1. Introduction
Hyperspectral imaging is a technique that acquires data from many narrow and contiguous spectral bands, enabling spectral signatures of various materials to be detected. Hyperspectral images, HSIs, produce data cubes that consist of a set of two-dimensional images, where each pixel contains the reflectance or radiance values at different wavelengths or bands. HSI classification is a process of assigning each pixel in an HSI to one of several predefined classes, which presents a challenging task due to the high-dimensional nature of hyperspectral data and the complexity of spectral signatures. HSI classification algorithms are designed to extract useful information from the hyperspectral data and map this information to the predefined classes. This process involves the use of mathematical algorithms and statistical techniques to analyse the spectral information contained in each pixel.
HSI classification algorithms have a wide range of applications, including mineral and oil exploration and environmental monitoring [
1,
2,
3,
4,
5]. In mineral and oil exploration [
6], hyperspectral imaging can be used to identify the presence of specific minerals or hydrocarbons based on their unique spectral signatures. Environmental monitoring applications include the detection of pollutants and the mapping of vegetation types [
7,
8].
Many algorithms have been developed for HSI classification, including supervised, unsupervised, and hybrid approaches. Supervised algorithms rely on prior knowledge about the spectral properties of the target of interest, and use this information to train a classification model. The most common supervised classification algorithm employed in hyperspectral imaging is the maximum likelihood classifier [
9]. This algorithm assumes that the spectral response of each target class is normally distributed, and calculates the probability that each pixel belongs to each class. The pixel is then classified to the class with the highest probability. Other supervised classification algorithms include support vector machines [
10], decision trees [
11], and artificial neural networks [
12]. Unsupervised classification algorithms include clustering algorithms such as k-means [
13], hierarchical clustering [
14], and self-organizing maps [
15,
16]. These algorithms group pixels into clusters based on their spectral similarity, without any prior knowledge of the target classes. The resulting clusters can then be labelled and classified based on their spectral properties. Hybrid algorithms combine the strengths of both supervised and unsupervised approaches. For example, a hybrid algorithm might use an unsupervised clustering algorithm to group pixels into clusters, and then use a supervised algorithm to assign labels to the clusters based on prior knowledge of the target classes.
The traditional algorithms mentioned above mostly focus on classifying different extracted features [
17]. With the development of deep learning research [
18], HSI classification methods have gradually shifted to extracting and classifying high-level deep features. Convolutional neural network (CNN)-based methods are widely used due to their end-to-end architecture and good classification properties. These architectures consist of multiple layers of convolutional and pooling operations, which are used to learn hierarchical features from the input data. The classifier in the end learns to classify each pixel based on the features learned from the input data, and the final output of the algorithm is a classification map that assigns a label or class to each pixel in the HSI.
The deep belief network (DBN) [
19], stacked autoencoder (SAE) [
20], and recurrent neural network (RNN) [
21] treat each HSI pixel as independent spectral signatures for deep learning networks, which cannot extract sufficient information. Chen et al. [
22] first designed a CNN framework extracting simple deep features from HSIs. To extract more convincing features, researchers developed the backbone for deep learning networks, such as GoogleNet [
23] and Resnet [
24], with skip architectures. Zhong et al. [
25] proposed the framework of a 3D CNN with the residual block from Resnet and obtained deeper features for classification. One recently proposed HSI classification algorithm is the residual attention network (RAN), proposed by Wang et al. [
26]. RAN is a deep-learning-based algorithm that integrates residual connections and attention mechanisms to improve the classification performance. The residual connections help to alleviate the vanishing gradient problem and enable the network to learn more complex features, while the attention mechanism helps to focus on discriminative features and suppress noisy ones. Experimental results on several benchmark hyperspectral datasets demonstrated that RAN outperforms many state-of-the-art methods in terms of classification accuracy. The CNN-based HSI classification algorithms have been shown to be effective at achieving high levels of classification accuracy, particularly when large amounts of labelled training data are available.
With the development of natural language processing (NLP) technology, the transformer architecture shows a strong feature extraction ability, especially when applied to the vision tasks. Vision transformer [
27] has been applied to computer vision (CV) and shown exciting results. He et al. [
28] designed a BERT-like architecture, which flattens the HSI cube as a sequence of the transformer input. Hong et al. [
29] proposed the SpectralFormer network, which learns information from neighbouring bands. However, the current transformer-based methods for HSI classification introduce feature inconsistencies generated by a large number of differences between different bands when directly inputting samples into adjacent bands as a sequence, resulting in insufficient feature-extraction capabilities. Furthermore, the network fails to consider the correlation between the feature channels when modelling the input vector.
We proposed a multidimensional spectral transformer with channel-wise correlation (MSTCC) to combine neighbouring band features and feed them to vectors used to classify their differences. The main contributions of this paper are as follows:
To overcome difficulties that arise when extracting global features with a CNN, we proposed a transformer-based network architecture to better extract long-range relationship features of cube bands from HSIs;
To better combine the related features between bands of different dimensions, we proposed a channel-related feature extraction method;
Combining all the above-mentioned points, we proposed a new method for HSI classification. We also validated the proposed model using several comparison methods, revealing that it achieved great results on the studied datasets.
3. Our Methods
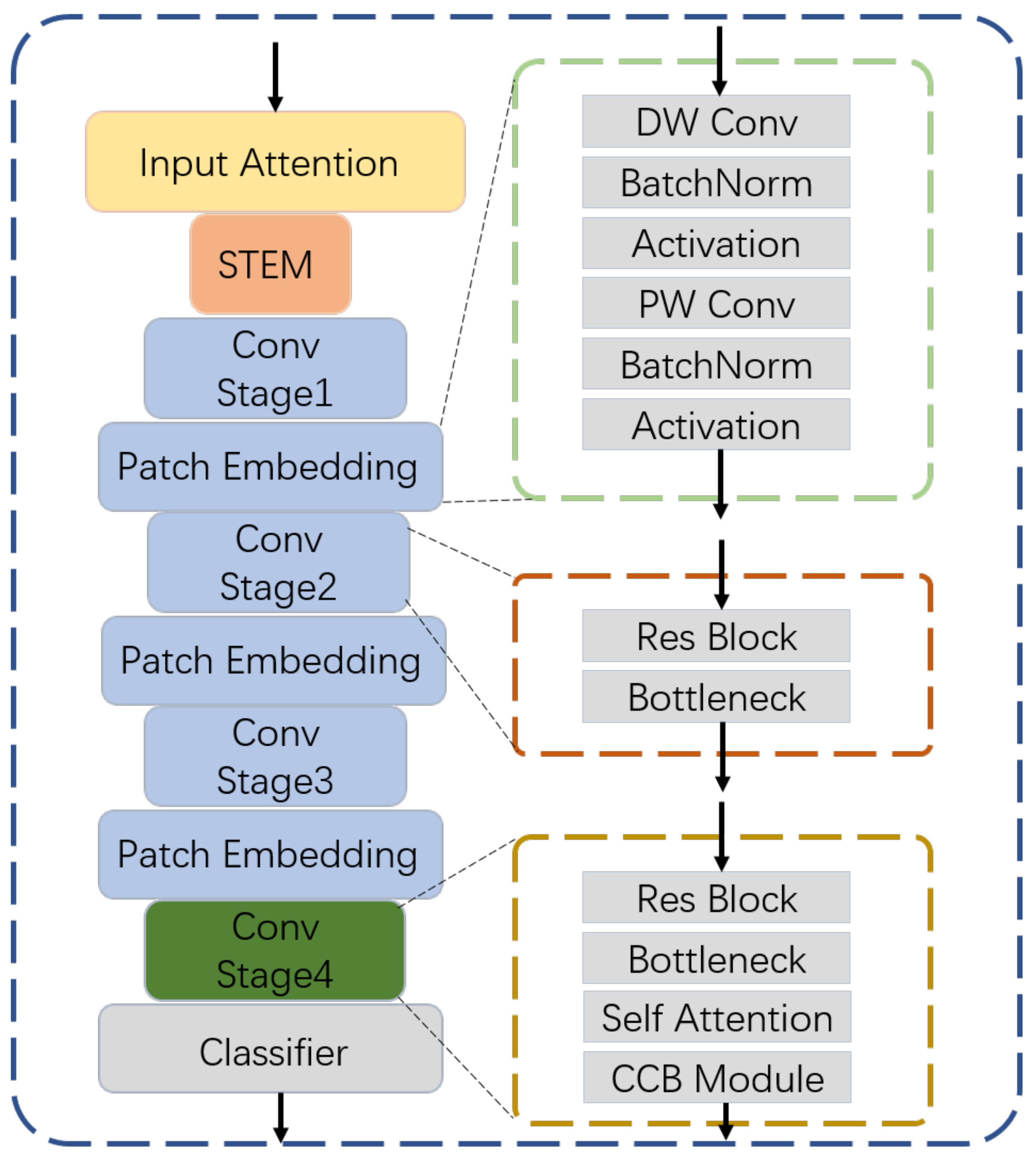
Our MSTCC is based on the transformer architecture with a well-designed CCB (channel correlation block) module. We did not manually set the fixed region, instead the network searches pixels via an attention-based method which preserves the feature stability of the region. The overall framework of the MSTCC is shown in
Figure 1.
Our architecture is based on the transformer methods, which contain patch embedding modules and convolutional modules for feature extraction. The patch embedding module consists of depth-wise convolution layers, point-wise convolution, batch normalization layers and activation layers. The depth-wise convolution layers and the point-wise convolution layers are used to increase feature latitudes and reduce computational complexity. The activation layers in our method is the ReLU activation, which achieved great results in classification tasks.
3.1. Input Mask for Training
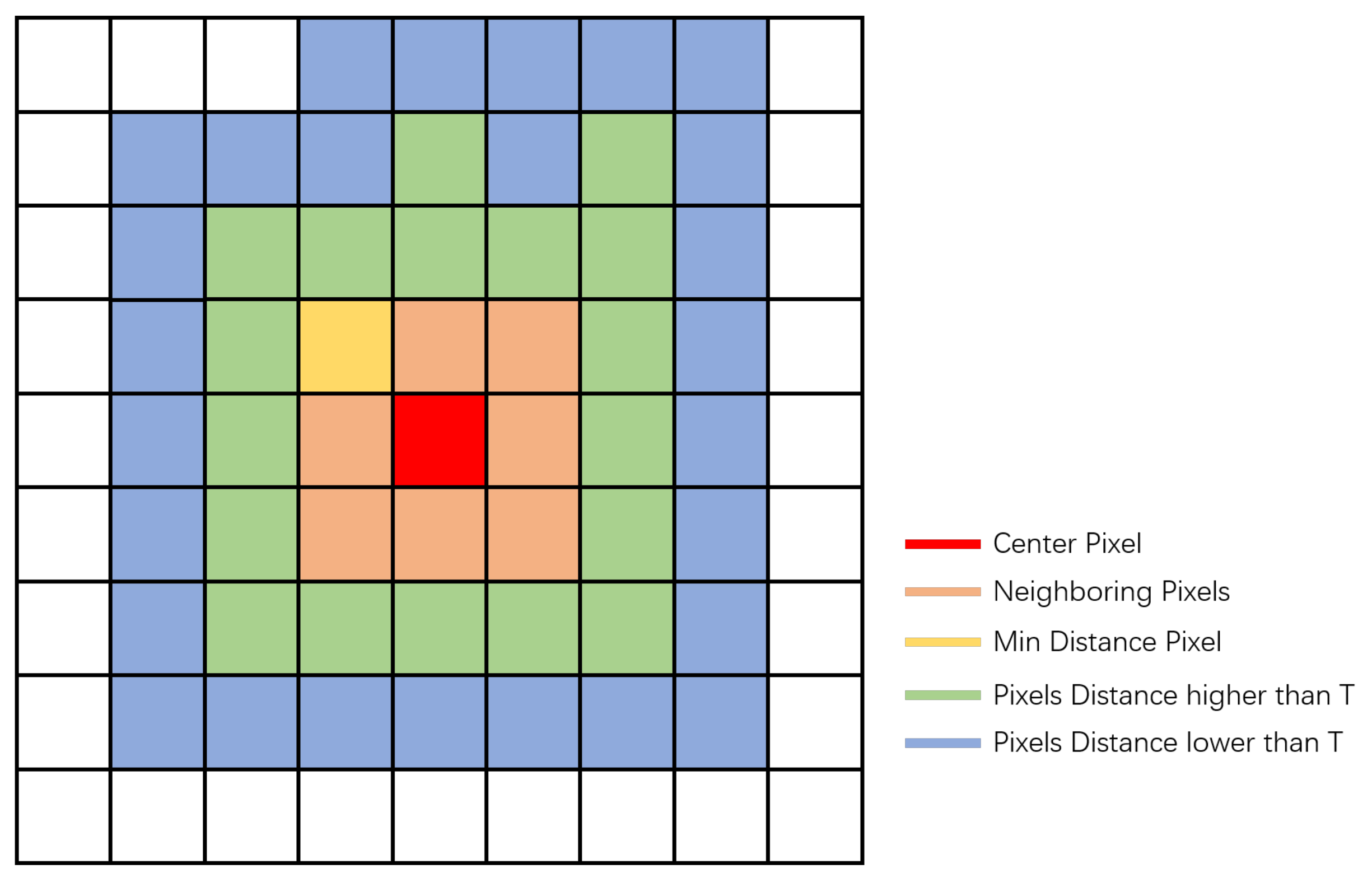
The relationship between adjacent pixels is different, so the length of the image cube as the input should change accordingly to improve the effectiveness of feature extraction. We suppose that the input dataset is .
For each ( pixel in the image), we calculated the correlation distance between it and surrounding pixels, taking a minimum of eight adjacent pixels as the threshold , recording all correlation distances as . We calculated the correlation between each point and the centre pixel extending from the centre along the horizontal and vertical directions, and added the distance to D until its value was less than .
All similar distances in
D were normalized as coefficients of the corresponding pixel points, where the coefficient for pixel
i was computed via the following equation:
where
i and
j indicate the indices of the centre pixel and its correlated pixel for
. We extracted the feature vectors by two
convolutional layers,
and
, which were used to transform the multidimensional features to one dimension with the coefficient
for each pixel. In our experiments, the parameters of these two layers were learnt from training. The correlation between the two pixels was computed using the Gaussian distance. This attention-based method is shown in
Figure 2.
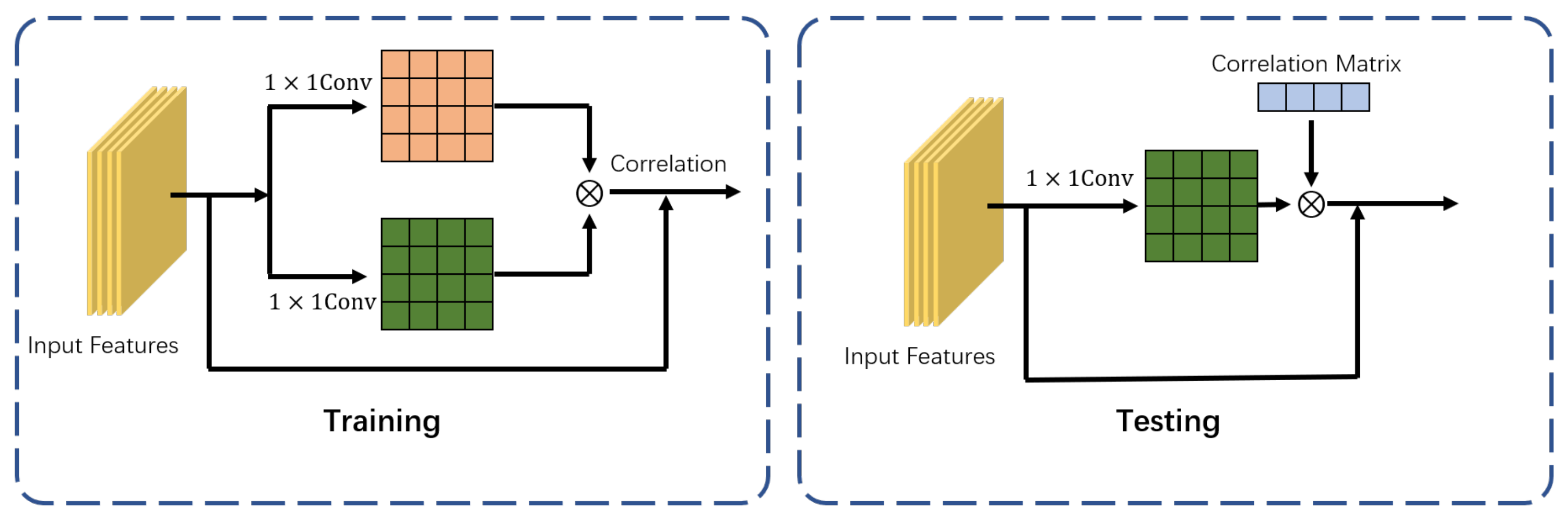
3.2. Channel Correlation Block
In view of the poor ability of network classifiers to identify similar features, we proposed a channel-wise method to extract the features by designing a channel correlation module. The module architecture is shown in
Figure 3. When extracting features into the classifier during training, the channel correlation matrix converts the feature information as a learnable parameter and adds it to the self-attention module of the fourth stage.
5. Discussion
In this work, we proposed two aspects for HSI classification:
- 1.
To extract HSI image features, and strengthen the connection between adjacent pixels, we proposed a transformer-based architecture with a mask input. This improved network performance in training.
- 2.
To enhance the classifier’s ability to discriminate between the input features, we proposed the channel correlation block (CCB) module to enhance its ability to distinguish between similar features.
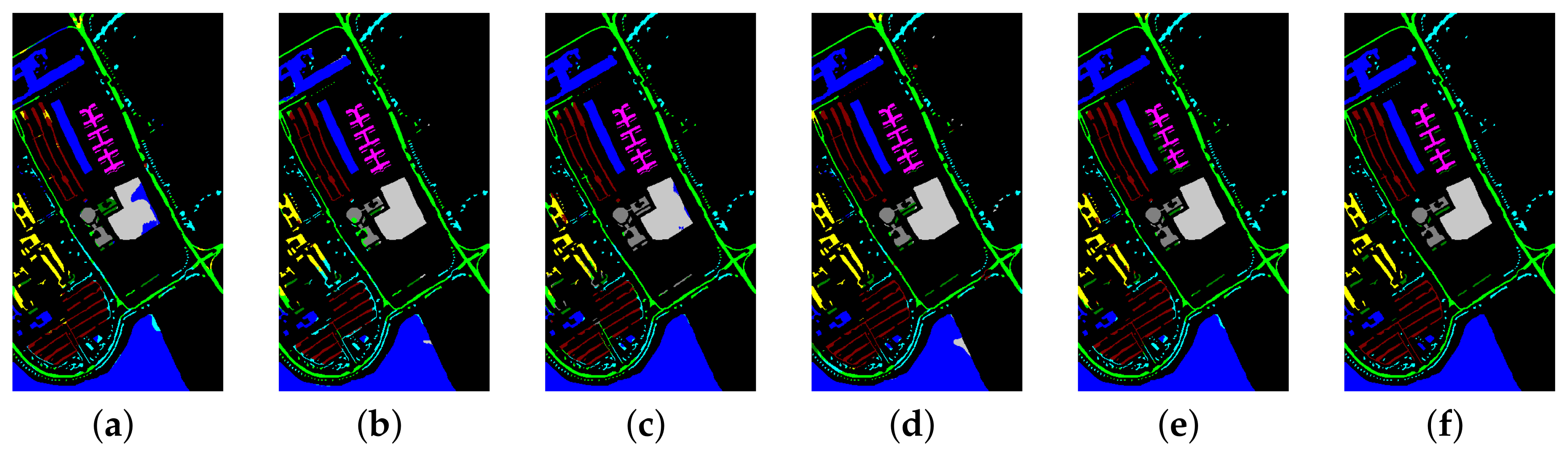
Our proposed method shows that the transformer-based model can better extract global features than the CNN model, rather than just localized features. The correlation between different channels can better help the model distinguish HSI categories. We set up three CNN-based methods and one transformer-based method to conduct comparative experiments with our transformer-based method. The OA and Kappa coefficients of the latter two groups were higher than the former on the three datasets, proving the effectiveness of global feature classification.
For the two modules proposed, ablation experiments were set up to analyse their effectiveness. It can be seen from the OA and Kappa indicators that the CCB module performed better than the input mask. This shows that the correlation of deep features can more effectively distinguish features and improve the discriminative ability of the classifiers. The input mask, being a priori information for feature extraction, can reduce invalid information extraction in model training and improve the classification accuracy. These two methods improve the feature extraction ability of the model at different levels. The two components can be added to the model at the same time, and they achieved the best accuracy on three datasets, outperforming in the other individual settings in the ablation experiment.
For the input mask component, we found that the pixel correlation of each pixel in its various directions decreased significantly with distance. The correlation between features exceeding a certain distance threshold and the features of the point pixel was low, so the mask input aided the model to focus on the feature information of each pixel to improve feature discrimination.
Regarding the channel correlation block component, we found that in the last stage of the transformer architecture, the self-attention module was used to strengthen the mutual discrimination between pixel features. The similarity between features can be computed, together with the self-attention module, to provide high-quality features for the classifier.
As a method of processing at the beginning, the input mask received low-level features with spatial sparsity, resulting in instability in the different inputs. For example, compared with the baseline on the PU dataset, the classification accuracy decreased slightly for the model with the input mask. However, in general, adding the mask to an image effectively focussed in on high-value feature information and improved the accuracy of model classification. In contrast, the CCB module with deep features and dense information increased the similar feature extraction ability of the classifier.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}