
A Deep Neural Networks-Based Sound Speed Reconstruction with Enhanced Generalization by Training on a Natural Image Dataset
Abstract
:1. Introduction
2. Materials and Methods
2.1. Generation of Sound Speed Distribution Datasets from Breast Phantom Data
2.2. Generation of Sound Speed Distribution Datasets from Natural Images
2.3. Computation of the Observed Signals
2.4. Network Architecture and the Training
2.5. Measurement Condition
3. Results
3.1. Generated Datasets and the Properties
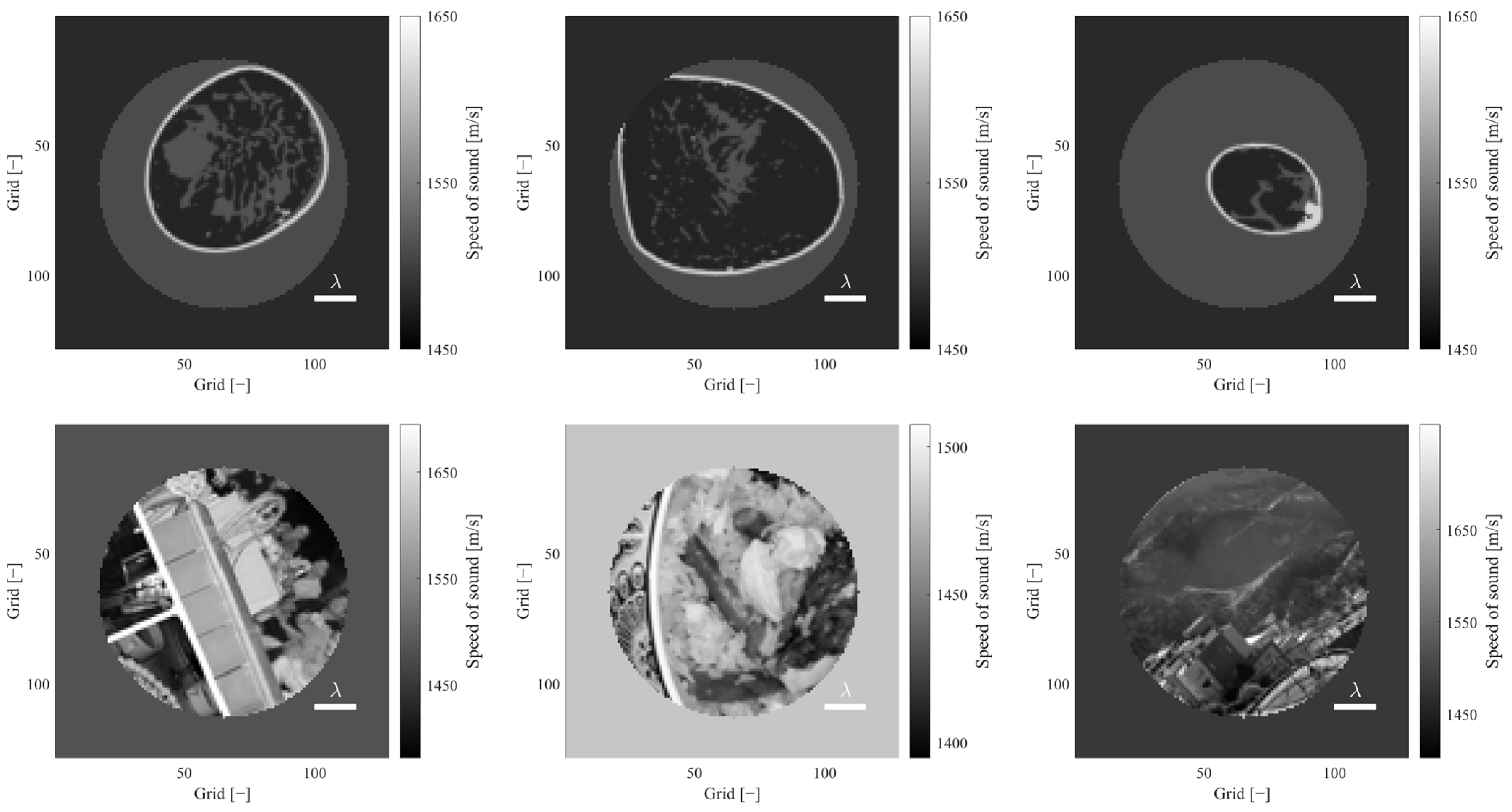
3.2. Visual Comparison
3.3. Quantitative Evaluation
3.4. Generalization Performance Evaluation for Tumour Structures outside the Training Data
4. Discussion
4.1. Impacts of Training Data on Reconstruction Quality and Generalization Performance
4.2. Towards Reliable Sound Speed Imaging
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chung, H.W.; Cho, K.H. Ultrasonography of soft tissue “oops lesions”. Ultrasonography 2015, 34, 217. [Google Scholar] [CrossRef] [PubMed]
- Wiratkapun, C.; Bunyapaiboonsri, W.; Wibulpolprasert, B.; Lertsithichai, P. Biopsy rate and positive predictive value for breast cancer in BI-RADS category 4 breast lesions. Med. J. Med. Assoc. Thail. 2010, 93, 830. [Google Scholar]
- He, N.; Wu, Y.P.; Kong, Y.; Lv, N.; Huang, Z.M.; Li, S.; Wang, Y.; Geng, Z.J.; Wu, P.H.; Wei, W.D. The utility of breast cone-beam computed tomography, ultrasound, and digital mammography for detecting malignant breast tumors: A prospective study with 212 patients. Eur. J. Radiol. 2016, 85, 392–403. [Google Scholar] [CrossRef] [PubMed]
- Uematsu, T. Ultrasonographic findings of missed breast cancer: Pitfalls and pearls. Breast Cancer 2014, 21, 10–19. [Google Scholar] [CrossRef] [PubMed]
- Spratt, J.S.; Meyer, J.S.; Spratt, J.A. Rates of growth of human neoplasms: Part II. J. Surg. Oncol. 1996, 61, 68–83. [Google Scholar] [CrossRef]
- Vriens, B.E.; de Vries, B.; Lobbes, M.B.; van Gastel, S.M.; van den Berkmortel, F.W.; Smilde, T.J.; van Warmerdam, L.J.; de Boer, M.; van Spronsen, D.J.; Smidt, M.L.; et al. Ultrasound is at least as good as magnetic resonance imaging in predicting tumour size post-neoadjuvant chemotherapy in breast cancer. Eur. J. Cancer 2016, 52, 67–76. [Google Scholar] [CrossRef]
- Kim, S.Y.; Cho, N.; Choi, Y.; Lee, S.H.; Ha, S.M.; Kim, E.S.; Chang, J.M.; Moon, W.K. Factors affecting pathologic complete response following neoadjuvant chemotherapy in breast cancer: Development and validation of a predictive nomogram. Radiology 2021, 299, 290–300. [Google Scholar] [CrossRef]
- Greenleaf, J.F.; Johnson, S.A.; Samayoa, W.F.; Duck, F.A. Algebraic reconstruction of spatial distributions of acoustic velocities in tissue from their time-of-flight profiles. Acoust. Hologr. 1975, 6, 71–90. [Google Scholar]
- Duric, N.; Littrup, P.; Poulo, L.; Babkin, A.; Pevzner, R.; Holsapple, E.; Rama, O.; Glide, C. Detection of breast cancer with ultrasound tomography: First results with the Computed Ultrasound Risk Evaluation (CURE) prototype. Med. Phys. 2007, 34, 773–785. [Google Scholar] [CrossRef]
- Greenleaf, J.F. Computerized tomography with ultrasound. Proc. IEEE 1983, 71, 330–337. [Google Scholar] [CrossRef]
- Mueller, R.K. Diffraction tomography I: The wave-equation. Ultrason. Imaging 1980, 2, 213–222. [Google Scholar] [CrossRef]
- Devaney, A.J. A filtered backpropagation algorithm for diffraction tomography. Ultrason. Imaging 1982, 4, 336–350. [Google Scholar] [CrossRef] [PubMed]
- Devaney, A.J. Reconstructive tomography with diffracting wavefields. Inverse Probl. 1986, 2, 161. [Google Scholar] [CrossRef]
- Sandhu, G.Y.; Li, C.; Roy, O.; Schmidt, S.; Duric, N. Frequency domain ultrasound waveform tomography: Breast imaging using a ring transducer. Phys. Med. Biol. 2015, 60, 5381. [Google Scholar] [CrossRef] [PubMed]
- Roy, O.; Jovanović, I.; Hormati, A.; Parhizkar, R.; Vetterli, M. Sound speed estimation using wave-based ultrasound tomography: Theory and GPU implementation. In Proceedings of the SPIE Medical Imaging 2010, San Diego, CA, USA, 13–18 February 2010. [Google Scholar]
- Agudo, O.C.; Guasch, L.; Huthwaite, P.; Warner, M. 3D imaging of the breast using full-waveform inversion. In Proceedings of the International Workshop on Medical Ultrasound Tomography, Speyer, Germany, 1–3 November 2017. [Google Scholar]
- Li, C.; Sandhu, G.S.; Roy, O.; Duric, N.; Allada, V.; Schmidt, S. Toward a practical ultrasound waveform tomography algorithm for improving breast imaging. In Proceedings of the SPIE Medical Imaging 2014, San Diego, CA, USA, 15–20 February 2014. [Google Scholar]
- Wang, K.; Matthews, T.; Anis, F.; Li, C.; Duric, N.; Anastasio, M.A. Waveform inversion with source encoding for breast sound speed reconstruction in ultrasound computed tomography. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2015, 62, 475–493. [Google Scholar] [CrossRef]
- Pérez-Liva, M.; Herraiz, J.L.; Udías, J.M.; Miller, E.; Cox, B.T.; Treeby, B.E. Time domain reconstruction of sound speed and attenuation in ultrasound computed tomography using full wave inversion. J. Acoust. Soc. Am. 2017, 141, 1595–1604. [Google Scholar] [CrossRef]
- Lin, H.; Azuma, T.; Qu, X.; Takagi, S. Robust contrast source inversion method with automatic choice rule of regularization parameters for ultrasound waveform tomography. Jpn. J. Appl. Phys. 2016, 55, 07KB08. [Google Scholar] [CrossRef]
- Robins, T.; Camacho, J.; Agudo, O.C.; Herraiz, J.L.; Guasch, L. Deep-learning-driven full-waveform inversion for ultrasound breast imaging. Sensors 2021, 21, 4570. [Google Scholar] [CrossRef]
- Suganyadevi, S.; Seethalakshmi, V.; Balasamy, K. A review on deep learning in medical image analysis. Int. J. Multimed. Inf. Retr. 2022, 11, 19–38. [Google Scholar] [CrossRef]
- Wang, G.; Ye, J.C.; De Man, B. Deep learning for tomographic image reconstruction. Nat. Mach. Intell. 2020, 2, 737–748. [Google Scholar] [CrossRef]
- Fan, Y.; Wang, H.; Gemmeke, H.; Hopp, T.; Hesser, J. Model-data-driven image reconstruction with neural networks for ultrasound computed tomography breast imaging. Neurocomputing 2022, 467, 10–21. [Google Scholar] [CrossRef]
- Prasad, S.; Almekkawy, M. Deepuct: Complex cascaded deep learning network for improved ultrasound tomography. Phys. Med. Biol. 2022, 67, 065008. [Google Scholar] [CrossRef] [PubMed]
- Feigin, M.; Freedman, D.; Anthony, B.W. A deep learning framework for single-sided sound speed inversion in medical ultrasound. IEEE Trans. Biomed. Eng. 2019, 67, 1142–1151. [Google Scholar] [CrossRef] [PubMed]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A brief review of domain adaptation. In Proceedings of the ICDATA 2020 and IKE 2020, Las Vegas, NV, USA, 27–30 July 2020. [Google Scholar]
- Jush, F.K.; Biele, M.; Dueppenbecker, P.M.; Maier, A. Deep Learning for Ultrasound Speed-of-Sound Reconstruction: Impacts of Training Data Diversity on Stability and Robustness. J. Mach. Learn. Biomed. Imaging 2023, 2, 202–236. [Google Scholar]
- Lou, Y.; Zhou, W.; Matthews, T.P.; Appleton, C.M.; Anastasio, M.A. Generation of anatomically realistic numerical phantoms for photoacoustic and ultrasonic breast imaging. J. Biomed. Opt. 2017, 22, 041015. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Bria, A.; Marrocco, C.; Tortorella, F. Addressing class imbalance in deep learning for small lesion detection on medical images. Comput. Biol. Med. 2020, 120, 103735. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Cobbold, R.S. Foundations of Biomedical Ultrasound; Oxford University Press: New York, NY, USA, 2006; p. 76. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Tikhonov, A.N.; Arsenin, V.Y. Solution of Ill-Posed Problems; Wiley: New York, NY, USA, 1977. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv 2016, arXiv:1610.02136. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A Simple Unified Framework for Detecting Out-of-distribution Samples and Adversarial Attacks. In Proceedings of the 32rd Conference on Neural Information Processing Systems (NIPS’18), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Hsu, Y.C.; Shen, Y.; Jin, H.; Kira, Z. Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Watanabe, Y.; Azuma, T.; Takagi, S. Array geometry dependency in sound speed reconstruction using Deep Neural Network. Neurocomputing, 2023; submitted. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ring diameter | 20 mm |
| Number of elements | 64 |
| Frequency | 500 kHz |
| Grid size | 187.5 m |
| Breast (Train) | Natural Images (Train) | |
|---|---|---|
| Breast (Test) | 1.4 ± 3.8 | 5.5 ± 9.6 |
| Natural images (Test) | 72.5 ± 44.1 | 9.6 ± 15.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Watanabe, Y.; Azuma, T.; Takagi, S. A Deep Neural Networks-Based Sound Speed Reconstruction with Enhanced Generalization by Training on a Natural Image Dataset. Appl. Sci. 2024, 14, 37. https://doi.org/10.3390/app14010037
Watanabe Y, Azuma T, Takagi S. A Deep Neural Networks-Based Sound Speed Reconstruction with Enhanced Generalization by Training on a Natural Image Dataset. Applied Sciences. 2024; 14(1):37. https://doi.org/10.3390/app14010037
Chicago/Turabian StyleWatanabe, Yoshiki, Takashi Azuma, and Shu Takagi. 2024. "A Deep Neural Networks-Based Sound Speed Reconstruction with Enhanced Generalization by Training on a Natural Image Dataset" Applied Sciences 14, no. 1: 37. https://doi.org/10.3390/app14010037