
Improving OCR Accuracy for Kazakh Handwriting Recognition Using GAN Models

Abstract
:1. Introduction
2. Materials and Methods
- -
- To train a generative adversarial network with different loss functions, experimental determination hyperparameters, and formulation;
- -
- To compare CER and WER metrics of handwritten text recognition models after training with generated data.
2.1. Loss Functions of GAN Models
2.2. Evaluation Metrics of GAN Algorithms
3. Results
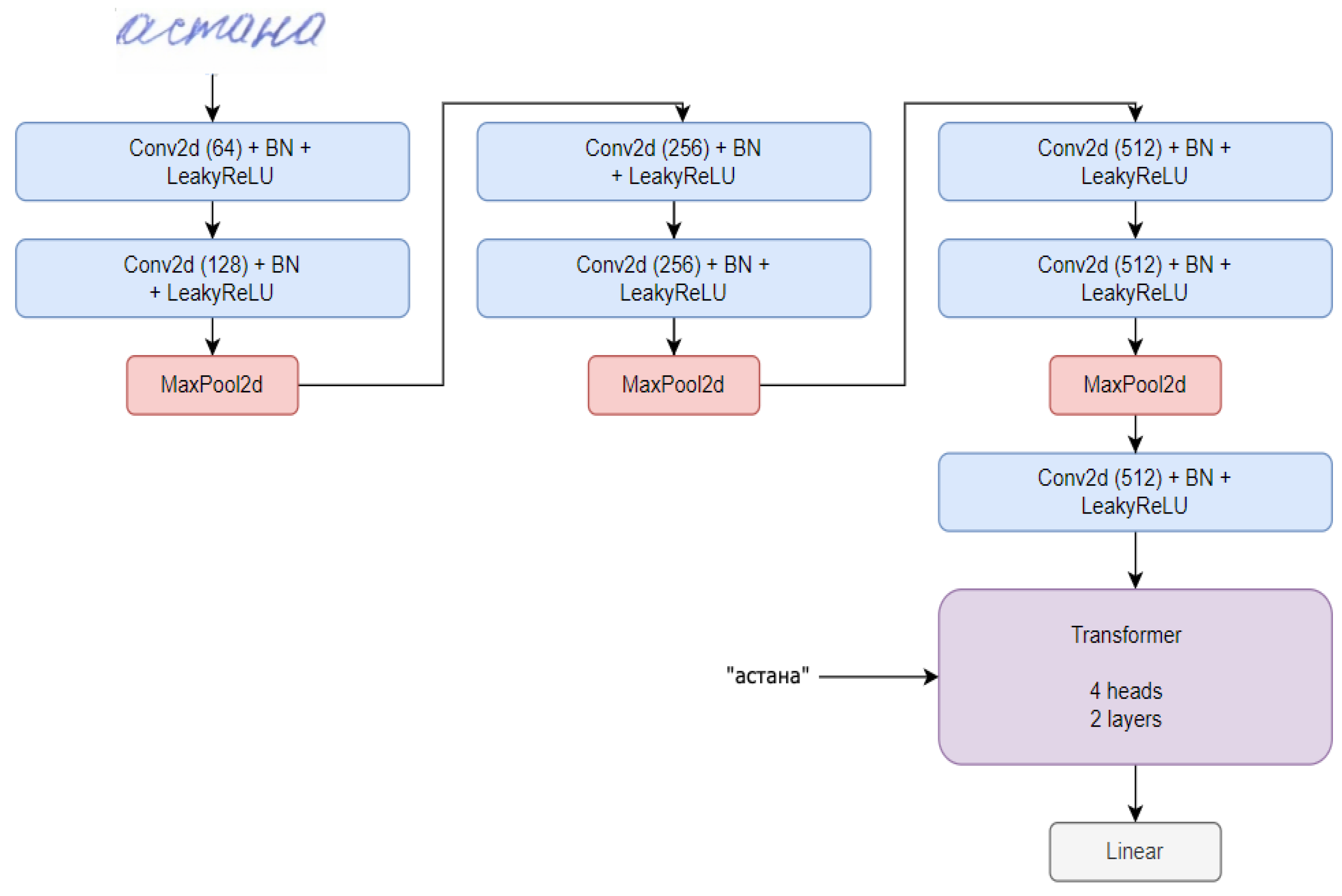
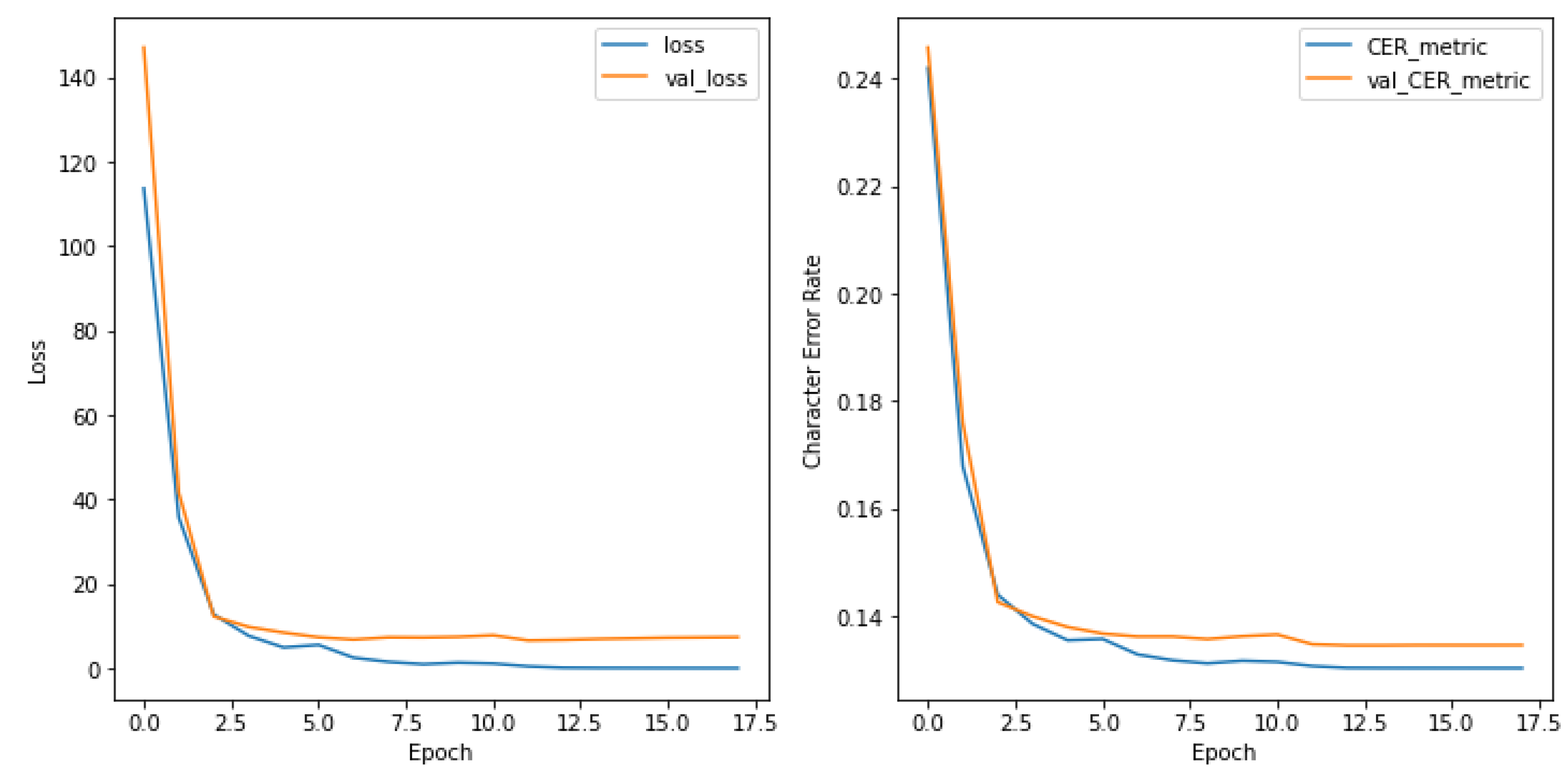
3.1. Kazakh Handwritten Dataset Description and Presettings
3.2. Parameters of Proposed Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef]
- Tran, B.H.; Le-Cong, T.; Nguyen, H.M.; Le, D.A.; Nguyen, T.H.; Le Nguyen, P. SAFL: A Self-Attention Scene Text Recognizer with Focal Loss. arXiv 2020, arXiv:2201.00132. [Google Scholar]
- Metzenthin, E.; Bartz, C.; Meinel, C. Weakly Supervised Scene Text Detection using Deep Reinforcement Learning. arXiv 2022, arXiv:2201.04866. [Google Scholar]
- Available online: https://astanatimes.com/2017/10/kazakhstan-to-switch-to-latin-alphabet-by-2025 (accessed on 25 April 2023).
- Fedotov, A.; Tussupov, J.; Sambetbayeva, M.; Idrisova, I.; Yerimbetova, A. Development and implementation of a morphological model of kazakh language. Eurasian J. Math. Comput. Appl. 2015, 3, 69–79. [Google Scholar]
- Dash, A.; Ye, J.; Wang, G. A review of Generative Adversarial Networks (GANs) and its applications in a wide variety of disciplines—From Medical to Remote Sensing. arXiv 2021, arXiv:2110.01442. [Google Scholar]
- Fussell, L.; Moews, B. Forging new worlds: High-resolution synthetic galaxies with chained generative adversarial networks. Mon. Not. R. Astron. Soc. 2019, 485, 3203–3214. [Google Scholar] [CrossRef]
- Laino, M.E.; Cancian, P.; Politi, L.S.; Della Porta, M.G.; Saba, L.; Savevski, V. Generative Adversarial Networks in Brain Imaging: A Narrative Review. J. Imaging 2022, 8, 83. [Google Scholar] [CrossRef]
- Park, S.-W.; Ko, J.-S.; Huh, J.-H.; Kim, J.-C. Review on Generative Adversarial Networks: Focusing on Computer Vision and Its Applications. Electronics 2021, 10, 1216. [Google Scholar] [CrossRef]
- Kovalev, V.A.; Kozlovsky, S.A.; Kalinovsky, A.A. Generation of artificial chest X-ray images using generative-adversarial neural networks. Informatics 2018, 15, 7–17. [Google Scholar]
- Fogel, S.; Averbuch-Elor, H.; Cohen, S.; Mazor, S.; Litman, R. ScrabbleGAN: Semi-Supervised Varying Length Handwritten Text Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4324–4333. [Google Scholar]
- Shonenkov, A.; Karachev, D.; Novopoltsev, M. StackMix and Blot Augmentations for Handwritten Text Recognition. Comput. Vis. Pattern Recognit. 2021. [Google Scholar] [CrossRef]
- Berikov, V.; Amirgaliyev, Y.; Cherikbayeva, L.; Yedilkhan, D.; Tulegenova, B. Classification at incomplete training information: Usage of clustering group to improve performance. J. Theor. Appl. Inf. Technol. 2019, 19, 5048–5060. [Google Scholar]
- Mazzolini, D.; Mignone, P.; Pavan, P.; Vessio, G. An easy-to-explain decision support framework for forensic analysis of dynamic signatures. Forensic Sci. Int. Digit. Investig. 2021, 38, 301216. [Google Scholar] [CrossRef]
- Bhowal, P.; Banerjee, D.; Malakar, S.; Sarkar, R. A two-tier ensemble approach for writer dependent online signature verification. J. Ambient. Intell. Humaniz. Comput. 2021, 13, 21–40. [Google Scholar] [CrossRef]
- Vorugunti, C.S.; Pulabaigari, V.; Mukherjee, P.; Gautam, A. COMPOSV: Compound feature extraction and depthwise separable convolution-based online signature verification. Neural Comput. Applic 2022, 34, 10901–10928. [Google Scholar] [CrossRef]
- Sumeet, S. Singh and Sergey Karayev. Full Page Handwriting Recognition via Image to Sequence Extraction. In Book: Document Analysis and Recognition; ICDAR: Lausanne, Switzerland, 2021; pp. 55–69. [Google Scholar]
- Kenshimov, C.; Mukhanov, S.; Merembayev, T.; Yedilkhan, D. A Comparison of Convolutional Neural Networks for Kazakh Sign Language Recognition. East.-Eur. J. Enterp. Technol. 2021, 5, 44–54. [Google Scholar] [CrossRef]
- Buribayev, Z.; Merembayev, T.; Amirgaliyev, Y.; Miyachi, T. The Optimized Distance Calculation Method with Stereo Camera for an Autonomous Tomato Harvesting. In Proceedings of the 2021 IEEE International Conference on Smart Information Systems and Technologies (SIST), Nur-Sultan, Kazakhstan, 28–30 April 2021; IEEE: Piscataway, NJ, USA; pp. 1–5. [Google Scholar]
- Amirgaliyev, Y.; Shamiluulu, S.; Merembayev, T.; Yedilkhan, D. Using machine learning algorithm for diagnosis of stomach disorders. In Proceedings of the Mathematical Optimization Theory and Operations Research: 18th International Conference, MOTOR 2019, Ekaterinburg, Russia, 8–12 July 2019; Revised Selected Papers (pp. 343–355); Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar]
- Daiyrbayeva, E.; Yerimbetova, A.; Nechta, I.; Merzlyakova, E.; Toigozhinova, A.; Turganbayev, A. A Study of the Information Embedding Method into Raster Image Based on Interpolation. J. Imaging 2022, 8, 288. [Google Scholar] [CrossRef]
- Merembayev, T.; Amirgaliyev, Y.; Saurov, S.; Wójcik, W. Soil Salinity Classification Using Machine Learning Algorithms and Radar Data in the Case from the South of Kazakhstan. J. Ecol. Eng. 2022, 23, 61–67. [Google Scholar] [CrossRef]
- Jin, T.; Zhuang, J.; Xiao, J.; Xu, N.; Qin, S. Reconstructing Floorplans from Point Clouds Using GAN. J. Imaging 2023, 9, 39. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. In Advances in Neural Information Processing Systems; Curran Associates: Red Hook, NY, USA, 2009; pp. 2080–2088. [Google Scholar]
- Tran, N.T.; Bui, T.A.; Cheung, N.M. Dist-GAN: An Improved GAN using Distance Constraints. In Book Chapter; ECCV: Coburg, Victoria, 2018. [Google Scholar]
- Ghojogh, B.; Karray, F.; Crowley, M. Theoretical Insights into the Use of Structural Similarity Index in Generative Models and Inferential Autoencoders. In Image Analysis and Recognition; Campilho, A., Karray, F., Wang, Z., Eds.; ICIAR 2020; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12132. [Google Scholar] [CrossRef]
- Shlens, J. Notes on Kullback-Leibler Divergence and Likelihood Computer Science. arXiv 2014, arXiv:1404.2000. [Google Scholar]
- Ho, Y.; Wookey, S. The Human Visual System and Adversarial AI//Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Image and Video Processing (eess.IV). arXiv 2020, arXiv:2001.01172. [Google Scholar]
- Amirgaliyev, B.; Yeleussinov, A.; Taizo, M. Kazakh handwritten recognition. J. Theor. Appl. Inf. Technol. 2020, 98, 2744–2754. [Google Scholar]
- Krishnan, P.; Kovvuri, R.; Pang, G.; Vassilev, B.; Hassner, T. TextStyleBrush: Transfer of Text Aesthetics from a Single Example. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. In Proceedings of the IEEE, International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4401–4410. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Li, M.; Lv, T.; Chen, J.; Cui, L.; Lu, Y.; Florencio, D.; Zhang, C.; Li, Z.; Wei, F. TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models. arXiv 2021, arXiv:2109.10282. [Google Scholar]
- Wick, C.; Reul, C.; Puppe, F. Calamari—A High-Performance Tensorflowbased Deep Learning Package for Optical Character Recognition. Digit. Humanit. Q. 2020, 14, 25–29. [Google Scholar]
- Hamada, M.A.; Sultanbek, K.; Alzhanov, B.; Tokbanov, B. Sentimental text processing tool for russian language based on machine learning algorithms. In Proceedings of the ICEMIS’19: The 5th International Conference on Engineering & MIS, Astana, Kazakhstan, 6–8 June 2019; pp. 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | IS | FID | SSIM |
|---|---|---|---|
| TextStyleBrush | 35.24 | 32.11 | 0.2 |
| GanWriting | 49.33 | 29.23 | 0.38 |
| ScrabbleGAN | 51.21 | 20.14 | 0.43 |
| Dataset | WER (%) | CER (%) |
|---|---|---|
| real 45 k | 25.65 | 11.15 |
| real + generated 59 k | 23.21 | 9.24 |
| real + generated 67 k | 17.34 | 9.01 |
| real + generated 89 k | 15.21 | 8.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeleussinov, A.; Amirgaliyev, Y.; Cherikbayeva, L. Improving OCR Accuracy for Kazakh Handwriting Recognition Using GAN Models. Appl. Sci. 2023, 13, 5677. https://doi.org/10.3390/app13095677
Yeleussinov A, Amirgaliyev Y, Cherikbayeva L. Improving OCR Accuracy for Kazakh Handwriting Recognition Using GAN Models. Applied Sciences. 2023; 13(9):5677. https://doi.org/10.3390/app13095677
Chicago/Turabian StyleYeleussinov, Arman, Yedilkhan Amirgaliyev, and Lyailya Cherikbayeva. 2023. "Improving OCR Accuracy for Kazakh Handwriting Recognition Using GAN Models" Applied Sciences 13, no. 9: 5677. https://doi.org/10.3390/app13095677