
A Study on Detection of Malicious Behavior Based on Host Process Data Using Machine Learning


Abstract
:1. Introduction
2. Related Works
2.1. Research on Behavior-Based Cyber-Attack Detection
2.2. Machine Learning Algorithms
- NB: Naïve Bayes is a probabilistic classifier that has been employed in various cyber-attack detection research, such as Sarker, I.H. [25]. It is computationally efficient and performs well with discrete data, making it a suitable choice for our study.
- RF: Random Forest is an ensemble learning method that has demonstrated high performance in multiple cyber-attack detection studies, including Aslan, O., et al. [10], Sarker, I.H. [25] and Ranjan, R., et al. [41]. Its ability to handle large datasets and perform feature selection makes it a relevant choice for our experiment.
- AE: Autoencoders are unsupervised learning models that have been used in anomaly detection tasks due to their ability to learn useful representations of data. In this study, we chose AE for its potential to capture complex patterns in the application process data.
- MemAE: Memory-augmented Deep Autoencoder is a deep learning model that incorporates memory mechanisms to enhance the representation learning capabilities of autoencoders. MemAE was selected for this study as it has demonstrated promising performance in detecting anomalies, particularly in complex and high-dimensional data.
2.2.1. K-Nearest Neighbors (KNN)
2.2.2. Naïve Bayes (NB)
2.2.3. Random Forest (RF)
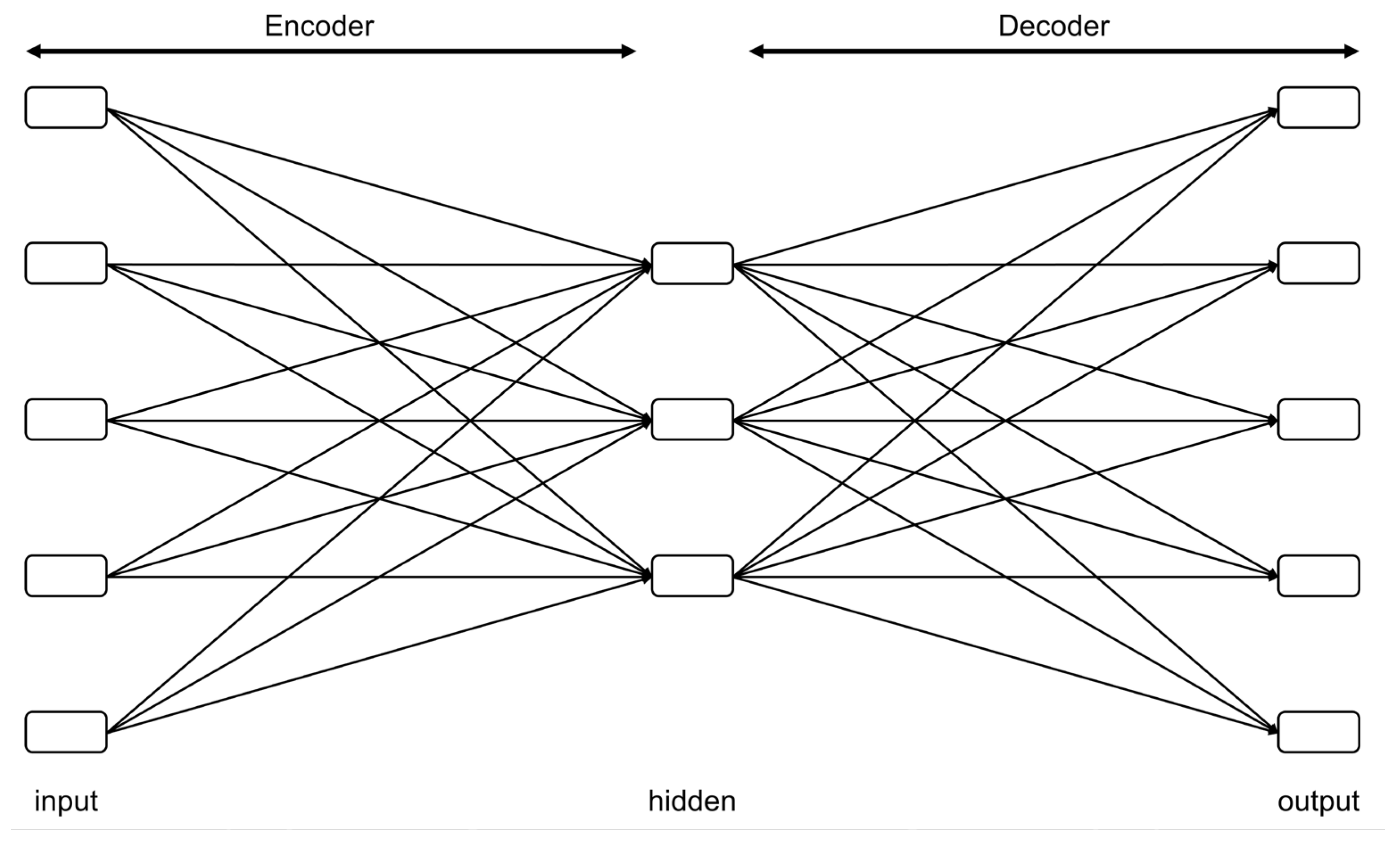
2.2.4. Autoencoder (AE)
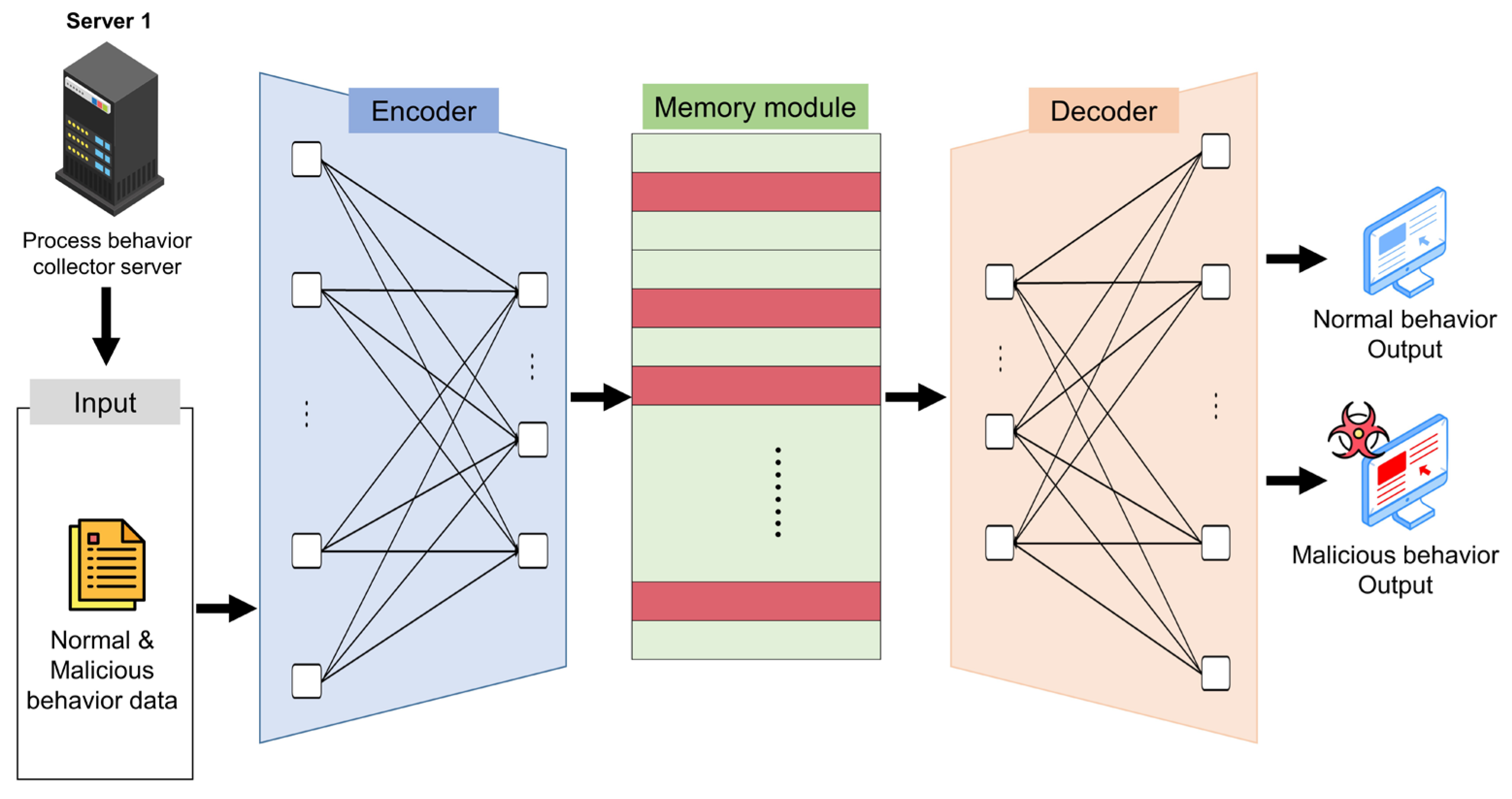
2.2.5. Memory-Augmented Deep Autoencoder (MemAE)
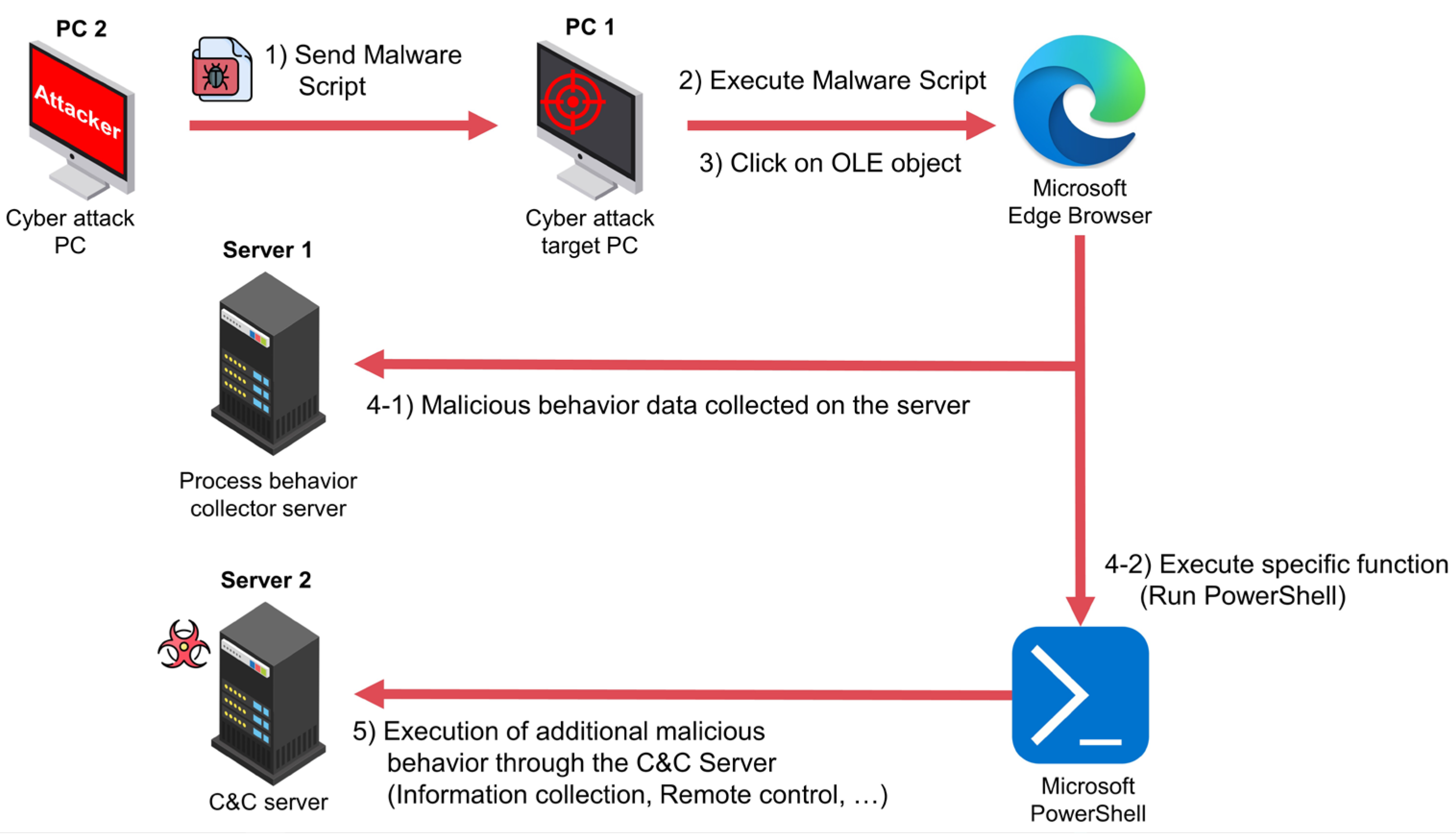
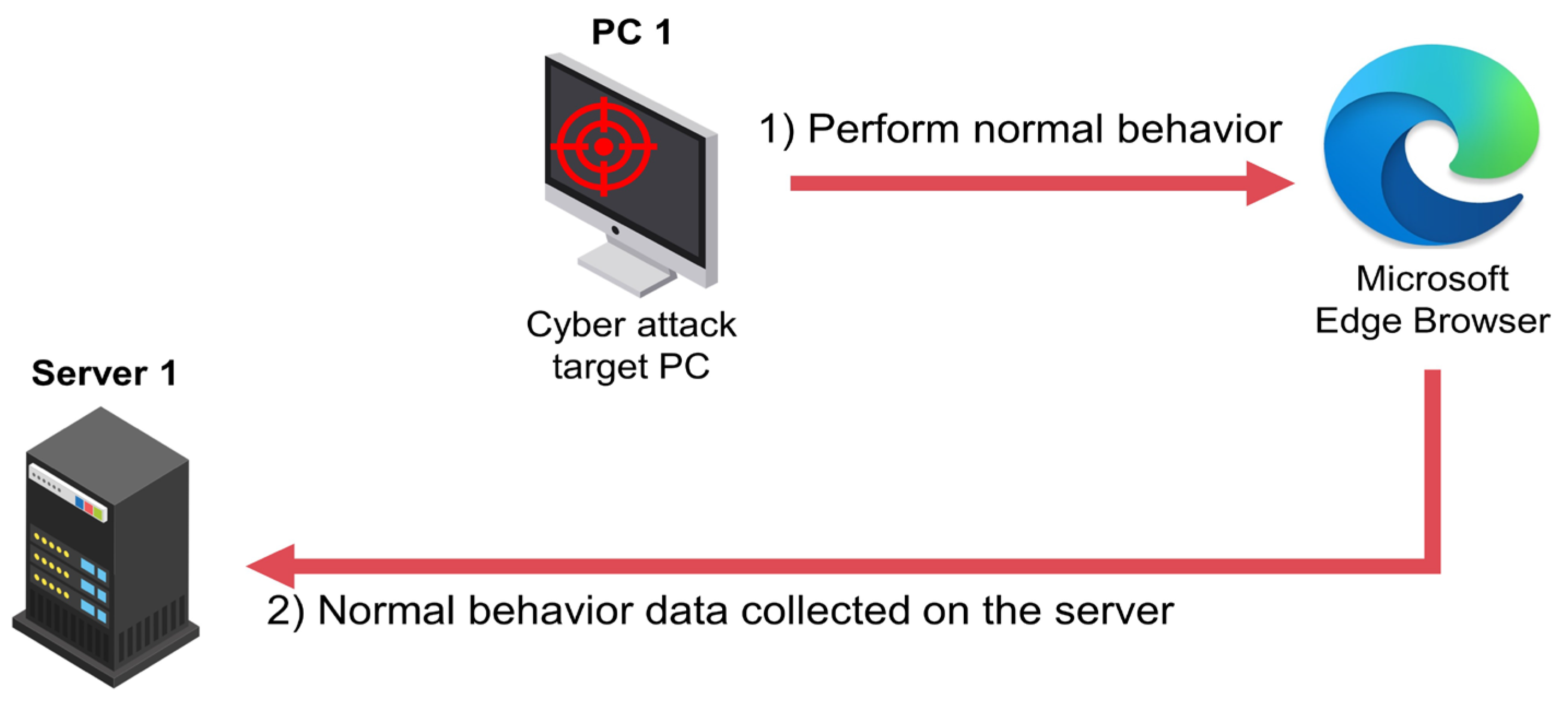
3. Experimental Environment and Data Description
4. Experiments
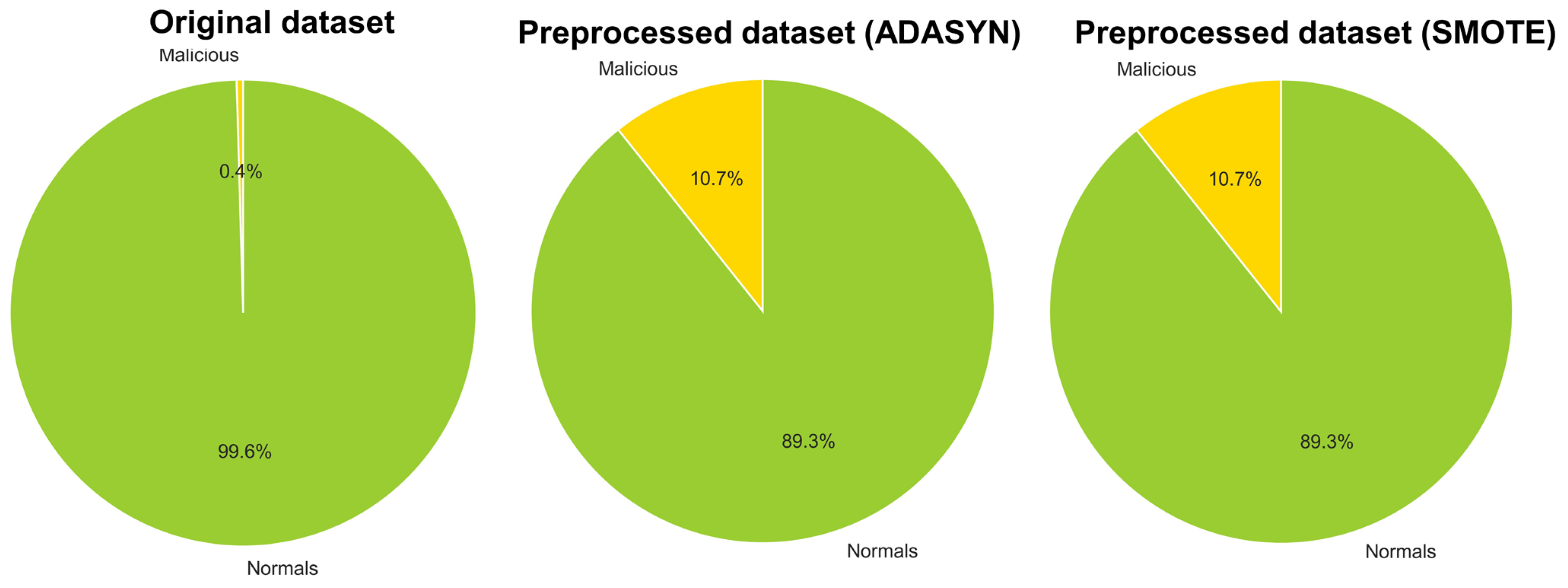
4.1. Data Preprocess
4.2. Parameters and Performance Evaluation of Models
- Precision: It indicates the ratio of true positive samples among the samples classified as abnormal by the model. In other words, precision is a metric that aims to reduce False Positive (FP) cases. Higher precision means that the model correctly classifies most of the samples as abnormal.
- Recall: It indicates the ratio of true positive samples among the actual abnormal samples. In other words, recall is a metric that aims to reduce False Negative (FN) cases. Higher recall means that the model correctly classifies most of the actual abnormal samples as abnormal.
- F1-Score: It is the harmonic mean of precision and recall, representing the balance between precision and recall. Higher F1-score means that the model has both high precision and high recall.
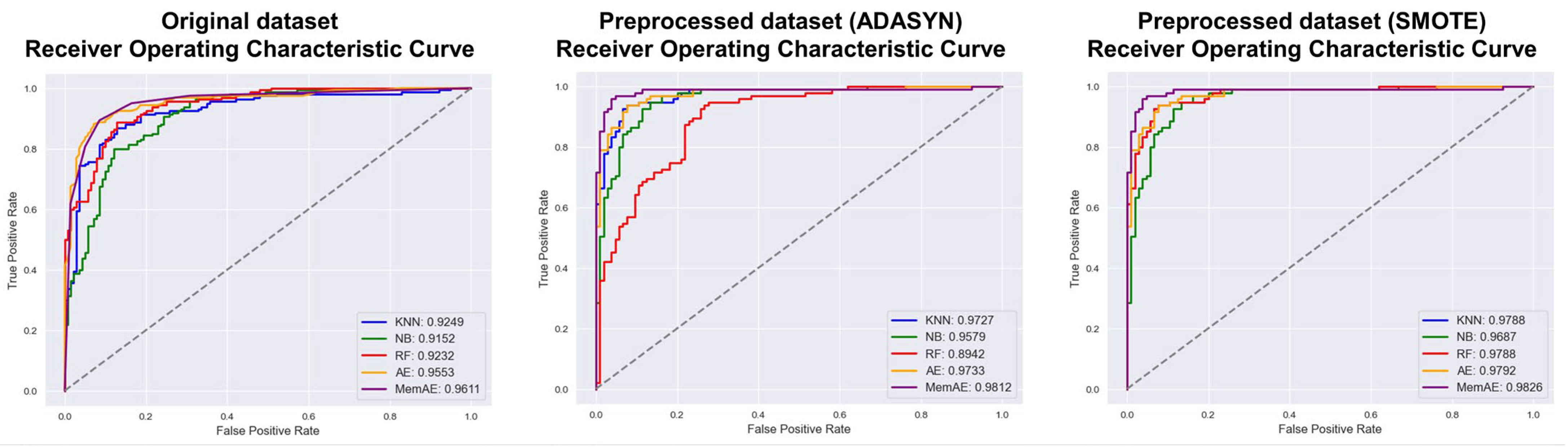
- Receiver Operating Characteristic (ROC) Curve: It is one of the ways to visualize the performance of the anomaly detection model. The ROC curve is a graph that shows the changes in True Positive Rate (TPR) and False Positive Rate (FPR) as the classification threshold of the model is changed. The better the model’s performance, the closer the ROC curve is to the upper left corner, and the performance of the anomaly detection model is also expressed by the Area Under the Curve (AUC).
4.3. Experiments Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| APT | Advanced Persistent Threats |
| RF | Random Forest |
| LMT | logistic model trees |
| KNN | K-Nearest Neighbors |
| ART | Adaptive Resonance Theory |
| DoS | Denial-of-Service |
| NB | Naïve Bayes |
| LDA | Linear Discriminant Analysis |
| XGBoost | Extreme Gradient Boosting |
| SVM | Support Vector Machines |
| AdaBoost | Adaptive Boosting |
| SGD | Stochastic Gradient Descent |
| LR | Logistic regression |
| MLP | Multilayer Perceptron |
| AE | Autoencoder |
| MemAE | Memory-augmented Deep Autoencoder |
| SMOTE | Synthetic Minority Over-sampling Technique |
| PCA | Principal Component Analysis |
| t-SNE | t-distributed Stochastic Neighbor Embedded |
| UMAP | Uniform Manifold Approximation and Projection |
| FP | False Positive |
| FN | False Negative |
| ROC | Receiver Operating Characteristic |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| AUC | Area Under the Curve |
| TP | True Positive True Negative |
| TN | True Negative |
| AUROC | Area Under the Receiver Operating Characteristic Curve |
References
- Arora, B. Exploring and analyzing Internet crimes and their behaviours. Perspect. Sci. 2016, 8, 540–542. [Google Scholar] [CrossRef] [Green Version]
- Check Point Research: Third Quarter of 2022 Reveals Increase in Cyberattacks and Unexpected Developments in Global Trends. Available online: https://blog.checkpoint.com/2022/10/26/third-quarter-of-2022-reveals-increase-in-cyberattacks (accessed on 18 March 2023).
- Wanjala, M.Y.; Jacob, N.M. Review of Viruses and Antivirus patterns. Glob. J. Comput. Sci. Technol. 2017, 17, 1–3. [Google Scholar]
- Xiao, Y.; Xing, C.; Zhang, T.; Zhao, Z. An intrusion detection model based on feature reduction and convolutional neural networks. IEEE Access 2019, 7, 42210–42219. [Google Scholar] [CrossRef]
- Papamartzivanos, D.; Mármol, F.G.; Kambourakis, G. Introducing deep learning self-adaptive misuse network intrusion detection systems. IEEE Access 2019, 7, 13546–13560. [Google Scholar] [CrossRef]
- Mayuranathan, M.; Murugan, M.; Dhanakoti, V. Best features based intrusion detection system by RBM model for detecting DDoS in cloud environment. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 3609–3619. [Google Scholar] [CrossRef]
- Jiang, F.; Fu, Y.; Gupta, B.B.; Liang, Y.; Rho, S.; Lou, F.; Meng, F.; Tian, Z. Deep learning based multi-channel intelligent attack detection for data security. IEEE Trans. Sustain. Comput. 2018, 5, 204–212. [Google Scholar] [CrossRef]
- Tian, Q.; Han, D.; Li, K.-C.; Liu, X.; Duan, L.; Castiglione, A. An intrusion detection approach based on improved deep belief network. Appl. Intell. 2020, 50, 3162–3178. [Google Scholar] [CrossRef]
- Zhang, C.; Costa-Pérez, X.; Patras, P. Tiki-taka: Attacking and defending deep learning-based intrusion detection systems. In Proceedings of the 2020 ACM SIGSAC Conference on Cloud Computing Security Workshop, Virtual Event, 9 November 2020; pp. 27–39. [Google Scholar]
- Aslan, Ö.; Ozkan-Okay, M.; Gupta, D. Intelligent behavior-based malware detection system on cloud computing environment. IEEE Access 2021, 9, 83252–83271. [Google Scholar] [CrossRef]
- Das Malwerk. Available online: https://dasmalwerk.eu/ (accessed on 18 March 2023).
- MalwareBazaar. Available online: https://bazaar.abuse.ch/ (accessed on 18 March 2023).
- TheZoo Aka. Available online: https://thezoo.morirt.com/ (accessed on 18 March 2023).
- Malshare. Available online: https://malshare.com/ (accessed on 18 March 2023).
- Tekdefense. Available online: http://www.tekdefense.com/downloads/ (accessed on 18 March 2023).
- Virussign. Available online: https://virussign.com/ (accessed on 18 March 2023).
- Virusshare. Available online: https://virusshare.com/ (accessed on 18 March 2023).
- Kernelmode. Available online: https://www.kernelmode.info/forum/ (accessed on 18 March 2023).
- Quinlan, J.R. Bagging, boosting, and C4. 5. In Proceedings of the Aaai/Iaai, Portland, OR, USA, 4–8 August 1996; Volume 1, pp. 725–730. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Landwehr, N.; Hall, M.; Frank, E. Logistic model trees. Mach. Learn. 2005, 59, 161–205. [Google Scholar] [CrossRef] [Green Version]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Jones, C.B.; Chavez, A.; Hossain-McKenzie, S.; Jacobs, N.; Summers, A.; Wright, B. Unsupervised online anomaly detection to identify cyber-attacks on internet connected photovoltaic system inverters. In Proceedings of the 2021 IEEE Power and Energy Conference at Illinois (PECI), Urbana, IL, USA, 1–2 April 2021; pp. 1–7. [Google Scholar]
- Carpenter, G.A.; Grossberg, S. Adaptive Resonance Theory; Springer: New York, NY, USA, 2010. [Google Scholar]
- Sarker, I.H. CyberLearning: Effectiveness analysis of machine learning security modeling to detect cyber-anomalies and multi-attacks. Internet Things 2021, 14, 100393. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Murphy, K.P. Naive bayes classifiers. Univ. Br. Columbia 2006, 18, 1–8. [Google Scholar]
- Balakrishnama, S.; Ganapathiraju, A. Linear discriminant analysis—A brief tutorial. Inst. Signal Inf. Process. 1998, 18, 1–8. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T. Xgboost: Extreme Gradient Boosting; R Package Version 0.4-2; 2015; Volume 1, pp. 1–4. Available online: https://cran.r-project.org/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 2 March 2023).
- Wang, L. Support Vector Machines: Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005; Volume 177. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- DeMaris, A. A tutorial in logistic regression. J. Marriage Fam. 1995, 57, 956–968. [Google Scholar] [CrossRef]
- Ibrahim, W.N.H.; Anuar, S.; Selamat, A.; Krejcar, O.; Crespo, R.G.; Herrera-Viedma, E.; Fujita, H. Multilayer framework for botnet detection using machine learning algorithms. IEEE Access 2021, 9, 48753–48768. [Google Scholar] [CrossRef]
- García, S.; Grill, M.; Stiborek, J.; Zunino, A. An empirical comparison of botnet detection methods. Comput. Secur. 2014, 45, 100–123. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Wang, S.; Philip, S.Y. Heterogeneous graph matching networks: Application to unknown malware detection. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5401–5408. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Han, X.; Pasquier, T.; Bates, A.; Mickens, J.; Seltzer, M. Unicorn: Runtime provenance-based detector for advanced persistent threats. arXiv 2020, arXiv:2001.01525. [Google Scholar]
- Ranjan, R.; Kumar, S.S. User behaviour analysis using data analytics and machine learning to predict malicious user versus legitimate user. High-Confid. Comput. 2022, 2, 100034. [Google Scholar] [CrossRef]
- Gaddam, A.; Mukhopadhyay, S.C.; Gupta, G.S. Elder care based on cognitive sensor network. IEEE Sens. J. 2010, 11, 574–581. [Google Scholar] [CrossRef]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.v.d. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- Youn, J.; Kim, K.; Kang, D.; Lee, J.; Park, M.; Shin, D. Research on Cyber ISR Visualization Method Based on BGP Archive Data through Hacking Case Analysis of North Korean Cyber-Attack Groups. Electronics 2022, 11, 4142. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Data | Detection Technique | Limitations |
|---|---|---|---|
| Aslan, O., et al. [10] | Host (System calls, …) [11,12,13,14,15,16,17,18,19] | J48 [19], RF [20], LMT [21], KNN [22] | No analysis of false positives/negatives |
| Jones, C. B., et al. [23] | IDS Data, Host (System calls, …) [23] | ART [24] | Limited to online anomaly detection |
| Sarker, I. H. [25] | UNSW-NB15 [26], NSL-KDD [27] | RF [20], KNN [22], NB [28], LDA [29], XGBoost [30], SVM [31], AdaBoost [32], SGD [33], LR [34] | No evaluation on real-world attacks |
| Ibrahim, W. N. H., et al. [35] | CTU-13 [36] | KNN [22], SVM [31], MLP [37] | Limited to botnet command and control server detection |
| Wang, S., et al. [38] | Host (System calls, …) [13] | SVM [31], LR [34], MLP [37], MatchGNet [38], GCN [39] | No analysis of false positives/negatives |
| Han, X., et al. [40] | Host (System calls, …) [40] | Graph-based [40] | Limited evaluation on real-world data |
| Ranjan, R., et al. [41] | Host (server, app, …) [41] | RF [20] | Limited data collection, algorithm validation, and visualization methods |
| Parent_Elevated | Elevated | Elevated_Type | Removed | Image_Codesign | Is_Wow | Label |
|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 | 3 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 0 | 0 | 3 | 0 | 0 | 0 | 1 |
| Column | Description |
|---|---|
| Parent_elevated | Whether the parent process’s token is elevated 0: Token not elevated (Not admin rights) 1: Token elevated (Elevate to Administrator privileges) |
| Elevated | Whether the token is elevated 0: Token not elevated (Not admin rights) 1: Token elevated (Elevate to Administrator privileges) |
| Elevated_type | Token elevation type 1: TokenElevationTypeDefault 2: TokenElevationTypeFull 3: TokenElevationTypeLimited |
| Removed | Whether to delete the execution image of Process 0: Execution image not deleted 1: Execution image deleted |
| Image_codesign | Electronic Signature Verification Value Unknown = 0 NoSignature = 1 Trusted = 2 Expired = 3 Revoked = 4 Distrust = 5 SecuritySettings = 6 BadSignature = 7 |
| Is_wow | 0: Not a WoW process 1: WoW process |
| Label | 0: Malicious behavior 1: Normal behavior |
| Parameters | AE Value | MemAE Value |
|---|---|---|
| Epochs | 100 | 1 |
| Batch size | 32 | 1 |
| Activation function | LeakyReLU, Linear | relu, sigmoid |
| Optimizer | adam | adam |
| Memory size | - | 100 |
| Loss function | Mean squared error | Mean squared error |
| Actual Values | |||
|---|---|---|---|
| Positive | Negative | ||
| Predicted Values | Positive | TP | FP |
| Negative | FN | TN | |
| Models | Original Dataset | Preprocessed Dataset (ADASYN) | Preprocessed Dataset (SMOTE) |
|---|---|---|---|
| KNN | 0.9249 | 0.9727 | 0.9788 |
| NB | 0.9152 | 0.9579 | 0.9687 |
| RF | 0.9232 | 0.8942 | 0.9788 |
| AE | 0.9553 | 0.9733 | 0.9792 |
| MemAE | 0.9611 | 0.9812 | 0.9826 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| KNN | 0.90 | 0.93 | 0.91 |
| NB | 0.77 | 0.82 | 0.79 |
| RF | 0.89 | 0.92 | 0.90 |
| AE | 0.93 | 0.96 | 0.94 |
| MemAE | 0.92 | 0.96 | 0.94 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| KNN | 0.94 | 0.91 | 0.93 |
| NB | 0.93 | 0.88 | 0.90 |
| RF | 0.83 | 0.78 | 0.80 |
| AE | 0.92 | 0.93 | 0.92 |
| MemAE | 0.97 | 0.94 | 0.96 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| KNN | 0.98 | 0.96 | 0.97 |
| NB | 0.86 | 0.86 | 0.86 |
| RF | 0.98 | 0.96 | 0.97 |
| AE | 1.00 | 0.99 | 0.99 |
| MemAE | 1.00 | 1.00 | 1.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, R.; Kim, K.; Choi, B.; Jeong, Y. A Study on Detection of Malicious Behavior Based on Host Process Data Using Machine Learning. Appl. Sci. 2023, 13, 4097. https://doi.org/10.3390/app13074097
Han R, Kim K, Choi B, Jeong Y. A Study on Detection of Malicious Behavior Based on Host Process Data Using Machine Learning. Applied Sciences. 2023; 13(7):4097. https://doi.org/10.3390/app13074097
Chicago/Turabian StyleHan, Ryeobin, Kookjin Kim, Byunghun Choi, and Youngsik Jeong. 2023. "A Study on Detection of Malicious Behavior Based on Host Process Data Using Machine Learning" Applied Sciences 13, no. 7: 4097. https://doi.org/10.3390/app13074097