
Underwater Object Detection Method Based on Improved Faster RCNN

Abstract
:1. Introduction
- A two-stage underwater object detection method is proposed and improved, which is based on the Faster RCNN, and its initial image dataset is subjected to Mosaic [4] data enhancement and related preprocessing. The improved Faster RCNN model has stable performance and good accuracy, and is more conducive to underwater object detection.
- VGG16 is replaced by Res2Net101 in the feature extraction module of the improved Faster RCNN, because the structure of Res2Net101 can enhance the expression ability of the receptive field in the network layer of the improved Faster RCNN. The OHEM algorithm is introduced to effectively solve the imbalance problem of the positive and negative samples of the candidate prior frame.
- The IOU structure in the improved Faster RCNN is replaced by GIOU [5], and the non-overlapping area between the candidate prior frame and the real object is also taken into account, so that the weakness of the original IOU can be weakened and the improved Faster RCNN can better optimize the candidate prior frame in the training process.
- The original NMS algorithm is replaced by the Soft-NMS algorithm [6], which only needs simple modification and no additional parameters, is easy to realize and can be easily applied to different object detection algorithms. The training strategy of the improved model is optimized by a multi-scale training approach [7], which can improve the robustness of the improved Faster RCNN detection algorithm to different object sizes.
2. Related Work
2.1. Development of Underwater Object Detection Technology
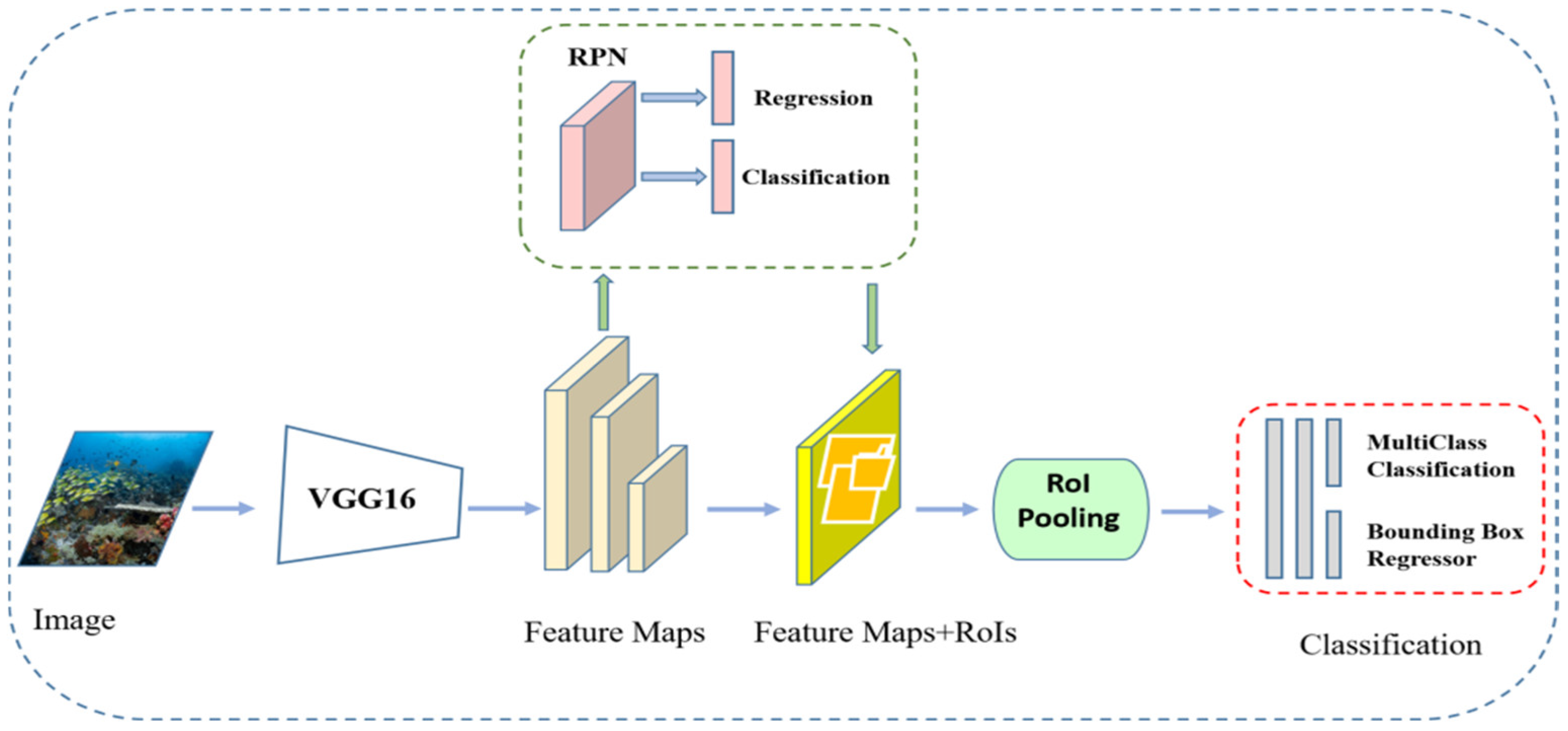
2.2. Network Structure of the Faster RCNN
2.3. Loss Function of the Faster RCNN
3. Proposed Method
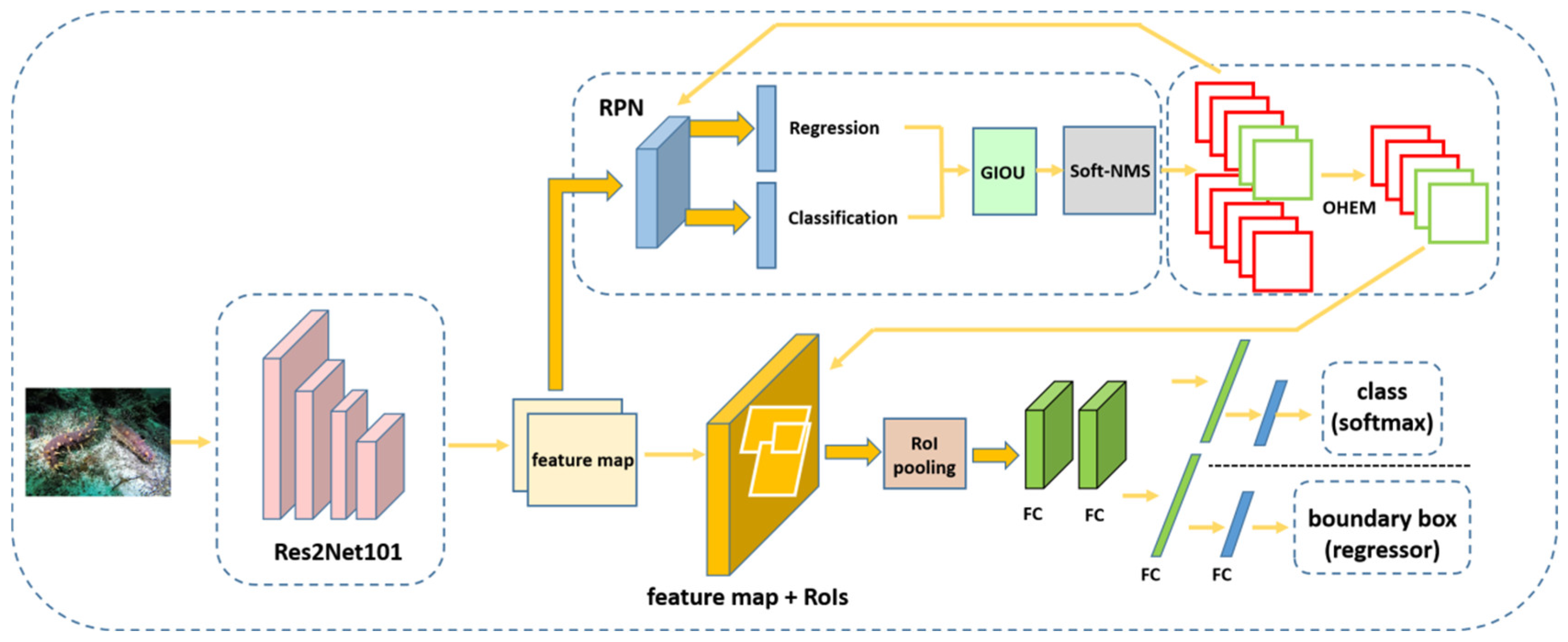
3.1. Improvement of the Faster RCNN
3.2. Initial Screening of Bounding Boxes
3.3. Improved Backbone Network
3.4. Positive and Negative Sample Imbalance Improvement
3.5. Improvement of Bounding Box Mechanism
3.5.1. GIOU
3.5.2. Soft-NMS
3.6. Multi-Scale Training
4. Experiments
4.1. Mosaic Data Enhancement and Related Preprocessing
4.1.1. Dataset Preprocessing
4.1.2. Mosaic Data Enhancement
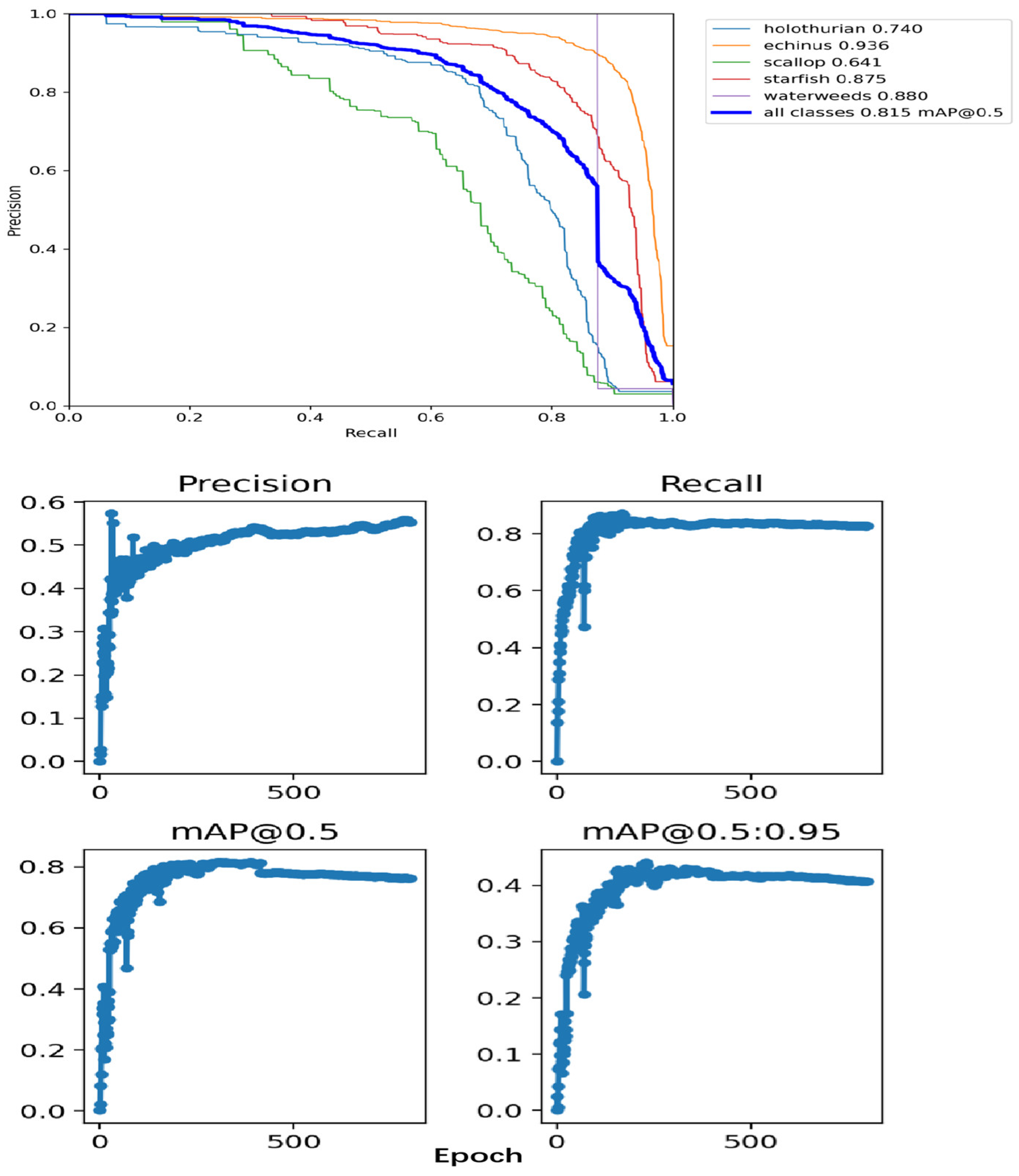
4.2. Evaluation Indicators
4.3. Comparative Experiments of Backbone Network Selection
4.4. Comparison Experiments
4.5. Ablation Experiments and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RCNN | Regions with Convolutional Neural Network Feature |
| VGG16 | Visual Geometry Group Network 16 |
| Res2Net101 | Residual 2 Network 101 |
| OHEM | Online Hard Example Mining |
| GIOU | Generalized Intersection Over Union |
| Soft-NMS | Soft Non-Maximum Suppression |
| RPN | Region Proposal Network |
| ROI | Region of Interest |
| LSTM | Long Short-Term Memory |
| DTW | Dynamic Time Warping |
References
- Xu, X.; Zou, S.; Liu, J. Research on the promotion path of scientific and technological innovation ability of marine industry based on big data under the background of marine power strategy. In Proceedings of the 2021 International Conference on E-Commerce and E-Management (ICECEM), Dalian, China, 24–26 September 2021; pp. 356–360. [Google Scholar]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P.H.S. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Grisham, M.P. Mosaic. In A Guide to Sugarcane Diseases; Rott, P., Bailey, R.A., Comstock, J.C., Croft, B.J., Eds.; La Librairie du Cirad: Montpellier, France, 2000. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS--improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–20 September 2005; pp. 5561–5569. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient multi-scale training. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, pp. 9310–9320. [Google Scholar]
- Li, W.; Logenthiran, T.; Phan, V.T.; Woo, W.L. A novel smart energy theft system (SETS) for IoT-based smart home. IEEE Internet Things J. 2019, 6, 5531–5539. [Google Scholar] [CrossRef]
- Zeng, X.; Lin, S.; Liu, C. Multi-View Deep Learning Framework for Predicting Patient Expenditure in Healthcare. IEEE Open J. Comput. Soc. 2021, 2, 62–71. [Google Scholar] [CrossRef]
- Kashyap, P.K.; Kumar, S.; Jaiswal, A.; Prasad, M.; Gandomi, A.H. Towards Precision Agriculture: IoT-enabled Intelligent Irrigation Systems Using Deep Learning Neural Network. IEEE Sens. J. 2021, 21, 17479–17491. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, M.; Zhan, X. Behavioral cloning for driverless cars using transfer learning. In Proceedings of the 2018 IEEE/ION Position, Location and Navigation Symposium (PLANS), Monterey, CA, USA, 23–26 April 2018; pp. 1069–1073. [Google Scholar]
- Lin, Y.-Y.; Yang, J.-Y.; Kuo, C.-Y.; Huang, C.-Y.; Hsu, C.-Y.; Liu, C.-C.C. Use Empirical Mode Decomposition and Ensemble Deep Learning to Improve the Performance of Emotional Voice Recognition. In Proceedings of the 2020 IEEE 2nd International Workshop on System Biology and Biomedical Systems (SBBS), Taichung, Taiwan, 3–4 December 2020; pp. 1–4. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Mittal, S.; Srivastava, S.; Phani, .J.J. A Survey of Deep Learning Techniques for Underwater Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of theEuropean Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Deng, J.; Xuan, X.; Wang, W.; Li, Z.; Yao, H.; Wang, Z. A review of research on object detection based on deep learning. J. Phys. Conf. Ser. 2020, 1684, 012028. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep absolute pose regression with synthetic views. arXiv 2017, arXiv:1712.03452. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Roh, M.C.; Lee, J. Refining faster-RCNN for accurate object detection. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 514–517. [Google Scholar]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG waveform images using faster R-CNN and deep transfer learning. BMC Med. Inform. Decis. Mak. 2022, 22, 297. [Google Scholar] [CrossRef]
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using Unsupervised Colour Correction Method. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Zhang, D.; Kopanas, G.; Desai, C.; Chai, S.; Piacentino, M. Unsupervised underwater fish detection fusing flow and objectiveness. In Proceedings of the 2016 IEEE Winter Applications of Computer Vision Workshops (WACVW), New York, NY, USA, 10 March 2016; pp. 1–7. [Google Scholar]
- Yuan, F.; Huang, Y.-F.; Chen, X.; Cheng, E. A Biological Sensor System Using Computer Vision for Water Quality Monitoring. IEEE Access 2018, 6, 61535–61546. [Google Scholar] [CrossRef]
- Wang, J.H.; Lee, S.K.; Lai, Y.C.; Lin, C.C.; Wang, T.Y.; Lin, Y.R.; Hsu, T.H.; Huang, C.W.; Chiang, C.P. Anomalous Behaviors Detection for Underwater Fish Using AI Techniques. IEEE Access 2020, 8, 1–11. [Google Scholar] [CrossRef]
- Phillips, J.J. ROI: The search for best practices. Train. Dev. 1996, 50, 42–48. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Xu, Q.; Zhang, X.; Cheng, R.; Song, Y.; Wang, N. Occlusion Problem-Oriented Adversarial Faster-RCNN Scheme. IEEE Access 2019, 7, 170362–170373. [Google Scholar] [CrossRef]
- Hahn, G.; Lutz, S.M.; Laha, N.; Lange, C. A framework to efficiently smooth L1 penalties for linear regression. bioRxiv 2020, 1–35. [Google Scholar]
- Qassim, H.; Verma, A.; Feinzimer, D. Compressed residual-VGG16 CNN model for big data places image recognition. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 169–175. [Google Scholar]
- Theckedath, D.; Sedamkar, R.R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Lin, S.L. Application Combining VMD and ResNet101 in Intelligent Diagnosis of Motor Faults. Sensors 2021, 21, 6065. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.; Tian, S.; Yu, L.; Lu, H.; Lv, X. Fully convolutional attention network for biomedical image segmentation. Artif. Intell. Med. 2020, 107, 101899. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA 2007, New Orleans, LA, USA, 77–9 January 2007; pp. 1027–1035. [Google Scholar]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. Part B Cybernetics 1999, 29, 433–439. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, W.; Chen, Y.; Liu, C.; Yu, L. GFNet: Gate Fusion Network with Res2Net for Detecting Salient Objects in RGB-D Images. IEEE Signal Process. Lett. 2020, 27, 800–804. [Google Scholar]
- Kaiyan, Z.; Xiang, L.; Weibo, S. Underwater object detection using transfer learning with deep learning. In Proceedings of the CIPAE 2020: 2020 International Conference on Computers, Information Processing and Advanced Education, Ottawa, ON, Canada, 16–18 October 2020; pp. 157–160. [Google Scholar]
- Albahli, S.; Nida, N.; Irtaza, A.; Yousaf, M.H.; Mahmood, M.T. Melanoma Lesion Detection and Segmentation Using YOLOv4-DarkNet and Active Contour. IEEE Access 2020, 8, 198403–198414. [Google Scholar] [CrossRef]
- He, M.X.; Hao, P.; Xin, Y.Z. A robust method for wheatear detection using UAV in natural scenes. IEEE Access 2020, 8, 189043–189053. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Y.; Liu, J.; Yu, S.; Wang, K.; Han, Z.; Tang, Y. Underwater Object Detection based on YOLO-v3 network. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 22–24 October 2021; pp. 571–575. [Google Scholar]
- Mathias, A.; Dhanalakshmi, S.; Kumar, R. Occlusion aware underwater object tracking using hybrid adaptive deep SORT-YOLOv3 approach. Multimed. Tools Appl. 2022, 81, 44109–44121. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Avg-P(%) | mAP@0.5(%) |
|---|---|---|
| Faster RCNN (VGG16) | 41.0 | 68.4 |
| Faster RCNN (ResNet50) | 41.2 | 68.1 |
| Faster RCNN (ResNet101) | 41.1 | 68.7 |
| Faster RCNN (Res2Net101) | 41.5 | 69.1 |
| Methods | Avg-P(%) | mAP@0.5(%) | F1 |
|---|---|---|---|
| Fast RCNN | 38.3 | 62.1 | 45.6 |
| Faster RCNN | 41.0 | 68.4 | 52.8 |
| YOLOV3 | 42.1 | 70.1 | 54.7 |
| SSD | 42.0 | 70.4 | 54.5 |
| Ours | 43 | 71.7 | 55.3 |
| Methods | Avg-P(%) | mAP@0.5(%) |
|---|---|---|
| Faster RCNN (VGG16) | 41.0 | 68.4 |
| Faster RCNN (Res2Net101) | 41.5 | 69.1 |
| Faster RCNN (Res2Net101 + GIOU) | 41.2 | 69.3 |
| Faster RCNN (Res2Net101 + OHEM) | 41.1 | 69.5 |
| Faster RCNN (Res2Net101 + SoftNMS) | 41.5 | 69.2 |
| Faster RCNN (Res2Net101 + GIOU + OHEM + SoftNMS) | 41.5 | 69.7 |
| Faster RCNN (Res2Net101 + GIOU + OHEM + SoftNMS) + Multi-scale training | 43 | 71.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Xiao, N. Underwater Object Detection Method Based on Improved Faster RCNN. Appl. Sci. 2023, 13, 2746. https://doi.org/10.3390/app13042746
Wang H, Xiao N. Underwater Object Detection Method Based on Improved Faster RCNN. Applied Sciences. 2023; 13(4):2746. https://doi.org/10.3390/app13042746
Chicago/Turabian StyleWang, Hao, and Nanfeng Xiao. 2023. "Underwater Object Detection Method Based on Improved Faster RCNN" Applied Sciences 13, no. 4: 2746. https://doi.org/10.3390/app13042746