1. Introduction
Lots of real systems can be expressed as complex networks [
1]. In complex networks, besides the small world effect [
2,
3] and the power-law feature of degrees’ distribution [
4,
5], the community structure is considered as a most interesting and important feature [
6,
7], for example, the collection of web pages on related topics in the network of the World Wide Web [
8,
9], clusters of customers with similar interests in the network of purchase relationships [
9], and academic collaborations in a co-authorship network [
10]. Community detection is helpful to find these interesting structures and to understand dynamical behaviors on complex networks [
11]. Therefore, a community detection algorithm is significantly important.
Community detection is thought as a NP-hard problem. Therefore, obtaining a correct community partition is a large challenge. At present, many methods have been developed to detect the community structure, such as divisive algorithms [
6,
12], agglomerative algorithms [
13,
14,
15], spectral clustering [
16,
17,
18] dynamic methods [
19,
20,
21], Infomap [
22], Label propagation [
23], clustering based on density [
24], and optimization methods [
25,
26,
27]. Among them, the optimization methods are widely focused on. These class methods define the community detection as the optimization problem of an objective function. Two popular optimization methods are the Newman’s fast algorithm [
13] and the Louvain algorithm [
26]. The Newman’s fast algorithm maximizes the modularity
Q [
28] in the merging process of communities in pairs. Finally, the community partition with maximal
Q is thought as a good partition result. The complexity is
, and
is the number of nodes and edges of a network. Compared with the Newman’s fast algorithm, the complexity of the Louvain algorithm [
26] is linear, which has less time cost than the Newman’s fast algorithm. It aims to maximize the modularity
Q [
28]. When a node is removed from one community to another one, the calculation of the increase in the modularity is only related to the node and two corresponding communities. Thus, the computational efficiency is obviously better than that of the Newman’s fast algorithm. In addition, the Louvain algorithm can be conveniently parallelized to improve the calculation speed [
29,
30,
31].
The Louvain algorithm [
26] has been applied to a larger network. However, the accuracy of the detection result is rarely researched [
32,
33]. If we do not consider the processing of the network structure [
32,
33], the accuracy of the Louvain algorithm can be improved simply from two main points. Firstly, we can select a better objective function as the optimization goal. Currently, in addition to
Q, some other quality functions can also be used as the objective functions of optimization, such as moudularity
F [
34] and
M [
35]. However, they have some shortcomings. For example, there exists the resolution limit problem for modularity
Q [
36,
37,
38,
39]: when the size of a community is below a certain threshold, it cannot be detected by Q [
36]. This threshold does not depend on a particular network structure, but results only from the comparison between the number of links of interconnected communities and the total number of links of the network. Conversely, in some cases, maximizing
Q tends to split a large community into smaller ones [
39,
40]. Moreover, some random networks, which have no apparent community structure, may have unreasonably large values of
Q [
41,
42].
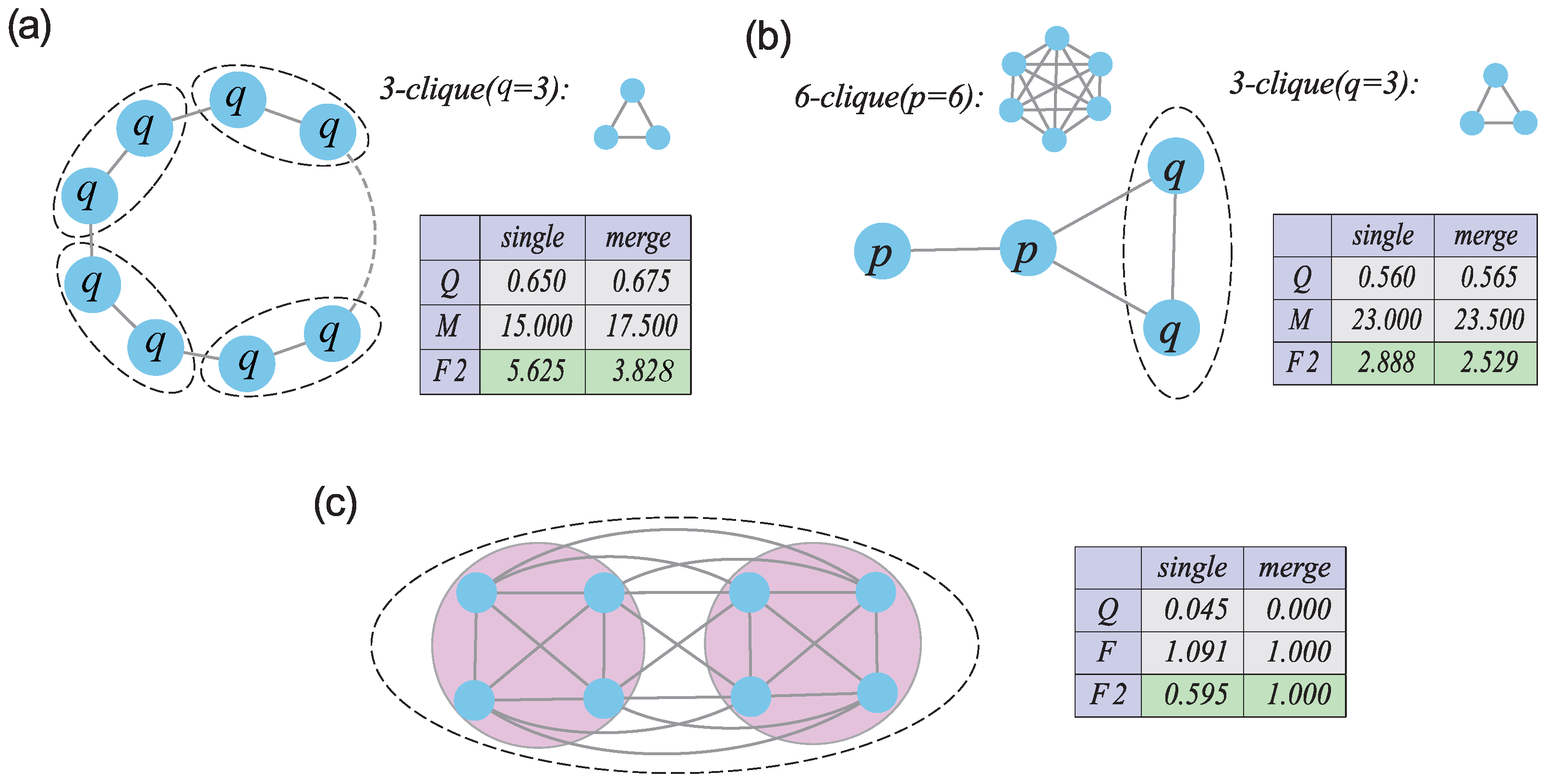
M approaches the infinite when an isolated subgraph within the network emerges as a community, or the whole network constitutes a single community. Thus, we need to design a better quality function as an objective function. Secondly, for the result of the Louvain algorithm, we can combine the feature of the real communities to obtain a better community structure. Currently, two plausible definitions to describe the community feature are weak community and strong community. The weak community is defined as the community with an internal degree larger than the external degree from a mesoscopic view. This is because the community structure is a mesoscopic structure and not all communities found by an algorithm meet the definition of a weak community. Thus, we can consider the definition of the weak community to constrain the communities obtained by the Louvain algorithm.
In this paper, we propose a new modularity called as an objective function. Compared with other objective functions, the have many advantages. For example, overcomes the resolution limit problem on the considered networks and does not divide the closely connected network into several small communities. Moreover, we propose a constrained Louvain algorithm by combining the definition of a weak community. Generally, the communities obtained by an algorithm contain some small communities and communities not satisfying the definition of a weak community. Therefore, it is necessary to added some constraints to the communities obtained by the Louvain algorithm. The results on ground truth networks and benchmark networks demonstrate that the constrained Louvain algorithm with is better than the other three objective functions. Moreover, the constrained Louvain algorithm with is also superior to the Newman’s fast algorithm and the classical Louvain algorithm with .
4. Results
In this section, we evaluate the performance of the constrained Louvain algorithm with different objective functions and compare the constrained Louvain algorithm with
and two classical algorithms by the normalized mutual information (
) [
47]. The better the algorithm, the higher the value of the
.
First of all, we execute the constrained Louvain algorithm with different objective functions on the ground truth networks and the benchmark networks.
For the ground truth networks, the result is as shown in
Table 2. The
values of
are the highest for the networks, except for the karate network. For the karate network, the constrained Louvain algorithm with
and
Q divides the network into four communities. For the constrained Louvain algorithm with
, after merging two small communities, the node 10 is different than the ground truth network. As a result, The
value of the constrained Louvain algorithm with
is smaller than the one with
Q. For all other ground truth networks, the constrained Louvain algorithm with
is the best. In particular, for DBLP and the Amazon network, the constrained Louvain algorithm with
Q identifies 179 and 201 communities, respectively. However, the constrained Louvain algorithm with
obtains 7916 and 1819 communities, respectively. Obviously, the
Q has a resolution limit problem and the
has not had this problem. For the constrained Louvain algorithm with
F and
M, there are many communities that are not satisfying the definition of a weak community, or the sizes are less than 4. Finally, these communities are disbanded. Therefore, the result is inferior to the constrained Louvain algorithm with
.
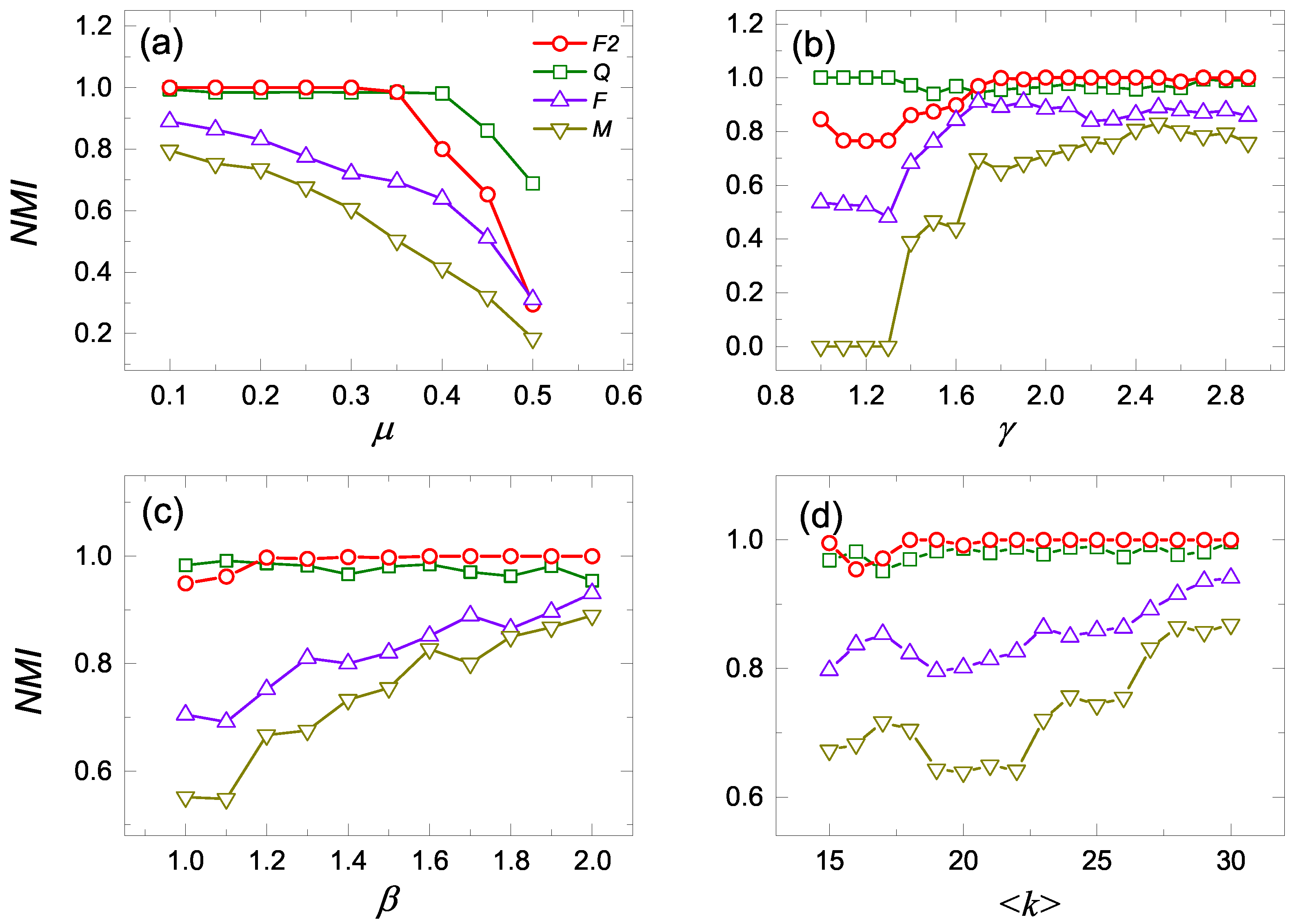
We also ran the constrained Louvain algorithm on the
benchmark networks. In
Figure 2a, the
values of the constrained Louvain with
are highest when
. With the increase in
, the community structure becomes more fuzzy and harder to identify, all
values decrease and the
value of the constrained Louvain algorithm with
becomes less than the one with
Q. This demonstrates that the constrained Louvain algorithm with
has the best performance for the networks with a clear community structure. Here, it is not necessary to calculate the cases of
, because the communities are not satisfying the definition of a weak community. In
Figure 2b, for the small value of
, the
values of the constrained Louvain algorithm with
Q are the highest. However, with the increase in
, the heterogeneity of networks becomes stronger and the
values of the constrained Louvain algorithm with
becomes higher than the constrained Louvain algorithm with other objective functions. Obviously, the stronger the heterogeneity of the networks are, the better is the performance of
. In
Figure 2c, for the high values of the parameter
, the constrained Louvain algorithm with
has the highest
values. With the increase in
value, the distribution of the community sizes becomes heterogeneous so that the resolution limit problem appears for some objective functions. Due to the advantage of
in
Figure 1, the constrained Louvain algorithm with
identifies the number of communities more correctly. In
Figure 2d, the values of the
are highest for the constrained Louvain algorithm with
, regardless of the values of
. In this case, the constrained Louvain algorithm with
Q still has the resolution limit problem due to the small number of communities found. Moreover, the constrained Louvain algorithm with
F and
M obtains too many communities that are not satisfying the definition of a weak community, or the sizes are less then 4. As a result, the constrained Louvain algorithm with
can better identify the community structure.
Due to the optimal performance of the constrained Louvain algorithm with
, it is expected to be a competitive algorithm. Next, we compare it with the classical Louvain algorithm with
and the Newman’s fast algorithm [
13] by
on ground truth networks and
benchmark networks.
Table 3 gives the values of
on ground truth networks. Compared with the classical Louvain algorithm based on
, the constrained Louvain algorithm based on
is better except for the football network. Compared with the fast algorithm, the constrained Louvain algorithm is better except for the karate network. Moreover, for the DBLP and Amazon networks, the cost of the fast algorithm is beyond our tolerance. In
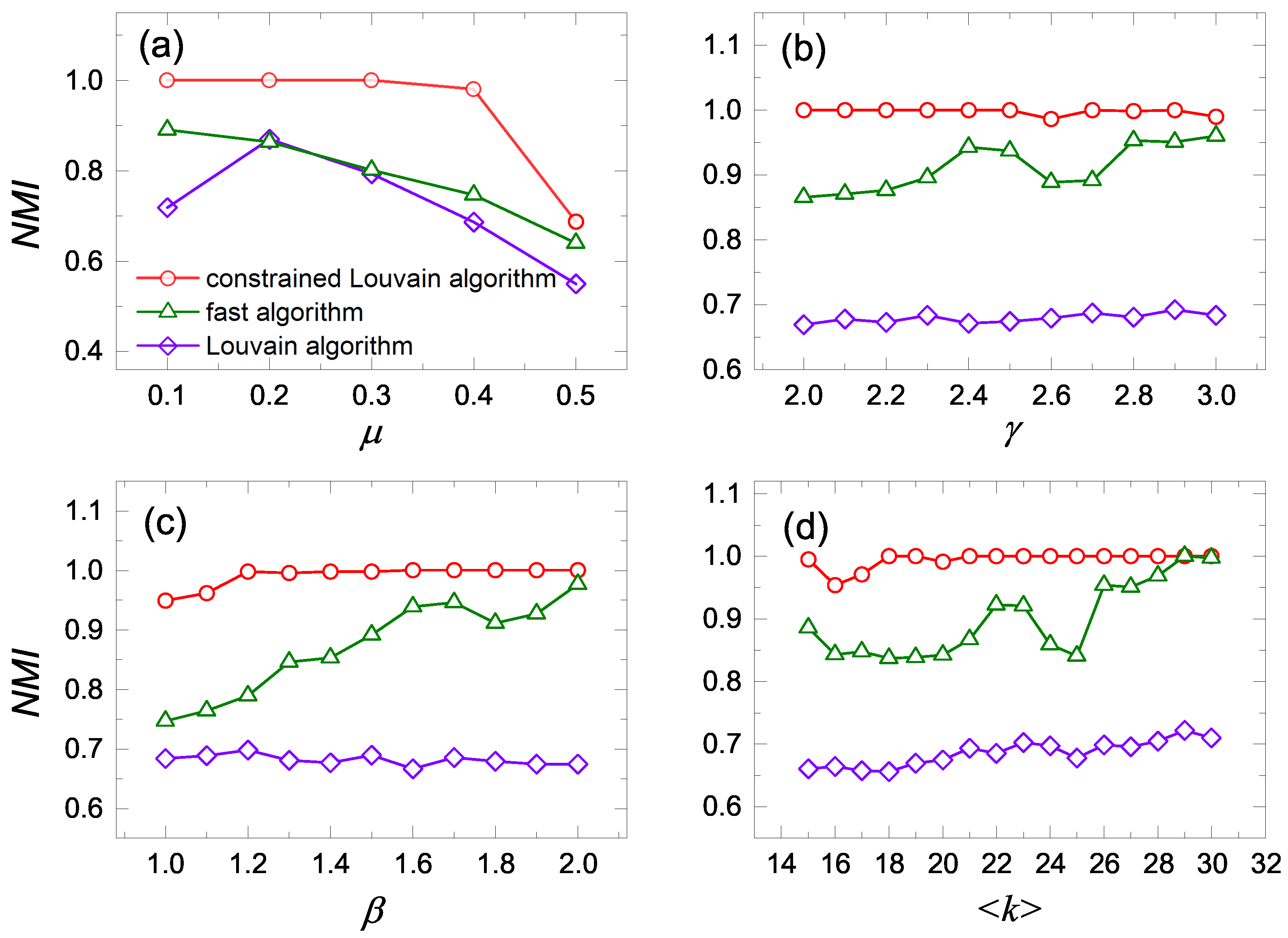
Figure 3, we also calculate the values of
when one parameter is changed for parameters
,
,
and
. As a result, the constrained Louvain algorithm with
has the highest values of
, which perform better than the other two methods. Therefore, the constrained Louvain algorithm with
can identify communities better.
5. Conclusions
The Louvain algorithm aims to optimize an objective function of the whole network, so it can excellently detect the community structure. Moreover, the Louvain method has a high efficiency. However, the communities obtained by the classical Louvain algorithm are not still the real communities. In this paper, we proposed a new local modularity function as an objective function of optimization. can overcome certain problems of other modularity functions such as the resolution limit problem and does not split the well-connected network into small communities. Both theoretical deductions and some examples suggest that identifies communities better than the objective functions of . Thus, is competitive as an objective function. Then, we proposed the constrained Louvain algorithm by adding the constraints , and the node number of each community is larger than 3 to the Louvain algorithm. This is because there exists some small communities and some communities that are not satisfying the weak community among the communities obtained by the Louvain algorithm. The constraints are meaningful. Finally, on both the real-world networks and the computer generated benchmark networks, the constrained Louvain algorithm with shows a high accuracy of identifying community structures in most of the considered networks.
For hierarchical networks, we can add tunable parameters [
48] in
to detect the hierarchical structure by the constrained Louvain algorithm. Through proper revisions, the constrained Louvain algorithm with
can be easily extended to directed or weighted networks. With the development of the computer technique, the data of the large network and dynamic network are more easily collected. Therefore, the community detection of dynamic and large networks is an interesting and challenging topic [
49,
50]. At the same time, the constrained Louvain algorithm can be paralleled, which is the same as the classical Louvain paralleled algorithm [
30,
31,
51,
52]. This is helpful for community detection in large or dynamic networks.
In the interdisciplinary area, the Louvain algorithm has many applications, such as disease modules’ identification [
53], a hierarchical clustering approach of network embedding [
54], the spatiotemporal analysis of a bike-share system [
55] and the analysis of wireless sensor networks [
56,
57]. Our constrained Louvain algorithms are also applied to these fields. Moreover, modularity functions can be used to assess the training results for neural networks [
58]. Our study on the modularity function
may hopefully lead to further studies that might be worth pursuing.






{kind=link}
{kind=link}
{kind=link}