
Boundary–Inner Disentanglement Enhanced Learning for Point Cloud Semantic Segmentation


Abstract
:1. Introduction

- (1)
- This paper shows that reducing boundary–inner entanglement is beneficial for overall semantic segmentation accuracy.
- (2)
- This paper proposes BIDEL, a lightweight framework for improving the segmentation accuracy of boundary points, which can maximize boundary–inner disentanglement through a newly formulated boundary loss function. Notably, BIDEL does not need additional complex modules and learning parameters, and it can be integrated into many existing segmentation networks.
- (3)
- Experiments on challenging indoor and outdoor benchmarks show that BIDEL can bring significant improvements in boundary and overall performance across different baselines.
2. Related Work
2.1. Semantic Segmentation
2.2. Semantic Boundary
3. Methods
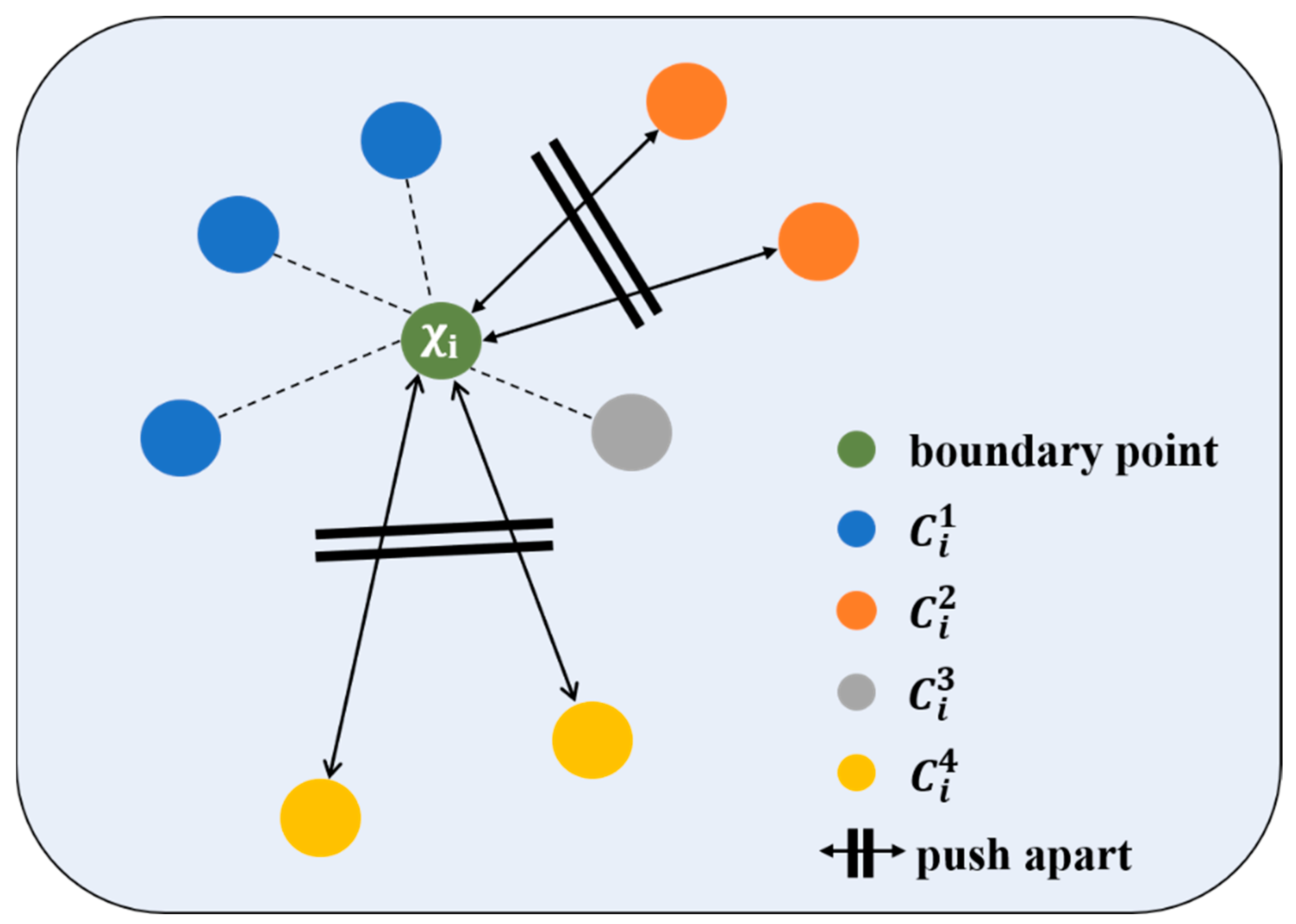
3.1. Boundary–Inner Entanglement Measurement
- denotes the input point cloud;
- n denotes the number of points in ;
- denotes point in ;
- denotes the ground truth of ;
- denotes the Euclidian 3D coordinates of ;
- denotes the feature of ;
- denotes the boundary point set in .
- (1)
- : boundary points within the same category;
- (2)
- : inner points within the same category;
- (3)
- : boundary points in a different category;
- (4)
- : inner points in a different category.
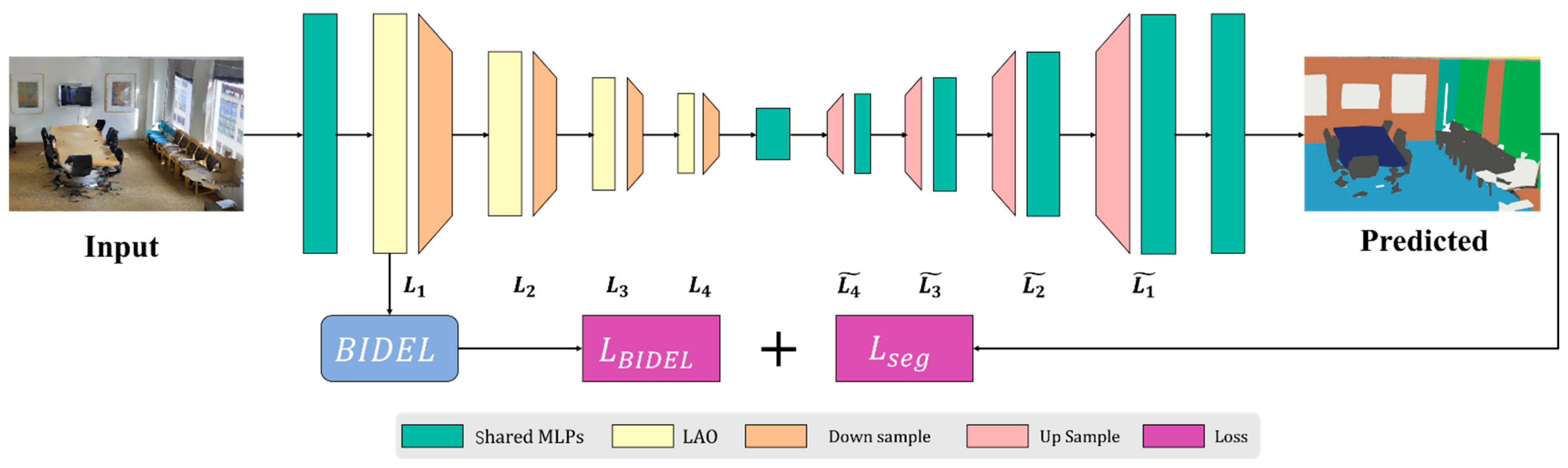
3.2. Boundary–Inner Disentanglement Enhanced Learning
3.3. Implementation Details
4. Experimental Results and Discussion
4.1. S3DIS Indoor Scene Segmentation
4.2. Toronto-3D Outdoor Scene Segmentation
4.3. Semantic3D Outdoor Scene Segmentation
4.4. Ablation Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, P.; Ma, Z.; Fei, M.; Liu, W.; Guo, G.; Wang, M. A Multiscale Multi-Feature Deep Learning Model for Airborne Point-Cloud Semantic Segmentation. Appl. Sci. 2022, 12, 11801. [Google Scholar] [CrossRef]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.K.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Qi, C.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Pierdicca, R.; Paolanti, M.; Matrone, F.; Martini, M.; Morbidoni, C.; Malinverni, E.S.; Frontoni, E.; Lingua, A.M. Point Cloud Semantic Segmentation Using a Deep Learning Framework for Cultural Heritage. Remote Sens. 2020, 12, 1005. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Hu, H.; Cao, Y.; Zhang, Z.; Tong, X. A Closer Look at Local Aggregation Operators in Point Cloud Analysis. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 326–342. [Google Scholar]
- Xu, M.; Zhou, Z.; Zhang, J.; Qiao, Y. Investigate indistinguishable points in semantic segmentation of 3d point cloud. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 3047–3055. [Google Scholar]
- Hu, Z.; Zhen, M.; Bai, X.; Fu, H.; Tai, C.-L. JSENet: Joint Semantic Segmentation and Edge Detection Network for 3D Point Clouds. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 222–239. [Google Scholar]
- Gong, J.; Xu, J.; Tan, X.; Zhou, J.; Qu, Y.; Xie, Y.; Ma, L. Boundary-Aware Geometric Encoding for Semantic Segmentation of Point Clouds. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 1424–1432. [Google Scholar]
- Du, S.; Ibrahimli, N.; Stoter, J.E.; Kooij, J.F.P.; Nan, L. Push-the-Boundary: Boundary-aware Feature Propagation for Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–15 September 2022; pp. 1–10. [Google Scholar]
- Liu, T.; Cai, Y.; Zheng, J.; Thalmann, N.M. BEACon: A boundary embedded attentional convolution network for point cloud instance segmentation. Vis. Comput. 2021, 38, 2303–2313. [Google Scholar] [CrossRef]
- Yin, X.; Li, X.; Ni, P.; Xu, Q.; Kong, D. A Novel Real-Time Edge-Guided LiDAR Semantic Segmentation Network for Unstructured Environments. Remote Sens. 2023, 15, 1093. [Google Scholar] [CrossRef]
- Tang, L.; Zhan, Y.; Chen, Z.; Yu, B.; Tao, D. Contrastive Boundary Learning for Point Cloud Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8489–8499. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2D-3D-Semantic Data for Indoor Scene Understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Maturana, D.; Scherer, S.A. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. OctNet: Learning Deep 3D Representations at High Resolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6620–6629. [Google Scholar]
- Le, T.; Duan, Y. PointGrid: A Deep Network for 3D Shape Understanding. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9204–9214. [Google Scholar]
- Wang, P.-S.; Liu, Y.; Guo, Y.-X.; Sun, C.-Y.; Tong, X. O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection From Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Li, L.; Zhu, S.; Fu, H.; Tan, P.; Tai, C.-L. End-to-End Learning Local Multi-View Descriptors for 3D Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1916–1925. [Google Scholar]
- You, H.; Feng, Y.; Ji, R.; Gao, Y. PVNet: A Joint Convolutional Network of Point Cloud and Multi-View for 3D Shape Recognition. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E.G. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Wang, C.; Pelillo, M.; Siddiqi, K. Dominant Set Clustering and Pooling for Multi-View 3D Object Recognition. arXiv 2019, arXiv:1906.01592. [Google Scholar]
- Yu, T.; Meng, J.; Yuan, J. Multi-view Harmonized Bilinear Network for 3D Object Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 186–194. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- Wang, W.; Cai, Y.; Wang, T. Multi-view dual attention network for 3D object recognition. Neural Comput. Appl. 2021, 34, 3201–3212. [Google Scholar] [CrossRef]
- Guo, M.; Cai, J.; Liu, Z.; Mu, T.; Martin, R.R.; Hu, S. PCT: Point Cloud Transformer. Comput. Vis. Meida 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the Neural Information Processing Systems (NeurlIPS), Montréal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-Shape Convolutional Neural Network for Point Cloud Analysis. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8887–8896. [Google Scholar]
- Thomas, H.; Qi, C.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar]
- Wu, W.; Qi, Z.; Li, F. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9613–9622. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Li, Y.; Hao, S.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent Slice Networks for 3D Segmentation of Point Clouds. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2626–2635. [Google Scholar]
- Xu, M.; Ding, R.; Zhao, H.; Qi, X. PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3172–3181. [Google Scholar]
- Lei, H.; Akhtar, N.; Mian, A.S. SegGCN: Efficient 3D Point Cloud Segmentation With Fuzzy Spherical Kernel. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11608–11617. [Google Scholar]
- Mao, J.; Wang, X.; Li, H. Interpolated Convolutional Networks for 3D Point Cloud Understanding. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019; pp. 1578–1587. [Google Scholar]
- Binh-Son, H.; Minh-Khoi, T.; Sai-Kit, Y. Pointwise Convolutional Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 984–993. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10288–10297. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Qin, C.; You, H.; Ran, H.; Fu, Y. Rethinking Network Design and Local Geometry in Point Cloud: A Simple Residual MLP Framework. arXiv 2022, arXiv:2202.07123. [Google Scholar]
- Lee, H.J.; Kim, J.U.; Lee, S.; Kim, H.G.; Ro, Y.M. Structure Boundary Preserving Segmentation for Medical Image With Ambiguous Boundary. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4816–4825. [Google Scholar]
- Wang, K.; Zhang, X.; Zhang, X.; Lu, Y.; Huang, S.; Yang, D. EANet: Iterative edge attention network for medical image segmentation. Pattern Recognit. 2022, 127, 108636. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, J.; Zhou, Z.; Xu, M.; Qi, X.; Qiao, Y. Learning Geometry-Disentangled Representation for Complementary Understanding of 3D Object Point Cloud. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021. [Google Scholar]
- Frosst, N.; Papernot, N.; Hinton, G.E. Analyzing and Improving Representations with the Soft Nearest Neighbor Loss. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Salakhutdinov, R.; Hinton, G.E. Learning a Nonlinear Embedding by Preserving Class Neighbourhood Structure. In Proceedings of the Eleventh International Conference on Artificial Intelligence and Statistics, San Juan, Puerto Rico, 21–24 March 2007. [Google Scholar]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 797–806. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. SEMANTIC3D.NET: A New Large-Scale Point Cloud Classification Benchmark. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Hannover, Germany, 6–9 June 2017; pp. 91–98. [Google Scholar]
- Tchapmi, L.P.; Choy, C.B.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Ma, L.; Li, Y.; Li, J.; Tan, W.; Yu, Y.; Chapman, M.A. Multi-Scale Point-Wise Convolutional Neural Networks for 3D Object Segmentation From LiDAR Point Clouds in Large-Scale Environments. IEEE Trans. Intell. Transp. Syst. 2021, 22, 821–836. [Google Scholar] [CrossRef]
- Rim, B.; Lee, A.; Hong, M. Semantic Segmentation of Large-Scale Outdoor Point Clouds by Encoder–Decoder Shared MLPs with Multiple Losses. Remote Sens. 2021, 13, 3121. [Google Scholar] [CrossRef]
- Yan, K.; Hu, Q.; Wang, H.; Huang, X.-Z.; Li, L.; Ji, S. Continuous Mapping Convolution for Large-Scale Point Clouds Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | OA (%) | mACC (%) | mIoU (%) | |
|---|---|---|---|---|
| Control group | (x, y, z, r, g, b) | 88.7 | 85.9 | 74.4 |
| Experiment group | (x, y, z, r, g, b, @boundary) | 93.0 | 90.5 | 81.6 |
| Configuration | ||
|---|---|---|
| Hardware | CPU | AMD Ryzen 9 5900X 12-Core Processor 3.70 GHz |
| GPU | NVIDIA GeForce RTX 3080 Ti | |
| Software | Python IDE | Pycharm |
| Deep learning library | Tensorflow | |
| Visualization | Cloud Compare |
| Methods | mIoU (%) | OA (%) | mACC (%) | Ceil. | Floor | Wall | Beam | Col. | Wind. | Door | Table | Chair | Sofa | Book. | Board | Clut. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [33] | 41.1 | - | 49.0 | 88.8 | 97.3 | 69.8 | 0.1 | 3.9 | 46.3 | 10.8 | 59.0 | 52.6 | 5.9 | 40.3 | 26.4 | 33.2 |
| SegCloud [50] | 48.9 | - | 57.4 | 90.1 | 96.1 | 69.9 | 0.0 | 18.4 | 38.4 | 23.1 | 70.4 | 75.9 | 40.9 | 58.4 | 13.0 | 41.6 |
| PointCNN [29] | 57.3 | 85.9 | 63.9 | 92.3 | 98.2 | 79.4 | 0.0 | 17.6 | 22.8 | 62.1 | 74.4 | 80.6 | 31.7 | 66.7 | 62.1 | 56.7 |
| SPG [51] | 58.0 | 86.4 | 66.5 | 89.4 | 96.9 | 78.1 | 0.0 | 42.8 | 48.9 | 61.6 | 84.7 | 75.4 | 69.8 | 52.6 | 2.1 | 52.2 |
| GAC [40] | 62.9 | 87.8 | - | 92.3 | 98.3 | 82.0 | 0.0 | 20.4 | 59.0 | 40.9 | 85.8 | 78.6 | 70.8 | 61.7 | 74.7 | 52.8 |
| PCT [27] | 61.3 | - | 67.7 | 92.5 | 98.4 | 80.6 | 0.0 | 19.4 | 61.6 | 48.0 | 76.6 | 85.2 | 46.2 | 67.7 | 67.9 | 52.3 |
| IAF-Net * [6] | 64.6 | 88.4 | 70.4 | 91.4 | 98.6 | 81.8 | 0.0 | 34.9 | 62.0 | 54.7 | 79.7 | 86.9 | 49.9 | 72.4 | 74.8 | 52.1 |
| JSENet * [7] | 67.7 | - | - | 93.8 | 97.0 | 83.0 | 0.0 | 23.2 | 61.3 | 71.6 | 89.9 | 79.8 | 75.6 | 72.3 | 72.7 | 60.4 |
| PushBoundary * [9] | 67.1 | 89.7 | - | 94.0 | 97.9 | 82.6 | 0.0 | 23.3 | 56.6 | 75.4 | 80.1 | 91.1 | 75.7 | 74.4 | 62.3 | 59.1 |
| CBL * [12] | 65.3 | 87.5 | 74.5 | 92.2 | 97.7 | 81.0 | 0.0 | 36.8 | 61.0 | 39.4 | 78.1 | 88.1 | 81.4 | 71.5 | 68.7 | 52.6 |
| KPConv [31] | 66.2 | - | - | 94.8 | 98.4 | 82.9 | 0.0 | 18.0 | 53.4 | 67.1 | 83.0 | 91.4 | 63.8 | 75.5 | 71.6 | 60.8 |
| +BIDEL * | 67.0 | - | - | 94.9 | 98.5 | 83.3 | 0.0 | 21.4 | 54.9 | 68.5 | 83.1 | 91.2 | 66.0 | 75.7 | 71.8 | 61.1 |
| RandLA-Net [28] | 62.7 | 87.5 | 71.1 | 92.3 | 97.8 | 80.7 | 0.0 | 19.5 | 59.2 | 46.8 | 78.0 | 85.7 | 63.2 | 70.9 | 68.0 | 53.0 |
| +BIDEL * | 64.7 | 88.0 | 73.6 | 93.0 | 96.1 | 81.5 | 0.0 | 28.8 | 62.7 | 43.9 | 74.0 | 87.0 | 72.6 | 71.9 | 73.7 | 55.8 |
| Input | Methods | mIoU(%) | OA(%) | Road | Road Marking | Natural | Building | Utility Line | Pole | Car | Fence |
|---|---|---|---|---|---|---|---|---|---|---|---|
| xyz | PointNet++ [34] | 41.8 | 84.9 | 89.3 | 0.0 | 69.0 | 54.1 | 43.7 | 23.3 | 52.0 | 3.0 |
| DGCNN [41] | 61.8 | 94.2 | 93.9 | 0.0 | 91.3 | 80.4 | 62.4 | 62.3 | 88.3 | 15.8 | |
| KPConv [31] | 69.1 | 95.4 | 94.6 | 0.1 | 96.1 | 91.5 | 87.7 | 81.6 | 85.7 | 15.7 | |
| MS-PCNN [52] | 65.9 | 90.0 | 93.8 | 3.8 | 93.5 | 82.6 | 67.8 | 72.0 | 91.1 | 22.5 | |
| MS-TGNet [48] | 70.5 | 95.7 | 94.4 | 17.2 | 95.7 | 88.8 | 76.0 | 74.0 | 94.2 | 23.6 | |
| RandLA-Net [28] | 77.7 | 93.0 | 94.6 | 42.6 | 96.9 | 93.0 | 86.5 | 78.1 | 92.9 | 37.1 | |
| Multi-Loss PointNet++ [53] | 71.0 | 83.6 | 92.8 | 27.4 | 89.9 | 95.3 | 85.6 | 74.5 | 44.4 | 58.3 | |
| MappingConvSeg [54] | 82.9 | 94.7 | 97.2 | 67.9 | 97.6 | 93.8 | 86.9 | 82.1 | 93.7 | 44.1 | |
| xyz, rgb | KPConv [31] | 81.4 | - | 97.9 | 74.9 | 96.6 | 91.6 | 87.1 | 81.7 | 94.8 | 26.9 |
| +BIDEL * | 82.0 | - | 97.9 | 76.3 | 97.5 | 92.5 | 87.5 | 82.6 | 95.1 | 26.2 | |
| RandLA-Net [28] | 81.1 | 96.3 | 95.5 | 56.8 | 96.2 | 93.1 | 88.0 | 82.2 | 88.2 | 48.4 | |
| +BIDEL * | 81.5 | 96.7 | 96.1 | 61.3 | 97.0 | 93.5 | 87.3 | 81.2 | 90.1 | 45.3 |
| Boundary Loss | mIoU (%) | OA (%) | mACC (%) |
|---|---|---|---|
| 64.5 | 87.5 | 72.5 | |
| 62.2 | 86.7 | 71.7 | |
| 64.8 | 87.8 | 72.9 |
| mIoU (%) | OA (%) | mACC (%) | |
|---|---|---|---|
| 0.5 | 64.0 | 87.4 | 72.5 |
| 1 | 64.8 | 87.8 | 72.9 |
| 5 | 63.4 | 87.7 | 71.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; She, J.; Zhao, Q.; Wen, X.; Guan, Y. Boundary–Inner Disentanglement Enhanced Learning for Point Cloud Semantic Segmentation. Appl. Sci. 2023, 13, 4053. https://doi.org/10.3390/app13064053
He L, She J, Zhao Q, Wen X, Guan Y. Boundary–Inner Disentanglement Enhanced Learning for Point Cloud Semantic Segmentation. Applied Sciences. 2023; 13(6):4053. https://doi.org/10.3390/app13064053
Chicago/Turabian StyleHe, Lixia, Jiangfeng She, Qiang Zhao, Xiang Wen, and Yuzheng Guan. 2023. "Boundary–Inner Disentanglement Enhanced Learning for Point Cloud Semantic Segmentation" Applied Sciences 13, no. 6: 4053. https://doi.org/10.3390/app13064053