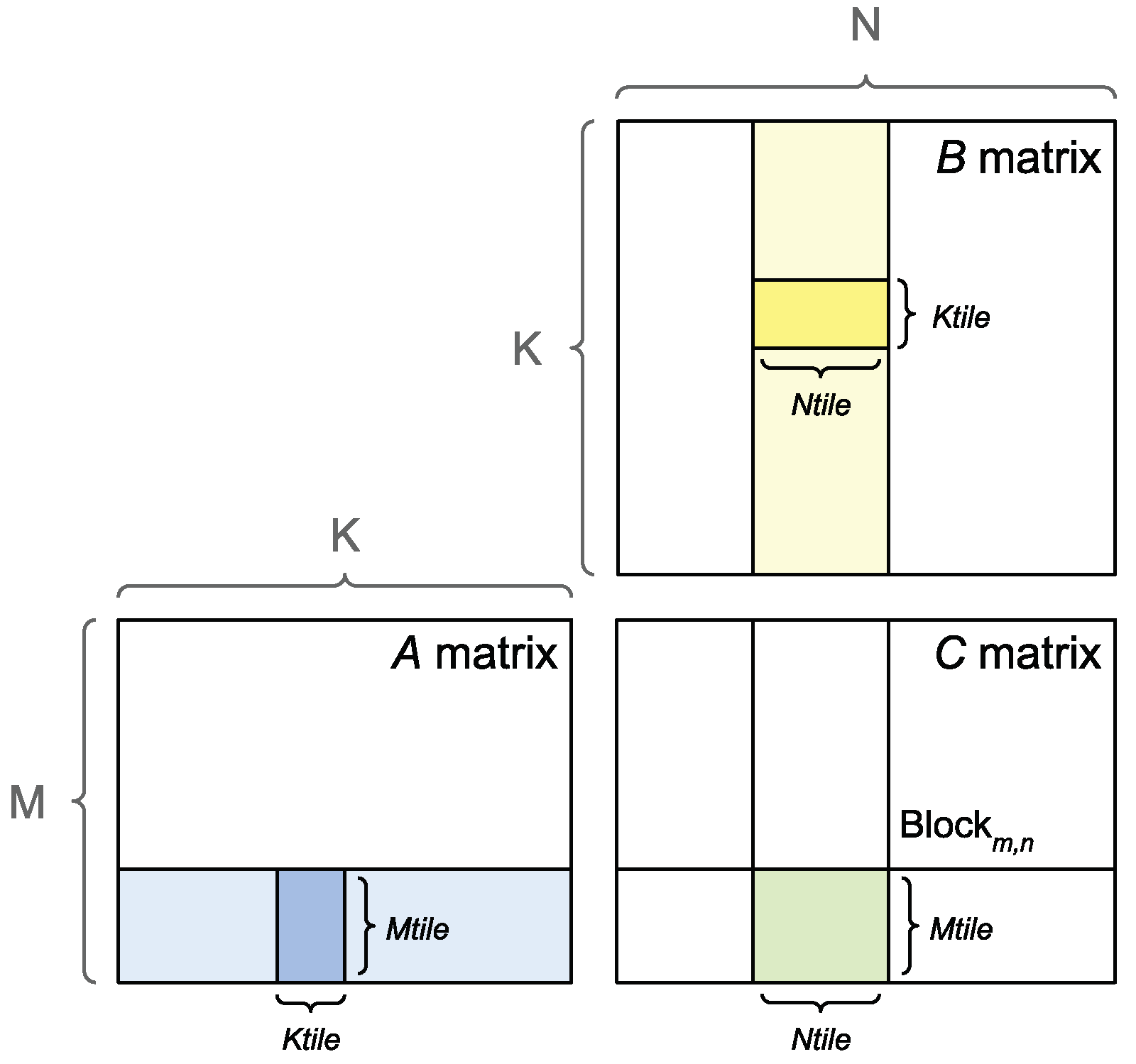
There are multiple GEMM implementations designed to accelerate it in many-core architectures. One of the most common implementations in GPUs is tiled GEMM.
Figure 5 demonstrates the process of tiled GEMM implementation. As discussed in
Section 1, the output matrix is firstly partitioned into multiple tiles, whose shape is empirically determined by the on-chip cache size (
in the green-colored tile in
Figure 5). To obtain the results of this target tile, one has to use the corresponding tiles in both input matrices, colored as light blue and yellow in
Figure 5. However, in most cases, the required memory space is far more than that of the on-chip cache capacity if we load all elements located in both input tiles onto the chip. Therefore, a common approach is to iterate both tiles at
step to obtain partially temporary results at each step and, finally, accumulate the overall results.
Inside each tile step, the calculation as well as the matrix tile are partitioned into several iterations. For each iteration, the threads in the CTA will load the required data elements in the current iteration into shared memory to minimize off-chip memory accesses later, since there will be certain data reuse across warps within a CTA. A synchronization barrier must be inserted right after the memory access instructions to ensure all data elements required for the current iteration are residing on shared memory already to be loaded into registers later. For each iteration tile, warps are responsible for temporarily loading data elements into registers and conducting WMMA calculations to save the intermediate results in registers, then storing them back to shared memory.
After all iterations finish, the CTA should write the final results from shared memory back to global memory. Note that if multiple CTAs are responsible for the same target tile from matrix C (called the split_k mode), some extra constraints must be added to avoid data race and ensure memory consistency.
2.3. CUTLASS Design Principles
As discussed earlier, CUTLASS is a hierarchical and flexible library providing APIs abstracting at different level of granularities.
It allows programmers to make use of these APIs to assemble the high-performance kernel and express their desires for various problem sizes. There are five levels of APIs that CUTLASS provides, as shown in
Table 1. In CUTLASS, users are responsible for exploiting different levels of abstractions through the APIs to assemble the desired kernels meeting both performance and customization (Listing 2). The mainloop and epilogue, as the main body of GEMM kernels, are described via the collective level APIs, which orchestrate the copy/math micro-kernels with architecture-specific synchronizations. Meanwhile, the tile APIs are compiled into core GPU micro-kernels performing substantial math/copy operations spanning cooperative threads, and the
Atom APIs are architecture instructions associated with meta-information. We may conclude that the hierarchical CUTLASS decouples the API design: the
Collective and
Tile APIs aim at describing algorithm-specific CTA/warps orchestration, while the
Atom APIs target architecture-specific instruction generation. Note that in
Table 1, the
Tile and
Atom APIs are decorated with the
cute namespace prefix. CuTE is a layout library introduced in the latest CUTLASS 3.0 release [
14]. The purpose of this library is to define and manipulate hierarchical, multidimensional layouts of threads and data. It is worth noting that almost all of these APIs or classes are templated, desiring some compile-time known information to specialize corresponding implementations; then, they are compiled into dedicated instructions to copy or calculate the specific type.
Like other numeric or operator libraries, CUTLASS allows users to call GEMM or any other kernels from the host. A typical procedure of producing the GEMM results of
cutlass::half_t (i.e.,
fp16) as input type is presented below:
| Listing 2. A typical procedure producing the GEMM results. |
using ElementA = cutlass::half_t;
using LayoutA = cutlass::layout::RowMajor;
constexpr int AlignmentA = 128 / cutlass::sizeof_bits<ElementA>::value;
// Same as matrices B and C
using ElementAccumulator = cutlass::half_t;
using ArchTag = cutlass::arch::Sm80;
using OperatorClass = cutlass::arch::OpClassTensorOp;
using ThreadblockShape = cutlass::gemm::GemmShape<128, 128, 32>;
using WarpShape = cutlass::gemm::GemmShape<64, 64, 32>;
using InstructionShape = cutlass::gemm::GemmShape<16, 8, 16>;
constexpr int NumStages = 4;
using EpilogueOp =
cutlass::epilogue::thread::LinearCombination<
ElementC, AlignmentC, ElementAccumulator, ElementAccumulator>;
// Classic data-parallel device GEMM implementation type
using DeviceGemmBasic =
cutlass::gemm::device::GemmUniversal<ElementA, LayoutA, ElementB,
LayoutB, ElementC, LayoutC, ElementAccumulator, OperatorClass
,ArchTag, ThreadblockShape, WarpShape, InstructionShape,
EpilogueOp,
cutlass::gemm::threadblock::
GemmIdentityThreadblockSwizzle<>, NumStages, AlignmentA, AlignmentB>; |
As we claimed before, CUTLASS is a highly templated library; hence, nearly all of its data types and interfaces are specified with templates. The matrix is defined by the tuple <Element, Layout> and AlignmentA, and it is used to determine the memory access granularity to the corresponding memory region. Since CUDA now supports 128-bit coalesced memory access (using LDG.128 SASS instruction), the number of elements per instruction loads is thus determined by 128/sizeof_bits(Element). Next, some required information is defined such as the MMA operation type (whether CUDA Core or Tensor Core will be used) and the underlying GPU hardware architecture tag. Lastly, the hierarchical tile shapes assigned to different levels of the collaboration group (thread block, warp or per MMA) are defined with the GemmShape template type. The epilogue operation is the auxiliary phase after the main loop of kernel for the scalar calculation or type conversion. Note that asynchronous global memory to shared memory instruction (LDG.STS SASS instruction) is proposed since Ampere generation; therefore, this producer–consumer pattern is pipelined and several memory access stages are exploited to overlap the MMA operation and global memory access. The number of pipelined stages is defined by NumStages. All the above information is then passed to GEMM kernel templates to generate the target code.
There are several advantages of encoding key information (such as element types, tile shapes and memory access granularities) as template parameters. For example, if the tile shape is fixed at the compile-time, register spills could be avoided when indexing tile elements. Besides, loop unrolling could be performed accordingly to saturate the instruction cache. Further, with this compiler–assistant information, register usage could be reduced since some variables are encoded as constants and part of input data could be fetched from CUDA constant memory to mitigate the DRAM bandwidth.
3. Results and Discussion
In this section, we demonstrate the key insights discovered from the benchmarks.
3.1. Testbed
Our experiments are conducted with NVIDIA A100 40 GB PCIe version. There are 108 Tensor Core SMs and 40 MB L2 cache total, with 1555 GB/s off-chip memory bandwidth. On the software side, we built CUTLASS 3.0 with host compiler
gcc@10.4.0 and CUDA version ‘11.4.0’ under
Debian 11 as the host OS. All measured kernels were warmed up with 10 repeated runs and invoked 20 times to obtain the average execution elapsed times. The standard deviations of all kernel executions are less than 5% and the results are stable. The theoretical peak performance for various kinds of data formats on different hardware units is listed in
Table 2.
Theoretically, we can conclude that exploiting ASIC hardware units in the GPU could dramatically boost the performance for low-precision data formats. However, the substantial speedup may be restricted by some other factors, like limitations of CTA slots per SM, shared memory usage and memory access latency. Thus, benchmarks of GEMM on off-the-shelf commercial GPUs are necessary for engineers to assess the Tensor Core benefits.
Before we continue to dig out the performance insight brought by the Tensor Core benchmarks, it should be pointed out that the CUTLASS naming conventions indicate the implementation details of kernels. Here is a GEMM kernel example:
Fields in the kernel name are separated by underlines. tensorop means the underlying hardware component used for the primary MMA operations is Tensor Core (as for CUDA Core, the corresponding name is simt). The s in the next field means the Tensor Core MMA instructions are targets for single floating point numbers (d for double floating point numbers and h for half types). Then, 1688 indicates that the warp-level MMA tile shape is —i.e., —within each CTA tile. The 128x128_16 represents the CTA tile shape () is , and the trailing 4 is the number of pipeline stages for asynchronous global memory to shared memory copies (LDG.STS). The last field, align4, indicates that the maximum alignment between operands A and B is 4.
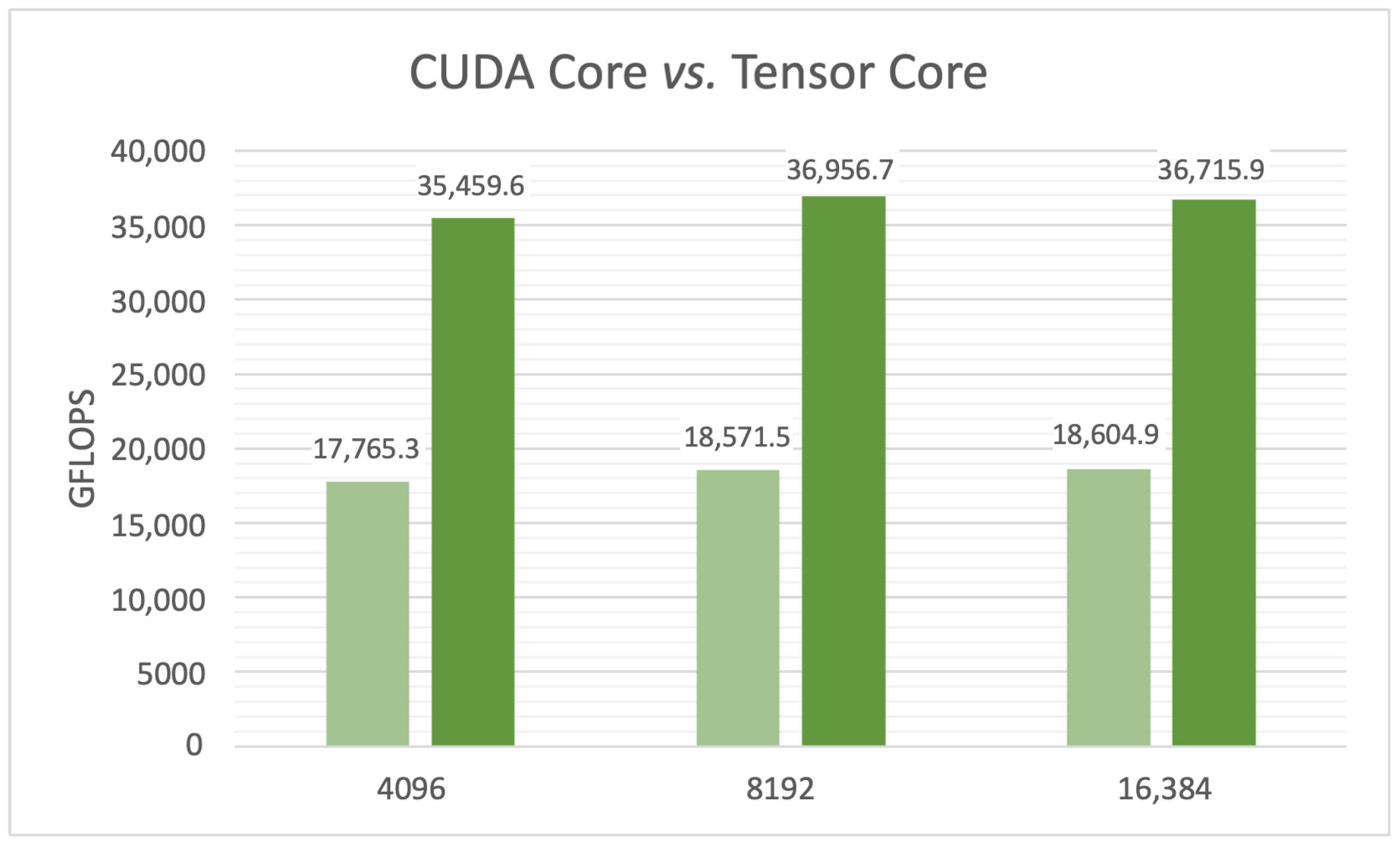
3.2. Tensor Core vs. CUDA Core
We first compare GEMM kernels in the cases of with and without Tensor Core involved. The runtime comparisons are demonstrated in
Figure 6. As we can see, the GFLOPS of GEMM kernels with Tensor Core are much higher than those without Tensor Core.
The average speedup between kernels with and without Tensor Core is 1.98. It should be pointed out that some implementation details vary between these two kernels, including the CTA tile shape and the asynchronous shared memory fetching pipeline stages.
Putting together
Table 2 and
Figure 6, we can figure out that the achieved
fp32 GEMM performance via CUTLASS is about 95% of the peak
fp32 performance, which is often regarded as a satisfying implementation.
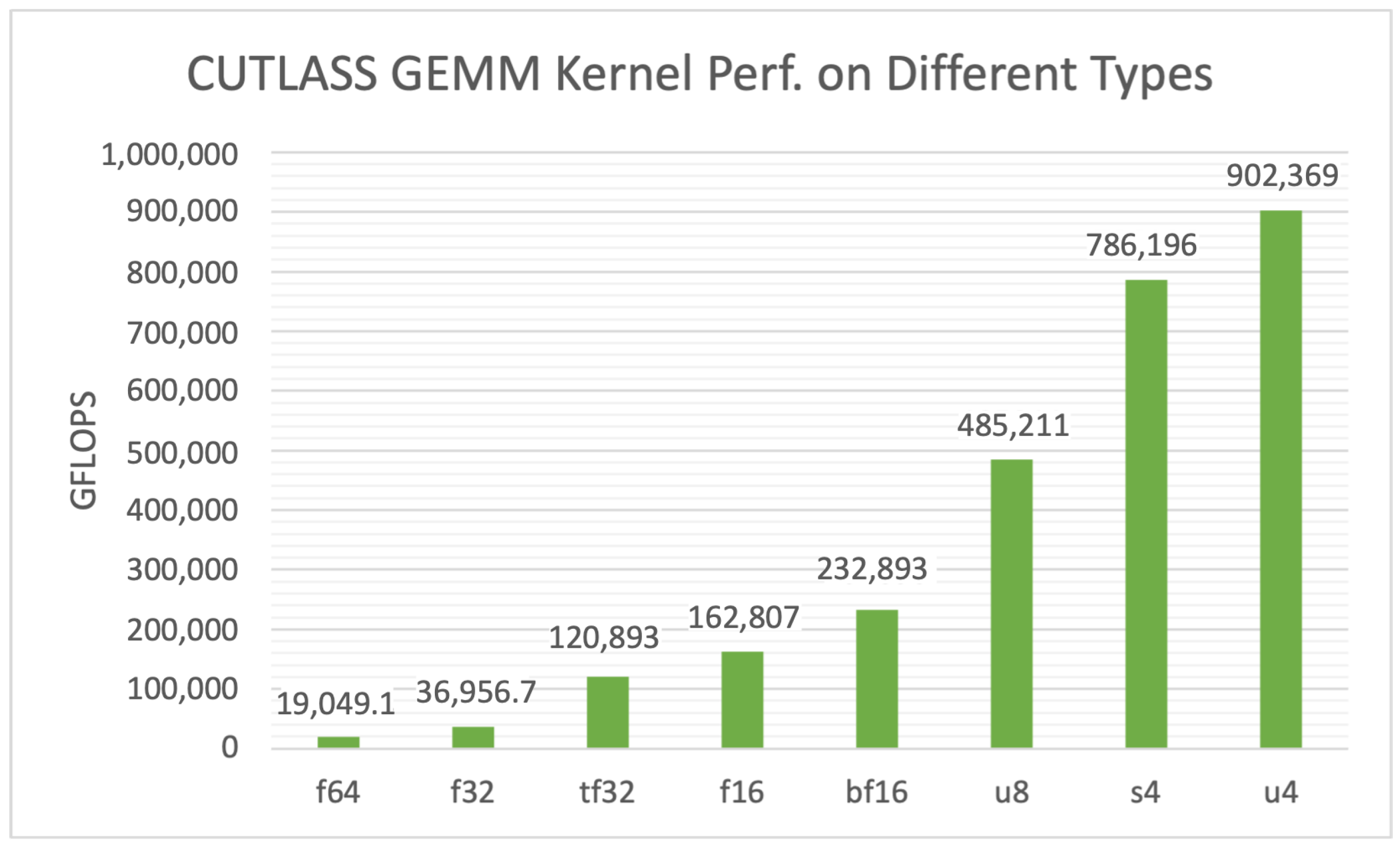
3.3. Data Formats
In this section, we mainly focus on the varied performance when applying CUTLASS GEMM kernels to different data types.
As
Figure 7 illustrates, there is a obvious trend that as the bitwidth of element type decreases, the achieved GEMM performance increases correspondingly. This is reasonable since the high-precision element type requires more bandwidth as well as cycles to execute the wider MMA instructions on Tensor Core. Another observation is that the achieved performance of extreme low-precision data types like
u8 (unsigned 8-bit integer), and even
s4 and
u4, is much higher than that of conventional data types, which leads to the wide use of such types in deep learning model inferences.
3.4. Tile Shapes and Split_k
In this section, we explore the relationship between the achieved performance, the CTA tile shape and orchestration. We first compare two GEMM kernels under problem size and fp32 inputs. Configurations of the inspected kernels remain the same, except for the CTA shape: one is 128x128_16 and the other is 256x128_16. The performance metrics, measured in GFLOPS, obtained for both kernels are 36,956.7 and 115,962, respectively. There is a significant performance gap between these two kernels, even though almost all kernel parameters are identical except the CTA tile shape. As the thread block size (i.e., the number of threads in one CTA) and the orchestration of warps along each tile dimension are the same as well, we can conclude that configuring the CTA tile shape correctly has a huge impact on overall kernel performance.
Another performance-impacting factor that deserves inspection is the split_k setting, which controls the number of CTAs working on the same tile of the output matrix. split_k is introduced to tackle the problem that for some small GEMM workloads, the one-CTA-one-tile strategy will not saturate the entire GPU SM resources, extremely for cases with small M and N but large K problem sizes. For example, for a output matrix, the abovementioned CTA orchestration with tile shape strategy ends up with only CTAs for this kernel, while there are 108 SMs in the A100 GPU. The number of fetch–calculate–store iterations required for each CTA to loop over alongside the K dimension is , where K is the reduced dimension of input matrices and k is the corresponding CTA tile dimension. To fully utilize the GPU resource and reduce the workload assigned to each CTA, one can parallelize the execution at the dimension K by orchestrating more than one CTA on the same tile of the output matrix. Thus, loop iterations required for that tile could be evenly distributed among multiple CTAs and, for each CTA, the number of iterations would then be reduced by split_k times.
Table 3 shows the achieved performance for
fp32 GEMM kernels with a varying
split_k parameter and with
and
problem size. As we can see, as the value of
split_k factor increases, the performance of the obtained kernel boosts as well. However, there is a kneepoint where increasing the
split_k value will harm the overall performance. It should be emphasized that enabling parallel
split_k mode with its value larger than one needs one extra reduction kernel to aggregate temporary results from different CTAs and the corresponding predefined global buffers into the final output tile destination. Hence, the larger
split_k is, the longer the reduction latency will be.
3.5. Asynchronous Copy
To implement a performant GEMM kernel, software pipelining is required to hide the global-to-shared memory access latency as much as possible. Asynchronous copy is a new hardware feature proposed in Ampere that allows programmers to explicitly invoke non-blocking global-to-shared memory access with no extra registers required for storing temporarily accessed data.
Table 4 lists the relative speedup for kernel
s1688gemm_f16_256x128_32x2 gained via applying asynchronous global-to-shared memory copies. Observation shows that enabling this new hardware feature could bring averaged 1.195 speedups over different matrix sizes with
fp16 input and
fp32 output. Enabling async. copy brings more flexibility for the SM scheduler since Tensor Cores only accelerate the computation while the off-chip bandwidth remains the same. It offers the opportunities to pipeline and overlap the computation and memory access.
4. Related Works
Tensor Core has been a hot topic since the release of its first generation. Works [
15,
16,
17,
18] conducted micro-benchmarks to demonstrate the underlying mechanisms of Tensor Core, including the SASS instruction of
mma_sync, the cost cycles for each MMA instruction as well as the tile orchestrations for each thread within one warp. Zhao et al. [
19] pointed out the phenomenon that the utilization of CUDA Core and Tensor Core could not be high simultaneously; therefore, they proposed a source-to-source compiler that transforms a common kernel into a persistent SM-centric kernel, allowing workloads using Tensor Core or CUDA Core to be scheduled into the same SM. SIMD2 [
20] used off-the-shelf commercial GPUs to emulate general purpose computation on the dedicated Tensor Core, revealing the potential of extending the calculation capacity for a wider range of workloads. Likewise, PET [
21] proposed a transformation that allows partial equivalent operations and an automatic correction mechanism to ensure that the results are acceptable for tensor programs. Another direction is to fuse isolated kernels utilizing the CUDA Core or Tensor Core separately into monolithic macro-kernels and integrating architecture supports in hardware for this change [
22]. There are also some workload-specific optimizations exploiting Tensor Core to accelerate the computation on GNN or sparse matrix operations [
23,
24].
GEMM is a well-studied workload accelerated by GPUs, which has many adoptions in deep learning and scientific computing applications. There are some works focusing on exploiting Tensor Core to accelerate GEMM while maintaining the precision requirements [
25]. Also, Mix-GEMM [
26] explores the usage of GEMM on deep learning model inference running on edge devices. The design of workload distribution on GEMM is also studied to better utilize the GPU on-chip resources [
27]. Besides, other specialized linear algebra operations like SYMM and TRMM [
28] can be implemented and optimized with CUTLASS.
GPU operator tuning is the process of finding the most suitable tiling size and other kernel configurations like the number of pre-fetching stages for asynchronous copy. Nowadays, machine learning compilers like TVM [
29] have enabled us to seek out the optimal solution with automatic search, but the search space is still to large for an exhaustive traverse. To bridge the gap between performant but less flexible vendor-provided libraries (like cuDNN) and highly customizable but less optimal libraries like CUTLASS, Bolt [
30] was proposed to integrate CUTLASS into TVM as the backend of the search process for high-quality code generation. Besides, Graphene [
31] was proposed to serve as an IR to minimize the effort for kernel experts to express tensor operations at a low level without losing general expression ability.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}