
Analysis of Machine Learning Techniques for Information Classification in Mobile Applications

Abstract
:1. Introduction
2. Challenges and Issues
3. Architectures for Machine Learning on Mobile Devices
3.1. Cloud
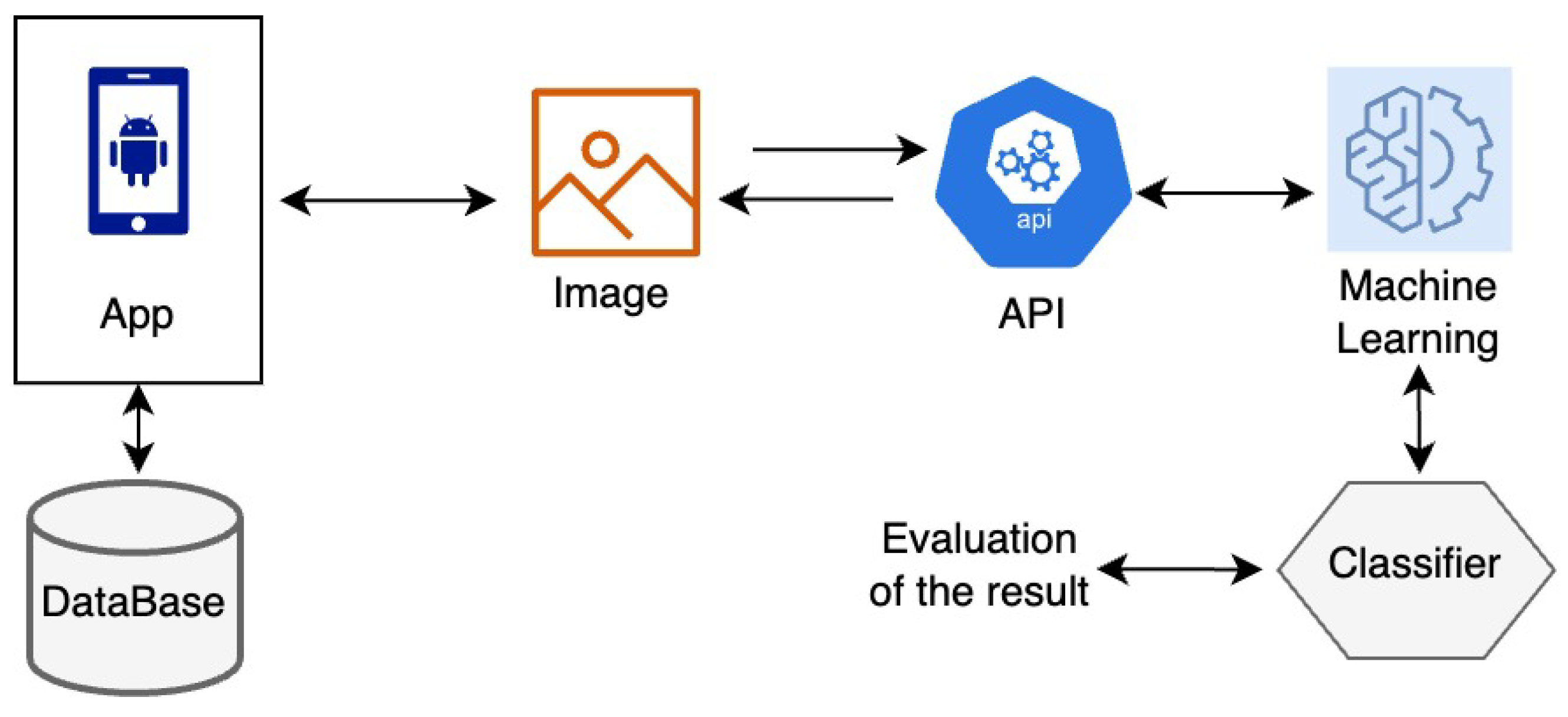
3.1.1. Testing without Training
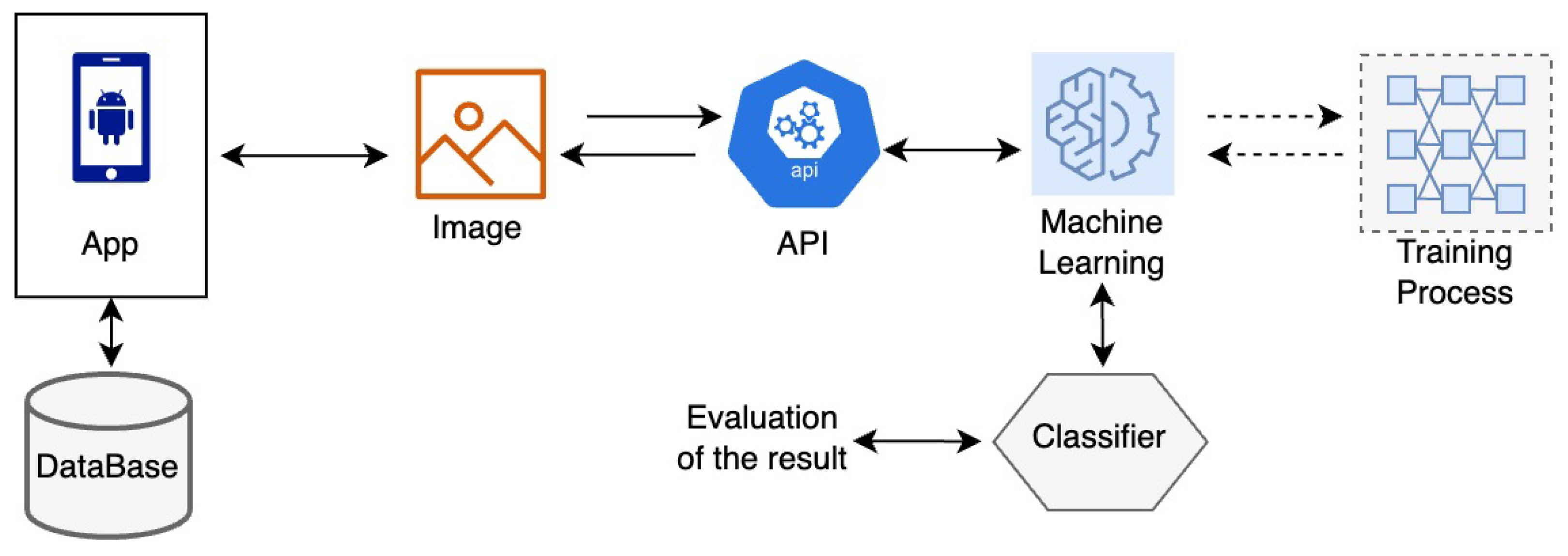
3.1.2. Training and Testing
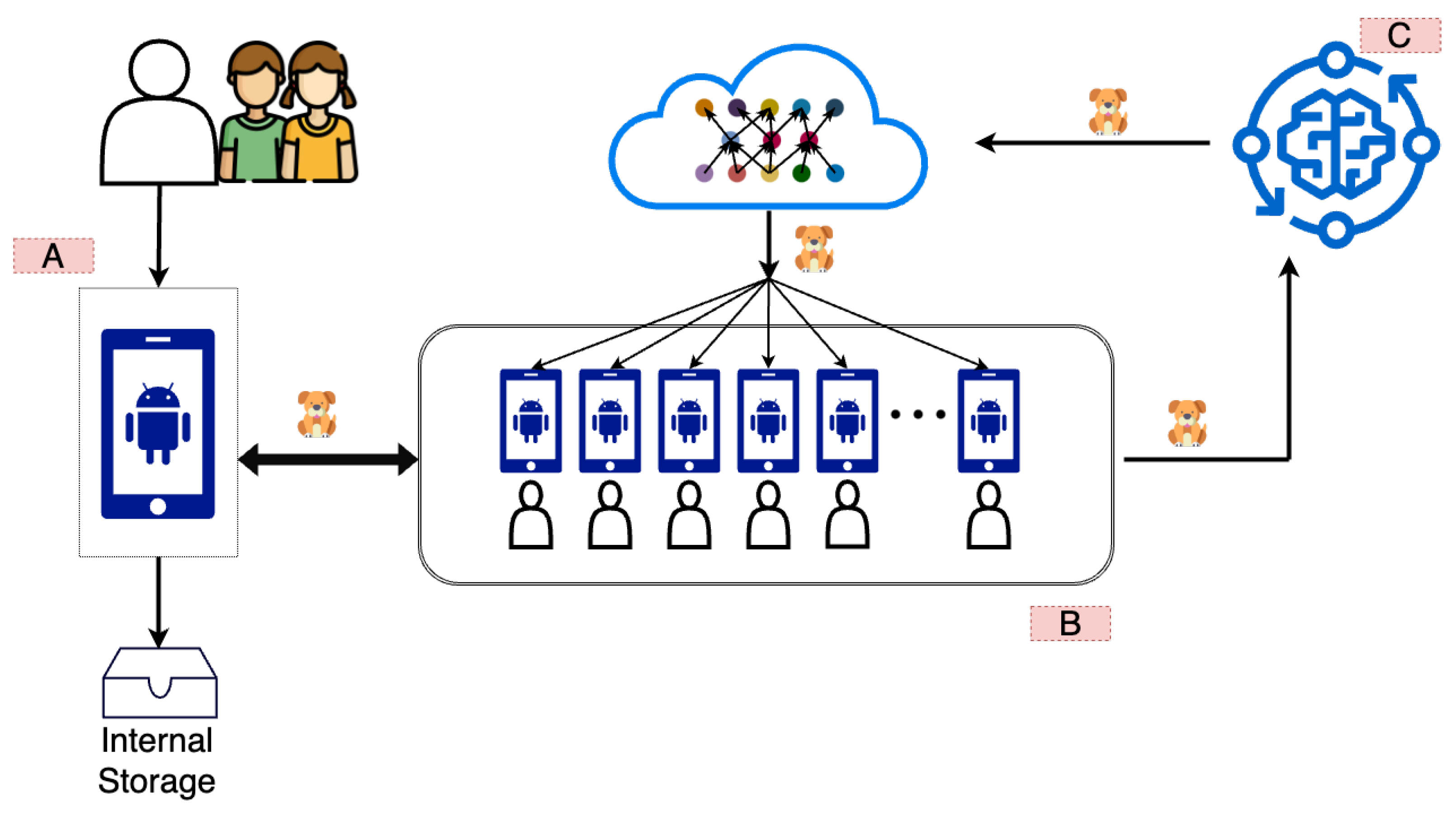
3.2. On-Device Architecture
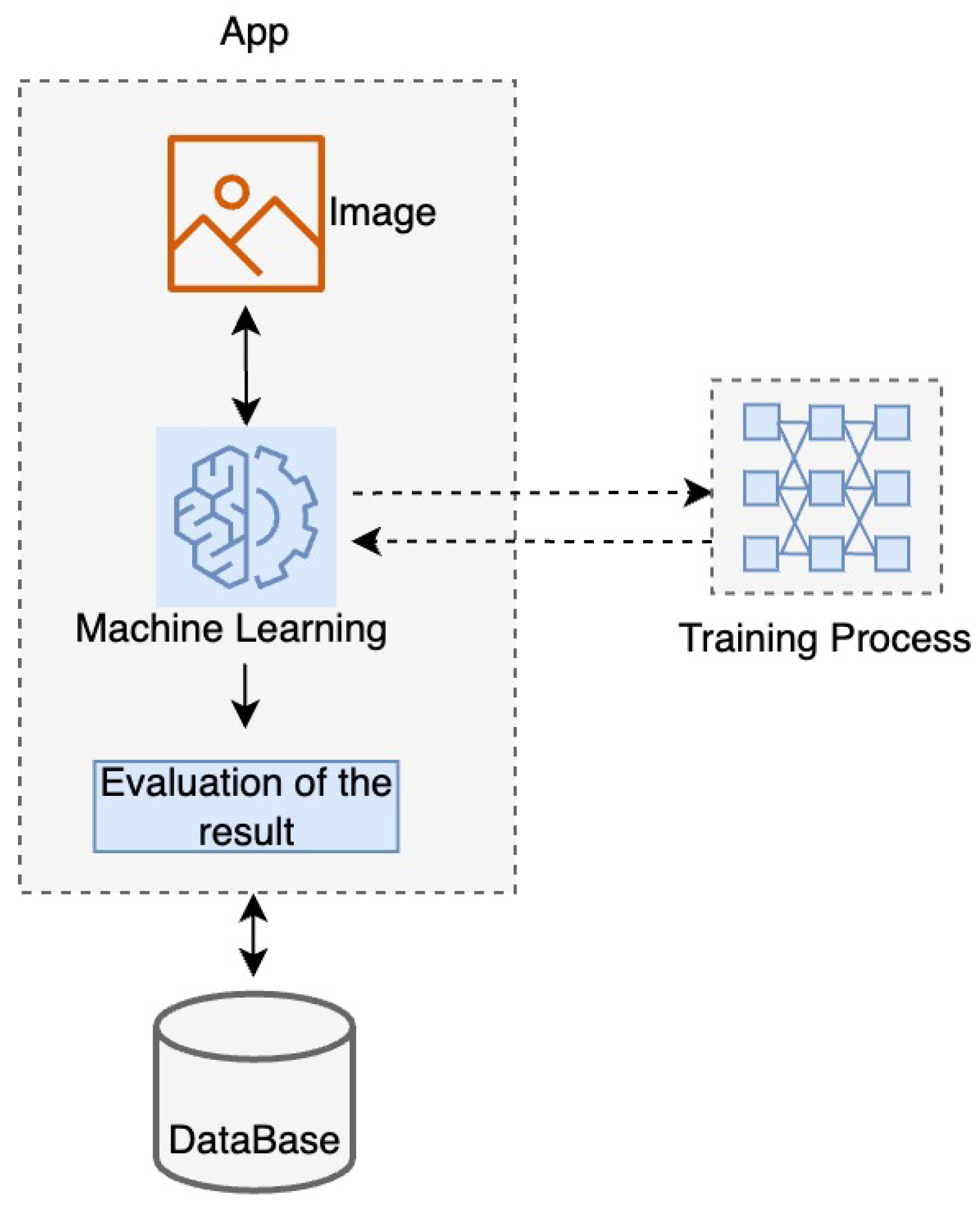
3.2.1. On-Device Testing with Pretrained Models
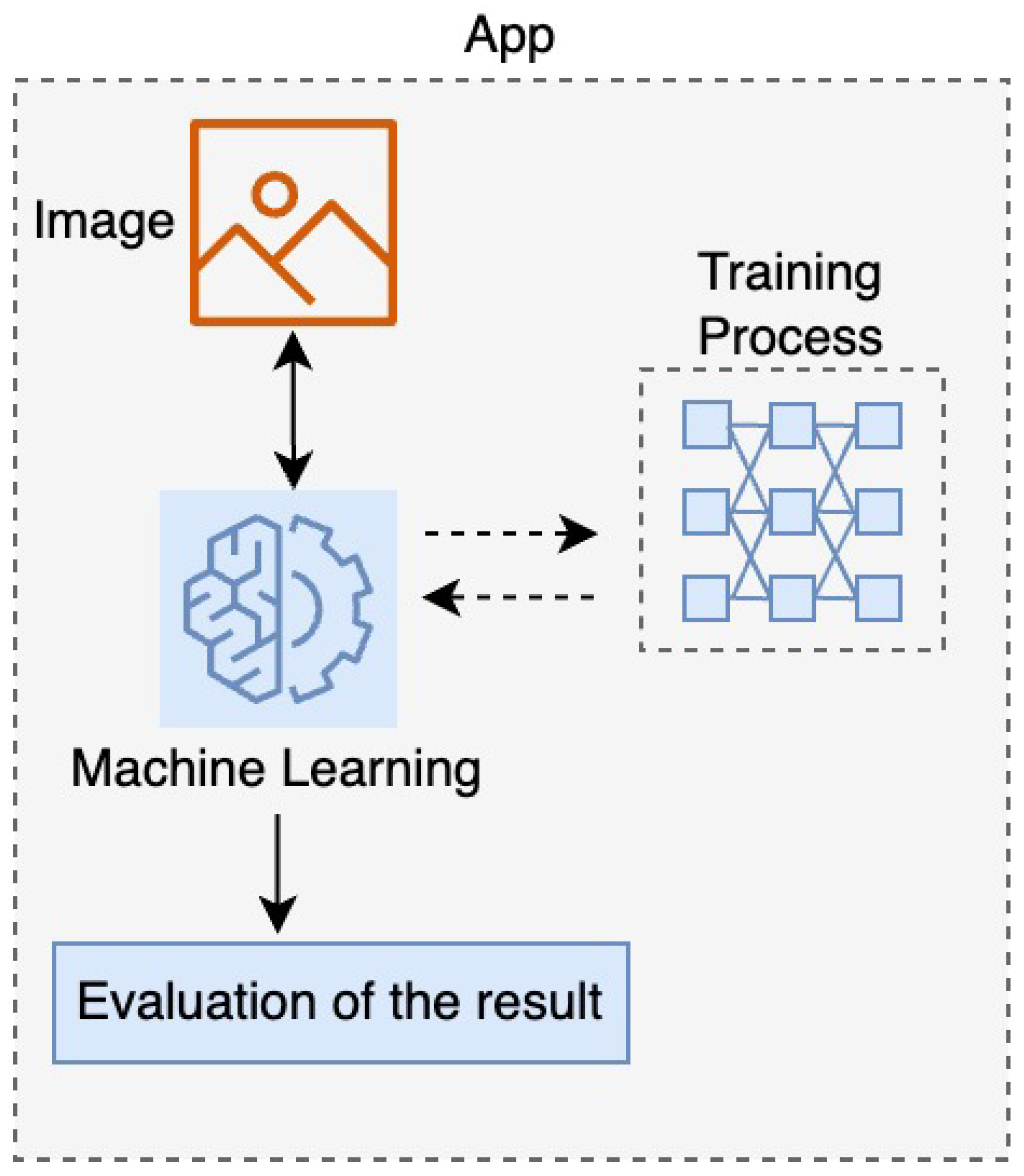
3.2.2. Training and Testing on the Device
3.3. Hybrid
4. Image and Video Classification Algorithms on Mobile Devices
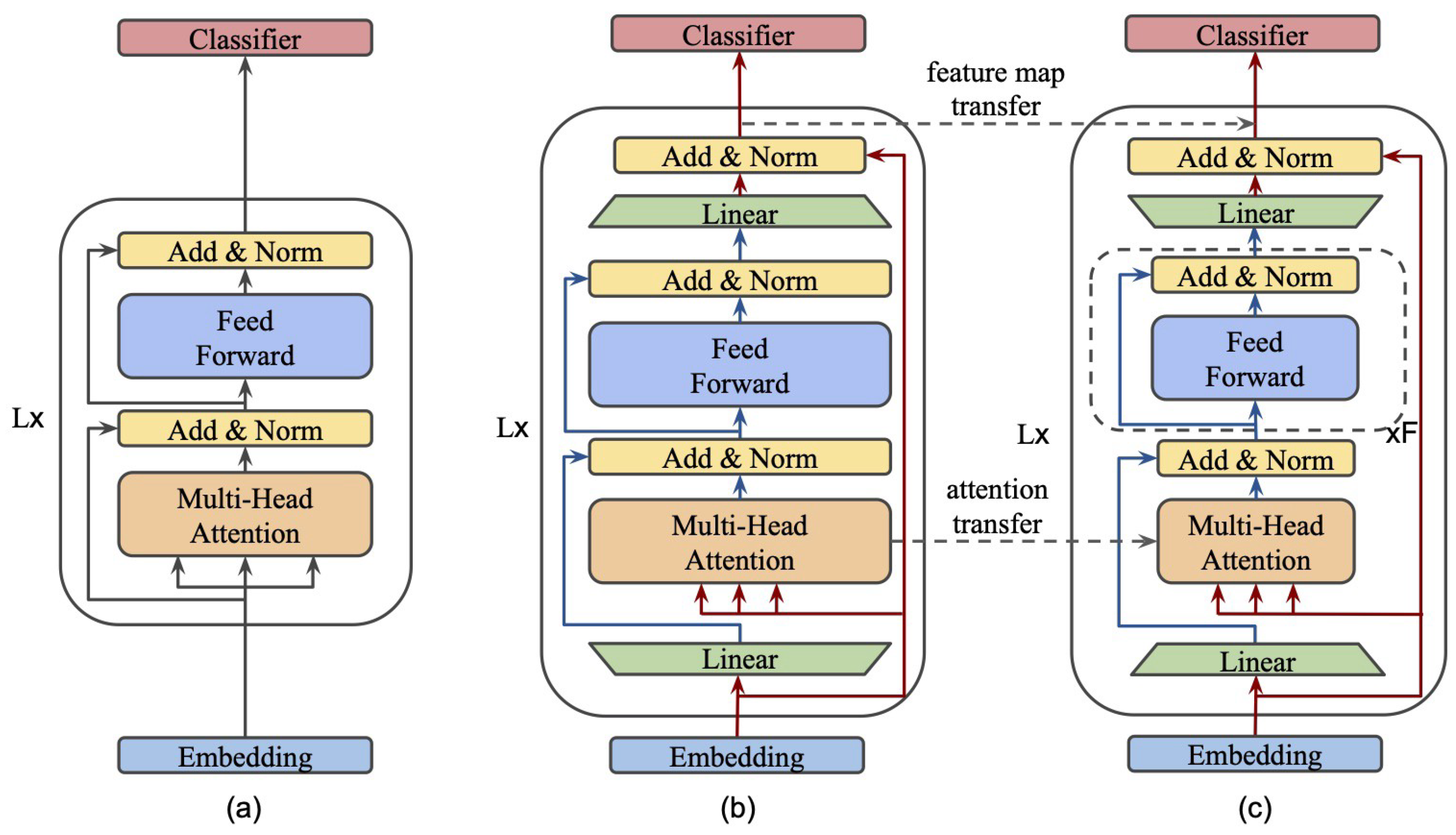
4.1. MobileNet
- MobileNetV3: This version of the model is based on the EfficientNet search method with specific parameter space targets required for use on mobile devices. It is a lightweight model that allows for image classification with low inference times and fits architectures with limited computational resources [32,33].
MobileNet Architecture
4.2. EfficientNet
4.2.1. EfficientNet Architecture
4.2.2. EfficientNet Variants
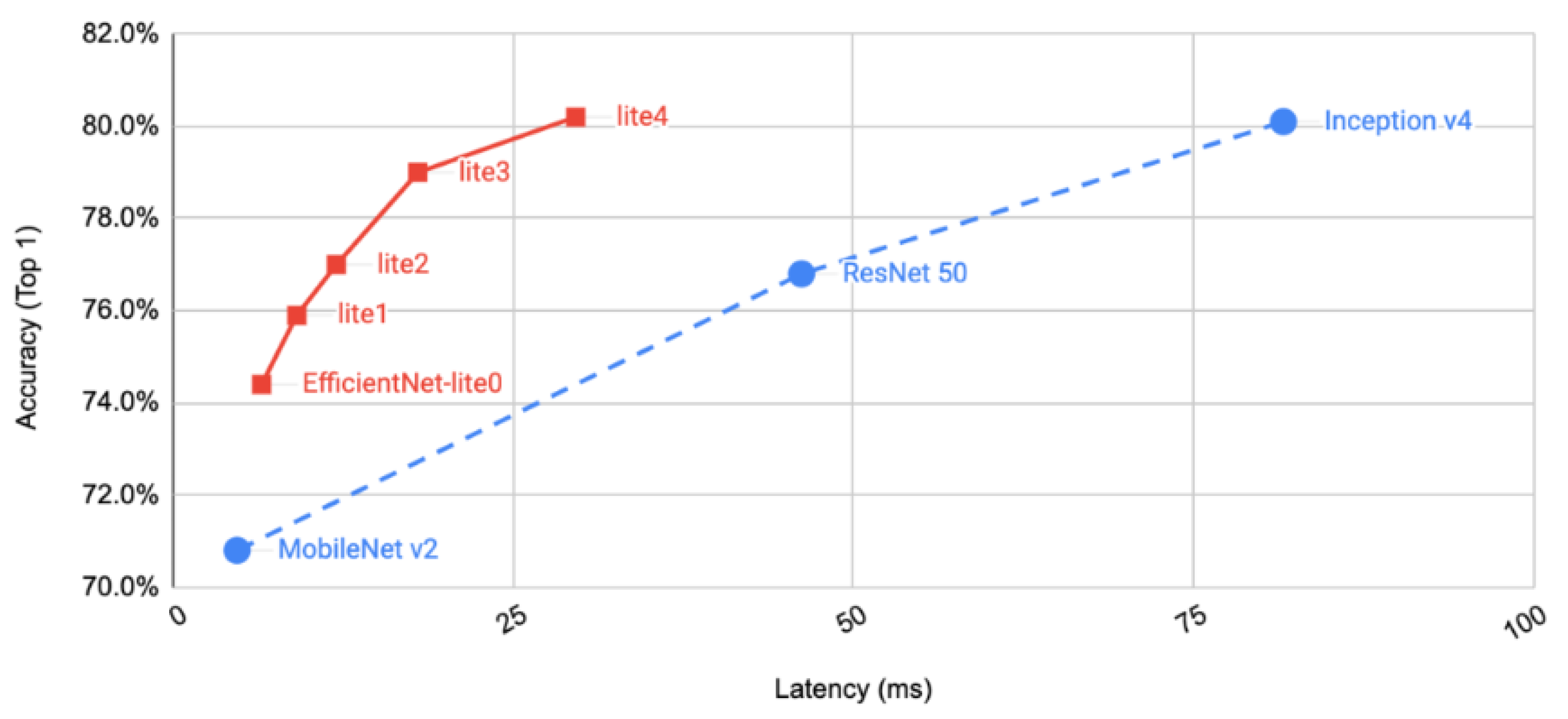
4.2.3. EfficientNet-Lite
5. Text Analytics Algorithms on Mobile Devices
6. Frameworks for Mobile Devices
- TensorFlow Lite: Is a computational intelligence platform for local inference designed primarily for low-resource computing hardware such as mobile devices and embedded and edge systems. It enables on-device artificial intelligence by supporting programmers in running their models on relevant hardware and IoT devices [69]. This tool provides various methods of optimisation, compression and conversion of an ML model into a tflite format. This platform ensures data security through local device training without the need for an Internet connection [70].
- OpenCV: OpenCV is an open-source computer library developed in C and C++ on Linux, Windows and MacOS X with support for Python, Ruby Matlab and other languages [71]. It also supports mobile applications, which allows for the development of applications that require face recognition, object detection, image processing and manipulation, etc.
- The ML Kit by Google: Is a free mobile development SDK for Google’s machine learning model in Android and iOS applications. It has features in its computer vision and natural language processing APIs. All ML Kit APIs run on the device, enabling real-time use cases. This also means that the functionality is available offline [72].
- Core ML: Is a machine learning development kit for Apple devices. It offers easy integration of machine learning models into applications. This library allows the user to transform models generated by other libraries using the ML Core utility, in addition to allowing users to preview the model directly from Xcode and download it using the ML Core Ready utility. It also allows the user to transform models from other types of libraries using Core ML Converters or downloaded ready-made Core ML models and preview the model easily or directly in Xcode. Furthermore, the kit allows the user to create computer vision, natural language, speech and audio models [73].
- Google Cloud AI: Tools use Google technologies to help developers solve common AI problems. Google AI continuously updates products and implemented algorithms in order to achieve the best inference results for developers. Google AI features include speech-to-text conversion, natural language processing and optical character recognition, among others [74].
- CAFFE2: Caffe2 provides an easy way to provide proof of concept and take advantage of the contributions of new models and algorithms provided by the scientific community. GPUs can be use in the cloud to train large volumes of data and scale trained models to mobile devices using Caffe2’s cross-platform libraries [75].
- DialogFlow: Is a natural language understanding platform with which users can design a conversational user interface and embed it in a mobile or web application. It analyzes different file types of input such as text input or audio input, such as a voice recording, and can respond to users in different ways such as through text or an artificial voice [76].
- Microsoft Cognitive Services: Is an artificial intelligence (AI) service that bases its operation on sending data to a central server that is in charge of carrying out the training and returning the trained model to the source device. This service helps developers add cognitive intelligence to applications without prior AI knowledge or skills. Azure Cognitive Services enables developers to add functionality to their applications such as the ability to see, hear, speak and analyze [77].
- The Firebase ML Kit: Is a set of tools and services that focused on offering the developer powerful machine learning so that can be included in apps using an Android or iOS system. It has a set of APIs, also known as an application programming interfaces, that is cloud-enabled and allows the user to perform different actions, such as recognizing text, recognizing landmarks and image tagging [78].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Features | Support | Functions |
|---|---|---|---|
| CAFFE2 [75] | Integration with mobile applications | C++, Python, Android, IOS | Training and testing on the device |
| OpenCV [79] | Integration with mobile applications; Facial recognition; Gesture recognition | C++, Java, Python, Android, IOS | Training and testing on the device |
| TensorFlow Lite [20,69] | Lightl Integration with mobile devices; Efficient | Android, IOS, RaspBerry Pi | Training and testing on the device |
| Google ML KIT [72] | Light; Integration with mobile devices; High speed of inference | Android, IOS | Training and testing on the device |
| DialogFlow [76,80] | Multichannel implementation; Advanced AI; State-based models; End-to-end administration | C, C#, Go, Java Node.js, Python | Inferences in the cloud |
| Microsoft Cognitive Services [77,81] | Computer vision; Speech recognition; Natural language understanding; Decision management | Python, Java, .NET, JS, GO, PHP | Inferences in the cloud |
| Core ML [73] | Creation of models; Pretrained or own models; No training allowed | IOS and converted models from other libraries | Model implementation; Pretrained on devices |
| Firebase ML Kit [78] | Text recognition; Image tagging; Object recognition and tracking; Language identification | Android, iOS | Inferences on the device or in the cloud |
| Google Cloud AI [74] | Speech to text; Natural language; Document AI | Java, Go, Python, Node.js | Inferences on the device or in the cloud |
| Pytorch Mobile [82] | Integration in mobile applications | iOS, Android and Linux | Training and testing on the device |
7. Federated Learning
- Vertical federated learning: Is applied in cases in which the datasets share the same sample space but have a different feature space, with training data vertically divided.
- Horizontal federated learning: Is proposed for architectures for which the participating customer datasets share the same type of characteristics but have different data samples, with the entire data set divided horizontally into data samples and assigned to two customers.
- Hybrid federated learning: Is applied when datasets from different customers have not only have different sample architectures but also share different feature architectures.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarwar, M.; Soomro, T.R. Impact of smartphone’s on society. Eur. J. Sci. Res. 2013, 98, 216–226. [Google Scholar]
- Statista. Share of Users Worldwide Accessing the Internet in 3rd Quarter 2022, by Device. Available online: https://www.statista.com/statistics/1289755/internet-access-by-device-worldwide/ (accessed on 10 April 2023).
- Why On-Device Machine Learning? Available online: https://developers.google.com/learn/topics/on-device-ml/learn-more. (accessed on 15 January 2023).
- Addressing the Challenges of On-Device Machine Learning. Available online: https://blog.developer.adobe.com/addressing-the-challenges-of-on-device-machine-learning-1f71ebcedd69 (accessed on 15 January 2023).
- Addepto. What Are the Top 10 Challenges of Machine Learning? Available online: https://addepto.com/blog/what-are-the-top-10-challenges-of-machine-learning/ (accessed on 15 January 2023).
- Linkedin. The Benefits and Challenges of Edge Machine Learning. Available online: https://www.linkedin.com/pulse/benefits-challenges-edge-machine-learning-wallaroolabs (accessed on 15 January 2023).
- Ribeiro, M.; Grolinger, K.; Capretz, M.A. MLaaS: Machine Learning as a Service; IEEE: Piscataway, NJ, USA, 2015; pp. 896–902. [Google Scholar] [CrossRef]
- Google Cloud, AI and Machine LEARNING Products. Available online: https://cloud.google.com/products/ai (accessed on 6 January 2023).
- IBM Watson Machine Learning. Available online: https://www.ibm.com/cloud/watson-studio (accessed on 6 January 2023).
- Welcome to Machine Learning Studio. Available online: https://studio.azureml.net/ (accessed on 6 January 2023).
- Oracle Machine Learning. Available online: https://docs.oracle.com/en/database/oracle/machine-learning/oml4py/1/mlpug/machine-learning-classes-and-algorithms.html (accessed on 6 January 2023).
- Machine Learning on AWS. Available online: https://aws.amazon.com/machine-learning (accessed on 6 January 2023).
- Eshratifar, A.E.; Abrishami, M.S.; Pedram, M. JointDNN: An Efficient Training and Inference Engine for Intelligent Mobile Cloud Computing Services. IEEE Trans. Mob. Comput. 2021, 20, 565–576. [Google Scholar] [CrossRef]
- Wang, X.; Xu, Y.; Xu, K.; Tagliasacchi, A.; Zhou, B.; Mahdavi-Amiri, A.; Zhang, H. PIE-NET: Parametric Inference of Point Cloud Edges. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Online, 6–12 December 2020; pp. 20167–20178. [Google Scholar]
- Long, Y.; Chakraborty, I.; Srinivasan, G.; Roy, K. Complexity-Aware Adaptive Training and Inference for Edge-Cloud Distributed AI Systems. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021; pp. 573–583. [Google Scholar] [CrossRef]
- Laskaridis, S.; Venieris, S.I.; Almeida, M.; Leontiadis, I.; Lane, N.D. SPINN: Synergistic Progressive Inferenceof Neural Networks over Device and Cloud. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, MOBICOM ’20, London, UK, 21–25 September 2020; Association for Computing Machinery (ACM): New York, NY, USA, 2020; pp. 1–15. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Z.; Gan, C.; Zhu, L.; Han, S. DataMix: Efficient Privacy-Preserving Edge-Cloud Inference. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; Volume 12356, pp. 578–595. [Google Scholar] [CrossRef]
- Ogden, S.S.; Kong, X.; Guo, T. PieSlicer: Dynamically Improving Response Time for Cloud-based CNN Inference. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Virtual Event, 19–23 April 2021; ACM: New York, NY, USA, 2021; pp. 249–256. [Google Scholar] [CrossRef]
- Li, Y.; Han, Z.; Zhang, Q.; Li, Z.; Tan, H. Automating Cloud Deployment for Deep Learning Inference of Real-time Online Services. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020. [Google Scholar]
- Reda, M.; Suwwan, R.; Alkafri, S.; Rashed, Y.; Shanableh, T. AgroAId: A Mobile App System for Visual Classification of Plant Species and Diseases Using Deep Learning and TensorFlow Lite. Informatics 2022, 9, 55. [Google Scholar] [CrossRef]
- Mondal, S.; Modi, S.; Garg, S.; Das, D.; Mukherjee, S. ICAN: Introspective Convolutional Attention Network for Semantic Text Classification; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 158–161. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Vatsal, S.; Purre, N.; Moharana, S.; Ramena, G.; Mohanty, D. On-Device Information Extraction from Sms Using Hybrid Hierarchical Classification. In Proceedings of the 2020 IEEE 14th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, 3–5 February 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 178–181. [Google Scholar] [CrossRef]
- Garg, S.; Harichandana, S.S.; Kumar, S. On-Device Document Classification using Multimodal Features. In Proceedings of the 3rd ACM India Joint International Conference on Data Science & Management of Data (8th ACM IKDD CODS & 26th COMAD), Bangalore, India, 2–4 January 2021; Association for Computing Machinery: New York, NY, USA, 2020; pp. 203–207. [Google Scholar] [CrossRef]
- Buiu, C.; Dănăilă, V.R.; Răduţă, C.N. MobileNetV2 ensemble for cervical precancerous lesions classification. Processes 2020, 8, 595. [Google Scholar] [CrossRef]
- Ignatov, A.; Malivenko, G.; Timofte, R.; Tseng, Y.; Xu, Y.S.; Yu, P.H.; Chiang, C.M.; Kuo, H.K.; Chen, M.H.; Cheng, C.M.; et al. PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022; pp. 677–684. [Google Scholar] [CrossRef]
- Sidhpura, J.; Shah, P.; Veerkhare, R.; Godbole, A. FedSpam: Privacy Preserving SMS Spam Prediction. In Communications in Computer and Information Science, Proceedings of the ICONIP 2022: Neural Information Processing, New Delhi, India, 22 November 2022; Springer: Singapore, 2023; Volume 1793, pp. 52–63. [Google Scholar]
- Nagula, P.K.; Alexakis, C. A new hybrid machine learning model for predicting the bitcoin (BTC-USD) price. J. Behav. Exp. Financ. 2022, 36, 100741. [Google Scholar] [CrossRef]
- Wibowo, A.; Hartanto, C.A.; Wirawan, P.W. Android skin cancer detection and classification based on MobileNet v2 model. Int. J. Adv. Intell. Inform. 2020, 6, 135–148. [Google Scholar] [CrossRef]
- GitHub. MobileNet. Available online: https://github.com/tensorflow/tfjs-models/tree/master/mobilenet (accessed on 8 January 2023).
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Koonce, B. Convolutional Neural Networks with Swift for Tensorflow; Apress: Berkeley, CA, USA, 2021; pp. 109–123. [Google Scholar] [CrossRef]
- Huang, J.; Mei, L.; Long, M.; Liu, Y.; Sun, W.; Li, X.; Shen, H.; Zhou, F.; Ruan, X.; Wang, D.; et al. Bm-net: Cnn-based mobilenet-v3 and bilinear structure for breast cancer detection in whole slide images. Bioengineering 2022, 9, 261. [Google Scholar] [CrossRef]
- Michele, A.; Colin, V.; Santika, D.D. MobileNet Convolutional Neural Networks and Support Vector Machines for Palmprint Recognition. In Procedia Computer Science, Proceedings of the 4th International Conference on Computer Science and Computational Intelligence (ICCSCI 2019): Enabling Collaboration to Escalate Impact of Research Results for Society, Yogyakarta, Indonesia, 12–13 September 2019; Elsevier: Amsterdam, The Netherlands, 2021; pp. 110–117. [Google Scholar] [CrossRef]
- Bi, C.; Wang, J.; Duan, Y.; Fu, B.; Kang, J.R.; Shi, Y. MobileNet based apple leaf diseases identification. Mob. Netw. Appl. 2020, 1–9. [Google Scholar] [CrossRef]
- Rajbongshi, A.; Sarker, T.; Ahamad, M.M.; Rahman, M.M. Rose Diseases Recognition using MobileNet. In Proceedings of the 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Istanbul, Turkey, 22–24 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Zaki, S.Z.M.; Zulkifley, M.A.; Stofa, M.M.; Kamari, N.A.M.; Mohamed, N.A. Classification of tomato leaf diseases using MobileNet v2. IAES Int. J. Artif. Intell. 2020, 9, 290. [Google Scholar] [CrossRef]
- Sae-Lim, W.; Wettayaprasit, W.; Aiyarak, P. Convolutional Neural Networks Using MobileNet for Skin Lesion Classification. In Proceedings of the 2019 16th International Joint Conference on Computer Science and Software Engineering (JCSSE), Chonburi, Thailand, 10–12 July 2019; pp. 242–247. [Google Scholar] [CrossRef]
- Venkateswarlu, I.B.; Kakarla, J.; Prakash, S. Face mask detection using MobileNet and Global Pooling Block. In Proceedings of the 2020 IEEE 4th Conference on Information & Communication Technology (CICT), Chennai, India, 3–5 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Velasco, J.; Pascion, C.; Alberio, J.W.; Apuang, J.; Cruz, J.S.; Gomez, M.A.; Molina, B.J.; Tuala, L.; Thio-ac, A.; Jorda, R.J. A Smartphone-Based Skin Disease Classification Using MobileNet CNN. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 2632–2637. [Google Scholar] [CrossRef]
- Souid, A.; Sakli, N.; Sakli, H. Classification and Predictions of Lung Diseases from Chest X-rays Using MobileNet V2. Appl. Sci. 2021, 11, 2751. [Google Scholar] [CrossRef]
- Hartanto, C.A.; Wibowo, A. Development of Mobile Skin Cancer Detection using Faster R-CNN and MobileNet v2 Model. In Proceedings of the 2020 7th International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), Kota Semarang, Indonesia, 24–25 September 2020; pp. 58–63. [Google Scholar] [CrossRef]
- Pan, H.; Pang, Z.; Wang, Y.; Wang, Y.; Chen, L. A New Image Recognition and Classification Method Combining Transfer Learning Algorithm and MobileNet Model for Welding Defects. IEEE Access 2020, 8, 119951–119960. [Google Scholar] [CrossRef]
- Rahman, M.M.; Biswas, A.A.; Rajbongshi, A.; Majumder, A. Recognition of local birds of Bangladesh using MobileNet and Inception-v3. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 309–316. [Google Scholar] [CrossRef]
- Kadam, K.; Ahirrao, S.; Kotecha, K.; Sahu, S. Detection and Localization of Multiple Image Splicing Using MobileNet V1. IEEE Access 2021, 9, 162499–162519. [Google Scholar] [CrossRef]
- Díaz-Gaxiola, E.; Morales-Casas, Z.E.; Castro-López, O.; Beltrán-Gutiérrez, G.; López, I.F.V.; Rendón, A.Y. Estudio comparativo de arquitecturas de CNNs en hojas de Pimiento Morrón infectadas con virus PHYVV o PEPGMV. Res. Comput. Sci. 2019, 148, 289–303. [Google Scholar] [CrossRef]
- EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling. Available online: https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html (accessed on 10 January 2023).
- EfficientNet Keras (and TensorFlow Keras). Available online: https://pypi.org/project/efficientnet/ (accessed on 6 January 2023).
- Atila, Ü.; Uçar, M.; Akyol, K.; Uçar, E. Plant leaf disease classification using EfficientNet deep learning model. Ecol. Inform. 2021, 61, 101182. [Google Scholar] [CrossRef]
- Yi, S.L.; Yang, X.L.; Wang, T.W.; She, F.R.; Xiong, X.; He, J.F. Diabetic Retinopathy Diagnosis Based on RA-EfficientNet. Appl. Sci. 2021, 11, 11035. [Google Scholar] [CrossRef]
- Fudholi, D.H.; Rani, S.; Arifin, D.M.; Satyatama, M.R. Deep Learning-based Mobile Tourism Recommender System. Sci. J. Inform. 2021, 8, 111–118. [Google Scholar] [CrossRef]
- GitHub. EfficientNet-Lite. Available online: https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/lite/ (accessed on 10 January 2023).
- Blog, T. Higher Accuracy on Vision Models with EfficientNet-Lite. Available online: https://blog.tensorflow.org/2020/03/higher-accuracy-on-vision-models-with-efficientnet-lite.html (accessed on 15 January 2023).
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the 38th International Conference on Machine Learning, ICML, Online, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Thompson, C.W.; Ross, K.M. Natural-Language Interface Generating System. U.S. Patent 4,688,195, 18 August 1987. [Google Scholar]
- Sarker, S.; Wells, J.D. Understanding mobile handheld device use and adoption. Commun. ACM 2003, 46, 35–40. [Google Scholar] [CrossRef]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. Mobilebert: A compact task-agnostic bert for resource-limited devices. arXiv 2020, arXiv:2004.02984. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Saha, U.; Mahmud, M.S.; Keya, M.; Lucky, E.A.E.; Khushbu, S.A.; Noori, S.R.H.; Syed, M.M. Exploring Public Attitude Towards Children by Leveraging Emoji to Track Out Sentiment Using Distil-BERT a Fine-Tuned Model. In Proceedings of the Third International Conference on Image Processing and Capsule Networks, Online, Bangkok, Thailand, 20–21 May 2022; pp. 332–346. [Google Scholar]
- Palliser-Sans, R.; Rial-Farràs, A. HLE-UPC at SemEval-2021 Task 5: Multi-Depth DistilBERT for Toxic Spans Detection. arXiv 2021, arXiv:2104.00639. [Google Scholar]
- Chaudhary, Y.; Gupta, P.; Saxena, K.; Kulkarni, V.; Runkler, T.A.; Schütze, H. TopicBERT for Energy Efficient Document Classification. arXiv 2020, arXiv:2010.16407. [Google Scholar]
- For Mobile & Edge. Available online: https://www.tensorflow.org/lite/performance/model_optimization (accessed on 6 January 2023).
- Rashidi, M. Application of TensorFlow Lite on Embedded Devices: A Hands-On Practice of TensorFlow Model Conversion to TensorFlow Lite Model and Its Deployment on Smartphone to Compare Model’s Performance. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1698946&dswid=-2072 (accessed on 6 January 2023).
- Brahmbhatt, S. Practical OpenCV; Apress: Berkeley, CA, USA, 2013; ISBN 978-1-4302-6080-6. [Google Scholar]
- Google ML Kit. Available online: https://developers.google.com/ml-kit (accessed on 6 January 2023).
- Machine Learning. Available online: https://developer.apple.com/machine-learning/ (accessed on 6 January 2023).
- Google. Google Cloud AI. Available online: https://developer.apple.com/machine-learning/ (accessed on 6 January 2023).
- CAFFE2. Caffe2: Anew Lightweight, Modular, and Scalable Deep Learning Framework. Available online: https://caffe2.ai/docs/caffe-migration.html (accessed on 6 January 2023).
- Cloud, G. DialogFlow. Available online: https://cloud.google.com/dialogflow (accessed on 6 January 2023).
- Del Sole, A. Introducing Microsoft Cognitive Services. In Microsoft Computer Vision APIs Distilled: Getting Started with Cognitive Services; Apress: Berkeley, CA, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Google. Firebase ML Kit. Available online: https://firebase.google.com/docs/ml-kit (accessed on 6 January 2023).
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library, 1st ed.; O’Reilly: Springfield, MO, USA, 2008; ISBN 978-0-5965-5404-0. [Google Scholar]
- Reyes, R.; Garza, D.; Garrido, L.; la Cueva, V.D.; Ramirez, J. Methodology for the Implementation of Virtual Assistants for Education Using Google Dialogflow; Martínez-Villaseñor, L., Batyrshin, I., Marín-Hernández, A., Eds.; Springer International Publishing: Cham, Switzerland, 27 October 2019; Volume 11835, pp. 440–451. [Google Scholar] [CrossRef]
- Masood, A.; Hashmi, A. Cognitive Computing Recipes: Artificial Intelligence Solutions Using Microsoft Cognitive Services and TensorFlow; Apress: Berkeley, CA, USA, 2019. [Google Scholar]
- PyTorch. PyTorch Mobile. Available online: https://pytorch.org/mobile/home/ (accessed on 6 January 2023).
- Banabilah, S.; Aloqaily, M.; Alsayed, E.; Malik, N.; Jararweh, Y. Federated learning review: Fundamentals, enabling technologies, and future applications. Inf. Process. Manag. 2022, 59, 103061. [Google Scholar] [CrossRef]
- IBM. What Is Federated Learning? Available online: https://research.ibm.com/blog/what-is-federated-learning (accessed on 15 January 2023).
- Research, G. Federated Learning: Collaborative Machine Learning without Centralized Training Data. Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 15 January 2023).
- Team, D.S. Aprendizaje Federado. Available online: https://datascience.eu/es/aprendizaje-automatico/aprendizaje-federado/ (accessed on 15 January 2023).
- Zhu, H.; Zhang, H.; Jin, Y. From federated learning to federated neural architecture search: A survey. Complex Intell. Syst. 2021, 7, 639–657. [Google Scholar] [CrossRef]







| Service | Description | Interface | Models | Extras |
|---|---|---|---|---|
| Amazon [12] | Automated infrastructure that applies ML techniques to information stored on Amazon Web Services. | Amazon ML console, Amazon CLI | Users can use their information with pretrained algorithms that can be included in: - Regression; - Binary classification; - Multiclass classification. | Additional payments for information stored in a collection of cloud computing services billed separately. |
| Google Cloud [8] | Gives customers access to cutting-edge algorithms used by Google with the help of other industry-leading applications for use in searches. Users have the ability to make their own algorithms. | The terminal is run using gcloud ml-engine to control tensor flow processes. | Customers have the ability to create models or use pretrained models that are supported by following apps: -Multimedia analysis (image and video); -Dialogue recognition; -Text analysis; -Translation. | Google account required. |
| IBM Watson [9] | Focuses on putting algorithms into production using REST API connectors. | -IBM’s SPSS graphical analysis software can be used as a front end; -API connectors allow customers to design models in third-party data science applications. | Users can design algorithms in any language using REST API connectors. Access to Apache Speak’s MLlib library of machine learning models is available through IBM’s Data Science Experience workbench platform (implementation currently in a closed beta). | A Bluemix account is required. |
| Microsoft Azure [10] | Includes predefined models that clients can use on their data. | Azure Machine Learning Studio, R and Python coding. | Customers may use their information in algorithms, including: - Decision tree; -Bayesian systems; -Deep neural networks; - Decision jungles; -The rating service supports these algorithms; -Binary classification. -Regression clustering. | A paid Azure account and a free Microsoft account are required. |
| Oracle [11] | Oracle is a database architecture relational in which data are managed and processed over local and wide area networks. The Oracle database has its own networking component to enable communications across networks. | Oracle machine learning AutoML. | Machine learning function. | Oracle Platform account required. |
| Approach | Architecture | Device or Technology | Proposal Scope | Reference |
|---|---|---|---|---|
| JoinDNN | Hybrid | Mobile | Computing with a mobile device and the cloud | Eshratifar et al. [13] |
| Pie-NET | Cloud | 3D Points | Parametric inference of edges | Wang et al. [14] |
| MEANet | Cloud | IoT | Image Classification | Long et al. [15] |
| SPINN | Cloud | CNN | CNN splitting at run time | Laskaridis et al. [16] |
| DATAMIX | Hybrid | Edge devices | Speech recognition | Liu et al. [17] |
| PieSlicer | Cloud | Online services | Cloud-based CNN inference | Ogden et al. [18] |
| Deep Learning Inference on Real-time | Cloud | DNN | Cloud development | Li et al. [19] |
| Version | Input Size (px) | #Params | Accuracy |
|---|---|---|---|
| EfficientNetB0 | 4,057,253 | 76.3%/93.2% | |
| EfficientNetB1 | 6,582,914 | 78.8%/94.4% | |
| EfficientNet-B2 | 7,777,012 | 79.8%/94.9% | |
| EfficientNet-B3 | 10,792,746 | 81.1%/95.5% | |
| EfficientNet-B4 | 17,684,570 | 82.6%/96.3% | |
| EfficientNet-B5 | 28,525,810 | 83.3%/96.7% | |
| EfficientNet-B6 | 40,973,969 | 84.0%/96.9% | |
| EfficientNet-B7 | 64,113,049 | 84.4%/97.1% |
| PRE-Trained Model | Image Input Size (px) | Acuracy | Parameters | Inference Time | Size |
|---|---|---|---|---|---|
| EfficientNetV2 [54] | 83% | 55 M | 57 ms | 220 MB | |
| MobileNet [55] | 70.4% | 4.3 M | 22.6s | 16 MB | |
| MobileNetV2 [55] | 71.3% | 3.5 M | 25.9 ms | 14 MB | |
| ResNet50 [56] | 74.9% | 25.6 M | 58.2 ms | 98 MB | |
| VGG16 [57] | 71.3% | 138.4 M | 69.5 ms | 528 MB | |
| InceptionV3 [58] | 77.9% | 23.9 M | 42.2 ms | 92 MB | |
| NASNetMobile [59] | 74.4% | 5.3 M | 27 ms | 23 MB | |
| DenseNEt121 [60] | 75% | 8.1 M | 77.1 ms | 33 MB | |
| Xception [59] | 79% | 22.9 M | 109.4 ms | 88 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez Arteaga, S.; Sandoval Orozco, A.L.; García Villalba, L.J. Analysis of Machine Learning Techniques for Information Classification in Mobile Applications. Appl. Sci. 2023, 13, 5438. https://doi.org/10.3390/app13095438
Pérez Arteaga S, Sandoval Orozco AL, García Villalba LJ. Analysis of Machine Learning Techniques for Information Classification in Mobile Applications. Applied Sciences. 2023; 13(9):5438. https://doi.org/10.3390/app13095438
Chicago/Turabian StylePérez Arteaga, Sandra, Ana Lucila Sandoval Orozco, and Luis Javier García Villalba. 2023. "Analysis of Machine Learning Techniques for Information Classification in Mobile Applications" Applied Sciences 13, no. 9: 5438. https://doi.org/10.3390/app13095438