
Research on Applying the “Shift” Concept to Deep Attention Matching
Abstract
:1. Introduction
- (1)
- The “dislocation” matching method proposed in this paper focuses on mining “dislocation” information in the “representation” stage of SM-DAM. Through the attention module, the granularity representation of response and utterance at different levels can achieve the cross-attention, so that the dependency information between the “dislocation” levels can be obtained more deeply (compared with the dislocation matching method of SM-DAM), and then the similarity matching can be performed. The experimental results show that the matching method proposed in this paper is effective, which also verifies the rationality and effectiveness of the processing step of mining the deep representation of the targeted point-to-point first, and then extracting the information from all the processed representations as a whole.
- (2)
- By the dislocation granularity matching method of SM-DAM, and using four matrices to aggregate into a 3D matrix for testing, it is found that the dislocation granularity matching method of SM-DAM and the information extracted by the method proposed in this paper have a large duplication, which shows that the multi-level dislocation cross-attention granularity matching method proposed in this paper is an improvement in the same nature of the dislocation granularity matching method of SM-DAM. In addition, it is possible to extract complete information using a simpler method, and the matching method proposed in this paper is a more complete information supplement method based on SM-DAM.
2. Related Work
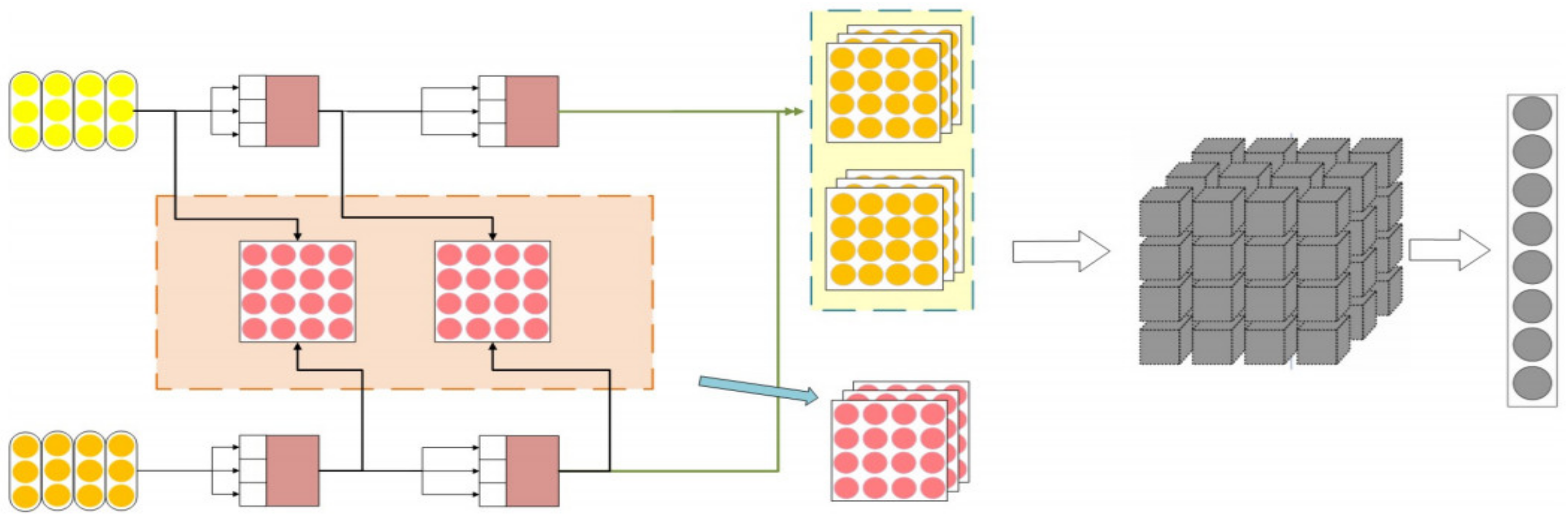
3. Improved DAM
3.1. Deep Attention Matching Model
3.1.1. Representation
3.1.2. Matching
3.1.3. Aggregation
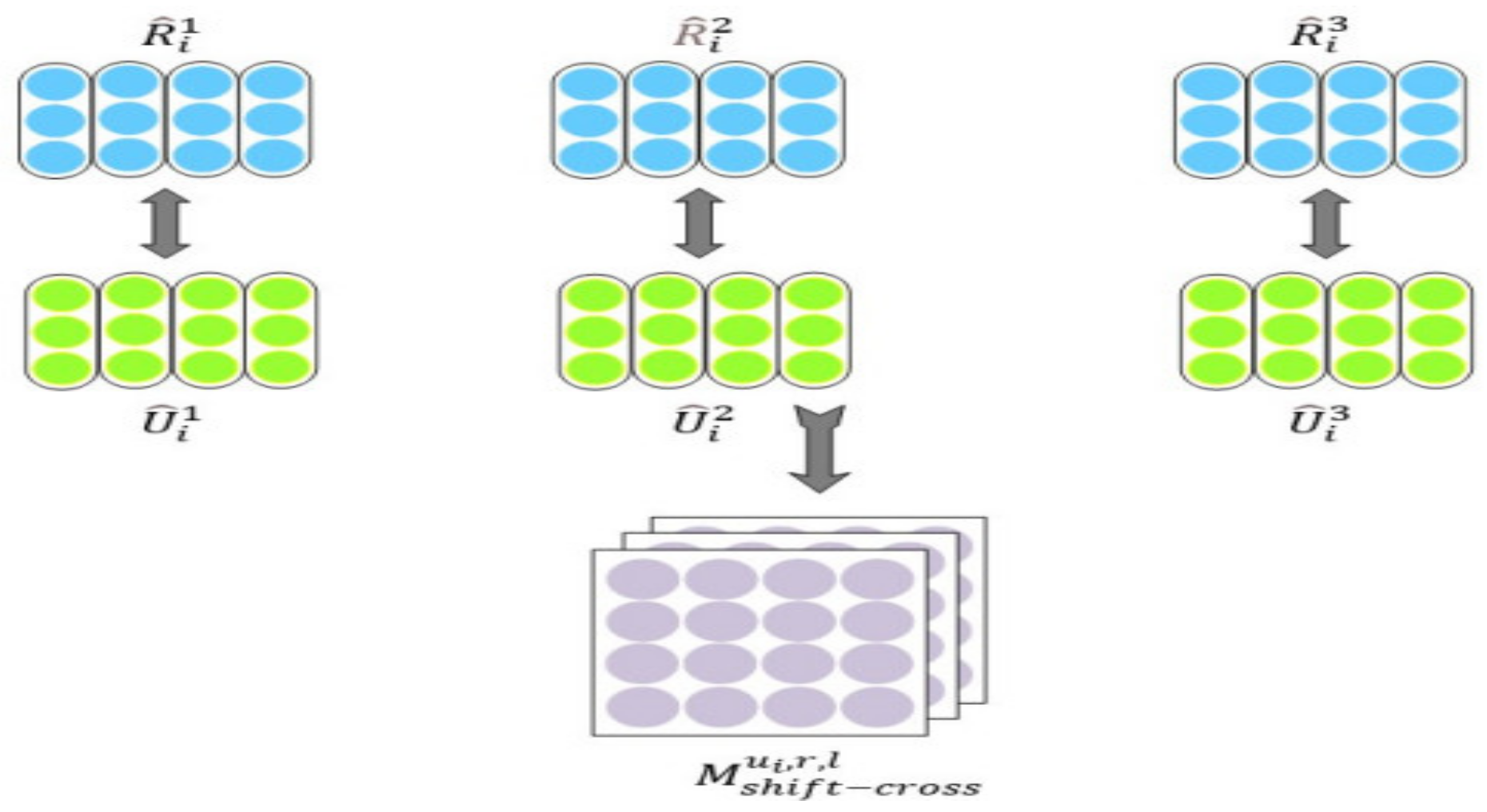
3.2. Shifted Granularity Matching
3.3. Multi-Level Shifted Cross Attention Granularity Matching
4. Experiments
4.1. Dataset
4.2. Evaluation Metric
4.3. Comparison Methods
4.4. Experiment Results
- The multi-level shifted cross-attention granularity matching method can mine more information than that of the other two matching methods;
- The method can cover part of the information that can be mined using the cross-attention and self-attention matching, for example, there may be some overlap between them, but fails to be better than the full DAM in terms of results as it has not completely replaced both the matching methods;
- Mshift and Mcross are subject to interaction space through convolution and pooling after aggregation, but in the separate case, this space does not exist, thus reducing the mining of a portion of the information. Mshift−cross contains the interaction space of Mshift and Mcross parts, which can be extracted under the convolutional pooling;
- There is an overlap between the adjacent granularities, allowing for the partial substitution between the granularities so that the information extracted in the non-shifted case can still be overlapped under the shifted matching.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DAM | Deep Attention Matching Network |
| GRU | Gated Recurrent Unit |
| NMT | Neural network machine translation |
| RCNN | Regions with Convolutional Neural Network Feature |
| RNN | Recurrent Neural Networks |
| SMN | Sequential Matching Network |
| SM-DAM | Enhanced deep attention matching model based on dislocation granularity matching |
References
- Turing, A.M. Computing machinery and intelligence. In Parsing the Turing Test; Springer: Berlin/Heidelberg, Germany, 2009; pp. 23–65. [Google Scholar]
- Ji, Z.; Lu, Z.; Li, H. An information retrieval approach to short text conversation. arXiv 2014, arXiv:1408. 6988. [Google Scholar]
- Wang, H.; Lu, Z.; Li, H.; Chen, E. A dataset for research on short-text conversations. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 935–945. [Google Scholar]
- Young, S.; Gašić, M.; Keizer, S.; Mairesse, F.; Schatzmann, J.; Thomson, B.; Yu, K. The hidden information state model: A practical framework for pomdp-based spoken dialogue management. Comput. Speech Lang. 2010, 24, 150–174. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Dong, D.; Wu, H.; Zhao, S.; Yu, D.; Tian, H.; Liu, X.; Yan, R. Multi-view response selection for human-computer conversation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 372–381. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.; Pineau, J. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. arXiv 2015, arXiv:1506.08909. [Google Scholar]
- Wu, Y.; Wu, W.; Xing, C.; Zhou, M.; Li, Z. Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots. arXiv 2016, arXiv:1612.01627. [Google Scholar]
- Ritter, A.; Cherry, C.; Dolan, B. Data-driven response generation in social media. In Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics (ACL): Edinburgh, UK, 2011. [Google Scholar]
- Young, S.; Gašić, M.; Thomson, B.; Williams, J.D. Pomdp-based statistical spoken dialog systems: A review. Proc. IEEE 2013, 101, 1160–1179. [Google Scholar] [CrossRef]
- Banchs, R.E.; Li, H. Iris: A chat-oriented dialogue system based on the vector space model. In Proceedings of the ACL 2012 System Demonstrations, Jeju, Republic of Korea, 8–14 July 2012; pp. 37–42. [Google Scholar]
- Gu, J.C.; Ling, Z.H.; Zhu, X.; Liu, Q. Dually interactive matching network for personalized response selection in retrieval-based chatbots. arXiv 2019, arXiv:1908.05859. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional neural network architectures for matching natural language sentences. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2042–2050. [Google Scholar]
- Kadlec, R.; Schmid, M.; Kleindienst, J. Improved deep learning baselines for ubuntu corpus dialogs. arXiv 2015, arXiv:1510.03753. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.V.; Charlin, L.; Liu, C.W.; Pineau, J. Training end-to-end dialogue systems with the ubuntu dialogue corpus. Dialogue Discourse 2017, 8, 31–65. [Google Scholar] [CrossRef]
- Lu, X.; Lan, M.; Wu, Y. Memory-based matching models for multi-turn response selection in retrieval-based chatbots. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Hohhot, China, 26–30 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 269–278. [Google Scholar]
- Wu, B.; Wang, B.; Xue, H. Ranking responses oriented to conversational relevance in chat-bots. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; Technical Papers. pp. 652–662. [Google Scholar]
- Yan, R.; Song, Y.; Wu, H. Learning to respond with deep neural networks for retrieval-based human-computer conversation system. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 55–64. [Google Scholar]
- Zhang, Z.; Li, J.; Zhu, P.; Zhao, H.; Liu, G. Modeling multi-turn conversation with deep utterance aggregation. arXiv 2018, arXiv:1806.09102. [Google Scholar]
- Zhou, X.; Li, L.; Dong, D.; Liu, Y.; Chen, Y.; Zhao, W.X.; Yu, D.; Wu, H. Multi-turn response selection for chatbots with deep attention matching network. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1118–1127. [Google Scholar]
- Shang, L.; Lu, Z.; Li, H. Neural responding machine for short-text conversation. arXiv 2015, arXiv:1503. 02364. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A diversity-promoting objective function for neural conversation models. arXiv 2015, arXiv:1510.03055. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Spithourakis, G.P.; Gao, J.; Dolan, B. A persona-based neural conversation model. arXiv 2016, arXiv:1603.06155. [Google Scholar]
- Serban, I.; Klinger, T.; Tesauro, G.; Talamadupula, K.; Zhou, B.; Bengio, Y.; Courville, A. Multiresolution recurrent neural networks: An application to dialogue response generation. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Serban, I.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Shang, M.; Fu, Z.; Peng, N.; Feng, Y.; Zhao, D.; Yan, R. Learning to converse with noisy data: Generation with calibration. In Proceedings of the International Joint Conferences on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Song, H.; Zhang, W.N.; Cui, Y.; Wang, D.; Liu, T. Exploiting persona information for diverse generation of conversational responses. arXiv 2019, arXiv:1905.12188. [Google Scholar]
- Vinyals, O.; Le, Q. A neural conversational model. arXiv 2015, arXiv:1506.05869. [Google Scholar]
- Xing, C.; Wu, W.; Wu, Y.; Liu, J.; Huang, Y.; Zhou, M.; Ma, W.Y. Topic augmented neural response generation with a joint attention mechanism. arXiv 2016, arXiv:1606.08340 2. [Google Scholar]
- Zhu, Q.; Cui, L.; Zhang, W.; Wei, F.; Liu, T. Retrieval-enhanced adversarial training for neural response generation. arXiv 2018, arXiv:1809.04276. [Google Scholar]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, DC, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Bordes, A.; Chopra, S.; Weston, J. Question answering with subgraph embeddings. arXiv 2014, arXiv:1406.3676. [Google Scholar]
- Yao, X.; Van Durme, B. Information extraction over structured data: Question answering with freebase. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 956–966. [Google Scholar]
- Yih, S.W.T.; Chang, M.W.; He, X.; Gao, J. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of the Joint Conference of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing of the AFNLP, Beijing, China, 28–30 July 2015. [Google Scholar]
- Zhou, H.; Young, T.; Huang, M.; Zhao, H.; Xu, J.; Zhu, X. Commonsense knowledge aware conversation generation with graph attention. In Proceedings of the Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13 July 2018; pp. 4623–4629. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured attention networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- Guanwen, M.; Jindian, S.; Shanshan, Y.; Da, L. Multi-turn response selection for chatbots with hierarchical aggregation network of multi-representation. IEEE Access 2019, 7, 111736–111745. [Google Scholar]
- Zhenyu, Z.; Xiaohui, Y.; Zhiquan, F. Self-attention Mechanism Fusion for Recommendation in Heterogeneous Information Network. Lect. Notes Electr. Eng. 2023, 917, 1147–1155. [Google Scholar]
- Niu, Z.Y.; Zhong, G.Q.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Stokel-Walker, C.; Van Noorden, R. What ChatGPT and generative AI mean for science. Nature 2023, 614, 214–216. [Google Scholar] [CrossRef]
- Huh, S. Are ChatGPTs knowledge and interpretation ability comparable to those of medical students in Korea for taking a parasitology examination? A descriptive study. J. Educ. Eval. Health Prof. 2023, 20, 1. [Google Scholar]
- King, M.R. A Conversation on Artificial Intelligence, Chatbots, and Plagiarism in Higher Education. Cell. Mol. Bioeng. 2023, 16, 1–2. [Google Scholar] [CrossRef]
- Zeng, M.J.; Xiao, N.F. Effective Combination of DenseNet and BiLSTM for Keyword Spotting. IEEE Access 2019, 7, 10767–10775. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA, 1999; Volume 463. [Google Scholar]
- Voorhees, E.M. The trec-8 question answering track report. In Proceedings of the 8th Text Retrieval Conference, Gaithersburg, Maryland, 17–19 November 1999; Volume 1999, pp. 77–82. Available online: https://www.researchgate.net/publication/2888359_The_TREC-8_Question_Answering_Track_Evaluation (accessed on 12 February 2023).
- Yu, C.; Jiang, W.; Zhu, D.; Li, R. Stacked multi-head attention for multi-turn response selection in retrieval-based chatbots. In Proceedings of the IEEE 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 3918–3921. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | ||
|---|---|---|
| Contexts | Candidate Response | Label |
| hey … i installed a pata card in my comp with __number__ hd s on it dmesg says the card is there (it seems to be using the libata module) but the drives on the card … has someone experience with these kinds of cards | that is already loaded… part of ide_core in lsmod but no __path__ for the disks :( | 1 |
| maybe the dmesg has some clue can you post it to pastebin? that’s a bit hard because it’s a different comp with no net but the line that caught my eye was ata2 sata link down … it is sata or pata?? | or an option or something its pretty obvious to what it does check out imap | 0 |
| Test Set | ||
|---|---|---|
| Contexts | Candidate Response | Label |
| cool also i feel like i m helping the project by using it more traffic to the site etc did you send output for when you run metasploit yeah i gues you are :d hhaa ok man ill use ubuntus paste site now yeah ill get the output error and re paste bin now gimme a sec ……… try just doing it again with the run file wait a sec metasploit has n’t worked once yet right | ok will do :) nope | 1 |
| because of email relaying problems the default configurations …… from the same subnet as the server runs on | 0 | |
| did you get that msg i just sent you i am trying to set ftp hree | 0 | |
| just general setup trouble when i create the virtual …… drive space and a decent amount of graphics memory | 0 | |
| for example libpulse0 amd64 (……) sounds like you may be using some extra ppa s or other repos | 0 | |
| try booting with acpi =off (is a laptop is n’t it) it is ……… finding my harddisk or something …? | 0 | |
| so im pretty fucked trying to install new drivers ……and it removed everything | 0 | |
| __url__ if you go down to the bottom of that …… about myproblem poster name is trent | 0 | |
| ………… | 0 | |
| Training Set | ||
|---|---|---|
| Contexts | Candidate Response | Label |
| Learning pure English by watching original English movies_ EOS_ I’ve watched it many times over and over again._ EOS_ One CD was nearly seen by me | Your English should be good now | 1 |
| I also want to know. I’m bold when I feel ambiguous. How can I be cautious when I really get together? Is it a sullen feeling? I don’t understand | 0 | |
| Video resources comprehensive Post_ EOS_ At the beginning, I only knew these two_ EOS_ Can you tell me why I didn’t see the words playing after opening these two websites? Do I need to download another player to solve Gracias. | Downloaded_ OOV_ What can I do if I still can’t see the player? It seems like I really can’t see it | 1 |
| It’s all about persistence. If you want to be permanent, it’s impossible, and it’s all about doing it many times | 0 | |
| Test Set | ||
|---|---|---|
| Contexts | Candidate Response | Label |
| Let life be a little warm, a little plump, a beautiful change in broken thoughts_ EOS_ 115. I took a shower this morning, put on some incense, and washed my head. I sent the paper to my uncle and asked him to help me read it. Otherwise, I really don’t know how to modify it. I browsed Sina News and was ready to wash my clothes in the afternoon. I watched Weibo and sorted out my room and my reading notes_ EOS_ I haven’t seen you for a long time. Come on_ EOS_ Hee hee, the center of gravity has been taken away by something recently. I need to come back and continue working hard | I don’t know. Why don’t you help me find it on Douban | 0 |
| 160 and 180 are all together, and what about 170 | 0 | |
| You have a magic trick | 0 | |
| He’s all dumb and cute〜 | 0 | |
| I don’t know yet | 0 | |
| If I don’t work overtime, I’ll register for 075. I left my mobile phone number under Dou Mail | 0 | |
| No, I won’t tell you where he is secretly | 0 | |
| Who took it? Tell me I’ll get it back | 1 | |
| Don’t be afraid, what should I do? | 0 | |
| I didn’t leave, no one took it | 1 | |
| Ubuntu Dialogue Gorpus | Douban Conversation Corpus | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R2@1 | R10@1 | R10@2 | R10@5 | MAP | MRR | P@1 | R10@1 | R10@2 | R10@5 | |
| Dis-1 | 0.941 | 0.776 | 0.881 | 0.970 | 0.558 | 0.604 | 0.431 | 0.257 | 0.425 | 0.769 |
| Dis-2 | 0.939 | 0.770 | 0.876 | 0.968 | 0.553 | 0.601 | 0.427 | 0.257 | 0.427 | 0.760 |
| Dis-3 | 0.936 | 0.767 | 0.876 | 0.968 | 0.549 | 0.602 | 0.427 | 0.255 | 0.413 | 0.754 |
| Dis-1β | 0.903 | 0.724 | 0.844 | 0.920 | 0.532 | 0.585 | 0.410 | 0.244 | 0.398 | 0.721 |
| Dis-2β | 0.905 | 0.720 | 0.832 | 0.923 | 0.533 | 0.579 | 0.406 | 0.244 | 0.390 | 0.710 |
| DAM | 0.938 | 0.767 | 0.874 | 0.969 | 0.550 | 0.601 | 0.427 | 0.254 | 0.410 | 0.757 |
| Ubuntu Dialogue Gorpus | Douban Conversation Corpus | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R2@1 | R10@1 | R10@2 | R10@5 | MAP | MRR | P@1 | R10@1 | R10@2 | R10@5 | |
| 1 to 3 | 0.945 | 0.780 | 0.884 | 0.972 | 0.560 | 0.604 | 0.436 | 0.260 | 0.420 | 0.770 |
| 2 to 4 | 0.940 | 0.770 | 0.880 | 0.968 | 0.556 | 0.602 | 0.430 | 0.254 | 0.413 | 0.766 |
| 3 to 5 | 0.932 | 0.760 | 0.871 | 0.959 | 0.539 | 0.594 | 0.411 | 0.240 | 0.405 | 0.752 |
| 1 to 4 | 0.937 | 0.771 | 0.879 | 0.968 | 0.553 | 0.601 | 0.428 | 0.250 | 0.412 | 0.762 |
| 2 to 5 | 0.921 | 0.743 | 0.844 | 0.942 | 0.528 | 0.579 | 0.401 | 0.237 | 0.398 | 0.730 |
| 1 to 5 | 0.930 | 0.757 | 0.869 | 0.955 | 0.535 | 0.592 | 0.407 | 0.240 | 0.401 | 0.750 |
| DAM | 0.938 | 0.767 | 0.874 | 0.969 | 0.550 | 0.601 | 0.427 | 0.254 | 0.410 | 0.757 |
| Ubuntu Dialogue Gorpus | Douban Conversation Corpus | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R2@1 | R10@1 | R10@2 | R10@5 | MAP | MRR | P@1 | R10@1 | R10@2 | R10@5 | |
| SMN | 0.926 | 0.726 | 0.847 | 0.961 | 0.529 | 0.569 | 0.397 | 0.233 | 0.396 | 0.724 |
| DAM | 0.938 | 0.767 | 0.847 | 0.969 | 0.550 | 0.601 | 0.427 | 0.254 | 0.410 | 0.757 |
| SMHA | 0.941 | 0.773 | 0.879 | 0.972 | 0.560 | 0.604 | 0.429 | 0.254 | 0.422 | 0.773 |
| Ours-1 | 0.941 | 0.776 | 0.881 | 0.970 | 0.558 | 0.604 | 0.431 | 0.257 | 0.425 | 0.769 |
| 1 to 3 | 0.945 | 0.780 | 0.884 | 0.972 | 0.560 | 0.604 | 0.436 | 0.260 | 0.420 | 0.770 |
| Ubuntu Dialogue Gorpus | Douban Conversation Corpus | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| R2@1 | R10@1 | R10@2 | R10@5 | MAP | MRR | P@1 | R10@1 | R10@2 | R10@5 | |
| Ours-1 | 0.941 | 0.776 | 0.881 | 0.970 | 0.558 | 0.604 | 0.431 | 0.257 | 0.425 | 0.769 |
| Only Mshift | 0.901 | 0.722 | 0.830 | 0.922 | 0.511 | 0.556 | 0.359 | 0.212 | 0.397 | 0.721 |
| Only Mself | 0.931 | 0.741 | 0.859 | 0.964 | 0.527 | 0.574 | 0.382 | 0.221 | 0.403 | 0.750 |
| Only Mcross | 0.932 | 0.749 | 0.863 | 0.966 | 0.535 | 0.585 | 0.400 | 0.234 | 0.411 | 0.733 |
| Only Mshift-cross | 0.935 | 0.761 | 0.869 | 0.966 | 0.546 | 0.592 | 0.418 | 0.245 | 0.408 | 0.751 |
| DAM | 0.938 | 0.767 | 0.874 | 0.969 | 0.550 | 0.601 | 0.427 | 0.254 | 0.410 | 0.757 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, K.; Xiao, N. Research on Applying the “Shift” Concept to Deep Attention Matching. Appl. Sci. 2023, 13, 3934. https://doi.org/10.3390/app13063934
Hu K, Xiao N. Research on Applying the “Shift” Concept to Deep Attention Matching. Applied Sciences. 2023; 13(6):3934. https://doi.org/10.3390/app13063934
Chicago/Turabian StyleHu, Kai, and Nanfeng Xiao. 2023. "Research on Applying the “Shift” Concept to Deep Attention Matching" Applied Sciences 13, no. 6: 3934. https://doi.org/10.3390/app13063934