Advances in Image Processing, Analysis and Recognition Technology
Share This Topical Collection
Editor
 Dr. Dariusz Frejlichowski
Dr. Dariusz Frejlichowski
Dr. Dariusz Frejlichowski
E-Mail
Website
Collection Editor
Faculty of Computer Science and Information Technology, West Pomeranian University of Technology, Szczecin Zolnierska 52, 71-210 Szczecin, Poland
Interests: machine vision; computer vision; image processing; image recognition; biometrics; medical images analysis; shape description; binary images representation; fusion of various features representing an object of interest; content-based image retrieval; practical applications of image processing; analysis and recognition algorithms
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
For many decades, researchers have been trying to make computer analyses of images as effective as human vision. For this purpose, many algorithms and systems have been created so far. The whole process covers various stages, including image processing, representation and recognition. The results of this work have found many applications in computer-assisted areas of everyday life. They improve particular activities and provide useful tools, sometimes only for entertainment but quite often significantly for increasing safety. In fact, the practical implementation of image processing algorithms is particularly wide. Moreover, the rapid growth of computational complexity and computer efficiency has allowed for the development of more sophisticated and effective algorithms and tools. Although significant progress has been made so far, many issues still remain open, resulting in the need for the development of novel approaches.
The aim of this Topical Collection on “Advances in Image Processing, Analysis and Recognition Technology” is to give researchers the opportunity to provide new trends, latest achievements and research directions as well as to present their current work on the important problem of image processing, analysis and recognition.
Potential topics of interest for this Topical Collection include (but are not limited to) the following areas:
- Image acquisition;
- Image quality analysis;
- Image filtering, restoration and enhancement;
- Image segmentation;
- Biomedical image processing;
- Color image processing;
- Multispectral image processing;
- Hardware and architectures for image processing;
- Image databases;
- Image retrieval and indexing;
- Image compression;
- Low-level and high-level image description;
- Mathematical methods in image processing, analysis and representation;
- Artificial intelligence tools in image analysis;
- Pattern recognition algorithms applied for images;
- Digital watermarking;
- Digital photography;
- Practical applications of image processing, analysis and recognition algorithms in medicine, surveillance, biometrics, document analysis, multimedia, intelligent transportation systems, stereo vision, remote sensing, computer vision, robotics, etc.
Dr. Dariusz Frejlichowski
Collection Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Applied Sciences is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2400 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- image processing
- image analysis
- image recognition
- computer vision
Published Papers (7 papers)
Open AccessReview
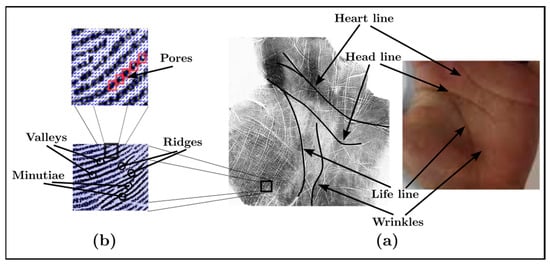
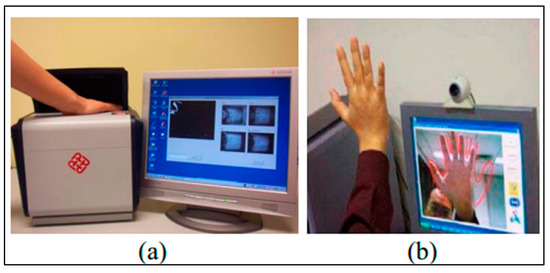
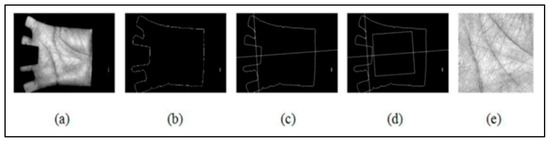
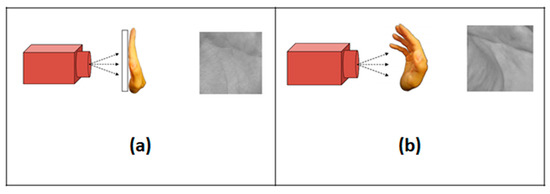
Palmprint Recognition: Extensive Exploration of Databases, Methodologies, Comparative Assessment, and Future Directions
by
Nadia Amrouni, Amir Benzaoui and Abdelhafid Zeroual
Viewed by 1091
Abstract
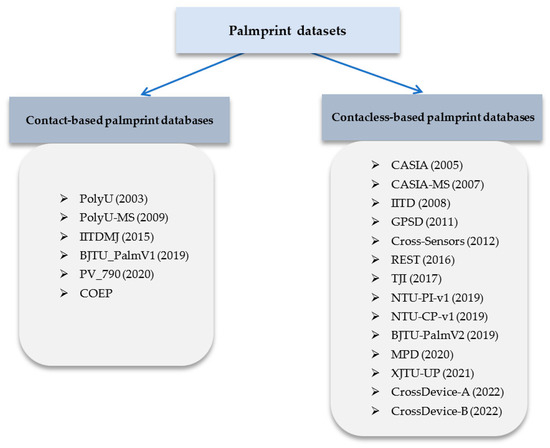
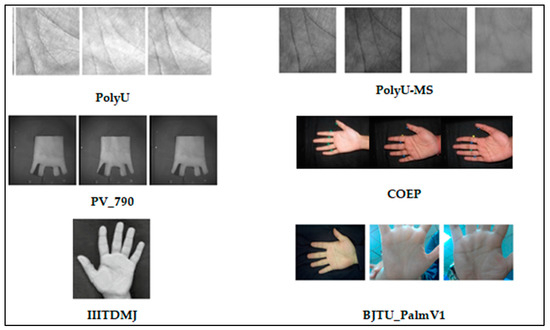
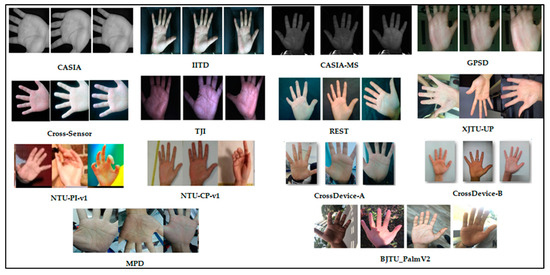
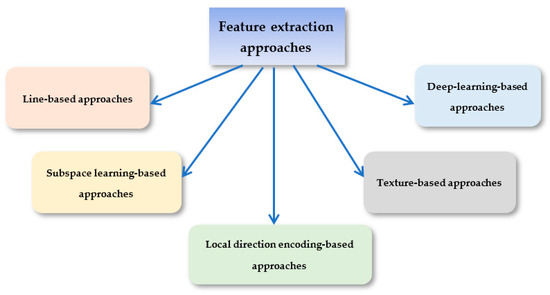
This paper presents a comprehensive survey examining the prevailing feature extraction methodologies employed within biometric palmprint recognition models. It encompasses a critical analysis of extant datasets and a comparative study of algorithmic approaches. Specifically, this review delves into palmprint recognition systems, focusing on
[...] Read more.
This paper presents a comprehensive survey examining the prevailing feature extraction methodologies employed within biometric palmprint recognition models. It encompasses a critical analysis of extant datasets and a comparative study of algorithmic approaches. Specifically, this review delves into palmprint recognition systems, focusing on different feature extraction methodologies. As the dataset wields a profound impact within palmprint recognition, our study meticulously describes 20 extensively employed and recognized palmprint datasets. Furthermore, we classify these datasets into two distinct classes: contact-based datasets and contactless-based datasets. Additionally, we propose a novel taxonomy to categorize palmprint recognition feature extraction approaches into line-based approaches, texture descriptor-based approaches, subspace learning-based methods, local direction encoding-based approaches, and deep learning-based architecture approaches. Within each class, most foundational publications are reviewed, highlighting their core contributions, the datasets utilized, efficiency assessment metrics, and the best outcomes achieved. Finally, open challenges and emerging trends that deserve further attention are elucidated to push progress in future research.
Full article
►▼
Show Figures
Open AccessArticle
Driver Attention Detection Based on Improved YOLOv5
by
Zhongzhou Wang, Keming Yao and Fuao Guo
Cited by 1 | Viewed by 1890
Abstract
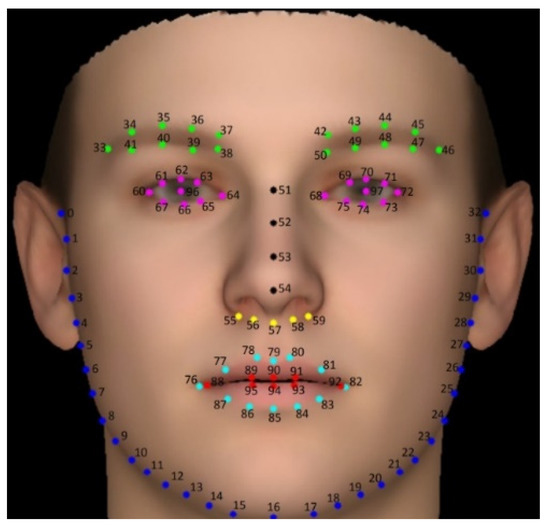
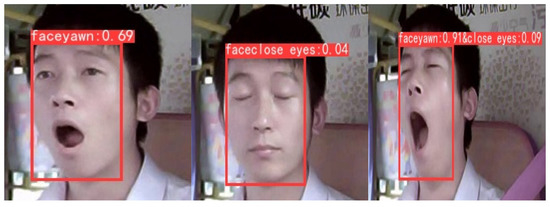
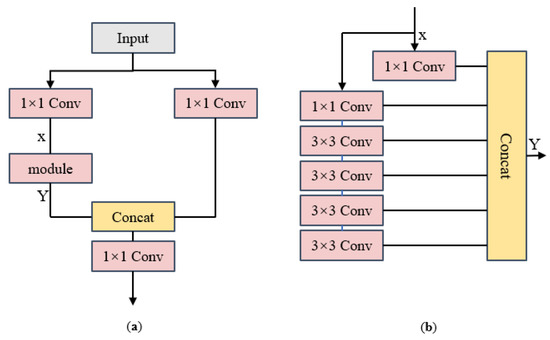
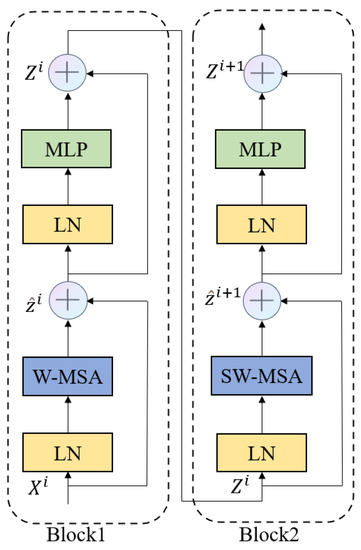
In response to negative impacts such as personal and property safety hazards caused by drivers being distracted while driving on the road, this article proposes a driver’s attention state-detection method based on the improved You Only Look Once version five (YOLOv5). Both fatigue
[...] Read more.
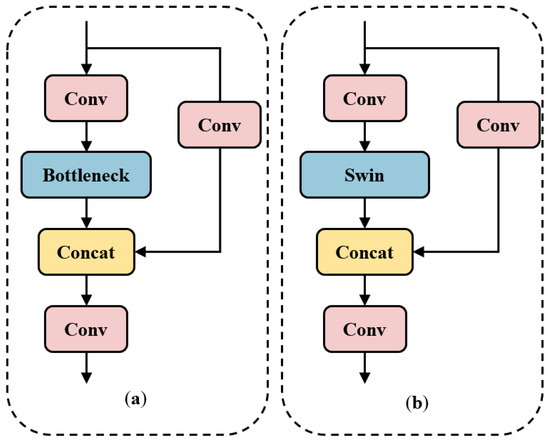
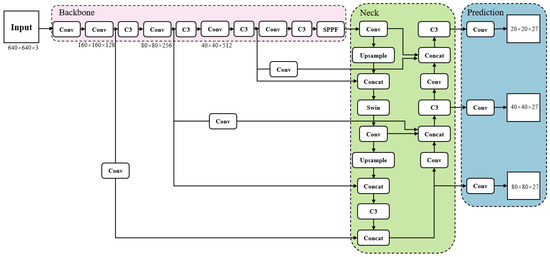
In response to negative impacts such as personal and property safety hazards caused by drivers being distracted while driving on the road, this article proposes a driver’s attention state-detection method based on the improved You Only Look Once version five (YOLOv5). Both fatigue and distracted behavior can cause a driver’s attention to be diverted during the driving process. Firstly, key facial points of the driver are located, and the aspect ratio of the eyes and mouth is calculated. Through the examination of relevant information and repeated experimental verification, threshold values for the aspect ratio of the eyes and mouth under fatigue conditions, corresponding to closed eyes and yawning, are established. By calculating the aspect ratio of the driver’s eyes and mouth, it is possible to accurately detect whether the driver is in a state of fatigue. Secondly, distracted abnormal behavior is detected using an improved YOLOv5 model. The backbone network feature extraction element is modified by adding specific modules to obtain different receptive fields through multiple convolution operations on the input feature map, thereby enhancing the feature extraction ability of the network. The introduction of Swin Transformer modules in the feature fusion network replaces the Bottleneck modules in the C3 module, reducing the computational complexity of the model while increasing its receptive field. Additionally, the network connection in the feature fusion element has been modified to enhance its ability to fuse information from feature maps of different sizes. Three datasets were created of distracting behaviors commonly observed during driving: smoking, drinking water, and using a mobile phone. These datasets were used to train and test the model. After testing, the mAP (mean average precision) has improved by 2.4% compared to the model before improvement. Finally, through comparison and ablation experiments, the feasibility of this method has been verified, which can effectively detect fatigue and distracted abnormal behavior.
Full article
►▼
Show Figures
Open AccessArticle
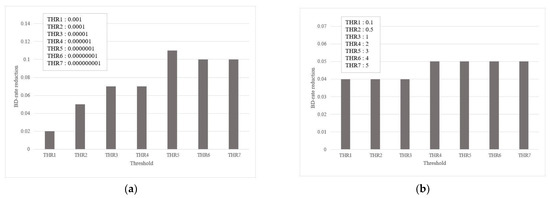
Improving OCR Accuracy for Kazakh Handwriting Recognition Using GAN Models
by
Arman Yeleussinov, Yedilkhan Amirgaliyev and Lyailya Cherikbayeva
Cited by 5 | Viewed by 1964
Abstract
This paper aims to increase the accuracy of Kazakh handwriting text recognition (KHTR) using the generative adversarial network (GAN), where a handwriting word image generator and an image quality discriminator are constructed. In order to obtain a high-quality image of handwritten text, the
[...] Read more.
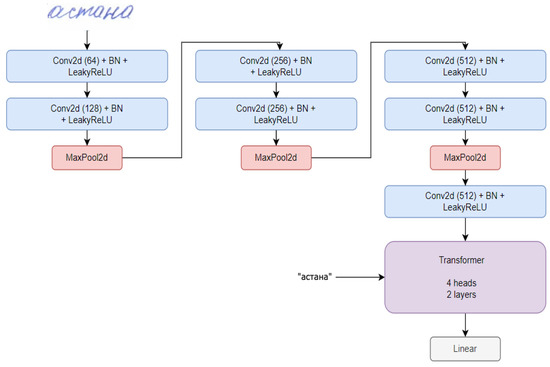
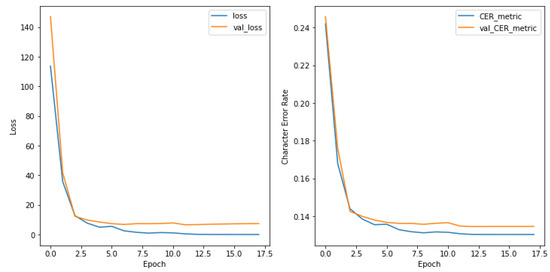
This paper aims to increase the accuracy of Kazakh handwriting text recognition (KHTR) using the generative adversarial network (GAN), where a handwriting word image generator and an image quality discriminator are constructed. In order to obtain a high-quality image of handwritten text, the multiple losses are intended to encourage the generator to learn the structural properties of the texts. In this case, the quality discriminator is trained on the basis of the relativistic loss function. Based on the proposed structure, the resulting document images not only preserve texture details but also generate different writer styles, which provides better OCR performance in public databases. With a self-created dataset, images of different types of handwriting styles were obtained, which will be used when training the network. The proposed approach allows for a character error rate (CER) of 11.15% and a word error rate (WER) of 25.65%.
Full article
►▼
Show Figures
Open AccessArticle
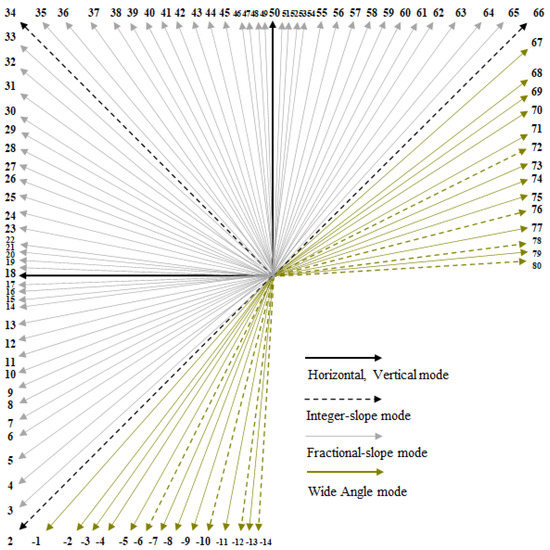
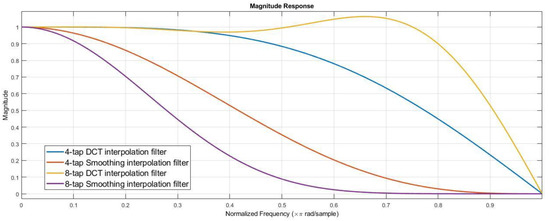
Frequency-Based Adaptive Interpolation Filter in Intra Prediction
by
Su-Yeon Lim, Min-Kyeong Choi and Yung-Lyul Lee
Viewed by 1331
Abstract
This paper proposes a method to improve the fractional interpolation of reference samples in the Versatile Video Coding (VVC) intra prediction. The proposed method uses additional interpolation filters which use more integer-positioned reference samples for prediction according to the frequency information of the
[...] Read more.
This paper proposes a method to improve the fractional interpolation of reference samples in the Versatile Video Coding (VVC) intra prediction. The proposed method uses additional interpolation filters which use more integer-positioned reference samples for prediction according to the frequency information of the reference samples. In VVC, a 4-tap Discrete Cosine Transform-based interpolation filter (DCT-IF) and 4-tap Smoothing interpolation filter (SIF) are alternatively performed on the block size and block directional prediction mode for reference sample interpolation. This paper uses four alternative interpolation filters such as 8-tap/4-tap DCT-IFs, and 4-tap/8-tap SIFs and an interpolation filter selection method using a high-frequency ratio calculated from one-dimensional (1D) transform of the reference samples are proposed. The proposed frequency-based Adaptive Filter allows to achieve the overall Bjøntegaard Delta (BD) rate gains of −0.16%, −0.13%, and −0.09% for Y, Cb, and Cr components, respectively, compared with VVC.
Full article
►▼
Show Figures
Open AccessArticle
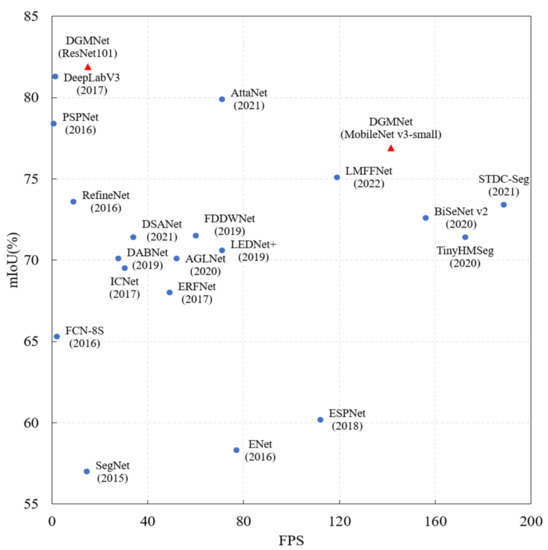
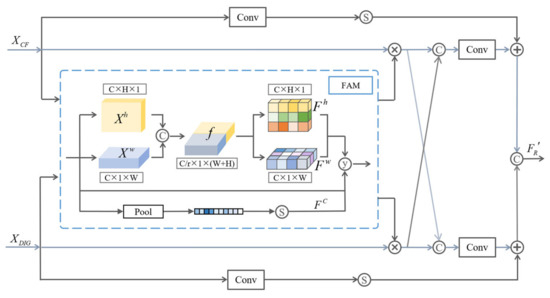
Detail Guided Multilateral Segmentation Network for Real-Time Semantic Segmentation
by
Qunyan Jiang, Juying Dai, Ting Rui, Faming Shao, Ruizhe Hu, Yinan Du and Heng Zhang
Viewed by 1330
Abstract
With the development of unmanned vehicles and other technologies, the technical demand for scene semantic segmentation is more and more intense. Semantic segmentation requires not only rich high-level semantic information, but also rich detail information to ensure the accuracy of the segmentation task.
[...] Read more.
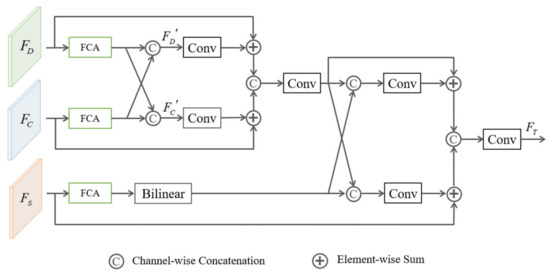
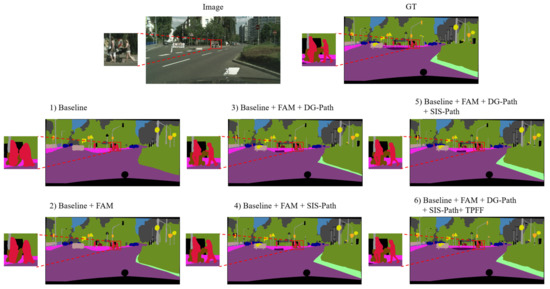
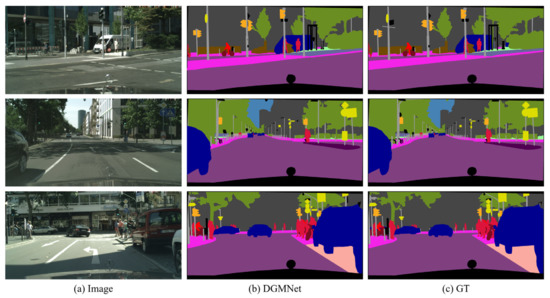
With the development of unmanned vehicles and other technologies, the technical demand for scene semantic segmentation is more and more intense. Semantic segmentation requires not only rich high-level semantic information, but also rich detail information to ensure the accuracy of the segmentation task. Using a multipath structure to process underlying and semantic information can improve efficiency while ensuring segmentation accuracy. In order to improve the segmentation accuracy and efficiency of some small and thin objects, a detail guided multilateral segmentation network is proposed. Firstly, in order to improve the segmentation accuracy and model efficiency, a trilateral parallel network structure is designed, including the context fusion path (CF-path), the detail information guidance path (DIG-path), and the semantic information supplement path (SIS-path). Secondly, in order to effectively fuse semantic information and detail information, a feature fusion module based on an attention mechanism is designed. Finally, experimental results on CamVid and Cityscapes datasets show that the proposed algorithm can effectively balance segmentation accuracy and inference speed.
Full article
►▼
Show Figures
Open AccessArticle
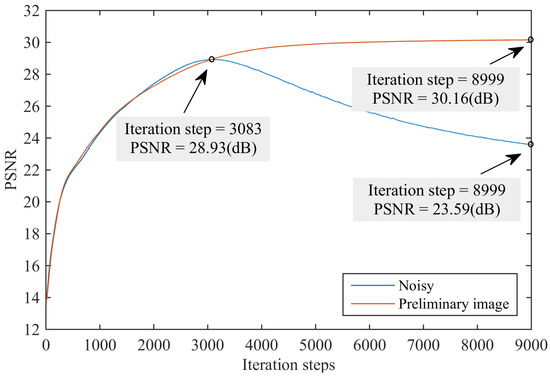
Learning from Multiple Instances: A Two-Stage Unsupervised Image Denoising Framework Based on Deep Image Prior
by
Shaoping Xu, Xiaojun Chen, Yiling Tang, Shunliang Jiang, Xiaohui Cheng and Nan Xiao
Cited by 2 | Viewed by 1406
Abstract
Supervised image denoising methods based on deep neural networks require a large amount of noisy-clean or noisy image pairs for network training. Thus, their performance drops drastically when the given noisy image is significantly different from the training data. Recently, several unsupervised learning
[...] Read more.
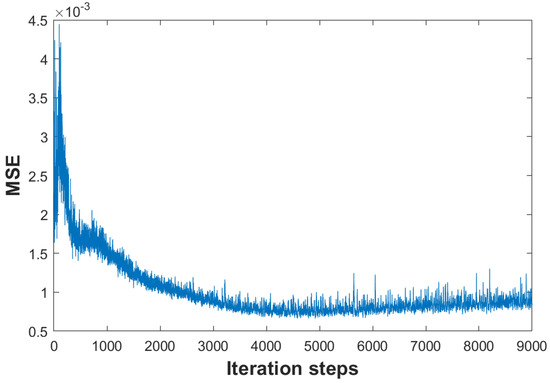
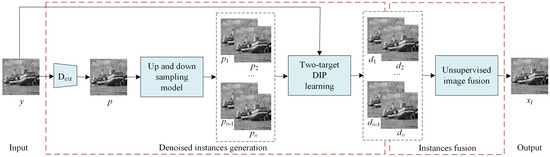
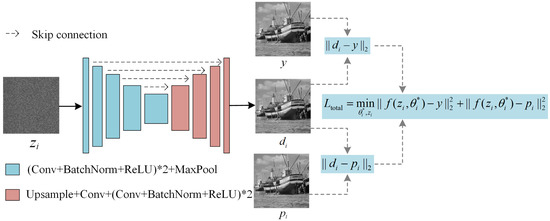
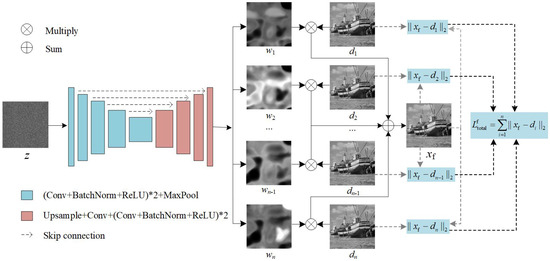
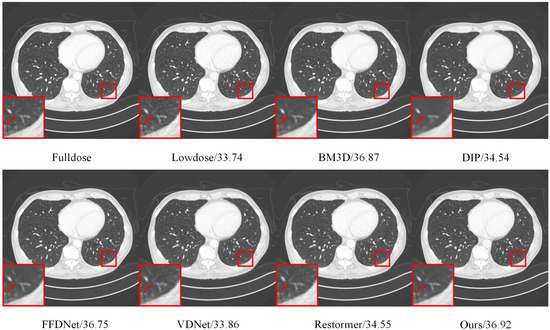
Supervised image denoising methods based on deep neural networks require a large amount of noisy-clean or noisy image pairs for network training. Thus, their performance drops drastically when the given noisy image is significantly different from the training data. Recently, several unsupervised learning models have been proposed to reduce the dependence on training data. Although unsupervised methods only require noisy images for learning, their denoising effect is relatively weak compared with supervised methods. This paper proposes a two-stage unsupervised deep learning framework based on deep image prior (DIP) to enhance the image denoising performance. First, a two-target DIP learning strategy is proposed to impose a learning restriction on the DIP optimization process. A cleaner preliminary image, together with the given noisy image, was used as the learning target of the two-target DIP learning process. We then demonstrate that adding an extra learning target with better image quality in the DIP learning process is capable of constraining the search space of the optimization process and improving the denoising performance. Furthermore, we observe that given the same network input and the same learning target, the DIP optimization process cannot generate the same denoised images. This indicates that the denoised results are uncertain, although they are similar in image quality and are complemented by local details. To utilize the uncertainty of the DIP, we employ a supervised denoising method to preprocess the given noisy image and propose an up- and down-sampling strategy to produce multiple sampled instances of the preprocessed image. These sampled instances were then fed into multiple two-target DIP learning processes to generate multiple denoised instances with different image details. Finally, we propose an unsupervised fusion network that fuses multiple denoised instances into one denoised image to further improve the denoising effect. We evaluated the proposed method through extensive experiments, including grayscale image denoising, color image denoising, and real-world image denoising. The experimental results demonstrate that the proposed framework outperforms unsupervised methods in all cases, and the denoising performance of the framework is close to or superior to that of supervised denoising methods for synthetic noisy image denoising and significantly outperforms supervised denoising methods for real-world image denoising. In summary, the proposed method is essentially a hybrid method that combines both supervised and unsupervised learning to improve denoising performance. Adopting a supervised method to generate preprocessed denoised images can utilize the external prior and help constrict the search space of the DIP, whereas using an unsupervised method to produce intermediate denoised instances can utilize the internal prior and provide adaptability to various noisy images of a real scene.
Full article
►▼
Show Figures
Open AccessArticle
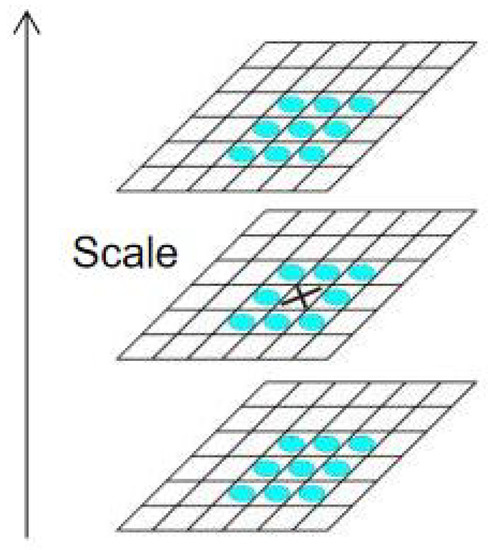
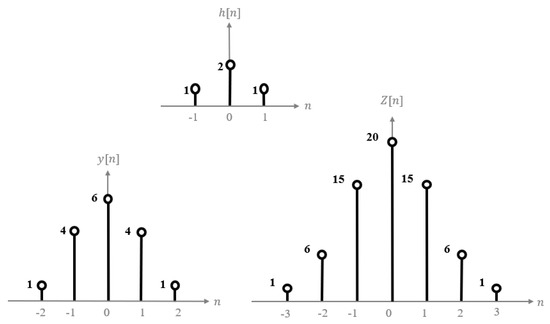
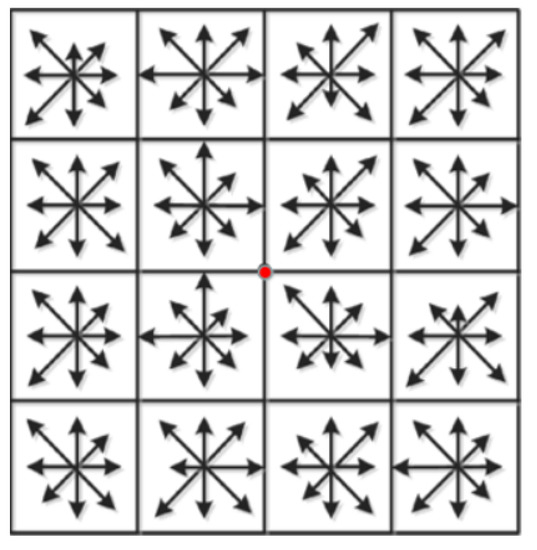
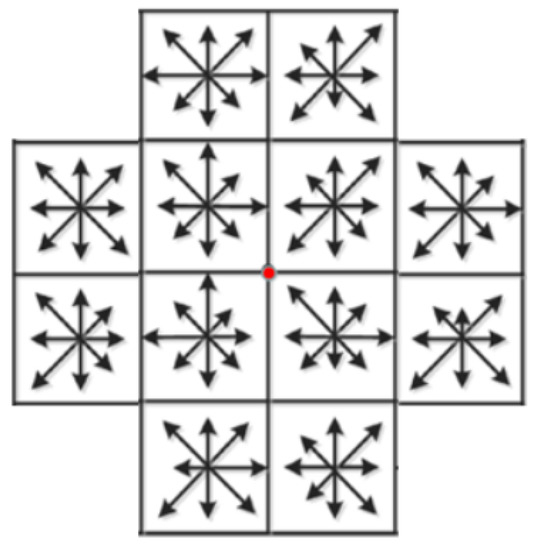
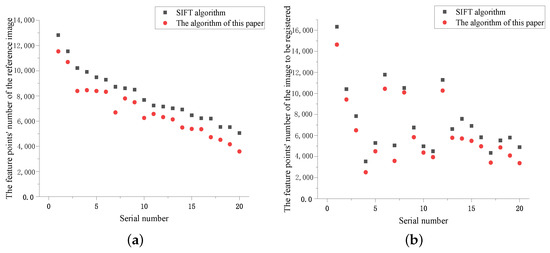
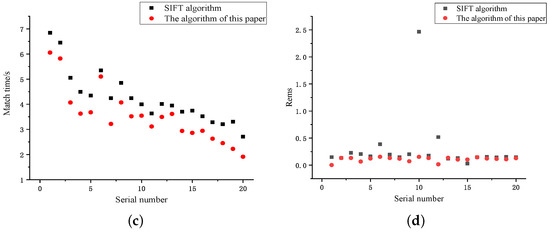
Research on Image Matching of Improved SIFT Algorithm Based on Stability Factor and Feature Descriptor Simplification
by
Liang Tang, Shuhua Ma, Xianchun Ma and Hairong You
Cited by 6 | Viewed by 2470
Abstract
In view of the problems of long matching time and the high-dimension and high-matching rate errors of traditional scale-invariant feature transformation (SIFT) feature descriptors, this paper proposes an improved SIFT algorithm with an added stability factor for image feature matching. First of all,
[...] Read more.
In view of the problems of long matching time and the high-dimension and high-matching rate errors of traditional scale-invariant feature transformation (SIFT) feature descriptors, this paper proposes an improved SIFT algorithm with an added stability factor for image feature matching. First of all, the stability factor was increased during construction of the scale space to eliminate matching points of unstable points, speed up image processing and reduce the dimension and the amount of calculation. Finally, the algorithm was experimentally verified and showed excellent results in experiments on two data sets. Compared to other algorithms, the results showed that the algorithm proposed in this paper improved SIFT algorithm efficiency, shortened image-processing time, and reduced algorithm error.
Full article
►▼
Show Figures




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}