1. Introduction
In this article, we present a new statistical distribution with three parameters that has some desirable properties. There are many previous studies and researches on the topic of composite distributions and the study of their properties, as well as methods for estimating the parameters and the reliability function. Here are some related researches and studies on this topic. Nadarajah and KOT [
1] introduced a composite probability model, as he derived some of the characteristics of the proposed model represented by the probability distribution function, moments, mode, median, and the study of property measures of dispersion such as variance, average deviation, torsion, and flattening, and the parameters of the proposed model and the reliability function were estimated. Lingji et al. [
2] develop a new composite statistical model Beta-Gamma, investigated the model properties, estimated the parameters and the risk function in different ways, and applied the model to real data in the health field. Akinsete et al. [
3] discussed construction of a new composite statistical model for the Beta-Pareto distribution with four parameters and the study of the properties of the model, such as the arithmetic mean, mode, median, standard deviation, variance, skewness, and flatness, as well as the parameters and reliability of the model. Barreto et al. [
4] discussed the study of a complex statistical model Beta-Generalised Exponential in terms of its mathematical properties and the derivation of
rth degree moments.
A study on the complex distribution beta-Burr XII was published, in which the characteristics were derived by Paranaiba et al. [
5]. A study on the construction of a composite statistical model for the Beta-Half Cauchy distribution was presented by Cardeior and Lemonts [
6], such as the arithmetic mean and mode, and some properties of the dispersion measures. ALkadim and Boshi [
7] published a paper that combined the exponential-Pareto distribution with two independent distributions, the Exponential and the Pareto distribution. The properties of the new distribution were studied in terms of the probability density function, the reliability function, the cumulative function, the risk function, and the use of the method of greatest likelihood to estimate the parameters. Gupta and Kundu [
8] proposed the generalized exponential distribution and Nasiri [
9] estimated the parameters via using different method in person of outlier.
Many literatures researched the issue of new statistical models based on the Weibull distribution. For example, Martinez et al. [
10] developed the generalized modified Weibull distribution. Lee et al. [
11] developed a beta Weibull model. Tahir et al. [
12] developed a new Weibull-Pareto distribution. Emam developed the generalised Weibull-Weibull distribution [
13]. Emam and Tashkandy [
14] developed the generalised Arcsine-Kumaraswamy-X family of distributions by incorporating a trigonometric function, the Weibull claim model [
15] using a class of claim distributions, the modified alpha-power Weibull-Weibull model [
16], the generalised modified Weibull model [
17] and the Khalil generalized Weibull distribution based on ranked set samples [
18]. The exponential probability density function is:
Here
is the inverse scale parameter. The exponential is:
Next, the Weibull cumulative distribution function with two parameters takes the following form:
where
,
is the scale parameter and
is the shape parameter.
2. The E-WD
In this section we introduce a new combined statistical model and study its behavior. It is the E-WD with three agency parameters, which also consists of an exponential family and a Weibull distribution. The proposed model is superior to many previous distributions and proves its efficiency in modeling stock movement data in the stock market. The cumulative distribution function (CDF) of the new combined statistical model is as follows:
The probability density function (PDF) of the complex statistical model gives as follows:
and
, the function in the aforementioned Equation (
5)
, but
The function in Equation (
5) is a non-probability PDF because its integral is not equal to one, so the appropriate method to convert it into a probability density function is to multiply it by the reciprocal of integration. The PDF of the proposed E-WD is:
The corresponding CDF gives as follows:
Furthermore, the survival function, hazard function, cumulative hazard function, and reverse hazard function of E-WD are given, respectively, by
The importance and main motivation for the proposed modification E-WD:
- (i)
To improve the flexibility and distribution properties of Weibull model.
- (ii)
The proposed model can take several forms: a right-skewed form, a left-skewed form, a decreasing form, a curved form, and a symmetric form.
- (iii)
A simple way to add an additional parameter that gives an extended distribution with “heavy tail” properties and is very useful in modeling stock movement data and financial data.
- (iv)
The important statistical functions of the modified E-WD are presented in closed forms.
- (v)
The new version has many special statistical features. Now we present the visual representation of the PDF of the E-WD.
Various visual representations of the E-WD PDF are shown in
Figure 1. The representations of f(x) are obtained for
and for; (i)
(blue-line), (ii)
(green-line), (iii)
(orange-line), (vi)
(red-line). In
Figure 1, the representations of f(x) are obtained for
and for; (i)
(blue-line), (ii)
(green-line), (iii)
(orange-line), (vi)
(red-line). In left banal of
Figure 1 we can observe the different shapes of the PDF of the E-WD. These include a right-skewed shape (green line), a decreasing shape (orange line), a curved shape (red line), zero skewness and a symmetrical shape (blue line). In right banal of
Figure 1 we can observe the different shapes of the PDF of the E-WD. These include a left-skewed shape (red line), a decreasing shape (green line), and a symmetrical shape (blue line and orange line). From
Figure 1, we can see that the E-WD PDF is very flexible and therefore can be used to cover datasets with indicated, decreasing, right-skewed, left-skewed or symmetric behaviour.
Figure 2 presents the CDF of the corresponding casses of
Figure 1.
3. The Heavy-Tailed Characteristic
This section offers the heavy-tailed behavior and regular variational results of the E-WD. Probability distributions that are right-skewed and possess heavy-tailed behavior are very useful in providing the best description of the biomedical data sets. A probability model is called a heavy tailed distribution, if it satisfies for every
pTheorem 1. , the probability distribution that given in Equation (5) is heavy tailed distribution as . Proof. Based on Equation (
10), we can write that
□
An important property of the heavy-tailed probability distributions is called the regular variational property. This property implies that the tail of the distribution decays in a power-law fashion, with an exponent
that determines how fast it decays. The larger the value of
, the slower the decay of the tail. The regular variational property has important implications for many areas of science and engineering, including finance, telecommunications, and network science. It allows us to model extreme events and rare occurrences more accurately and to estimate their probabilities more reliably. Here, we derive the regular variational property of the E-WD. According to Karamata’s theorem (see, Seneta [
19]), the E-WD in terms of SF
is regularly varying, if it satisfies for every
p
where
represents an index of regular variation.
Theorem 2. , non-zero and finite, the probability distribution that given in Equation (5) is regularly varying model. Proof. Using Equation (
10), we can write that
□
The expression in Equation (
18) is non-zero and finite
. Thus,
that given in Equation (
5) is a regular varying distribution and
is the index of regular variation.
6. Maximum Likelihood Estimation (MLE)
Let
are observed values of
that is an ordered random sample from the E-WD. The E-WD likelihood is
and the corresponding log-likelihood function
is
Taking the first partial derivatives of log-likelihood (
39) with respect to
and equating each to zero.
Solving Equation (42) for
, we have
Solving Equations (
40) and (41) after substituting Equation (
43), we get the maximum likelihood estimators
of the
parameters.
The asymptotic confidence intervals of the parameters
,
and
. Then
is the observed variance covariance matrix, such that
A
two-sided approximate confidence intervals for the parameters
,
and
are then given by
and
respectively, where
and
are the estimated variances of
,
, and
, which are given by the diagonal elements of
, and
is the upper
percentile of the standard normal distribution.
Next, obtain the bootstrap confidence intervals for boot-p for the unknown parameters ), we apply the following algorithms
- 1.
Generate sample of size n from the and estimate a .
- 2.
Generate another sample of size n using . Then estimate .
- 3.
Repeat step 2 B times.
- 4.
Via
, that is, the CDF of
, the
C.I. of
is given by
where
and
x is prefixed.
For more details about the bootstrap confidence intervals, one may refer to Kundu and Joarder [
26].
8. Simulation Study
In this section, we show the usefulness of the theatrical findings in this paper by conducting series of simulation experiments. The simulations show the bias and estimated risk of bayesian and the maximum likelihood estimates. The biases and ERs are given, respectively, by
and
Coverage probabilities (CPs) are also calculated at the 95% and 90% HPD credible intervals. Point and Interval estimation of the parameters
,
, and
for n = 25, 50, and 100 are presented in
Table 1.
Table 2 represents the simulation results for the parameters
,
and
, respectively for n = 200, 300, and 400. The bayesian estimate are calculated based on GE, LINEX and SE loss functions. In addition, 95% and 90% the confidence, Bootstrap and HPD credible intervals are calculated with the corresponding width. The simulation experiments can be explained though the following steps:
We generate sample of sizes n = 25, 50, 100, 200, 300, 400 from the via initial parameter values are and .
Again use each of the cases in step (1) for calculating the Bayesian estimates for both cases of GE, LINEX and SE loss functions. The parameter in LINEX is chosen as −3 and 7. The parameter in general entropy is chosen as 0.5.
For the Bayesian analysis, we take random values for the hyper-parameters as ∼.
The steeps (1)–(3) are repeated M = 10,000 times, then the estimate, bias and estimated risk (ER) in each cases are calculated in
Table 1 for n = 25, 50, and 100 and in
Table 2 for n = 200, 300, and 400. Obtain the point Estimation of the parameter
and
using MLE and MCMC methods (with 10,000 repetitions and zero burns).
The and approximate confidence, bootstrap HPD credible intervals with their width are calculated.
The bais and ER shows that the Bayesian approach gives better estimates. Also, in most cases the Bayesain estimate based Linex with positive shows good performance.
In most cases the estimation of and in over estimated, while in some cases it is under estimated.
In most cases the estimation of in under estimated, while in some cases it is over estimated.
The interval length increases as the confidence level increases as expected.
9. Application of the E-WD to the Stock Price Data
In this section, we apply the composite distribution E-WD to Sarhad stock exchange market transactions data for four variables especially: the open price, the high price, the low price, and the close price.
Table 3 shows the descriptive statistics of the proposed stock price data. The data is analyzed and the maximum likelihood and the bayesian estimate results for the parameters
and
, respectively, are obtained.
Table 4,
Table 5,
Table 6 and
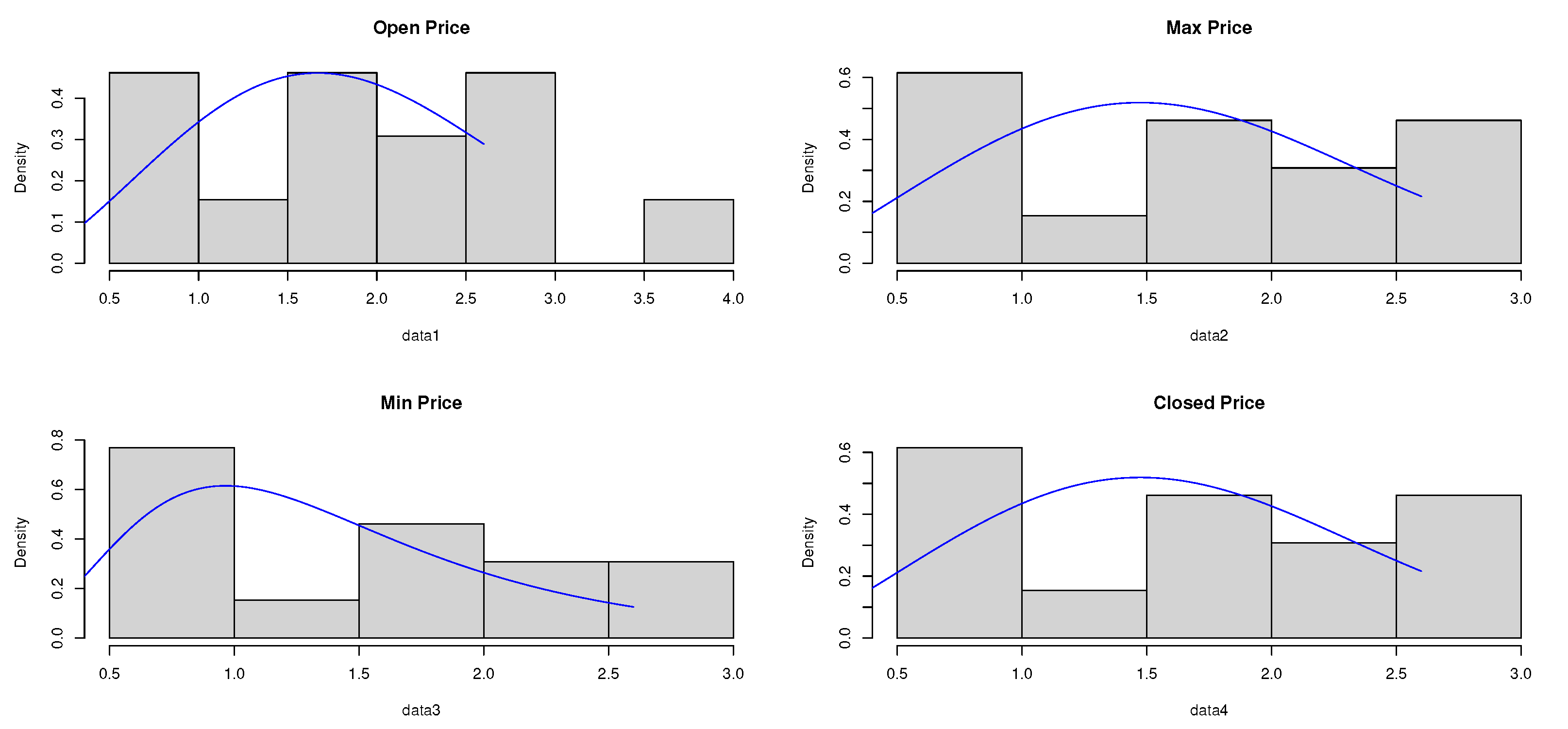
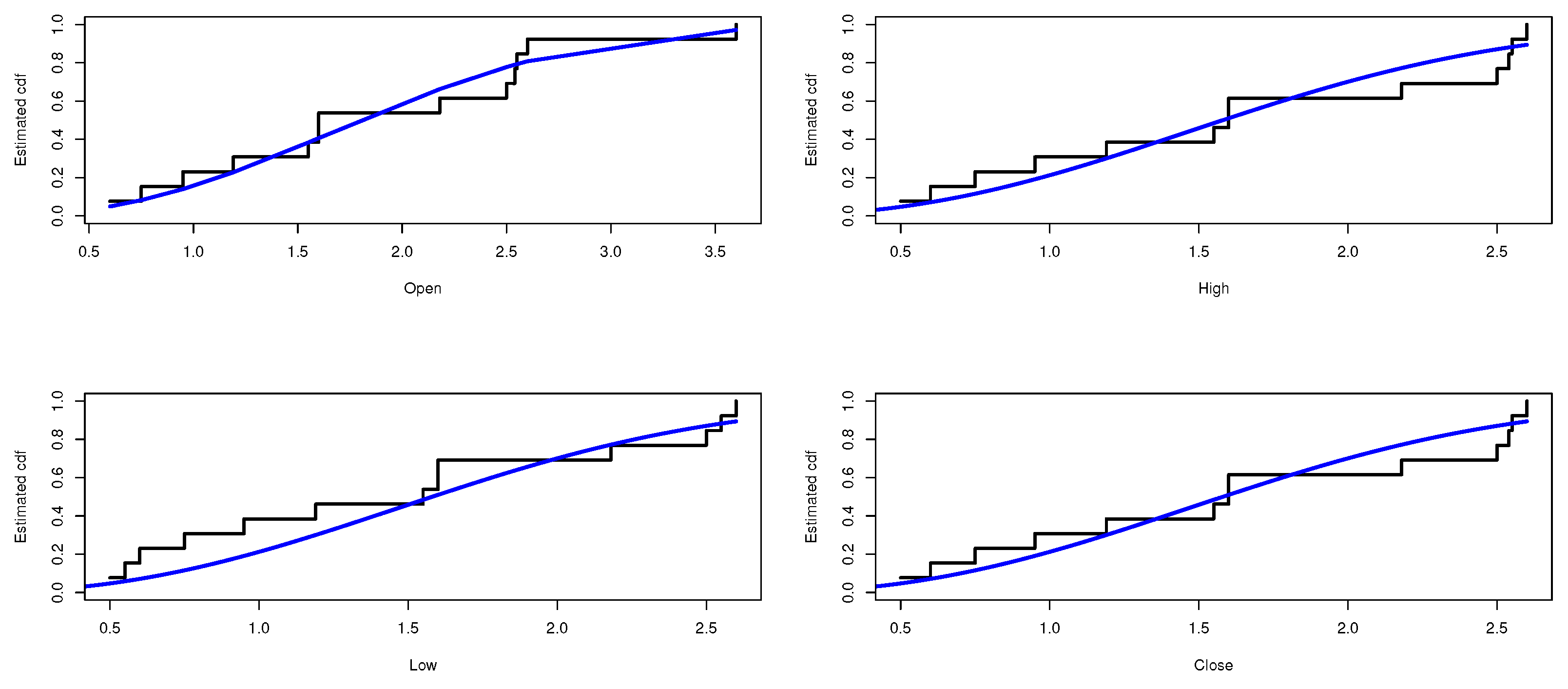
Table 7 represent the estimate result for the opening price, the high price, the low price, and the Closing price, respectively. The stimated PDF and stimated PDF of the proposed data based on E-WD are ploted in
Figure 4 and
Figure 5, respectively. The PP plot are shown in
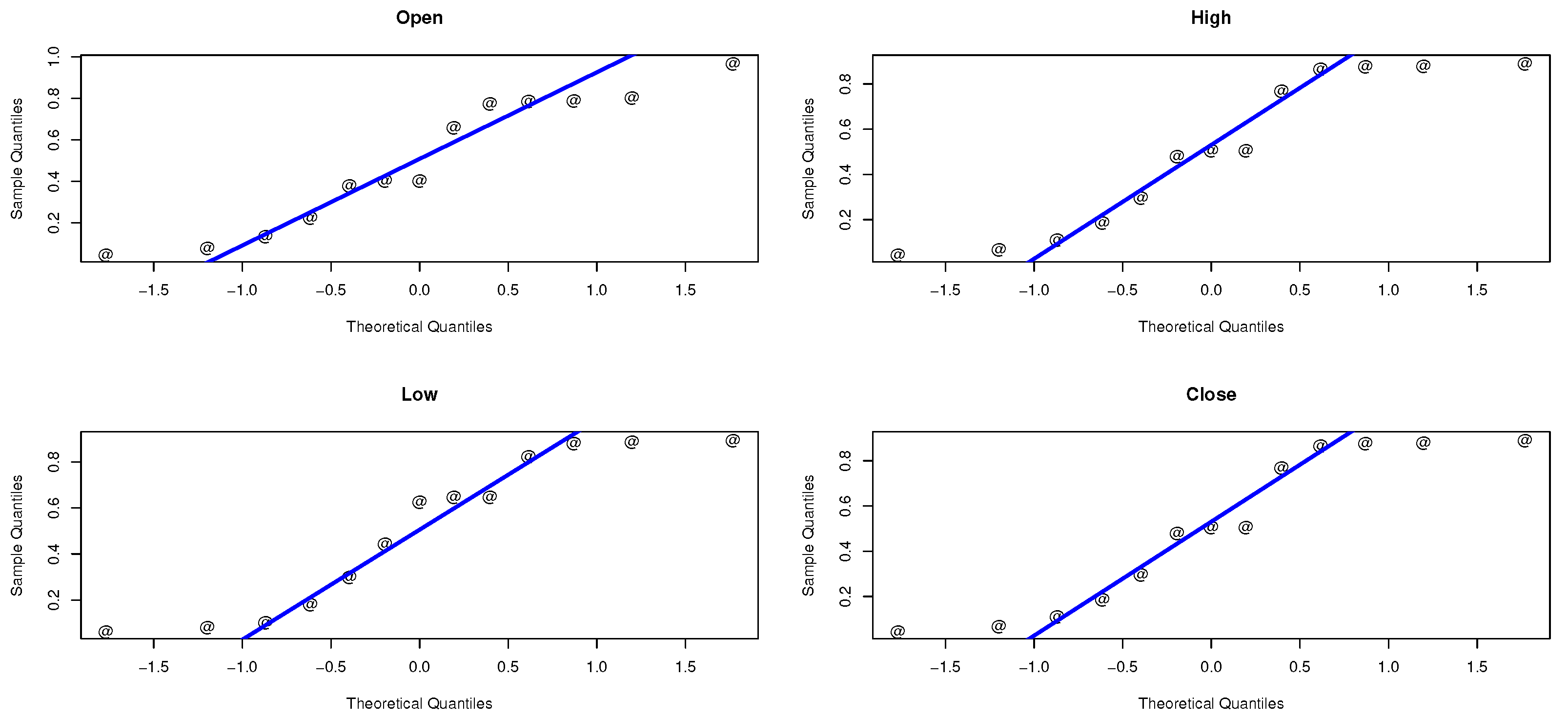
Figure 6. The Kaplan–Meier survival function the Q-Q normality plot are shown in
Figure 7 and
Figure 8, respectively.
The goodness-of-fit results of the E-WD model are compared with some other models, including the Mudholkar exponintiated Weibull distribution [
27] (MEWD), the generalized Weibull Modified Weibull distribution (GWMWD), the generalized Weibull-Rayleigh distribution (GWRD), the exponentiated distribution (EXP-CD). The CDF of the competing probability models are, respectively, given by
and
Table 8 compare the E-WD via some recognition criterion, such as The: Akaike information criterion (AIC), Bayesian information criterion (BIC), Hannan–Quinn information criterion (HQIC) and consistent Akaike information Criterion (CAIC).
Table 9 compares the E-WD based on one-sample Kolmogorov-Smirnov test.
Table 9 compares the E-WD and the competing models with the Kolmogorov-Smirnov test for one sample. The results in
Table 8 and
Table 9 suggest that the E-WD model provides a better fit than other competing models and could be chosen as a suitable model for analyzing stock price data.
From the results in
Table 8 and
Table 9, it can be seen that the model E-WD could be selected as the best model among the fitted models because the proposed model has the lowest values for AIC, BIC, HQC, and CAIC and the highest values for Kolmogorov-Smirnov
p-value.
10. Conclusions
Financial markets play basic role through financial operations, from issuing securities and offering them to investors to making them available for trading. The name of a share is derived from the concept of participation, because the share represents a certain part, a share or a piece of the capital of a listed company, and its owner is considered a shareholder of this company. Shares, for example—These are usually tradable through the trading methods prescribed in the money market regulations. In this study, we introduce a new three-parameter modification of the Weibull model, called the exponentiated Weibull distribution. We proofed that, the new model has many statistical advantages, the flexibility, the heavy-tailed behavior and the regular variation property were offered. We presented many of the important statistical functions including the quantile function, rth-moment, moment generating function, characteristic function, identifiability property, the information generating function, the Shannon entropy and the information energy have been derived in closed forms. The distribution parameters are estimated using the maximum likelihood approach and Bayesian estimation. The squared error loss function, the LINEX loss function, and the general entropy loss function are used for the Bayesian procedure. The simulation result shows that the Bayesian approach gives better estimates and specially Linex loss function with positive constant shows good performance. and interval estimate of each parameter and the corresponding width are obtained. The interval length increases as the confidence level increases as expected. We apply the new composite exponentiated Weibull distribution to the real stock exchange transaction data over four variables, the opening price, the high price, the low price, and the closing price. The goodness of fit results are compared with some other models. The comparisons are made using the Kolmogorov-Smirnov test for one sample and some recognition criterion, such as, the Akaike information criterion, Bayesian information criterion, Hannan-Quinn information criterion and consistent Akaike information criterion. The results indicate that the proposed model provides better fits than other competing models and could be chosen as an adequate model.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}