1. Introduction
The rapid advancement of artificial intelligence (AI) technologies, particularly in the domains of machine learning and deep learning, has fostered the development of various AI models [
1,
2,
3]. Generative models utilizing AI frameworks have garnered significant attention, as they learn from provided sample distributions and create samples that closely mimic the features of the training data [
4,
5,
6,
7]. These models have been successfully applied to numerous image processing and data analysis tasks due to their ability to generate interesting and realistic samples without requiring the learning of complex structural features [
8,
9,
10].
Generative adversarial networks (GANs) are a prominent type of generative model, capable of producing realistic samples by learning the latent space of a dataset [
11,
12,
13,
14]. A GAN consists of two neural networks, namely the generator and the discriminator. The generator receives a random noise vector as input and aims to create fake samples that closely resemble real samples. The discriminator, on the other hand, learns to differentiate between real samples and fake samples generated by the generator. Through an iterative process of deception and detection, the generator and discriminator improve their performance, ultimately synthesizing a generated sample distribution that minimizes the difference from the real sample distribution.
In GAN, all data are considered random variables with their corresponding probability distributions. Each time a random variable is measured, it produces a different value, making it necessary to understand the probability distribution of the random variable to generate numbers that adhere to a specific distribution. By having knowledge of the probability distribution, the statistical properties of the data can be analyzed. GAN generates data randomly to conform to a given probability distribution, resulting in generated data with values comparable to the original data used to determine the probability distribution. Thus, the ultimate goal of GAN is to estimate the probability distribution of unprocessed data, enabling an artificial neural network to generate an infinite number of new datasets that share the exact same probability distribution as the original data. In summary, GAN learns the probability distribution and uses deep learning to generate this distribution.
GANs have been expanded in various domains [
6,
15,
16], including image and video processing as well as image translation, voice signals, 3D rendering, and natural language processing [
17,
18,
19,
20,
21,
22,
23,
24]. One notable application is text-to-image synthesis, which involves generating synthetic images based on given conditional text inputs [
25,
26,
27,
28,
29]. By using different input noise vectors, GANs can generate distinct synthetic images corresponding to the same input sentence.
However, conventional GANs face a significant limitation in text-to-image synthesis tasks: due to the use of a random distribution as the input noise vector, controlling the features of the generated samples based on input texts is challenging [
30]. To overcome this limitation, conditional GANs (cGANs) have been introduced, allowing for the generation of text-conditional images by incorporating text-conditional encoding vectors in the generator and discriminator [
31,
32,
33]. The cGAN-based GAN with conditional latent space interpolation and manifold interpolation (GAN-CLS-INT) has been proposed for text-to-image synthesis [
25]. Although GAN-CLS-INT can generate natural-looking images from textual descriptions, it often fails to produce images that fully correspond to the given text, with generated images only partially reflecting the context of the input text [
34,
35].
In this study, we introduce TextControlGAN, a groundbreaking text-to-image synthesis model that expands upon the ControlGAN architecture [
36]. The primary innovation of ControlGAN lies in the inclusion of a more advanced classifier, as opposed to the classification component within the cGAN discriminator. ControlGAN comprised three sub-networks: a generator, a discriminator, and a classifier. The generator capitalizes on both the discriminator and the classifier, where the classifier supplies conditional information, and the discriminator refines the authenticity of the generated images. Data augmentation (DA) techniques are employed to train the classifier, thereby improving its classification quality and reducing overfitting issues [
37,
38].
In TextControlGAN, we substitute the classifier with a regressor that learns to encode text conditional vectors. The regressor aims to estimate the corresponding encoding vector given an image input. DA techniques are applied in the training process of the regressor, paralleling the approach used with classifiers in traditional ControlGAN models. Consequently, the generator learns to generate images that can be accurately estimated by the regressor based on the feedback provided.
The primary objective of our study is to generate realistic images that adhere to the context of given texts using TextControlGAN. We evaluate the model using quantitative methods and conventional GAN metrics [
39,
40,
41], comparing its performance to other text-to-image synthesis GANs based on the cGAN framework. This study’s main contributions are fourfold: (1) the proposal of a GAN architecture capable of generating images conditioned on given text descriptions, (2) integrating neural network structures using independent regressors to train three neural network structures: in the regressor, it learns by estimating the text encoding vector for the given image, (3) the experimental validation of TextControlGAN’s capacity to generate realistic images, and (4) the implementation of data augmentation techniques for the independent regressor without impacting the discriminator.
The rest of this paper is organized as follows: in
Section 2, we provide the necessary background on GANs, conditional GANs, and controllable GANs, as well as related work in text-to-image synthesis. In
Section 3, we describe our proposed TextControlGAN model and the training details. In
Section 4, we present and discuss our experimental results. Finally, we conclude the paper and provide directions for future research in
Section 5.
2. Background
2.1. Generative Adversarial Networks
The GAN, first proposed by Goodfellow et al. in 2014 [
11], is a neural network architecture consisting of two adversarial networks: a generator and a discriminator. The generator network is responsible for generating synthetic data, while the discriminator network aims to distinguish between real and generated data. This competition between the two networks compels them to iteratively learn and enhance their abilities to generate and differentiate data, respectively. The GAN training process can be represented by the following equation, where
D denotes the discriminator network and
G represents the generator network:
where
represents the objective function of GAN training;
denotes image samples; and
denotes random noise vectors sampled from a specific distribution.
and
denote the original data distribution and noise distribution, respectively.
The primary goal of GAN is to maximize the function from the perspective of D while minimizing it from the perspective of G. Consequently, if image is used as the input of D, the discriminator aims to output one, i.e., otherwise, if a synthetic image becomes the input, it is expected to produce zero, i.e., . However, the generator has an opposite objective to the discriminator, in which .
This can be interpreted as the generator attempting to deceive the discriminator by generating increasingly realistic images that the discriminator cannot distinguish from real samples. This adversarial training process pushes both networks to improve, resulting in the generator producing high-quality synthetic data that closely resembles the distribution of the real data.
2.2. Conditional GANs
A cGAN [
31] is a type of GAN that can generate data conditioned on given conditions. For example, a cGAN can generate images of faces given text descriptions of the desired facial features as conditions. cGANs can be used to generate images corresponding to a given input, such as generating an image of a face from its description. The cGAN training process is similar to the GAN training process, with the addition of conditions y on both the generator and discriminator networks:
where
represents the objective function of cGAN training;
denotes image samples;
denotes conditional vector; and
denotes random noise vectors sampled from a specific distribution.
To implement this concept, the conditional vector, y, is generally concatenated or multiplied to the input noise vector, z, in the generator, whereas y is concatenated or multiplied to the input layer or penultimate layer in the discriminator. After the cGAN training, the generator can produce conditional samples with different y values.
2.3. Controllable GANs
Recent advancements have been made in conditional-based methods for generating realistic samples. For instance, the Auxiliary Classifier GAN (ACGAN) [
35] is a conventional method for generating conditional samples that employs a classification layer in the discriminator and exhibits satisfactory results. However, the auxiliary classifier was found to be insufficient for generator training [
42,
43,
44], as it encountered issues of overfitting the classifier. Moreover, incorporating Data Augmentation (DA) techniques in ACGAN’s training process proved challenging [
45], given that the additional classifier was attached to the discriminator. The utilization of DA in GAN structures’ learning has been identified as a key concern within this method.
To address this issue, ControlGAN [
36] was proposed, highlighting a trade-off in performance when using DA for ACGAN. ControlGAN aims to separate the classifier from the discriminator, enabling the use of DA without impeding GAN training by leveraging DA solely for independent classifiers. Specifically, ControlGAN introduces three distinct neural network structures and a target function designed to maintain a balanced training process for a generator that is concurrently trained by two separate network modules.
By successfully separating the classifier from the discriminator, ControlGAN presents a promising solution for enhancing the performance of conditional GANs, thus contributing to the ongoing development and optimization of GAN architectures for a myriad of applications within the realm of generative models.
2.4. Text-to-Image Synthesis
Text-to-image synthesis refers to the process of producing images from textual descriptions, which presents a formidable challenge as it necessitates the comprehension of textual meaning and its subsequent conversion into corresponding visual concepts. This field offers numerous applications, such as the creation of photorealistic avatars based on textual descriptions. Multiple approaches have been proposed to address text-to-image synthesis, including retrieval-based methods and generation-based methods.
Retrieval-based methods involve selecting images from an extensive database that correspond to a given textual description. These selected images are subsequently combined to form a new image that adheres to the desired specifications. One notable advantage of retrieval-based methods lies in their capacity to generate high-quality images, provided that a database of high-quality images is available. Furthermore, these methods tend to be faster than generation-based methods since they do not necessitate the creation of images from scratch. However, retrieval-based methods are contingent upon the availability of a large image database, which may prove challenging to obtain. Additionally, these methods may struggle to retrieve all pertinent images from the database, particularly in cases where the textual description is lengthy or complex.
On the other hand, generation-based methods entail the creation of images from scratch, guided by the given textual description. These methods typically employ a generative model, such as a GAN, to generate images that align with the textual description. A primary advantage of generation-based methods is their ability to generate images even in the absence of an image database. Nonetheless, training generation-based methods can be arduous, and the resulting images may not exhibit the same level of realism as those produced by retrieval-based methods. As GANs have demonstrated outstanding performance in general image synthesis [
35,
46], GAN-based text-to-image synthesis has recently garnered significant attention. GAN-based models generally introduce the cGAN architecture, where encoding vectors of conditional texts are used as y in Equation (2). As one of the studies with this idea, GAN-INT-CLS [
16] has demonstrated that this model can successfully generate synthetic images that follow the contexts in given sentences.
The GAN-INT-CLS model is a GAN architecture that accepts both image and text data as input, effectively generating images that correspond to specified textual descriptions. This model comprised two main components: a text encoder responsible for converting input text into a latent vector, and an image generator tasked with producing an image derived from the latent vector. The discriminator is trained to differentiate between authentic and counterfeit (text, image) pairs.
To provide contextual information during the discriminator’s training process, pairs comprising a genuine image and mismatched text are incorporated as counterfeit examples. Furthermore, GAN-INT-CLS introduces interpolation within the embedding vector, which facilitates training with continuous manifold data. Consequently, this enables the generation of images that adhere to the features delineated in corresponding textual descriptions, even in cases where the model has not previously encountered those precise combinations.
By employing such a sophisticated approach, the GAN-INT-CLS model demonstrates its potential for generating high-quality images in response to a diverse range of textual descriptions. Thus advancing the field of text-to-image synthesis and expanding its applicability in various domains.
There are several other existing studies related to the proposed method. Reed et al. [
47], were able to generate 64 × 64 resolution images corresponding to textual descriptions by building on the Generative Adversarial What-Where Networks [
48]. To improve the generative process, StackGAN [
26] was proposed to divide the process into two stages, with the first stage generating low-resolution images with basic visual information and the second stage generating high-resolution images with more detailed features. Furthermore, the authors of [
27] enhanced the StackGAN method to deal with both conditional and unconditional generative tasks while stabilizing the training of GANs by approximating multiple distributions jointly. To explore class information from text descriptions, TAC-GAN [
49] was proposed, which employs a text-conditioned auxiliary classifier to diversify synthetic images and enhance their structural coherence.
3. Methods
3.1. Text-to-Image Synthesis with Controllable GAN Framework
In this paper, we present a text-to-image synthesis model based on the ControlGAN [
36] framework as a viable alternative to cGAN. One primary advantage of employing a ControlGAN lies in its utilization of an independent classifier, while in cGAN, the discriminator assumes responsibility for classification. This approach enables us to train the classifier with DA methods, incorporating modified and slightly distorted images during the training process.
The proposed model, TextControlGAN, builds upon the concept of ControlGAN to condition texts. Given that text encoding vectors possess continuous values, TextControlGAN introduces a regressor, distinguishing it from conventional ControlGAN. The regressor fulfills a role analogous to the classifier in ControlGAN, as it seeks to estimate text encoding vectors from given images. By employing DA methods for training the regressor, which slightly distort input images during the process, the regressor model can be trained with reduced overfitting issues and exhibit enhanced performance.
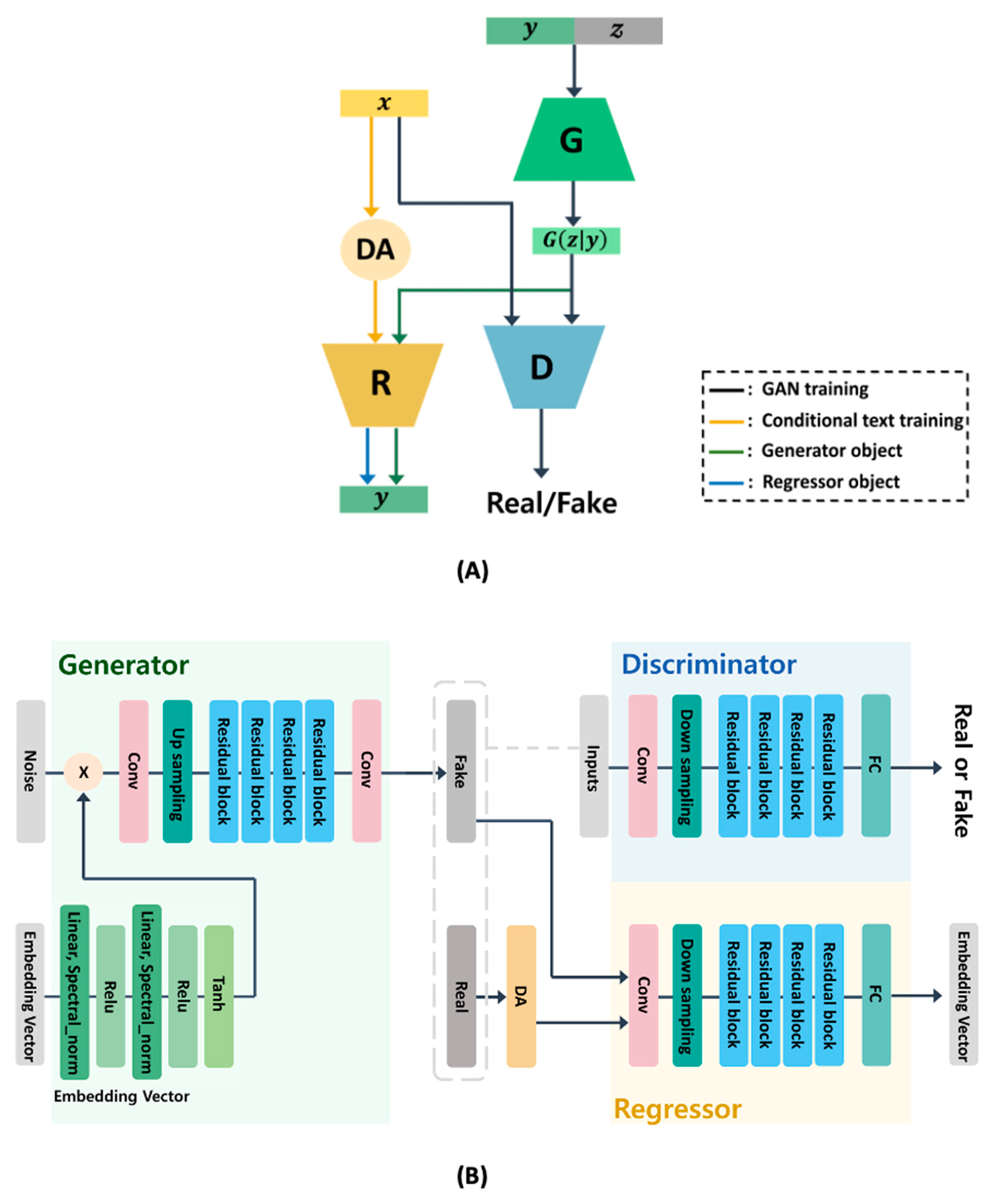
Consequently, TextControlGAN comprises three distinct neural network structures: a generator, a discriminator, and a regressor.
Figure 1 illustrates the comprehensive structure of TextControlGAN. The generator generates synthetic images using corresponding text embedding vectors and noise vectors as inputs. These images are then compared to real-world images by the discriminator. Deviating from cGAN and GAN-INT-CLS models, the discriminator is solely responsible for its primary task, which is the binary classification of authentic versus fake imitations. Instead of involving the discriminator in the conditional text learning, conditional texts are learned exclusively by another specialized structure called the regressor. Within the regressor, DA methods are employed to improve performance, enabling the generator to learn the conditional information more effectively than if it relied only on the discriminator in cGAN and GAN-INT-CLS. The objective of TextControlGAN learning can be represented as follows:
where
represents the regressor and
is the objective function of the regressor.
The TextControlGAN objective as expressed in Equation (3) bears resemblance to that of cGAN; however, a key difference is that, in TextControlGAN, the discriminator (D) does not learn the conditional information with y. As demonstrated in Equations (3) and (5), the generator has dual objectives: it seeks to deceive the discriminator in order to be classified as real, while simultaneously aiming to have the correct text encoding vectors estimated by the regressor, in accordance with the generated images.
All structures in TextControlGAN are composed of residual blocks; the generator, discriminator, and regressor each contain four such blocks. Each block comprises two convolutional layers. In the generator, upsampling by a factor of two is executed using the nearest neighbor method within each residual block. The generator is composed of 10 convolutional layers with 96 kernels, where the first and the last two layers are convolutional layers and four residual blocks with two convolutional layers each. Similarly, downsampling is performed on the first three residual blocks of both the discriminator and regressor, effectively reducing dimensionality by eight times. The regressor accepts augmented images as inputs with the purpose of estimating corresponding text encoding vectors.
The utilization of the TextControlGAN framework is anticipated to yield superior performance in conditional text learning. This expectation arises from the fact that the regressor is trained more effectively than the text-learning component of the discriminator in GAN-INT-CLS. Consequently, the generator learns from this more proficient regressor and, in turn, generates more realistic and text-conditioned images. Moreover, as the discriminator’s training is specifically focused on GAN training, this also contributes to an overall enhancement in image quality.
3.2. Training Details of TextControlGAN
To train TextControlGAN, the Adam optimizer [
50] was used with the parameters of
and
; the learning rate of the generator and discriminator was set to 0.0001 [
51]. In order to address the mode collapse issue in the GAN training, the Wasserstein loss [
30] and hinge loss [
52] functions were used in the generator and discriminator, respectively. For the regressor, the Adam optimizer was employed with
and
, which are conventional values for deep learning models. The learning rate of the regressor was set at 0.0005. The model was trained on one RTX 3090GPU with 24GB memory with a batch size of 128. The version of Python was 3.8.12 and the Pytorch version was 1.9.0 with CUDA 11.1.
4. Result and Discussion
4.1. Quantitative Evaluation with a Bird Image Dataset
In the evaluation of the proposed model, the Caltech-UCSD Birds-200 (CUB) [
40] dataset was employed. The CUB dataset consists of 11,788 images for 200 different types of birds. Each image is annotated with attributes of birds, which correspond to the colors and shapes of the birds. By using this annotation, text captions to describe the images have been employed in GAN-INT-CLS, where 27,450 pairs of images and corresponding texts exist; whereas there are 11,788 images in the dataset, these pairs are composed of multiple texts for particular images. The text encoding vector y has a dimension of 1024 for each text. In this experiment, images with a 64 × 64 resolution were produced and evaluated; thus, real images in the dataset were down-scaled with the same size in the preprocessing step.
For the quantitative evaluation metrics, Inception score (IS) [
39] and Frechet Inception distance (FID) [
41] were used, where these metrics are conventional methods to evaluate generative models. These metrics commonly use a pre-trained Inception network, and specific layer outputs of the network are employed to assess the quality of generated images; a high IS and a low FID indicate superior performance. The IS was measured with ten different sets of 5000 samples, which is a conventional method for calculating IS; then, the average IS and standard deviation were computed.
In the evaluation, two baseline models were compared to the proposed model. First, cGAN-based GAN-INT-CLS was evaluated with IS and FID in order to demonstrate the performance of the DA methods integrated with the independent regressor. Additionally, TextControlGAN without DA was assessed to verify that the independent regressor cannot solely perform without DA methods.
Table 1 showcases the performance of various models, including recent models, such as AttnGAN and DM-GAN [
53], highlighting that the proposed TextControlGAN outperforms other methods, including GAN-INT-CLS. TextControlGAN achieved an IS of 4.41 ± 0.02, signifying a 17.6% improvement compared to GAN-INT-CLS in terms of IS. This demonstrates the effectiveness of the proposed framework, which employs an independent regressor in conjunction with DA techniques, in accurately learning conditional text. Moreover, the FID for TextControlGAN decreased by 36.6% relative to GAN-INT-CLS, further substantiating TextControlGAN’s superior performance.
However, when DA techniques were excluded from the proposed architecture (TextControlGAN w/o DA), the performance declined compared to that of TextControlGAN. This outcome is believed to stem from overfitting issues in the regressor, as DA techniques generally reduce overfitting in neural network models. As a result, this finding highlights the necessity of incorporating DA techniques when training the proposed architecture to ensure optimal performance.
An evaluation of the proposed model, TextControlGAN, was conducted to assess its computing time per epoch, in comparison to GAN-INT-CLS. The results indicated that the proposed model required approximately 447.56 s, while GAN-INT-CLS necessitated approximately 637.55 s per epoch. Despite being 29.8% less computationally efficient than GAN-INT-CLS, TextControlGAN surpassed GAN-INT-CLS in terms of performance, as evidenced by the presented results.
4.2. Quantitative Evaluation of Generated Images by TextControlGAN
In this section, we present several images generated by TextControlGAN alongside multiple textual examples.
Figure 2 showcases the results obtained from TextControlGAN and other baseline models. Generally, when generating text-conditional images, TextControlGAN consistently outperformed the other methods, which occasionally failed to produce images that adhered to the given textual conditions.
For instance, in the first text example, one of the textual conditions specified that “The belly is white”. However, the alternative models were unable to accurately capture this condition in their generated images. In contrast, all images generated by TextControlGAN successfully depicted a bird with a white belly. Moreover, in the third example, where the objective was to generate images featuring an “orange beak”, TextControlGAN predominantly produced images with the desired attribute. Conversely, many images generated by the other models not only lacked the orange color in the beak but also failed to incorporate the color in other body parts.
These examples demonstrate the superior capability of TextControlGAN in capturing the nuances of textual descriptions and effectively translating them into accurate visual representations, thereby highlighting its potential for generating high-quality, text-conditional images in various applications.
4.3. Evaluation with Higher Resolution Images
In supplementary experiments, TextControlGAN was employed to generate 128 × 128 resolution images, which were then assessed using untrained text inputs. The CUB dataset, featuring 128 × 128 resolution images, served as the training set. The TextControlGAN architecture for this experiment remained identical to the previous experiment involving 64 × 64 images, with the exception of the number of layers. Additional residual modules, each comprising two convolutional layers and either downsampling or upsampling, were introduced. Specifically, the generator was equipped with an additional residual module featuring upsampling, while the discriminator and regressor each received an additional residual module with downsampling. The number of training iterations and hyperparameters for the model were set to match those of the previous experiment.
Figure 3 displays the generated images with random text inputs, revealing that the 128 × 128 resolution images corresponded to bird images and exhibited features characteristic of the CUB training set. Moreover, generated images utilizing untrained text inputs were evaluated. As ControlGAN-based models excel in the intricate modification of minor features, this strength was assessed through alterations in the shape of the bird images’ bills.
Figure 4 presents the generated images using untrained text inputs with modifications in minor features, demonstrating that the images produced by TextControlGAN adhered to the corresponding text inputs. In particular, it was observed that minor features, such as the shape of the bill, could be effectively controlled by TextControlGAN’s input text. Consequently, TextControlGAN successfully generated bird images with both long-pointed and short-pointed bills, further illustrating the model’s capacity for precise control over visual features.
5. Conclusions
In this paper, we have introduced a novel GAN-based text-to-image synthesis model, termed TextControlGAN. While existing models have incorporated the conditional GAN (cGAN) framework in their training processes, TextControlGAN leverages the ControlGAN-based framework to enhance the model’s text-conditioning capabilities. Within TextControlGAN, an independent regressor is implemented along with Data Augmentation (DA) techniques for its training.
Evaluations were conducted using a bird image dataset containing approximately 30,000 pairs of images and corresponding textual descriptions. The results revealed that TextControlGAN achieved a 17.6% improvement in Inception Score (IS) and a 36.6% reduction in Fréchet Inception Distance (FID) when compared to GAN-INT-CLS, a cGAN-based model. In the comparison of generated images, it was observed that those produced by TextControlGAN adhered to the conditional text inputs, while alternative models occasionally failed to accurately reflect the contextual information of the text inputs.
By incorporating an independent regressor and DA techniques, the proposed TextControlGAN learning method was applied to the GAN-INT-CLS model structure, leading to exceptional performance. The versatility of the proposed method allows for its easy adaptation to other model structures, thus contributing to the exploration and development of additional models in future research endeavors.









{kind=link}
{kind=link}
{kind=link}
{kind=link}